78
Opinion Mining and Sentiment Analysis She Feng Shanghai Jiao Tong University [email protected] April 15, 2016

Opinion Mining and Sentiment Analysis
She Feng Shanghai Jiao Tong University
April 15, 2016

Outline
• What & Why?
• Data
• Tasks
• Interesting methods
• Topic Model
• Neural Network
2
What is Opinion Mining / Sentiment Analysis?
3

What is Opinion Mining / Sentiment Analysis?• Two types of textual information
• Facts, Opinions
• Note: facts can imply opinions
4

What is Opinion Mining / Sentiment Analysis?• Two types of textual information
• Facts, Opinions
• Note: facts can imply opinions
• Most text information processing systems focus on facts
• web search, chat bot
5

What is Opinion Mining / Sentiment Analysis?• Two types of textual information
• Facts, Opinions
• Note: facts can imply opinions
• Most text information processing systems focus on facts
• web search, chat bot
• Sentiment analysis focuses on opinions
• identify and extract subjective information
6

Why is Sentiment Analysis important?
7

Why is Sentiment Analysis important?• It’s useful
8
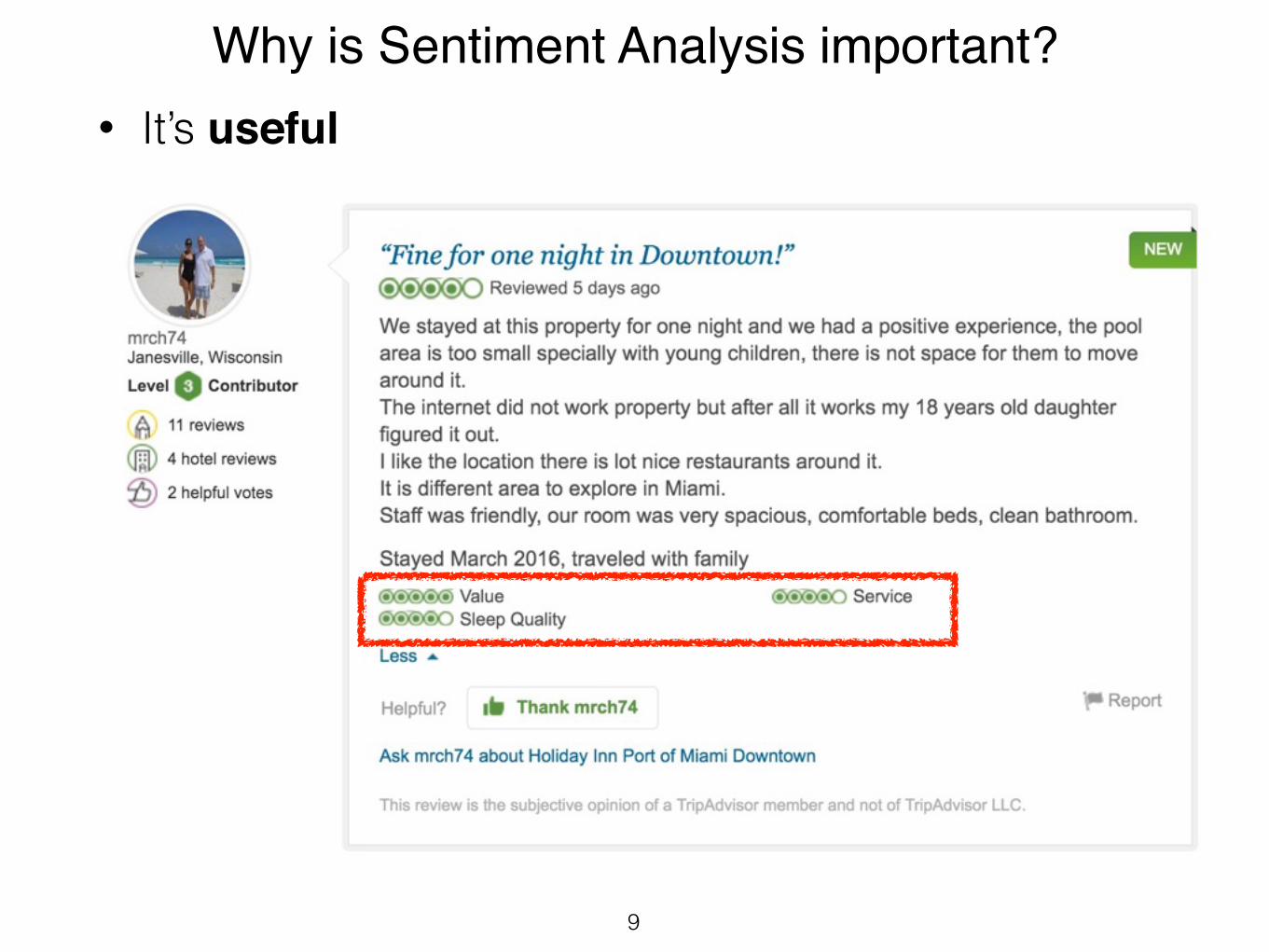
Why is Sentiment Analysis important?• It’s useful
9
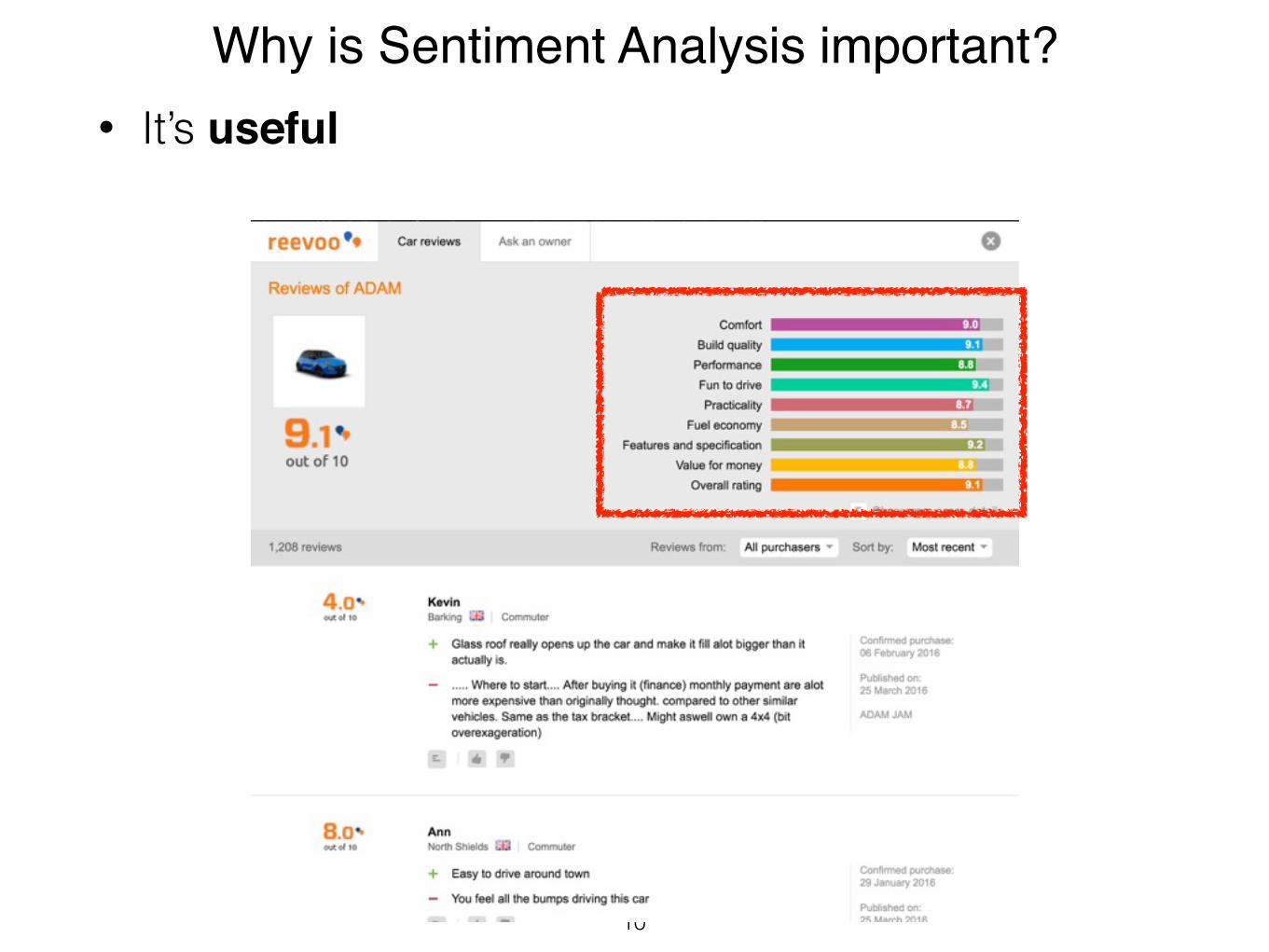
Why is Sentiment Analysis important?• It’s useful
10
Why is Sentiment Analysis important?• It’s useful
11

Why is Sentiment Analysis important?• It’s necessary
12
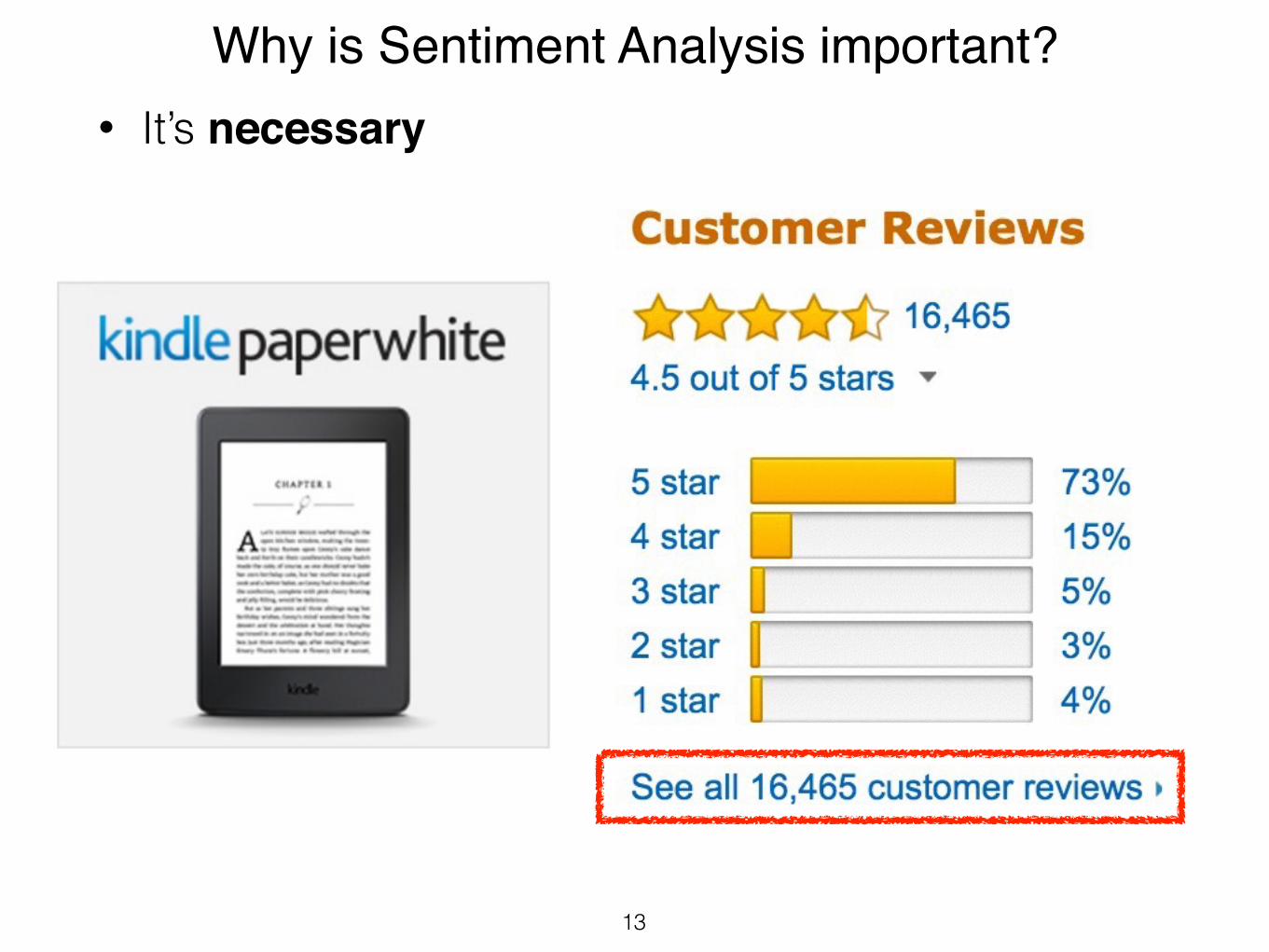
Why is Sentiment Analysis important?• It’s necessary
13

