NetworkMultis.1 Review: Bus Connected SMPs (UMAs) Caches are used to reduce latency and to lower bus traffic Must provide hardware for cache coherence and process synchronization Bus traffic and bandwidth limits scalability (<~ 36 processors) Processor Processor Processor Cache Cache Cache Single Bus Memory I/O Processor Cache
Transcript
NetworkMultis.1
Review: Bus Connected SMPs (UMAs)
Caches are used to reduce latency and to lower bus traffic Must provide hardware for cache coherence and process
synchronization Bus traffic and bandwidth limits scalability (<~ 36
processors)
Processor Processor Processor
Cache Cache Cache
Single Bus
Memory I/O
Processor
Cache
NetworkMultis.2
Review: Multiprocessor Basics
# of Proc
Communication model
Message passing 8 to 2048
Shared address
NUMA 8 to 256
UMA 2 to 64
Physical connection
Network 8 to 256
Bus 2 to 36
Q1 – How do they share data?
Q2 – How do they coordinate?
Q3 – How scalable is the architecture? How many processors?
NetworkMultis.3
Network Connected Multiprocessors
Either a single address space (NUMA and ccNUMA) with implicit processor communication via loads and stores or multiple private memories with message passing communication with sends and receives
Interconnection network supports interprocessor communication
Processor Processor Processor
Cache Cache Cache
Interconnection Network (IN)
Memory Memory Memory
NetworkMultis.4
Summing 100,000 Numbers on 100 Processors
sum = 0;for (i = 0; i<1000; i = i + 1)sum = sum + Al[i]; /* sum local array subset
Start by distributing 1000 elements of vector A to each of the local memories and summing each subset in parallel
The processors then coordinate in adding together the sub sums (Pn is the number of processors, send(x,y) sends value y to processor x, and receive() receives a value)
half = 100;limit = 100;repeathalf = (half+1)/2; /*dividing line
if (Pn>= half && Pn<limit) send(Pn-half,sum); if (Pn<(limit/2)) sum = sum + receive(); limit = half;until (half == 1); /*final sum in P0’s sum
NetworkMultis.5
An Example with 10 Processors
P0 P1 P2 P3 P4 P5 P6 P7 P8 P9
sum sum sum sum sum sum sum sum sum sum
half = 10
NetworkMultis.7
Communication in Network Connected Multi’s
Implicit communication via loads and stores hardware designers have to provide coherent caches and
process synchronization primitive lower communication overhead harder to overlap computation with communication more efficient to use an address to remote data when demanded rather than to send for it in case it might be used (such a machine has distributed shared memory (DSM))
Explicit communication via sends and receives simplest solution for hardware designers higher communication overhead easier to overlap computation with communication easier for the programmer to optimize communication
NetworkMultis.8
Cache Coherency in NUMAs
For performance reasons we want to allow the shared data to be stored in caches
