21
Multilingual Relevant Sentence Detection Using Reference Corpus Ming-Hung Hsu, Ming-Feng Tsai, Hsin-Hsi Chen Department of CSIE National Taiwan University AIRS2004
| Date post: | 02-Jan-2016 |
| Category: |
Documents |
| Upload: | hilary-johns |
| View: | 220 times |
| Download: | 0 times |

Multilingual Relevant Sentence Detection Using Reference Corpus
Ming-Hung Hsu, Ming-Feng Tsai, Hsin-Hsi ChenDepartment of CSIE
National Taiwan UniversityAIRS2004

2
Abstract
IR with reference corpus is one approach which takes the result of IR as the representation of query (sentence), when dealing with relevant sentences detection.
Lack of information and language difference are two major issues in relevant detection among multilingual sentences.

3
Abstract
This paper refers to a parallel corpus for information expansion and translation, and introduces different representations, i.e. sentence-vector, document-vector and term-vector.
The experiment results show that higher performance is gained when larger and finer grain parallel corpus of the same domain as test data is adopted.

4
Introduction
Relevance detection on sentence level is an elementary task in some emerging applications like multi-document summarization and question-answering.
The challenging issue behind sentence relevance detection is: the surface information that can be employed to detect relevance is much fewer than that in document relevance detection.

5
Introduction
Zhang (2002) employed an Okapi system to retrieve relevant sentences with queries formed by topic descriptions.
Instead of using an IR system to detect relevance of sentences, a reference corpus has been proposed (Chen, 2004).
In this approach, a sentence is considered as a query to a reference corpus, and two sentences are regarded as similar if they related to the similar document lists returned by IR systems.

6
Introduction
How to extend the applications to multilingual information access is very important.
This paper extends the reference corpus approach to identify relevant sentences in different languages.

7
Relevance Detection Using Reference Corpus
To use a similarity function to measure if a sentence is on topic is similar to the function of an IR system.
We use a reference corpus, and regard a topic and a sentence as queries to the reference corpus.
An IR system retrieves documents from the reference corpus for these two queries.
Each retrieved document is assigned a relevant weight by the IR system.

8
Relevance Detection Using Reference Corpus
In this way, a topic and a sentence can be in terms of two weighting document vectors.
Cosine function measures their similarity and the sentence with similarity score higher than a threshold is selected.
The issues behind the IR with reference corpus approach include the reference, the performance of an IR system, the number of documents consulted, the similarity threshold, and the number of relevant sentences extracted.

