1+1 Nationa' Library Bibliothèque nationale du Canada Acquisitions and Direction des acquisitions et Bibliographie services Branch des services bibliographiques 395 Wellmglon Slrecl 395. rue Wcnington onaw•. Onl.no Onaw. (Onl.no) K1AON4 KIAON4 NOTICE AVIS The quality of this microform is heavily dependent upon the quality of the original thesis submitted for microfilming. Every effort has been made to ensure the highest quality of reproduction possible. If pages are missing, contact the university which granted the degree. Sorne pages may have indistinct print especially if the original pages were typed with a poor typewriter ribbon or if the university sent us an inferior photocopy. Reproduction in full or in part of this microform is governed by the Canadian Copyright Act, R.S.C. 1970, c. C-30, and subsequent amendments. Canada La qualité de cette microforme dépend grandement de la qualité de la thèse soumise au microfilmage. Nous avons tout fait pour assurer une qualité supérieure de reproduction. S'il manque des pages, veuillez communiquer avec l'université qui a conféré le grade. La qualité d'impression de certaines pages peut laisser à désirer, surtout si les pages originales ont été dactylographiées à l'aide d'un ruban usé ou si l'université nous a fait parvenir une photocopie de qualité inférieure. La reproducticn, même partielle, de cette microforme est soumise à la Loi canadienne sur le droit d'auteur, SRC 1970, c. C-30, et ses amendements subséquents.
Transcript
1+1 Nationa' LibraryolCanacJ~
Bibliothèque nationaledu Canada
Acquisitions and Direction des acquisitions etBibliographie services Branch des services bibliographiques
395 Wellmglon Slrecl 395. rue Wcningtononaw•. Onl.no Onaw. (Onl.no)K1AON4 KIAON4
NOTICE AVIS
The quality of this microform isheavily dependent upon thequality of the original thesissubmitted for microfilming.Every effort has been made toensure the highest quality ofreproduction possible.
If pages are missing, contact theuniversity which granted thedegree.
Sorne pages may have indistinctprint especially if the originalpages were typed with a poortypewriter ribbon or if theuniversity sent us an inferiorphotocopy.
Reproduction in full or in part ofthis microform is governed bythe Canadian Copyright Act,R.S.C. 1970, c. C-30, andsubsequent amendments.
Canada
La qualité de cette microformedépend grandement de la qualitéde la thèse soumise aumicrofilmage. Nous avons toutfait pour assurer une qualitésupérieure de reproduction.
S'il manque des pages, veuillezcommuniquer avec l'universitéqui a conféré le grade.
La qualité d'impression decertaines pages peut laisser àdésirer, surtout si les pagesoriginales ont étédactylographiées à l'aide d'unruban usé ou si l'université nousa fait parvenir une photocopie dequalité inférieure.
La reproducticn, même partielle,de cette microforme est soumiseà la Loi canadienne sur le droitd'auteur, SRC 1970, c. C-30, etses amendements subséquents.
•
••
Improvement of Accoustic ModelsIn Automatic Speech Recognition
Systems
Rafah Aboul-Hosn.School Of Computer Science.
McGill University.Montreal,Canada.
August 23, 1995
A Thesis Submitted to the Faculty of Graduate Studiesand Research in Partial Fulfillment of the Requirements
for the Degree of Masters In Computer Science.
@1995 Raiah Aboul-Hosn
1+1 National Libraryof Canada
BibliothèQue nationaledu Canada
Acquisitions and Direction des acquisitions etBibliographie Services Branch des services bibliographiques
395 Wellington Sueet 395, rue WellingtonOU.wa, Ontario OUawa (Ontario)K1AON4 K1AON4
The author has granted anirrevocable non-exclusive licenceallowing the National Library ofCanada to reproduce, loan,distribute or sell copies ofhisjher thesis by any means andin any form or format, makingthis thesis available to interestedpersons.
The author retains ownership ofthe copyright in hisjher thesis.Neither the thesis nor substantialextracts trom it may be printed orotherwise reproduced withouthisjher permission.
L'auteur a accordé une licenceirrévocable et non exclusivepermettant à la Bibliothèquenationale du Canada dereproduire, prêter, distribuer ouvendre des copies de sa thèsede quelque manière et sousquelque forme que ce soit pourmettre des exemplaires de cettethèse à la disposition despersonnes intéressées.
L'auteur conserve la propriété dudroit d'auteur qui protège sathèse. Ni la thèse ni des extraitssubstantiels de celle-ci nedoivent être imprimés ouautrement reproduits sans sonautorisation.
ISBN 0-612-12153-4
Canada
•
•
Abstract
This thesis explores the use of efficient acoustic modeling techniques to improvethe performance of automatic speech recognition (A5R) systems. The principalidea behind this study b that the prouunciation of a word is not only affectedby the variability of the speaker and the environment, but largely by the wordsthat precede and foUow it. Bence, to accuratcly represent a language, one shouldmodcl the sounds in contex/ with other sounds. Furthermore, due to the largeamount of modcls produced when every sound is represented in every context itcau appear in, one needs to use a elus/_ring teclmique by which sounds of similarproperties are grouped together so as to limit the number of models needed. Theaim of this research is two fold: the first is to explore the effects of using contextdependent modcls on the performance of an ASR system, the second is to combinethe context dependent models pertaining to a specifie sound in a complex structureto produce a context independent modcl containing contextual information. Twosuch complex structures are designed aud their performance is tested.
Résumé
Le sujet de cette thèse est l'amélioration de la performance d'un système automatique de la reconaissance de la parole (RAP) par l'utilisation des techniquesefficaces pour la modélisation acoustique. L'idèe principale de cette étude estque la prononciation d'un mot n'est pas seuleument influencée par le locuteur etl'environnement. mais surtout par les mots qui le precèdent et ceux qui le suivent.Par conséquence, pour pouvoir bien représenter une langue, cn doit représenterles sons dans leurs contextes. Malheureusement, le nombre de modèles qu'on obtient si on associe un modèle a chaque contexte est trop grand, ce qui rend lesystème inefficace. Aflll de réduire le nombre de modèles requis, on utilise destechniques de regroupement des modèles contextuels. Le but de ce recherche estpremièrement d'étudier l'effet des modèles conte."(tuels sur la performance d'unsystème automatique pour la reconaissance de la parole et deuxièment d'intégrerles modèles contextuels appartenant a un son dans des structures complèxes. Deuxstructures sont ainsi dé"elopées et leur effet sur la performance d'un système esté''a\ué.
•
•
Acknowledgement
1 would like to thank myadvisor Dr. Renato DeMori, whose help and guidance helped me greatly through out my research period.
1 would also like to extend my appreciating and gratitude to all the members of the Speech Group at the School Of Computer Science At McGill forall their heplful hints and comments.
Special thanks to Michael Galler and Charles Snow, my two mentors andfriends, for ail their patience and guidance.
,
•
•
Contents
1 Introduction1.1 Applications of Speech Recognition .
1.1.1 Telecommunication...............1.1.1.1 Automating Sorne Operator Services1.1.1.2 Accessing Information Over the Telephone.
3.2.2.1 Fast Fourier Transform .3.2.3 Discrete vs Continuous Models
ii
1222456
910101214151616li1920
22222425262831
•'~ .
CONTENTS
3.3 Statistical Approach to RecClgnition ...3.3.1 Acoustic Moueling Using Hr-.Il\ls .
3.3.1.1 Markov Chain .....3.3.1.2 Hidden Markov Models .3.3.1.3 Parameters of an HMM .3.3.1.4 Structure of an HMM ..3.3.1.5 Types of HMMs .....
