55
1/5/2009 1 Introduction to Data Mining Kwok-Leung Tsui Industrial & Systems Engineering Georgia Institute of Technology

1/5/2009 1
Introduction to Data Mining
Kwok-Leung TsuiIndustrial & Systems EngineeringGeorgia Institute of Technology

1/5/2009 2
What is Data Mining
• Data mining is– extraction of meaningful/useful/interesting patterns from a large volume of data sources (signal, image, time series, image, transaction, text, web, etc.)
Data mining is one of top ten emerging technology!
( MIT’s Technology Review, 2004)
Data Flood !!

1/5/2009 3
• Data mining is an emerging multi‐disciplinary field:– Statistics (especially, multivariate statistics)– Machine learning– Application Background (e.g., Biology…)– Pattern recognition– Databases– Visualization– OLAP and data warehousing– etc.
DM Fields & Backgrounds

1/5/2009 4
• Data Mining = DM
• Knowledge Discovery in Database = KDD
• Massive Data Sets = MD(Very Large Data Base = VLDB)
• Data Analysis = DA
Commonly Used Language in Data Mining

1/5/2009 5
DM ≠ MDDM ≠ DA
DA+MD = DM ?
• Statistical DM:– Computationally feasible algorithms.– Little or no human intervention.
• Money issue:– DA software (~$ 5-10K), DM software(~ $100K)
Data Mining

1/5/2009 6
• Data Mining is exploratory data analysis with little or no human interaction using computationally feasible techniques, i.e., the attempt to find unknown interesting structure.<source: Ed Wegman>
Statistical Data Mining

1/5/2009 7
• Data mining is the process of exploration and analysis, by automatic or semi-automatic means, of large quantities of data in order to discover meaningfulpatterns and rules.
<source: Mastering Data Mining by Berry and Linoff, 2000>
Data Mining

1/5/2009 8
• Knowledge discovery in databases (KDD) is a multi-disciplinary research field for non-trivial extraction of implicit, previously unknown, and potentially useful knowledge from data.<source: Data Mining by Adriaans and Zantinge, 1996>
KDD

1/5/2009 9
• KDD Process (DM Process)– The process of using data mining methods (algorithms) to
extract knowledge according to the specifications of measures and thresholds, using a database along with any necessary preprocessing or transformations
• Data Mining (& Modeling)– A step in the knowledge discovery process consisting of
particular algorithms(methods) that, under some acceptable objective, produces particular patterns or knowledge over the data.
• Text mining, web mining, etc.• Some people treat DM and KDD equivalently.
KDD & Data Mining

1/5/2009 10
Data Mining, Statistics, CS
Data Miners
Statisticians Computer Scientists
Extract useful information from large amount of raw data
Support data mining by mathematical theory and statistical methods
Support data mining by computational algorithm and relevant software
Friedman

1/5/2009 11
• Bioinformatics
• Sales and Marketing
• Health Care / Medical Diagnosis
• Supply Chain Management
• Process Control
• Network Intrusion Detection
• Astronomy
• Sports and Entertainment
Applications

1/5/2009 12
Examples of DM Applications
• Finance: Forecast stock price or movement using neural network or time series
• Telecom: Predict churn rate and customer usage using tree, logistic regression, and activity monitoring
• Retail: Identify cross selling using association rules, e.g. Market Basket Analysis, RFM Analysis
• Pharmaceutical: Segment customers into different behavior groups using clustering and classification
• Banking: Customer relationship management (CRM) using clustering and association

1/5/2009 13
Examples of DM Applications
• Hotel/airline: Identify potential customers for promotion offers using tree or neural network
• Ocean terminal operation data mining for efficiency improvement
• Sales/demand data mining for inventory planning
• UPS transaction data mining for mail box location design

1/5/2009 14
Prerequisites for Data Mining
• Large amount of data (internal & ext.) (called “data warehouse”, “data mart”, etc.)
– Phone calls, web visits, supermarket transactions, weather data etc.
– Mega-, giga-, tera-bytes, ….
– Information technology advancement
– Most companies have these resources
Friedman

1/5/2009 15
Prerequisites for Data Mining
• Advanced computer technology (big CPU, parallel architecture, etc.)
– allow fast access to vast amount of data
– allow computationally intensive algorithm and statistical methods
• Knowledge in business or subject matter– ask important business questions
– understand and verify discovered knowledge

