26
Online Aggregation Joe Hellerstein UC Berkeley
| Date post: | 17-Dec-2015 |
| Category: |
Documents |
| Upload: | tobias-george |
| View: | 217 times |
| Download: | 1 times |

Online Aggregation
Joe Hellerstein
UC Berkeley

Online Aggregation: Motivation
Select AVG(grade) from ENROLL;
• A “fancy” interface:
+Query Results
AVG3.262574342

A Better Approach
• Don’t process in batch! Online aggregation:

Isn’t This Just Sampling?
• Yes– we need values to arrive in random order– “confidence intervals” similar to sampling work
• … and No!– stopping condition set on the fly!– statistical techniques are more sophisticated– can handle GROUP BY w/o a priori
knowledge...
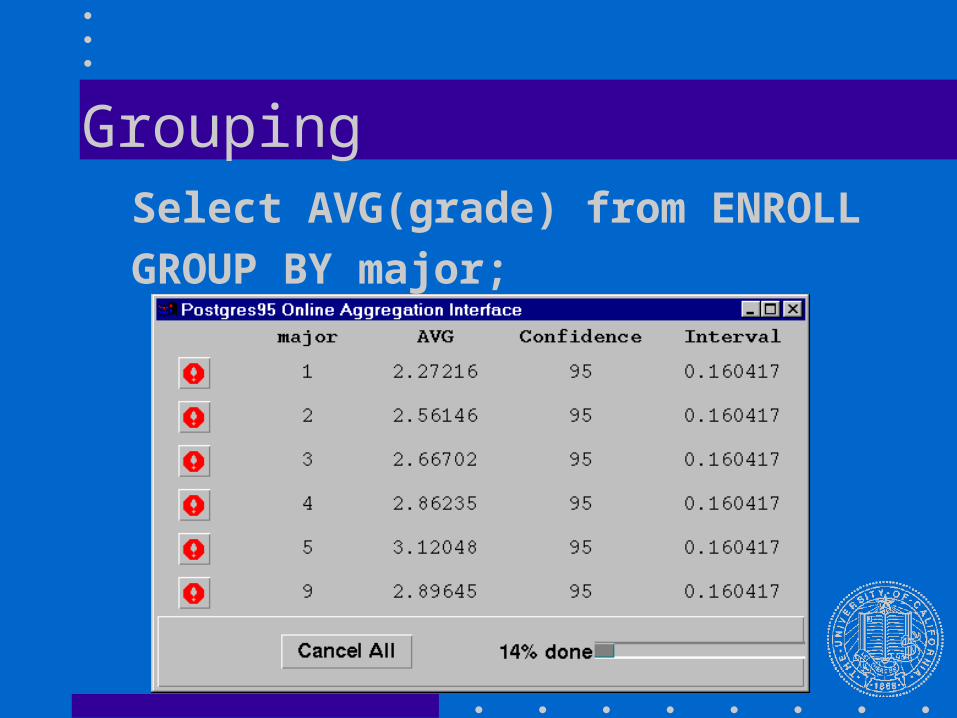
Grouping Select AVG(grade) from ENROLL
GROUP BY major;

Requirements
• Usability– Continuous output
• non-blocking query plans
– time/precision control
– fairness/partiality
• Performance– time to accuracy
– time to completion
– pacing

Fairness/Partiality• Speed controls!

Applications• Large-scale Data Analysis
– Online drill-down/roll-up/CUBE– Visualization tools– Data mining– Distributed requests
• Generally:– Any long-running activity should be visualized and
controllable on line.– Accuracy rarely critical for non-lookups

A Naïve Approach
Select onln_avg(grade) from ENROLL;• Can do it in Illustra/Informix today!• But...
– No grouping– Can’t meet performance & usability needs:
• no guarantee of continuous output– optimized for completion time!
• no guarantee of fairness (or control over partiality)• no control over pacing

Random Access to Data• Heap Scan
– OK if clustering uncorrelated to agg & grouping attrs
• Index Scan– can scan an index on attrs uncorrelated to agg or
grouping (or index on random())
• Sampling:– could introduce new sampling access methods (e.g.
Olken’s work)

Group By & Distinct
• Fair, Non-Blocking Group By/Distinct– Can’t sort! Must use hash-based techniques
• sorting blocks
• sorting is unfair
– Hybrid hashing! • especially for duplicate elimination.
– “Hybrid Cache” even better.

