45
Next Generation Sequencing: Applications in Agriculture Charles Johnson, PhD Director, Genomics and Bioinformatics [email protected] www.txgen.tamu.edu

Next Generation Sequencing: Applications in Agriculture
Charles Johnson, PhD
Director, Genomics and Bioinformatics [email protected]
www.txgen.tamu.edu

Norman BorlaugCredited with saving over 1 billonpeople from starvation
Nobel Prize winner
Plant Breeder – leader of theGreen Revolution
One of my graduate professors


THE TEXAS A&M UNIVERSITY SYSTEM
Texas A&M AgriLIFE11 Universities
7 State AgenciesHealth Sciences Center
Texas A&M Engineering
Dwight Look College of EngineeringTexas A&M University
Texas A&M Engineering Experiment Station
Texas A&M Engineering Extension Service
Texas A&M Transportation Institute
College of Agriculture and Life Sciences
Texas A&M University
Texas A&M AgriLIFE Research
Texas A&M AgriLIFE Extension
Texas A&M Forest Service
Texas A&M Veterinary MedicalDiagnostic Laboratory
Ranked #1 in Agriculture Research Expenditures in US

• Equipment• Inexperience• Lack of Training
Removing Roadblocks

Who we are…
Our Vision: Become the leading genomic and bioinformatics academic service provider through superior quality service, innovation, and technical excellence. Meeting the needs of scientists across the Texas A&M System, Texas and world.
Our Core Values:
Service Obsessed – Dedication to every client’s success. Striving to exceed expectation on a daily basis and provide the best serve possible. Trust and personal responsibility in all relationships.
Problem Solvers – “Let us sweat the details, we’ll make it happen and not give up!” Problems are solved and only viewed as temporary obstacles. Innovation that matters, for TAMUS, Texas & the World.
Excellence and Pride - We strive to be the best at what we do.

Department College
Animal Science College of Agriculture and Life Science
Biochem & Biophys College of Agriculture and Life Science
Biology College of Science
Ecosystem Science and MGMT College of Agriculture and Life Science
Electrical Engineering / Chem College of Engineering
Entomology College of Agriculture and Life Science
Forest Sciences College of Agriculture and Life Science
Health and Kinesiology College of Education and Human Development
Horticulture College of Agriculture and Life Science
Nutrition and Food Science College of Agriculture and Life Science
Plant Pathology College of Agriculture and Life Science
Poultry Science College of Agriculture and Life Science
Rural Public Health Health Science Center
Soil And Crop Sciences College of Agriculture and Life Science
Statistics College of Science
Texas Veterinary Medical Diagnostic Laboratory College of Agriculture and Life Science
Veterinary Integrative Biosciences College of Veterinary Medicine
Veterinary Large Animal Medicine College of Veterinary Medicine
Biomedical Sciences College of Veterinary Medicine
Physiology & Pharmacology College of Veterinary Medicine
Veterinary Pathobiology College of Veterinary Medicine
Wildlife Science College of Agriculture and Life Science
Total
Genomics Across The World
Over 650 Scientist; >20 Countries

Project Highlights
• Human & Animal Health• Plant pathogens
– Host/Plant Relationships• Plant & Animal Breeding
– > different 17 species• Over 3500 Bacterial genomes• 1st Quarter horse sequence• 1st Scarlet Macaw sequence• 1st Pacific Shrimp sequenced• Insects, Companion Animals, Wild life• Metagenomics

Center for Bioinformatics, Genomics and Systems
Engineering
Bioinformatics, Computational Biology,
Research in Agriculture & Life Science

Feb 2014 Texas A&M University System and IBM formed a partnership
Genomics, Geoscience, Engineering and Computer Science
25 IBM Scientist moving to TAMU
13PB storage
PowerPC and Intel (~18k nodes) Super Computers
Blue Gene system
“Fat Node” for Bioinformatics 2TB RAM/Node
TAMU and IBM

Texas A&M Seed Grant Program
Empowering Genomics



Current State of Art (Reality)
• 18,000 people per year per HiSeqx (10 pack) 30x coverage. (Only Human)
• True cost ~$72M/4 years – closer to $100M to sequence and store data for 72,000 people
• All new born 3M per year would take 1,666 HiSeqx $3B per year

Single Molecule Real Time Sequencing (SMRT): PacBio
Applications:• Genome (de novo and resequencing)• Transcriptome (expression profiling, Whole transcriptome, small RNA and miRNA)•Epigenome (ChIP-Seq, DNA Methylation).
PacBio (2010)• 2900 bp (avergae) at 87-90% accuracy.• 35-75K reads per 30-120 min run.• $2/M basesPros: Longest reads, fast.Cons: Low yield at high accuracy,
Methodology:• Fluorescent dyes• Zero-mode waveguide
$695,000