1/5/2009 16
Data Mining Process
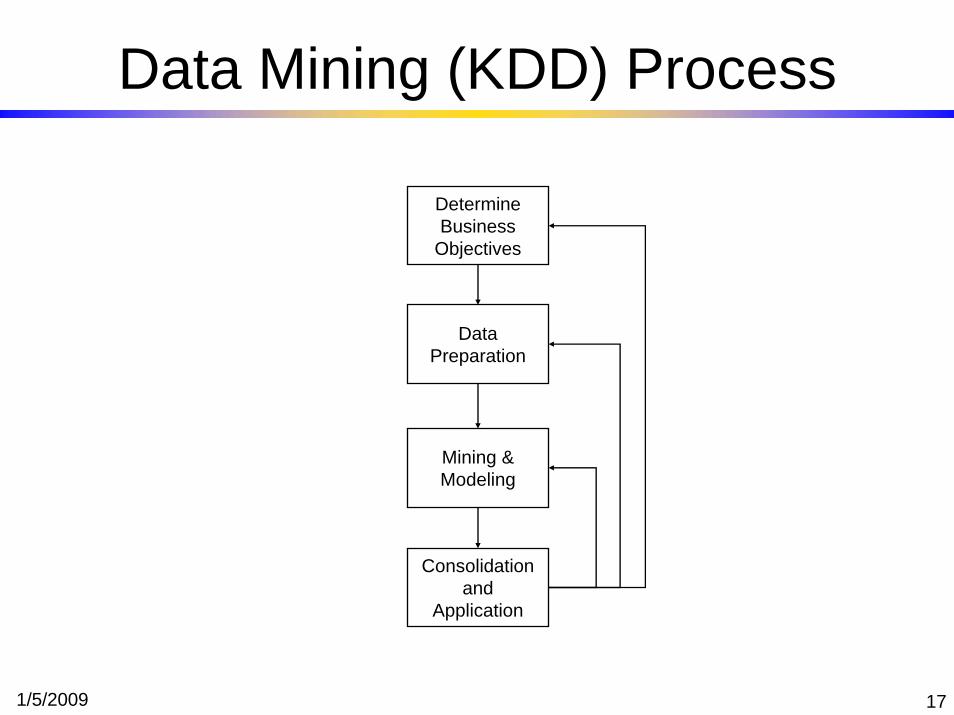
1/5/2009 17
Data Mining (KDD) Process
Determine Business
Objectives
Data Preparation
Mining & Modeling
Consolidation and
Application

