REYNALDO CARVAJAL ORTIZ 93 CAPITULO 5 METODOS ESTADISTICOS PARA ANALISIS BIVARIADO El análisis bivariado permite examinar si existe relación (asociación) entre dos variables. Las variables pueden ser ambas numéricas, una numérica y la otra categórica o ambas categóricas En el área de la Epidemiología el análisis bivariado permite examinar si existe asociación estadística entre exposición y efecto. La estadística proporciona los métodos (Pruebas de significancia) para determinar si la asociación o diferencia observada entre los grupos es o no estadísticamente significante. Estadísticamente significante quiere decir “es poco probable que la diferencia observada entre los grupos pueda ser explicada por efectos del azar”. Por consiguiente, existe asociación estadística entre exposición y efecto. Si se demuestra que el estudio tiene validez interna (control de sesgos) y precisión, es posible concluir que la asociación observada es real, o que los hallazgos obtenidos con el estudio son verdaderos.
Transcript
REYNALDO CARVAJAL ORTIZ
93
CAPITULO 5
METODOS ESTADISTICOS PARA
ANALISIS BIVARIADO
El análisis bivariado permite examinar si existe relación (asociación) entre
dos variables. Las variables pueden ser ambas numéricas, una numérica y
la otra categórica o ambas categóricas
En el área de la Epidemiología el análisis bivariado permite examinar si
existe asociación estadística entre exposición y efecto.
La estadística proporciona los métodos (Pruebas de significancia) para
determinar si la asociación o diferencia observada entre los grupos es o no
estadísticamente significante.
Estadísticamente significante quiere decir “es poco probable que la
diferencia observada entre los grupos pueda ser explicada por efectos del
azar”. Por consiguiente, existe asociación estadística entre exposición y
efecto.
Si se demuestra que el estudio tiene validez interna (control de sesgos) y
precisión, es posible concluir que la asociación observada es real, o que
los hallazgos obtenidos con el estudio son verdaderos.
REYNALDO CARVAJAL ORTIZ
94
La aplicación de pruebas de significancia estadística requiere el
conocimiento de los siguientes conceptos:
5.1. DECISIONES ESTADÍSTICAS
Son aquellas que se toman a partir de la información obtenida en el estudio
(información muestral).
5.2. HIPÓTESIS ESTADÍSTICAS
Son enunciados de relación entre variables (exposición – efecto) que pueden ser verdaderos o falsos.
5.3. HIPÓTESIS NULA
Se nota por Ho. y puede ser verdadera o falsa.
La Hipótesis nula consiste en una proposición de no diferencia. Se
establece con el ánimo de rechazarla con base con los resultados del
estudio.
Rechazar una Hipótesis nula significa que es muy poco probable que la
Hipótesis nula sea cierta y que los resultados obtenidos en el estudio se
deban a simple azar.
5.4. HIPÓTESIS ALTERNA
Se nota por Ha. y puede ser verdadera o falsa.
Cuando se rechaza la Hipótesis nula, el investigador por descarte acepta
la hipótesis alterna (Ha.)
REYNALDO CARVAJAL ORTIZ
95
Aceptar una Hipótesis alterna significa que existe una verdadera asociación
entre exposición – efecto o que las diferencias obtenidas en el estudio
son reales.
El contraste de la Ho., se basa en distribuciones de probabilidad por lo
cual siempre se llega a conclusiones con márgenes pequeños de
probabilidad de error. (nivel de significancia )
5.5. PRUEBAS DE SIGNIFICANCIA ESTADÍSTICA
Son procedimientos que facilitan decidir si una Hipótesis nula se rechaza o
no se rechaza.
La aplicación de estas pruebas parte del supuesto de que se ha utilizado
un diseño de muestreo probabilístico (al azar, sistemático, estratificado o
conglomerados) para obtener la información muestral que permita tomar
decisiones estadísticas.
5.6. Errores en la Prueba de Hipótesis
En el contraste de la Ho., se puede cometer dos tipos de error:
Error Tipo I (). Consiste en rechazar una Hipótesis nula verdadera.
Este error se conoce como nivel de significancia estadística a partir del
cual se toma la decisión de rechazar o no rechazar la Hipótesis nula.
Generalmente se considera un nivel de significancia igual o menor a 5%
(= 0.05, =0.01, etc.).
Error Tipo II (). Consiste en no rechazar una Hipótesis nula falsa.
REYNALDO CARVAJAL ORTIZ
96
El cuadro siguiente resume los dos tipos de error.
Estado Real de la Ho.
