25
Online Analytical Processing By Samraiz Tejani – 30 Pawan Patil - 24
| Date post: | 18-Jul-2015 |
| Category: |
Education |
| Upload: | samraiz-tejani |
| View: | 67 times |
| Download: | 0 times |

Online Analytical Processing
By Samraiz Tejani – 30
Pawan Patil - 24

What is Data Mining?
• Data mining is the process of finding patterns in a given data set. These patterns can often provide meaningful and insightful data to whoever is interested in that data.

What is Data Warehousing?
A data warehouse is a subject-oriented, integrated, time-variant and non-volatile collection of data in support of management's decision making process.

• Subject-Oriented: A data warehouse can be used to analyse a particular subject area. For example, "sales" can be a particular subject.
• Integrated: A data warehouse integrates data from multiple data sources. For example, source A and source B may have different ways of identifying a product, but in a data warehouse, there will be only a single way of identifying a product.
• Time-Variant: Historical data is kept in a data warehouse. For example, one can retrieve data from 3 months, 6 months, 12 months, or even older data from a data warehouse. This contrasts with a transactions system, where often only the most recent data is kept. For example, a transaction system may hold the most recent address of a customer, where a data warehouse can hold all addresses associated with a customer.
• Non-volatile: Once data is in the data warehouse, it will not change. So, historical data in a data warehouse should never be altered.

Example
Facebook basically gathers all of your data – your friends, your likes, who you stalk, etc – and then stores that data into one central repository.
Even though Facebook most likely stores your friends, your likes, etc, in separate databases, they do want to take the most relevant and important information and put it into one central aggregated database.
Why would they want to do this? For many reasons – they want to make sure that you see the most relevant ads that you’re most likely to click on, they want to make sure that the friends that they suggest are the most relevant to you, etc.

• A Data Warehouse Delivers Enhanced Business Intelligence
• A Data Warehouse Saves Time
• A Data Warehouse Enhances Data Quality and Consistency
• A Data Warehouse Provides Historical Intelligence
• A Data Warehouse Generates a High ROI

What is OLAP?
• OLAP (online analytical processing) is computer processing that enables a user to easily and selectively extract and view data from different points of view.

Online Transaction Processing vs Online Analytical Processing
• OLTP (On-line Transaction Processing)
It is characterized by a large number of short on-line
transactions (INSERT, UPDATE, DELETE).
The main emphasis for OLTP systems is put on very
fast query processing, maintaining data integrity in
multi-access environments and an effectiveness
measured by number of transactions per second.
In OLTP database there is detailed and current data,
and schema used to store transactional databases is
the entity model
• OLAP (On-line Analytical Processing)
It is characterized by relatively low volume of
transactions.
Queries are often very complex and involve
aggregations.
For OLAP systems a response time is an effectiveness
measure.
OLAP applications are widely used by Data Mining
techniques.
In OLAP database there is aggregated, historical data,
stored in multi-dimensional schemas

Example
OLTP-style transaction:
• Sam, from Mumbai just bought a box of tomatoes, charge his account, deliver the tomatoes from our Belapur warehouse; decrease our inventory of tomatoes from that warehouse
OLAP-style transaction:
• How many cases of tomatoes
were sold in all Belapur
warehouses in the years 2000
and 2001?

OLAP cube
• An OLAP cube is an array of data understood in terms of its 0 or more dimensions. OLAP is an acronym for online analytical processing.
• OLAP is a computer-based technique for analysing business data in the search for business intelligence.

Operations
• To Call for the specific data the user use the following Operations:
1. Slicing
2. Dicing
3. Drilling
4. Pivot

Slicing
Slicing is done by selecting along one dimension.

Dicing
Dicing is done by selecting along two or three dimension.

Drilling
• Drill up:
Drills with switching from a detailed to an aggregated level
within same classification hierarchy.
Example : week > month > quarter>yearly
• Drill down:
Switching from an aggregated to a more detailed level within
the same classification hierarchy.
Example : yearly>quarter>month>week

Pivot or Rotate
• A visualization operation which rotates the data access in order to provide an alternative representation.

