36
Near Real Time Streaming With Apache Samza Antispam Use Case
| Date post: | 15-Apr-2017 |
| Category: |
Software |
| Upload: | michael-sklyar |
| View: | 342 times |
| Download: | 2 times |

Near Real Time Streaming With Apache
SamzaAntispam Use Case

Hello!Michael Sklyar
Team leader, R&D @ Cyren

Cyren

CYREN Customers

Business Case Antispam
https://www.youtube.com/watch?v=M_eYSuPKP3Y

Remember 2002?
VS 2010

Spam is businessMost of the email traffic is spam Spamvertising
Malware
Fraud, 419
Cryptolocker
Phishing

CYREN Antispam
SDKs and SAAS
Inbound and Outbound
Global View
24/7
RPD
Reputation

Antispam Main Challenge
FPs FNs
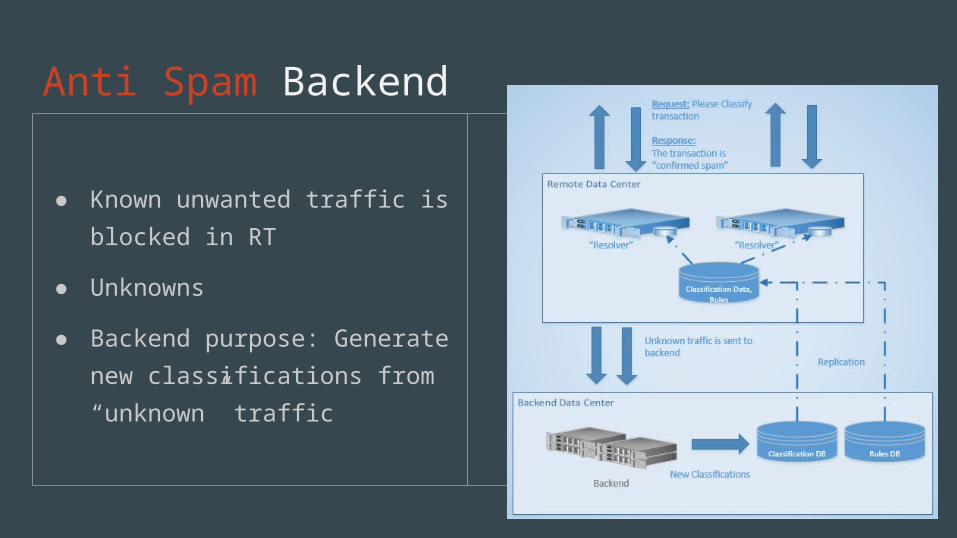
Anti Spam Backend
● Known unwanted traffic is blocked in RT
● Unknowns● Backend purpose: Generate
new classifications from “unknown” traffic

Sample classification logic: Bulk new domains
If it smells like spam...
●A link to a domain is seen in a big amount of emails
●Recently registered
●Doesn’t have a good (Cyren) reputation
●Passes defending mechanisms

Bulk New Domains Logic Challenges
●Process Billions of transactions per day
●Count the appearance of domains in “Windows”
●External Services
● DO IT FAST

Before we dig in...Questions about the use case?

Replacing the backendBulk new domain abstraction
Parse Enrich Count ClassifyRawTransactions
Unknown traffic
DCsReplication

Replacing the backend Technological stack

Apache Samza Stream Processing Framework
YARN KAFKA
Samza API
Layers:
1. Streaming: Kafka
2. Execution: YARN
3. Processing: Samza API
Originally By Linkedin
The Obvious:
DistributedHigh availabilityHorizontally scalable

