52
Network Biology day two Paolo Tieri, CNR, Italy Universidade Federal de Minas Gerais Belo Horizonte, Brazil

Network Biology day two
Paolo Tieri, CNR, Italy Universidade Federal de Minas Gerais
Belo Horizonte, Brazil

2 Tools and Resources
• Resources and soAware for network biology – VisualizaEon and analysis tools – Databases – Standards
2

• Tools for visualizaEon • Tools for analysis • Tools for both • Standalone • web-‐based • Plugins (R, matlab…) • Free and license purchase

Cytoscape
• Tomorrow!

CellDesigner • hQp://www.celldesigner.org/ • Structured diagram editor for drawing gene-‐regulatory and biochemical networks
• hQp://www.celldesigner.org/models.html model repository

yEd • hQp://www.yworks.com/en/products/yfiles/yed/
• Desktop applicaEon that can be used to quickly and effecEvely generate high-‐quality diagrams

Pajek
• hQp://pajek.imfm.si/doku.php?id=pajek • Pajek (Slovene word for Spider) is a program (Windows only) for analysis and visualizaEon of large networks
• Quite powerful, good for very large graphs (fast), not very used in biology

Biolayout 3D • hQp://www.biolayout.org/ • Designed for visualizaEon, clustering, exploraEon and analysis of very large network graphs in two-‐ and three-‐dimensional space derived primarily, but not exclusively, from biological data
• hQp://youtu.be/pzyDC16YK14

Circos • hQp://circos.ca/ • soAware package for visualizing data and informaEon. It visualizes data in a circular layout — this makes Circos ideal for exploring relaEonships between objects or posiEons
hQp://youtu.be/y08gvSvoHxg
If you are curious: hQp://youtu.be/M-‐rTAr3pj5g (54 mins)

Hive Plots • hQp://www.hiveplot.net/ • A scalable, computaEonally fast, and straight-‐forward network visualizaEon method that makes possible visual interpretaEon of network structure and evoluEon hQp://youtu.be/1cKG-‐VHIr8A

PINA Protein InteracEon Network Analysis
• hQp://cbg.garvan.unsw.edu.au/pina/ • integrated plajorm for protein interacEon network construcEon, filtering, analysis, visualizaEon and management

VisANT
• hQp://visant.bu.edu/ • IntegraEve network plajorm to connect genes, drugs, diseases and therapies

NeAT Network Analysis Tools
• hQp://rsat.ulb.ac.be/index_neat.html • Modular computer programs specifically designed for the analysis of biological network

Netwalker • hQps://netwalkersuite.org/ • desktop applicaEon for funcEonal analyses of large-‐scale genomics datasets within the context of molecular network

DAPPLE Disease AssociaEon Protein-‐Protein Link Evaluator
• hQps://www.broadinsEtute.org/mpg/dapple/dappleTMP.php
• DAPPLE looks for significant physical connec7vity among proteins encoded for by genes in loci associated to disease according to protein-‐protein interacEons reported in the literature
• The hypothesis behind DAPPLE is that causal geneEc variaEon affects a limited set of underlying mechanisms that are detectable by protein-‐protein interac7ons

IPA Ingenuity • hQp://www.ingenuity.com/products/ipa • Understanding of complex ‘omics data at mulEple levels by integraEng data from a variety of experimental plajorms and providing insight into the molecular and chemical interacEons, cellular phenotypes, and disease processes
• hQp://youtu.be/_HDkjuxYRcY

Gephi • hQps://gephi.github.io/
• Gephi is an interacEve visualizaEon and exploraEon plajorm for all kinds of networks and complex systems, dynamic and hierarchical graphs
• hQp://player.vimeo.com/video/9726202

Databases
• Different from online tools, but more and more are offering integrated analysis and visualizaEon tools

