43
Natural Language Processing Lecture 8—2/5/2015 Susan W. Brown
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | charles-montgomery |
| View: | 215 times |
| Download: | 1 times |

Natural Language Processing
Lecture 8—2/5/2015Susan W. Brown

04/19/23 Speech and Language Processing - Jurafsky and Martin 2
Today
Part of speech tagging HMMs
Basic HMM model Decoding
Viterbi
Review chapters 1-4

04/19/23 Speech and Language Processing - Jurafsky and Martin 3
POS Tagging as Sequence Classification
We are given a sentence (an “observation” or “sequence of observations”) Secretariat is expected to race tomorrow
What is the best sequence of tags that corresponds to this sequence of observations?
Probabilistic view Consider all possible sequences of tags Out of this universe of sequences, choose the
tag sequence which is most probable given the observation sequence of n words w1…wn.

04/19/23 Speech and Language Processing - Jurafsky and Martin 4
Getting to HMMs
We want, out of all sequences of n tags t1…tn the single tag sequence such that
P(t1…tn|w1…wn) is highest.
Hat ^ means “our estimate of the best one” Argmaxx f(x) means “the x such that f(x) is
maximized”

04/19/23 Speech and Language Processing - Jurafsky and Martin 5
Getting to HMMs
This equation should give us the best tag sequence
But how to make it operational? How to compute this value?
Intuition of Bayesian inference: Use Bayes rule to transform this equation
into a set of probabilities that are easier to compute (and give the right answer)

Bayesian inference
Update the probability of a hypothesis as you get evidence
Rationale: two components How well does the evidence match the
hypothesis? How probable is the hypothesis a priori?
04/19/23 Speech and Language Processing - Jurafsky and Martin 6

04/19/23 Speech and Language Processing - Jurafsky and Martin 7
Using Bayes Rule

04/19/23 Speech and Language Processing - Jurafsky and Martin 8
Likelihood and Prior

04/19/23 Speech and Language Processing - Jurafsky and Martin 9
Two Kinds of Probabilities
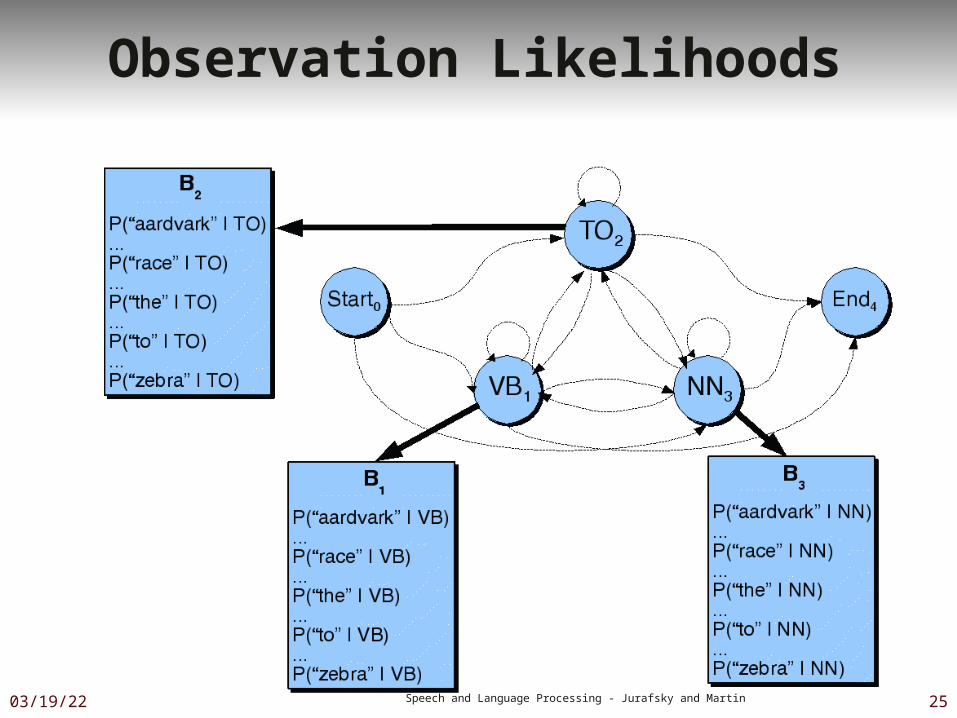
Tag transition probabilities p(ti|ti-1) Determiners likely to precede adjs and
nouns That/DT flight/NN The/DT yellow/JJ hat/NN So we expect P(NN|DT) and P(JJ|DT) to be high
Compute P(NN|DT) by counting in a labeled corpus:

04/19/23 Speech and Language Processing - Jurafsky and Martin 10
Two Kinds of Probabilities
Word likelihood probabilities p(wi|ti) VBZ (3sg Pres Verb) likely to be “is” Compute P(is|VBZ) by counting in a
labeled corpus:

04/19/23 Speech and Language Processing - Jurafsky and Martin 11
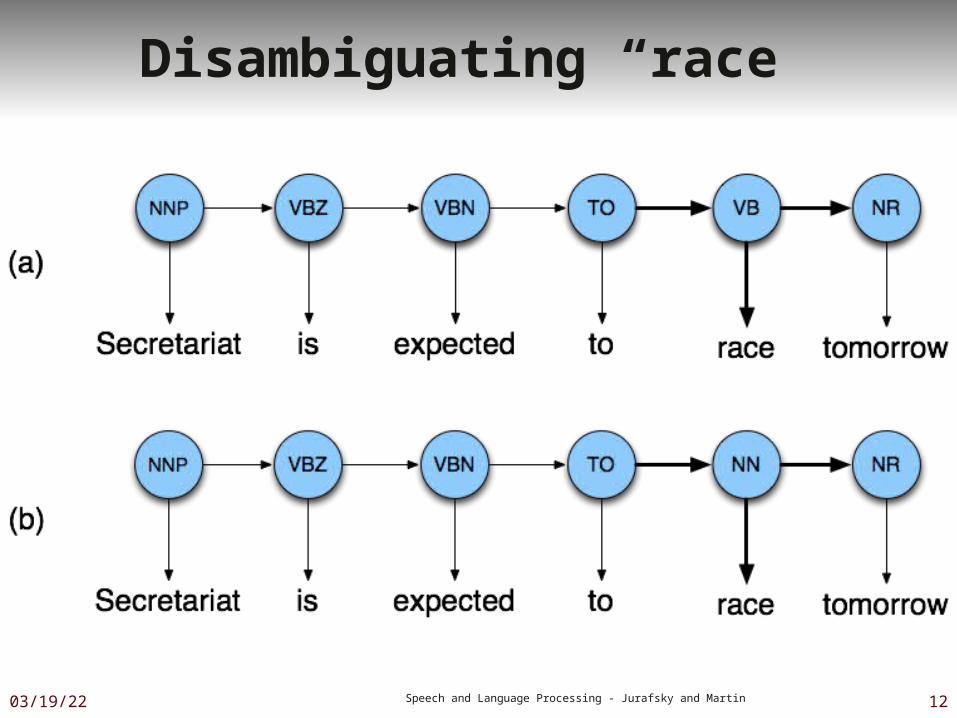
Example: The Verb “race”
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NR
People/NNS continue/VB to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
How do we pick the right tag?
04/19/23 Speech and Language Processing - Jurafsky and Martin 12
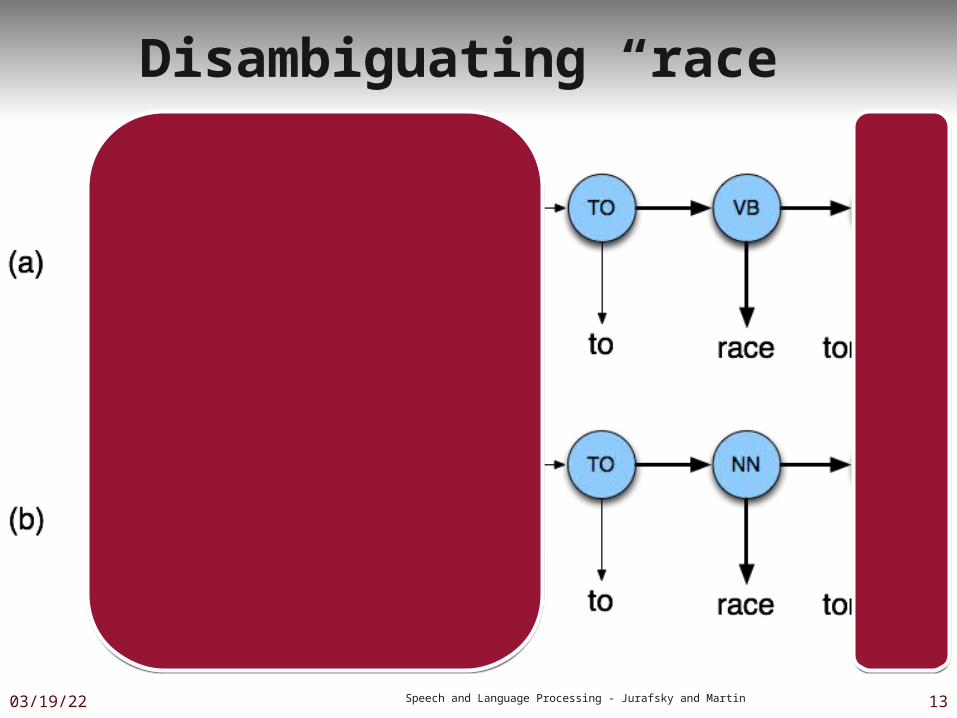
Disambiguating “race”
04/19/23 Speech and Language Processing - Jurafsky and Martin 13
Disambiguating “race”