Index Striding
• For fair Group By:– want random tuple from Group 1, random tuple
from Group 2, ...– Idea: Index gives tuples from a single group.– Sol’n: one access method opens many cursors in
index, one per group. Fetch round-robin.– Can control speed by weighting the schedule– Gives fairness/partiality, info/speed match!
(Next step: “heap stride”)

Join Algorithms
• Non-Blocking Joins– no sorting!– merge join OK, but watch “interesting orders”!– hybrid hash not great– symmetric “pipeline” hash [Wilschut/Apers 91]– nested loops always good, can be too slow– optimization...?

Query Optimization
• 2 components in cost function:– dead time (td ): time spent doing “invisible” work
-- tax this at a high rate!
– output time (to ): time spent producing output
– this will do a lot automagically!
• User control vs. performance?– can use competition (e.g., a la Rdb)
• “interesting” (i.e. bad!) ordering

Extended Aggregate Functions
• Aggs need to return tuples in the middle of processing– add a 4th “current estimate” function
• open, iterate, estimate, close
– sometimes like close function (AVG), sometimes not (COUNT)
– aggregation code needs to spit this out to the front-end

API• Current API uses built-in methods
– button-press = query invocation• e.g., select StopGroup(val);• High overhead, need to know internals.• Very flexible. Easy to code!
– Estimates returned as tuples • no distinction between estimates and final answer• OK?
– A general API for running status?

Pacing
• Inter-tuple speed is critical!!

Statistical Issues
• Confidence Intervals for SQL aggs– given an estimate, probability p that we’re within of
the right answer
• 3 types of estimates Conservative (Hoeffding’s inequality) Large-Sample (Central Limit Theorems) Deterministic
Previous work + new results from Peter Haas

Initial Implementation
• prototype in PostgreSQL (a/k/a Postgres95, a/k/a PG-Lite)– aggs with running output– hash-based grouping, dup elimination– index striding– optimizer tweaks– “API” hacks and a simple UI

Pacing studySelect AVG(grade), Interval(0.99) From ENROLL;
Normal plan

Access Methods, Big GroupSelect AVG(grade), Interval(0.99) From ENROLLGROUP BY college;
College L: 925K/1.5 Mtuples

Access Methods, Small Group
Surprise!!!
Cost of API call?
Select AVG(grade), Interval(0.99) From ENROLLGROUP BY college;
College S: 15K/1.5 Mtuples
Future Work
• Better UI– simple example: histograms w/error bars– online data visualization (Tioga DataSplash)
• data viz = “graphical” aggregate
• sampled points, or sampled wavelet coefficients?
• great for panning, zooming
• Nested Queries– Tie-ins with AI’s “anytime algorithms”
Future Work II
• Control w/o Indices– Heap Striding = do multiple scans
• optimization 1: fast scans can pass hints to slow
• optimization 2: “piggyback” scans via buffering
• big payoff for complex queries
• Checkpointing/continuation– also continuous data streams

Future Work III
• Sample Tracking– important for financial auditing, statistical
quality control– cached views, RID-lists, logical views
• More stats:– non-standard aggs– simultaneous confidence intervals– allow for slop in cardinality estimation

Summary• DSS/OLAP users very demanding!
– “speed of thought” performance required– only choices: precomputation or estimation– for estimation, need to provide control and steady,
useful feedback• puts user in the driver’s seat• takes some performance burden away from system
– Requires significant backend support• but well worth the effort• runs the “impossible” queries

