Oxford Nanopore: MinIon• 1Gb in 6 hrs• 5kb reads• No decrease in quality over time
$1000

General NGS Applications
Genome (DNA-Seq)• De novo sequencing• Resequencing• Targeted Resequencing• Metagenomics• Genotyping/breeding (RAD-Seq).
Transcriptome (RNA-Seq)• Gene expression profiling• Small RNA• Whole transcriptome
Epigenome• ChIP-Seq• Methylation analysis.
Reading vs. Counting Applications

De novo SequencingSequencing and constructing a new genome or transcriptome.• Complicated by lack of reference.• Aided by long reads, paired ends and mate pair reads.• High coverage needed• Error rates not as important due to coverage.
Paired end Mate-Pair

ResequencingUsed to measure variation of a sample in relation to a known reference.• Single nucleotide polymorphisms (SNPs)• Copy number variations (CNVs).• Genomic rearrangements.• Insertion/deletions (indels).
Targeted Resequencing• Exomes (solution-based or microarray-based capture)• Amplicons• Genome-wide association studies (GWAS). Case studies of large populations lookiong at SNPs, etc.
Higher coverage with less reads.Read length not as critical.Error rates are critical as false positives/negatives may confound data.Multiplexing is critical to justify expense.

RNA-Seq
Total RNA, Poly A-enriched or rRNA-depleted
Chemical Fragmentation
cDNA Synthesis
cDNA Fragmentation
Adaptor ligation, amplification, purification
Size selection
Size selection
Size selection
Small RNA Prep is similar, but ligates adaptors first and relies on size selection• RNA isolation method must include small RNAs!
Prokaryotes, Eukaryotes,
Dealing with Ribosomes

Epigenomics
ChIP Seq: Identify DNA binding protein targets• Shear DNA to average of ~ 500 bp• Pulldown targets with antibody• Purify and make library
Whole Genome Bisulfite Seq (WGBS):Genome-wide DNA methylation status. • Uses bisulfite treatment to convert unmethylated cytosines to uracil (which is read as thymine).
MeDIP Seq: ChIP for Methylated DNA.
Reduced Representation Bisulfite Sequencing (RRBS): Uses restriction enzymes, size selection to reduce complexity and to enrich for CpGislands.

Metagenomics
• Usually primers to conserved regions of 16S/18s ribosomal RNA gene flanking highly variable regions are used to generate amplicons that are then sequenced and compared to a database.
• Shotgun metagenomics is gaining ground as it may reduce bias, but at the expense of increased cost (coverage).

Other Applications
Single Cell Seq: • Cancer cell evolution.
Ancient DNA: Sequencing highly fragmented DNA from recovered samples.
Non-coding RNA-Seq: Identify novel non-coding RNAs• Disease and other biomarkers
Cell Line-Seq: Clear, comprehensive genetic patterns of various cell lines• Mutation rates.
FFPE-Seq: Isolating nucleic acids from formalin-fixed, paraffin embedded tissues.
Custom: If you need it, it can probably be done.

