MPI – An introduction by Jeroen van Hunen • What is MPI and why should we use it? • Simple example + some basic MPI functions • Other frequently used MPI functions • Compiling and running code with MPI • Domain decomposition • Stokes solver • Tracers/markers • Performance • Documentation
Transcript
MPI – An introduction by Jeroen van Hunen
• What is MPI and why should we use it?
• Simple example + some basic MPI functions
• Other frequently used MPI functions
• Compiling and running code with MPI
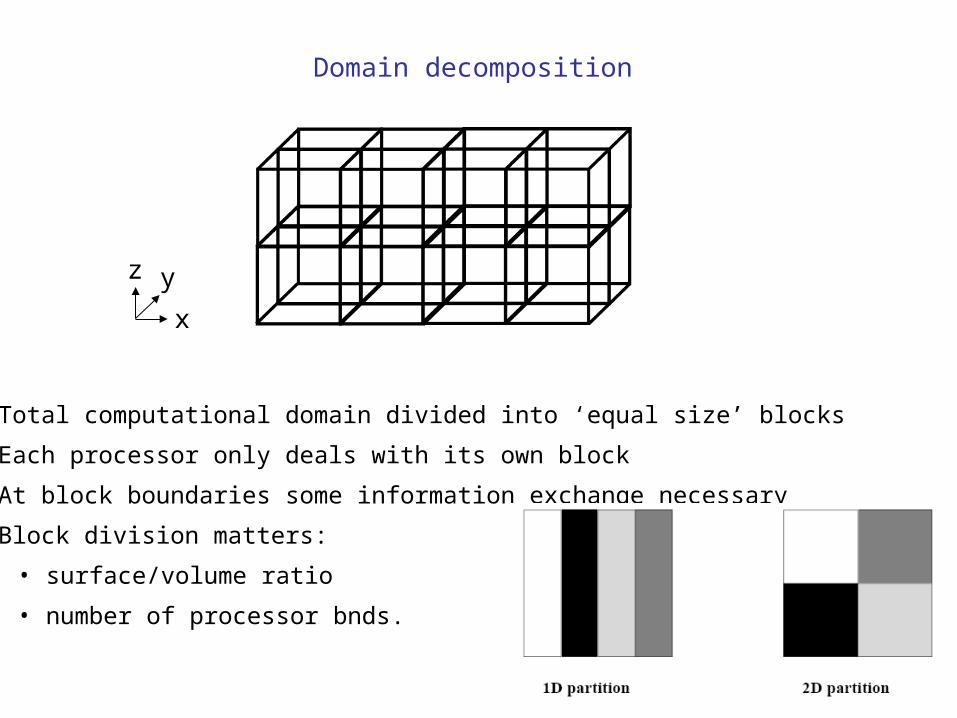
• Domain decomposition
• Stokes solver
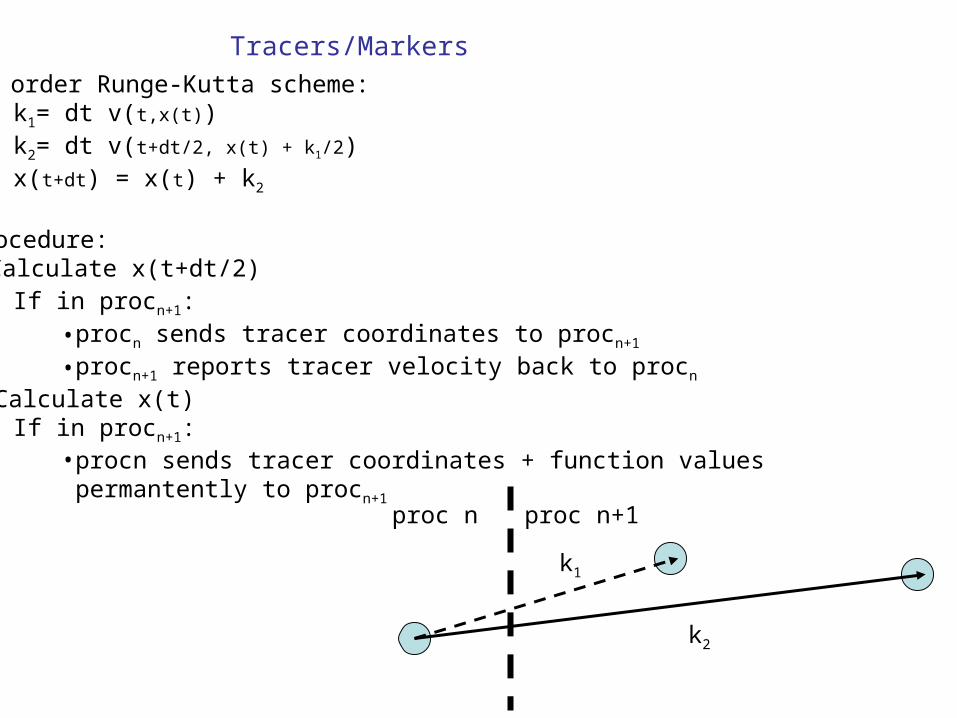
• Tracers/markers
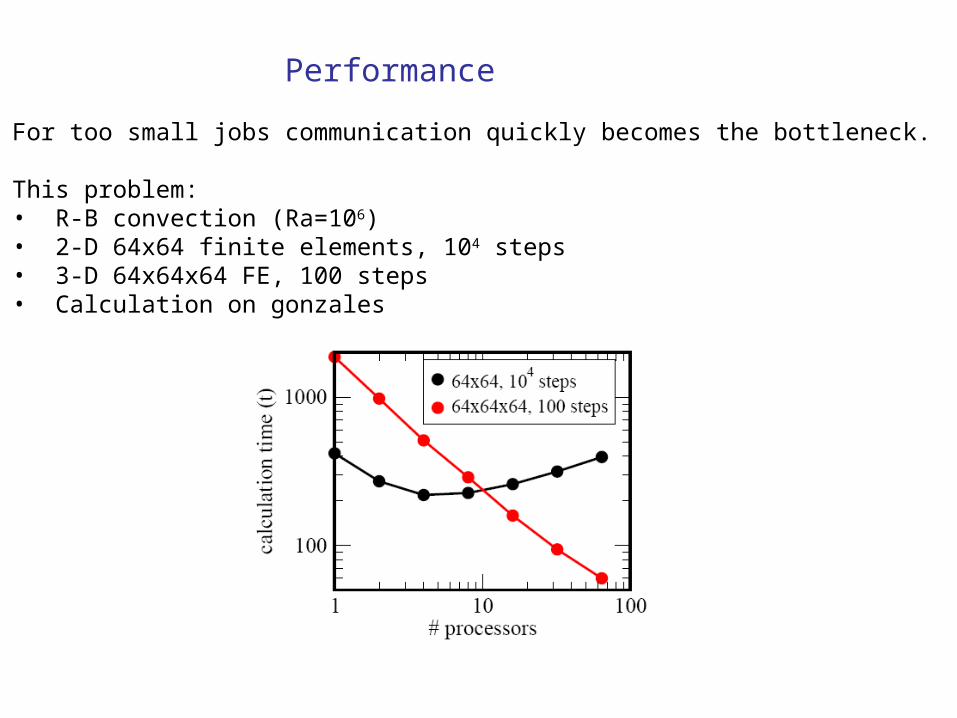
• Performance
• Documentation
What is MPI?
• Mainly a data communication tool: “Message-Passing Interface”• Allows parallel calculation on distributed memory machines• Usually Single-Program-Multiple-Data principle used: all processors have similar tasks (e.g. in domain decomposition)• Alternative: OpenMP for shared memory machines
Why should we use MPI?