3.3.2 Using HMMs for Training and Recogn:tion .3.3.2.1 Overview of Training .3.3.2.2 Overview of Recognition .
ii:
333435363i3940424243
•
4 Training and Recognition Algorithms 444.1 Introduction........................ 444.2 The Fundamental Problems for HMM Design ..... 454.3 Problem I:Calculating P(O 1.\) • . . . . . . . . . . . . 46
4.3.1 Basic computation 464.3.2 The Forward-Backward Algorithm . 4i
4,4 Problem 2:Finding An Optimal Path . . . . . . . . . . 514.4.1 The Viterbi Algorithm . . . . . . . . . . . . . . 514,4.2 Recognition Using the Viterbi Algorithm . . . . 524,01.3 The Viterbi Bearn Search Algo~ithm 54
4.5 Problem 3:Estimating the Parameters of an HMM . . . 564.5.1 Maximum Likelihood Estimation ;"Iethod. . . . 564.5.2 MLE Method with Multiple Sentences ..... 594.5.3 Estimating the Output Distributions of a CDHMM 62
6.5.2.1 Assembling and Pruning the Allophones 876.5.2.2 Clustering the Allophones . . . . . . . . . .. 87
6.5.3 Training and Recognition using CD Models 896.5.3.1 Initialization ..... . . . . . . . . . . . .. 896.5.3.2 Building the Phoneme Bigram Model . . 896.5.3.3 Recognition results . . . . . . . . . . . . 916.5.3.·1 Effect of Using Phonme Bigram Weights 92
Merging CD Models to Form CI Modcls ..... 936.6.1 CD ModeIs in Parallcl . . . . . . . . . . 94
6.6.1.1 Results . . . . . 956.6.2 A Form of State Clustering . . . . . 96
6.6.2.1 Results ..... . . . . . 97
•
; Conclusion and EUture Work 100
,,
•
List of Figures
2.1 Ovt:rview of the speech organs (ad"pted from [OGrady Si]) .. 12
•
3.1 Example of a simple ASR syst~m .3.2 Example of a Markov Model .3.3 A five state, left-to-right HMM model .
.1.1 Example of a trel1is, adapted from [DeMori J .4.2 Training with multiple observations .
6.1 Topology used in [Schwa S5] .6.2 Topology used in [Lee 89] .6.3 HMM topologies used .6.4 Parallel structure for the central phoneme ~aa~ ..6.5 Tied state structure for the central phoneme ~aa~ .
v
2435:19
5061
i9i9SO959i
•
List of Tables
2.1 List of the English Phonemcs .2.2 English Phonemcs and their corrcsponding featurcs
1118
•
6.1 Recognition using CI models . . . . . . . . . . . . . 8S6.2 Elfect of phoneme bigram weights on CI models . . 846.3 Clusters used for the CD models. . . . . . . . . . . 886,4 Recognition using CD models . . . . . . . . . . . . 916.5 Improvement in recognition using CD models 916.6 Elfect of phoneme bigram weights on CD models. . . . . . .. 926.ï Improvement in recognition using CD models with bigram
weights . . . . . . . . . . . . . . . . • . . . . . . . . . • . . .. 926.8 Recognition using allophoncs combined in a parallel manner . 966.9 Elfect of bigram weights on the parallel structured models .. 966.10 Recognition using state tying between allophoncs •.. 986.11 Elfect of J:,igram weights on the tied state models . 986.12 Overall rcsults using a phoneme bigram weight of 4 . . 99
,
VI
•
•
Chapter 1
Introduction
Although rcsearch in voice proccssing has been carried out for decadcs, be·
ginning 1990, the combination of powerful, inexpensive workstations and
improvcd a1gorithms for speech decoding, stimulated the use of speech tech·
nology in a variety of applications such as telecommunication, multimedia,
and a wide range of consumer products.
Nowadays, research in voice proccssing covers four main domains: VOlcr
synthesis, in which the machine transforms text into a synthcsized voice mes·
sage and transmits it, speech ruognition, in which the machine is capable of
~understanding~ the human voice and can thus act upon the speech it un·
derstood, speaker recognition, in which the machine identifies a person from
his/her voi!:e and finally natural language processing in which the machine
can understand the message uttered and can then translated it to anothcr
language.
1
• CH..\PTER 1. INTRODUCTION 2
•
The applications of automatic speech recognition or ASR systems arc nu
merous, but by far, the telephone industry remains th.. principle test bed and
implementation source of such systems (example BNR, AT&T, NYNEX).
The next section will review the main applications of speech recognition and
especially its usage in the telecommunication area.
1.1 Applications of Speech Recognition
1.1.1 Telecommunication
As the telephone industry evolves in the coming years to provide easy to use
and efficient products to its customers, several technologies will become more
and more valuable. One of the principal technologies is speech recognition. In
fact, in 1994, the projected voice processing market was over $1.5 billion, and
its estimatcd growth is around 30% per year [Wilpon 94]. Indeed, nowadays,
the principal telecommunication companies around the worId are using sorne
form of automatic speech recognition in their products. FoUowing are a few
samples of what is currently available on the market.
1.1.1.1 Autornating Sorne Operator Services
The task of automating part of the telephone conversation usually destined
to an operator, such as billing functions (coIIect caIIs, caIling cards, persan
to-person and biII~to-third-party) was first investigated by AT&T in 1985.
The driving force, at that time, was to reduce the workload of operators. by,
• CHAPTER 1. INTRODUCTION 3
•
providing a simple ASR system capable of accurately distinguishing words
from a small vocabulary and acting upon them. Early results in 1986 and
198; of such systems proved quite promising [Wilpon 88].
The first commercial product, called Automated Alternate Billing Services
or AABS, was put on the market in 1989. It was developed by Bell Northern
Research (BNR) and it consisted of a very simple speech recognizer capable
of very accurately recognizing the words yes/no in different pronunciations
[Lennig 90]. Combined with the Touch Tone service, the ASR system au
tomated the answers of customers when asked about accepting the collect
caUs, or when charging calls to a third number.
However, it was only in 1992 that a system capable of recognizing more
words was put on the market by AT&T. The system was called Voice Recog
nition Call Processing or VRCP and it fully automated the billing functions
described previously. This product uscd a technique called word spotting that
enables the system to recognize key words in a sentence. This meant that
the system could accurately recognize phrases such as:~ Oh, Please, could I
possibly make a col/cet cali to Mr Doe~, or ~ Hi, I would like to make a col/ect
calI please~, by keying on the word col/eet and ignoring the rest [LeeC 90b].
This technique provcd to be very succC5sful and according to [LeeC 90b] it
accurately recognizes 95% of all calls that can be automated.
This year, 1995, BNR released their Automated Directory Assistance
service ADAS which uses yet another technique called Flezible Vocabulary
Recognition of FVR [Lennig 92]. This method relies on entering the wor~s
• CHAPTER 1. INTRODUCTION 4
•
uttered by the customer as a sequence of subword units (like phonemes)
and then using pattern matching techniques to find the sequences of units
that matches the uttered sequence in a pronunciation dictionary. This way,
theoretically, thousands of words can be recognized. This service allows
a person to obtain telephone numbers via an ASR system using the FVR
technique, by first stating the language he/she would Iike to converse with,
then the systems asks the customer (in the selected language) to give the
city name, the system recognizes the city name and asks the caller which
listing category (residential or commercial) she/he needs, the listing is also
automatically recognized. In the case where the listing is local, the system
can further be used to recognize a selection of frequently asked listings. The
information gathered by the ADAS is then transmitted to the computer
terminal of a human operator who handles the final stages of the cali.
1.1.1.2 Accessing Information Over the Telephone
In 1981, NTT developed an Automatic Answer Network System of Electri
cal Requests, ANSER that is used to gather banking information (accounts
statements, balance, etc ..) via a voice processing system that combines both
speech recognition and voice synthesis [Wilpon 94]. The system is composed
of a 16 word [encan! and 10 Japanese digits and permits the customer to ask
questions about 600 Japanese banks spread across iO Japanese cities. The
system is also speaker independent and uses isolated word detection. It is
fully interactive, recognizing the customer's request and replying back. One
1A lexicon is use<! to contain the phonetic transcription oC the words in the vocabulary,,
• CHAPTER 1. INTRODUCTION 5
•
of the key advantages of the service is its ability to fully interact with rotary
dial phones as weil as Touch Tone.
Recently, BNR released another product. called StockTalk, that allows
customers to inquire about the stocks of companies listed on the NASDAQ,
Toronto and New York Stock Exchange. The ASR system used is speaker
independent, and uses subword detection. The caller is first asked to say
which stock exchange she/he requires, the system recognizes the narne and
then asks the person to say which stocks she/he wants to inquire about.
Then the information acquired is passed to Telerate (the computerized stock
quotation service) and the system gets the information needed, then the
logic module of the StockTalk parses the information and transforms it into
English text which is then synthesized and transmitted to the caller.