Apache Kafka Streaming
● Topics
● Partitions
● Offsets
● Producers
● Consumers
Distributed, partitioned, replicated publish-subscribe messaging system
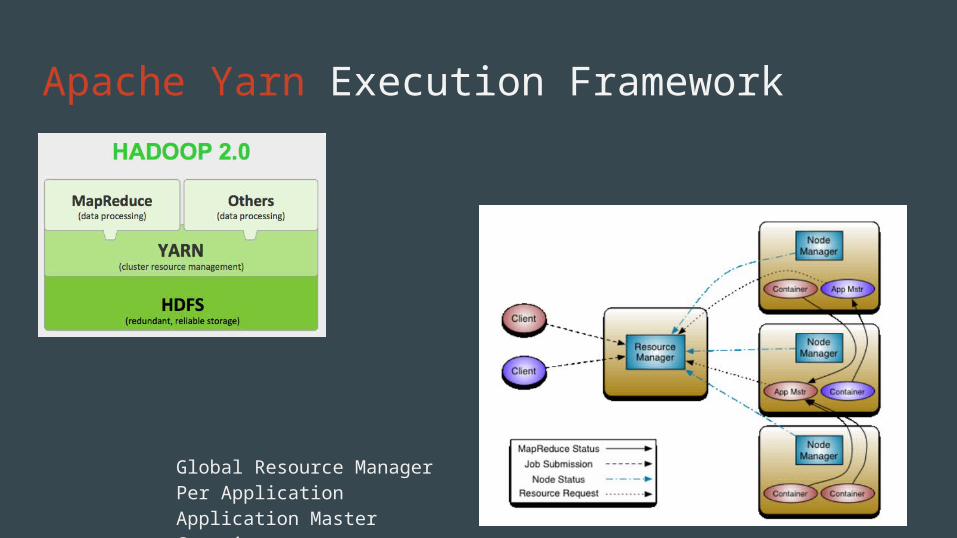
Apache Yarn Execution Framework
Global Resource ManagerPer Application Application MasterContainers
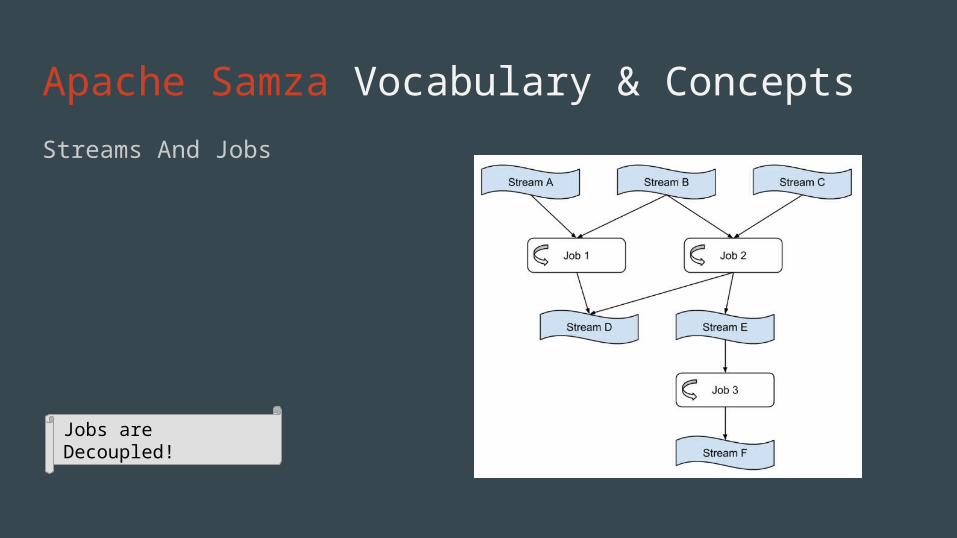
Apache Samza Vocabulary & ConceptsStreams And Jobs
Jobs are Decoupled!