Verdadera Falsa
Conclusión con
base en la prueba
de significancia
estadística
Rechazar
Ho.
Error
Poder del
Estudio
(1- )
No rechazar
Ho.
Decisión
Correcta
(1-)
Error
5.7. PODER ESTADÍSTICO DE UN ESTUDIO (POTENCIA)
Capacidad que tiene el estudio para rechazar una Hipótesis nula falsa.
Capacidad que tiene el estudio de detectar diferencias cuando
realmente las hay
Probabilidad de que los resultados del estudio sean verdaderos
Usualmente en el diseño de una muestra, se establecen apriori valores de
poder iguales o mayores a 80%.
Los errores y son inversamente proporcionales y su punto de equilibrio
sucede cuando = 0.05 (confianza del 95%) y = 0.20 (poder del 80%).
REYNALDO CARVAJAL ORTIZ
97
5.8. PASOS PARA APLICAR UNA PRUEBA DE SIGNIFICANCIA
ESTADÍSTICA.
Primero : Establecer la Hipótesis nula (Ho.) y alterna (Ha.)
Segundo: Definir el nivel de significancia (usualmente del 5%).
Tercero : Definir y aplicar la estadística de prueba para obtener el valor
de probabilidad (valor-p).
La correcta aplicación de la estadística de prueba (fórmula
estadística) depende de el nivel de medición de las variables
(nominal, ordinal, numérico), de los supuestos que se deben
cumplir y del tamaño de muestra o cantidad de datos para
analizar.
Se recomienda asesorarse de un buen estadístico.
Cuarto : Comparar el valor-p con el nivel de significancia :
Si valor-p menor o igual que entonces rechazar la Ho.
Si valor-p mayor que entonces No rechazar la Ho.
REYNALDO CARVAJAL ORTIZ
98
5.9. METODOS ESTADISTICOS PARA EXAMINAR ASOCIACION
ENTRE UNA VARIABLE CATEGORICA (INDEPENDIENTE) Y
OTRA NUMERICA (DEPENDIENTE)
Exposición Efecto
Categorías Valores Numéricos
Grupos
1. MAS DE DOS GRUPOS
2. Análisis de varianza de una via (One Way): Estadística F
3. Métodos de comparaciones múltiples:
Scheffe
Tukey
Duncan
Student- Newman- Keuls
2. SOLAMENTE DOS GRUPOS
1. Análisis de varianza de una vía (One way): Estadística F
2. Prueba t de Student: En este caso t = F
3. Pruebas No Paramétricas cuando los supuestos de normalidad
estadística y homogeneidad de varianza no se cumplen: Prueba U
de Mann Whitney, Wilcoxon Matched- Pairs Signed – rank test
REYNALDO CARVAJAL ORTIZ
99
Ejemplo 1:
Se desea estudiar si existe relación entre ingesta de alcohol etílico y tiempo
de reacción (seg) a un estímulo auditivo.
Tiempo de reacción (seg.) a un estímulo auditivo
por grupo de estudio.
GRUPO
A
GRUPO
B
GRUPO
C
1 4 7
2 5 8
3 6 9
4 7 10
5 8 11
Los resultados del análisis estadístico univariado se muestran a
continuación:
GRUPO
A B C
Promedio Aritmético 3.0 6.0 9.0
Varianza 2.5 2.5 2.5
Desviación estándar 1.581 1.581 1.581
Total Datos 5 5 5
Bajo la Hipótesis Nula (Ho) se esperaría de que si no existe asociación
entre ingesta de alcohol etílico y tiempo de reacción (seg) a un estímulo
auditivo, se esperaría igual promedio de tiempo de reacción en cada uno
de los grupos.
Ho: A= B = C
REYNALDO CARVAJAL ORTIZ
100
La hipótesis alterna sería
Ha: A B C Ensayo bilateral
Ha: A B c Ensayo unilateral
Aplicando los pasos para la prueba de Significancia Estadística se
tiene:
Primero: Establecer la hipótesis nula (Ho) y alterna (Ha)
Ho: No existe asociación entre ingesta de alcohol etílico y tiempo
de reacción (seg.) a un estímulo auditivo.
Ha: Si existe asociación entre ingesta de alchohol etílico y tiempo de
reacción (seg) a un estímulo auditivo.
