56
1 Bryan Hang Zhang Natural Language Processing Almost From Scratch
| Date post: | 14-Jan-2017 |
| Category: |
Data & Analytics |
| Upload: | bryan-gummibearehausen |
| View: | 228 times |
| Download: | 1 times |

11
Bryan Hang Zhang
Natural Language Processing Almost From Scratch

22
• Presents a deep neural network architecture for NLP tasks
• Presents results comparable to state-of-art on 4 NLP tasks
• Part of Speech tagging
• Chunking
• Named Entity Recognition
• Semantic Role Labeling
• Presents word embeddings learned from a large unlabelled corpus and shows an improvement in results by using these features
• Presents results of joint training for the above tasks.

33
• Propose a unified neural network architecture and learning algorithm that can be applied to various NLP tasks
• Instead of creating hand-crafted features, we can acquire task-specific features ( internal representation) from great amount of labelled and unlabelled training data.
Motivation

44
• Part of Speech Tagging
• Successively assign Part-of-Speech tags to words in a text sequence automatically.
• Chunking• Chunking is also called shallow parsing and it's basically the
identification of parts of speech and short phrases (like noun phrases)
• Named Entity Recognition• classify the elements in the text into predefined categories
such as person, location etc.
Task Introduction

55
• SRL is sometimes also called shallow semantic parsing, is a task in consisting of the detection of the semantic arguments associated with the predicate or verb of a sentence and their classification into their specific roles.
Semantic Role Labeling
e.g 1. Mark sold the car to Mary.
agent represent predicate theme recipient
e.g 2.

66
State-of-the-art systems experiment setup
ÜÙÕ½ÞéÜÛÝß

77
Benchmark Systems

88
Networks Architecture

99
• Traditional Approach:
• hand-design features
• New Approach:
• multi-layer neural networks.
The Networks

1010
• Transforming Words into Feature Vectors
• Extracting Higher Level Features from Word Feature Vector
• Training
• Benchmark Result
Bullet

1111
• Transforming Words into Feature Vectors
• Extracting Higher Level Features from Word Feature Vector
• Training
• Benchmark Result
Bullet
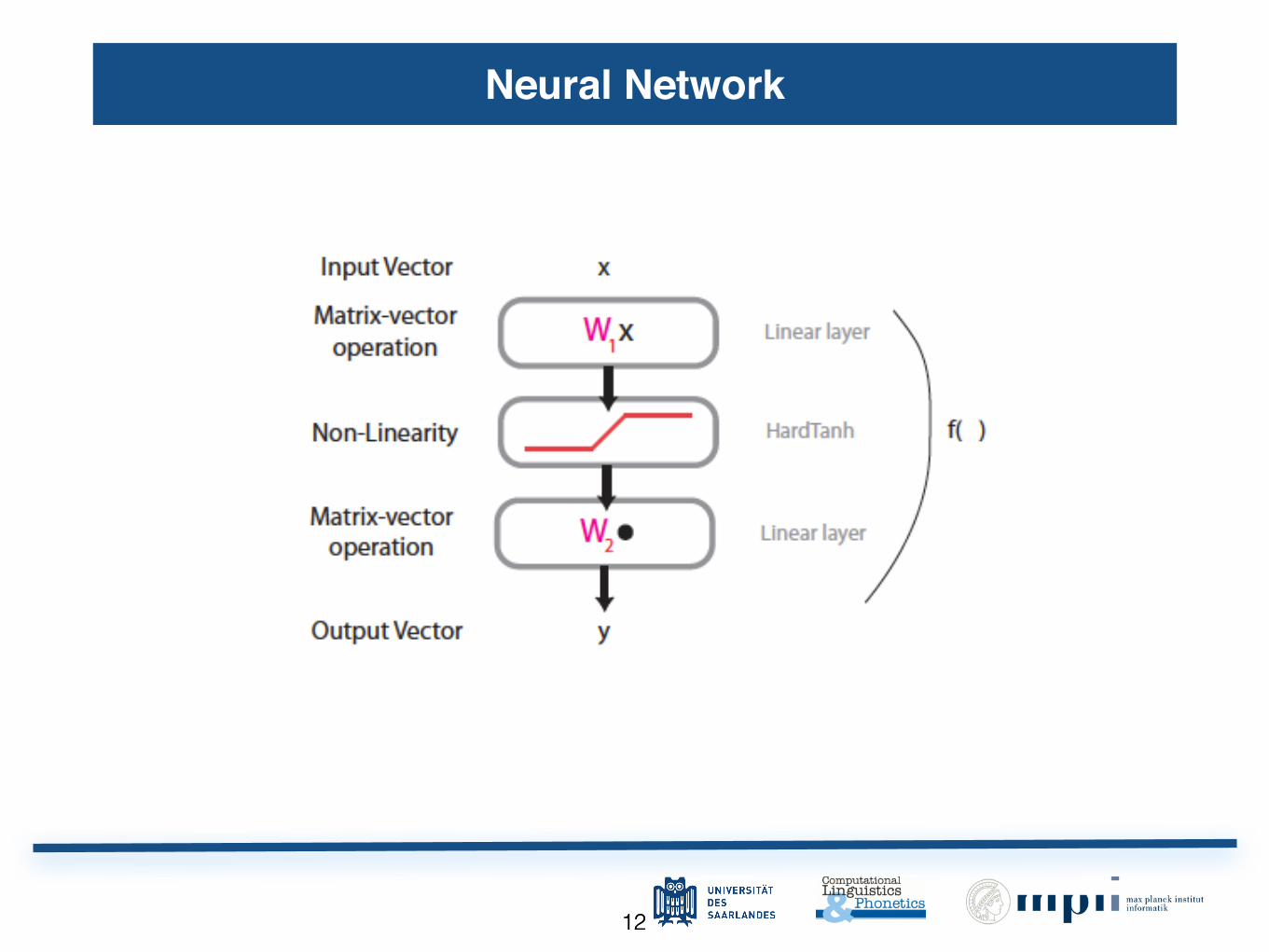
1212
Neural Network