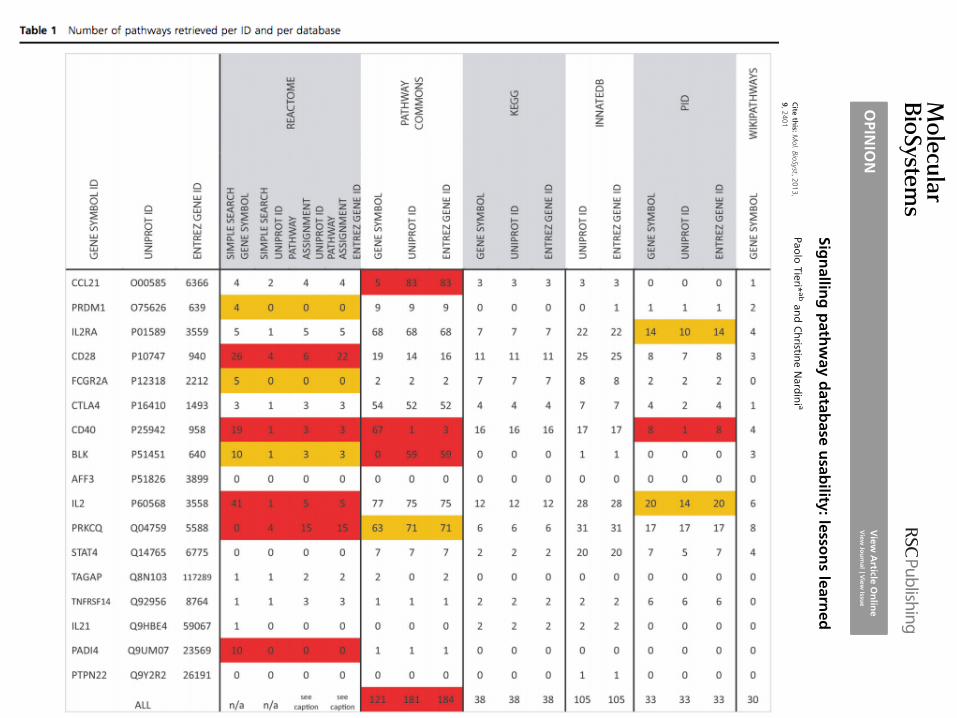
Warnings on DB usage
• Ambiguity about the logic behind the queries the user is allowed to formulate (query logic)
• inconsistency among the iden7fiers the user is allowed to adopt (Pathway nomenclature and iden7fiers)
• a database may simply be missing the relevant pathway
Thisjournalis
cThe
RoyalSocietyof
Chemistry
2013Mol.BioSyst.,2013,
9,2401--24072401
Cite
this:M
ol.BioSyst.,2013,9,2401
Sign
alling
path
way
datab
aseu
sability:lesso
ns
learned
PaoloTieri*
ab
andChristine
Nardini a
Background:issues
andlim
itationsrelated
toaccessibility,
understandabilityand
easeof
useof
signallingpathw
aydatabases
may
hamper
ordivert
researchw
orkflow,
leading,in
thew
orstcase,
tothe
generationof
confusingreference
framew
orksand
misinterpretation
ofexperim
entalresults.In
anattem
ptto
retrievesignalling
pathway
datarelated
toa
specificset
oftest
genes,w
equeried
andanalysed
theresults
fromsix
ofthe
major
curatedsignalling
pathway
databases:Reactom
e,Pathw
ay-Com
mons,K
EGG
,InnateDB,PID
,andW
ikipathways.Findings:although
we
expecteddiff
erences–
oftena
desirablefeature
forthe
integrationof
eachindividual
query,w
eobserved
variationsof
exceptionalm
agnitude,with
disproportionatequality
andquantity
ofthe
results.Some
ofthe
more
remarkable
dif-ferences
canbe
explainedby
thediverse
conceptualdesigns
andpurposes
ofthe
databases,the
typesof
datastored
andthe
structureof
thequery,
asw
ellas
bym
issingor
erroneousdescriptions
ofthe
searchprocedure.To
gobeyond
them
ereenum
erationof
theseproblem
s,w
eidentified
anum
berof
operationalfeatures,
inparticular
innerand
crosscoherence,
which,
oncequantified,
offerobjective
criteriato
choosethe
bestsource
ofinform
ation.Conclusions:insilico
biologyheavily
