On Feature Selection in Maximum Entropy Approach to Statistical Concept- based Speech-to-Speech Translation Authored by: Liang Gu and Yuqing Gao Presented by: Ruhi Sarikaya October 1 st , 2004
Transcript
On Feature Selection in Maximum
Entropy Approach to Statistical Concept-
based Speech-to-Speech Translation
Authored by: Liang Gu and Yuqing Gao
Presented by: Ruhi Sarikaya
October 1st, 2004
Outline
� Statistical Concept-based Speech Translation
� Natural Concept Generation (NCG)
� Feature Selection in Statistical NCG
� Conciseness vs. Informativity of Concepts
� Features using both Concept & Word Information
� Multiple Feature Selection
� Experimental Results
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
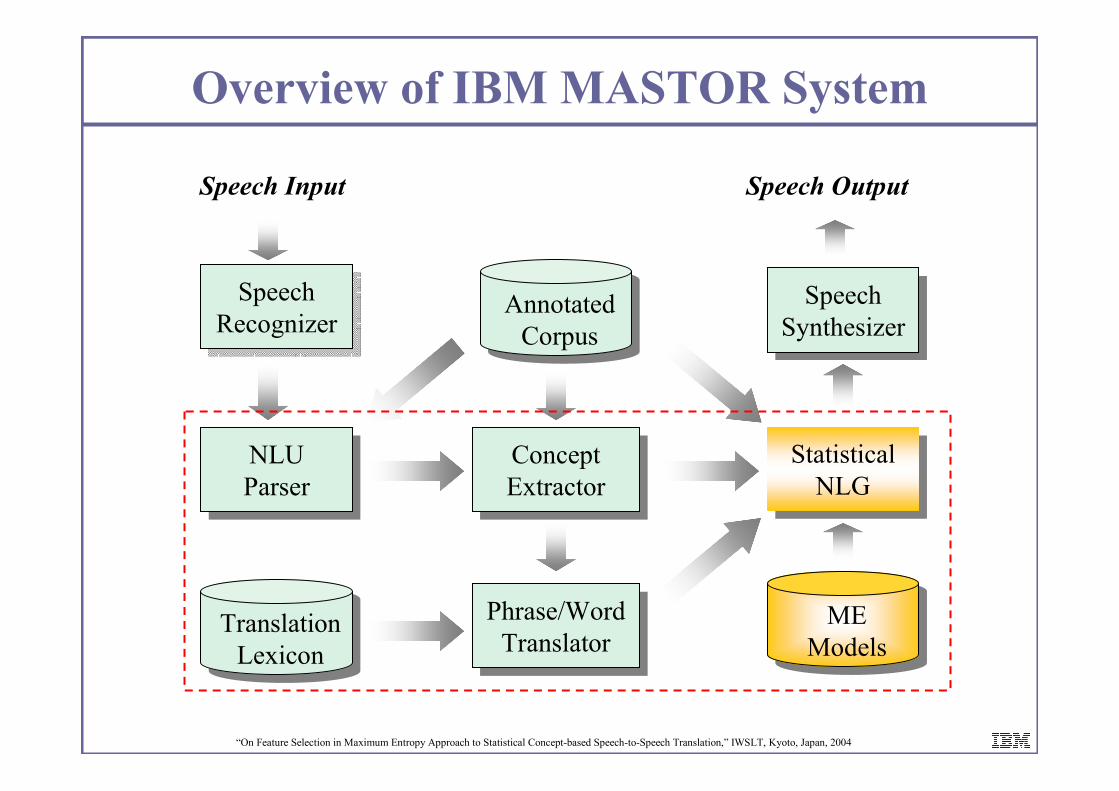
Overview of IBM MASTOR System
Speech
Recognizer
Speech
Recognizer
Translation
Lexicon
ME
Models
Speech Input
NLU
Parser
NLU
ParserConcept
Extractor
Concept
Extractor
Phrase/Word
Translator
Phrase/Word
Translator
Speech Output
Speech
Synthesizer
Speech
Synthesizer
Statistical
NLG
Statistical
NLG
Annotated
Corpus
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Spoken Language Translation via Concepts
Speech
Recognizer
Speech
Recognizer
Speech Input
Natural
Language
Understanding
Natural
Language
Understanding
Natural
Concept
Generation
Natural
Concept
Generation
Speech Output
Speech
Synthesizer
Speech
Synthesizer
Natural
Word
Generation
Natural
Word
Generation
Natural Language Generation
Statistical Concept-based Machine Translation
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Concept-based Speech Translation
� Language-independent representation of intended
meanings
� Parsed from source language
� Organized in a language-dependent tree-structure
� Comparable to interlingua
� More flexible meaning preservation
� Wider sentence coverage
� Easier portability between different domains
� Design and selection of concepts
� Generation of concepts
ConceptsConcepts
MeritsMerits
ChallengesChallenges
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Natural Concept Generation (NCG)
� Correct set of concepts in target language
� Appropriate order of concepts in target language
� Statistical model-based generation
� Trained on Maximum-Entropy models
� Design of generation procedure
� Generation of concept sequences
� Transformation of semantic parse tree
� Selection of features
Purpose
Approaches
Challenges
7“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Statistical NCG on Sequence Level
QUERY PRON WEAPONPOSSESS
QUERYPRON WEAPONPOSSESS
English
Chinese
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Statistical NCG on Sequence Level
C1 C2 CM…
SnS1 …S2
Source C
Target S Sn+1
( )( )
( )∑∏
∏
∈
−−
−
=
Vs k
sscsfg
k
k
sscsfg
k
nnmnnmk
nnmk
sscsp1
1
,,,,
,,,,
1,, v
v
α
α
kfv
: feature of concepts
g: binary test function
kα : probability weight corresponding to feature kfv
( ) ( ) =
= −−
otherwise
sscsfifsscsfg nnmknnmk
0
,,,1,,,, 1
1
vv
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Statistical NCG on Sequence Level (Cont.)
