20
Open government data Learn why it will change your digital life forever Viewpoint
| Date post: | 15-Apr-2017 |
| Category: |
Business |
| Upload: | hewlett-packard-enterprise-business-value-exchange |
| View: | 8 times |
| Download: | 0 times |

Open government dataLearn why it will change your digital life forever
Viewpoint

Viewpoint
Table of contents
Evolve and change to a mature standard 3
On to enlightenment 4
Read about its value chain 6
Combine open data, Big Data, and IoT 7
Go from open data to IoT 11
Get value from your information systems 12
Gain added-value services 13
Incorporate an open data engagement model 14
Incorporate business and industry 19
Move forward 19
About the author 20

3
Open Government Data—a strategic initiative in governments around the world—offers greater transparency to citizens by sharing government data in a machine-readable format, for free reuse by others.
Over the last five to seven years, most governments adopted an open data policy,1 and many data sets are now available on a multitude of websites, such as data.gov. Like any new technology or trend, open data is going through the usual cycles of the Gartner hype cycle adoption curve.2 However, now’s the time to refocus open data from useless inconsistent data sets—full of errors—to a trustworthy and valuable input source for all kinds of applications (apps) and information analytics, including new value-added services for companies and citizens.
Evolve and change to a mature standard
Get through inflated expectations It’s clear that open government data is here to stay, as it’s widely backed by senior government executives.3 In Europe, open data received a big boost by the updated PSI Directive 2013,4 which was translated into local laws in the subsequent two years. This directive states that open data will be the default for most information, with respect for privacy and allowance for some exceptions to the rule.
In the early days of open data, 2008 to 2013, the primary focus was on setting up an open data platform and publishing as many open data sets as possible. So, platforms started popping up everywhere, as every government level—city, regional, federal, and continental—wanted its own channel.
Many governments, particularly in the U.S. and UK, invested heavily in them and also in educating companies and schools on the value of using these data streams. This resulted in a first generation of citizen-centric apps, such as “find my nearest hospital” and “where are public bathrooms.” Often these were—and still are—driven by local contests, such as AppsForX, with X being the name of a city or organisation. They were useful in raising awareness and understanding the value of these data sets, but the apps themselves created little business value, so few companies were established, and even less survived based on this first generation of apps.
Because the focus was on getting as many data sets out there as possible, it was hard for a company or individual to find the correct data sets, bring them together consistently, and make some kind of practical use out of them as an application or analysis. Whilst there are various techniques available, such as linked open data (LOD), to bring these all together, mostly only technical people are fully aware of the value of these techniques—rarely the individuals who simply want to use the data sets.
As the state of open government data evolves, it becomes more and more normal to share that data and for others to use it—for profit and others’ benefits. Making it a reliable source of high-quality, consistent data, available for everyone, to provide better services for others is the goal.
If you’re looking for ways to expand your open data initiatives and their impact, become more influential in creating and stimulating economic advantage out of this data. This will help businesses looking to obtain value from open data, either in processing it directly into apps or services, or by enriching and combining it with other commercial data and reselling it in a Data-as-a-Service model. This evolution of open data is likely to positively impact most everyone’s daily life.
Viewpoint
1 http://www.opendatabarometer.org/
2 http://www.gartner.com/technology/research/methodologies/hype-cycle.jsp
3 http://www.opendatabarometer.org/
4 http://ec.europa.eu/digital-agenda/en/european-legislation-reusepublic-sector-information

Now, there’s nothing fundamentally wrong with this approach. In fact, it’s typical for any new technology on the Gartner5 hype-cycle curve, especially in the early phases when an initiative is mostly (new) technology driven. And governments should certainly continue to produce open data, but the quantity of data sets is clearly not the only parameter that will make this a long-lasting business model.
Recently, governments started questioning the failure rate of start-ups and survival of added-value services with positive longer-term business potential. Because of this, since 2014, governments shifted away from publishing high-volume supply- and quantity-driven data sets to developing industry partnerships and providing demand- and quality-driven data sets.6, 7 Governments realise open data’s real value will come from industry and the added value that companies can bring to the public. This makes it much more efficient for a government to have an open dialogue with industry partners to align the production of data sets to the services each industry wants to produce.
This approach also means governments need to be trustworthy sources of publishing information. This leads to early discussions on how governments should become service-level agreement (SLA)-driven to open data users. This type of SLA should contain basic guarantees that the government publishing entity will provide the data, keep it correct, and update or enhance it going forward.
On to enlightenment
Recently, there has been increased interest from the European Union (EU) Digital Agenda to provide standards to all EU countries to make open data sets more consistent. The EU launched a great deal of material to standardise publishing and harvesting of open data sets amongst member states. Various initiatives—defining standard data models, vocabularies, and metadata—are taking place to realise reuse of data sets across government publishing entities. Signs are good that the quality and consistency of information will increase by leveraging these models and standards.
Despite the existence of many open data platforms, there remains considerable resistance at the department executive level inside governments to engage and publish open data, or allow its reuse by other governments and countries. This is mainly due to lack of awareness and engagement.
So, all too often, many governments fall back on publishing classical printed reports in which much statistical data is printed in graph format. Because of governments’ reluctance to publish open data, for example, journalists must often resort to scanning printed reports or retyping their content in order to make an analysis in the press. So, suddenly, one starts to question the correctness of the information—the fact that parts of the published data may be owned by others, the data could be wrongly interpreted, and many more reasons surface. These are all fears of the unknown and attributes of dealing with basic change management. Embracing open data is therefore more than a mere technique; it’s also a significant cultural shift to greater information openness and transparency.
4
Viewpoint
5 http://ec.europa.eu/digital-agenda/en/european-legislation-reusepublic-sector-information
6 https://www.bestuurszaken.be/open-data-dag-vlaanderen
7 http://www.opengovpartnership.org/country/united-kingdom

