36
NaLIX Natural Language Interface for querying XML Huahai Yang Department of Information Studies Joint work with Yunyao Li and H.V. Jagadish at University of Michigan
| Date post: | 01-Jan-2016 |
| Category: |
Documents |
| Upload: | douglas-walsh |
| View: | 215 times |
| Download: | 0 times |

NaLIXNatural Language Interface for
querying XML
Huahai Yang
Department of Information Studies
Joint work with Yunyao Li and H.V. Jagadish
at University of Michigan

Outline
• Motivation• Basic ideas• System design• Live demonstration of NaLIX• User study• Conclusion• Q & A

XML is Everywhere
• Extensible Markup Language (XML) for data exchange and storage
• Almost every application domain is moving towards XML based document formats – Digital libraries– Office documents– GIS– ...

How to Query XML?
• We can of course use keywords search. Can we do better?
After all, XML has structures.

Example XML Fragment
<bookinfo>
<book>
<title>One Fish Two Fish</title>
<author>John Meyer</author>
<author >Peter Smith</author>
<price>7.95</price>
</book>
<book>
<title>Goodnight Moon</title>
<author >Margaret Brown</author>
<price>10.55</price>
</book>
</bookinfo>

Example Query
Query: Find titles and prices of books by ‘Meyer’
bookinfo
Just Lost
book
title author
author
price
Mercy Meyer
Gina Meyer
$5.75
book
titleprice
Brown Hedi
$13.95

More Powerful Queries
• Aggregation– What are the books with more than 5
authors?• Value Join
– Find all the books, where an author of each book is the same as an author of Pride and Prejudice.
• Nesting– Find all the articles published in 2000 and
with keyword “XML”.

Standard Approach - XQuery
• XQuery –a structured query language – search for specific information within
XML documents primarily based on path expression

Standard Approach - XQuery
for $b in document(“bib.xml”)//book
where $b/author contains ‘Meyer’
return <result>
<title> $b/title </title><price> $b/price </price>
</result>
Query: Find titles and prices of books by ‘Meyer’
book
titleauthor
author
price
book
titleprice
bookinfo

Another Document Structure
• The same XQuery no longer works
author
name
Dr. Meyer
author
namebook
M. Brown
Goodnight Moon
title
book
title
price
One Fish Two Fish
$12.50
book
title price
Cat in the Hat
$14.95
bookinfo

Standard Approach - XQuery
• XQuery is powerful, but ……
The user may NOT KNOW the structure of bib.xml!

Solution 1 – Study Schema
• Ask the user to study the structure of bib.xml and write a query in XQuery

Solution 1 – Study Schema
More problems• Data evolution: The document structure may change
over time• Heterogeneity: multiple XML documents with similar
content but different structures• Plain unrealistic from an usability point of view

Solution 2 – Keyword Search
• Keyword Search – IR approach- Discard all tags:
“Mary”
- Treat tags as keywords:
“book article year title author Mary”

Query: What are the titles and years of the publications, of which Mary is an author?
===> “year title author Mary”
Solution 2 – Keyword Search
bibliography(1)
bib(2)bib(11)
year(3)year(12)
book (4)article(7)
title(5) author(6)
title(8)
author(10)
book(13)article(16)
title(14)
author(15)title(17)
author(18)19992000
XMLBob
HTMLMary
DatabaseCodd
C++John
Joe
author(9)

Solution 2 – Keyword Search
Pro
-Required no knowledge of document structure
Con -Does not take advantage of the structure
-Cannot express complex query semantic

Our Approach
• Taking advantage of whatever partial knowledge user may have on document schema
• Support wide range of queries – from regular XQuery to keyword
search• Minimum effort required for the user
–Natural language query is desirable

Basic Ideas
• Map parsed natural language query into XQuery.
– Proximity in natural language parse tree should correspond to proximity in matched XML tree
• XML is human readable and is human created!
• Interactive query formulation to help users pose system-understandable queries.

What are the Challenges?
Challenge 1:
Automatically understand user intent of an arbitrary natural language question.
Challenge 2:
How to map user intent to XML schema?- Should I use “author” or “writer”?
- Is “Gone with the wind” a book or a movie?
- Are books grouped by year or by author in the bibliography?

Our focus is on the second challenge
User Intent => XML Schema
• Match users’ limited schema knowledge with the actual document schema.– Schema-Free Xquery
• Meaningful query focus

Meaningful Query Focus
• Without knowing the document structure, the user can still specify WHICH nodes should be meaningfully related
• The Meaningful Query Focus (MQF) is the most specific XML structure in which the nodes are related.
authortitle
Mary
year authortitle
Mary
year
MQF (year, title, author)

Intuition
- A node in a XML document usually represent a real-world entity
book art icle
t it le author
J oe
t it le
year
author
Bob
bib
1999
XML HTML
(2)
(3)
(9)(8)
(7)
(6)(5)
(4)
author(10)
Mary
- Two nodes are related to each other by their lowest common ancestor
article is one of the most specific entities that contain entity title and author

Intuition
The entity represented by a lowest common ancestor node may not be the most specific type of entity that contains the types of entities each of the nodes represents
NOT all lowest common ancestors are meaningful !
book art icle
t it le author
J oe
t it le
year
author
Bob
bib
1999
X ML X ML
(2)
(3)
(9)(8)
(7)
(6)(5)
(4)
author(10)
Mary