Segundo: Definir el nivel de significancia = 0.05
Tercero: Seleccionar y aplicar la Estadística de Prueba: F
Partiendo del supuesto de que las muestras provienen de
distribuciones normales y como las varianzas obtenidas son
homogéneas se puede utilizar análisis de varianza de una vía
ANOVA, (One Way):
FUENTE
DE VARIACION
SUMA DE
CUADRADOS
GRADOS DE
LIBERTAD
CUADRADOS
MEDIOS
ESTADISTICA F
VALOR-p
Entre grupos 90 2 45
18.0
0.000435 Dentro de grupos 30 12 2.5
Total 120 14
Cuarto: Como el valor–p es menor que = 0.005 se rechaza la Hipótesis Nula y se
acepta la hipótesis alterna.
REYNALDO CARVAJAL ORTIZ
101
Análisis: Los resultados obtenidos muestran que es muy poco probable (valor-p=
0.000435) que las diferencias observadas en los tiempos promedios de
reacción (seg) para los grupos A, B, C se puedan explicar por simple azar. Por
consiguiente, hay diferencias estadísticamente significantes a nivel = 0.05
Conclusión: Existe asociación entre ingesta de alcohol etílico y tiempo de
reacción (seg) a un estímulo auditivo.
Si en lugar de haber comparado tres grupos se hubiesen comparado dos,
para contrastar los promedios se puede utilizar la estadística t de student o
la estadística F, siempre y cuando se cumplan los supuestos de normalidad
estadística y homogeneidad de varianzas. En estos casos siempre t = F
Esquema que ilustra diferentes métodos para aplicación de la estadística
t.
REYNALDO CARVAJAL ORTIZ
102
Ejemplo 2 (Aplicación de la Estadística t)
Los datos siguientes se refieren al estudio realizado en un Centro de Salud
para evaluar la calidad del servicio de Consulta Externa con base en el
tiempo de espera (minutos) para recibir atención médica.
Se desea saber si el tiempo promedio de espera se redujo
significativamente después de aplicar una intervención.
En este caso la variable dependiente es numérica (tiempo) y la variable
dependiente categórica con dos grupos independientes antes y después
de la intervención). Por consiguiente, se puede aplicar una prueba t o su
equivalente una prueba F (ANOVA One way). En caso de no cumplirse los
supuestos estadísticos para su aplicación, se utilizarían métodos No
Paramétricos descritos en el esquema anterior.
TABLA DE ANALISIS DE DATOS
ESTADISTICA
ANTES DE LA
INTERVENCION
DESPUES DE LA
INTERVENCIÓN
Total Datos 100 100
Promedio 48.7 35.0
Varianza 173.202 60.606
Varianza entre muestras 9384.50
Varianza residual 116.90
Estadística F 80.28
valor-p 0.0000
Estadística t 8.959
valor–p 0.0000
REYNALDO CARVAJAL ORTIZ
103
Aplicando los pasos de una Prueba de significancia estadística
tenemos:
Primero: Establecer la Hipótesis nula (Ho) y alterna (Ha)
Ho: El tiempo promedio de espera para atención antes y después de la
intervención es similar.
Ha: El tiempo promedio de espera para atención después de la intervención es
mucho menor que antes de ella.
Segundo: Nivel de significancia = 0.05
Tercero: Con Estadístico de Prueba t, valor–p = 0.0000
Con Estadístico de Prueba F, valor-p = 0.0000
Cuarto: Como valor–p mucho menor que el nivel de significancia ,
se rechaza la Hipótesis Nula
Análisis: El tiempo promedio de espera para ser atendido en consulta
externa disminuyó después de la intervención en
aproximadamente catorce minutos. Dicha disminución no es
por simple azar sino debido a las estrategias aplicadas
durante la intervención. Es posible buscar reducirlo aún mas
sin ir en detrimento del acto médico.
REYNALDO CARVAJAL ORTIZ
104
5.10. METODOS ESTADISTICOS PARA EXAMINAR ASOCIACION
ENTRE DOS VARIABLES CATEGORICAS.
Ambas Nominales Ambas Ordinales
RH
TOTAL
GRAVEDAD
EXPOSICIÓN
TOTAL SEXO + - 0 1 2
H Leve
M Moderada
TOTAL Severa
TOTAL
Coeficientes de asociación . Coeficientes de correlación no
- Contingencia de Cramer paramétricos
- Chi-cuadrado . Prueba de la mediana
- Probabilidad exacta de Fisher . Prueba U de Mann-Withney
- Prueba Q de Cochran . Anova de dos clasificaciones de
- Coeficiente PHI Friedman
Coeficientes de Concordancia
- Kappa de Cohen
- Prueba de McNemar
Medidas de Fuerza de Asociación
- Razón de tasas (Rate Ratio)
- Riesgo relativo (Relative Risk )
- Razón de riesgos (Risk Ratio)
- Desigualdad relativa (Odds Ratio)
REYNALDO CARVAJAL ORTIZ
105
Una Nominal y otra ordinal
GRADO
RECUPERADO
TOTAL SI NO
I
II
III
TOTAL
- Chi-cuadrado para tendencia lineal
- Coeficiente de asociación PHI
- Coeficiente de Cramer
Ejemplo: La tabla siguiente corresponde a los hallazgos en un estudio
de Investigación Operativa. Se desea probar si hubo un cambio
estadísticamente significante después de aplicada la
intervención.