1313
P~�B¢��¢
Window approach network Sentence approach network
P~�B¢��¢
Window approach network Sentence approach network
Two Approaches Overview

1414
• K Discrete Features construct a Matrix as a lookup table
Lookup tablesÁ.�
S�_ÒK�Ádiscrete feature¼8�³¸Matrix
Lookup Tables

1515
• Window Size: for example, 5
• Raw text features:
• — Lower case word
• — Capitalised feature
Words to Features: Window Approach
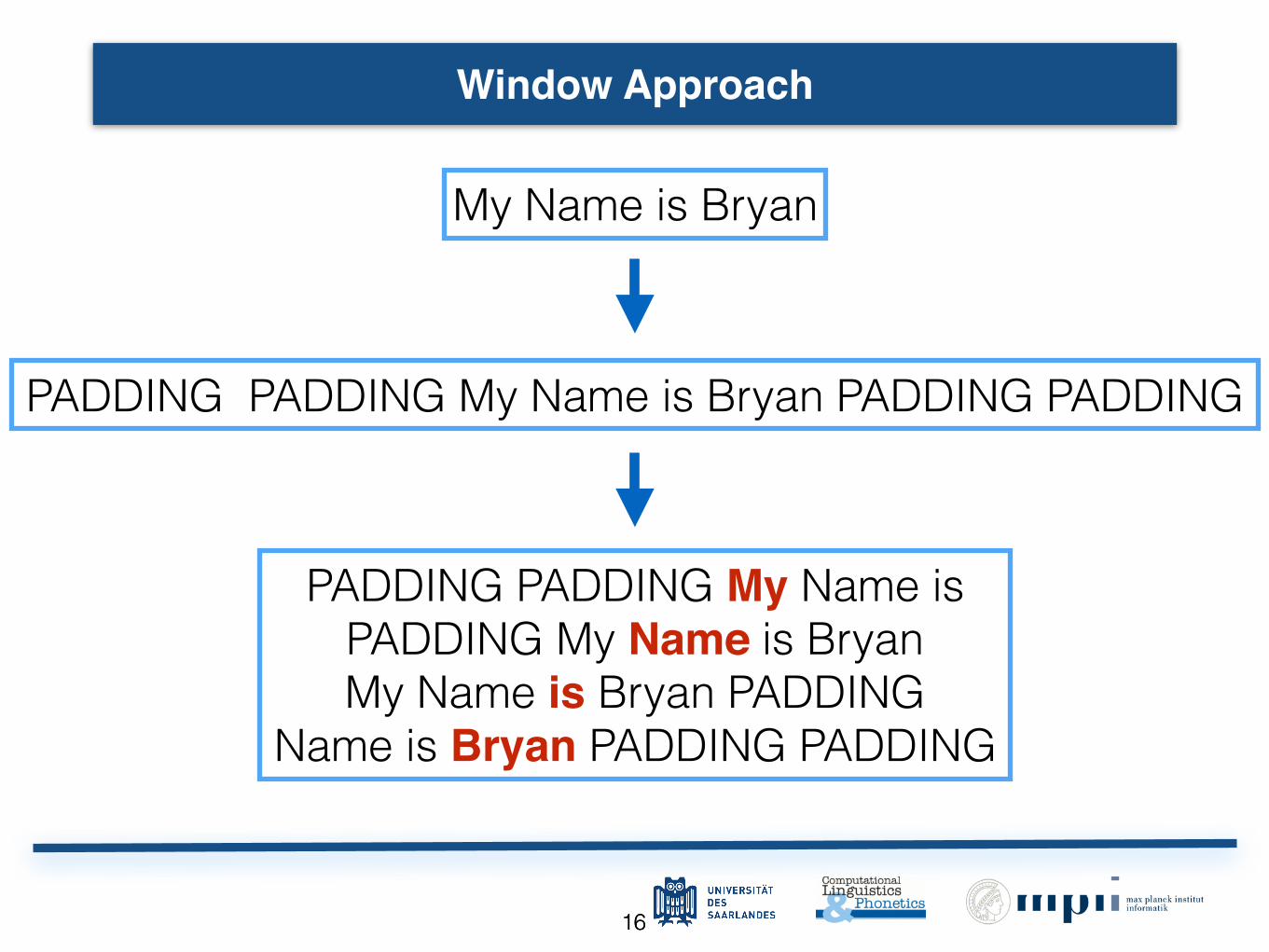
1616
Window Approach
My Name is Bryan
PADDING PADDING My Name is Bryan PADDING PADDING
PADDING PADDING My Name is PADDING My Name is Bryan My Name is Bryan PADDING
Name is Bryan PADDING PADDING

1717
Word to FeaturesWords to features!
My
Word index!
Caps index!
Vocabulary size (130,000)!
Number of options (5)!
50!
5!
6"
Word Lookup Table
Caps Lookup Table

1818
Words to Features
PADDINGPADDING
MyName
is
Words to features!
PADDING PADDING
My Name
is 275!
7"

1919
• Transforming Words into Feature Vectors
• Extracting Higher Level Features from Word Feature Vector
• Training
• Benchmark Result
Bullet