1.1.2 Consumer Products
Along with the telecommunication market. many other consumer products
are taking advantage of ASR systems. In rObert 94J, it is suggcsted that the
speech recognition consumer market has an average growth of 40% per year,
and that an estimated $2 billion dollars will be invcsted in speech technology
be the end of the dccade.
Already, numerous computer companies have incorporated sorne form of ASa
systems in their applications. Others have produced voice activated home
appliances such as VeR and TV remote controls..
In other areas, researchers are integrating speaker indellendent ASR systems
• CllAPTEfl J. INTIWDUCTlON
in f1ight sirnlllators and in air t.raffic cont.rol syst.ems [Gall 92J.
1.2 Motivation and Outline
6
•
The system described in t.his t.besis is a continuolt,;, ,;peakcr indcpendent,
autolllatic .<pcec}, recognition system whose "ultimate" goal is to be capable
of underst.anding continuous speecb from a speaker irrespective of bis/her
age, gender, sex, and tbe environment in whicb be/sbe is speaking (quiet or
noisy). This area of research has captured a lot on interest because of its vast
applications in industry and although tbe "ultimate" goal is still far fetched,
technological advances and more efficient techniques in speech are constantly
reducing the gap betwcen the perfect system and the current state of the art
in ASR syst.ems.
The moti\'ation behind tbe research conducted in this paper is the de
velopment of more efficient techniques to mode! the sounds of the language;
this is called acoustie modeIing and it will be fully described in the follow
ing chapters. Nowadays, the important improvements in the performance of
ASR systems are deliverd by improved acoustic modeling. The idea that the
pronunciation of a word is not only affected by the variability of the speaker
and tbe environment. but largcly by the words that precede and follow it,
bas led researcbers to model sounds in eontext with other sounds [Schwa 85]
[Lee 90b]. Furthermore, due to tbe large amoufit of models produced when
every sound is represented in every context it can appear in, researchers devel-
•
•
CHAPTER 1. INTRODUCTION
oped cluslcring lcchn'iqucs by which sounds of similar prop,·rt.ies at'<' gt'Ollllt'd
together 50 as 1.0 limit the number of moclds Ileeded [Ljol !),I] [Yollng !J,t]
[DeMori 9.5J. These two iclcas form the bases of t.he experilllent.s performed
in this thesis in which new approaches to acoustic n1CJdding and <'Ontext. dus
tering are investigated. These arc fully c1escribed iu chapter G.
Building efficient ASR systems is a complex task because of the interdisei
plinary nature of the speech problem. One can think of speech processing hy
machine as an amalgamation of many different 11c1c1s ranging from anatomy
which l'l'ovide insights on which organs the humans use to eommllnicat.e.
1.0 linguistics which describes the properties of the soumIs created, to en
gineering with which one can l'l'present the acoustic properties of sOllnds
and determine methods by which these properties can be extmcted from
the signal, 1.0 statistical analysis techniques which l'l'ovide the essencc of
recognition, and computer science with which ail the previous princip!e arc
combined in efficient algorithms 1.0 produce what is called automatic speech
recognition systems.
The material in this thesis is organized in ; chapters. The first t.hre"
chapters describe the main principles involved in the implementation of ASR
systems: chapter 2 gives an overview of speech generation in humans and
sorne linguistic backgr'lUnd, chapter 3 is divided into two main parts: the
first part describes how linguistic know!edge is combined 1.0 signal processing
techniques to extract perceptually meaningful parametcrs from the signal,
and the second part describes the statistica1 approach to recognition in which
• CHAPTER 1. INTRODUCTION 8
•
stochastic processes are used to model the sounds of a language. Chapter
4 gives a detailed description of the algorithms that implement recognition
and training using stochastic processes. Chapter 5 presents the main factors
which lead to the increase in performance of ASR systems.Chapter 6 describes
the experiments conducted and finally chapter ï concludes the thesis work.
•
•
Chapter 2
Overview of Speech
Generation and Phonetics
Understanding how humans communicate between each other and the prop
erties of the sounds they produce provide rcsearchers in this area with ideas
on how to simulate the human speech proccss by machine.
This chapter attempts to give sorne of the background theory neccssary
for ASR implementations. it is divided into two main parts: the first part
gives an overview of the stages the speech signal goes through until it is pro
nounced by the speaker, the second part describes sorne basic princip!es in
Iinguistics, mainly the physio!ogical aspects of speech production or articu
latory phonetics and the physical properties of sounds or acoustic phonetics.
9
• CHAPTER 2. SPEECH GENERATION AND PHONETICS 10
•
2.1 Overview of Human Speech Generation
As automatic speech recognition systems try to mimicspeech production and
perception of humans, in order to understand such systems, one needs to first
understand how humans use their brains and speech organs to communicate
between each other. During a conversation between two people, the speaker
first decidcs on what he/she wants to say in his/her brain, then chooscs
the words he/she would like to express his/her thoughts in along with the
loudncss and pitch of his/her voice. Next, the speaker's neurological system
rcsponsible for the muscle movements. tells the vocal cords when to vibrate
and informs the rcst of the speech organs of the positions they have to assume
in order to produce the sequence of words. Finally, the sentence is uttered,
the speech produced is in the form of air wavcs that travel to the listener's
ear where the inverse process takcs place: first the ear performs some spectral
analysis on the incoming signal, then the neurological system"extracts" the
features out of the signal coming from the ear, the brain then interprets these
ft'aturcs and finally the (istener understands the words.
2.2 Speech Production and Acoustic-Phonetics
Although humans can produce an infinite number of speech sounds or phones,
each language can be characterized by a fini te set of abstract Iinguistic
units called phonerres, table 2.1 gives an example of the English phonemes.
Phonemes provide a language with an alphabet of sounds from which ail
words pertaining to this language can be uniquely described.
• CHAPTER 2. SPEECH GENERATION t\ND PHONETICS
Phoneme Example Phoneme Example Phoneme Exampleiy heed 1 led t lotih bit r race k kickeh b~t y yet z aebraae had w wet v !Leryix ros~s er bird f [Iveax th~ en mutton th thingah mud m mom s ~IS
UW boot n noon sh shoeuh hood ng sin~ hh helpoy bQY d dad zh me~re
aw bou~h g go dx butterow hoed p pop el bottleao bought ch church sil ·aa hod jh judge epi ·ey bait dh then . ·ay hide b bob . ·
Table 2.1: List of the English Phonemes
11
•
Al/ophones describe a class of phones pertaining to a specific variant of a
phoneme. Due to the non discrete nature of the vocal tract, and its ability
to vary in many ways, an infinite number of phones can correspond to aspe
cific phoneme. There are numerous sources of variability: different people
have different pronunciation for the same phoneme, repeated pronunciations
of the same phoneme by the same speaker produces different phones, finally
phonemes vary depending on the context in which they appear in. The pro
nunciation of a phoneme is affected by the phoneme that precedes it and the
one that fol1ows it in a word, this effect is called coarticulation. Coarticu
lation is due to the fact that the articu1atory organs do not shift from one,
• CHAPTER 2. SPEECH GENERATION AND PHONETICS 12
position to the other abruptly, rather the transition is quite graduai and the
signal slowly changes from the characteristics of the previous sound to the
newone.
2.2.1 Physiology of the Speech System
Before reviewing the different classes of sound, it is important to know how
and where speech is generated in the human body. Fig 2.1 displays the speech
organs.
•Figure 2.1: Overview of the speech organs (adapted from (OGrady 8i))
pulled apart 50 there is no constriction as the air flo\\'s from the Inngs
to the trachea. In this case the speech signal consists of nois,' and is
aperiodic.
Whisper Soumis (such as bouse) these arc also unvoiced, and they occur
when the front portion of the vocal cords arc brought together and the
back portion are pulled apart.
Voiced Sounds (all vo\\'els are voiced, voiced consonants such vow), thcse
occur when the vocal cords are brought close together but arc not
completely closed. As the air from the lungs p""scs through the n1Ll'row
glottis, it causes the vocal cords to vibrate periodically, the rate of
vibration is referred to as the fundamcntal frcquency (Fa). /Iowevcr,
• CIIAPTER 2. SPEECH GENERATION AND PHONETICS 14
•
since both FO and the vocal tract shape change often, the signal is not
considered periodic but rather quasi-periodic.