Meaningful Lowest Common Ancestor
Given the sets of nodes with tag name title, year and author
bibliography(1)
bibbib
yearyear
bookarticle
title author
title
author
book article
titleauthor
titleauthor1999
2000
XMLBob
HTMLMary
DatabaseCodd
C++John
Joe
author
(4)
(5) (6)
(8)
(7)
(9)
(10)
(3)
(14)(15)
(13) (16)
(17)(18)
(2)
(12)
(11)
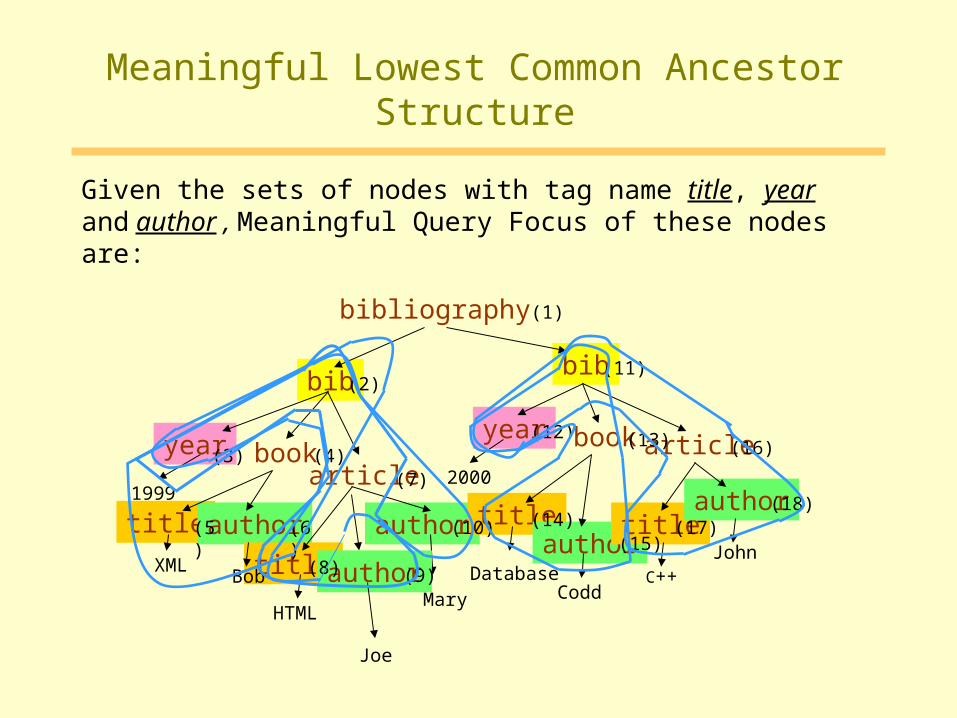
Meaningful Lowest Common Ancestor Structure
Given the sets of nodes with tag name title, year and author , Meaningful Query Focus of these nodes are:
bibliography(1)
bibbib
yearyear
bookarticle
title author
title
author
book article
titleauthor
titleauthor1999
2000
XMLBob
HTMLMary
DatabaseCodd
C++John
Joe
author
(4)
(5) (6)
(8)
(7)
(9)
(10)
(3)
(14)(15)
(13) (16)
(17)(18)
(2)
(12)
(11)

Vocabulary Problem
• Users may not know the exact tag names• Solution: term expansion
– WordNet® • English nouns, verbs, adjectives and
adverbs are organized into synonym sets, each representing one underlying lexical concept.
– Ontology mapping• Domain knowledge

for $b in MQF doc(“bib.xml”)//expand(writer) $c in MQF doc(“bib.xml”)//title $d in MQF doc(“bib.xml”)//yearwhere $b = “Mary” return $c, $d
Term expansion
User may not know the exact tag names
term expansion
for $b in doc(“bib.xml”)//author $c in doc(“bib.xml”)//title $d in doc(“bib.xml”)//yearwhere mlca($b, $c, $d) and $b = “Mary” return $c, $d

Query Translation Process
English Sentence Classified Parse Tree Schema-Free XQuery Dependency Parse Tree
List (V)
title (N)
published (A)
by (Prep)
Addison-Wesley (N)
the (Det)
book (N)
of (Prep)
List (CMT)
title (NT)
published by (CM)
publisher(NT)
Addison-Wesley (VT)
the (MM)
book (NT)
of (CM) for $m0 in timber-mlca($v0, document("sdblp.xml")//title,
$v1, document("sdblp.xml")//book,
$v2, document("sdblp.xml")//publisher)
where $v2 = "Addison-Wesley"
return <result>{$v0}</result>
List the titles of all the books published by Addison-Wesley .

System Architecture
XMLDBMS
Classifier Validator Translator
user
GUI
Dependency Parser
NLQ NLQ Classified Parse tree
Valid Parse tree
NLQParsetree
Query Repository
Command
History & Template
Message Generator
Errors
Warnings
Feedbacks
Results
Feedbacks
Results
Command
History&Template

Implementation● NaLIX itself is a Java application
● Web version is under development● Contains off-the-shelf components
● Natural Language Parser: MiniPar● XML Database: Timber● Thesaurus: WordNet● Ontology: manually constructed
• Under development:– User interactive domain ontology construction– Machine learning of domain ontology

Interactive Query Formulation
Invalid Query: List all the books with the same author as an author of “Advanced Programming in the Unix Environment”
FeedbackMessage
Suggestions
ExampleUsage

Experiment
• NaLIX vs. Keywords search
• Subjects: 18 UAlbany students
- No training on NaLIX was offered
• Tasks: 12 standard XMP use cases
Dataset: subset of DBLP
- All the books and SIGMOD conference articles by year 2003.

Ease of Use
Number of query reformulation
Time to formulate an acceptable query

Search Quality
Precision
Recall

Conclusions
• Taking advantage of inherent structure of XML, precise and powerful queries with natural language can be achieved
• Using NaLIX, naive user can effectively search unfamiliar XML data with ease and precision
• Iterative query reformulation can be an effective search strategy.


