Apache Samza Vocabulary & ConceptsPartitions and Tasks
Partition 1 Partition 2 Partition 2
Task 1 Task 2 Task 3
Partition 1 Partition 2
Incoming Stream (Kafka Topic)
Samza Job
Outgoing Stream
Tasks are single-threaded
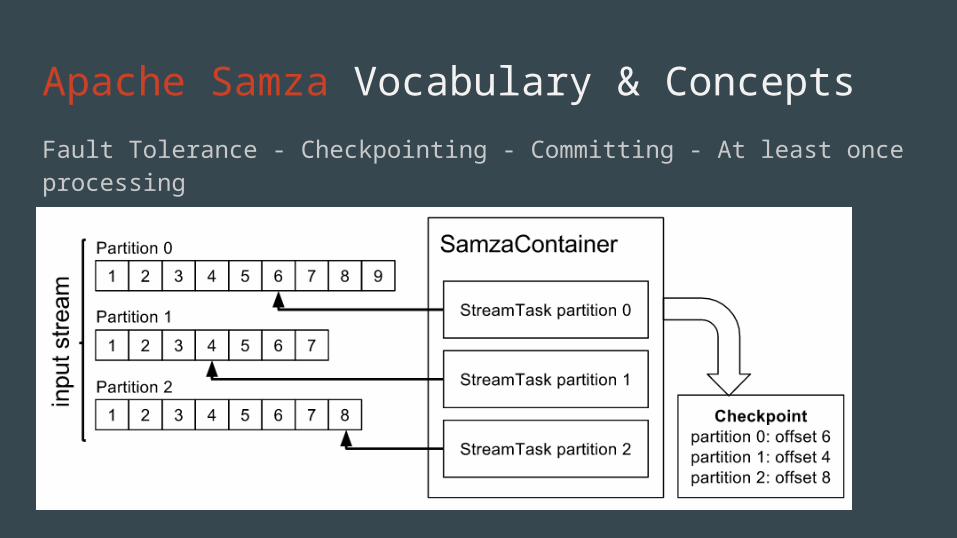
Apache Samza Vocabulary & ConceptsFault Tolerance - Checkpointing - Committing - At least once processing
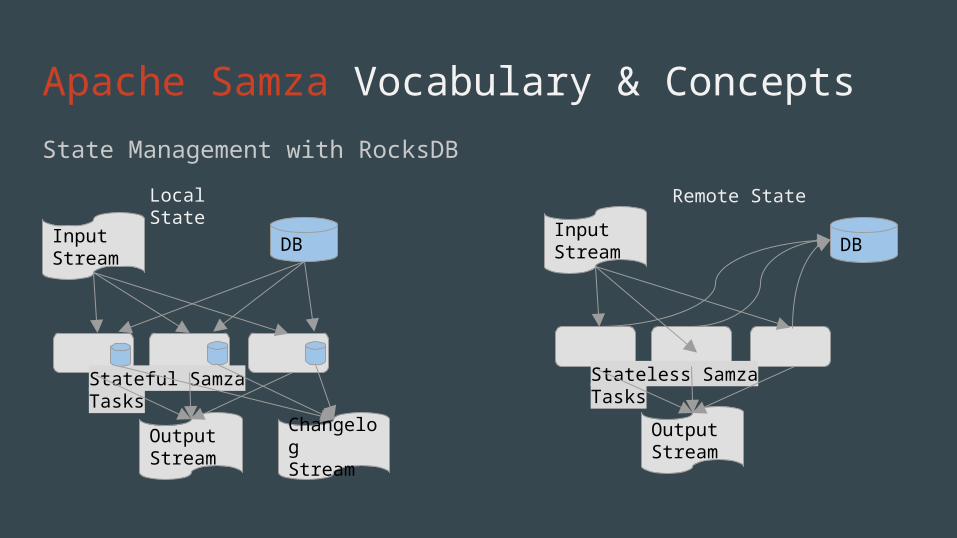
Apache Samza Vocabulary & ConceptsState Management with RocksDB
Local State Remote State
InputStream DB
Stateless Samza Tasks
OutputStream
InputStream
Stateful Samza Tasks
OutputStream
DB
ChangelogStream

Apache Samza APIpublic class SplitStringIntoWordsTask implements StreamTask {
// Send outgoing messages to a stream called "words" in the "kafka" system. private final SystemStream OUTPUT_STREAM = new SystemStream("kafka", "words");
public void process(IncomingMessageEnvelope envelope, MessageCollector collector, TaskCoordinator coordinator) { String message = (String) envelope.getMessage();
for (String word : message.split(" ")) { // Use the word as the key, and 1 as the value.
// A second task can add the 1's to get the word count. collector.send(new OutgoingMessageEnvelope(OUTPUT_STREAM, word, 1)); } }}