Along with the classes described above, phonemes can be classified into
thlee additional classes: vowels, consonants and glides, manner of articula
tion, and place of articulation. Each of these classes will be described in the
following threc sections.
2.2.2 Vowels, Consonants and Glides
One can distinguish betwecn vowels and consonants based on articulation
and acoustic properties. Glides (such as wet, ~ou) on the other hand, have
common features with both vowels and consonants 1.
The first distinction that can be made between vowels and consonants
is the shape of the vocal tract during their pronunciation' vowels are ail
voiced which, as we saw, means that the vocal folds are close together but
not constrictcd; consonants can be voiced and unvoiced, and sorne of them
arc produccd when the vocal tract is momentarily blocked and then reopened
(such as \?Op). Vowels are also more sonorant than consonants, that is we
perceive them as louder and longer; this is a. result of the difference in artic
ulation.
Vowels are further divided into two classes, simple vowels in which the
\'owels doesn't show a noticeable change in quality when pronounced as in
s!:t. d~d, myg, and diphthongs which are vowels that exhibit a. change due
1Ref« to table 2.2 for the list of vowels. g1ides and consonants
• CHAPTER 2. SPEECH GENER..1TION AND PHONETICS 15
•
to the movement of the tongue away from the initial vowel towards a glidc
position as in boy,may.
Glidcs falls somewhere in between the two ether classes: they are pro
nounced as vowels but they either move quickly to another articulation as in
~et or \,!'et, or stop abruptly as in bo~ and no\!'.
Although glides are perceived by th. auditory system as quickly articulated
vowels, they act as consonants. Glides are sometimes referred to as semi
voweis or semi-consonants.
2.2.3 Manner of Articulation
Manner of articulation refers to the position of the glottis, lips, tongue, and
velum during phoneme production (refer to fig 2.1 of the speech organs).
For example, when the velum is lowered, air flows through the nostrils
producing nasaI sounds such as Done, or lIlaim; stops or plosives sounds, such
as pop and lIib, come about when the vocal tract is completely blocked for
a moment and then reopened so that the constrictrd air bursts out creat
ing this "explosive" sound; liquids, such as lama and roar, are like vowels,
however. in this case, the tongue is used as an obstruction in the oral tract
which causes air to deflect around the tip; fricatives, such as frog and yan,
are characterized by a continuous airllow through the mouth, but the vocal
cords are 50 close together that during their production, continuous noise is
produced; if the noise has a high amplitude, these sounds are called strident
/ricatives; when a stop precedes a fricative, the sound is called affricative as
• CHAPTER 2. SPEECH GENERATION AND PHONETICS 16
•
in church and iump.
Table 2.2 shows the english phonemes with their manner and place of artic
ulation.
2.2.4 Place of Articulation
The place oC articulation is considered one of the most important classifica·
tions Cor phonemes because it enables a finer distinction between the different
sounds. Although languages may share common voicing and manner of ar·
ticulation, the place of articulation varies largely.
Place of articulation is mostly associated with consonants because they use
a rclatively narrow constriction, however vowels can also be subdivided into
classes based on the tongue position as will be seen in subsequent sections.
2.2.4.1 Consonants
Eight regions in the vocal tract are associated with consonants production,
reCer to fig 2.1.
Labial: constriction occurs at the lip. If both lips are constricted, the sound
is called bilabia4 if the sound involves the lower lip and the upper teeth
is it reCerred to as labiodentaL
Dental: tip of the tongue touches the back of the incisor. If the tip protrudes
between the teeth the sound is called interclentaL
.4Iveolar: tip of the tongue approaches or touches the alveolar ridge (a small
ridge protruding from the behind the upper front teeth)•
• CHAPTER 2. SPEECH GENERATION AND PHONETICS
Palatal: the tongue blade constricts with the hard palate.
li
•
Velar: the tongue is close to the velum (50ft area towards the rear of the
roof of the mouth).
Uvular: tongue approaches or touches the uvula (f1eshy f1ap of tissue that
hangs from the velum).
Pharyngeal: the pharynx is constricted.
Glottal: vocal tract is either constricted or it is completely closed.
The place of articulation for the English consonants is shown in table 2.2.
2.2.4.2 Vowels
In vowels, variation in place of articulation is represented by different po
sitions in the tongue and !ips. The tongue can assume a combination of
heights and positions: low, mid, high and front, central. back. The first three
represent the height of the tongue while the last three represent its position.
The lips can be either rounded or unrounded (place of articulation for the
different vowels and diphthongs is presented in table 2.2).
,
•
•
CHAPTER 2. SPEECH GENERATION AND PHONETICS
Phonernes Voiced Manner of Place ofArticulation Articulation
iy yes vowel high front tenseih yes vowel high front laxey yes vowel rnid front tenseeh yes vowel rnid front laxae yes vowel low front tenseaa yes vowel low back laxao yes vowel rnid back lax roundedow yes vowel rnid back tense roundeduh yes vowel high back lax roundeduw yes vowel high back tense roundeder yes vowel rnid tense (retrofiex)ah yes vowel rnid back laxax yes vowel rnid lax (shwa)ay yes diphthong low back to high frontaw yes diphthong low back to high backoy yes diphthong rnid back to high fronty yes glide front unroundedw yes glide back rounded1 yes Iiquid a1veolarr yes liquid retrofiex
rn yes nasal labialn yes nasal a1veolarf no fricative labiodentalv yes fricative labiodentalth no fricative dentaldh yes fricative dentals no fricative a1veolar stridentz yes fricative a1veolar strident
sh no fricative palatal stridentzh yes fricative palatal stridenthh no fricative glottalp no stop labialb yes stop labialt no stop a1veolard yes stop a1veolark no stop velarg yes stop velarch no affricative a1veopalataljh yes affricative a1veopalatal
Table 2.2: Enl!lish Phonemes and their corresoondinl! features
18
• CHAPTER 2. SPEECH GENERATION AND PHONETICS
2.2.5 Acoustic-Phonetics
19
•
In the previous sections, phonemes were classified on an articulatory base, in
this section, they are differentiated based on their acoustic properties. The
aim in this section is to investigate the waveform and spectral properties of
each phoneme, and to assign to each one sorne cornmon acoustic aspects.
A signal can be represented in both time and frequency domains [Opp 89J.
Although the time domain representation encodes all the information needed,
it is often too hard to interpret because two sounds that may appear identical
to the auditory system might have two different time plots. Most acoustic
features of speech sounds are more apparent in the frequency domain, thus
the use of a wideband spectrogram for analysis. A spectrogram transforms
the time domain representation of a signal into its frequency domain, and
plots it in a three dimensional way (time vs frequency vs amplitude). It is
mostly used in speech to examine formant frequencies; duration of acoustic
segments and their periodicity.
Following is a brief overview of the main acoustic properties of phonemes.
These properties are believed to be the cues upon which the human auditory
systems distinguishes between sounds [OShaug 8iJ; however, although nec
essary, these properties are not sufficient to map the signal to a phonemic
string due to speaker and environment variabilities and the context in which
the phonemes appear in.
,
• CHAPTER 2. SPEECH GENERATION AND PHONETICS
2.2.5.1 Acoustic Properties of Phonemes
20
•
Vowels (simple and diphthongs) have usually the largest amp!itudeand longest
duration compared to other phonemes. As was discussed earlier, vowels cause
the vocal tract to vibrate in a quasi·periodic manner, this results in the en·
ergy being concentrated in spectral !ines at mul~iples of tr.e fundamental
frequency FO. Vowels are primarily distinguished by the location of the first
three formant frequencies, FI, F2, and F3. Usually, front vowels have high
F2 and F3, while mid vowels tend to show well separated and balanced loca
tions of formants, and finally the back vowels seem to have low FI and F2.
Glides and !iquids are very similar to vowels in that they are also sonorant
and produce periodic signals. Glides tend to be transient, with a steady
spectrum that has a shorter duration than vowels. Liquids have also very
similar spectra to the vowels, but they normally have lower amplitudes.
Nasals show a sharp change in the intensity and spectral features of a vowel,
due to the entry of air into the nasal cavity. They are characterized by reso
nances that are more highly damped than those of vowels.