Once again have multiple copies of the same data with the same address in different processors
bus snooping won’t work, since there is no single bus on which all memory references are broadcast
Directory-base protocols keep a directory that is a repository for the state of every block in
main memory (which caches have copies, whether it is dirty, etc.) directory entries can be distributed (sharing status of a block
always in a single known location) to reduce contention directory controller sends explicit commands over the IN to each
processor that has a copy of the data
NetworkMultis.9
IN Performance Metrics Network cost
number of switches number of (bidirectional) links on a switch to connect to the
network (plus one link to connect to the processor) width in bits per link, length of link
Network bandwidth (NB) – represents the best case bandwidth of each link * number of links
Bisection bandwidth (BB) – represents the worst case divide the machine in two parts, each with half the nodes and
sum the bandwidth of the links that cross the dividing line
Other IN performance issues latency on an unloaded network to send and receive messages throughput – maximum # of messages transmitted per unit time # routing hops worst case, congestion control and delay
NetworkMultis.10
Bus IN
N processors, 1 switch ( ), 1 link (the bus) Only 1 simultaneous transfer at a time
NB = link (bus) bandwidth * 1 BB = link (bus) bandwidth * 1
Processor node
Bidirectionalnetwork switch
NetworkMultis.11
Ring IN
If a link is as fast as a bus, the ring is only twice as fast as a bus in the worst case, but is N times faster in the best case
N processors, N switches, 2 links/switch, N links N simultaneous transfers
NB = link bandwidth * N BB = link bandwidth * 2
NetworkMultis.12
Fully Connected IN
N processors, N switches, N-1 links/switch, (N*(N-1))/2 links
N simultaneous transfers NB = link bandwidth * (N*(N-1))/2 BB = link bandwidth * (N/2)2
NetworkMultis.13
Crossbar (Xbar) Connected IN
N processors, N2 switches (unidirectional),2 links/switch, N2 links
N simultaneous transfers NB = link bandwidth * N BB = link bandwidth * N/2
NetworkMultis.14
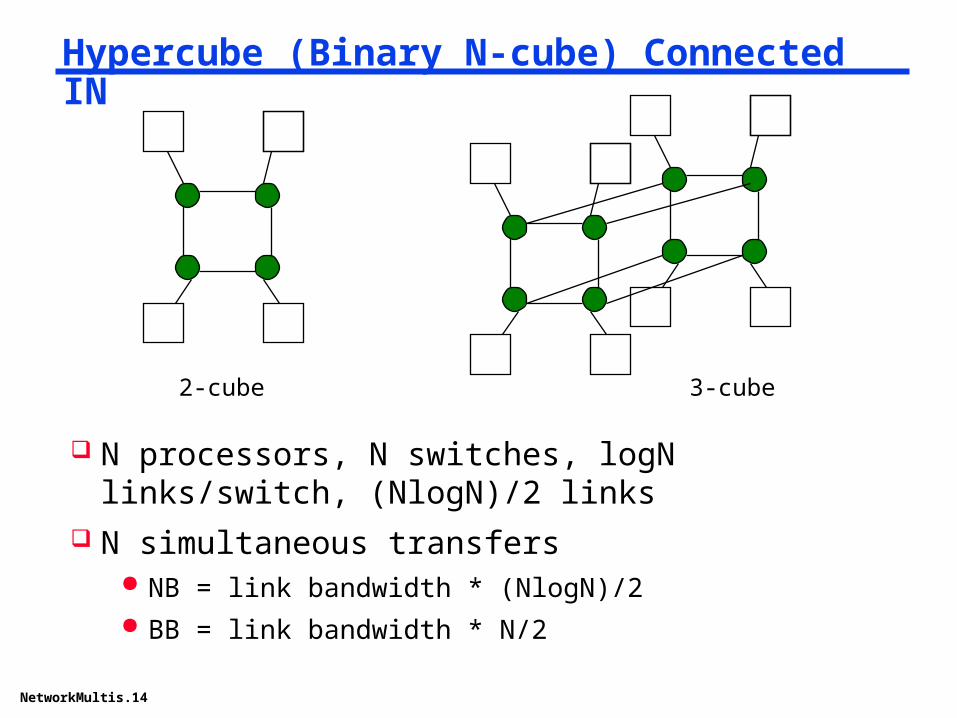
Hypercube (Binary N-cube) Connected IN
N processors, N switches, logN links/switch, (NlogN)/2 links
N simultaneous transfers NB = link bandwidth * (NlogN)/2 BB = link bandwidth * N/2
2-cube 3-cube
NetworkMultis.15
2D and 3D Mesh/Torus Connected IN
N simultaneous transfers
N processors, N switches, 2, 3, 4 (2D torus) or 6 (3D torus) links/switch, 4N/2 links or 6N/2 links
NetworkMultis.16
Fat Tree
C DA B
Trees are good structures. People in CS use them all the time. Suppose we wanted to make a tree network.
Any time A wants to send to C, it ties up the upper links, so that B can't send to D.
The bisection bandwidth on a tree is horrible - 1 link, at all times
The solution is to 'thicken' the upper links. More links as the tree gets thicker increases the bisection