Why is Sentiment Analysis important?• It’s difficult
14

Why is Sentiment Analysis important?• It’s difficult
15
“Honda’s Accord and Toyota’s Camry are nice sedans.”
“Honda’s Accord and Toyota’s Camry are nice sedans, but hardly the best cars on the road.”

Why is Sentiment Analysis important?• It’s difficult
16
“Honda’s Accord and Toyota’s Camry are nice sedans.”
“Honda’s Accord and Toyota’s Camry are nice sedans, but hardly the best cars on the road.”
Opinions are complicated.Human language is ambiguous.

Data
17
Lets’ look at what kind of data is used for sentiment analysis.

Data: user-generated content
18
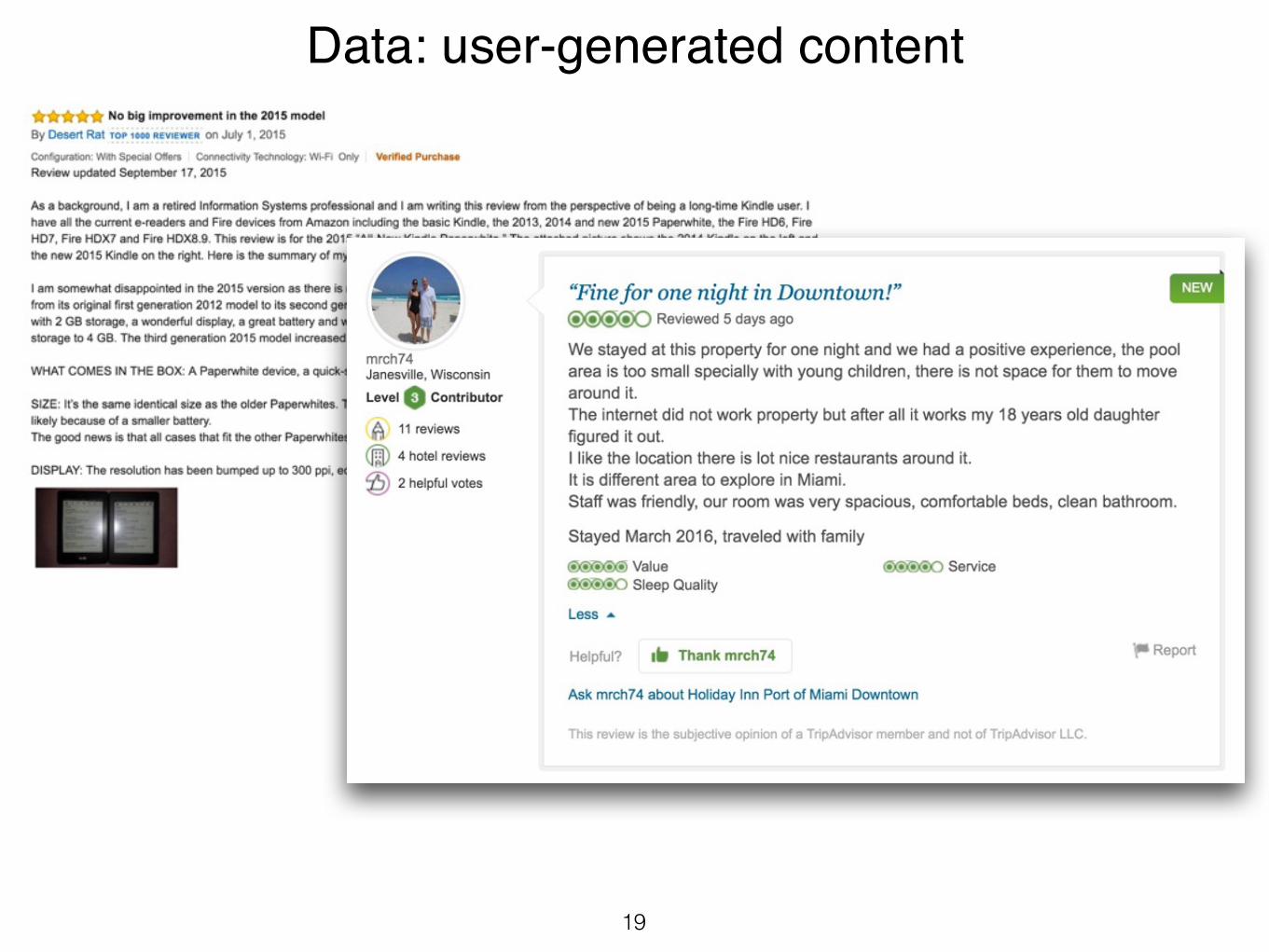
Data: user-generated content
19
Data: user-generated content
20

Data: user-generated content
• most of them unlabeled
• the labels are noisy #Panama #PanamaPapers
• the texts are also noisy
• different lengths, most are very short
• overall, the amount of useful training data is a bottleneck for sentiment analysis
21

Data: knowledge bases• WordNet
• A lexical database for English with emphasis on synonymy
• Nouns, verbs, adjectives are grouped into synonymy sets, “synsets”
• Words are linked according to lexical and conceptual relations, creating a “net”
• Not specifically sentiment oriented, but helps with identifying opinion targets
• http://wordnet.princeton.edu/
22

Data: knowledge bases
• SentiWordNet
• A lexical database based on WordNet synsets
• Each synset is assigned three sentiment scores: positivity, negativity, objectivity
• http://sentiwordnet.isti.cnr.it/
23

Data: knowledge bases
• ProBase
• A hyponym-hypernym dataset
• 2.7 million concepts
• http://probase.msra.cn/
24

• Good for:
• entity identification
• summarization
• unsupervised settings
25
Data: knowledge bases

Opinion in user-generated texts
• Let’s look at some examples of review sentences.
26

Opinion in user-generated texts
• target object
• aspect of the object
• sentiment value
• opinion holder
• time
27
We care about the following about an opinion:

• The room was extremely clean and well kept. The only complaint we had was no refrigerator but since we were only there for 2 nights so it was not a big deal. Bathroom was ample size.
28
target aspect value holder time
hotelroomutility
bathroom/ /
Opinion in user-generated texts

• The room was extremely clean and well kept. The only complaint we had was no refrigerator but since we were only there for 2 nights so it was not a big deal. Bathroom was ample size.
29
target aspect value holder time
hotelroom utility
bathroom+ - + / /
Opinion in user-generated texts

• The room was extremely clean and well kept. The only complaint we had was no refrigerator but since we were only there for 2 nights so it was not a big deal. Bathroom was ample size.
30
target aspect value holder time
hotelroom utility
bathroom + ? + / /
Opinion in user-generated texts