Fricatives (and stops) have a very dilferent spectrum than the sonorants
mentioned above: they are aperiodic, less intense (because the constriction
of the vocal tract causes energy loss), and most of their energy is generally
concentrated in the high frequencies. Unvoiced fricatives are produced by
exciting the vocal tract by a steady air f10w which becomes turbulent at the
point of constriction. They exhibit a highpass spectrum and are shorter in
duration than fricative sounds. Voiced fricatives use two acoustic sources, a
periodic glottal source and the usual noise generated when the vocal tract is,,
• CHAPTER 2. SPEECH GENERATION AND PHONETICS 21
•
constricted. The noise amplitude varies between different voiced fricatives:
the non-strident fricatives (low noise component) show an almost periodie
signal and a spectrum similar to a weak version of glides, strident fricatives
on the other hand, show a large noise energy concentrated at high frequen.
CÎes.
Stops are highly influenced by the vowel that follows them 50 they are more
difficult to distinguish. Unlike all other classes of phonemes described 50 far,
stops are transient rather than a steady-state phenomena. They are usually
characterized by a long period of silence (during the constriction of airflow)
followed by a sudden increase in amplitude (when the vocal tract is reopened
and air flows out). When air is released, turbulent noise (referred to as lrica
tion) continues at the opening of the constriction for about 10-40 ms. On
average, unvoiced stops have a longer frication than voiced stops.
One has to mention of course, that none of these observations holds
true all the time. Spectral analysis shows a large variation among different
speakers and there is generally an overlap betwecn formants across different
pronunciations [Rabi 93], these factors, accompanicd with the coarticulation
effect2complicate the task of automatically identifying phonemes from their
spectral properties.
2Coarticulation causes aIIophone5 ta have different spectra (rom the phone theyrepresent ..:
•
•
Chapter 3
Architecture of A Speech
Recognition System
3.1 Introduction
This chapter explores the foundations of automatic speech recognition sys
tems (ASR). As was discussed previously, implementing such systems goes
beyond computer science, it involves principles from a varlety of fields such
as anatomy, linguistics, signal processing, pattern recognition etc... . The
following sections describe sorne of the building blocks of ASR systems and
the main principles underlying their implementation.
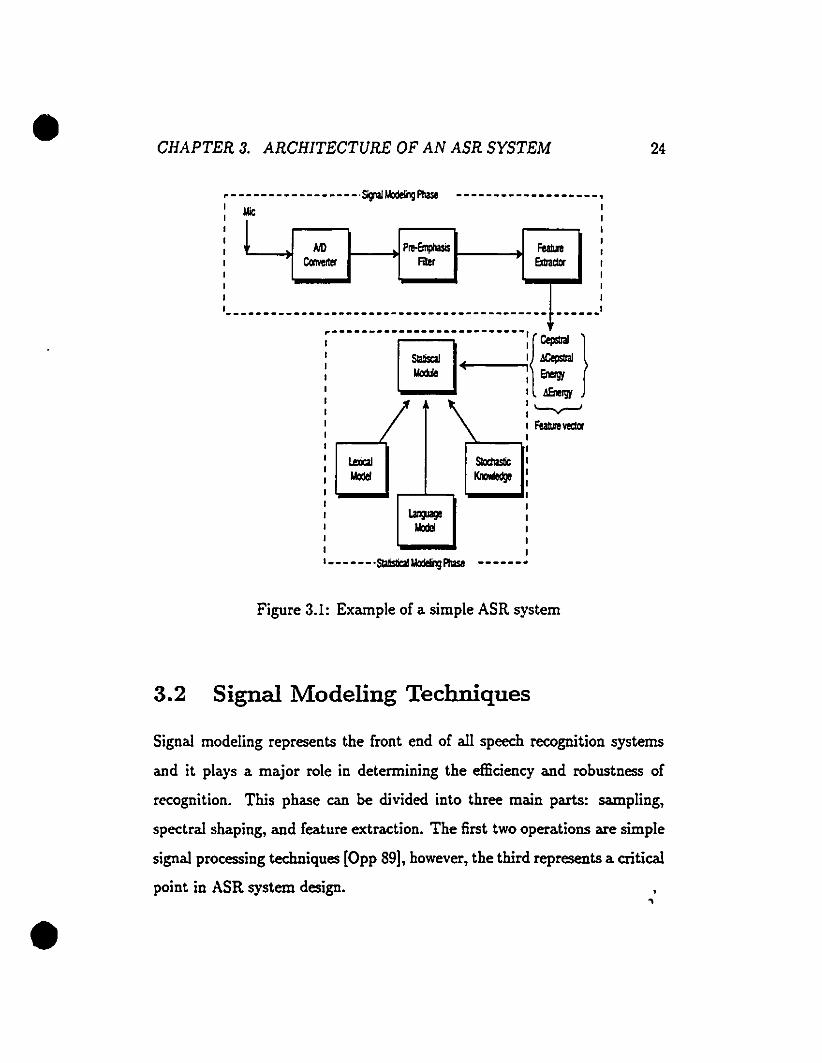
Speech recognition by machine undergoes two main phases as can be seen
from fig 3.1: the signal modeling phase in which the analogue signal is con
vertcd into a digital form, then fcd to the feature extractor that uses spectral
22
• CHAPTER 3. ARCHITECTURE OF AN ASR SYSTEM 23
•
analysis techniques to produce a parametric representation of the signal, and
the recognition phase in which statistical modeling and search techniques are
used to hypothesize the most likely word that was initial1y pronounced.
The a.im in the first phase is to extract from the input signal, features that
are similar to those used by the human auditory system to distinguish be
tween different sounds. In the second phase, the a.im is that given these
features, to determine the most likely sequence of words that was spoken.
Hence, recognition relies heavily on the feature vector produced during the
first phase: the more perceptually meaningful the features, the better the
recognition.
Chapter 1 reviewed the first building block of ASR design which is speech
generation by humans and the acoustical properties of sounds. The first part
of this chapter explores techniques by which this linguistic knowledge can
be combined to spectral analysis algorithms to produce a meaningful feature
vector. The second part reviews the statistical modeling approa.ch to speech
recognition. It is important to note here that the sections that fol1ow describe
the techniques used on Roger our ASR system at McGill University, however
there are alternative methods in both extra.cting the features (as in the use of
Linear Prediction Coding [OShaug 87)) and in recognizing the words (as in
the use of Artificial Intelligence strategies or different pattern classification
Table 6.2: Effect of phoneme bigram weights on CI modeis
the role of the bigram weights: they increase the importance of the transi·
tiona! probabilities, so the viterbi measure becomes pW(ph).L(obs).
Four different weights are tested on the best performing CI mo<l~Is ob·
tained previously. From the results of table 6.2, one can see that, as the
bigram weight increases, the number of insertions decreases whiIe the number
of deietions increases. This is due to the fact that, a larger weight imposes
more constraints on the a priori phoneme sequence probabiIity. This uIti
mately prevents unseen phonemes sequences from being produced resulting
in a lower number of insertions but also prevents, in sorne instances, correct
phonemes from appearing resuiting in a higher number of deletions. A good
tradcoff between the two was found using a weight of 4, which results in a
1.;% increase in UA. It is important to note here that since the PC depends
only on the number of deletions and substitution, it normally decreases (due
to the increase in deIetions) as the weight increases, indeed. with a weight of
4, the PC goes down by 0.63%.
•
• CHAPTER 6. EXPF.RIMENTS \VITH CD MODELS
6.5 Designing Contest Dependent Models
6.5.1 Clustering Techniques
85
•
The first step in designing CO models is to decide on the clustering strategy.