2020
Extracting Higher Level Features Word Feature Vectors
L-layer Neural Network
Extracting Higher Level Features From Word Feature Vectors
LuÁNeural Network
lu�O
àåãéÜ
Extracting Higher Level Features From Word Feature Vectors
LuÁNeural Network
lu�O
àåãéÜ
Extracting Higher Level Features From Word Feature Vectors
LuÁNeural Network
lu�O
àåãéÜ
Any feed forward neural network with L layers cane be seen as a composition of function corresponding to each layer l
: parameters
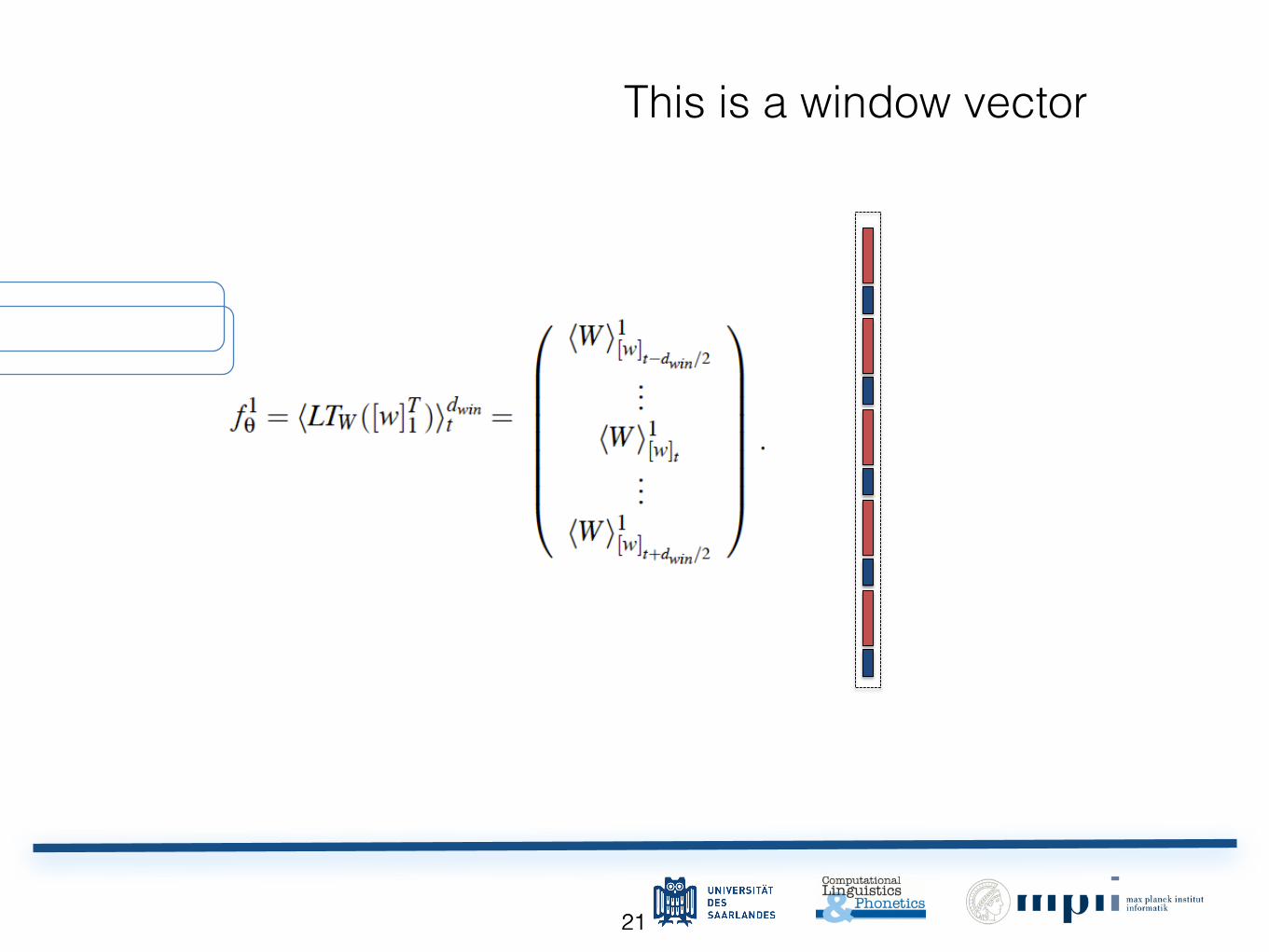
2121
Window approach
Á:G
€
t = 3,dwi n = 2
€
w11
w12
Mw13
Mw5
K−1
w5K
/�Á_ÁK�áÕßçÒYF³¸ÊÁ¬<"áÕßç
Window approach
Window approach
Á:G
€
t = 3,dwi n = 2
€
w11
w12
Mw13
Mw5
K−1
w5K
/�Á_ÁK�áÕßçÒYF³¸ÊÁ¬<"áÕßç
Window approach
Words to features!
PADDING PADDING
My Name
is 275!
7"
This is a window vector