• The room was extremely clean and well kept. The only complaint we had was no refrigerator but since we were only there for 2 nights so it was not a big deal. Bathroom was ample size.
31
target aspect value holder time
hotelroom utility
bathroom + ? + / /
Opinion in user-generated texts
Ambiguous!
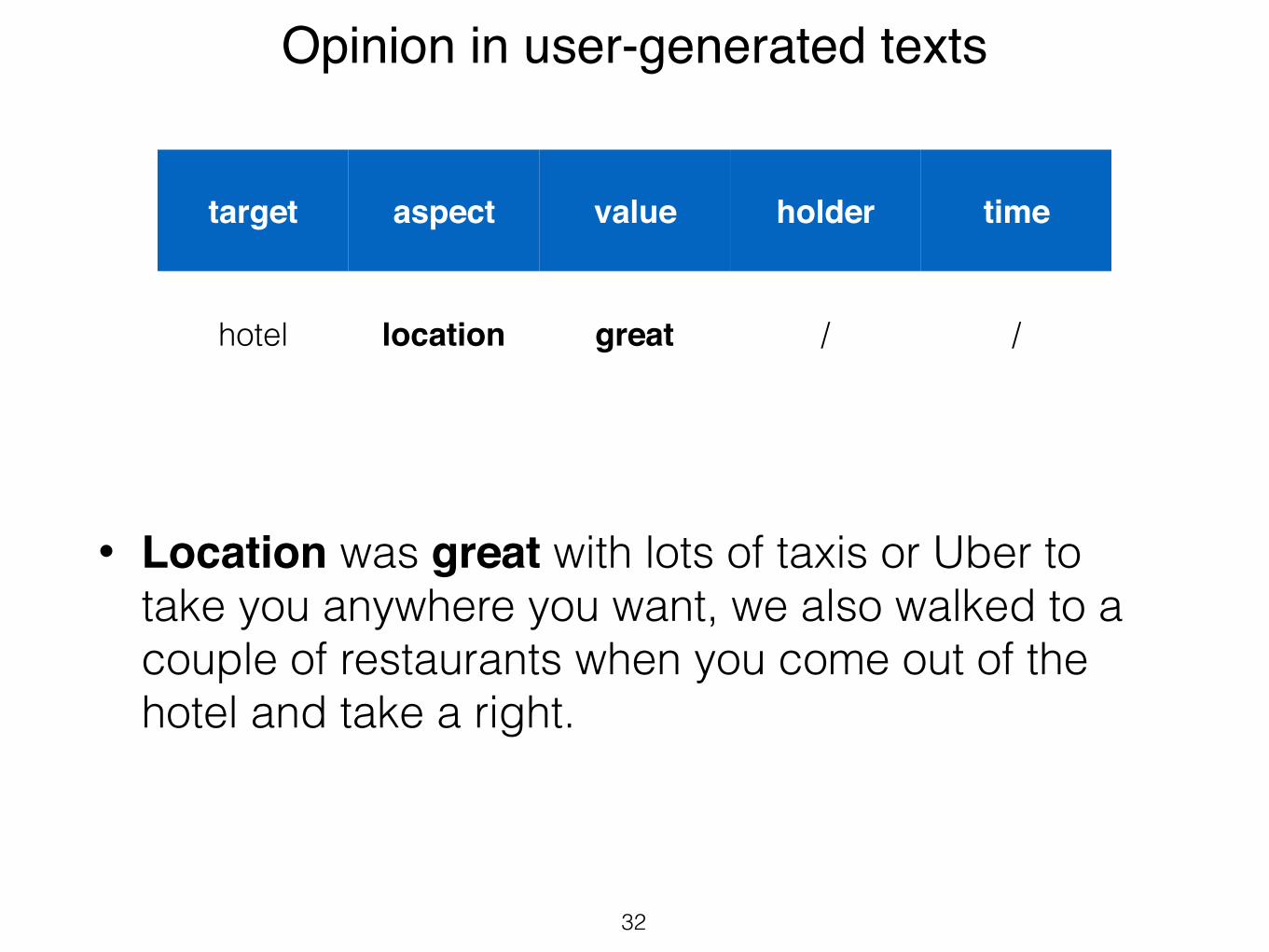
• Location was great with lots of taxis or Uber to take you anywhere you want, we also walked to a couple of restaurants when you come out of the hotel and take a right.
32
target aspect value holder time
hotel location great / /
Opinion in user-generated texts
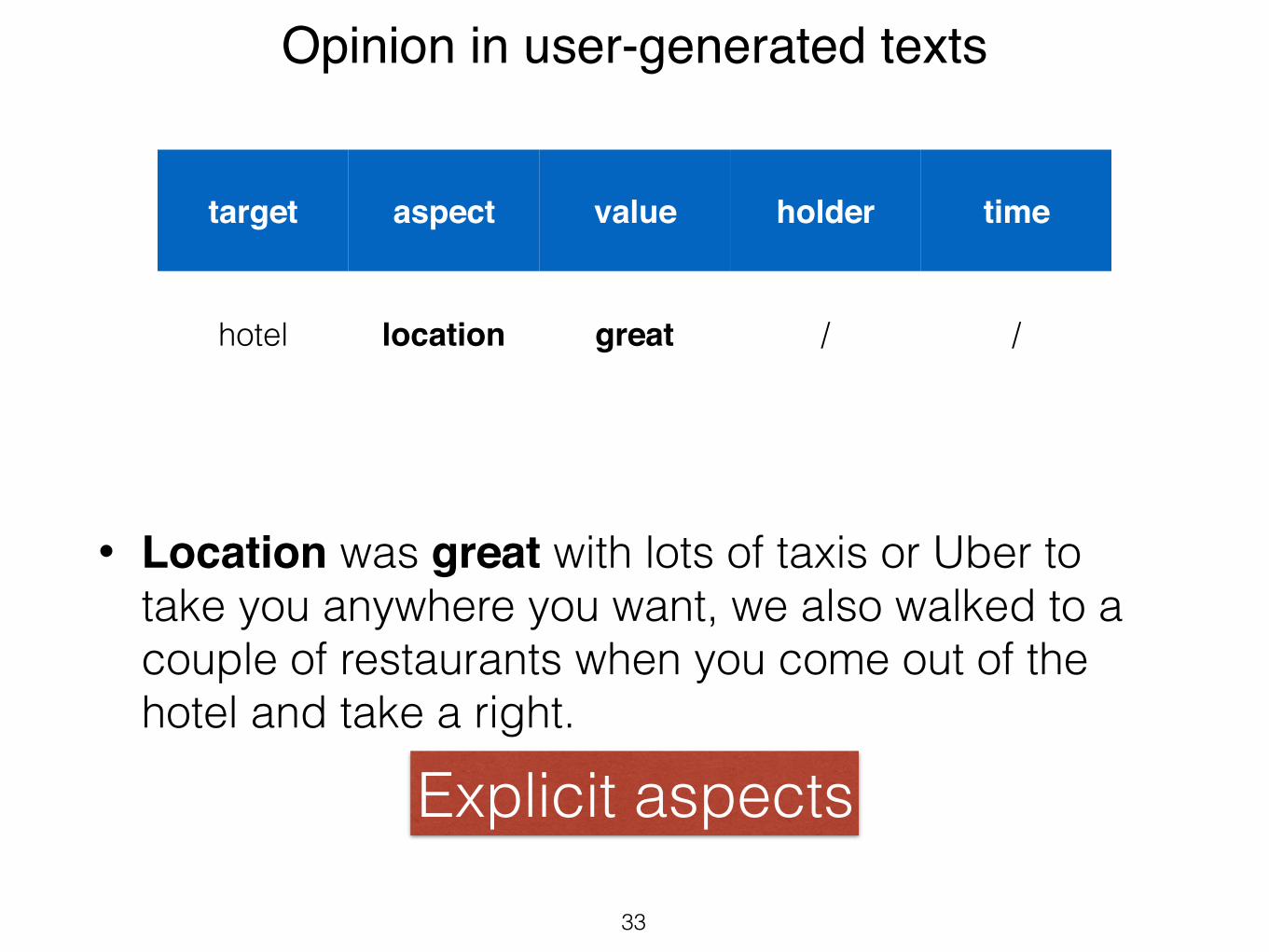
• Location was great with lots of taxis or Uber to take you anywhere you want, we also walked to a couple of restaurants when you come out of the hotel and take a right.
33
target aspect value holder time
hotel location great / /
Opinion in user-generated texts
Explicit aspects
• There are restaurants right out the front door. The little pub was our favorite. Lots of restaurants within walking distance as well.
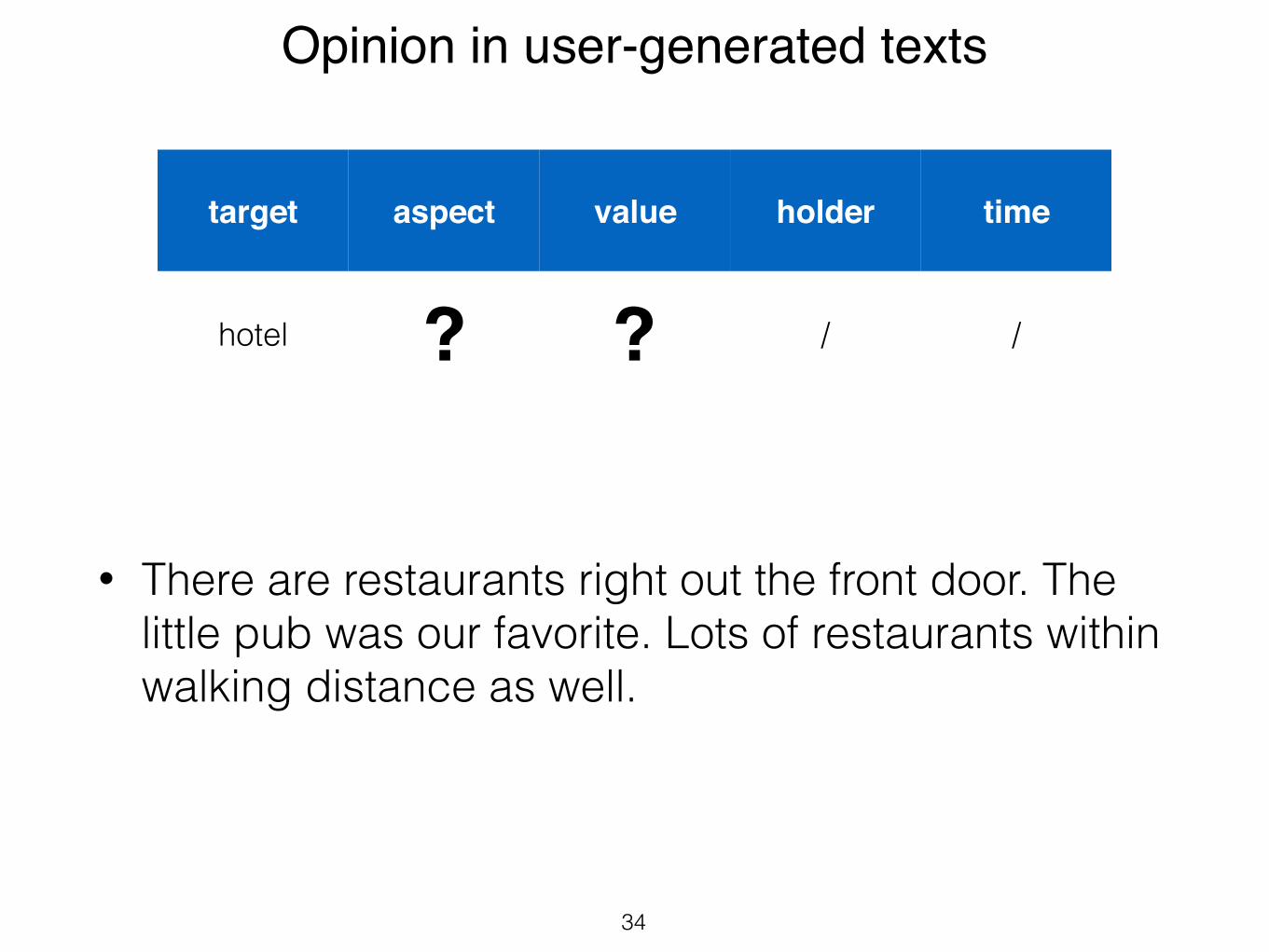
34
target aspect value holder time
hotel ? ? / /
Opinion in user-generated texts
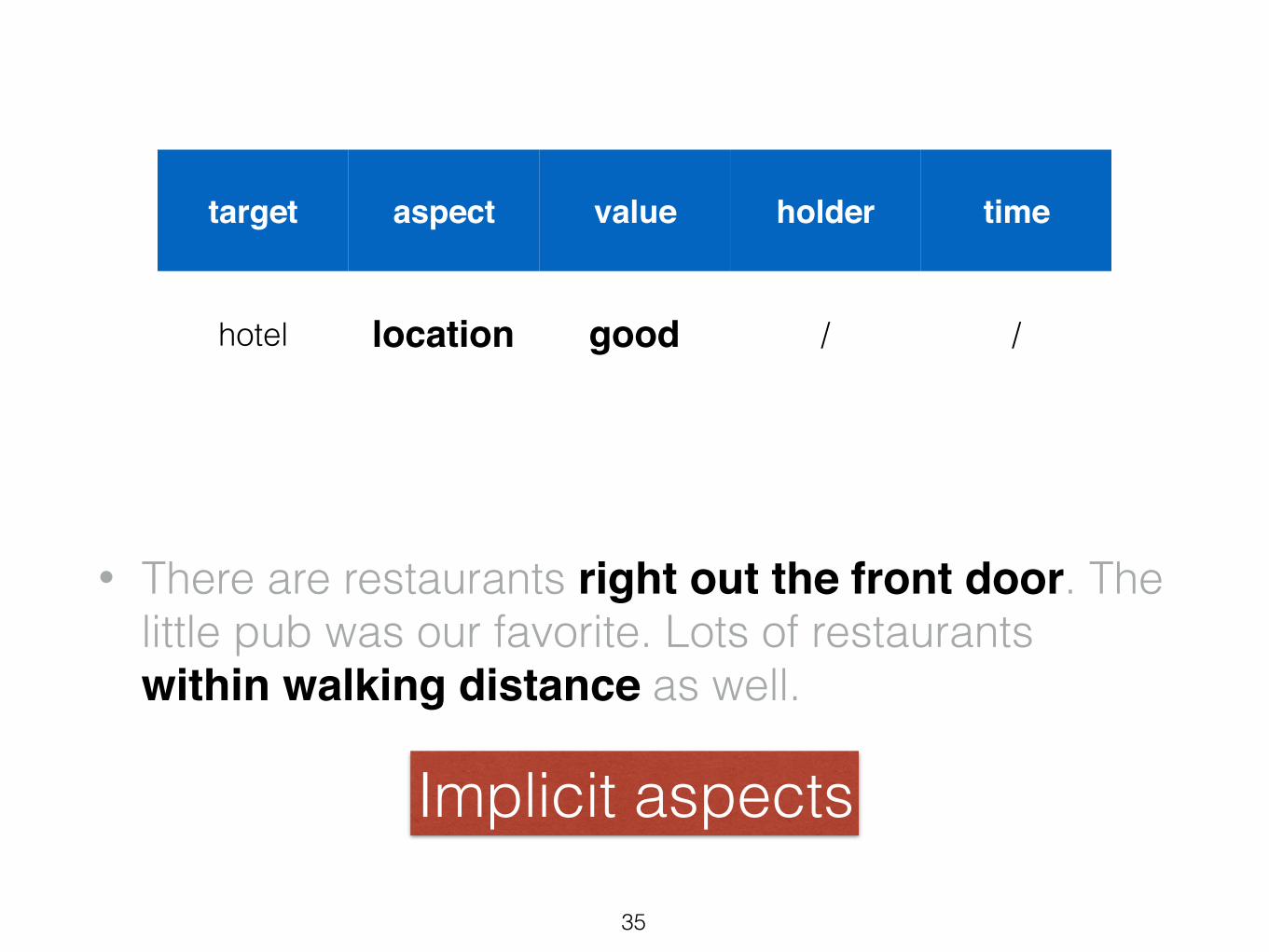
• There are restaurants right out the front door. The little pub was our favorite. Lots of restaurants within walking distance as well.
35
target aspect value holder time
hotel location good / /
Implicit aspects
Tasks• Review summarization
• Sentiment classification
• Subjectivity / objectivity identification
• Opinion holder / target identification
• Sexism / racism detection
• Sarcasm / irony detection
• Humor detection
• Fake review detection
• …
36
unstructured
structured

