23
Modeling Scene and Object Contexts for Human Action Retrieval with Few Examples Yu-Gang Jiang Zhenguo Li Shih-Fu Chang IEEE Transactions on CSVT 2011
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 0 times |

Modeling Scene and Object Contexts for Human Action
Retrieval with Few Examples
Yu-Gang JiangZhenguo Li
Shih-Fu ChangIEEE Transactions on CSVT 2011

Outline
• Context-based Action Retrieval Framework• Experiment Result• Conclusion

Framework
A. Video Representation and Negative Sample Selection
B. Obtaining Action Context1. Scene Recognition2. Object Recognition
C. Estimating Action-Scene-Object Relationship
D. Incorporationg Multiple Contextual Cues

Context-Based Action Retrival Framework

A. Video Representation and Negative Sample Selection
• Use the bag-of-features framework

A. Video Representation and Negative Sample Selection
• Use the bag-of-features framework• Use k-means clustering to generate 4000
visual words

A. Video Representation and Negative Sample Selection
• Use the bag-of-features framework• Use k-means clustering to generate 4000
visual words• Quantize each video clip into two 4000-D
histograms of visual words

A. Video Representation and Negative Sample Selection
• Use the bag-of-features framework• Use k-means clustering to generate 4000
visual words• Quantize each video clip into two 4000-D
histograms of visual words• Apply Local and Global Consistency(LGC) [27]
• Pick negative samples after propagation
[27] D. Zhou, O. Bousquet, T. Lal, J. Weston, and B. Scholkopf, “Learning with local and global consistency,” in Proc. Neural Inform. Process. Syst., 2004, pp. 321–328.
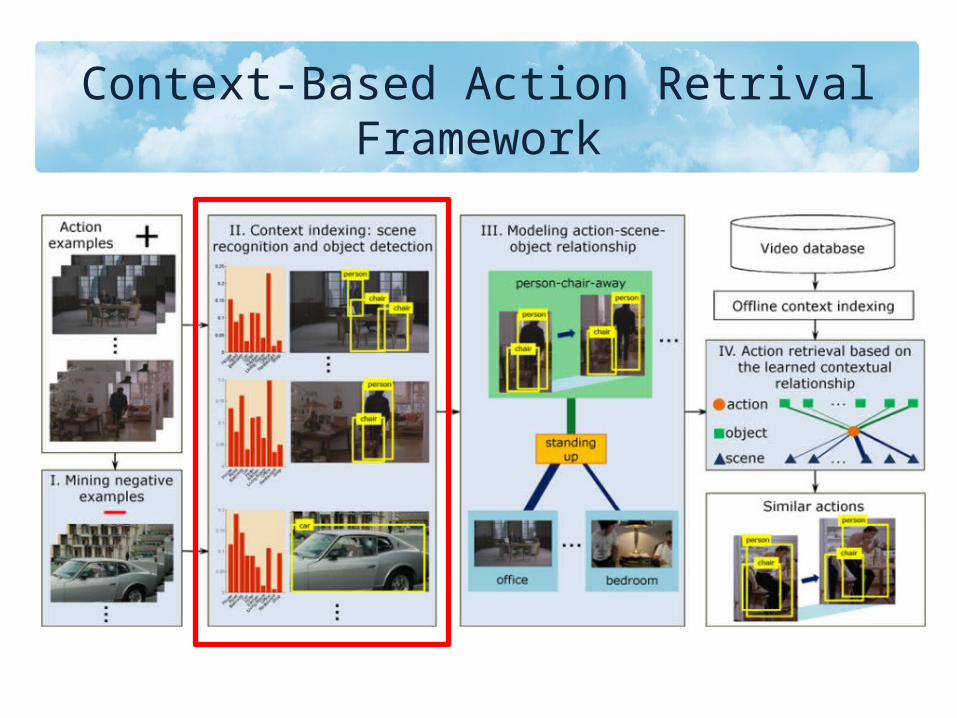
Context-Based Action Retrival Framework

B. Scene Recognition
• Train different classifiers for two bag-of-features and simply average their probability predictions
• The scene models are learned by SVM• Adopt 10 scene classes
House Road Bedroom Car Interior Hotel
Kitchen Living Room Office Restaurant Shop

B. Object Recognition
• It can only detect person, chair and car• Define actions– Track objects based on location and box size– Discard isolated detections
• Compute average spatial distance between different types of object

B. Object Recognition

Context-Based Action Retrival Framework

C. Estimating Action-Scene-Object Relationship
• Define context-based inference score
– Well distinguish samples from P and N
– Produce similar scores if two samples are close

C. Estimating Action-Scene-Object Relationship
• F : prediction matrix of contextual cues• c : coefficient vector
...
…m contextual cues
n training samples
c
F × ...

C. Estimating Action-Scene-Object Relationship
Constraint 1 Constraint 2

Context-Based Action Retrival Framework

D. Incorporating Multiple Contextual Cues
• Given an action a and a test sample x
: context weight parameter: the prediction score of contextual cues on x: action prediction score based on raw visual features: refined prediction after incorporating contextual cues
AnswerPhone DriveCar Eat Kiss GetOutCar HandShake
FightPerson HugPerson Run SitDown SitUP StandUp

Experiment Results
• Mean average precision(mAP)• Retrieval Performance by Raw Features

Experiment Results
• Scene vs. Object

Experiment Results
• Scene vs. Object

Experiment Results
• Comparison to the state of art– SVM learning– Movie script-mining

Conclusion
• An algorithm based on semi-supervised learning paradigm is used to model action-scene-object dependency from limited samples
• This algorithm can be applied to other types of action videos

