9
Similarity Computation Between Multilingual Sentences
When this approach is extended to deal with multilingual relevance detection, a parallel corpus (document-aligned or sentence aligned) is used instead.
Two sentences are considered as relevant if they have similar behaviors on the results returned by IR systems.
The results may be ranked list of documents or sentences depending on the aligning granularity.
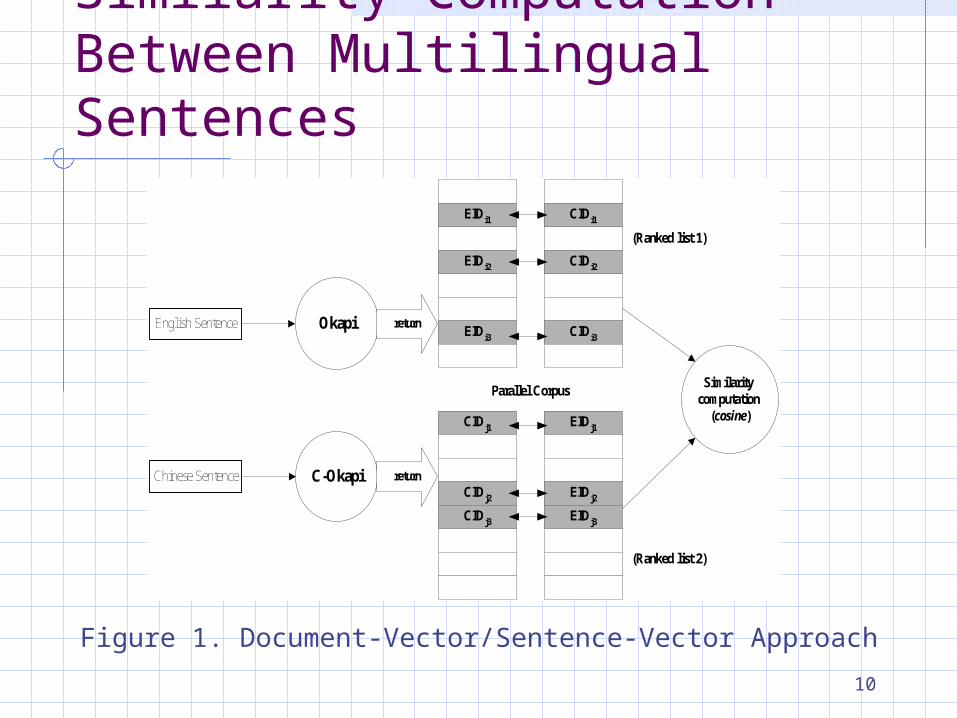
10
Similarity Computation Between Multilingual Sentences
Figure 1. Document-Vector/Sentence-Vector Approach
English Sentence Okapi
C-OkapiChinese Sentence return
return
Similarity computation
(cosine)CIDj1
CIDj2
CIDj3
Parallel Corpus
EIDi1
EIDi2
EIDi3
CIDi1
CIDi2
CIDi3
EIDj1
EIDj2
EIDj3
(Ranked list 1)
(Ranked list 2)
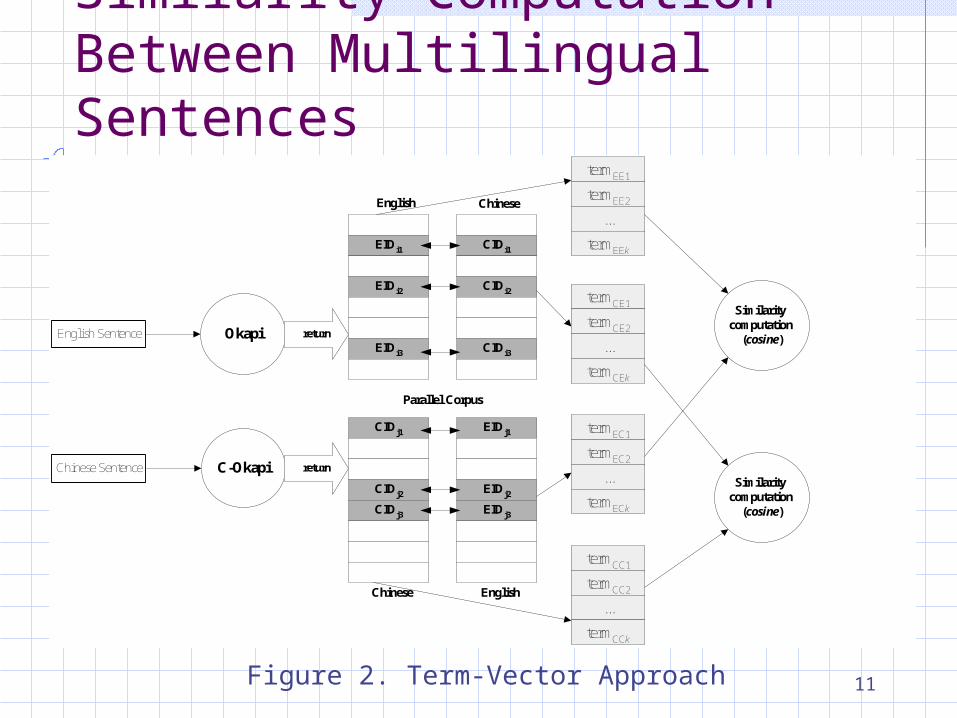
11
Similarity Computation Between Multilingual Sentences
Figure 2. Term-Vector Approach
English Sentence Okapi
C-OkapiChinese Sentence return
return
termCC1
termCC2
...
termCCk
termEE1
termEE2
...
termEEk
termEC1
termEC2
...
termECk
termCE1
termCE2
...
termCEk
Similarity computation
(cosine)
Similarity computation
(cosine)
CIDj1
CIDj2
CIDj3
Parallel Corpus
EIDi1
EIDi2
EIDi3
CIDi1
CIDi2
CIDi3
EIDj1
EIDj2
EIDj3
EnglishChinese
English Chinese