Aspect-based Opinion Mining
37
unstructured
structured
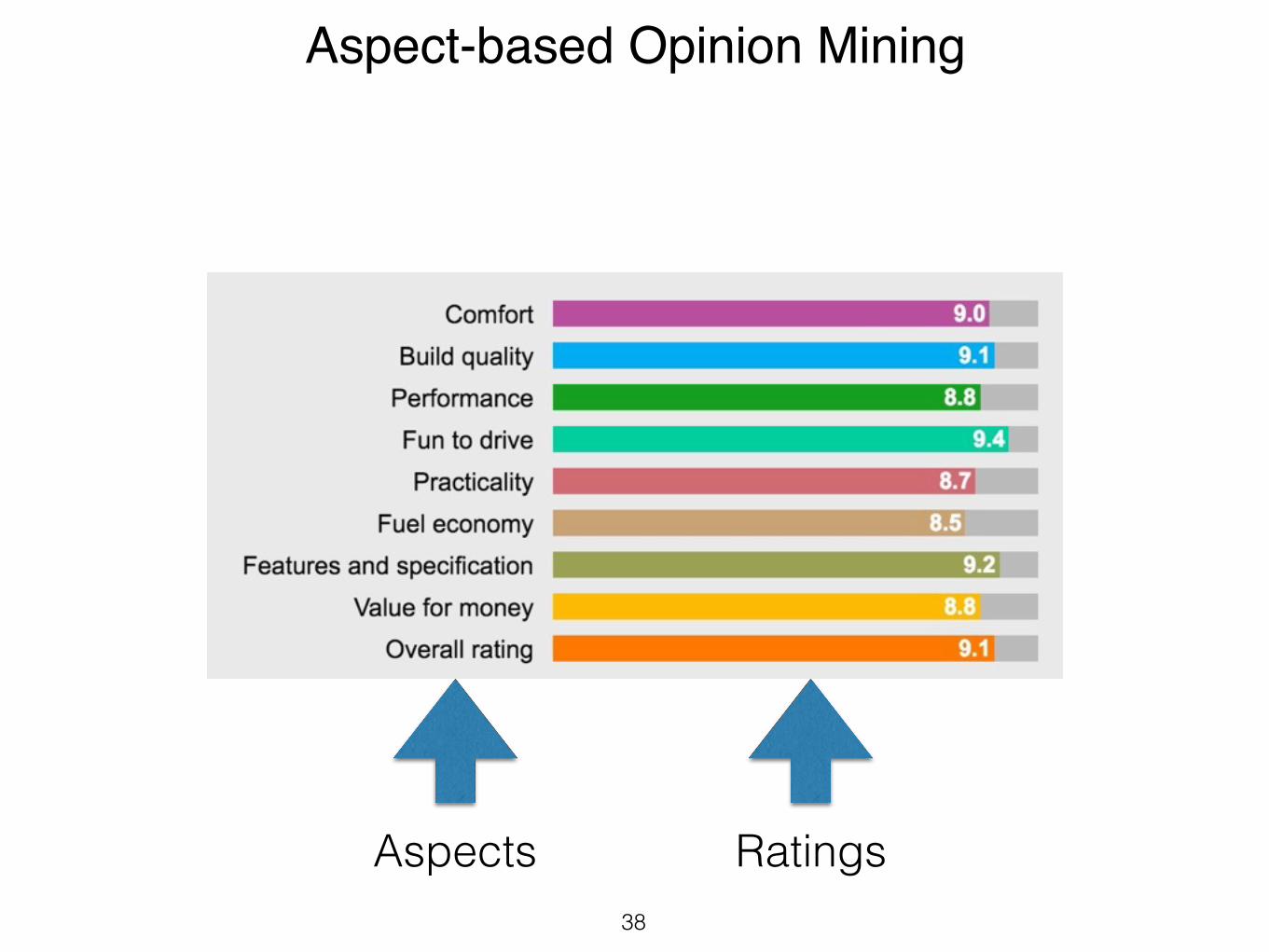
Aspect-based Opinion Mining
38
Aspects Ratings

Sub-tasks in Aspect-based Opinion Mining
• Aspect extraction
• Aspect identification
• Sentiment score prediction
39