Many strategies are available in the literature. In [Lee 90b]. two methods
are used and compared: the first is based on an agglomerative c/uslering
technique, the second on decision lrees. In the first method. a COHMM is
produced for every single ccmtext, so initially. each cluster contains only one
allophone. Then an entropy distance measure is used to test the similarity
between each pair of clusters pertaining to a phone and clusters that are
~closest~ to each CJther are merged together. The procedure is repeatcd until
a certain convergence criteria is met. Although this method minimizes the
entropy, its main disadvantage is that if the t.raining and test sentences are
different, then during recognition, the new allophones encountered had no
CD models associated with them, so CI models had to also be used, which
decreased the performance of the system. In the second method, clusters are
generated by using a decision tree in which the root node contains all the
allophones pertaining to a phoneme, then the tree is traversed top to bottom,
and at each level, node splitting is done using a binary question about sorne
context of the allophone. The splitting method is based on the same entropy
distance measure used in the first algorithm, the questions are chosen by an
expert to capture the different classes of contextual classes. The leaves of the
tree contain the generalized allophone. This method eliminated the problem
of the agglomerative clustering, because if a new allophone is encountered
• CHAPTER 6. EXPERIMENTS WITH CD MODELS 86
•
during recognition, then the tree is traversed and the cluster to which this
allophone belongs to is found. [Bahl 91] also uses binary decision trees to
determine the clusters by asking a question about the context at every level.
However, in his experiments, the context of a phoneme is not only defined
by the adjacent left and right phonemes but by severa.1 other phonemes pre
ceding and following the central phone. In [LeeC 91] a unit reduction role is
used to create context dependent units. The method is based on the number
of tokens of a particular unit that appear in the training data set. [Taki 92]
uses the successive splitting algorithm discussed earlier to optimize phoneme
classes. In that approach a simple HMM model consisting initially of one
state and two pdfs grows iteratively into a more complex model in which
contexts are clustered and integrated. Other researchers avoid the clustering
problem by integrating alileft and right contexts of a certain phoneme inside
the model structure of the phoneme in question [Jouv 94a] [Young 94]; this
is equivalent to tying the states of different allophoncs pertaining to the sa.me
phone.
In the experiments conducted in this thesis a form of unit reduction rule
is first performed to prune the allophones gathered from the TIMIT training
database, acoustic-phonetic rea.soning is then used to cluster the remaining
allophones. The fol1owing steps describe in details how the CD models were
produced.
• CHAPTER 6. EXPERIMENTS WITH CD MODELS
6.5.2 Creating and Clustering the Allophones
6.5.2.1 Assembling and Pruning the Allophones
87
•
The first step in this experiment was to gather all the possible allophones from
the training database of the TIMIT corpus. Since all the training sentences
of TIMIT are phonetically labelled, this made the task very simple. Once
all the allophones are gathered, the unit reduction rule is used to count the
number of times each allophone is encountered in the training set. This is an
important step because if there aren't enough samples for a certain allophone,
the CO model representing it will be poorly estimated and this will hinder
the performance of the system. The threshold for the unit reduction rule was
set to 10, so any allophone that didn't appear at least 10 times in the training
set was eliminated. From the 21444 different allophones encountered in the
3679 training sentences, only 582 allophones were thus kept; these formed
the set of CD models. However, because of the pruning, CI models had
to be added to the set of CD models to replace those allophones that were
eliminated. The total number of models used was 635: 582 CD models and
53 CI models.
6.5.2.2 Clustering the Allophones
The set of c1usters used is shown in table 6.3, the first 5 c1usters which
represent the vowels were adapted from [Gall 92), the consonants c1usters
were formed by hand, using the similarities between the acoustic properties
of certain consonants to group them together. The c1usters Wert. used for
bath the left and right contexts of the 582 allophones•
•
•
CHAPTER 6. EXPERIMENTS WITH CD MODELS
~ Cluster No. 1 Phonemes
1 ao aa ay aw ax ah2 ix ih iy ey3 ae er4 uwuhoyow5 eh6 v fhhjh m b p7 dhthchndt8 zsnggk9 zh sh10 r11 112 w13 y14 bel del gel kel pel qel tel sil epi15 el16 dx17 en
Table 6.3: Clusters used for the CD modcls
ss
• CHAPTER 6. EXPERIMENTS WITH CD MODELS
6.5.3 Training and Recognition using CD Models
6.5.3.1 Initialization
89
•
The CO models were initialized using the CI models produced in the first
stage. Each allophone was initially a duplicate of its central phoneme. The
models were then trained using the 3679 sentences from the TIMIT train
database. Since an HMM now represented triphones, the labelling of the
phrases had to change: each three phone segments were grouped together
to form a single segment representing a triphonc. The first and last phones
were padded with silences.
6.5.3.2 Building the Phoneme Bigram Model
In order to enhance the performance of the CD models, a phoneme bigrame
model incorporating the 582 CD and 53 CI models had to be designed.
Four criteria are used to inter-connect the models, however, as the grammar
is quite envolved, it will be explained by following an example:
Suppose an allophone model A is represented by clB-aa-cl6 where cl8 refers
to cluster B to whieh the left contezt of A belongs to, cl6 refers to cluster 6 to
which the right contezt of A belongs to, and aa is the central phoneme and
suppose it belongs to cluster 1 represented by cll.
Suppose also that clB=(z,s), cl6=(v,f) and cll=(ao,ah), then:
Criteria #1 Connect A to all allophones whose left context be10ngs to
cll and whose central phoneme belongs ta cl6, iff such allophone(s)
model(s) exist(s). 50 in this example connections would he made as
• CHAPTER 6. EXPERIMENTS WITH CD MODELS
follows:
el8-aa-cl6 - cll-v-X with probability P(v 1 aa) (X is any eluster)
c18-aa-cl6 - cll-f-X with probability PU 1aa)
90
•
Criteria #2 Connect A to all CI models that belong to its right c1uster el6.
So in this example connections would be made as follows:
el8-aa-cl6 - v with probability P(v 1aa)
cl8-aa-c16 - f with probability PU 1aa)
Citeria #3 Connect to A all CI models that belong to its left c1uster clB.
So in this example connections would be made as follows:
:: _ c18-aa-cl6 with probability P(aa 1::)
s _ cl8-aa-el6 with probability P(aa 1s)
Criteria #4 Connect all CI models together using the bigram probabilities
used for the CI models
The fini te state network thus formed contained in total 14220 transitions.
The chain had one entry state, through the silence CI model and multiple
exit states represented by the silence CI model and all CD models that had
the silence as their central phoneme and the c1uster 14 (to which the silence
belongs to) as their right context.
• CHAPTER 6. EXPERIMENTS W1TH CD MODELS 91
6.5.3.3 Recognition results
The recognition was performed alter each round of training. As the CI modelswere already well estimated, it only took 3 iterations for the CO model 1.0rcach the maximum likelihood the results are given in table 6.4
1 60.51 68.012 61.04 68.993 61.01 69.1i
~ UA(%) 1 PC(%) ~
Table 6.4: Recognition using CD models
UA(%) 60.33 61.01 0.68PC(%) 64.63 69.1i 4.54
~ 1 CI Models 1 CD Models 1 Improvement ~
Table 6.5: Improvement in recognition using CD models
As the results of table 6.5 indicate, recognition using CD models produced
considerably less deletions and substitutions (thus the 4.54% increase in the
PC), however the number of insertions remained relatively the same, so the
UA only increased by 0.68%. These results lead 1.0 believe that the difference
in order between the a priori phoneme sequence probability and the output
observation sequence was somehow large so in order to improve the UA, one
has 1.0 impose a weight on the language probability. The results of this test
are shown in the next section.
•
• CHAPTER 6. EXPERIMENTS WITH CD MODELS 92
6.5.3.4 Effect of Using Phoneme Bigram Weights
The same bigram weights were used on the best performing CD modcls (thoscof iteration 3) and indeed, the UA improved by 2.83% when a bigram wcightof 4 is used, and by 3048% when the weight was set to 6. These results arcpresented in tables 6.6 and 6.i.
Table 6.10: Recognition using state tying between a1lophones
1 62.66 66.86 308 593
2 63.96 66.96 220 685
4 64.'16 66.43 144 825
~ Weight 1 UA(%) 1 PC(%) 1 #Ins 1 #Oel ~
Table 6.11: Elfect of bigram weights on the tied state models
•
• CIlAPTER 6. EXPERIMENTS WITIi CD MODELS 99
•
•
CI Models CO Modcls CD Model Parallel Struc. Tied State
Pruned Struct.