It’s not just the
scale…
- it’s the complexity
Bioinformatics is Key

Crop Improvement

AG Genomics

AgriLife & Bayer Crop Science

Identify traits by phenotypic screening
Cross source material with elite cultivars
Select desirable progeny based on phenotype
Evaluate desirable lines for other agronomic traits
Repeat crossing and selection until quality reaches variety level
Traditional Breeding
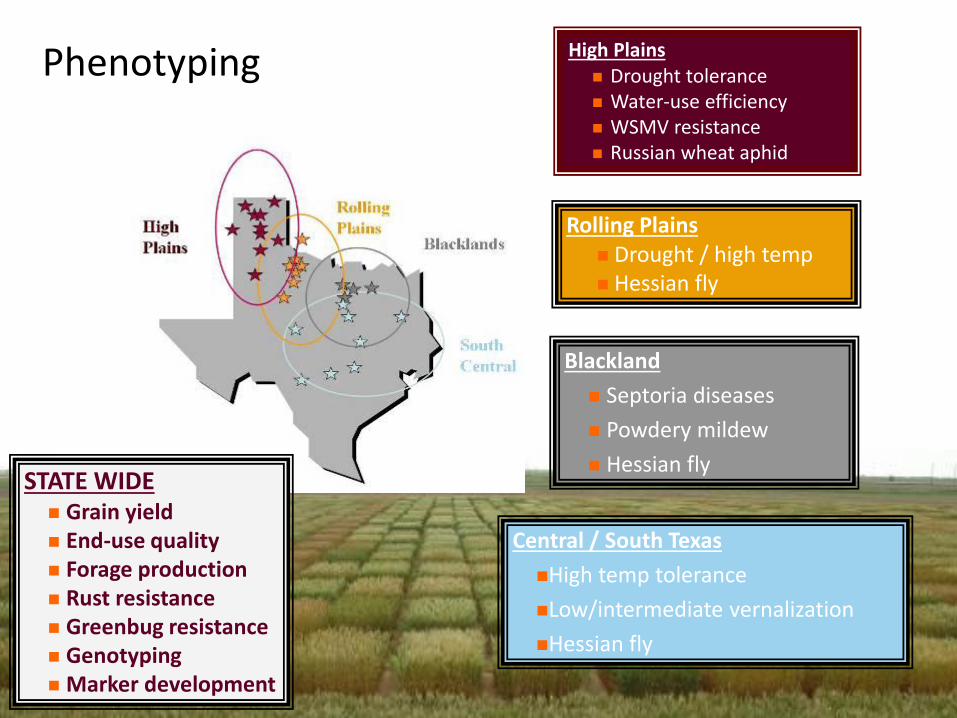
High Plains Drought tolerance Water-use efficiency WSMV resistance Russian wheat aphid
Rolling Plains Drought / high temp Hessian fly
Blackland
Septoria diseases
Powdery mildew
Hessian fly
Central / South Texas
High temp tolerance
Low/intermediate vernalization
Hessian fly
Phenotyping
STATE WIDE Grain yield End-use quality Forage production Rust resistance Greenbug resistance Genotyping Marker development

Genotype Breeding lines
Identify traits by phenotypic screening
Develop molecular maps that link DNA markers to specific Phenotypes (traits).
Use the marker(s) for MAS to guide breeder to select lines with their trait of interest.
Marker Assisted Selection
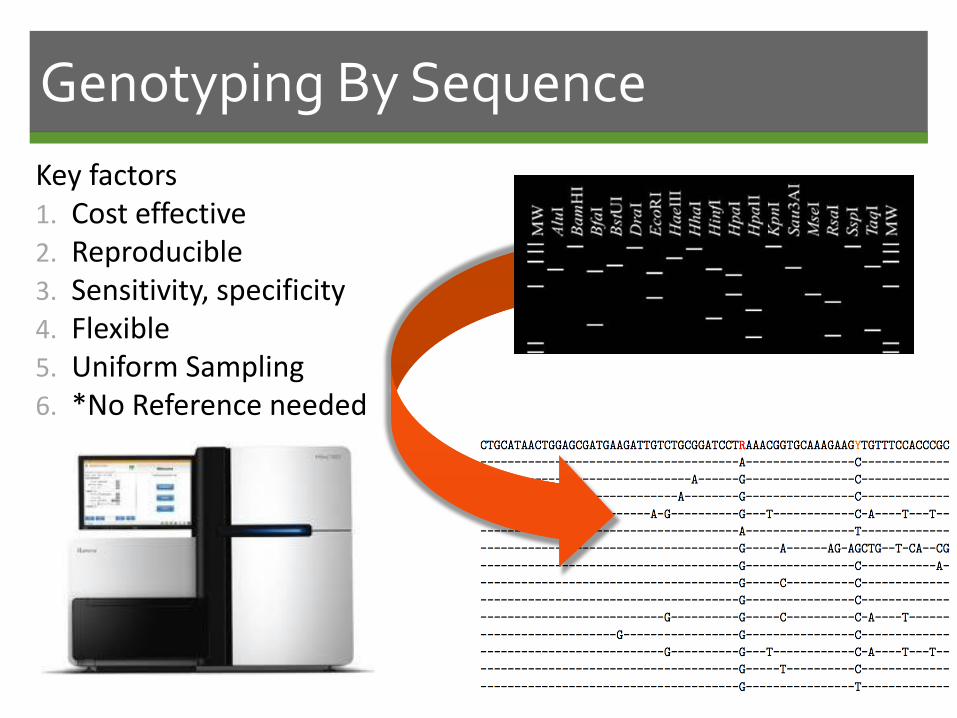
Genotyping By Sequence
1. Genome Size and complexity
2. Lack of reference
Key factors1. Cost effective2. Reproducible3. Sensitivity, specificity4. Flexible5. Uniform Sampling6. *No Reference needed