relieson
theinfor-
mation
storedin
databases.Toensure
thatcom
putationalbiology
mirrors
biologicalreality
andoffers
focusedhypotheses
tobe
experimentally
validated,coherence
ofdata
codificationis
crucialand
yethighly
underestimated.W
em
akepractical
recomm
endationsfor
theend-user
tocope
with
thecurrent
stateof
thedatabases
asw
ellas
forthe
maintainers
ofthose
databasesto
contributeto
thegoal
ofthe
fullenactment
ofthe
opendata
paradigm.
Backg
rou
nd
The
omic
revolution1
has
engen
dereda
num
berof
new
oppor-tun
itiesan
dch
allenges.
First,accessibility
todata
has
beengreatly
increased,
with
benefits
and
drawbacks
relatedto
dataavailability. 2
Second,
stemm
ing
fromaccessibility,
the
possibilityto
readsuch
datain
apractical
man
ner
isa
challen
ge.For
example,
standards
mustbe
defined
tosum
marise
the
largeam
ountofin
formation
contain
edin
the
omics
inth
eform
ofm
etadata.Th
esestan
-dards
areexpressed
as‘‘M
inim
alIn
formation
Standards’’
and
include
MIAM
E3
and
MIM
IX4
forexpression
dataan
dH
UPO
5
forprotein
s.Finally,data
organisation
iscrucialfor
re-usage,toallow
three
comm
onplace
tasksin
molecular
computation
albiology:(i)validate
novelresults,based
onexistin
gexperim
ents
(enh
ance
statisticalpow
er);(ii)
testan
dexplore
novel
dataan
alysesusin
gexistin
gexperim
ents
(enh
ance
the
biologicalbreadth
ofthe
findin
g);and
(iii)infer
additionalin
formation
by
integratin
gdiff
erent
sourcesof
data(see,
forexam
ple,th
eD
RYAD
initiative,
http://datadryad.org/).
Allof
these
tasksare
comm
only
performed
with
databases,w
hich
represent
the
most
directaccess
tobiological
data. 6
Data
integration
isth
em
ostrecen
tn
eedin
this
omic
revolutionan
dis
acrucial
stepfor
personalised
medicin
e.Patien
tsare
alsoa
complex
and