2222
Linear Layer (window approach)Linear Layer
Window approach
Parameters to be
trained
€
nhul (lu¼Áhidden unitO
Linear Layer
Window approach
Parameters to be
trained
€
nhul (lu¼Áhidden unitO
arXiv
Collobert, Weston, Bottou, Karlen, Kavukcuoglu and Kuksa
The matrix output of the lookup table layer for a sequence of words [w]T1
is then similarto (1), but where extra rows have been added for each discrete feature:
LT
W
1,...,W
K
([w]T1
) =
0
B
B
@
hW 1i1[w1]1
. . . hW 1i1[w1]
T
......
hWKi1[w
K
]1. . . hWKi1
[w
K
]
T
1
C
C
A
. (2)
These vector features in the lookup table e↵ectively learn features for words in the dictionary.Now, we want to use these trainable features as input to further layers of trainable featureextractors, that can represent groups of words and then finally sentences.
3.2 Extracting Higher Level Features from Word Feature Vectors
Feature vectors produced by the lookup table layer need to be combined in subsequent layersof the neural network to produce a tag decision for each word in the sentence. Producingtags for each element in variable length sequences (here, a sentence is a sequence of words)is a standard problem in machine-learning. We consider two common approaches which tagone word at the time: a window approach, and a (convolutional) sentence approach.
3.2.1 Window Approach
A window approach assumes the tag of a word depends mainly on its neighboring words.Given a word to tag, we consider a fixed size k
sz
(a hyper-parameter) window of wordsaround this word. Each word in the window is first passed through the lookup table layer (1)or (2), producing a matrix of word features of fixed size d
wrd
⇥ k
sz
. This matrix can beviewed as a d
wrd
k
sz
-dimensional vector by concatenating each column vector, which can befed to further neural network layers. More formally, the word feature window given by thefirst network layer can be written as:
f
1
✓
= hLTW
([w]T1
)idwin
t
=
0
B
B
B
B
B
B
B
B
@
hW i1[w]
t�d
win
/2
...hW i1
[w]
t
...hW i1
[w]
t+d
win
/2
1
C
C
C
C
C
C
C
C
A
. (3)
Linear Layer The fixed size vector f
1
✓
can be fed to one or several standard neuralnetwork layers which perform a�ne transformations over their inputs:
f
l
✓
= W
l
f
l�1
✓
+ b
l
, (4)
whereW l 2 Rn
l
hu
⇥n
l�1hu and b
l 2 Rn
l
hu are the parameters to be trained. The hyper-parametern
l
hu
is usually called the number of hidden units of the l
th layer.
HardTanh Layer Several linear layers are often stacked, interleaved with a non-linearityfunction, to extract highly non-linear features. If no non-linearity is introduced, our network
10
number of hidden units of the l th layer
arXiv
Collobert, Weston, Bottou, Karlen, Kavukcuoglu and Kuksa
The matrix output of the lookup table layer for a sequence of words [w]T1
is then similarto (1), but where extra rows have been added for each discrete feature:
LT
W
1,...,W
K
([w]T1
) =
0
B
B
@
hW 1i1[w1]1
. . . hW 1i1[w1]
T
......
hWKi1[w
K
]1. . . hWKi1
[w
K
]
T
1
C
C
A
. (2)
These vector features in the lookup table e↵ectively learn features for words in the dictionary.Now, we want to use these trainable features as input to further layers of trainable featureextractors, that can represent groups of words and then finally sentences.
3.2 Extracting Higher Level Features from Word Feature Vectors
Feature vectors produced by the lookup table layer need to be combined in subsequent layersof the neural network to produce a tag decision for each word in the sentence. Producingtags for each element in variable length sequences (here, a sentence is a sequence of words)is a standard problem in machine-learning. We consider two common approaches which tagone word at the time: a window approach, and a (convolutional) sentence approach.
3.2.1 Window Approach
A window approach assumes the tag of a word depends mainly on its neighboring words.Given a word to tag, we consider a fixed size k
sz