Viewpoint
New legislation came into effect in 2015, for all EU member states, making open data much more the default and standard way of publishing data. This will drive an even wider adoption of open data—at all government levels—and herald an increase in publishing new open data sets. Following are the principles that are part of the new EU PSI 20138 directive, which is now the norm for local legislation:
• Open data by default
• Quality and quantity
• Usable by all
• Data released for improved governance
• Data released for innovation
• Technical annex
As the early adopting countries of open data, the U.S. and UK launched a Digital Government Partnership in early 2015 to “use digital services to better serve citizens and businesses, and build a stronger digital economy.”9 This partnership further enhances their commitment to publish open data sets as one of the cornerstones of their open government approach.
There are still a lot of subject areas where open data is not yet widely accepted—where the debate still rages, or is just starting as open data10 is still in the early stages of becoming the norm, with some countries more advanced than others. Of course, open data tends to threaten traditional approaches and commercial ecosystems.
So, open data is undergoing a transformation at this very moment. It is evolving from a technology-inspired initiative into a cultural shift as it becomes the default for governments around the world. As such, this transformation closely matches the original objectives of facilitating more open and transparent government by using modern IT technologies to disclose government information. The whole movement is evolving from simply producing data sets to creating added-value services using open data and other data streams. It will increasingly become a substream of government information that can be merged with other information to achieve economic value for companies or benefit individuals.
So, open data is becoming a given and will not disappear. And all of the hype around it will likely fade away as it becomes natural for governments to have quality data sets available.
As open data follows the logical stages of the Gartner hype-cycle curve, the next phases are on the horizon and must be taken seriously as an available source of information in analytics and added-value services.
5
8 http://ec.europa.eu/digital-agenda/en/european-legislation-reusepublic-sector-information
9 https://www.whitehouse.gov/blog/2015/01/16/us-uk-digital-government-partnership
10 http://ec.europa.eu/research/swafs/index. cfm?pg=policy&lib=science
Viewpoint
6
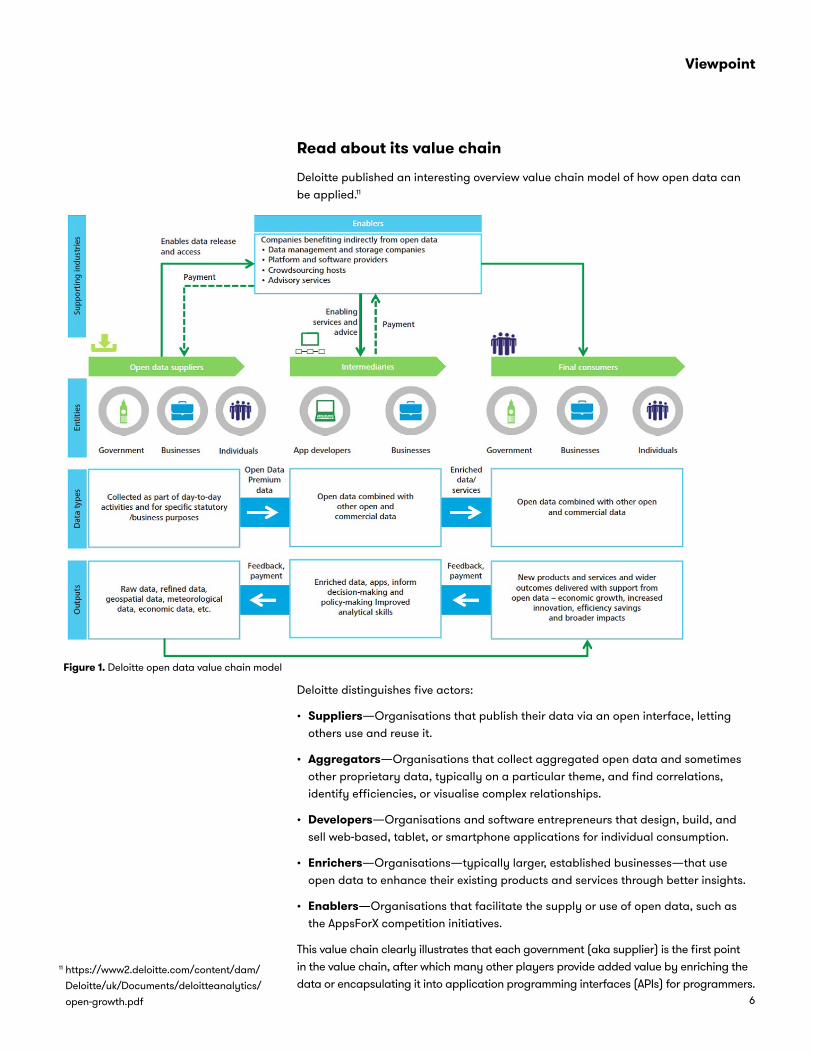
Figure 1. Deloitte open data value chain model
Read about its value chain
Deloitte published an interesting overview value chain model of how open data can be applied.11
11 https://www2.deloitte.com/content/dam/Deloitte/uk/Documents/deloitteanalytics/open-growth.pdf
Deloitte distinguishes five actors:
• Suppliers—Organisations that publish their data via an open interface, letting others use and reuse it.
• Aggregators—Organisations that collect aggregated open data and sometimes other proprietary data, typically on a particular theme, and find correlations, identify efficiencies, or visualise complex relationships.
• Developers—Organisations and software entrepreneurs that design, build, and sell web-based, tablet, or smartphone applications for individual consumption.
• Enrichers—Organisations—typically larger, established businesses—that use open data to enhance their existing products and services through better insights.
• Enablers—Organisations that facilitate the supply or use of open data, such as the AppsForX competition initiatives.
This value chain clearly illustrates that each government (aka supplier) is the first point in the value chain, after which many other players provide added value by enriching the data or encapsulating it into application programming interfaces (APIs) for programmers.