1/5/2009 18
Formulate Business Objectives
• Examples of a telecom company:– Identify important customer traits to keep profitable
customers and to predict fraudulent behavior, credit risks and customer churn
– Improve programs in target marketing, marketing channel management, micro-marketing, and cross selling
– Meet effectively the challenges of new product development
Formulate Business
Objectives
Data Preparation
Data Mining
Consolidation and
Application
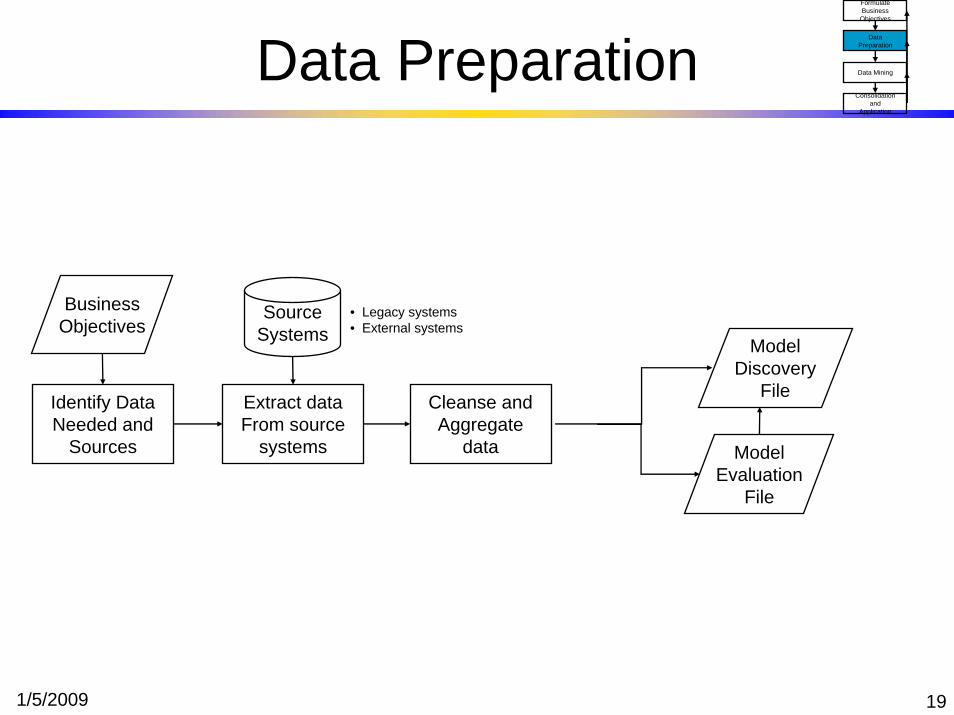
1/5/2009 19
Data Preparation
Extract dataFrom source
systems
Cleanse and Aggregate
data
Source Systems Model
DiscoveryFile
ModelEvaluation
File
• Legacy systems• External systems
BusinessObjectives
Identify Data Needed and
Sources
Formulate Business
Objectives
Data Preparation
Data Mining
Consolidation and