(a hyper-parameter) window of wordsaround this word. Each word in the window is first passed through the lookup table layer (1)or (2), producing a matrix of word features of fixed size d
wrd
⇥ k
sz
. This matrix can beviewed as a d
wrd
k
sz
-dimensional vector by concatenating each column vector, which can befed to further neural network layers. More formally, the word feature window given by thefirst network layer can be written as:
f
1
✓
= hLTW
([w]T1
)idwin
t
=
0
B
B
B
B
B
B
B
B
@
hW i1[w]
t�d
win
/2
...hW i1
[w]
t
...hW i1
[w]
t+d
win
/2
1
C
C
C
C
C
C
C
C
A
. (3)
Linear Layer The fixed size vector f
1
✓
can be fed to one or several standard neuralnetwork layers which perform a�ne transformations over their inputs:
f
l
✓
= W
l
f
l�1
✓
+ b
l
, (4)
whereW l 2 Rn
l
hu
⇥n
l�1hu and b
l 2 Rn
l
hu are the parameters to be trained. The hyper-parametern
l
hu
is usually called the number of hidden units of the l
th layer.
HardTanh Layer Several linear layers are often stacked, interleaved with a non-linearityfunction, to extract highly non-linear features. If no non-linearity is introduced, our network
10
arXiv
Collobert, Weston, Bottou, Karlen, Kavukcuoglu and Kuksa
The matrix output of the lookup table layer for a sequence of words [w]T1
is then similarto (1), but where extra rows have been added for each discrete feature:
LT
W
1,...,W
K
([w]T1
) =
0
B
B
@
hW 1i1[w1]1
. . . hW 1i1[w1]
T
......
hWKi1[w
K
]1. . . hWKi1
[w
K
]
T
1
C
C
A
. (2)
These vector features in the lookup table e↵ectively learn features for words in the dictionary.Now, we want to use these trainable features as input to further layers of trainable featureextractors, that can represent groups of words and then finally sentences.
3.2 Extracting Higher Level Features from Word Feature Vectors
Feature vectors produced by the lookup table layer need to be combined in subsequent layersof the neural network to produce a tag decision for each word in the sentence. Producingtags for each element in variable length sequences (here, a sentence is a sequence of words)is a standard problem in machine-learning. We consider two common approaches which tagone word at the time: a window approach, and a (convolutional) sentence approach.
3.2.1 Window Approach
A window approach assumes the tag of a word depends mainly on its neighboring words.Given a word to tag, we consider a fixed size k
sz
(a hyper-parameter) window of wordsaround this word. Each word in the window is first passed through the lookup table layer (1)or (2), producing a matrix of word features of fixed size d
wrd
⇥ k
sz
. This matrix can beviewed as a d
wrd
k
sz
-dimensional vector by concatenating each column vector, which can befed to further neural network layers. More formally, the word feature window given by thefirst network layer can be written as:
f
1
✓
= hLTW
([w]T1
)idwin
t
=
0
B
B
B
B
B
B
B
B
@
hW i1[w]
t�d
win
/2
...hW i1
[w]
t
...hW i1
[w]
t+d
win
/2
1
C
C
C
C
C
C
C
C
A
. (3)
Linear Layer The fixed size vector f
1
✓
can be fed to one or several standard neuralnetwork layers which perform a�ne transformations over their inputs:
f
l
✓
= W
l
f
l�1
✓
+ b
l
, (4)
whereW l 2 Rn
l
hu
⇥n
l�1hu and b
l 2 Rn
l
hu are the parameters to be trained. The hyper-parametern
l
hu
is usually called the number of hidden units of the l
th layer.
HardTanh Layer Several linear layers are often stacked, interleaved with a non-linearityfunction, to extract highly non-linear features. If no non-linearity is introduced, our network
10
To be trained
linear layers stackedinterleaved with nonlinearity function to extract highly non linear features. with out non linearity, the network would be just a linear model.
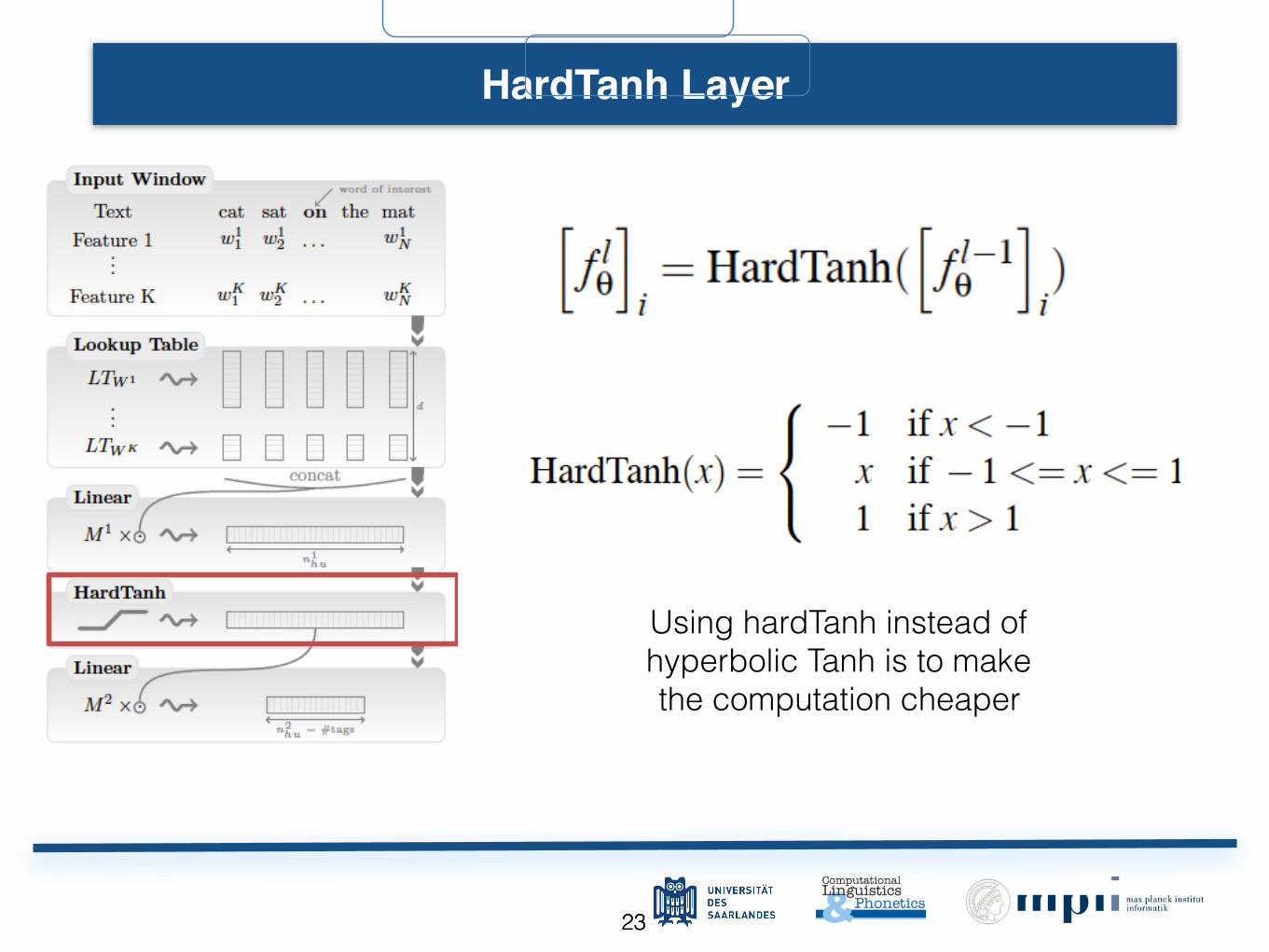
2323
HardTanh LayerHardTanh Layer
• Non-linear featureÁ8�Window approach
HardTanh Layer
• Non-linear featureÁ8�Window approach HardTanh Layer
• Non-linear featureÁ8�Window approach
Using hardTanh instead of hyperbolic Tanh is to make the computation cheaper