Sub-tasks in Aspect-based Opinion Mining
• We focus on the joint inference of aspects and sentiment scores
40
A set of reviews (of some product)
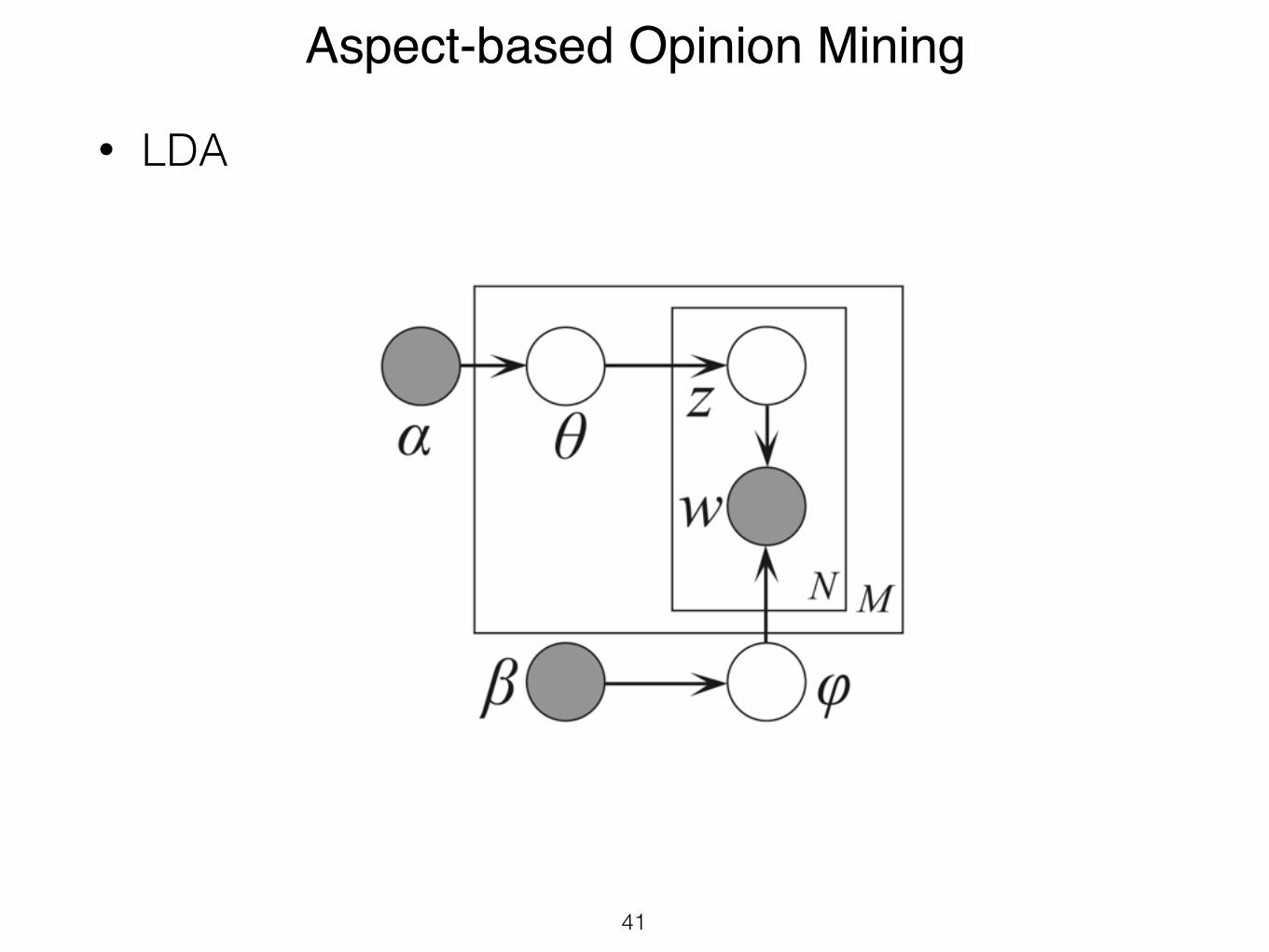
Aspect-based Opinion Mining
• LDA
41
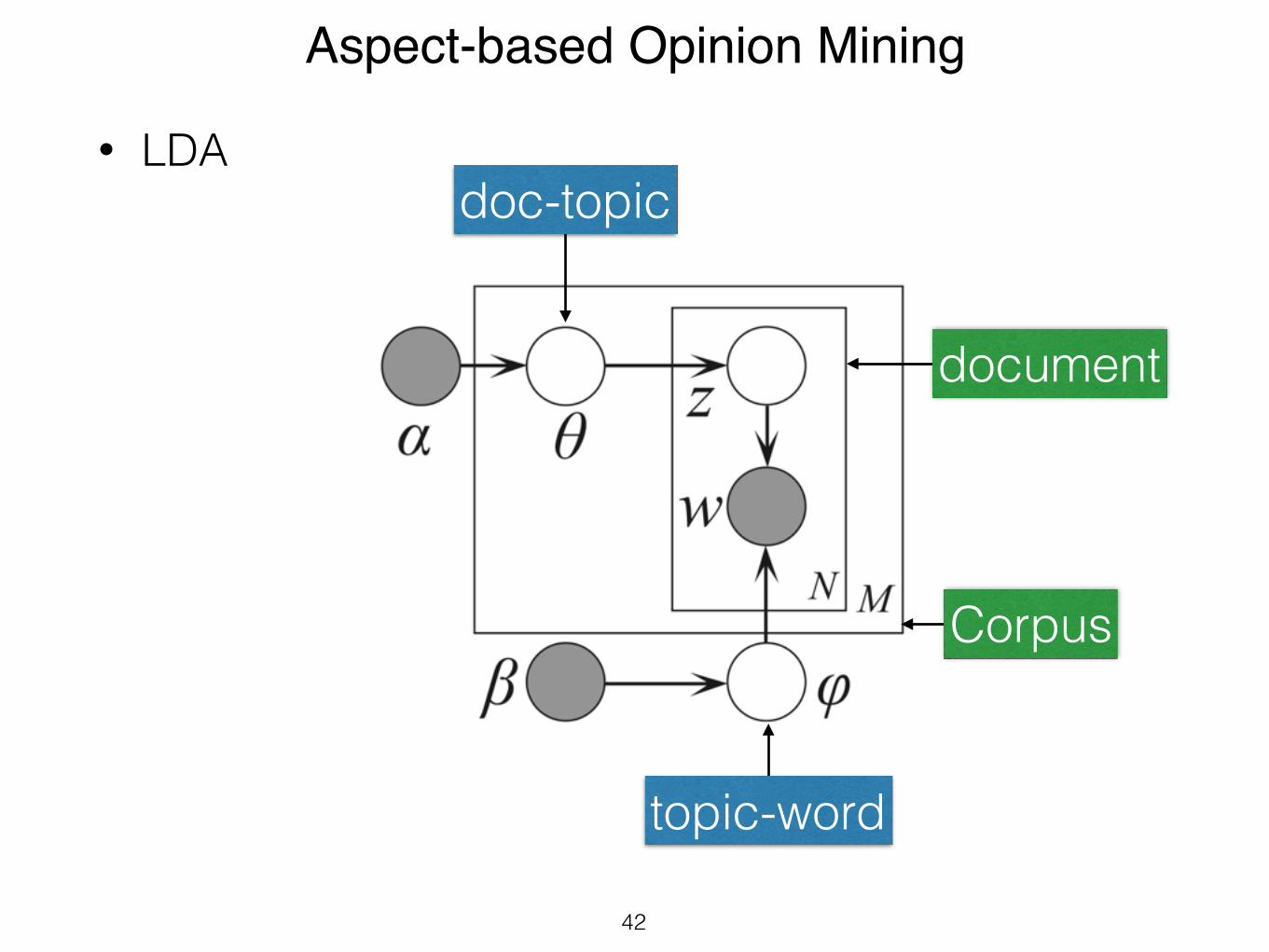
Aspect-based Opinion Mining
• LDA
42
doc-topic
document
Corpus
topic-word
43
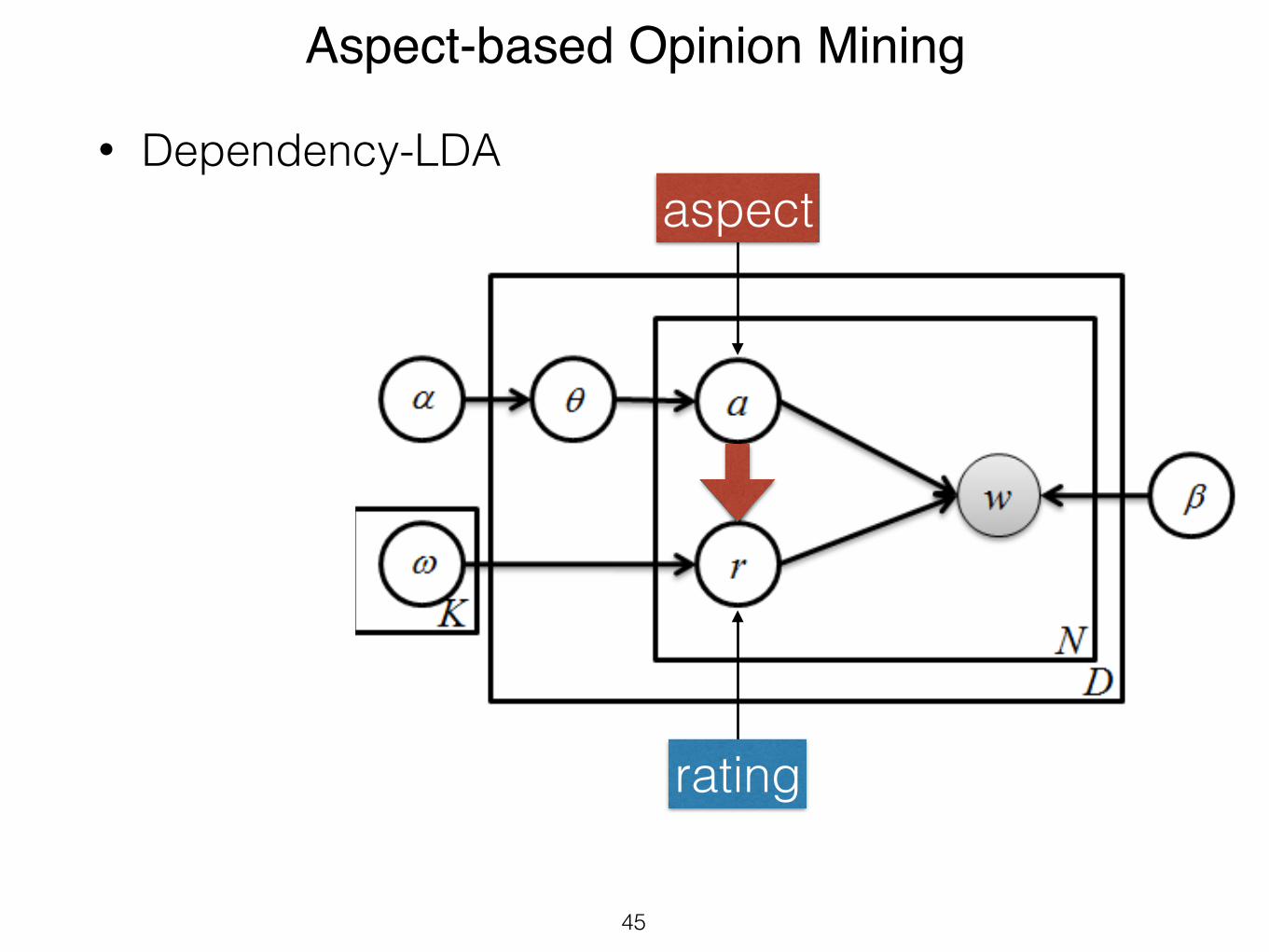
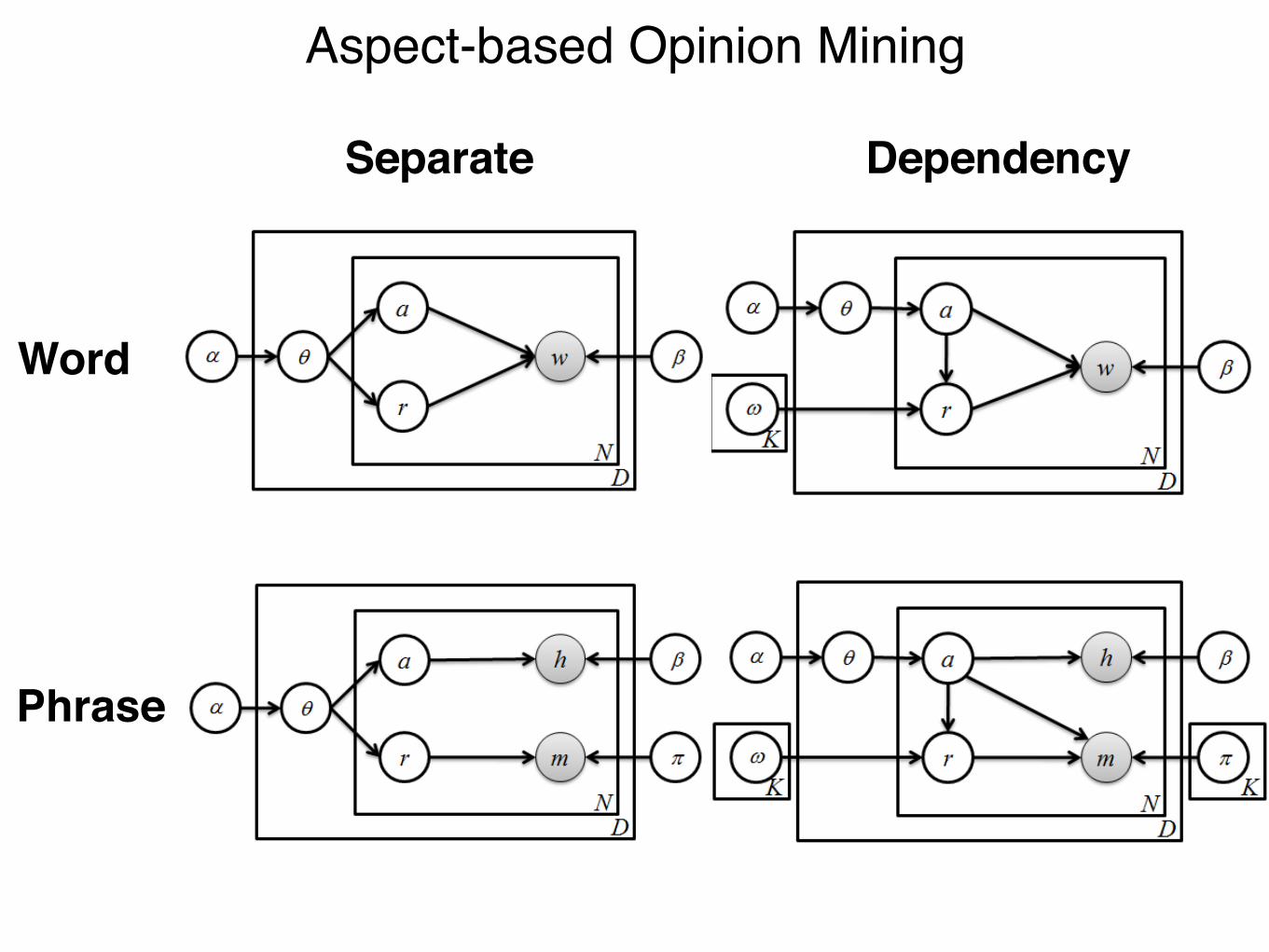
4.3 D-LDADependency-LDA (D-LDA) also models the dependency
between the latent aspects and ratings while learning froma bag-of-words model of reviews (Figure 3). The joint prob-ability distribution of D-LDA considers this dependency:
P (a, r,w, θ|α,β,ω) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (wn|an, rn,β)] (4)
Several models similar to D-LDA have been proposed inthe literature [14, 15, 7, 27, 11]. The model presented in[14] further considers the dependency of the rating from thelocal context. The model proposed in [15] (further extendedin [7]) assumes the dependency of the selected aspect fromthe sampled rating, i.e., the opposite direction of the depen-dency. The authors of [11] also make the same assumptionas [15] and apply the model at the sentence level to extractaspects and ratings.
Figure 3: D-LDA
4.4 PLDAWhile LDA assumes a bag-of-words model, Phrases-LDA
(PLDA) assumes a bag-of-phrases model of product reviews(Figure 4). A review is preprocessed into a bag-of-opinion-phrases < hn,mn > which leads to two observed variableshn (head term) and mn (modifier). Translating this processinto a joint probability distribution results in the expression:
P (z,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (zn|θ)P (hn,mn|zn,β,π)] (5)
In [29] a similar model is applied on opinion phrases toextract topics from reviews. While the generation of opin-ion phrases in [29] is the same as the generative process ofPLDA, their model further assumes that each sentence ofthe review is related to only one topic.
Figure 4: PLDA
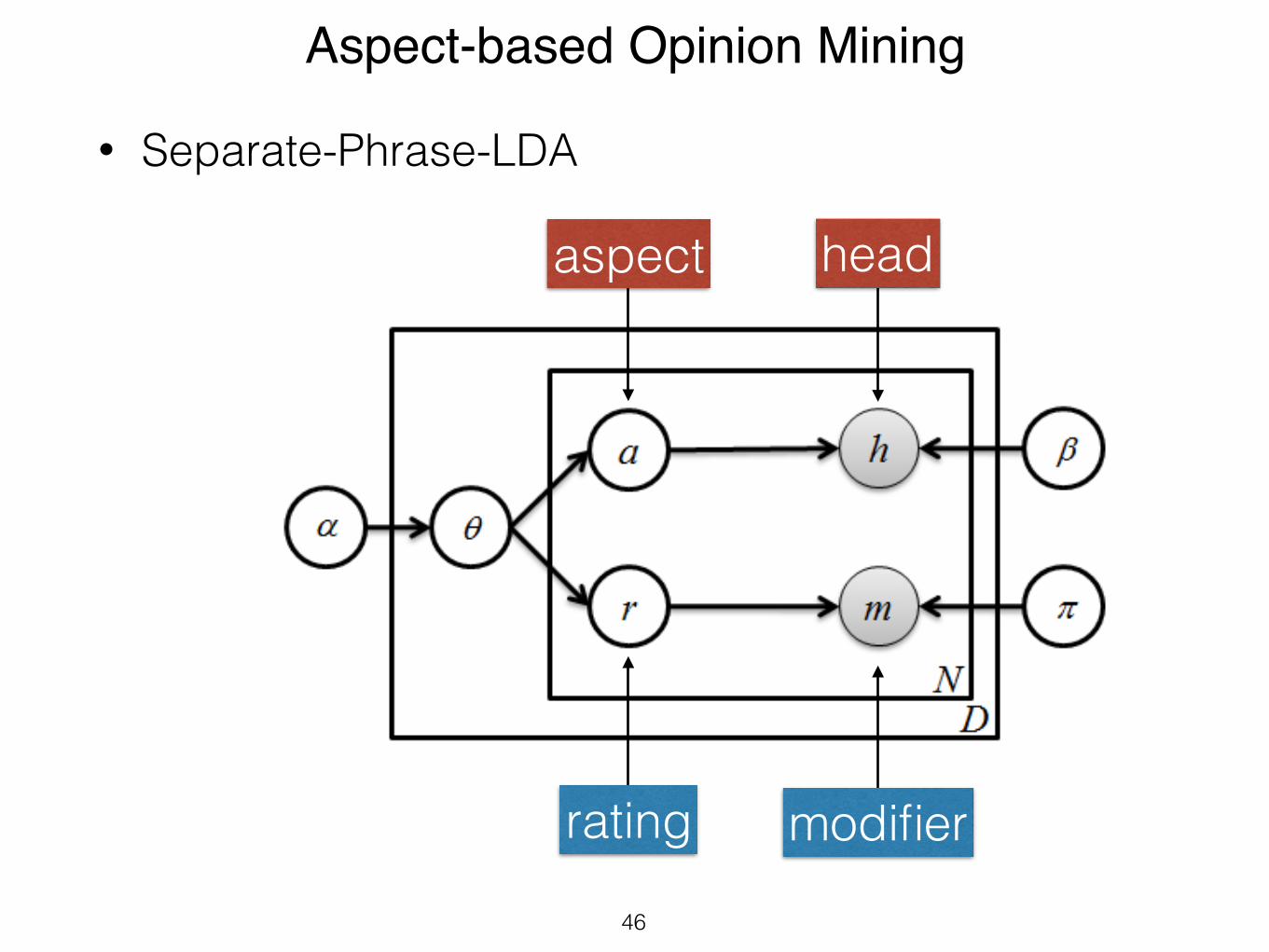
4.5 S-PLDACompared to PLDA, the S-PLDA model introduces a sep-
arate rating variable which is conditionally independent fromthe aspect. In this model a review is assumed to be gen-erated by first choosing a value of θ, and then repeatedly