Open Data
(Open) Big Data
(Open) Sensor Data
Viewpoint
7
Combine open data, Big Data, and IoT
Access a new world of value-added services Since 2013, the focus of open data has increasingly shifted away from simply producing and publishing data sets to using them for analytical or added-value purposes, such as doing something with them. This means open data is maturing, and companies are now seriously considering using these sets in their analytics environments—for internal purposes or to create value-added services for external data users.
Today, there are enough available tools, methods, and websites to position open data as a form of Big Data.12 And by using real-time sensors, along with Internet of Things (IoT) concepts, even greater value can be obtained from it. Arguably, a new technology-driven hype cycle could be starting here; regardless, this highlights some new possibilities in using open data for new valuable services in real time. One example that can be found, already in many countries, is using open data to divert traffic based on real-time information.
There is a real revolution going on in this space. Big Data techniques such as analyzing and visualising data can now be applied to make sense out of the many thousands of data sets each government (or country) publishes, even in real time and for sensor-based information streams.
Figure 2. The data revolution
Let’s look a little bit closer at how these ecosystems can actually coexist, strengthen each other, and bring value to companies and individuals.
12 http://opendata-tools.org/en/data/

Viewpoint
8
Figure 3. The value of joining data sets
Link open data to Big Data—one small step Now, it’s only a small step from open data to Big Data. One may not directly see the link, but think about weather forecast data as an example. This data tends to be high in variety and velocity, and certainly big in terms of volume if unprocessed and coming directly from, say, a satellite source. As such, there is a convergence between private Big Data sets and public Big Data sets, and the intersection shows an interesting area where these can be joined up and analysed.
In Figure 3, Joel Gurin, Open Data Now website13 owner, made it very clear that there is much added value in joining up these data sets.
The Guardian newspaper goes one step further and defines open data14 as:
• Big Data that’s not open is not democratic.
• Open data doesn’t have to be Big Data to matter.
• Big, open data doesn’t have to come from governments alone.
• But, when a government turns Big Data into open data, it’s especially powerful.
The added value comes from government institutes, and from bringing public and private data sets together. At first, one may be inclined to think this will present huge challenges in aligning the data sets to join or query them. But, there are a lot of techniques that can facilitate this process.
In the recent past, analytical and visualisation tools were very focused on a static database model to create some sort of meaning out of the database. IT teams spent considerable time transforming and cleansing data before loading it into a data warehouse, ready for use and analysis. This approach, however useful, is not very agile and usually only works on structured information and predefined queries or parameters. Fortunately, new techniques can speed up this lifecycle and make it much more dynamic.
Source: Joel Gurin, Open Data Now website
13 http://www.opendatanow.com/
14 http://www.theguardian.com/publicleaders-network/2014/apr/15/big-dataopen-data-transform-government