multifaceted
systemth
atm
ustbe
represented
bya
varietyof
heterogen
eousm
olecularsn
ap-sh
ots.In
deed,in
tegrationoccurs
atseveral
levels,in
cluding:
integrationof
homogeneous
studies,for
example,
transcriptionaldata
fromdiff
erentm
icroarrayplatform
sor
nextgeneration
sequencing(N
GS,
asan
example,
seeref.
7and
8);integration
ofheterogeneous
studies,for
example,
different
layersof
omics,
suchas
transcriptomic,
post-transcriptomic
andproteom
ic; 9–12
integrationand
reconstructionof
biologicalpathw
aysfrom
lowthroughput
experiments
13,14(see,
forexam
ple,the
definitionof
thepopular
KEG
Gdatabase
15);and,finally,overallintegrationof
theaforem
entionedstudies. 16
Indeed,
wh
ileth
efirst
two
typesof
integration
relyon
recently
defined
standards
(high
through
putdata
protocols),th
elatter
requirem
anual
curationof
previouslyexistin
gin
for-m
ation,
oftenstored
intextual
format,
and
only
recently
transformed
intosoft-m
odelsand
made
availablein
onlinerepos-
itoriesan
ddatabases. 17
Significan
teff
ortled
toth
ecreation
of
aKey
Laboratoryof
Com
putationalBiology,
CAS-M
PGPartner
Institutefor
Com
putationalBiology,
ShanghaiInstitutes
forBiological
Sciences,C
hineseAcadem
yof
Sciences,Yue
YangR
oad320,
Shanghai,P.
R.
China
bCN
R-IAC
Consiglio
Nazionale
delleR
icerche,Istitutoper
leApplicazioni
delC
alcolo,Viale
A.M
anzoni30,
Rom
a,Italy.
E-mail:
Received21st
June2013,
Accepted
23rdJuly
2013
DO
I:10.1039/c3mb70242a
ww
w.rsc.o
rg/m
olecu
larbio
systems
Molecu
larBio
Systems
OPIN
ION
Published on 24 July 2013. Downloaded by Federal University of Minas Gerais on 10/02/2015 16:24:38.
View
Article O
nlin
eV
iew Jo
urn
al | View
Issue
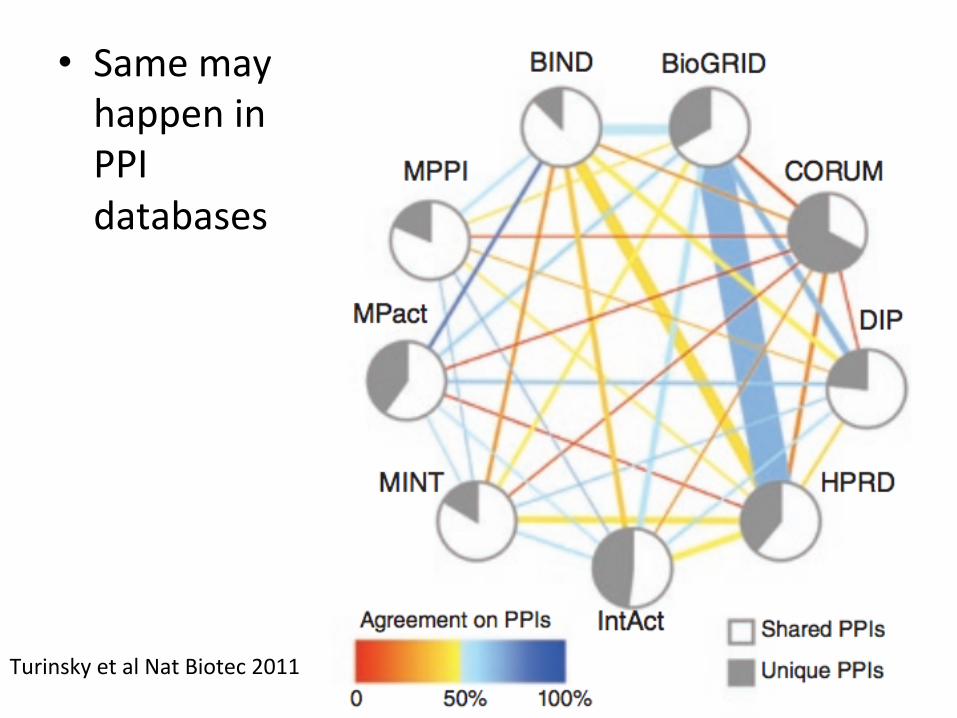
• Same may happen in PPI databases
Turinsky et al Nat Biotec 2011