UA(%) 62.03 64.86 64.i9 63.9i 64.46
PC(%) 64.00 68.4i 68.44 66.23 66.43
Table 6.12: Overall results using a phoneme bigram weight of 4
The rcsults of table 6.12 suggest that by trading context dependent mod
els with context independent models containing contextual information, the
performance of the system doesn 't depreciate significantly. In fact, the per
formance cornes very close to that of the CD models with only a 0.33%
dilference in unit accuracy between the tied state models and the pruned CD
modcls. In addition, the ne\V CI models are formed with only a smaIl subset
of ali the aliophoncsj one could then conclude that if alI, or most of, the
aliophoncs can be efficiently included in the CI structure, the gap between
the two performances should be significantly less.
The parallei structure formed from the CD models did not prove to be as
efficient as the tied sate structure. The performance of the system degraded
by 0.83% in unit accuracy when these models were used. One explanation
would be that the number of aIlophones was too low and not representative
of ail the contexts. Futhermore, since the search aIgorithm was forced to
choose one of the three paths and follow it ali the way until the end, then if
the wrong context was chosen at the beginning, the aIgorithm was not given
a chance to move to a ~ closer~ context at a later state, hence the decrease
•
•
•
CHAPTER 6. EXPERUI'IENTS \VITIl CD MODELS
in performance.
100
•
•
•
Chapter 7
Conclusion and Future Work
As the popularity of ASR systems continues to expand, the demand for a
high level of accuracy increases. This thesis explored one of the important
factors in improved ASR design which is the use of context dependent models
to represent the phonemes of the languages. Previous work (as in [Schwa 85J
and [Lee 90b]) has already demonstrated that the use of CD models provides
better accuracy rates. Indeed, our experiments have shown that the CD
models show ;;.ppr,~ximately a 4% incrcase in performance compared to the
CI models. The key point in designing such models is allophone c1ustering.
There arc many methods already developed to c1uster the phonemes, they
range from implementing iterative optimization algorithms such as [Taki 92J,
to using some form of agglomerative c1ustering technique as in [Lee 90b] and
[Young 94J, to building decision trees as in [Bah! 91], and finally to using
phonetic reasoning as was done in this thesis. Another consideration is the
trainability of these models: building robust CD models means training on
101
• CHAPTER ï. CONCLUSION AND FUTURE WORI{ 102
•
•
as many context-specific words as possible. However, there is always a lim
itation on the number of training sets available. Perhaps one can count the
number of training samples associated with each Gaussian (per modc1) and
disregard distributions which have a count below a certain threshold, this
will guarantee that the training data available can properly re-estimate the
parameters of the CO models. Finally, the CD models should be general
enough so as to produce good recognition rates even for words that arc not
present in the training database.
This thesis aIso explored sorne innovative techniques to merge CD modc1s
into complex CI structures. The aim of this study was to reduce both the
number of models needed and the complexity of the grammar used to connect
them together. By having CI models containing sorne contextual information,
one can both decrease the computation complexity while maintaing a good
accuracy. In the initial stages of this study, it was demonstrated that merging
aIl the aIlophones pertaining to one phoneme did not reduce the complexity, it
rather increased it, but when a small subset is used, and the viterbi algorithm
is aIlowed to go from one context to another at different stages of the search,
within the sarne models, the results were very promising. In fact, the tied
structure models were only 0.33% less accurate than the pruned CD models.
In futur work, one can perhaps gradually increment the number of allophones
in each complex structure until a certain computation complexity threshold
is attained.
•
•
•
Bibliography
[App 89] Applebaum T.H, Hanson B.A , Enhancing the Descrimination ofSpeaker Independent Hidden Markov Models with Corrective Training,Proceedings of the IEEE International Conference on Acoustics Speech,and Signal Processing, 1989, pp.302-30S.
[Bah186) Bahl L.R, Brown P.F, deSouza P.V, Mercer R.L, Nahamoo D.,Maximum Mutual Information Estimation of Hidden Markov Parameters for Speech Recognition, Proceedings of the IEEE International Conference on Acoustics Speech, and Signal Processing, 1986, pp.49-S2.
[Bahl91) Bahl L.R, deSouza P.V, Gopalakrishnan P.S, Nahamoo D.,Pecheriy M.A, Desision Trees for Phonological Rules in ContinuousSpeech, Proceedings of the IEEE International Conference on AcousticsSpeech, and Signal Processing, 1991, pp.18S-188.
[Bau 72) Baum L.E and associates, An Inequality adn Assoiciated Maximization Technique in Statistical Estimation of Probabilistic Functionsof Markov Processes, Inequalities, 1972, pp.1-8.
[Casa 90) Casacuberta F., Vidal E., Mas B., Rulot H., Learning the Strcuture of HMM's through Grammatical Inference Techniques, Proceedingsof the IEEE International Conference on Acoustics Speech, and SignalProcessing, 1990, pp.71ï-ï20.
[Chow 90) Chow Y.L, Maximum Mutual Information Estimation of HMMParameters for Continuous Speech Recogntion using the N-Best Algorithm, Proceedings of the IEEE International Conference on AcousticsSpeech, and Signal Processing, 1990, pp.ï01-ï04.
103
• BIBLIOGRAPHY 104
•
•
[DeMori 93] De Mori R, Flammia G., Speaker-Indcpendcnt Consonant Classification in Continuous Speech with Di..<tinctive Features and NeuralNetworks, Acoustical Society of America, Dec 1993.
[DeMori 94] De Mori D, Brugnara F., Giuliani D., ParaUd Hidden MarkovModels for Speech Recognition, Istituto per la Ricerca Scientifica e Technologica, Pante de Povo, Trento, Italy, Apr 1994.
[DeMori] De Mori, R., Snow, C., Galler, M., Speech Recognition and Understanding, School of Computer Science, McGill University.
[DeMori 95] De Mori, R., Brugnara F., Ga!ler M., Search and LearningStrategies for Improving Hidden Markov Modr.ls, Computer Speech andLanguage, Vol 9, Apr 1995, pp.107-121.
[Eph 89] Ephraim Y., Dembo A., Rabiner L.R, A Minimum DiscriminationInformation Approach for Hidden Markov Models, IEEE 'i'ransactionson Information Theory, Vol 35, No.5, Sept 89, pp.1001-1013.
[Furu 86] Furui S., Speaker Independent Isolated Word Recognition UsingDynamic Features of Speech Recognition Proceedings of the IEEE International Conference on Acoustics Speech, and Signal Proccssing, Vol34. No. 1, Feb 1986, pp.52-59.
[Gall 92] Galler M., Improving Phoneme Models for Speaker-IndependentAutomatic Speech Recognition Master Thcsis, Faculty of Science, McGillUniversity, 1992.
[Gauv 91] Gauvain, J.L., Haton, J.P., Pierrel, J-M, Perennou, G., Caclen, J.,Reconnaissance Automatic de la Parole, DUNOD informatique, BordasParis, 1991.
[Gauv 95] Gauvain, J.L., Lamel L., A Phone-Based Approach To NonLinguistic Speech Feature Identification, Computer Speech and Language, Vol 9, Jan 1995, pp.87-103.
[Haeb 92J Haeb-Umbach R., Ney H., Linear Discriminant Analysis for lmproved Large Vocabulary Continuous Speech Recognition, IEEE Transactions, 1992, Vol 1, pp.13-16.
[Haeb 93J Haeb-Umbach R., GelIer D., Ney H., lmprovements in ConnectedDigit Recognition Using Linear Discriminant Analysis and Mixture Densities, IEEE Transactions, 1993, Vol 2, pp.239-242.
[Huang 89] Huang, X.D., Jack M.A., Semi-Continous Markov Models forSpeech Signais, Readings in Speech Recognition, Academie Press, 1989.
[Jouv 94a] Jouvet D, Dautremont M, Gossart A., Comparaison des Multimodeles et des Densites Multigaussiennes pour la Reconaissance de laParole par Modeles de Markov, ICLSP 1994, YOKOHAMA, pp.153-158.
[Jouv 94b] Jouvet D, Bartkova K, Stouff A., Structure of Al/ophonic Models and Reliable Estimation of the Contextual Parameters, ICLSP 1994,YOKOHAMA, pp.147-150.
[Komo 87] Komo J.J, Random Signal Analysis in Engineering Systems, Academie Press, 1987.
[Lee 89J Lee K.F, Hon H.W, Speaker lndependent Phone Recognition UsingHidden Markov Models, Proceedings of the IEEE International Conference on Acoustics Speech, and Signal Processing, Vol 37, No.11, Nov1989, pp. 1641-1646.