Viewpoint
9
Techniques like LOD make it possible to join open data sets from around the world, simply by using the uniform resource identifier (URI) of each data set. This makes analysing data interesting, as it’s independent from the source or format from which it originates. All you need to know is the URI. And as technology matures, more and more dynamics are coming out of these tools, enabling additional unstructured data sets to be analysed automatically. These new features generate a new dynamic and new possibilities.
With LOD, the jump to the semantic web can be made. According to Tim Berners Lee,15 if open data sets are the pieces, and the semantic web is the whole of all these pieces, it is a part—not the whole—of Web 2.0.16, 17 Of course, there are many pieces that all link up together to form the semantic web, as depicted in Figure 4. For the purposes of this document, the focus is on open data only.
Figure 4. Pieces forming the semantic web18
An interesting dimension of the semantic web is that artificial intelligence processes can now be applied—getting the web to do some thinking for us—to publish open data sets. This is less “science fiction” than it sounds. In the last couple of years, many new semantic algorithms have come to life that interpret data and match them with similar data sets. So, these algorithms can derive what fields are, for example, an address in a particular data set, and join them up with similar fields in other data sets. These algorithms are all based on underlying standardised data models and brought together in ontologies. Several organisations are publishing standardised data models, so there is a definite advantage and need for this.
Source: Wikimedia
15 https://nl.wikipedia.org/wiki/Tim_Berners-Lee
16 http://www.w3.org/DesignIssues/Semantic.html
17 http://www.techrepublic.com/article/an-introduction-to-timberners-lees-semantic-web/
18 http://upload.wikimedia.org/wikipedia/commons/f/f3/Semantic_Web_Stack.png

Government
Partners
Partners
BI 2.0
Big Data
Open data
Advanced visualisation
BI 2.0Applying DW & BI techniques to analyse data sets
Big Data
Open dataMany data streams from various websites
all over the world
Virtualisation/services Visualise data sets and bring to public
Deliver (new) services to citizens or companies
Bring these data sets together and congregate them—find meaning out of the
(automatically/semantic/ontology based)
Viewpoint
10
One example is Dublin Core,19 where lots of standard models are defined and published. If analytical tools implement these standard data models and apply the semantic web algorithms, then a lot of the joining up and interpreting of data sets can be automated. If a data set is further encapsulated in an RDF stream, it can be queried using SPARQL, instead of loading the whole data set into the application. This brings even more options to the table of an analytical tool.
One example of how this can be applied to your website or application is Open Calais,20 which automatically creates rich semantic metadata for the content you submit—in well under a second. Using natural language processing (NLP), machine learning, and other methods, Calais analyses your document and finds the entities within it. And it goes beyond classic entity identification and returns facts and events hidden within your text as well. So, by applying semantic web methods to open data, a lot of information can be brought consistently together to be analysed, and even automatically joined up.
Now, apart from the characteristics of volume, variety, velocity, and vulnerability—as with Big Data, there are advanced analytical and visualisation Big Data methods that can also be easily applied to open data. Many new open source platforms are popping up, providing tools and mechanisms that make visualisations and analytics on open data sets much easier for companies and individuals. These platforms all use the same principle: Collect any number of open—and closed—data sets and let the platform produce a visualisation on it. So, getting meaning and value out of these open data sets has never been easier. A good overview of available data and visualisation sites can be found at http://opendata-tools.org/en/visualization/.
Bringing this all together, open data is the raw material. By applying LOD and semantic web techniques, you can get more automated alignment and meaning out of this data. It can be joined up in visualization, and using analytical toolsets, enable much faster and better interpretation of massive amounts of data. And because of this, open data deserves its new status as a valuable (extra) input stream in any analytical programme.
Figure 5. Best practice approach to extract value from open data sets19 http://dublincore.org/
20 http://www.opencalais.com/about

Bridges
Waterways
Water levels
Air pollution
IoT
Trac information
Weather station
Viewpoint
11
Go from open data to IoT
It is only a small next step from analysing static data sets to dynamic real-time sensor data and IoT. Governments are sending out more and more sensor data, such as weather stations, water levels, pollution levels, traffic density, and security cameras, as real-time open data sets. This lets companies create added-value services in real time by incorporating these real-time streams into their analytics platform or tool.
Figure 6. IoT sensor data inputs
Some companies, such as IBM, Google™, Microsoft®, and Cisco, were quick to realise the value in combining open data and IoT, creating platforms to take in various open data sets—static or real time, produced traditionally or via sensors. These companies have launched various open data platforms that collect and analyse these information streams and let users create new services to the public—paid or free.
These platforms all share a similar approach, in which:
• Information from sensors is collected and published on the platform. Governments play a vital role in helping publish data from public sensors. Of course, security and privacy concerns are taken seriously.
• A user logs onto the platform, connects various—sensor and other—data sets together for analysing and viewing the information in near real time.
• The user produces a visualisation or application with this data that can be shared with the world. The decision to make this a paid model is up to the user.
So, now it’s time for various industries to consider open data as an input stream as a valuable and trustworthy add-on source of (sometimes real-time) information. Companies can then use analytics, Big Data, and sensor data techniques on government-published open data sets.