MOLAP, ROLAP AND HOLAP
MOLAP (Multidimensional OLAP )
This is the more traditional way of OLAP analysis. In MOLAP, data is stored in a multidimensional cube. The storage is not in the relational database, but in proprietary formats.
Advantages:
Excellent performance: MOLAP cubes are built for fast data retrieval, and are optimal for slicing and dicing operations.
Can perform complex calculations: All calculations have been pre-generated when the cube is created. Hence, complex calculations are not only doable, but they return quickly.
Disadvantages:
Limited in the amount of data it can handle: Because all calculations are performed when the cube is built, it is not possible to include a large amount of data in the cube itself. This is not to say that the data in the cube cannot be derivedfrom a large amount of data. Indeed, this is possible. But in this case, only summary-level information will be included in the cube itself.
Requires additional investment: Cube technology are often proprietary and do not already exist in the organization. Therefore, to adopt MOLAP technology, chances are additional investments in human and capital resources are needed.

ROLAP(Relational OLAP)
This methodology relies on manipulating the data stored in the relational database to give the appearance of traditional OLAP's slicing and dicing functionality. In essence, each action of slicing and dicing is equivalent to adding a "WHERE" clause in the SQL statement.
Advantages:
Can handle large amounts of data: The data size limitation of ROLAP technology is the limitation on data size of the underlying relational database. In other words, ROLAP itself places no limitation on data amount.
Can leverage functionalities inherent in the relational database: Often, relational database already comes with a host of functionalities. ROLAP technologies, since they sit on top of the relational database, can therefore leverage these functionalities.
Disadvantages:
Performance can be slow: Because each ROLAP report is essentially a SQL query (or multiple SQL queries) in the relational database, the query time can be long if the underlying data size is large.
Limited by SQL functionalities: Because ROLAP technology mainly relies on generating SQL statements to query the relational database, and SQL statements do not fit all needs (for example, it is difficult to perform complex calculations using SQL), ROLAP technologies are therefore traditionally limited by what SQL can do. ROLAP vendors have mitigated this risk by building into the tool out-of-the-box complex functions as well as the ability to allow users to define their own functions.

HOLAP(Hybrid OLAP)
HOLAP technologies attempt to combine the advantages of MOLAP and ROLAP. For summary-type information, HOLAP leverages cube technology for faster performance. When detail information is needed, HOLAP can "drill through" from the cube into the underlying relational data.

Types of Schemas in Data warehousing
There are four types of schemas are available in data warehouse.
Star Schema:
A star schema is the one in which a central fact table is surrounded by denormalized dimensional tables. A star schema can be simple or complex. A simple star schema consists of one fact table where as a complex star schema have more than one fact table.

Snow Flake Schema:
A snow flake schema is an enhancement of star schema by adding additional dimensions. Snow flake schema are useful when there are low cardinality attributes in the dimensions.
Fact Constellation Schema:
The dimensions in this schema are segregated into independent dimensions based on the levels of hierarchy. For example, if geography has five levels of hierarchy like teritary, region, country, state and city; constellation schema would have five dimensions instead of one.
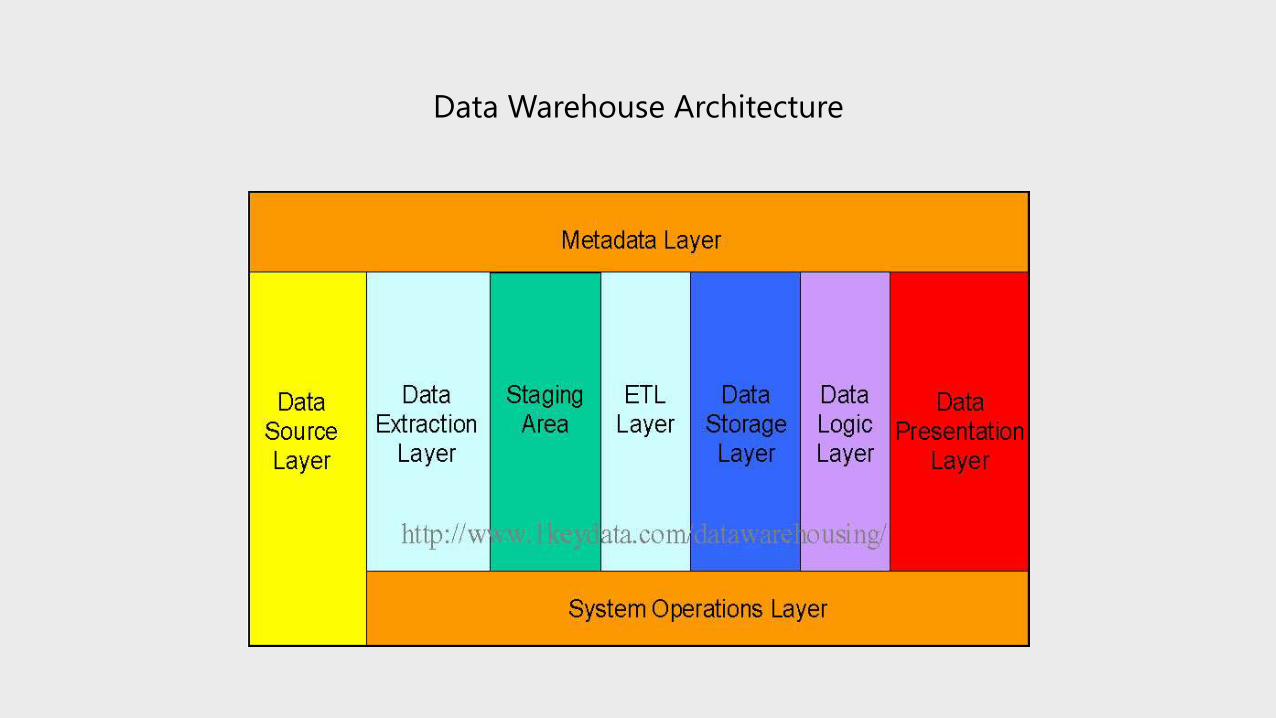
Data Warehouse Architecture