Application
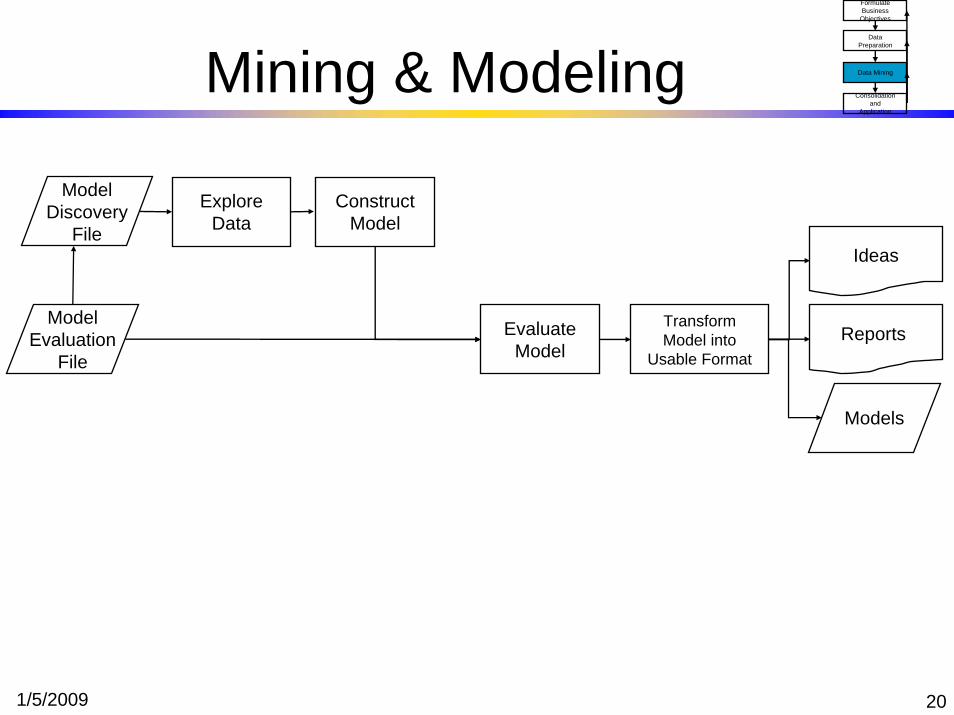
1/5/2009 20
Mining & Modeling
ModelDiscovery
File
ModelEvaluation
File
Explore Data
Construct Model
EvaluateModel
Transform Model into
Usable Format
Ideas
Reports
Models
Formulate Business
Objectives
Data Preparation
Data Mining
Consolidation and
Application
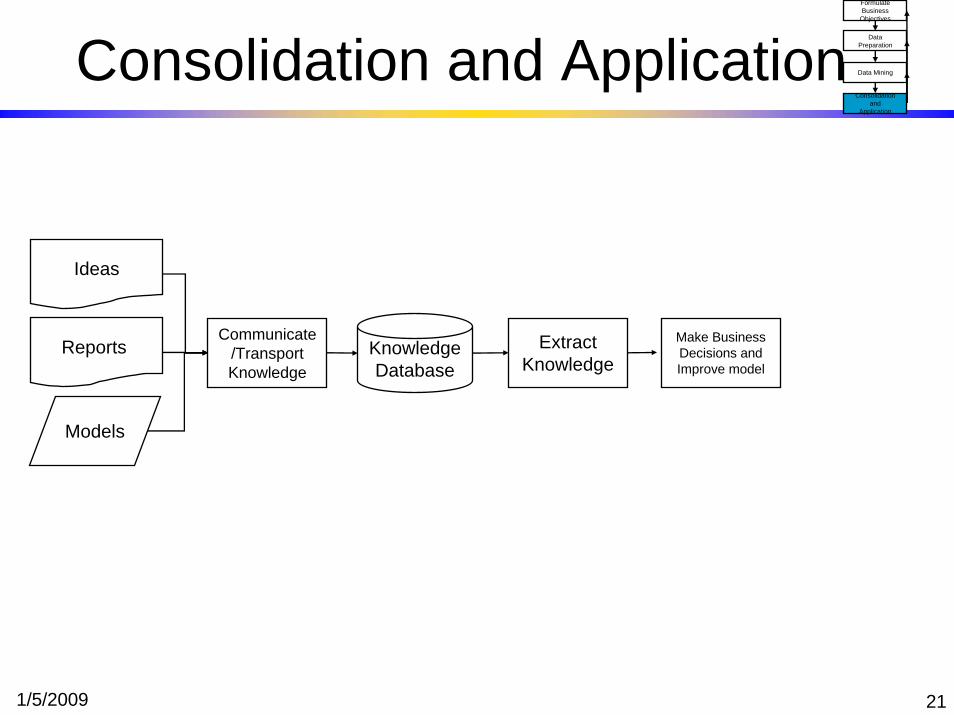
1/5/2009 21
Consolidation and ApplicationFormulate Business
Objectives
Data Preparation
Data Mining
Consolidation and
Application
Ideas
Reports
Models
Communicate/Transport Knowledge
Knowledge Database
Extract Knowledge
Make Business Decisions and Improve model
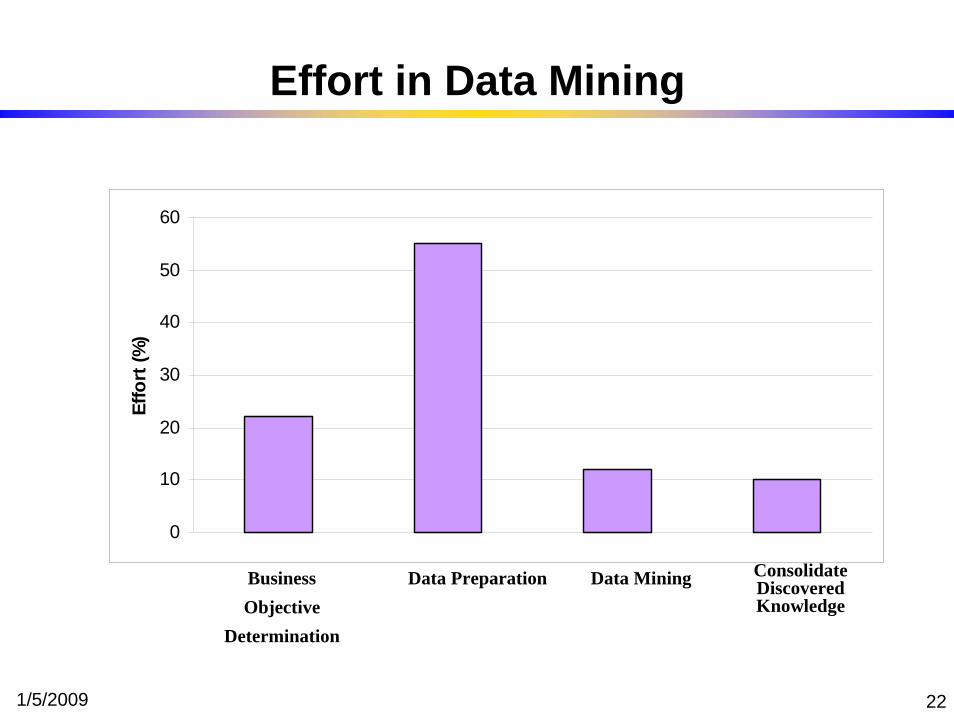
1/5/2009 22
Effort in Data Mining
0
10
20
30
40
50
60
Effo
rt (%
)
BusinessObjective
Determination
Data Preparation Data Mining Consolidate Discovered Knowledge