CONSULTA DEMORADA (%) EN CONSULTA EXTERNA ANTES
Y DESPUES DE LA INTERVENCION
SITUACION
CONSULTA EXTERNA
TOTAL
% CONSULTA
DEMORADA SI NO
Antes 63 37 100 63.0
Después 16 84 100 16.0
En este ejemplo ambas variables son categóricas nominales. Por haber
utilizado muestras diferentes de usuarios antes y después de la
intervención se consideran muestras independientes. Además, como el
tamaño de las muestras es suficientemente grande (100) cumple los
supuestos de normalidad estadística y pueden utilizarse para el análisis
pruebas aproximadas como la estadística Z, la estadística chi-cuadrado
corriente y chi-cuadrado de Mantel y Haenzel, en lugar de pruebas exactas
como la Dos binomial o la Hipergeométrica. Como medida de fuerza de
asociación se puede utilizar el riesgo relativo porque la consulta demorada
se puede considerar “Incidencia Acumulada”
REYNALDO CARVAJAL ORTIZ
106
Aplicando los pasos de una prueba de significancia estadistica
tenemos:
Primero: Establecer la Hipótesis nula (Ho) y alterna (Ha).
Ho: No existen diferencias en los porcentajes de consulta demorada antes y
después de aplicada la intervención.
Ha: Existen diferencias significantes en los porcentajes de consulta demorada
antes y después de aplicada la intervención.
Segundo: Definir el nivel de significancia = 0.05
Tercero: Seleccionar y aplicar la estadística de prueba para obtener el
valor de probabilidad. (valor-p).
- La estadística Z para diferencia de proporciones arroja un valor-p igual a
0.0000
- La estadística chi-cuadrado corriente da un valor–p igual a 0.0000
¡ Siempre estas dos estadísticas dan resultados iguales en una tabla de
cuatro casillas!
Cuarto: Comparar el valor-p con el nivel de significancia :
Como el valor-p de la prueba de significancia es menor que el nivel de
significancia , se rechaza la Hipótesis Nula.
Análisis: El porcentaje de consulta demorada después de la intervención
cambió dramáticamente de 63% (antes) a 16% (después). Estas
diferencias pueden deberse al efecto de la intervención aplicada
y no a simple azar.
REYNALDO CARVAJAL ORTIZ
107
PRUEBAS DE SIGNIFICANCIA ESTADISTICA PARA
COMPARACION DE DOS PROPORCIONES P1 , PO
SI NO
VARIABLES CATEGORICAS
INDEPENDIENTES NO INDEPENDIENTES
CONTRASTE p con P CONTRASTE P1 con Po CONTRASTE P1 con Po
1. Prueba exacta
binomial 2. Prueba aproximada
| p – P| Z= PQ / n
3. Prueba aproximada: Chi-cuadrado con G.L. = 1
Intervalo de Confianza
p Z1 - PQ / n
ESPERADO MAYOR QUE 5
Pruebas exactas Binomial Hipergeometrica
Utilice probabilidad exacta de FISHER
PRUEBAS
APROXIMADAS
1. Chi-cuadrado Corriente M – H Yates 2. Prueba Z
Z
2 = Chi
2
Intervalo de Confianza
(P1 – P0) Z P1q1 / N1 + Poqo / No
Elaborar Tabla 2 x 2 B
+ -
A + c
- b
Dejar para el análisis los pares discordantes
Por TLC: 1. Prueba de NcNemar
Z= (b-c)2 / (b+c)
2. Chi-cuadrado con G.L. = 1
3. Prueba Z con P=0.5 p = Prop.discordante
NP>5
Prueba Exacta Distribución
binomial con
P = 0.5 y n = b + c
REYNALDO CARVAJAL ORTIZ
108
5.11. METODOS ESTADISTICOS PARA EXAMINAR ASOCIACION
ENTRE DOS VARIABLES NUMERICAS
Cuando se tienen dos variables numéricas el mejor análisis estadístico es
el de correlación y regresión.
En Epidemiología clínica este modelo se utiliza mucho en estudios
farmacológicos de dosis respuesta.