Rather than design a bunch of N-port switches, use pairs
NetworkMultis.17
IN Comparison
For a 64 processor system
Bus Ring Torus 6-cube Fully connected
Network bandwidth
1
Bisection bandwidth
1
Total # of Switches
1
Links per switch
Total # of links
1
NetworkMultis.19
Network Connected Multiprocessors
Proc Proc Speed
# Proc IN Topology
BW/link (MB/sec)
SGI Origin R16000 128 fat tree 800
Cray 3TE Alpha 21164
300MHz 2,048 3D torus 600
Intel ASCI Red Intel 333MHz 9,632 mesh 800
IBM ASCI White
Power3 375MHz 8,192 multistage Omega
500
NEC ES SX-5 500MHz 640*8 640-xbar 16000
NASA Columbia
Intel Itanium2
1.5GHz 512*20 fat tree, Infiniband
IBM BG/L Power PC 440
0.7GHz 65,536*2 3D torus, fat tree, barrier
NetworkMultis.20
IBM BlueGene512-node proto BlueGene/L
Peak Perf 1.0 / 2.0 TFlops/s 180 / 360 TFlops/s
Memory Size 128 GByte 16 / 32 TByte
Foot Print 9 sq feet 2500 sq feet
Total Power 9 KW 1.5 MW
# Processors 512 dual proc 65,536 dual proc
Networks 3D Torus, Tree, Barrier
3D Torus, Tree, Barrier
Torus BW 3 B/cycle 3 B/cycle
NetworkMultis.21
A BlueGene/L Chip
32K/32K L1
440 CPU
Double FPU
32K/32K L1
440 CPU
Double FPU
2KBL2
2KBL2
16KB Multiport SRAM buffer
4MB L3ECC eDRAM
128B line8-way assoc
Gbit ethernet 3D torus Fat tree Barrier
DDR control
6 in, 6 out 1.6GHz
1.4Gb/s link
3 in, 3 out 350MHz
2.8Gb/s link
4 global barriers
144b DDR 256MB5.5GB/s
81
128
128
256
256
256
256
11GB/s
11GB/s
5.5 GB/s
5.5 GB/s
700 MHz
NetworkMultis.22
Networks of Workstations (NOWs) Clusters Clusters of off-the-shelf, whole computers with multiple
private address spaces Clusters are connected using the I/O bus of the
computers lower bandwidth that multiprocessor that use the memory bus lower speed network links more conflicts with I/O traffic
Clusters of N processors have N copies of the OS limiting the memory available for applications
Improved system availability and expandability easier to replace a machine without bringing down the whole
system allows rapid, incremental expandability
Economy-of-scale advantages with respect to costs
NetworkMultis.23
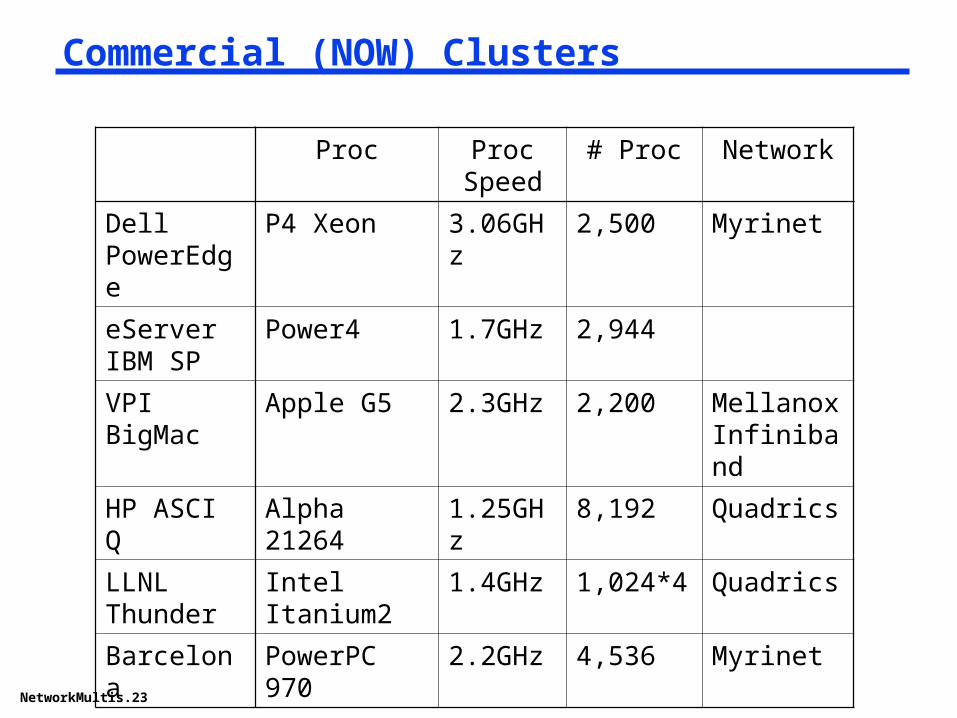
Commercial (NOW) Clusters
Proc Proc Speed
# Proc Network
Dell PowerEdge
P4 Xeon 3.06GHz 2,500 Myrinet
eServer IBM SP
Power4 1.7GHz 2,944
VPI BigMac Apple G5 2.3GHz 2,200 Mellanox Infiniband
HP ASCI Q Alpha 21264 1.25GHz 8,192 Quadrics
LLNL Thunder
Intel Itanium2 1.4GHz 1,024*4 Quadrics
Barcelona PowerPC 970 2.2GHz 4,536 Myrinet
NetworkMultis.24
Summary Flynn’s classification of processors - SISD, SIMD, MIMD
Q1 – How do processors share data? Q2 – How do processors coordinate their activity? Q3 – How scalable is the architecture (what is the maximum
number of processors)?
Shared address multis – UMAs and NUMAs Scalability of bus connected UMAs limited (< ~ 36 processors) Network connected NUMAs more scalable Interconnection Networks (INs)
- fully connected, xbar
- ring
- mesh
- n-cube, fat tree
Message passing multis Cluster connected (NOWs) multis