Whole genome?Cost - # individuals
Large and Complex Genomes
Polyploidy, repeats, high GC
Lack of Annotated Genome References
Genotyping with NGS

Reduce Representation or complexity reduction
Targeted Sequencing
Random shallow multiplex sequencing
Genotype-by-Sequencing
RADSeq
GBS (2dGBS)
Digital Genotyping (nested RE) 8,6,4
ddRADSeq
RESTSeq
bbRADSeq (double cutters)
nextRAD (no RE)
EzRad
Flavors of Genotyping by NGS

Markers for recombination binsfor phenotype association
SNP(s) discovery is done via reproducible reduced representation sequencing
Shotgun sequencingFull genome coverage
RE sequencingReduced representation
Restriction site Restriction site

Restriction enzyme aided DNA Sequencing
Uses restriction enzymes to reduce complexity and increase coverage of a small subset of the genome.
• Genotyping by Sequencing• Useful for large scale breeding and mapping studies• SNP detection.
Flexibility:• Choice of site(s) • Length of site (4-, 6-, 8-base cutters)
• DNA status: Methyl-sensitive Cutters
Shotgun sequence
RAD-Seq
Restriction site Restriction site

Restriction Enzymes
Primers
Barcodes
Fragmentation
Size Section
Sage Pippin!
Lab Variables

Genotyping by Sequencing
RAD-Seq
ddRAD-Seqwith size selection
FseI site FseI site
FseIsite
FseIsite
MspIsite
MspIsite
MspIsite
MspIsite
MspIsite
Peterson BK, Weber JN, Kay EH, Fisher HS, et al. (2012) Double Digest RADseq: An Inexpensive Method for De Novo SNP Discovery and Genotyping in Model and Non-Model Species. PLoS ONE 7(5): e37135. doi:10.1371/journal.pone.0037135http://www.plosone.org/article/info:doi/10.1371/journal.pone.0037135

Double Digest Benefits
1.Anchored paired end readsBoth ends usable as markersBuilt-in redundancy check
2.Size selection controls fragment length biasUniform coverageReduced sequence requirementsPloidy/dosage estimation

J. Catchen, A. Amores, P. Hohenlohe, W. Cresko, and J. Postlethwait. ``Stacks: building and genotyping loci de novo from short-read sequences’’. G3:
Genes, Genomes, Genetics, 1:171-182, 2011

Challenges
Users issues
Core issues
User * Core issues (Timing)
Working with your NGS CORE

Challenges-Users
Not main problem
Cost
Equipment
Samples
Main Problem
Training
Lack of Bioinformatics Training
Lack of Computer skills
Lack of Statistical training
Lack of laboratory experience
Students often don’t like learning new things (?)

Challenges- Core
Collaborators
Best and hardest part of the job
Juggling 20-50 Projects at a time
Everyone wants their project done first
P of failure = other lab methods, cost >>
Lack of planning- hint Google is your friend
“Who long will it take”
Authorship

Challenges- Timing
Tricks to getting your samples done quickly Provide lots of high quality DNA/RNA
The list is roughly in order of speed MiSeq run
Full flow cell of HiSeq rapid (2 lanes)
Full flow cell HiSeq High Output (HO) (8 lanes)
One lane HiSeq rapid (flexible type (PE or SE and any length)
One lane HiSeq Rapid (specific length and end type) *
More then one lane HiSeq HO (flexible)
More then one lane HiSeq HO (specific length and end-type)
One lane HiSeq HO (specific length and end-type)
Part of a lane (spike-in) (flexible for length and end-type)
Part of a lane (spike-in) specific length and end-type)
* Different run types can very considerably in terms of popularity so a run configuration that is less popular will take a long time to fill up.

Challenges- Spike-ins
Spike-in study
Why is it taking so long!!
Things that must happen
A run has to fit your length and end-type requirement
Someone else must want only part of a lane as well with same size and end-type
there must be enough samples to fill a flow cell (2 or 8 lanes)

Administration:
- Dr. Gail Martin
Laboratory:
- Dr. Richard Metz- R&D Lead
- Dr. Joshua Hill
- Shannon Parma
- Hiring - Postdoc
Bioinformatics:
- Dr. Noushin Ghaffari- scientist
- Dr. Marcel Brun- visiting scientist
- John Thiltges- IT Lead/computer engineer
- Hiring – (2) Bioinformatics Scientist, (2) Postdocs
Genomics & Bioinformatics Service
http://www.txgen.tamu.edu/

