Dosis Respuesta
Variable numérica Variable numérica
5.11.1. Introducción al análisis de regresión
Nomenclatura y conceptos básicos
1. Regresión.
Este término se debe al biólogo Galton quién, estudiando la estatura de
hijos y padres, quería ver en que medida la estatura de los hijos
señalaba un regreso, “una regresión” hacia la estatura media de la
raza, cuando la de sus padres se separaba de ella.
Esta técnica estadística busca analizar la relación existente entre una
variable aleatoria dependiente Y y una o más variables aleatorias
independientes X1, X2,............Xk.
La relación o ecuación de regresión de Y en función de X1, X2,............Xk
se denota por Y =f(X1, X2,............Xk); puede ser lineal, curvilínea,
diagonal, ortogonal, polinomica, etc.
REYNALDO CARVAJAL ORTIZ
109
Con base en un análisis de regresión se puede cuantificar en que
medida uno o más variables independientes Xi explican (o predicen) el
comportamiento o variabilidad de una variable dependiente Y.
5.11.2. Análisis de regresión lineal simple
Definir variables: independiente y dependiente
Definir tipo de regresión: Lineal o no Lineal
Verificar supuestos estadísticos
Si supuestos no se cumplen utilizar métodos No Paramétricos
Anexar análisis de varianza y coeficiente de determinación
Para análisis utilizar las tablas siguientes:
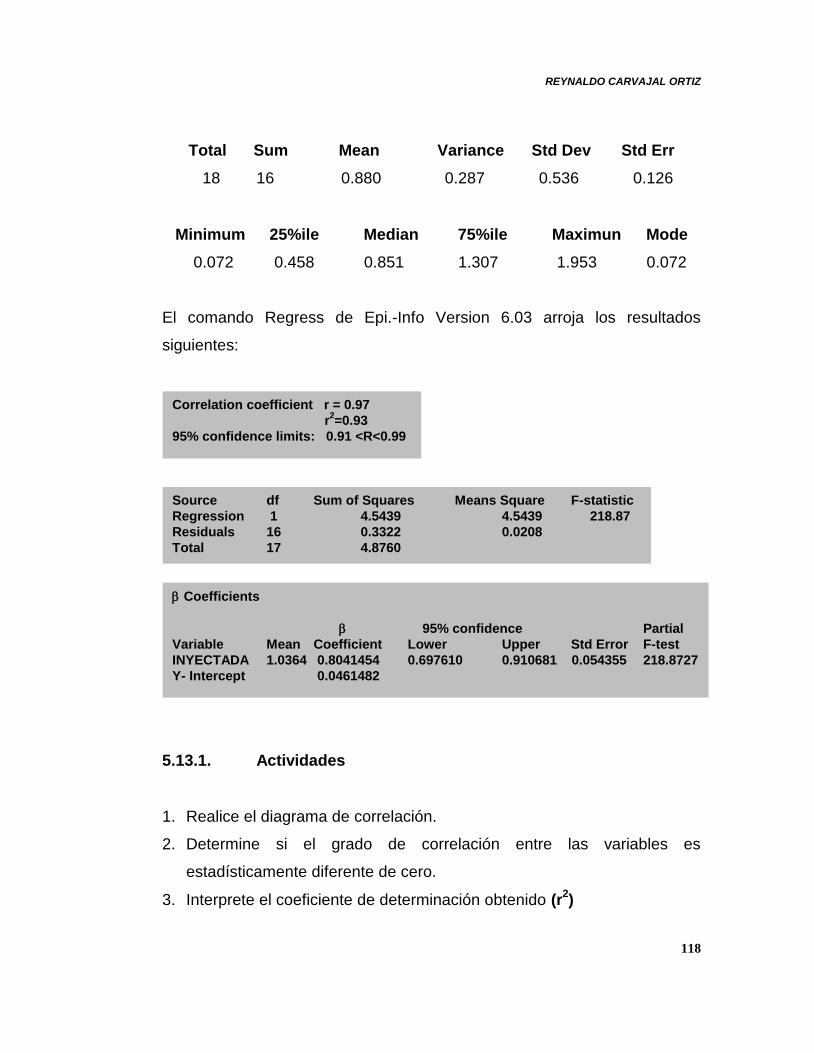
a) Análisis de Correlación
Estadístico Valor
Coeficiente de Correlación
Intervalo de confianza (95%)
Coeficiente de determinación
Coeficiente de correlación lineal r de Pearson
Indica el grado de asociación lineal entre dos variables. Se obtiene
sacando la raíz cuadrada al coeficiente de determinación.