Apache Samza API/** Implement this if you want a callback when your task
starts up. */public interface InitableTask {
void init(Config config, TaskContext context);
}
public interface WindowableTask {
void window(MessageCollector collector, TaskCoordinator
coordinator) throws Exception;
}
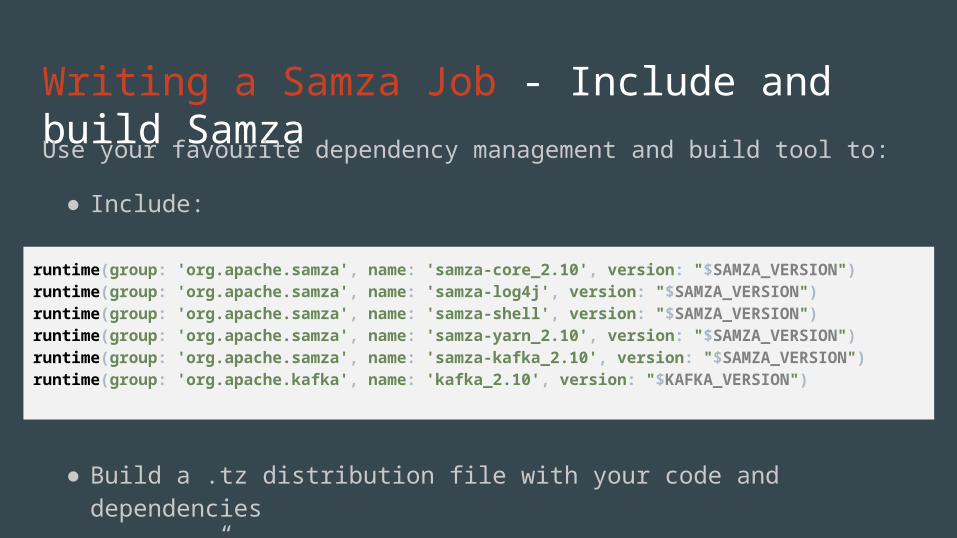
Writing a Samza Job - Include and build SamzaUse your favourite dependency management and build tool to:
●Include:
●Build a .tz distribution file with your code and dependencies
●“Extract” the samza-shell library (it will contain Samza shell scripts)
runtime(group: 'org.apache.samza', name: 'samza-core_2.10', version: "$SAMZA_VERSION")runtime(group: 'org.apache.samza', name: 'samza-log4j', version: "$SAMZA_VERSION")runtime(group: 'org.apache.samza', name: 'samza-shell', version: "$SAMZA_VERSION")runtime(group: 'org.apache.samza', name: 'samza-yarn_2.10', version: "$SAMZA_VERSION")runtime(group: 'org.apache.samza', name: 'samza-kafka_2.10', version: "$SAMZA_VERSION")runtime(group: 'org.apache.kafka', name: 'kafka_2.10', version: "$KAFKA_VERSION")

Writing a Samza Job - The codepublic class SplitStringIntoWordsTask implements StreamTask {
// Send outgoing messages to a stream called "words" in the "kafka" system. private final SystemStream OUTPUT_STREAM = new SystemStream("kafka", "words");
public void process(IncomingMessageEnvelope envelope, MessageCollector collector, TaskCoordinator coordinator) { String message = (String) envelope.getMessage();
for (String word : message.split(" ")) { // Use the word as the key, and 1 as the value.
// A second task can add the 1's to get the word count. collector.send(new OutgoingMessageEnvelope(OUTPUT_STREAM, word, 1)); } }}

Writing a Samza Job - Task PropertiesNasty and painful configuration specifying:
●Job properties: Name, artifact location, number of tasks, RAM, CPU
●Kafka Configuration: Systems and streams: incoming, outgoing, bootstrapping, coordination.
●SerDe definitions
https://samza.apache.org/learn/documentation/0.10/jobs/configuration-table.html
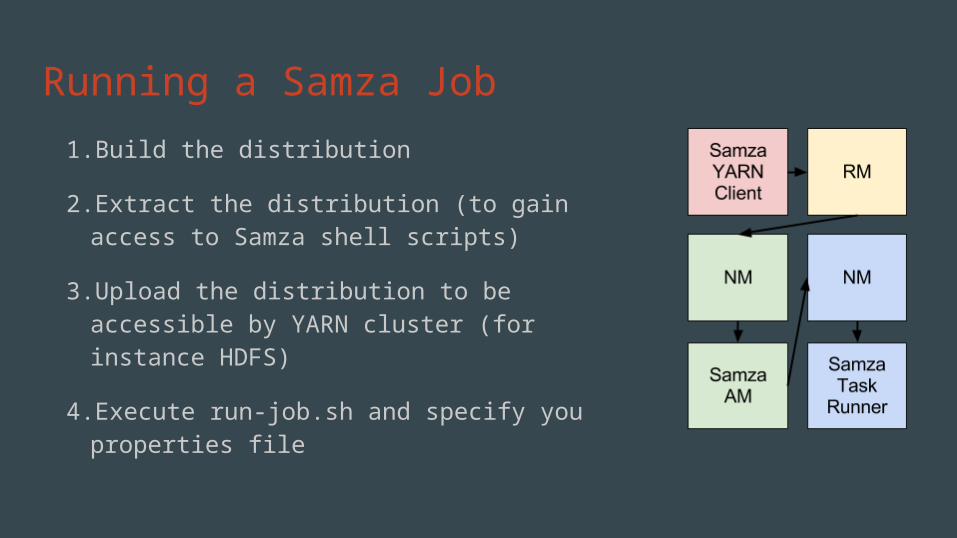
Running a Samza Job1.Build the distribution
2.Extract the distribution (to gain access to Samza shell scripts)
3.Upload the distribution to be accessible by YARN cluster (for instance HDFS)
4.Execute run-job.sh and specify you properties file