12
Similarity Computation Between Multilingual Sentences
Weighting scheme for term-vector approach:
I. Okapi-FN1
R = # of documents/sentences consulted
r = # of term t occurs in the R documents/sentences
0.5)r0.5)(nr(R
0.5)rnR0.5)(N(rlogW(t)

13
Similarity Computation Between Multilingual Sentences
Weighting scheme for term-vector approach:
II. Log-Chi-Square
χ2 =
Relevant documents/sente
nce
Non-relevant documents/sente
nces
Term t occurs A = r B = n –r
Term t not occur
C = R - r D = N – R – (n - r)
)DC)(DB)(CA)(BA(
)BCAD(N 2

14
Experiment Materials and Evaluation Method
Two Chinese-English aligned Corpora are referenced Sinorama
50,249 pairs of Chinese-English sentences, 500 pairs of them are randomly selected as test sentences. (so only 49,749 pairs of sentences are indexed)
HKSAR 18,147 pairs of Chinese-English documents

15
Experiment Materials and Evaluation Method
Test sentences = <C1, E1>, <C2, E2>, …, <C500, E500>
All test sentences are sent to the IR system, and a Chinese sentence i and a English sentence j are matched.
a match function RM(i, j):
RM(i, j) = |{k| Sim(i, k) > Sim(i, j), 1≦k≦500}| + 1
The evaluation score S(i) for a topic i and MRR
S(i) ={MRR =
1 / RM(i, i) if RM(i, i) 10≦0 if RM(i, i)
500
1)(
500
1i
iS
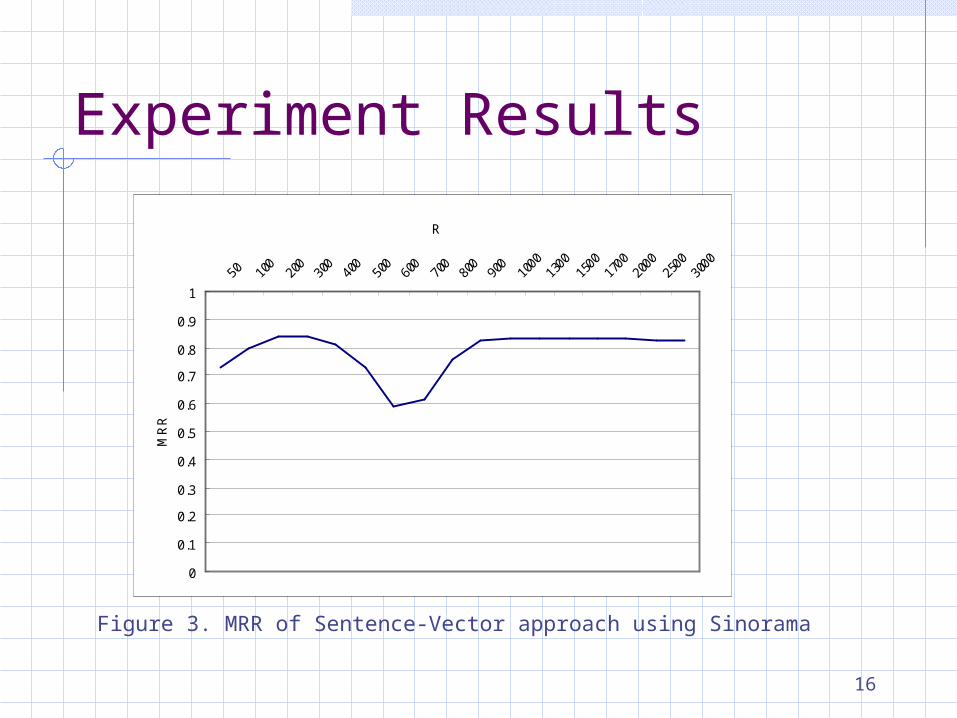
16
Experiment Results
Figure 3. MRR of Sentence-Vector approach using Sinorama
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
R
MR
R
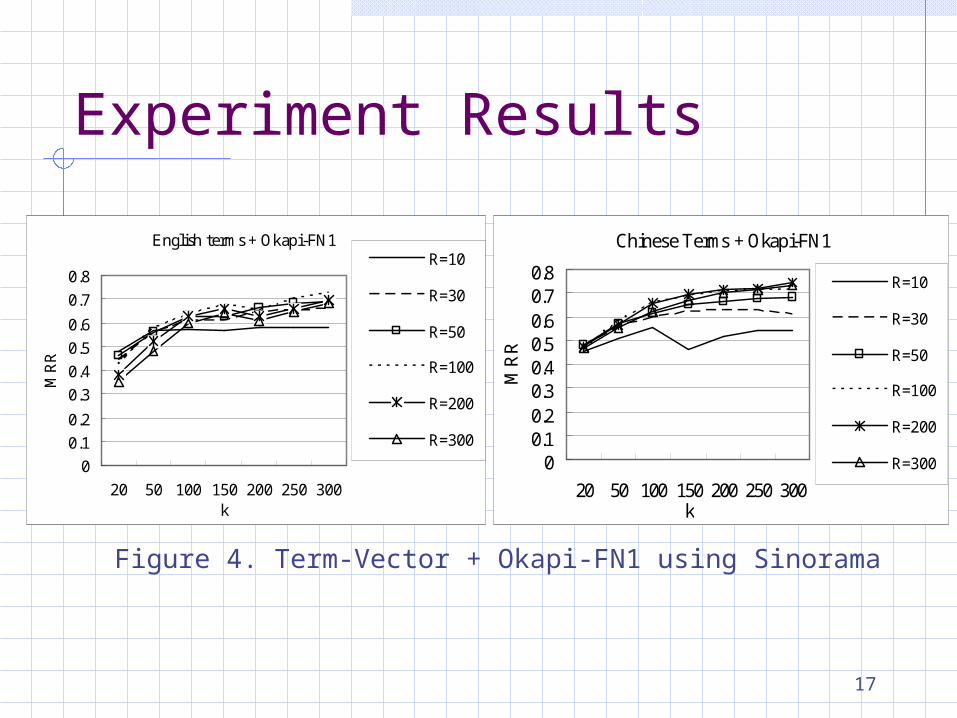
17
Experiment Results
Figure 4. Term-Vector + Okapi-FN1 using Sinorama
English terms + Okapi-FN1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
20 50 100 150 200 250 300k
MR
R
R=10
R=30
R=50
R=100
R=200
R=300
Chinese Terms + Okapi-FN1
00.10.20.30.40.50.60.70.8
20 50 100 150 200 250 300k
MR
R
R=10
R=30
R=50
R=100
R=200
R=300
18
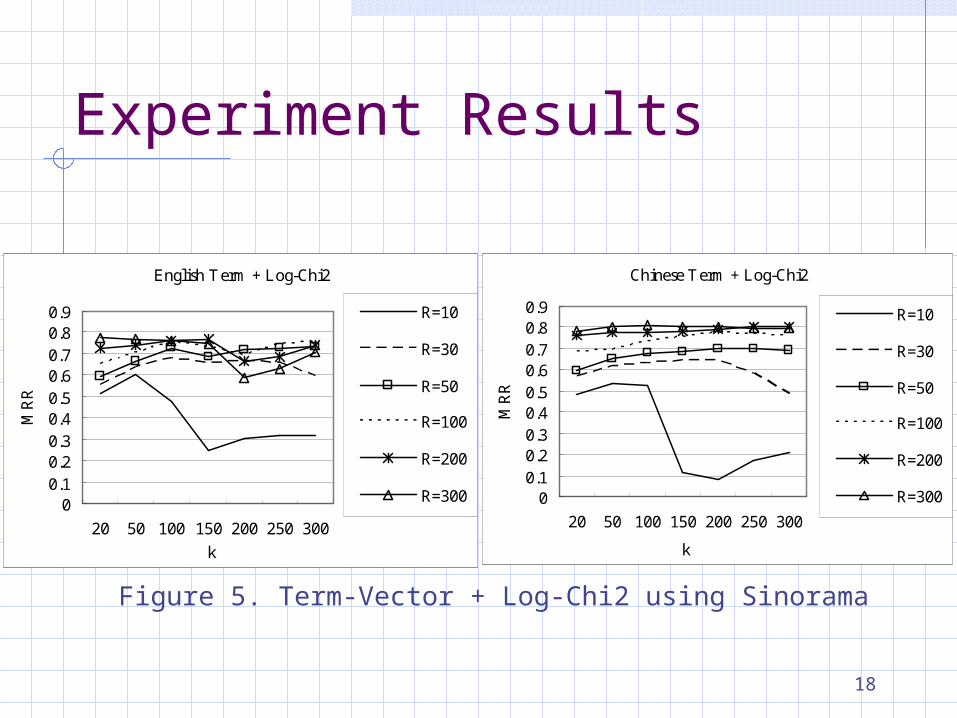
Experiment Results
Figure 5. Term-Vector + Log-Chi2 using Sinorama
English Term + Log-Chi2
00.10.20.30.40.50.60.70.80.9
20 50 100 150 200 250 300
k
MR
R
R=10
R=30
R=50
R=100
R=200
R=300
Chinese Term + Log-Chi2
00.10.20.30.40.50.60.70.80.9