Coeficiente de determinación : 2
Es una medida de la bondad de ajuste del modelo. Resulta del cociente
de dividir la suma de cuadrados debida a la regresión (SCR) entre la
suma total de cuadrados (SCT).
REYNALDO CARVAJAL ORTIZ
110
El coeficiente de determinación varía entre cero y uno e indica que tanto la
variabilidad de la variable dependiente es explicada por la variable
independiente. Se puede expresar en porcentaje.
Si en una regresión lineal 2
= 0, significa no asociación lineal entre las
variables. Pero, puede existir otro tipo de asociación entre ellas.
b) Análisis de Varianza para Regresión
Se utiliza para probar la bondad del modelo de regresión. Esto es, que tan
útil es la variable independiente para explicar el comportamiento de la
variable dependiente Y.
Fuente de
variación
Grados de
libertad
Suma de
cuadrados
Cuadrados
Medios
Estadística
F
Valor-p
Regresión 1
Error (Residual) n –2
Total n - 1
Expresión fundamental del análisis de varianza para regresión.
SCT = SCR + SCE
SUMA TOTAL SUMA CUADRADOS SUMA CUADRADOS DEL
CUADRADOS DE LA REGRESION ERROR (RESIDUALES)
Recordar que 2
= SCR / SCT
REYNALDO CARVAJAL ORTIZ
111
La variabilidad observada en la variable dependiente (suma de
cuadrados totales = SCT) se subdivide en dos partes; la variabilidad
debida al modelo de regresión (SCR) y variabilidad debida al error en la
estimación (Residuales = SCE).
La suma de los cuadrados debida al modelo de regresión (SCR) tiene
p-1 grados de libertad, donde p es el número de parámetros (i) en el
modelo, con i = 1, 2, 3,.......k.
Es un modelo de regresión lineal simple la SCR siempre tiene un grado
de libertad.
La SCE (Residuales) tiene n-p grados de libertad donde n es el total
de casos en el estudio.
Al dividir cada una de estas sumas de cuadrados por sus
correspondientes grados de libertad se obtiene los denominados MEAN
SQUARE (Cuadrados medios) que son las varianzas de la regresión y
de los residuales.
El valor del estadístico F resulta de dividir el cuadrado medio de
regresión entre el cuadrado medio residual.
El estadístico F se utiliza para probar la hipótesis de que la variable
independiente no contribuye con ninguna información para predecir la
variable dependiente. Esto equivale a probar estadísticamente que :
Ho = 1 = 0 en Regresión Lineal Simple
REYNALDO CARVAJAL ORTIZ
112
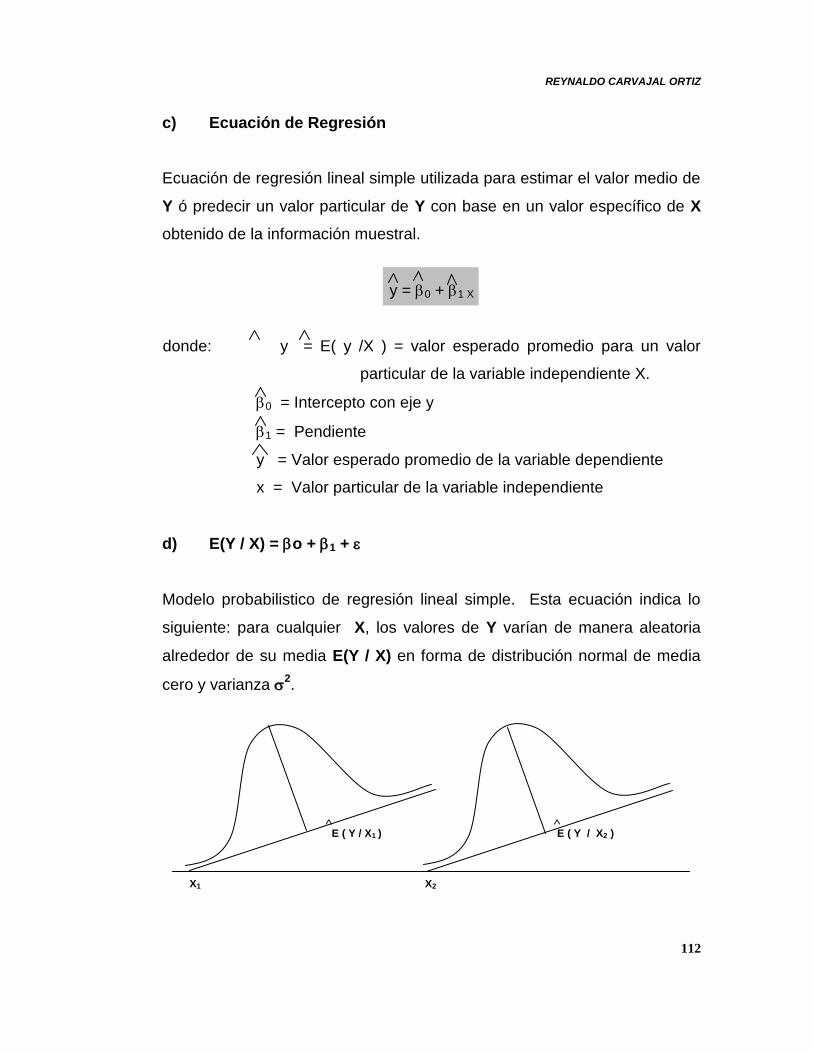
c) Ecuación de Regresión
Ecuación de regresión lineal simple utilizada para estimar el valor medio de
Y ó predecir un valor particular de Y con base en un valor específico de X
obtenido de la información muestral.