• Despite the high quality of single curated databases, conflicEng informaEon sEll persists
• Database curators should devote the same aQenEon that they pay to the molecular informaEon stored in their database to the descripEon of the algorithms and hypotheses behind the search procedures
• USER! Always consciously scru7nize the informa7on available to perform a rigorous choice of resources

Pathguide
• hQp://pathguide.org/ • Pathguide contains informaEon about 547 biological pathway related resources and molecular interacEon related resources

UniProt Unified Protein Resource
• hQp://www.uniprot.org/ • comprehensive, high-‐quality and freely accessible resource of protein sequence and funcEonal informaEon
• hQp://youtu.be/ado1r8IDm3U

InnateDB
• hQp://www.innatedb.com/ • Publicly available database of the genes, proteins, experimentally-‐verified interacEons and signaling pathways involved in the innate immune response of humans, mice and bovines to microbial infecEon

KEGG
• hQp://www.genome.jp/kegg/ • KEGG is a database resource for understanding high-‐level funcEons and uEliEes of the biological system, such as the cell, the organism and the ecosystem, from molecular-‐level informaEon, especially large-‐scale molecular datasets generated by genome sequencing and other high-‐throughput experimental technologies

KEGG Pathway
• hQp://www.genome.jp/kegg/pathway.html • KEGG PATHWAY: mapping is the process to map molecular datasets, especially large-‐scale datasets in genomics, transcriptomics, proteomics, and metabolomics, to the KEGG pathway maps for biological interpretaion of higher-‐level systemic func7ons
• hQp://www.genome.jp/kegg/tool/map_pathway1.html

REACTOME
• hQp://www.reactome.org/ • Reactome is a free, open-‐source, curated and peer reviewed pathway database
• The goal is to provide intuiEve bioinformaEcs tools for the visualizaEon, interpretaEon and analysis of pathway knowledge to support basic research, genome analysis, modeling, systems biology and educaEon
• The current version (v51) of Reactome was released on December 8, 2014

PathwayCommons
• hQp://www.pathwaycommons.org/about/ • Pathway Commons is a network biology resource and acts as a convenient point of access to biological pathway informaEon collected from public pathway databases, which you can search, visualize and download
• All data is freely available, under the license terms of each contribuEng database

APID Agile Protein InteracEon DataAnalyzer
• hQp://bioinfow.dep.usal.es/apid/index.htm • interacEve bioinformaEc web-‐tool that has been developed to allow exploraEon and analysis of main currently known informaEon about protein-‐protein interacEons all known experimentally validated protein-‐protein interacEons (BIND, BioGRID, DIP, HPRD, IntAct and MINT)integrated and unified in a common and comparaEve plajorm. The analyEcal and integraEve effort done in APID provides an open access frame where are unified in a unique web applicaEon

iRefWeb
• hQp://wodaklab.org/iRefWeb/ • web interface to a broad landscape of data on protein-‐protein interacEons (PPI) consolidated from major public databases
• reliability of an interacEon using simple criteria, such as the number of supporEng publicaEons, the scale of the corresponding studies (high-‐ or low-‐throughput) or the detecEon methods used in the original experiments

DAVID Database for AnnotaEon, VisualizaEon and Integrated Discovery • hQp://david.abcc.ncifcrf.gov/ • comprehensive set of funcEonal annotaEon tools for invesEgators to understand biological meaning behind large list of genes

Enrichr
• hQp://amp.pharm.mssm.edu/Enrichr/ • integraEve web-‐based and mobile soAware applicaEon that includes new gene-‐set libraries, an alternaEve approach to rank enriched terms, and various interacEve visualizaEon approaches to display enrichment results

HGNC HuGO Gene Nomenclature CommiQee
• hQp://www.genenames.org/cgi-‐bin/symbol_checker
• the only worldwide authority that assigns standardised nomenclature to human genes

STRING
• hQp://string-‐db.org/ • database of known and predicted protein interacEons. The interacEons include direct (physical) and indirect (funcEonal) associaEons; they are derived from four sources:
• Genomic Context • High-‐throughput Experiments • (Conserved) Coexpression • Previous Knowledge

IntAct
• hQps://www.ebi.ac.uk/intact/ • freely available, open source database system and analysis tools for molecular interacEon data. All interacEons are derived from literature curaEon or direct user submissions and are freely available

MINT Molecular INTeracEon database
• hQp://mint.bio.uniroma2.it/mint/Welcome.do
• Database focused on experimentally verified protein-‐protein interacEons mined from the scienEfic literature by expert curators