20 50 100 150 200 250 300
k
MR
R
R=10
R=30
R=50
R=100
R=200
R=300
19
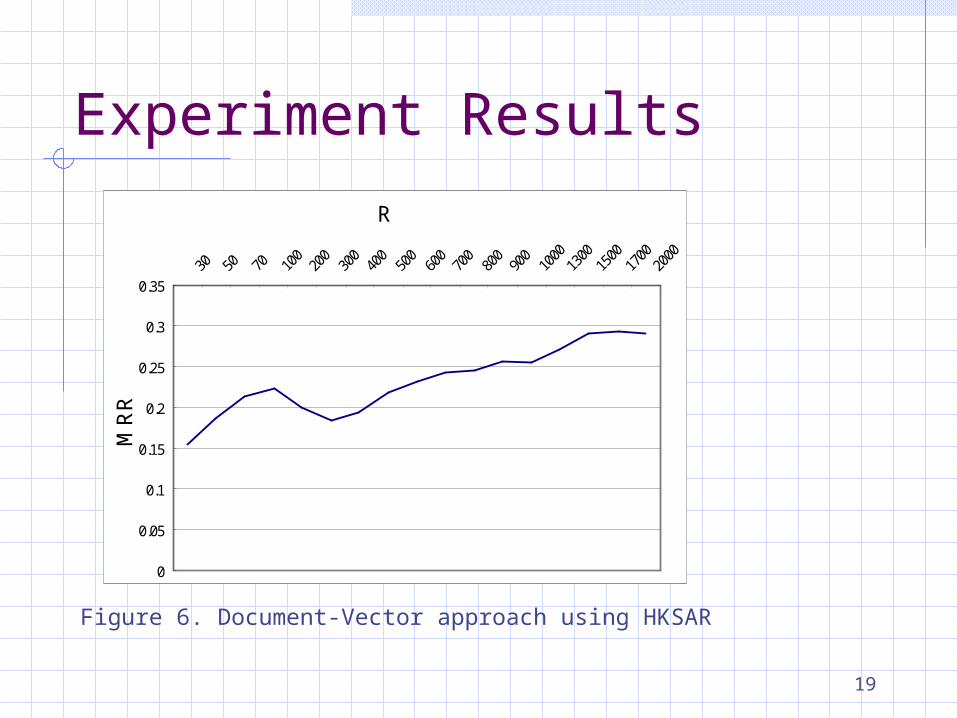
Experiment Results
Figure 6. Document-Vector approach using HKSAR
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
R
MR
R

20
Experiment Results
Figure 7. Term-Vector + Log-Chi2 using HKSAR
HKSAR: Ch term-elements + Log-Chi2
00.02
0.040.060.08
0.10.12
0.140.16
k
MR
R
R=10
R=50
R=100
R=200
HKSAR: English + Log-Chi2
00.020.040.060.08
0.10.120.140.16
k
MR
R
R=10
R=50
R=100
R=200

21
Conclusions and Future Work
This paper considers the kernel operation in multilingual relevant sentence detection, and a parallel reference corpus approach is adopted.
The issues of aligning granularity, the corpus domain, the corpus size, the language basis, and the term selection strategy are addressed.
We infer that a larger domain-coverage and finer-grained corpus is more appropriate to be used, so it demands more experiments to verify it.
Are there more characteristics of IR with reference corpus approach?

