( )
= ∏=
−∈
+
M
m
nnmVs
n sscsps1
11 ,,maxargGeneration
Select the concept candidate with highest probability:
C1 C2 CM…
S1 Sn+1…S2
Source C
Target S
START10 == −ss
SN…
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Model Training by Maximizing Entropy
( )( )
( )∑∏
∏
∈
−−
−
=
Vs k
sscsfg
k
k
sscsfg
k
nnmnnmk
nnmk
sscsp1
1
,,,,
,,,,
1,, v
v
α
α
( )[ ]∑∑∑= ∈
−=L
l qs m
nnmk
l
sscsp1
1,,logmaxargα
α
{ }LlqQ l ≤≤= 1, : total set of concept sequences
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Structural Concept Sequence Generation
Traverse the semantic parse tree in a bottom-up left-to-right breath-first
mode
Traverse the semantic parse tree in a bottom-up left-to-right breath-first
mode
For each un-processed concept unit on a parse tree, generate an optimal
concept unit in target language via the procedure
For each un-processed concept unit on a parse tree, generate an optimal
concept unit in target language via the procedure
Repeat until all units in the parse tree in the source language are processed Repeat until all units in the parse tree in the source language are processed
!S!
ADV ACTION-VERB PLACE
swiftness go-away place
!S!
ACTION-VERB BE ADV
go-away art place swiftness
leave the building quickly赶快赶快赶快赶快 离开离开离开离开 大楼大楼大楼大楼
12“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Feature Selection in Maximum-Entropy-
based Statistical NCG
Baseline
Features
Baseline
Features
Augmented
Features on
Parallel Corpora
Augmented
Features on
Parallel Corpora
C1 C2 CM…
SnS1 …S2
Source C
Target S SN…
( ) ( )kkkk
k sscsf 101
4 ,,, −+=v
( ) ( )kkkkk
k ssccsf 10101
5 ,,,, −++=v
� new features derived from both source language and target language
� Trained on parallel tree-bank
� Strengthen the link between source language and target language
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Conciseness vs. Informativity of Concepts
ConcisenessConciseness
InformativityInformativity
• Define minimum number of distinct concepts
• Reduce labor-extensive, time-consuming
annotation process
• Improve NLU parsing
• Define concepts as informative as possible
• Concept generation largely relies on the
sufficient information provided by each
concept
• Improve NCG
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Examples of NCG with too Concise Concepts
WHQ SUBJECT
What did you eat yesterday
AUX ACTION TIME
WHQSUBJECT
你你你你 昨天昨天昨天昨天 吃了吃了吃了吃了 什么什么什么什么
ACTIONTIME
�
WHQ SUBJECT
Where did you eat yesterday
AUX ACTION TIME
WHQSUBJECT
你你你你 昨天昨天昨天昨天 吃吃吃吃 在哪里在哪里在哪里在哪里
ACTIONTIME
�
� Two input English sentences with SAME set and order of concepts generate two
DIFFERENT concept sequences
� The concept WHQ is too concise that it is not informative enough to discriminate
the different generation behavior between (WHQ, what) and (WHQ, where)
� Features of and not helpful( ) ( )kkkk
k sscsf 101
4 ,,, −+=v ( ) ( )kkkkk
k ssccsf 10101
5 ,,,, −++=v
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Using both Concept & Word Information
WHQ SUBJECT
What did you eat yesterday
AUX ACTION TIME
WHQSUBJECT
你你你你 昨天昨天昨天昨天 吃了吃了吃了吃了 什么什么什么什么
ACTIONTIME
WHQ SUBJECT
Where did you eat yesterday
AUX ACTION TIME
WHQSUBJECT
你你你你 昨天昨天昨天昨天 吃吃吃吃 在哪里在哪里在哪里在哪里
ACTIONTIME
Concept information only
WHQ-what SUBJECT
What did you eat yesterday
AUX ACTION TIME
WHQ-whatSUBJECT
你你你你 昨天昨天昨天昨天 吃了吃了吃了吃了 什么什么什么什么
ACTIONTIME
WHQ-where SUBJECT
Where did you eat yesterday
AUX ACTION TIME
WHQ-whereSUBJECT
你你你你 昨天昨天昨天昨天 在哪里在哪里在哪里在哪里 吃的吃的吃的吃的
ACTIONTIME
�
�
�
�
Concept & Word information
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Features using both Concept & Word Information
( )( )( )
( )( )∑∏
∏
∈
−++−++
−++
=