Search
Harvesting
Linked Open Data
Database
Document
Data set
Application
Government/publishers responsibility Users
Unlocking data from source systems Publish and (re)using Open Data
Extract. transform, publish
Open Data
Open Data platform
Viewpoint
12
Get value from your information systems
Set up governance in an open data landscape Most articles on open data tend to focus on the practical use of it once the data set is published on an open data platform. However, it really all starts with unlocking data from source systems and bringing it—in a consistent way—to the open data platform. As such, concern for quality should originate in the back office, where traditional systems, databases, and products hold that information, usually in a non-normalised way. Figure 7 shows how the lifecycle of open data—from source to publication—could look.
Figure 7. Open data lifecycle
Whilst this paper’s author was writing a chapter for the Open Data Handbook of the Flemish Government,21 it was discovered that open data follows about the same patterns as any data set that is loaded into a data warehouse, and the same techniques remain valid:
• Data needs to be extracted from source systems in much the same way as it’s done for data warehouses.
• To make sure data is consistent with standard data models and that semantic web techniques can be applied, much attention should go into transforming the data and preparing it for publishing.
• It is essential to load cleaned and consistent data into a data warehouse. This can also be done when publishing data on an open data platform, including metadata provisioning.
As such, organisations can usually reuse most of their existing extra, transform, and load (ETL), and data warehousing tools. In fact, reusing them is highly preferred, as it automates the whole process, so updated data can be published by running the complete script.
It is strongly advised to also use all of the master data management (MDM) techniques with open data. There are good models available, such as DMBOK.22 Certain governments, like the UK and U.S., have gone to great lengths to provide standards, but all too often these are not sufficiently mandatory, which results in a lot of publishing variations.
21 https://overheid.vlaanderen.be/open-data-handleiding
22 http://www.dama.org/content/body-knowledge

Clean Query Visualise Publish
Your open data
Added value for citizens
It is recommended that governments create or enhance their existing MDM plan by including open data as a new channel for publishing data. Because data is often created at the entity level rather than enterprise, it’s essential to make sure every entity does this at its own level, before sharing data across entities.
It might even be a good idea for the publishing government to engage in a sort of SLA that commits to providing quality data aligned with other agencies, which is constantly kept up to date. Only with such a commitment can you be sure that open data will be used by companies.
Use governance in an open Big Data landscape With the arrival of Big Data analytics, the desire for consistency and quality in data sets will only increase, so good governance will be necessary.
Gain added-value services
There is still a lot of debate on what an added-value service really means. It’s the ultimate one million dollar question. At present, many consulting companies and the EU (the EPSI platform) have issued reports about the economical return that publishing open data will trigger. For a collection of articles on the facts so far, please read “The economic impact of open data: what do we already know?” of the The Open Data Institute,23 where you can learn that there are quite a lot of job opportunities and even GDP growth estimated by the EU.
It’s clear that value is out there, but how do you unlock it? In Figure 8, a model is presented to keep in mind when using open data.
Figure 8. Added value of open data
23 https://medium.com/@ODIHQ/theeconomic-impact-of-open-data-what-dowe-already-know-1a119c1958a0#.jgtgcpvzs
Getting meaning from open data may appear to be the most magical of all achievements, but analytical tools have matured beyond simple reporting and can now automatically look for meaning and present results in a highly visual way. Of course, interpretation is still up to the human who is looking at this data, but much more number crunching is being done automatically.
Viewpoint
13
Engage more
Stimulate innovation
Educate more
Steer & correct
Better life for all
Sensor Data
Big Data
Open data
Intelligent government
Digital services
Figure 9. A Vision (Intel)—Improving life with Open Data as one of the input streams*
*Loosely based on the Intel® Intelligent Systems Framework
Incorporate an open data engagement model
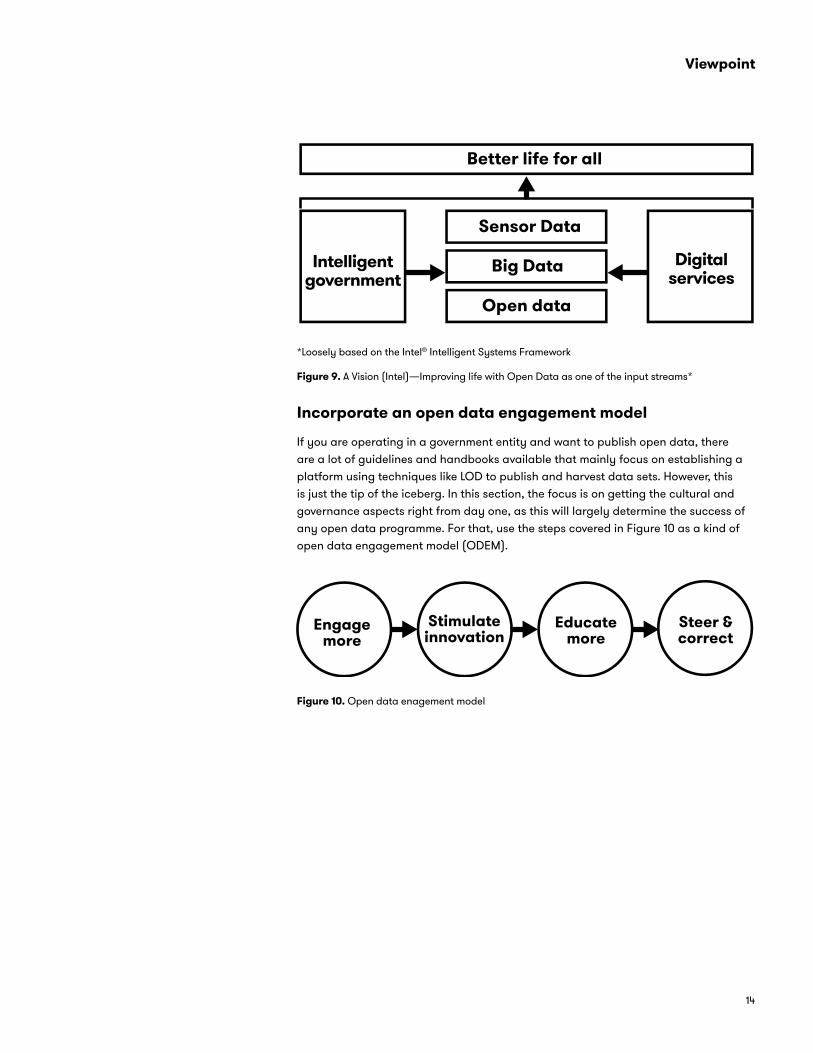
If you are operating in a government entity and want to publish open data, there are a lot of guidelines and handbooks available that mainly focus on establishing a platform using techniques like LOD to publish and harvest data sets. However, this is just the tip of the iceberg. In this section, the focus is on getting the cultural and governance aspects right from day one, as this will largely determine the success of any open data programme. For that, use the steps covered in Figure 10 as a kind of open data engagement model (ODEM).
Figure 10. Open data enagement model
Viewpoint
14