2424
• Window Approach works well for most NLP tasks . However, it fails with Semantic Role Labelling.
Window Approach Remark
Reason: the tag of a word depends on the verb ( predicate) chosen beforehand in
the sentence . If the verb falls outside the window then one cannot expect this word to be tagged correctly. Then it requires the consideration of sentence approach.

2525
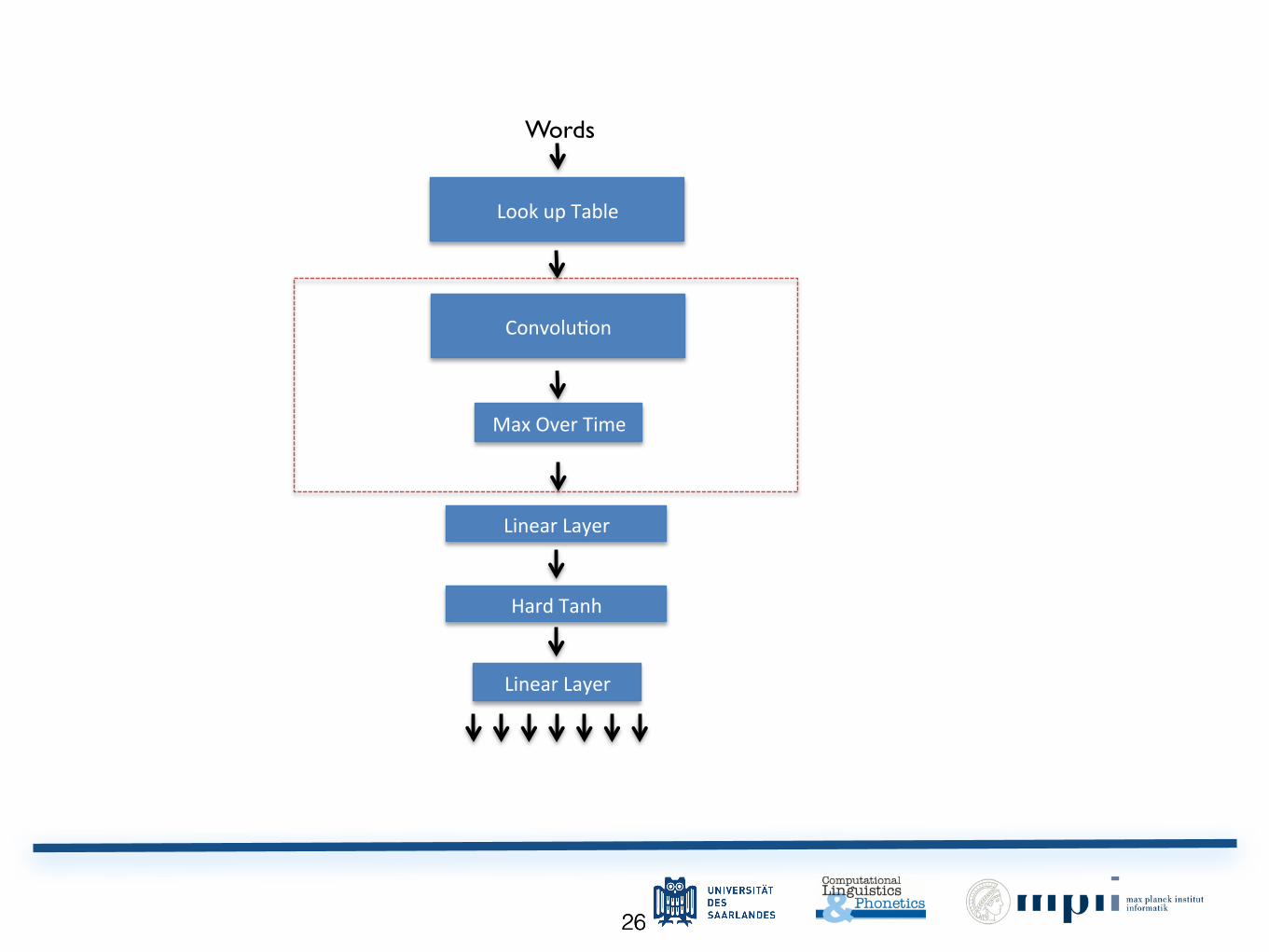
Convoluntional Layer : Sentence ApproachConvolutional Layer
Sentence approach
sentence#;¬<"áÕßç
→1<"Á¼ _�À�+ҵͳ»<"
Convolutional Layer
Sentence approach
sentence#;¬<"áÕßç
→1<"Á¼ _�À�+ҵͳ»<"
generalisation of window approach, windows in a sequence can be all taken into consideration
2626
Neural Network Architecture!
Look"up"Table"
Words!
Linear"Layer"
Hard"Tanh"
Linear"Layer"
Convolu7on"
Max"Over"Time"
3"

2727
Convoluntional NN

2828
Time Delay Neural Neural NetworkTime Delay Neural Network
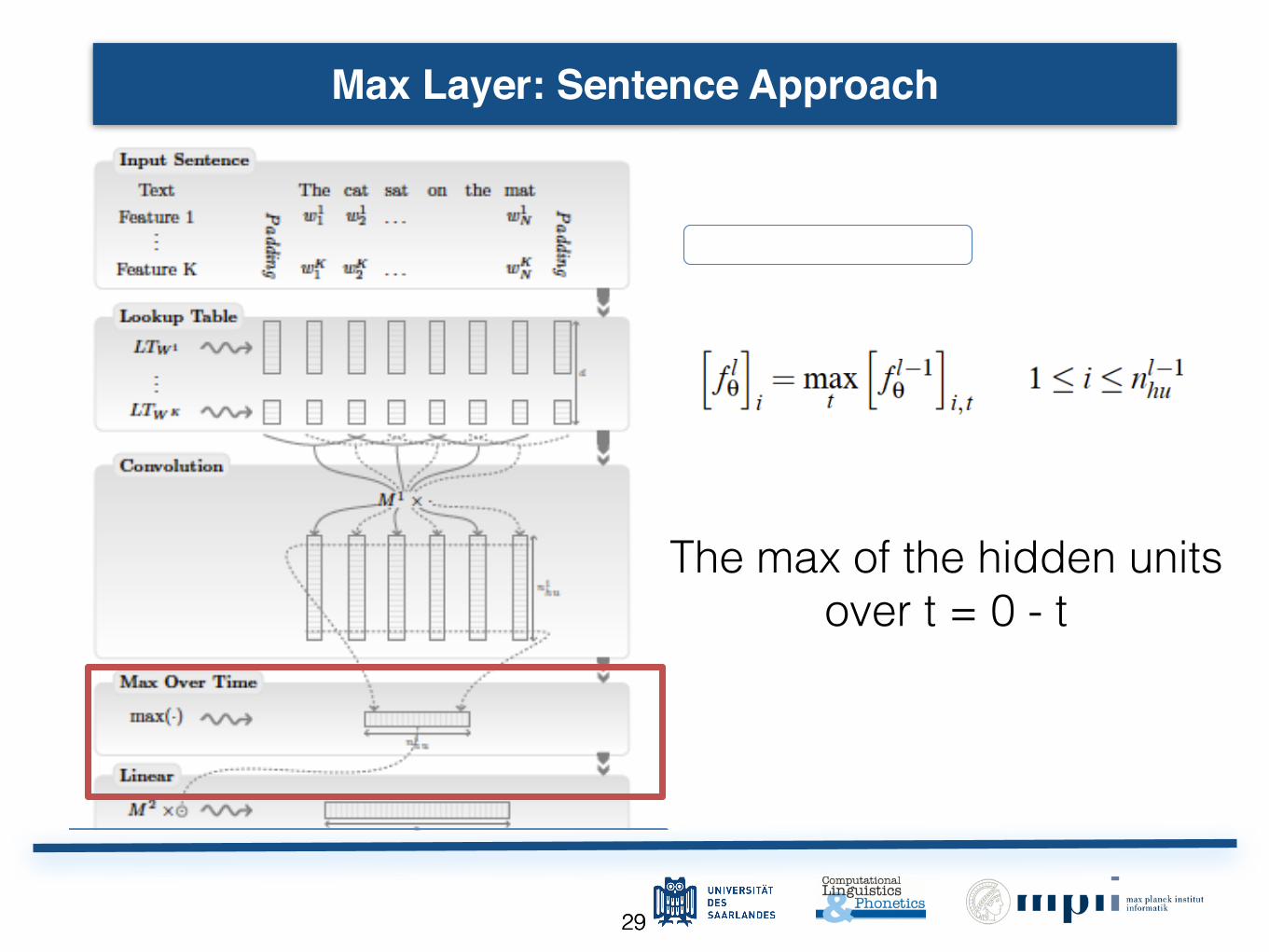
2929
Max Layer: Sentence ApproachMax Layer
Sentence approach
Shidden unit ±½Àt=0¢t¼��½¿Ï9ÈÒ(l
uÄÁ9ÈÀ
Max Layer
Sentence approach
Shidden unit ±½Àt=0¢t¼��½¿Ï9ÈÒ(l
uÄÁ9ÈÀ
The max of the hidden units over t = 0 - t