Vs k
sswwccsfg
k
k
sswwccsfg
k
nnmmmmnnmmmmk
nnmmmmk
sswwccsp111
7
1117
,,,,,,,
,,,,,,,
111 ,,,,, v
v
α
α
( )[ ]∑ ∑ ∑= ∈
−
=−++=
L
l qs
M
m
nnmmmmk
l
sswwccsp1
1
1
111 ,,,,,logmaxargα
α
Optimized on parallel treebank: { }LlvuQQ ll ≤≤= 1,
Concept Sequence:
Word Sequence:
{ }McccC ,,, 11 L=
{ }MwwwW ,,, 21 L=
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Multiple Feature Selection
ProblemProblem
StrategyStrategy
� Sparser data because of higher dimensional features
� Additional sets of features in ME-based concept generation
� Multiple sets of features represent context information in
both the source and the target language at different levels
ExampleExample Feature A:
Feature B:
( )( )
( )( )
( )( )
( )( )
∑∑ ∑
∏∑
∏
∏∑
∏
= ∈
−
=
∈
∈
+
=
−++
−++
−+
−+
L
l qs
M
m
k
sswwccsfg
k
Vs
k
sswwccsfg
k
k
ssccsfg
k
Vs
k
ssccsfg
k
k
l
nnmmmmkk
nnmmmmkk
nnmmkk
nnmmkk
1
1
1
,,,,,,,
,,,,,,,
,,,,,
,,,,,
1117
1117
115
115
log
log
maxarg
v
v
v
v
α
α
α
α
αα
( ) ( )kkkkk
k ssccsf 10101
5 ,,,, −++=v
( ) ( )kkkkkkk
k sswwccsf 1010101
7 ,,,,,, −+++=v
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Experimental Setup
3000 Vocabulary size
medical and force protectionDomain
10,000 annotated parallel sentencesCorpora
68Size of Concept Set
English – Chinese (Mandarin)Language Pair
statistical interlingua-based
speech translationMT Method
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Experiments on ME-based Statistical NCG
DescriptionDescription� Evaluate on primary concept sequences that represents the
top-layer concepts in a semantic parser tree
� Concept sequences containing only one concept are removed
as they are easy to generate
� Specific set of parallel concept sequences that contain the
same set of concepts in both languages
� 5600 concept sequences are selected, 80% for training and
20% for testing
� Random partitioning of training and test set for 100 times
� Average error rates were recorded
� Worst-case test: sequences appear in the training corpus are
not allowed to appear in the test corpus
� Normal-case test: sequences appear in the training corpus
may appear in the test corpus
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
ME-NCG Experiments with Forward Models
0.7% / 0.4%
0.7% / 0.4%
6.2% / 3.5%
14.0% / 8.8%
Training set
(SER / CER)
20.2% / 13.1%+ concept-word
features
17.4% / 11.4%+ multiple feature
selection
21.7% / 14.1%+ feature on parallel
corpora
28.0% / 18.9%
Test set
(SER / CER)
Baseline NCG with
basic feature
NCG Methods
� A concept sequence is considered to have an error during measurement of sequence error rate if one or more errors occur in this sequence
� Concept error rate, on the other hand, evaluates concept errors in concept sequences such as substitution, deletion and insertion
( )4
kfv
( )5
kfv
( )7
kfv
( ) ( )( ) ( )475
kkk fffvvv
+
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
ME-NCG Experiments with Forward-
Backward Models
0.5% / 0.3%
0.5% / 0.3%
5.7% / 3.2%
9.1% / 5.5%
Training set
(SER / CER)
17.7% / 11.5%+ concept-word
features
15.8% / 10.4%+ multiple feature
selection
17.8% / 11.6%+ feature on parallel
corpora
24.4% / 16.4%
Test set
(SER / CER)
Baseline NCG with
basic feature
NCG Methods
( )4
kfv
( )5
kfv
( )7
kfv
( ) ( )( ) ( )475
kkk fffvvv
+
“On Feature Selection in Maximum Entropy Approach to Statistical Concept-based Speech-to-Speech Translation,” IWSLT, Kyoto, Japan, 2004
Experiment on Statistical Interlingua-based S2S
0.437
0.536
0.4890.469Speech-to-Text
0.578 0.605Text-to-Text
Translation Methods
Bleu metric (proposed by Kishore et. al.) measures MT performance
by evaluating n-gram accuracy with a brevity penalty