“Applicazione della conformal prediction alla network anomaly detection” Relatori: Aniello Castiglione Alfredo De Santis Ugo Fiore Francesco Palmieri Partecipanti: Giuseppe Luciano Alessandro Merola Emanuele Pesce Università degli Studi di Salerno Corso di sicurezza
Transcript
“Applicazione della conformal prediction alla network anomaly detection”
Relatori:Aniello CastiglioneAlfredo De SantisUgo FioreFrancesco Palmieri
Sia: una sequenza di esempi, dove è l'i-esimo esempio con
Avendo la sequenza di esempi osservata (x1,y1), (x2,y2), ..., (xn-1,yn-1) e xn, si vuole prevedere y fornendo una regione di predizione
Tale regione denota l’insieme di tutti i possibili valori che la predizione y può assumere, dove ogni valore è corretto con una probabilità di almeno 1 - .
Γε (z1, z2,. .., zn−1 , xn)
B={z1, z2, ... , zn−1}
z i=(x i , y i) 1⩽i⩽n−1
ε
Conformal predictionAlgoritmo generale
Conformal predictionAdattamento dell'algoritmo
all'anomaly detection● ConformalPrediction(A,B, xn, y) è la funzione
che data xn e y restituisce la probabilità che xn abbia quella label, cioè appartenga a quella classe.
● Le classi sono due:● Flusso normale;● Flusso anomalo.
● Una feature del flusso viene passata all'algoritmo prima con un label poi con un'altra.
● La label a cui viene associata la probabilità maggiore è quella di appartenenza della feature.
Conformal predictionAlgoritmo adattato
Dove py indica la probabilità che xn appartenga alla classe y
Outline● Network anomaly detectioni● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri
Dataset● Synflood01: dati artificiali creati con Zenmap (un port scanner). Cattura di pacchetti contenenti anomalie e dati normali.
● Mawi02*: dataset disponibile online.
*Measurement and Analysis on the WIDE Internet (MAWI) è una raccolta di dataset contenente traffico di dati.
Il Framework di analisi dei datiPre-processing
Analizzati dei pacchetti con BRO (un IDS) che ci ha restituito flussi dei dati.
● I flussi hanno queste feature:● Ip e porta di origine e destinazione
● Protocollo
● Byte spediti e ricevuti
● Durata servizio
● Stato connessione
● Altri...
Il Framework di analisi dei dati Feature selection
● Individuazione del sottoinsieme di feature più significative per la discriminazione
● Le feature selezionate: durata della connessione numero di byte ricevuti flag tcp/udp attivi numero di porta della connessione numero di pacchetti del flusso
Il Framework di analisi dei dati Addestramento supervisionato
● Suddivisione dei dataset:
● Traning set: 60%. Dati utilizzati per addestrare il modello discriminatorio.
● Test set: 40%. Dati utilizzati per valutare le prestazioni del modello addestrato.
Outline● Network anomaly detection● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri
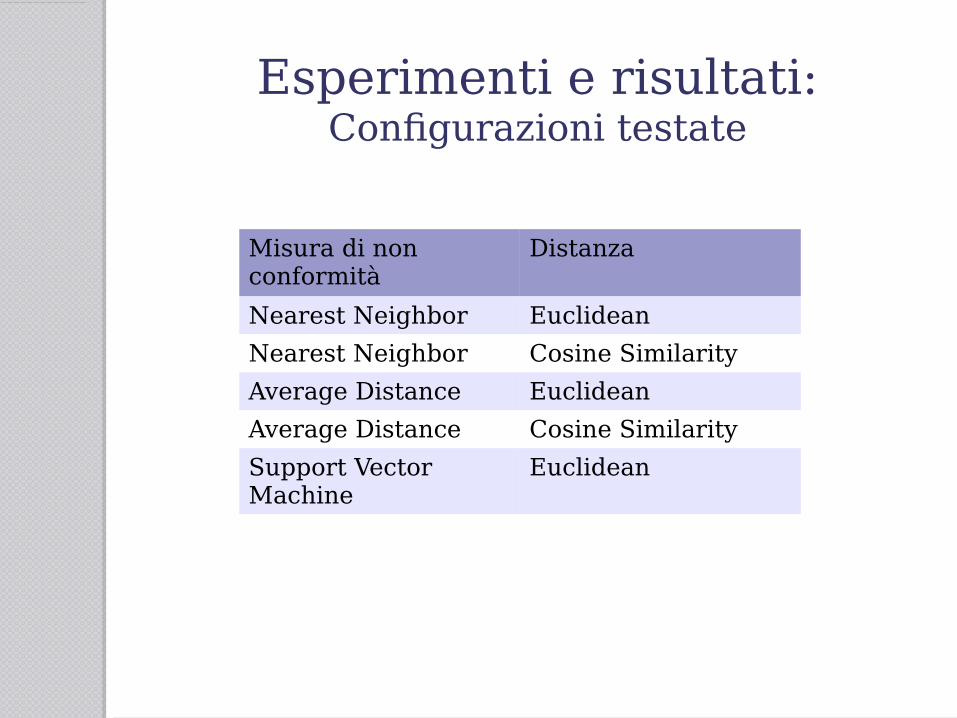
Esperimenti e risultati:Metodologia
● Prima fase: testing su dati artificiali Dataset Synflood01
Test set formato da 1513 flussi● Seconda fase: testing su dati reali
Dataset Mawi02 Test set formato da 4398 flussi
Valutazione performance in base ad indici prestazionali
Error rate: è la percentuale di misclassificazione
NN: nearest neighbours - AVG: average distance - SVM: support vector machine
Esperimenti e risultati:Risultati su Mawi02
● SVM ha dato il 4.43% di errore nel rilevamento:● 15 falso positivi ● 180 falso negativi
● Mentre ha dato:● 64 vero positivi● 4141 vero negativi
Per “positivo” si intende un flusso che è anomalo e “negativo” un flusso che non lo è.
Esperimenti e risultati:Cause degli errori
● SVMNatura dei dati, che non si presentano perfettamente separabili
● Average distancePoca robustezza della media, sulla quale questo criterio si basa. Anche un singolo outlier può influenzare di molto le prestazioni finali
● Nearest NeighborNon separabilità dei dati e poca omogeneità di dispersione.
Outline● Network anomaly detection● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri
Conclusioni
● L'algoritmo di conformal prediction si presta ad essere utilizzato nella network anomaly detection utilizzando SVM come classificatore, ma per ottenere risultati migliori si dovrebbero usare più features.
● Ranking performance misure di non conformità:
1)SVM
2)Nearest neighbor
3)Average distance
Sviluppi futuri
● Possibile variante dell'algoritmo:
Sliding window: usare solo il passato più recente al fine di migliorare i tempi computazionali