sampling N aspects and ratings as well as opinion phrases< hn,mn > conditioned on the chosen value of θ. Similarto S-LDA, θ represents the aspect/rating pairs and for everypair, α contains the probability of generating that combina-tion of aspect and rating (Figure 5). The joint probabilitydistribution of S-PLDA is as follows:
P (a, r,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (hn|an,β)P (mn|rn,π)] (6)
P (hn|an,β) and P (mn|rn,π) are multinomial distribu-tions conditioned on the aspect an and rating rn, respec-tively. The same model is presented in [21] as a comparisonpartner.
Figure 5: S-PLDA
4.6 D-PLDASimilar to the step from S-LDA to D-LDA, compared to
S-PLDA, the D-PLDA model adds the dependency betweenratings and aspects. There are various options for dependen-cies between the two latent variables and the two observedvariables. We assume that modifiers depend on the aspectand the rating. To illustrate the importance of this depen-dency, consider the following opinion phrases: ‘low LCDresolution’ and ‘low price’. The modifier ‘low’ expresses anegative opinion for the head term ‘LCD resolution’, whileit is a positive opinion for ‘price’. On the other hand, we as-sume that the rating of an aspect does not affect the choiceof a head term for that aspect.
D-PLDA can be viewed as generative process that firstgenerates an aspect and subsequently generates its rating.In particular, for generating an opinion phrase, this modelfirst generates an aspect an from an LDA model. Then itgenerates a rating rn conditioned on the sampled aspect an.Finally, a head term hn is drawn conditioned on an and amodifier mn is generated conditioned on both the aspect an
and rating rn (Figure 6). D-PLDA specifies the followingjoint distribution:
P (a, r,h,m, θ|α,ω,β,π) = P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (hn|an,β)P (mn|an, rn,π)] (7)
In [21] a similar model is presented. D-PLDA generatesthe modifier conditioned on both aspect and rating, but in[21] only the selected rating generates the modifier.
5. INFERENCE AND ESTIMATIONComputing the posterior distribution of the latent vari-
ables for the LDA models is intractable. Blei et al. [1] pro-posed to obtain a tractable lower bound by modifying the
807
Aspect-based Opinion Mining
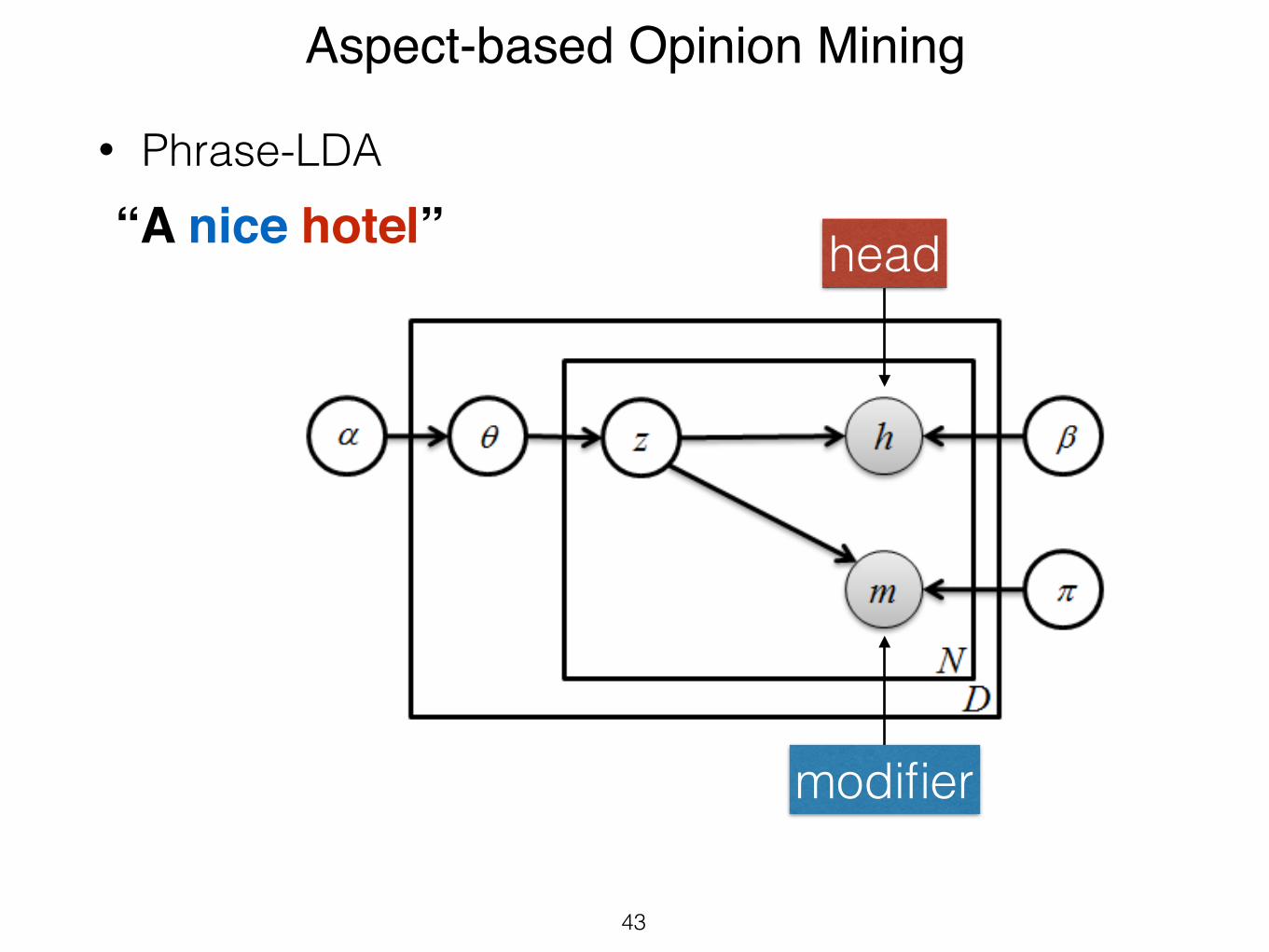
• Phrase-LDA
modifier
“A nice hotel” head