04/19/23 Speech and Language Processing - Jurafsky and Martin 14
Example
P(NN|TO) = .00047 P(VB|TO) = .83 P(race|NN) = .00057 P(race|VB) = .00012 P(NR|VB) = .0027 P(NR|NN) = .0012
P(VB|TO)P(NR|VB)P(race|VB) = .00000027 P(NN|TO)P(NR|NN)P(race|NN)=.00000000032
So we (correctly) choose the verb tag for “race”

Question
If there are 30 or so tags in the Penn set And the average sentence is around 20
words... How many tag sequences do we have
to enumerate to argmax over in the worst case scenario?
04/19/23 Speech and Language Processing - Jurafsky and Martin 15
30203020

Hidden Markov Models
Remember FSAs? HMMs are a special kind that use
probabilities with the transitions Minimum edit distance?
Viterbi and Forward algorithms Dynamic programming?
Efficient means of finding most likely path
04/19/23 Speech and Language Processing - Jurafsky and Martin 16

04/19/23 Speech and Language Processing - Jurafsky and Martin 17
Hidden Markov Models
We can represent our race tagging example as an HMM.
This is a kind of generative model. There is a hidden underlying generator
of observable events The hidden generator can be modeled
as a network of states and transitions We want to infer the underlying state
sequence given the observed event sequence

04/19/23 Speech and Language Processing - Jurafsky and Martin 18
States Q = q1, q2…qN; Observations O= o1, o2…oN;
Each observation is a symbol from a vocabulary V = {v1,v2,…vV}
Transition probabilities Transition probability matrix A = {aij}
Observation likelihoods Vectors of probabilities associated with the states
Special initial probability vector
Hidden Markov Models

04/19/23 Speech and Language Processing - Jurafsky and Martin 19
HMMs for Ice Cream
You are a climatologist in the year 2799 studying global warming
You can’t find any records of the weather in Baltimore for summer of 2007
But you find Jason Eisner’s diary which lists how many ice-creams Jason ate every day that summer
Your job: figure out how hot it was each day

04/19/23 Speech and Language Processing - Jurafsky and Martin 20
Eisner Task
Given Ice Cream Observation Sequence:
1,2,3,2,2,2,3… Produce:
Hidden Weather Sequence: H,C,H,H,H,C, C…

04/19/23 Speech and Language Processing - Jurafsky and Martin 21
HMM for Ice Cream

Ice Cream HMM Let’s just do 131 as the sequence
How many underlying state (hot/cold) sequences are there?
How do you pick the right one?
04/19/23 Speech and Language Processing - Jurafsky and Martin 22
HHHHHCHCHHCCCCCCCHCHCCHH
HHHHHCHCHHCCCCCCCHCHCCHH
Argmax P(sequence | 1 3 1)Argmax P(sequence | 1 3 1)

Ice Cream HMM
Let’s just do 1 sequence: CHC
04/19/23 Speech and Language Processing - Jurafsky and Martin 23
Cold as the initial stateP(Cold|Start)Cold as the initial stateP(Cold|Start)
Observing a 1 on a cold dayP(1 | Cold)Observing a 1 on a cold dayP(1 | Cold)
Hot as the next stateP(Hot | Cold)Hot as the next stateP(Hot | Cold)
Observing a 3 on a hot dayP(3 | Hot)Observing a 3 on a hot dayP(3 | Hot)
Cold as the next stateP(Cold|Hot)Cold as the next stateP(Cold|Hot)
Observing a 1 on a cold dayP(1 | Cold)Observing a 1 on a cold dayP(1 | Cold)
.2
.5
.4
.4
.3
.5
.2
.5
.4
.4
.3
.5.0024.0024

04/19/23 Speech and Language Processing - Jurafsky and Martin 24
POS Transition Probabilities
04/19/23 Speech and Language Processing - Jurafsky and Martin 25
Observation Likelihoods

04/19/23 Speech and Language Processing - Jurafsky and Martin 26
Decoding
Ok, now we have a complete model that can give us what we need. Recall that we need to get
We could just enumerate all paths given the input and use the model to assign probabilities to each. Not a good idea. Luckily dynamic programming (last seen in Ch. 3 with
minimum edit distance) helps us here

04/19/23 Speech and Language Processing - Jurafsky and Martin 27
Intuition
Consider a state sequence (tag sequence) that ends at state j with a particular tag T.
The probability of that tag sequence can be broken into two parts The probability of the BEST tag sequence
up through j-1 Multiplied by the transition probability from
the tag at the end of the j-1 sequence to T. And the observation probability of the word
given tag T.