Data Source Layer
This represents the different data sources that feed data into the data warehouse. The data source can be of any format -- plain
text file, relational database, other types of database, Excel file, etc., can all act as a data source.
Many different types of data can be a data source:
• Operations -- such as sales data, HR data, product data, inventory data, marketing data, systems data.
• Web server logs with user browsing data.
• Internal market research data.
• Third-party data, such as census data, demographics data, or survey data.
All these data sources together form the Data Source Layer.
Data Extraction Layer
Data gets pulled from the data source into the data warehouse system. There is likely some minimal data cleansing, but there is
unlikely any major data transformation.
Staging Area
This is where data sits prior to being scrubbed and transformed into a data warehouse / data mart. Having one common area
makes it easier for subsequent data processing / integration.

ETL Layer
This is where data gains its "intelligence", as logic is applied to transform the data from a transactional nature to an
analytical nature. This layer is also where data cleansing happens. The ETL design phase is often the most time-consuming
phase in a data warehousing project, and an ETL tool is often used in this layer.
Data Storage Layer
This is where the transformed and cleansed data sit. Based on scope and functionality, 3 types of entities can be found
here: data warehouse, data mart, and operational data store (ODS). In any given system, you may have just one of the
three, two of the three, or all three types.
Data Logic Layer
This is where business rules are stored. Business rules stored here do not affect the underlying data transformation rules,
but do affect what the report looks like.

Data Presentation Layer
This refers to the information that reaches the users. This can be in a form of a tabular / graphical report in a browser, an emailed
report that gets automatically generated and sent everyday, or an alert that warns users of exceptions, among others. Usually
an OLAP tool and/or a reporting tool is used in this layer.
Metadata Layer
This is where information about the data stored in the data warehouse system is stored. A logical data model would be an
example of something that's in the metadata layer. A metadata tool is often used to manage metadata.
System Operations Layer
This layer includes information on how the data warehouse system operates, such as ETL job status, system performance, and user
access history.

Conclusion
• Data warehousing is the leading and most reliable technology used today by companies for planning, forecasting, and management for e.g. resource planning, financial forecasting and control etc
• In computing, online analytical processing, or OLAP is an approach to answering multi-dimensional analytical queries swiftly.
• OLAP is part of the broader category of business intelligence, which also encompasses relational database, report writing and data mining.

![Online Analytical Processing on Graphs (GOLAP): Model and ...reports/papers/201214.pdf · online analytical processing of information networks1. Chen and Qu et. al. [16, 43] proposed](https://static.documents.pub/doc/80x56/5fc5e0d28d5c9c637530ab41/online-analytical-processing-on-graphs-golap-model-and-reportspapers-.jpg)














![A Novel Grouping Aggregation Algorithm for Online Analytical Processing · Online Analytical Processing (OLAP) is a model of multidimensional data analysis [1]. It is a critical application](https://static.documents.pub/doc/80x56/612863cc5697b86e54462b6b/a-novel-grouping-aggregation-algorithm-for-online-analytical-processing-online-analytical.jpg)