Step 1. Engage more First of all, it’s important to define and set a strategy for deploying open data in your entity. In the early days, the five-star model advised all governments—as a first step—to just publish it. This resulted in a quantity-led approach to open data; but it also had an adverse effect, as many companies do not want to use data that is not consistent or cleansed properly before publishing.
It may seem logical and applicable in all important government programmes to adopt a strategic approach, but the early days of open data clearly showed the programme was driven by technically inspired people who primarily wanted to demonstrate that linking data sets in a semantic web was possible. Although initially this was acceptable, we have now moved beyond this phase on the Gartner hype cycle.
Developing a strategy means getting buy-in from all levels to engage with open data and adopt a quality approach. It comes down from the top echelons, with government itself providing a framework for all entities to legally commit to open data. It also comes from the ground up, with all agencies committing to publishing data sets in a consistent way with other agencies. This means alignment and agreements will have to be created, shared, and sometimes even enforced.
Most governments will state they have the necessary laws and commitments in place. However, there’s still a lot to be done at the entity level to get the right leadership to acknowledge that open data will not threaten or increase their work and services. Rather, it will complement and help realise a truly digital government.
After a commitment is obtained at all levels, and governance put in place to start publishing open data, the first step is to create an open data master plan. This would bring together most—if not all—information streams in an entity and define which ones can be published as open data. Some restrictions will still apply to open data—such as privacy, so existing data classification schemes should be mapped against identified open data candidates.
Apart from identifying existing information streams, there must be valid instructions for newly created applications or information streams; they should be logical to identify these new streams with or without an open data marker. As such, it will become natural to define open data sets from any change in existing or new applications functionality.
A next important step is to align your open data sets with standard-defined data models for common objects like citizens, addresses, opening hours, budget, and service descriptions, amongst others. There are many standards available, but various entities are choosing their own data models, which makes it hard to interpret similar open data from different entities. Luckily, semantic web techniques can come to the rescue; regardless, try and fix this before publishing instead of letting algorithms guess (wrongly) about what elements it holds.
Readers who are familiar with MDM, data quality processes, and various existing data validation processes should feel very comfortable, as these processes are entirely valid for open data, and even more so as the scale of users is far larger than at the entity level.
Engage more summary
Develop a strategy to deploy open data in your entity—focus on cultural and governance aspects as much as technical ones.
Make an open data master plan and maintain it; consider an MDM approach.• Always go for quality and
consistent information; the rest will not be used anyway.
• Learn from your experiences and improve at the base.
• React to users’ feedback.
• Start reusing open data from other agencies in your analytical environment.
• For every new data stream in the back office, check whether it can be replaced by using or creating an open data stream.
• Automate the ETL process as much as possible.
• Do not delay; start now.
• Be a trustworthy partner by regularly updating your data—increase frequency, validate quality—and metadata.
Viewpoint
15