y = 0 + 1 X
donde: y = E( y /X ) = valor esperado promedio para un valor
particular de la variable independiente X.
0 = Intercepto con eje y
1 = Pendiente
y = Valor esperado promedio de la variable dependiente
x = Valor particular de la variable independiente
d) E(Y / X) = o + 1 +
Modelo probabilistico de regresión lineal simple. Esta ecuación indica lo
siguiente: para cualquier X, los valores de Y varían de manera aleatoria
alrededor de su media E(Y / X) en forma de distribución normal de media
cero y varianza 2.
E ( Y / X1 ) E ( Y / X2 )
X1 X2
REYNALDO CARVAJAL ORTIZ
113
La letra indica el error aleatorio (medición) y se supone con
distribución normal de media cero y con igual varianza 2
(homocedasticidad).
Este modelo supone también, los valores Yi independientes y las
medidas de distribución de la variable Y condicionadas a los Xi,
situadas en una recta denominada línea de regresión verdadera
(linealidad).
e) Supuestos para análisis de regresión lineal
SUPUESTO 1
Debe existir linealidad entre X, Y. Esta se puede comprobar con el
Coeficiente r de Pearson.
SUPUESTO 2
En el análisis residual el error debe :
Distribuirse Normal
Esto se debe comprobar utilizando un test para bondad de ajuste o
también mediante el test de Shapiro - Wilk que evalúa la correlación
entre los residuales y los valores esperados.
Gráficamente se debe obtener lo siguiente:
yi – yi
X ó Y
REYNALDO CARVAJAL ORTIZ
114
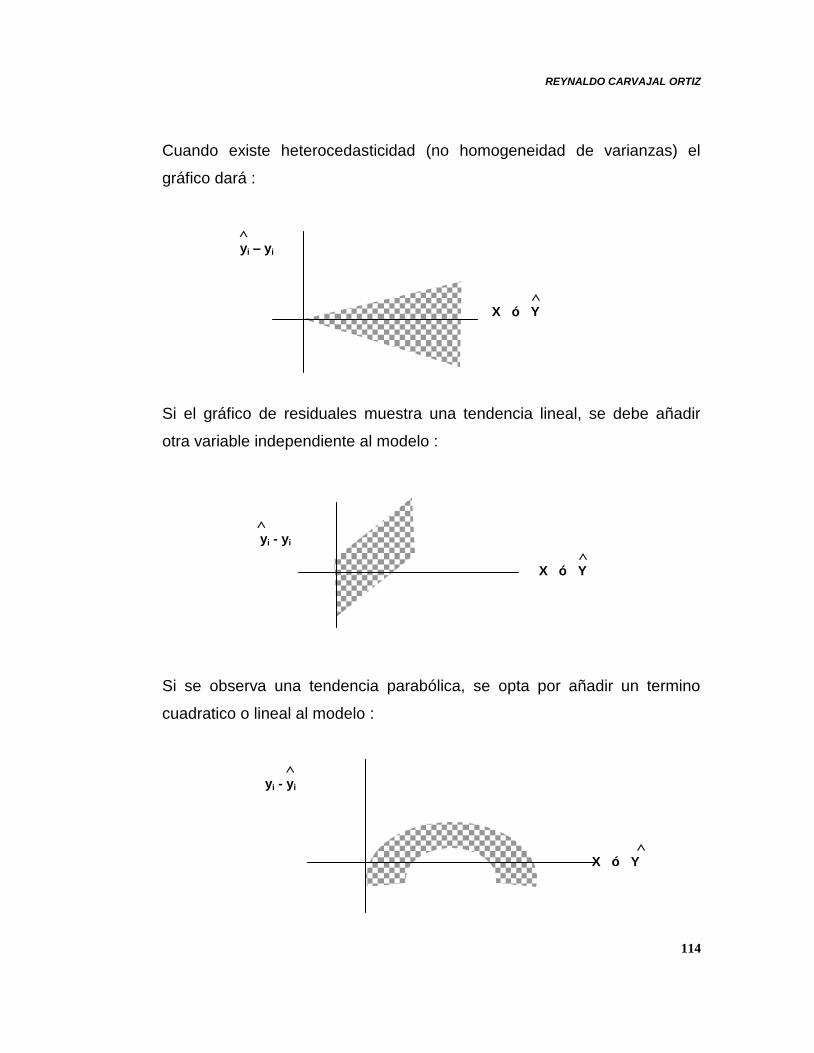
Cuando existe heterocedasticidad (no homogeneidad de varianzas) el
gráfico dará :
yi – yi
X ó Y
Si el gráfico de residuales muestra una tendencia lineal, se debe añadir
otra variable independiente al modelo :
yi - yi
X ó Y
Si se observa una tendencia parabólica, se opta por añadir un termino
cuadratico o lineal al modelo :
yi - yi
X ó Y
REYNALDO CARVAJAL ORTIZ
115
Los errores deben ser independientes
Esto se puede probar con el test de DURBIN–WATSON.
Los errores deben tener varianza costante.
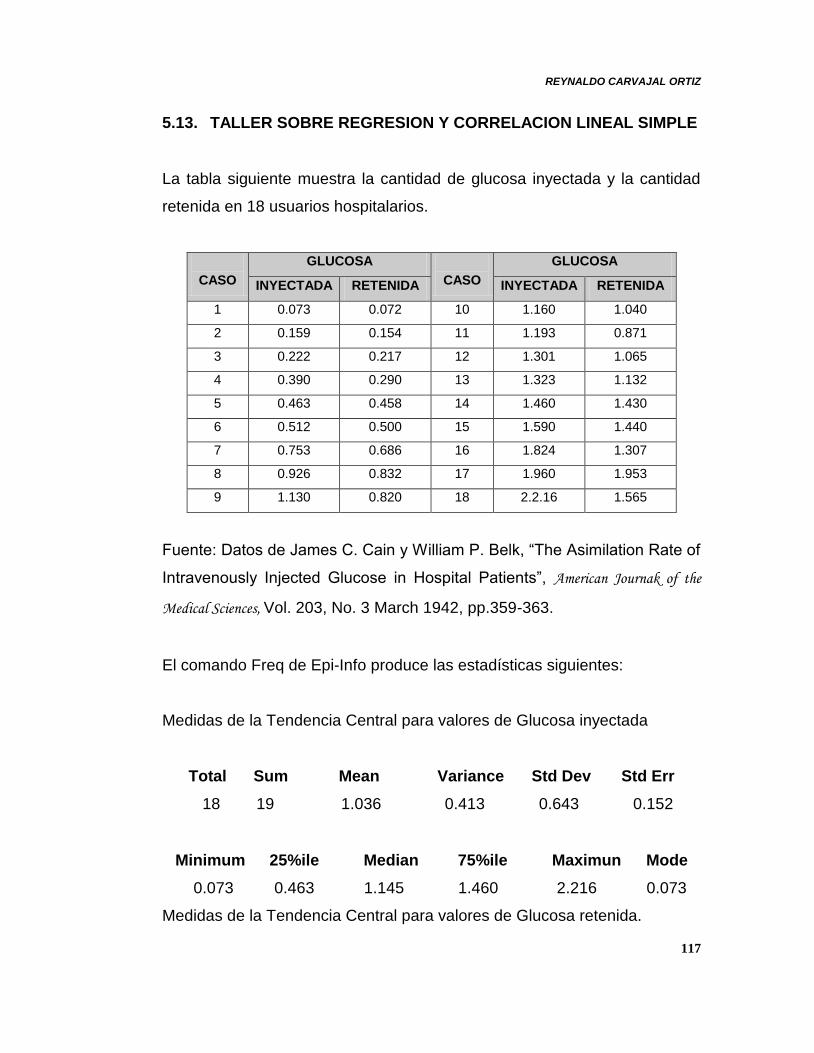
5.12. Ejemplo:
Análisis de Regresión entre Dosis (grm) de alcohol etílico ingerida y