• If sequential calculations take too long• If sequential calculations use too much memory
Output for 4 processors:
Code:
contains definitions, macros, function prototypes
initialize MPIask processor ‘rank’ ask # processors p
stop MPI
Simple MPI example
MPI calls for sending/receiving data
in C:
in Fortran:
in C:
in Fortran:
MPI_SEND and MPI_RECV syntax
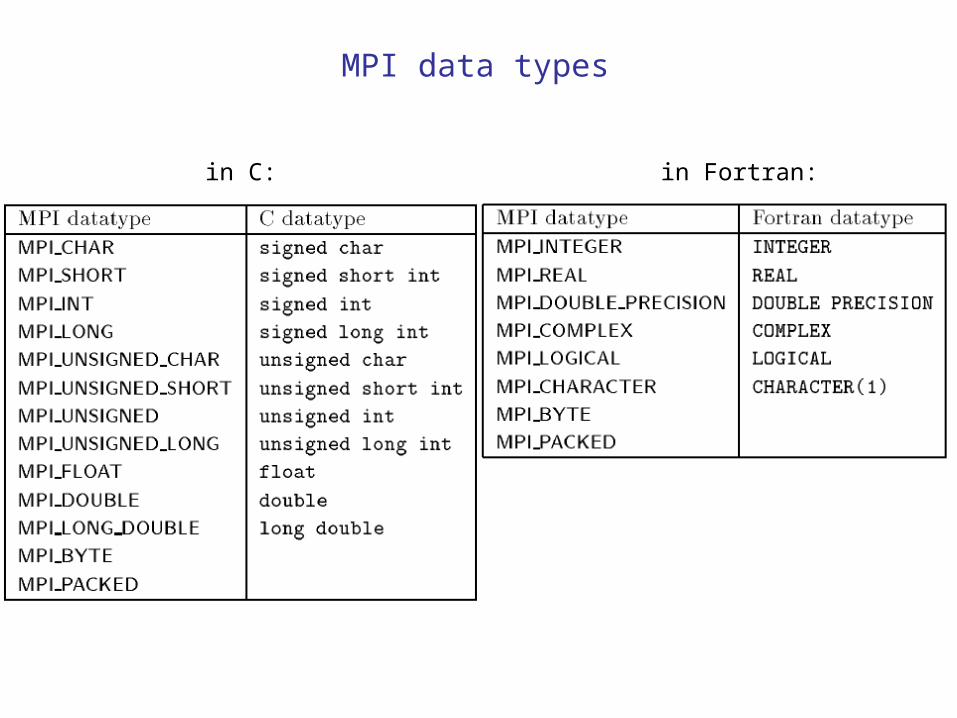
MPI data types
in C: in Fortran:
Other frequently used MPI calls
Sending and receiving at the same time: no risk for deadlocks:
… or overwrite send buffer with received info:
Other frequently used MPI calls
Synchronizing the processors: wait for each other at the barrier:
Broadcasting a message from one processor to all the others: both sending and receiving processors use same call to MPI_BCAST
Other frequently used MPI calls
“Reducing” (combining) data from all processors: add, find maximum/minimum, etc.
OP can be one of the following:
For results to be available at all processors, use MPI_Allreduce:
Additional comments:
• ‘wildcards’ are allowed in MPI calls for:• source: MPI_ANY_SOURCE• tag: MPI_ANY_TAG
•MPI_SEND and MPI_RECV are ‘blocking’: they wait until job is done
Deadlocks:•Deadlock
•Depending on buffer
•Safe
•Don’t let processor send a message to itself•In this case use MPI_SENDRECV


























![What is [Open] MPI?open]-mpi-1up.pdfMay 2008 Screencast: What is [Open] MPI? 3 MPI Forum • Published MPI-1 spec in 1994 • Published MPI-2 spec in 1996 Additions to MPI-1 • Recently](https://static.documents.pub/doc/80x56/6143c7b66b2ee0265c024306/what-is-open-mpi-open-mpi-1uppdf-may-2008-screencast-what-is-open-mpi-3.jpg)

![What is [Open] MPI?open]-mpi-2up.pdf2 May 2008 Screencast: What is [Open] MPI? 3 MPI Forum • Published MPI-1 spec in 1994 • Published MPI-2 spec in 1996 Additions to MPI-1 •](https://static.documents.pub/doc/80x56/6143c7b46b2ee0265c024305/what-is-open-mpi-open-mpi-2uppdf-2-may-2008-screencast-what-is-open-mpi.jpg)