Bulk new domain detection with Samza
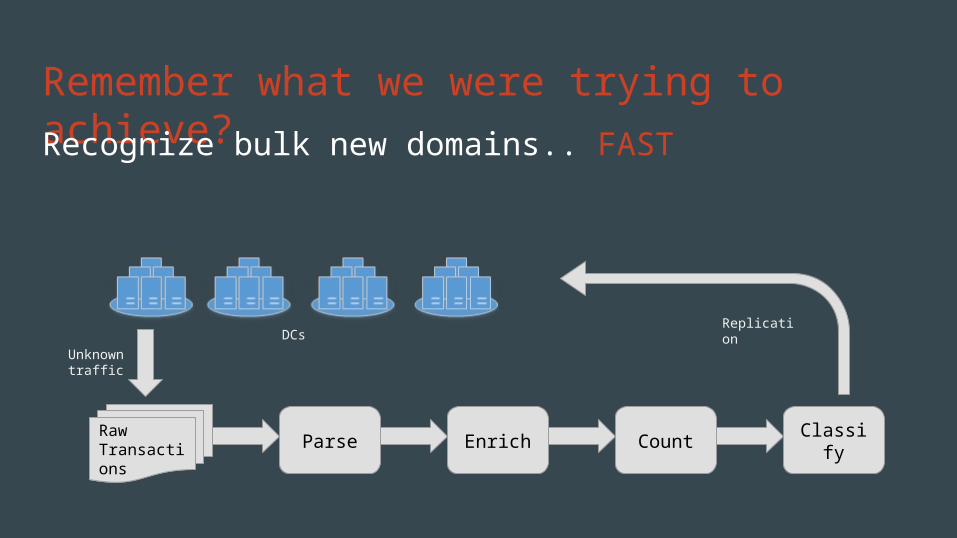
Remember what we were trying to achieve?Recognize bulk new domains.. FAST
Parse Enrich Count ClassifyRawTransactions
Unknown traffic
DCsReplication

Bulk new domain detection PerformanceWhat affects performance?
●Kafka and YARN cluster sizes
●Number of Kafka Partitions (Partition=>Samza Task)
●Number of Containers
●container
●Kafka: HDD IO
●Caching

MetricsSamza Metrics
Application Metrics - Codahale, Netflix servo
Time Series DB - Graphite/InfluxDB
UI - Grafana

Samza ImpressionsThe Good
StableVery easy to write jobsThread Safety is not an issueEasy to add branches to the job graphsHigh ThroughputLow LatencyReplayable streams

Samza Impressions
Could be better
Nasty PropertiesDoesn’t support partitions amount changeNot the most spoiling - no fancy UIsOnly supports at least once processing paradigmNot enough producersNot the most mature
If you don’t already have a YARN cluster…

Samza Getting StartedWriting the code is the easiest partSetting Kafka, Zookeeper,YARNBuilding - packing your code into an artifact, preparing it for extractionUnderstanding Properties
Good News
Hello-Samza
http://samza.apache.org/startup/hello-samza/0.10/

Thank You,
Questions?







![Data-Trace Types for Distributed Stream Processing Systemsmamouras/papers/Trace-Transductions.pdf · and Apache Samza [2] ... During compilation and deployment, this dataflow graph](https://static.documents.pub/doc/80x56/5aad5ccd7f8b9a2e088e1781/data-trace-types-for-distributed-stream-processing-mamouraspaperstrace-transductionspdfand.jpg)