3030
Tagging SchemeTagging Schemes

3131
• Transforming Words into Feature Vectors
• Extracting Higher Level Features from Word Feature Vector
• Training
• Benchmark Result
Bullet

3232
Training
Maximising the log-likelihood with respect to Theta
Training
�O�AÁ��QTraining
�O�AÁ��Q
is the training set

3333
Training: Word Level Log-Likelihood
Training
Word Level
Log-Likelihood
soft max all
over tags
cross-entropy, it is not ideal because of the tag of a word in the sentence and its neighbouring tags

3434
Training: Sentence Level Log-Likelihood
Training
Sentence Level Log-Likelihood
transition score to jump from tag k to tag i
€
Ak ,l
Sentence score for a tag path
€
[i ]1T

3535
Training Sentence Level Log-Likelihood
Training
Sentence Level
Log-Likelihood
Conditional likelihood
by normalizing w.r.t all possible paths
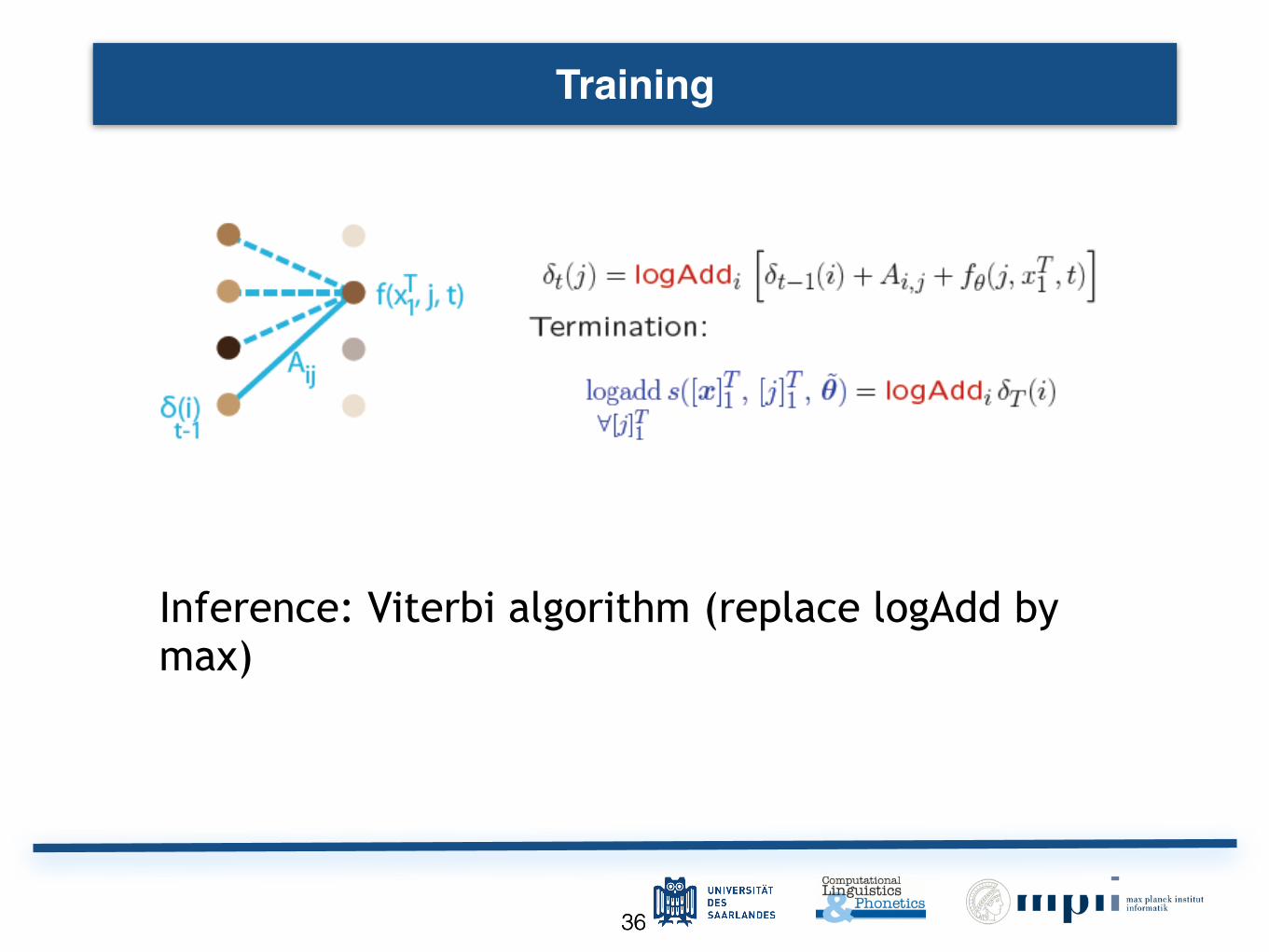
3636
Training Training
7zQo recursive Forward algorithm ¼W���
Inference: Viterbi algorithm (replace logAdd by
max)