1/5/2009 23
Data Preparation

1/5/2009 24
• Relational Database• Object Oriented Database• Transactional Database• Time Series, Spatial Database• Data Warehouse, Data Cube• SQL = Structured Query Language• OLAP = On-Line Analytical Processing• MOLAP = Multidimensional OLAP• Fundamental data object for MOLAP is the Data
Cube• ROLAP = Relational OLAP using extended SQL
Databases & Data Warehouses

1/5/2009 25
• Sources of Noises– Faulty data collection instruments, e.g., sensors– Transmission errors, e.g., intermittent errors from
satellite or internet transmissions– Data entry error– Technology limitations error– Naming conventions misused, e.g., same names but
different meaning– Incorrect classification
Data Preparation

1/5/2009 26
• Redundant data– Variables have different names in different databases– Raw variable in one database is a derived variable in
another– Changes in variable over time not reflected in
database• Irrelevant variables destroy speed (dimension
reduction needed)
Data Preparation

1/5/2009 27
• Problem of Missing Data– Missing values in massive data sets
• Missing data may be irrelevant to desired result• Massive data sets if acquired by instrumentation may have
few missing values
• Impute missing data manually or statistically• Missing Value Plot• Traditional methods limited for small data sets
Data Preparation

1/5/2009 28
• Problem of Outliers– Outliers easy to detect in low dimensions– A high dimensional outliers may not show up in low
dimensional projections– Clustering and other statistical modeling can be used– Fisher Info Matrix and Convex Hull Peeling more
feasible but still too complex for Massive datasets (Generally difficult for massive data)
– Traditional methods limited for small data sets
Data Preparation

1/5/2009 29
• Duplicate removal (tool based)
• Missing value imputation (manual and statistical)
• Identify and remove data inconsistencies
• Identify and refresh stale data
• Create unique record (case) ID
Data Cleaning

1/5/2009 30
• The KDD systems must be able to assist in the selection of appropriate parts of the databases to be examined
• For sampling to work, the data must satisfy certain conditions(e.g., no systematic biases)
• Sampling can be very expensive operation especially when the sample is taken from data stored in some databases
Database Sampling

1/5/2009 31
• Data Cube aggregation
• Dimension reduction
• Eliminate irrelevant and redundant attributes
• Data Compression
• Encoding mechanisms, quantizations, wavelet transformation, principle components, etc.
Database Reduction

1/5/2009 32
Data Preparation Using R

1/5/2009 33
Introduction to R
• A software package suitable for data analysis and graphic representation.
• Free and open source.
• Implementation of many modern statistical methods.
• Flexible and customizable.
1/5/2009 34
Software Download of R
• Go to http://www.cran.r-project.org/• Click on Windows (95 and later)• Click on base• Click on R-2.3.0-win32.exe• Press Save to download the file to your
computer.• Install R by doubling click on the downloaded
file and following the instructions.

1/5/2009 35
Using R
• To invoke R,– Go to Start ! Programs ! R
• To quit R, – Type q( ) at the R prompt (>) and press
Enter key.– Or simply close the window.

1/5/2009 36
Using R• A good introduction to R is available at
http://www.cran.r-project.org/– Click on Manuals under Documentations.– Videos on R:
wwww.decisionsciencenews.com/?p=261
• A few important commands– help.start() for a web-based interface to
the help system.– Help(topic) or ?topic for help on topic.– help.search(“pattern”) for help pages
containing pattern.