04/19/23 Speech and Language Processing - Jurafsky and Martin 28
The Viterbi Algorithm

04/19/23 Speech and Language Processing - Jurafsky and Martin 29
Viterbi Summary
Create an array With columns corresponding to inputs Rows corresponding to possible states
Sweep through the array in one pass filling the columns left to right using our transition probs and observations probs
Dynamic programming key is that we need only store the MAX prob path to each cell, (not all paths).

04/19/23 Speech and Language Processing - Jurafsky and Martin 30
Evaluation
So once you have you POS tagger running how do you evaluate it? Overall error rate with respect to a gold-
standard test set With respect to a baseline Error rates on particular tags Error rates on particular words Tag confusions...

04/19/23 Speech and Language Processing - Jurafsky and Martin 31
Error Analysis
Look at a confusion matrix
See what errors are causing problems Noun (NN) vs ProperNoun (NNP) vs Adj (JJ) Preterite (VBD) vs Participle (VBN) vs Adjective (JJ)

04/19/23 Speech and Language Processing - Jurafsky and Martin 32
Evaluation
The result is compared with a manually coded “Gold Standard” Typically accuracy reaches 96-97% This may be compared with result for a
baseline tagger (one that uses no context).
Important: 100% is impossible even for human annotators.
Issues with manually coded gold standards

04/19/23 Speech and Language Processing - Jurafsky and Martin 33
Summary
Parts of speech Tagsets Part of speech tagging HMM Tagging
Markov Chains Hidden Markov Models
Viterbi decoding

04/19/23 Speech and Language Processing - Jurafsky and Martin 34
Review
Exam readings Chapters 1 to 6
Chapter 2 Chapter 3
Skip 3.4.1, 3.10, 3.12
Chapter 4 Skip 4.7, 4.8-4.11
Chapter 5 Skip 5.5.4, 5.6, 5.8-5.10

04/19/23 Speech and Language Processing - Jurafsky and Martin 35
3 Formalisms
Regular expressions describe languages (sets of strings)
Turns out that there are 3 formalisms for capturing such languages, each with their own motivation and history Regular expressions
Compact textual strings Perfect for specifying patterns in programs or command-
lines
Finite state automata Graphs
Regular grammars Rules

Regular expressions
Anchor expressions ^, $, \b
Counters *, +, ?
Single character expressions ., [ ], [ - ]
Grouping for precedence ( ) [dog]* vs. (dog)*
No need to memorize shortcuts \d, \s
04/19/23 Speech and Language Processing - Jurafsky and Martin 36

FSAs
Components of an FSA Know how to read one and draw one Deterministic vs. non-deterministic
How is success/failure different? Relative power
Recognition vs. generation How do we implement FSAs for
recognition?
04/19/23 Speech and Language Processing - Jurafsky and Martin 37

04/19/23 Speech and Language Processing - Jurafsky and Martin 38
More Formally
You can specify an FSA by enumerating the following things. The set of states: Q A finite alphabet: Σ A start state A set of accept states A transition function that maps QxΣ to Q

FSTs
Components of an FST Inputs and outputs Relations
04/19/23 Speech and Language Processing - Jurafsky and Martin 39

Morphology
What is a morpheme? Stems and affixes Inflectional vs. derivational
Fuzzy -> fuzziness Fuzzy -> fuzzier
Application of derivation rules N -> V with –ize System, chair
Regular vs. irregular
04/19/23 Speech and Language Processing - Jurafsky and Martin 40

04/19/23 Speech and Language Processing - Jurafsky and Martin 41
Derivational Rules

04/19/23 Speech and Language Processing - Jurafsky and Martin 42
Lexicons
So the big picture is to store a lexicon (list of words you care about) as an FSA. The base lexicon is embedded in larger automata that captures the inflectional and derivational morphology of the language.
So what? Well, the simplest thing you can do with such an FSA is spell checking If the machine rejects, the word isn’t in the
language Without listing every form of every word

04/19/23 Speech and Language Processing - Jurafsky and Martin 43
Next Time
Three tasks for HMMs Decoding
Viterbi algorithm
Assigning probabilities to inputs Forward algorithm
Finding parameters for a model EM

