3737
• Transforming Words into Feature Vectors
• Extracting Higher Level Features from Word Feature Vector
• Training
• Benchmark Result
Bullet

3838
• use lower case words in the dictionary
• add ‘caps’ feature to words that have at least one non-initial capital letter.
• number with in a word are replaced with the string ‘Number’
Pre-processing

3939
Hyper-parametersHyper-parameters

4040
Benchmark Result
Sentences with similar words should be tagged in the same way.
e.g. The cat sat on the mat.
The feline sat on the mat.

4141
Neighbouring Wordsneighboring words
neighboring words¬*V�À�Y³»§¿§word embeddings in the word lookup table of a SRL neural network trained from scratch. 10 nearest neighbours using Euclidean metirc.

4242
• The Lookup table can also be trained on unlabelled data by optimising it to learn a language model.
• This gives words features that map similar words to similar vectors (semantically)
Word Embeddings

4343
Sentence Embedding
Document Embedding
Word Embedding

4444
Ranking Language ModelRanking Language Model
Ranking Language Model

4545
Tremendous Unlabelled DataLots of Unlabeled Data
• Two window approach (11) networks (100HU) trained on two corpus
• LM1 – Wikipedia: 631 Mwords – order dictionary words by frequency – increase dictionary size: 5000, 10; 000, 30; 000, 50; 000,
100; 000 – 4 weeks of training
• LM2 – Wikipedia + Reuter=631+221=852M words – initialized with LM1, dictionary size is 130; 000 – 30,000 additional most frequent Reuters words – 3 additional weeks of training

4646
Word EmbeddingsWord Embeddings
neighboring words¬*V�À�Y³»§Ï

4747
Benchmark PerformanceBenchmark�Performance

4848
Multitask Learning

4949arXiv
Natural Language Processing (almost) from Scratch
Lookup Table
Linear
Lookup Table
Linear
HardTanh HardTanh
Linear
Task 1
Linear
Task 2
M
2(t1) ⇥ · M
2(t2) ⇥ ·
LT
W
1
...LT
W
K
M
1 ⇥ ·n1
hu n1
hu
n2
hu,(t1)= #tags n2
hu,(t2)= #tags
Figure 5: Example of multitasking with NN. Task 1 and Task 2 are two tasks trained withthe window approach architecture presented in Figure 1. Lookup tables as well as the firsthidden layer are shared. The last layer is task specific. The principle is the same with morethan two tasks.
5.2 Multi-Task Benchmark Results
Table 9 reports results obtained by jointly trained models for the POS, CHUNK, NER andSRL tasks using the same setup as Section 4.5. We trained jointly POS, CHUNK and NERusing the window approach network. As we mentioned earlier, SRL can be trained onlywith the sentence approach network, due to long-range dependencies related to the verbpredicate. We thus also trained all four tasks using the sentence approach network. Inboth cases, all models share the lookup table parameters (2). The parameters of the firstlinear layers (4) were shared in the window approach case (see Figure 5), and the first theconvolution layer parameters (6) were shared in the sentence approach networks.
For the window approach, best results were obtained by enlarging the first hidden layersize to n
1
hu
= 500 (chosen by validation) in order to account for its shared responsibilities.We used the same architecture than SRL for the sentence approach network. The wordembedding dimension was kept constant d
0 = 50 in order to reuse the language modelsof Section 4.5.
Training was achieved by minimizing the loss averaged across all tasks. This is easilyachieved with stochastic gradient by alternatively picking examples for each task andapplying (17) to all the parameters of the corresponding model, including the sharedparameters. Note that this gives each task equal weight. Since each task uses the trainingsets described in Table 1, it is worth noticing that examples can come from quite di↵erent
27
Joint Training

5050
MultiTask Learning

5151
Temptation

5252
The Temptation·Á�ÁDy• Suffix Features – Use last two characters as feature
• Gazetters – 8,000 locations, person names, organizations
and misc entries from CoNLL 2003 • POS – use POS as a feature for CHUNK & NER
• CHUNK – use CHUNK as a feature for SRL

5353
·Á�ÁDy

5454
Ensembles·Á�ÁDy
�¿Ïàåãéܼ10�ÁNeural NetworkÒ.�
→SÜÙÕÁJAÒ��voting ensemble: voting ten network outputs on a per tag basis joined ensemble: parameters of the combining layer were trained on the existing training set while keeping the networks fixed.

5555
ConclusionConclusion
• Achievements
– “All purpose" neural network architecture for NLP tagging
– Limit task-specic engineering
– Rely on very large unlabeled datasets
– We do not plan to stop here
• Critics
– Why forgetting NLP expertise for neural network training skills?
• NLP goals are not limited to existing NLP task
• Excessive task-specic engineering is not desirable
– Why neural networks?
• Scale on massive datasets
• Discover hidden representations
• Most of neural network technology existed in 1997 (Bottou, 1997)

5656
Thank you!

