BioGRID
• hQp://thebiogrid.org/ • online interacEon repository with data compiled through comprehensive curaEon efforts
• Data from 44,686 publicaEons for 812,935 raw protein and geneEc interacEons from major model organism species

GeneMANIA
• hQp://genemania.org/ • GeneMANIA finds other genes that are related to a set of input genes, using a very large set of funcEonal associaEon data. AssociaEon data include protein and geneEc interacEons, pathways, co-‐expression, co-‐localizaEon and protein domain similarity

BioModels
• hQps://www.ebi.ac.uk/biomodels-‐main/ • repository of computaEonal models of biological processes. Models described from literature are manually curated and enriched with cross-‐references

ArrayExpress
• hQps://www.ebi.ac.uk/arrayexpress/ • database of funcEonal genomics experiments that can be queried and the data downloaded
• Gene expression data from microarray and high throughput sequencing studies
• Experiments are submiQed directly to ArrayExpress or are imported from the NCBI GEO database.

IDconverter
• hQp://idconverter.iib.uam.es/

Standards
• Standard languages to enable integraEon, exchange, visualisaEon and analysis of biological pathways at the molecular and the cellular level
• Biological Pathway Exchange (BioPAX) • Systems Biology Markup Language (SBML) • Systems Biology Graphical NotaEon (SBGN) • Cell Markup Language (CellML) • PSI-‐MI • … • hQp://www.psidev.info/


Standards / Guidelines • MIMIx is a community guideline advising the user on how to fully describe a molecular interacEon experiment and which informaEon it is important to capture
• Molecule (unanmiguous descripEon) • experiment (to capture the aspects of an interacEon experiment which are necessary to classify and criEcally assess the results and their interpretaEon)
• interac7on, including both qualitaEve parameters and quanEEve parameters, for example dissociaEon constants. However, this data is oAen not available, and thus MIMIx only requires two elements for the descripEon of an interacEon, the list of molecules par1cipa1ng in the interacEon, characterised as above, and a quality assessment
• …

Standards / Data Formats
• The Proteomics Standards IniEaEve (PSI) aims to define community standards for data representa7on in proteomics to facilitate data comparison, exchange and verificaEon
• The PSI MI format is a data exchange format for molecular interacEons. It is not a proposed database structure
• hQp://psidev.sourceforge.net/molecular_interacEons//rel25/doc/

Standards / Controlled Vocabulary
• The Controlled Vocabularies (CVs) of the Proteomic Standard IniEaEve (PSI) provide a consensus annota7on system to standardize the meaning, syntax and formalism of terms used across proteomics, as required by the PSI Working Groups
• Each PSI working group develop the CVs required by the technology or data type it aims to standardize

• [Term] • id: MI:0001 • name: interacEon detecEon method • namespace: PSI-‐MI • def: "Method to determine the interacEon." [PMID:14755292] • subset: Drugable • subset: PSI-‐MI_slim • synonym: "interacEon detect" EXACT PSI-‐MI-‐short [] • relaEonship: part_of MI:0000 ! molecular interacEon
• [Term] • id: MI:0002 • name: parEcipant idenEficaEon method • namespace: PSI-‐MI • def: "Method to determine the molecules involved in the interacEon." [PMID:14755292] • subset: PSI-‐MI_slim • synonym: "parEcipant detecEon" EXACT PSI-‐MI-‐alternate [] • synonym: "parEcipant ident" EXACT PSI-‐MI-‐short [] • relaEonship: part_of MI:0000 ! molecular interacEon

BioPAX
• hQp://www.biopax.org/index.html • Biological Pathway Exchange (BioPAX) is a standard language to represent biological pathways at the molecular and cellular level and to facilitate the exchange of pathway data


• 3+6=9 • But so does 4+5 • So, explore ways to do things • Find yours • Respect others’ way • ;-‐) thank you all!


