1/5/2009 37
Data Preparation
Data Matrix
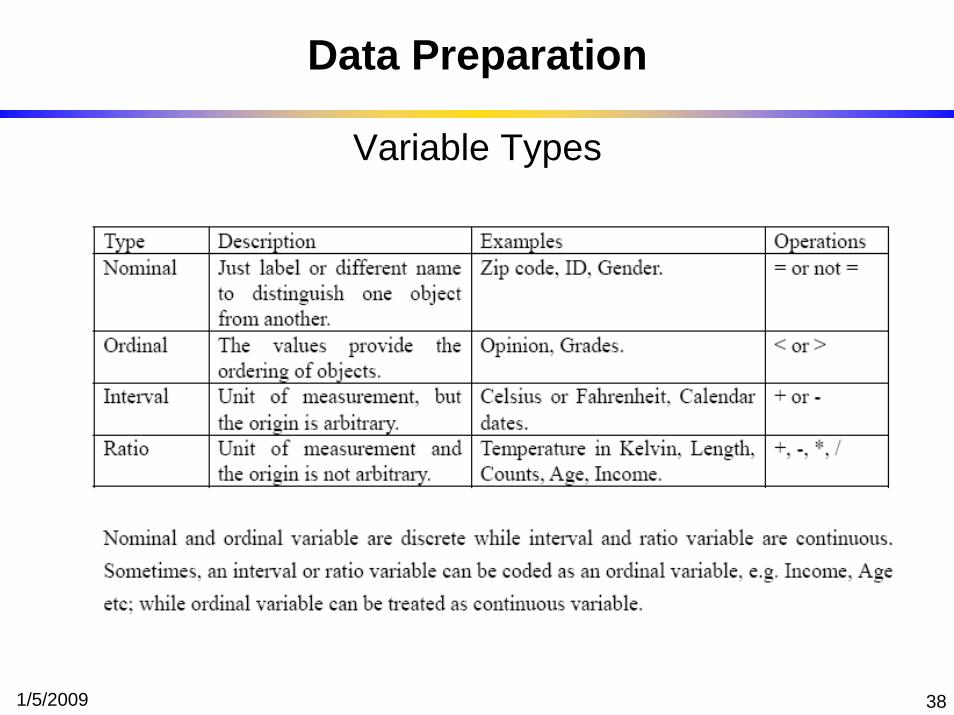
1/5/2009 38
Data Preparation
Variable Types

1/5/2009 39
Data Preparation
Missing Values

1/5/2009 40
Data Preparation
Missing Values

1/5/2009 41
Data Preparation

1/5/2009 42
Data Preparation

1/5/2009 43
Data Preparation
Data Dissimilarities (Distances)

1/5/2009 44
Data Preparation
Data Dissimilarities (Distances)

1/5/2009 45
Data Preparation
Data Dissimilarities (Distances)

1/5/2009 46
Data Preparation
Data Dissimilarities (Distances)

1/5/2009 47
Data Preparation
Data Scaling of Mixed-Type Data

1/5/2009 48
Data Preparation
Outlier Detection
Grubb’s test (z-score rule, non-resistant):

1/5/2009 49
Data Preparation
Outlier Detection
• Other Rules:– CV Rule:
• CV (coefficient of variation) = SD/mean• Call for outlier if CV exceeds certain threshold.
– Resistant Rule: • Resistant Score = (X – median )/ MAD• MAD = Median absolute deviation• Call for outlier if Score exceeds certain threshold
(say 5)