[Lee 90a] Lee K.F, Hon H.W, Reddy R., An Overview of the SPHINX SpeechRecognition System, IEEE Transactions of Acoustics, Speech and SignalProcessing, Vol 38., No. 1, Jan 1990, pp.35-44.
[Lee 90b] Lee K.F, Hayamizu S., Hon H.W., Huang C., Swartz J. Wiede R.,Al/ophone C/ustering for Continuous Speech Recognition, Proceedingsof the IEEE International Conference on Acoustics Speech, and SignalProcessing, 1990, pp.749-752.
• BIBLIOGRAPHY lOG
•
•
[LeeC 89] Lee C.H, Rabiner R.L, A Frame Synchronous Network Scarch Algorithm For Connected Word Recognition, Proceedings of the IEEEInternational Conference on Acoustics Speech, and Signal Processing,Vo137, No.n, Nov 1989, pp.1G49-1658.
[LeeC 90] Lee C.H, Rabiner R.L, Pieraccini R., Wilpon J.G, Acoustic Modeling for Large VocabulanJ Speech Recogntion, Computer Speech andLanguage, Vol 4, No.2, April 1990, pp.127-165.
[LeeC 90b] Lee C.H, Rabiner R.L, Goldman E.R., Wilpon J.G, AutomaticRecognition of Keywords in Unconstrained Speech using Hidden MarkovModels, IEEE Transactions of Acoustic, Speech and Signal Proccssing,Nov. 1990, pp.1870-1878.
[LeeC 91] Lee C.H, Giachin E., Rabiner R.L, Pieraccini R., Rosenberg A.E.,Improved Acoustic Modelling for Speaker Independent Large VocabulanJContinuous Speech Recognition, Proceedings of the IEEE InternationalConference on Acoustics Speech, and Signal Proccssing, 1991, pp.161164.
[Lennig 90] Lennig M., Putting Speech Recognition to Work in the TelephoneNetwork, Computer, August 1990, pp.35-41.
[Lennig 92] Lennig M., Automated Bilingual Directory Assistance Trial inBell Canada, Proceedings of the lst IEEE Workshop on Interactive VoiceTechnology for Telecommunication Applications, N.J, Oct. 1992.
[Lip 82] Liporace L.A, Maximum Likelihood Estimation for MultiflarariateObservations of Markov Sources, IEEE Transactions on InformationTheory, Vol IT-28, No.5, Sept 1982, pp.729-734.
[Ljol 94] Ljolje A., High Accuracy Phone Recognition Using Context Clustering and Quasi-Tiphone Models, Computer Speech and Language, Vol 8,Academie Press, 1994, pp.129-151.
[Makh 94] Makhoul J., Schwartz R., State of the Art in Continuous SpeechRecognition, Voice Communication Between Hurnans and Machines, National Academy Press, Washington D.C., 1994, pp.165-198.
• BIBLIOGR.1PHY 107
•
•
[Mokb 94] Mokbel C., Pachès·Leal, Jouvet D, Monnè J., Compensation ofTelephone Line Effects For Robust Speech Recognition, ICLSP 1994,YOKOHAMA, pp.161-164.
[Ney 88] Ney H., Noll A., Phoneme Modeling Using Continuous MixtureDensities, Proceedings of the IEEE International Conference on Acoustics Speech, and Signal Processing, 1988, pp.437-440.
[Norm 91J Normandin,Y, Hidden Markov Models, Maximum Mutual Infor.mation Estimation, and the Speech Recognition Problem, PhD Thesis,Department of Electrial Engineering, McGill University, 1991.
rObert 94J Oberteuffer J.A, Commercial Applications of Speech InterfaceTechnology:An Industry at the Threshold, Voice Communication betweenHumans and Machine, National Academy Press, 1994, pp.347-369.
[OGrady 87J O'Grady, Dobrobolsky, Contemporary Linguistic Analysis, AnIntroduction, Copp Clark Pittman, 1987.
[Opp 89] Oppenheim, A.V, Schafer, R.W., Discrete Time Signal Processing,NJ:Prentice Hall, Englewood Cliffs, 1989.
[OShaug 87J O'Shaughnessy D., Speech Communication, Human and Machine, Addison Wesley, 1987.
[Place 93] Placeway P.R, Schwartz P., Fung P., Nguyen L., The Estimation ofPowerfuI Language Models from Small and Large Corpora, Proceedingsof the IEEE International Conference on Acoustics Speech, and SignalProcessing, Minneapolis, April 1993, pp.33-36.
[Pic 90] Picone, J.W., Continuous Speech Recognition Using Hidden MarkovModels, IEEE ASSP Magazine, July 1993, pp.26-41.
[Pic 93J Picone, J.W., Signal Modeling Techniques in Speech Recognition,IEEE Procedings, Vol 81 NO 9, Sept 1993, pp.1215-1247.
[Roe 94] Roe B.D., Wilpon J.G., Voice Communication Between Humansand Machines, National Academy Press, Washington D.C., 1994.
[Rabi 78] Rabiner, L., Schafer, R.W., Digital Processing of Speech SignaisNJ:Prentice Hall, Englewood Cliffs, 1978.
• BIBLIOGRAPHY 108
•
•
[Rabi 88] Rabiner, L., Mathematical Foundation of Hidden Markov Models,NATO ASR Series, Vol F46, Berlin Heidelberg ,1988, pp.183-205.
[Rabi 89] Rabiner, L., A Tutorial on Hidden Markov Models and Selee!edApplications in Speech Recognition, Proceedings of the IEEE, Vol 77,No.2, Feb 1989, pp.257-285.
[Schwa 85] Schwartz R., Chow Y., Kimball O., Roucos S., Krasner M.,Makhoul J., Context-Dependent Modeling for Acoustic-Phone!ic Recognition of Continuous Speech, Procecdings of the IEEE InternationalConference on Acoustics Speech, and Signal Proccssing, April 1985,pp.1205-1208.
[Sun 95] Sun D., Deng L., Analysis of Acoustic-Phonetic Vllriations In Fluent Speech Using TIMIT, Proceedings of the IEEE International Conference on Acoustics Speech, and Signal Processing, 1995, pp.201-204.
[Taki 92] Takami J., Sagayama S., A Successive State Splitting Algorithmfor Efficient Al/ophone Modeling, Proceedings of the IEEE InternationalConference on Acoustics Speech, and Signal Processing, 1992, pp.15731576.
[VAl 88] Van Alphen, P., Pois, L.C.W., A Fast Algorithm for FIR Filterbank,Speech 88, 7th FASE Symp, Edimburgh, Book2, 1988, pp.677-682.
(VAI89] Van Alphen, P., Pois, L.C.W., A Real-Time FIR-Based filterbank,Proceedings Eurospeech, Paris, 1989, pp.621-624.
[VAl 91] Van Alphen, P., Van Bergem, D.R., Hidden Markov Models andTheir Application in Speech Recognition, IEEE Proccedings, Vol 79 No.1,April 1991, pp.1-25.
(Vite 67] Viterbi A.J, Error Bounds for Convolutional Codes and an Asymptotical/y Optimum Decoding Algorithm, IEEE Transactions on Information Theory, Vol 13, No.2, April 1967, pp.260-269.
• BIBLIOGRAPHY 109
•
•
[Wilpon 88J Wilpon J.G, DeMarco D., Mikkilinemi P.R., Isolated WordRecognition over the DDD Telephone Network, Proceedings of the IEEEInternational Conference on Acoustics Speech, and Signal Processing,New York, April 1988, pp.55-58.
[Wilpon 94J Wilpon J.G, Application of Voice Processing Technology inTelecommunication, Voice Communication between Humans and Machine, National Academy Press, 1994, pp.280-309.
[Young 92] Young S.J, The General Use of Tying in Phoneme-Based HMMSpeech Recogni::ers, Proceedings of the IEEE International Conferenceon Acoustics Speech, and Signal Processing, 1992, pp.I-569-5i2.
[Young 94J Young S.J., Woodland P.C., State Clustering in Hidden MarkovModel-Based Continous Speech Recognition, Computer Speech and Language, Vol 8, Oct 1994, pp.369-383.