At this point, you should determine whether you need an open data central team to safeguard all the quality attributes for all entities. The more consistency that is built in by applying standard data models, the more companies can start using all similar, joined-up data sets.
Government entities often focus only on publishing their own open data. However, they can also use open data from other entities or countries for internal purposes. An agency that uses open data from other entities can make its analytics even more powerful, certainly in an international context, when its local government results can be mapped onto those of other similar countries.
When creating open data sets, it’s essential to automate as much of the data extraction as possible, transforming it to a standard data model, and publishing it on an open data platform. In the business intelligence (BI)/data warehouse (DW) areas, ETL tools facilitate automation and the same tools and techniques can also be used for open data. This has the added benefit of automatically scheduling open data sets updates, keeping the open data up to date.
Strategically, it is essential to learn from your experiences and improve the base—every time, every day. This is not a one-time exercise; it is an ongoing process of discovering and adapting your information needs to the reality of changing applications, data models, and company requests. So, engaging at all levels is essential to open data success in your government entity.
Apart from publishing data, governments must be open to feedback from individuals or companies that use this data. Many government entities fear this feedback loop, as they think only negative comments will be received. Nevertheless, being an open and transparent government, which is the goal of open data, also means being responsive to customer feedback, responding adequately to all quality issues.
Step 2. Stimulate innovation Many governments believed that the success of open data would come naturally and many companies were waiting for the data to arrive so that they could start building apps on it. Nothing less is true these days, as many governments are realising it’s not enough just to provide data sets without guidance; they must stimulate organisations to create innovative services. In the early days, there were many hackathons and contests to get people interested in creating the initial wave of services. Although they did create an initial buzz, many of these applications did not survive or become sustainable. That is because the people who attended these data contests were mostly students and not companies that have a particular business model in place.
Countries like the U.S. and UK learned that open data is only used if the government stimulates industry to discover it—and its usability and economic value—before they will engage and make investments for building apps or new services. The Flemish Government took a different approach in subsidising selected government entities to propose an open data programme that will publish open data sets. A number of projects were selected that have the best possible chance of published data sets being picked up by companies and turned into services or apps. A subsidy is approved per project when data sets are published and used by industry.
Stimulate innovation summary
• Engage with communities of interest to use your open data—or understand why they won’t.
• Think ahead about applications using IoT and sensor data.
Viewpoint
16

So, continue with initial innovation contests, but increase focus on companies or industries that present a business plan for long-term data use. This will immediately generate corporate concerns about reliable partnerships with government entities, and raise questions about whether data is correct and up to date. The solution is to provide a contact in the government entity, ready to react together on any data issues. This puts governments in unusual territory; for the first time, they may have to subscribe to a business SLA when delivering open data. This should be seen as a positive move, likely to trigger more consistency in data models and raise the quality of released data.
New (technically inspired) hypes are emerging on the horizon. This time, these are techniques for IoT and real-time sensor data, based on open data principles. In response, governments should stimulate the institutionalisation of open data, and also actively engage with universities and leading-edge companies that want to take this one step further. After all, it’s only the start of accepting open data as a normal way of getting meaningful government data and creating services that help citizens learn new skills, navigate safely on the roads, and prepare for severe weather conditions. And these are just a few of the many new services that can be based on IoT and sensor data.
It’s best to work in a more cooperative and collaborative way with academic institutions and corporations to unlock the first data sets that companies want to use in their new services. This will deliver the best results in new added-value service delivered to citizens, based on continuous updates of government data.
Step 3. Educate From 2011 to 2014, the UK government spent a lot of time and resources educating school students about open data. The purpose: stimulate this younger generation, and get them acquainted with and using it. This proved an interesting approach, as when the younger generation is accustomed to open data, it becomes normal for them to use and publish it.
Even more education is needed. Citizens and companies around the world require more understanding of open data. Not so much on the technical aspects, such as LOD and URI, rather on practical uses of it—in creating new applications and services.
How far should governments go? Should they invest in applications and services themselves, even as innovators and thought leaders? Most likely, governments should restrict their activities to publishing open data and let the market do its work. However, shining the spotlight on good use cases by listing them on an apps website, like the U.S. government initiative apps.gov, can stimulate the market so long as this doesn’t give preference to any specific company or application.
In addition to educating citizens and companies, internal government personnel need educating. One might think more about how to set up an open data programme, as the data can also be a source of information for other government entities, such as, internal reuse of open data. So all government entities need to be made aware of how to read and process open data sets. Selected internal government data analysts should also receive training. These people should be made aware of the various—even open source—platforms that exist for producing visualisations and infographics with open data.
Educate summary
• Educate your internal personnel on how to use open data to improve citizen services.
• Give information sessions about how to publish and use open data sets.
• Repeat education steps frequently.
Viewpoint
17