1/5/2009 50
Data PreparationData Preparation
Mahalanobis Distance(multi-dimensional data)
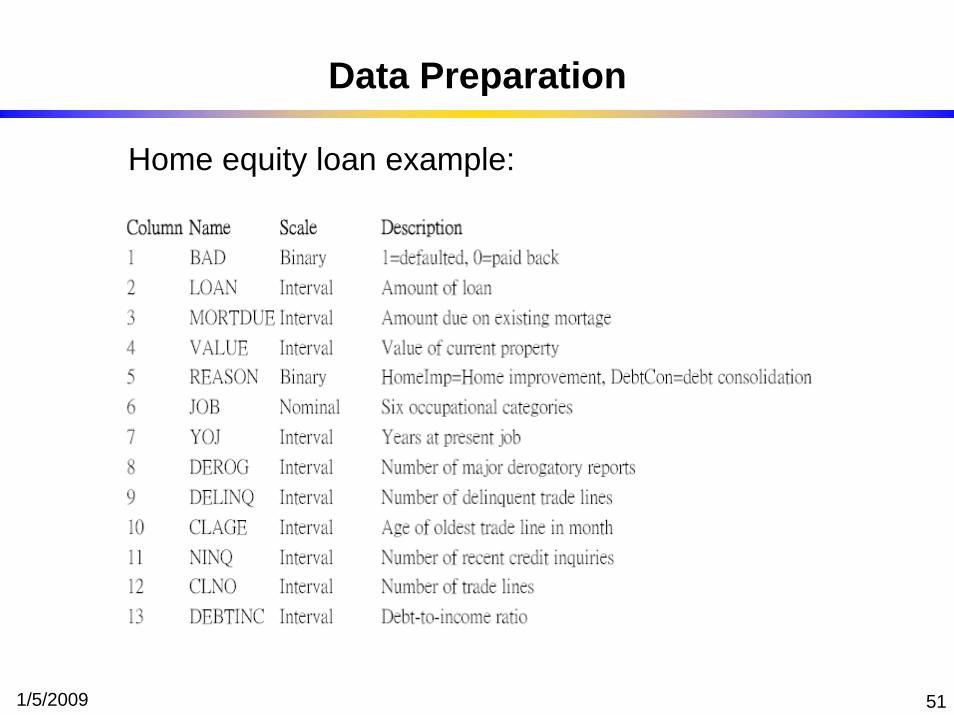
1/5/2009 51
Data Preparation
Home equity loan example:

1/5/2009 52
Data Preparation
1. Download data:
2. Remove cases with missing data:

1/5/2009 53
Data Preparation
3. Remove outliers.3a. Separate the data into two groups
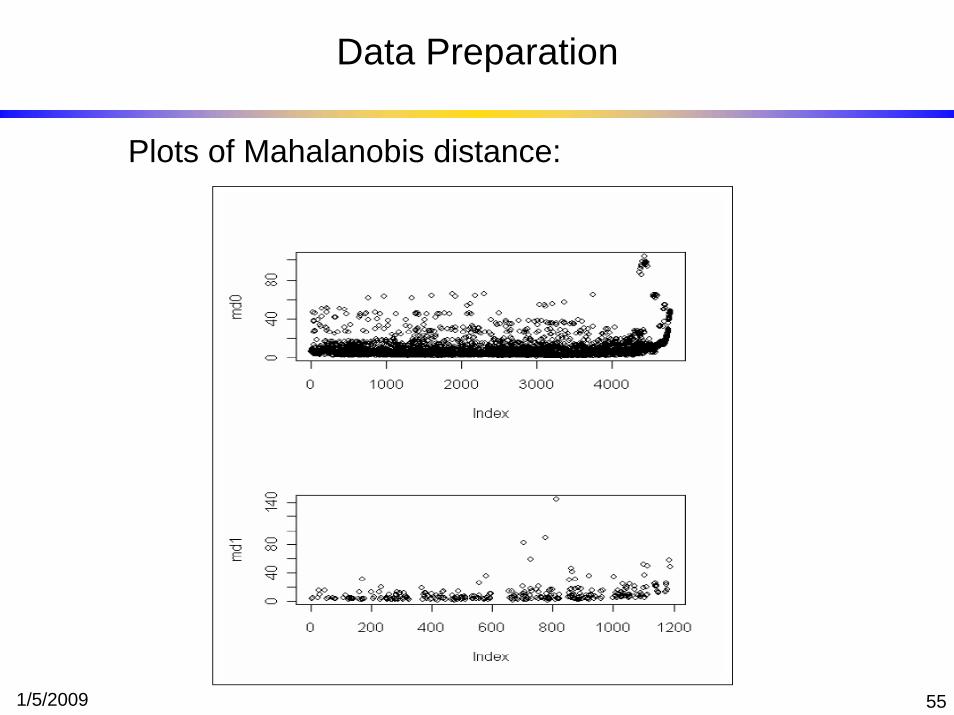
3b. Compute Mahalanobis distance for each group:

1/5/2009 54
Data Preparation
3c. Remove outliers in each of the two groups:
3d. Combine the two groups of data & write to file:
1/5/2009 55
Data Preparation
Plots of Mahalanobis distance:

