Government Enterprises
011010011111001
011010011111001
011010011111001
€ €€
€
Citizens/customers/knowledge workers
Media/data broker
Added value
services
As data quality remains a prime aspect of open data, education on MDM techniques is not wasted effort. Delivering good, reliable data sets is essential for this information to be trusted and used by industries and companies.
Note that education should be an ongoing process, not a one-off. Information sessions for internal government people and external audiences like students and companies should be repeated at least twice a year. Since not every entity is yet operating at full speed, evangelising and technical guidance remain a necessity.
Step 4. Steer and correct Open data is not a single, finite initiative. It’s just starting to impact governments, making it necessary to learn, steer, and correct open data activities adequately. That’s why governments need to keep an open approach to managing open data issues and adapt to any situation—innovation, new standards, new data sets, and critics.
In the last few years, many themed platforms were established; examples include healthcare, transport, and food platforms. Typically these were created by communities of interest, nonprofit organisations, or EU-funded research projects. They all facilitate using open data around one particular subject and offer a joined collection of data sets published by governments, often on an international scale. Techniques such as LOD and URI are being fully exploited to bring relevant data sets together and offer a collection of data to the user. In a way, a form of data brokering has been established, which is perfectly in line with the definition of open data—it enables organisations to enrich data or bring data sets together for the public’s benefit.
Figure 11. Linked open data approach
Steer and correct summary
• Trigger communities to use your data, and give them ideas.
• Help build community or themed platforms, and continue to use standards.
• Become demand driven.
To facilitate open data use, actively communicate with various industries or communities of interest. Go one step further—provide scheduling information to these organisations. This helps companies know when certain data sets will become available. Also listen to companies when they describe their data needs; this will help trigger creation and delivery of relevant open data sets.
Until now, many governments were supply driven, meaning they decided what data sets to open and when. This resulted in a large quantity of data sets rarely being used. Only by becoming more demand driven and publishing data sets that will actually be used, can governments succeed in creating impact. This requires good cooperation with companies, aligning data sets to defined needs.
Viewpoint
18

Future Past
Community of technical believers Culture: Think reuse from the beginning
Supply-driven Demand-driven
• Governments unilaterally decide what data sets to publish
• Driven by numbers of data sets, not by quality and consistency of information
• Governments seeking active partnerships with industry
• Publish quality data sets and be a trustworthy partner
• Tell us what you need and we will make it available
Incorporate business and industry
So far, this paper has focused on governments, suggesting ways to set up and run open data programmes; but, let’s not forget industry and community interests. Without the companies and citizens that use open data, there would be no applications or services based on these data sets.
So, how should industry and communities use open data? No matter which industry or community of interest you operate in, it’s essential to get familiar with the concepts of open data and investigate whether these data sets can be used as an extra source of information in your analytics programmes. Statistical information about demographics or society trends can prove very valuable for marketing research and positioning a (new) product to the right category of people. For example, weather and traffic information can be very useful for transport companies to plan or adjust work schedules and avoid idle time on the road.
Look for added value in your application. Try to find an app that people want and will pay for such as services that make their life better—avoiding traffic, getting children into the best schools, or renting homes in a green area.
Move forward
Open data is here to stay. The initial buzz will fade away over the next few years, and it will become normal for governments to publish open data in a consistent and high-quality way. However, we are not there yet, and our best advice is to use an ODEM approach to become a trustworthy source of information to the world. Only then, will the digitisation of governments become real, at least on the output side, with results made available in a machine-readable format. As demonstrated, there’s no shortage of technical methods or platforms, but a natural flow of data inside government applications needs establishing.
Figure 12. Aligning government data sets to defined needs
If you are in an industry or community that wants to use open data:
• Get familiar with open data concepts.
• Investigate what data you could use in your internal analytics.
• Engage with your government to explain what types of data you would like to use.
If you are a developer or company looking to develop services with open data:
• Engage with your government and ask for relevant data.
• Check the visualisation platforms, upload open data sets, and publish your work.
• Cross and link the data sets you obtain.
Viewpoint
19

www.dxc.technology
About DXC Technology DXC Technology (DXC: NYSE) is the world’s leading independent, end-to-end IT services company, helping clients harness the power of innovation to thrive on change. Created by the merger of CSC and the Enterprise Services business of Hewlett Packard Enterprise, DXC Technology serves nearly 6,000 private and public sector clients across 70 countries. The company’s technology independence, global talent and extensive partner network combine to deliver powerful next-generation IT services and solutions. DXC Technology is recognized among the best corporate citizens globally. For more information, visit www.dxc.technology.
Microsoft is either a registered trademark or trademark of Microsoft Corporation in the United States and/or other countries. Intel is a trademark of Intel Corporation in the U.S. and other countries. Google is a registered trademark of Google Inc.
© 2017 DXC Technology Company. All rights reserved. DXC-4AA6-1379ENW. March 2017
Viewpoint
About the author
Yves Vanderbeken Yves Vanderbeken is a DXC Technology (DXC) account chief technologist and lead enterprise architect for the Flemish government and local governments (Flanders). Since 2011, Vanderbeken has been a core team member of the Flemish government’s open data team. Working with the Flemish government, he defined the technical strategy for setting up the open data platform and extracting, transforming, and publishing information in a consistent manner. He is the co-author of the Open Data Handbook published by the Flemish Government in February 2014. Vanderbeken coaches and advises various departments on their open data master plan and how to disclose data from their source systems to the open data platform, ensuring data quality and consistency across data sets.

