Aspect-based Opinion Mining
44
• Separate-LDA
• Is it better to assume dependency between ratings andaspects?
• Is it better to learn from bag-of-words or preprocessthe reviews and learn from opinion phrases?
• Which preprocessing technique for extracting opinionphrases works best?
• Does the answer to the above questions differ for prod-ucts with few reviews and products with many re-views?
We start our investigation with the basic LDA model [1]and then gradually extend the model by considering differ-ent probabilistic assumptions. In summary we discuss fiveLDA-based models with various underlying assumptions forour problem: S-LDA extends LDA by assuming the review isgenerated by a set of aspects and their ratings. D-LDA addsthe dependency between aspects and their ratings. PLDAlearns one latent variable from opinion phrases. S-PLDAlearns both aspects and their corresponding ratings fromopinion phrases. Finally, D-PLDA learns aspects and rat-ings from opinion phrases while considering the dependencybetween the generated aspects and ratings.We also present a novel technique for extracting opinion
phrases from reviews based on dependency parsing. Differ-ent from current preprocessing methods which are mainlybased on syntactic properties our technique is based on thesemantic relationships between words. We conduct exten-sive experiments on a real life dataset from Epinions.com,and based on the results we propose a set of design guidelinesfor LDA models for aspect-based opinion mining.
4. LDA MODELS FOR ASPECT-BASEDOPINION MINING
In this section, we first briefly discuss the basic LDAmodel for the problem of aspect-based opinion mining. Thenwe introduce a series of models based on LDA making dif-ferent probabilistic assumptions.
4.1 LDALatent Dirichlet Allocation (LDA) is a generative proba-
bilistic model of a corpus [1]. The basic idea is that docu-ments are represented as mixtures over latent topics wheretopics are associated with a distribution over the words ofthe vocabulary. Figure 1 shows the graphical model of thismodel. Following the standard graphical model formalism,nodes represent random variables and edges indicate possi-ble dependency. Shaded nodes are observed random vari-ables and unshaded nodes are latent random variables. Fi-nally, a box around groups of random variables is a ‘plate’which denotes replication. The outer plate represents re-views and the inner plate represents words. D and N denotethe number of product reviews and the number of words ineach review, respectively. In our domain, LDA assumes thefollowing generative process:
1. Sample θ ∼ Dir(α).
2. For each word wn, n ∈ {1, 2, ..., N}
(a) Sample a topic zn ∼ Mult(θ)
(b) Sample a word wn ∼ P (wn|zn,β), a multinomialdistribution conditioned on the topic zn.
Translating this process into a joint probability distribu-tion results in the following expression:
P (z,w, θ|α,β) = P (θ|α)N!
n=1
[P (zn|θ)P (wn|zn,β)] (1)
The key inference problem is to compute the posteriordistribution of the latent variables given a review:
P (z, θ|w,α,β) =P (z,w, θ|α,β)
P (w|α,β) (2)
Since this distribution is intractable to compute (due tothe coupling between θ and β), variational inference is usedto approximate this distribution [1]. We will explain theinference and estimation techniques in Section 5.
Some of the current works [2, 30, 26, 25] apply this modelon reviews to extract topics as product aspects. In [2] and[30], the model has been used at the sentence level. The au-thors of [30] further improve the model by considering differ-ent word distributions for aspects, ratings, and backgroundwords. In [26, 25] the basic LDA model is improved byconsidering different topic distributions for local and globaltopics and is applied at the document level.
Figure 1: LDA
4.2 S-LDAThe second model replaces the one latent variable for top-
ics by two separate variables for aspects and ratings. We callthis model Separate-LDA (S-LDA). For every aspect/ratingpair, θ contains the probability of generating that combina-tion of aspect and rating. The variable θ is sampled onceper review. After sampling θ, the latent variables an andrn are sampled independently (conditional independency),and then a word wn is sampled conditioned on the sampledaspect and rating (Figure 2). The joint probability distri-bution of this model is as follows:
P (a, r,w, θ|α,β) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (wn|an, rn,β)] (3)
A model similar to S-LDA has been proposed in [12],learning two Dirichlet distributions (one for aspects and onefor sentiments) per review. While that model further con-siders the syntactic dependency between words and is morean LDA-HMM model, the generation of words conditionedon both aspects and ratings is the same as the generativeprocess of S-LDA.
Figure 2: S-LDA
806
aspect
rating
“It is very clean”“It is very dirty”
Aspect-based Opinion Mining
45
4.3 D-LDADependency-LDA (D-LDA) also models the dependency
between the latent aspects and ratings while learning froma bag-of-words model of reviews (Figure 3). The joint prob-ability distribution of D-LDA considers this dependency:
P (a, r,w, θ|α,β,ω) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (wn|an, rn,β)] (4)
Several models similar to D-LDA have been proposed inthe literature [14, 15, 7, 27, 11]. The model presented in[14] further considers the dependency of the rating from thelocal context. The model proposed in [15] (further extendedin [7]) assumes the dependency of the selected aspect fromthe sampled rating, i.e., the opposite direction of the depen-dency. The authors of [11] also make the same assumptionas [15] and apply the model at the sentence level to extractaspects and ratings.
Figure 3: D-LDA
4.4 PLDAWhile LDA assumes a bag-of-words model, Phrases-LDA
(PLDA) assumes a bag-of-phrases model of product reviews(Figure 4). A review is preprocessed into a bag-of-opinion-phrases < hn,mn > which leads to two observed variableshn (head term) and mn (modifier). Translating this processinto a joint probability distribution results in the expression:
P (z,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (zn|θ)P (hn,mn|zn,β,π)] (5)
In [29] a similar model is applied on opinion phrases toextract topics from reviews. While the generation of opin-ion phrases in [29] is the same as the generative process ofPLDA, their model further assumes that each sentence ofthe review is related to only one topic.
Figure 4: PLDA
4.5 S-PLDACompared to PLDA, the S-PLDA model introduces a sep-
arate rating variable which is conditionally independent fromthe aspect. In this model a review is assumed to be gen-erated by first choosing a value of θ, and then repeatedly
sampling N aspects and ratings as well as opinion phrases< hn,mn > conditioned on the chosen value of θ. Similarto S-LDA, θ represents the aspect/rating pairs and for everypair, α contains the probability of generating that combina-tion of aspect and rating (Figure 5). The joint probabilitydistribution of S-PLDA is as follows:
P (a, r,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (hn|an,β)P (mn|rn,π)] (6)
P (hn|an,β) and P (mn|rn,π) are multinomial distribu-tions conditioned on the aspect an and rating rn, respec-tively. The same model is presented in [21] as a comparisonpartner.
Figure 5: S-PLDA
4.6 D-PLDASimilar to the step from S-LDA to D-LDA, compared to
S-PLDA, the D-PLDA model adds the dependency betweenratings and aspects. There are various options for dependen-cies between the two latent variables and the two observedvariables. We assume that modifiers depend on the aspectand the rating. To illustrate the importance of this depen-dency, consider the following opinion phrases: ‘low LCDresolution’ and ‘low price’. The modifier ‘low’ expresses anegative opinion for the head term ‘LCD resolution’, whileit is a positive opinion for ‘price’. On the other hand, we as-sume that the rating of an aspect does not affect the choiceof a head term for that aspect.
D-PLDA can be viewed as generative process that firstgenerates an aspect and subsequently generates its rating.In particular, for generating an opinion phrase, this modelfirst generates an aspect an from an LDA model. Then itgenerates a rating rn conditioned on the sampled aspect an.Finally, a head term hn is drawn conditioned on an and amodifier mn is generated conditioned on both the aspect an
and rating rn (Figure 6). D-PLDA specifies the followingjoint distribution:
P (a, r,h,m, θ|α,ω,β,π) = P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (hn|an,β)P (mn|an, rn,π)] (7)
In [21] a similar model is presented. D-PLDA generatesthe modifier conditioned on both aspect and rating, but in[21] only the selected rating generates the modifier.
5. INFERENCE AND ESTIMATIONComputing the posterior distribution of the latent vari-
ables for the LDA models is intractable. Blei et al. [1] pro-posed to obtain a tractable lower bound by modifying the
807
• Dependency-LDAaspect
rating
4.3 D-LDADependency-LDA (D-LDA) also models the dependency
between the latent aspects and ratings while learning froma bag-of-words model of reviews (Figure 3). The joint prob-ability distribution of D-LDA considers this dependency:
P (a, r,w, θ|α,β,ω) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (wn|an, rn,β)] (4)
Several models similar to D-LDA have been proposed inthe literature [14, 15, 7, 27, 11]. The model presented in[14] further considers the dependency of the rating from thelocal context. The model proposed in [15] (further extendedin [7]) assumes the dependency of the selected aspect fromthe sampled rating, i.e., the opposite direction of the depen-dency. The authors of [11] also make the same assumptionas [15] and apply the model at the sentence level to extractaspects and ratings.
Figure 3: D-LDA
4.4 PLDAWhile LDA assumes a bag-of-words model, Phrases-LDA
(PLDA) assumes a bag-of-phrases model of product reviews(Figure 4). A review is preprocessed into a bag-of-opinion-phrases < hn,mn > which leads to two observed variableshn (head term) and mn (modifier). Translating this processinto a joint probability distribution results in the expression:
P (z,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (zn|θ)P (hn,mn|zn,β,π)] (5)
In [29] a similar model is applied on opinion phrases toextract topics from reviews. While the generation of opin-ion phrases in [29] is the same as the generative process ofPLDA, their model further assumes that each sentence ofthe review is related to only one topic.
Figure 4: PLDA
4.5 S-PLDACompared to PLDA, the S-PLDA model introduces a sep-
arate rating variable which is conditionally independent fromthe aspect. In this model a review is assumed to be gen-erated by first choosing a value of θ, and then repeatedly
sampling N aspects and ratings as well as opinion phrases< hn,mn > conditioned on the chosen value of θ. Similarto S-LDA, θ represents the aspect/rating pairs and for everypair, α contains the probability of generating that combina-tion of aspect and rating (Figure 5). The joint probabilitydistribution of S-PLDA is as follows:
P (a, r,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (hn|an,β)P (mn|rn,π)] (6)
P (hn|an,β) and P (mn|rn,π) are multinomial distribu-tions conditioned on the aspect an and rating rn, respec-tively. The same model is presented in [21] as a comparisonpartner.
Figure 5: S-PLDA
4.6 D-PLDASimilar to the step from S-LDA to D-LDA, compared to
S-PLDA, the D-PLDA model adds the dependency betweenratings and aspects. There are various options for dependen-cies between the two latent variables and the two observedvariables. We assume that modifiers depend on the aspectand the rating. To illustrate the importance of this depen-dency, consider the following opinion phrases: ‘low LCDresolution’ and ‘low price’. The modifier ‘low’ expresses anegative opinion for the head term ‘LCD resolution’, whileit is a positive opinion for ‘price’. On the other hand, we as-sume that the rating of an aspect does not affect the choiceof a head term for that aspect.
D-PLDA can be viewed as generative process that firstgenerates an aspect and subsequently generates its rating.In particular, for generating an opinion phrase, this modelfirst generates an aspect an from an LDA model. Then itgenerates a rating rn conditioned on the sampled aspect an.Finally, a head term hn is drawn conditioned on an and amodifier mn is generated conditioned on both the aspect an
and rating rn (Figure 6). D-PLDA specifies the followingjoint distribution:
P (a, r,h,m, θ|α,ω,β,π) = P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (hn|an,β)P (mn|an, rn,π)] (7)
In [21] a similar model is presented. D-PLDA generatesthe modifier conditioned on both aspect and rating, but in[21] only the selected rating generates the modifier.
5. INFERENCE AND ESTIMATIONComputing the posterior distribution of the latent vari-
ables for the LDA models is intractable. Blei et al. [1] pro-posed to obtain a tractable lower bound by modifying the
807
Aspect-based Opinion Mining
46
• Separate-Phrase-LDA
aspect head
rating modifier
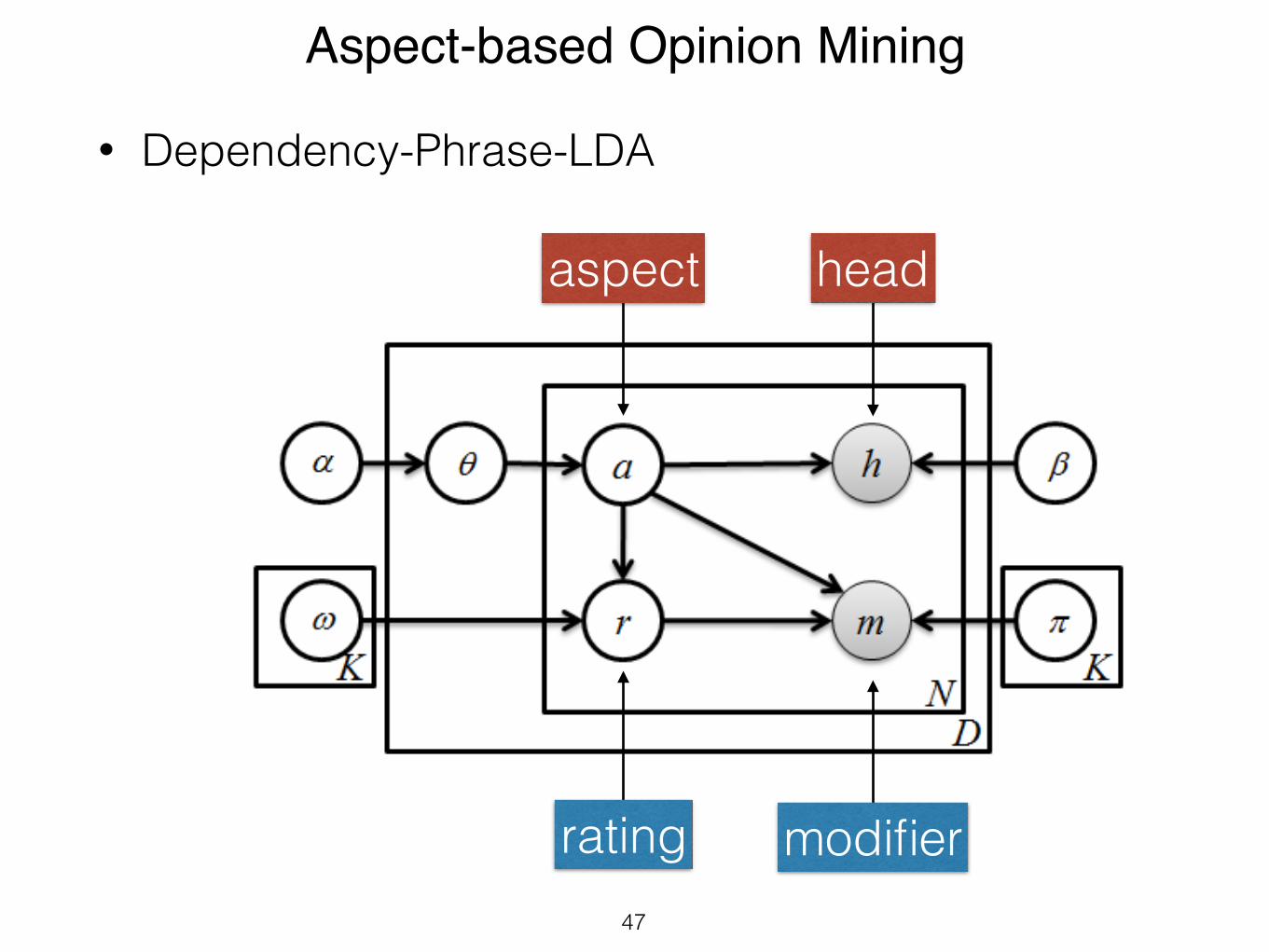
Figure 6: D-PLDA
graphical model through considering a variational Dirich-let parameter for generating θ and a variational multino-mial parameter for generating each latent variable. In agood approximation, the KL-divergence between the varia-tional distribution and the true posterior will be minimum.So, by setting the derivative of the KL-divergence with re-spect to variational parameters equal to zero, the updateequations can be obtained. Using Variational Estimation-Maximization (EM) technique [1], a lower bound on theposterior probability can be obtained.Regarding the computational complexity, each iteration
of variational inference for the basic LDA requires O(Nk)operations [1] where k is the number of topics. Accordingto the variational inference algorithms, S-LDA and D-LDArequire O(5Nk), PLDA and S-PLDA require O(2Nk), andD-PLDA require O(6Nk) operations for each iteration. Asstated in [1], the number of iterations required for a singledocument is on the order of the number of words in thedocument. This means that the total number of operationsfor the LDA models is roughly on the order of O(N2k).When working with conditional distributions, over-fitting
is always a serious problem [1]. A new review is very likelyto contain words that did not appear in any of the reviewsin a training corpus. Maximum likelihood estimate of themodel parameters assign zero probability to such words, andso zero probability to new reviews. Smoothing is a standardapproach to dealing with this problem [1]. We smooth all theparameters which depend on the observed data by assigningpositive probability to all vocabulary terms whether or notthey are observed in the training set.Finally, when estimating model parameters using maxi-
mum likelihood estimation, it is possible to increase the like-lihood by adding parameters, which may however result inover-fitting. Since our goal is to compare the average perfor-mance of different models, we perform our experiments fordifferent values of k. Note that, before applying the modelson reviews, we first apply the Porter Stemmer algorithm [24]and then remove stop words using a standard lists of stopwords2.
6. EXTRACTION OF OPINION PHRASESBag-of-words is a popular representation of documents in
text processing. In the area of aspect-based opinion miningmost of the current works [2, 30, 26, 25, 12, 14, 15, 7, 27, 11]adopt this representation of reviews. However, it is not clearwhether representing a review as a bag of words is sufficientfor this problem. Some of the recent works [29, 21] proposeto preprocess the product reviews to extract opinion phrasesand present LDA models that generate only opinion phrases.These works typically use some simple parsing techniques
2http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words
to extract pairs of frequent noun and nearest adjective, oruse POS patterns, e.g. “[adjective] [noun]”, “[noun] [verb][adjective]”, etc.
In this section, we present a novel method for extractingopinion phrases based on the Stanford Dependency parser[20], which is a parser widely used in the area of text mining.A dependency parser determines the semantic relationshipsbetween words and promises to generate opinion phrasesmore accurately than methods that consider only the prox-imity of words. Dependency parsers provide a simple de-scription of the grammatical relationships in a sentence. Inthe following, we briefly explain the grammatical relations[20] we use:
• Adjectival complement (acomp): An adjectival phrasewhich functions as the complement, e.g., “The auto-mode works amazing” parsed to ‘acomp(works, amaz-ing)’.
• Adjectival modifier (amod): An adjectival phrase thatserves to modify the meaning of a noun phrase, e.g.,“It has a wide screen” parsed to ‘amod(screen, wide)’;
• “And” conjunct (conj and): A relation between twoelements connected by the coordinating conjunction“and”, e.g., “The LCD is small and blurry” parsed to‘conj and(small, blurry)’.
• Copula (cop): A relation between the complement of acopular verb and the copular verb, e.g., “The batteriesare ok” parsed to ‘cop(ok, are)’.
• Direct object (dobj ): A noun phrase which is the ob-ject of the verb, e.g., “I like the auto-focus” parsed to‘dobj(like, auto-focus)’.
• Negation modifier (neg): A relation between a nega-tion word and the word it modifies, e.g., “The shutterlag is’n fast” parsed to ‘neg(fast, n’t)’.
• Noun compound modifier (nn): A noun that serves tomodify the head noun, e.g., “The shutter lag is’n fast”parsed to ‘nn(lag, shutter)’.
• Nominal subject (nsubj ): A noun phrase which is thesyntactic subject of a clause, e.g., “The zoom is disap-pointing” parsed to ‘nsubj(disappointing, zoom)’.
We employ these grammatical relations to define a set ofdependency patterns for extracting opinion phrases. In thefollowing we list the extraction patterns (N indicates a noun,A an adjective, V a verb, h a head term, m a modifier, and <h,m > an opinion phrase). Table 1 shows some examples ofhow these patterns are used for extracting opinion phrases.
1. amod(N,A) →< N,A >
2. acomp(V,A) + nsubj(V,N) →< N,A >
3. cop(A, V ) + nsubj(A,N) →< N,A >
4. dobj(V,N) + nsubj(V,N ′) →< N,V >
5. < h1,m > +conj and(h1, h2) →< h2,m >
6. < h,m1 > +conj and(m1,m2) →< h,m2 >
7. < h,m > +neg(m,not) →< h, not+m >
8. < h,m > +nn(h,N) →< N + h,m >
9. < h,m > +nn(N,h) →< h+N,m >
808
Aspect-based Opinion Mining
47
• Dependency-Phrase-LDA
aspect head
rating modifier
Aspect-based Opinion Mining4.3 D-LDADependency-LDA (D-LDA) also models the dependency
between the latent aspects and ratings while learning froma bag-of-words model of reviews (Figure 3). The joint prob-ability distribution of D-LDA considers this dependency:
P (a, r,w, θ|α,β,ω) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (wn|an, rn,β)] (4)
Several models similar to D-LDA have been proposed inthe literature [14, 15, 7, 27, 11]. The model presented in[14] further considers the dependency of the rating from thelocal context. The model proposed in [15] (further extendedin [7]) assumes the dependency of the selected aspect fromthe sampled rating, i.e., the opposite direction of the depen-dency. The authors of [11] also make the same assumptionas [15] and apply the model at the sentence level to extractaspects and ratings.
Figure 3: D-LDA
4.4 PLDAWhile LDA assumes a bag-of-words model, Phrases-LDA
(PLDA) assumes a bag-of-phrases model of product reviews(Figure 4). A review is preprocessed into a bag-of-opinion-phrases < hn,mn > which leads to two observed variableshn (head term) and mn (modifier). Translating this processinto a joint probability distribution results in the expression:
P (z,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (zn|θ)P (hn,mn|zn,β,π)] (5)
In [29] a similar model is applied on opinion phrases toextract topics from reviews. While the generation of opin-ion phrases in [29] is the same as the generative process ofPLDA, their model further assumes that each sentence ofthe review is related to only one topic.
Figure 4: PLDA
4.5 S-PLDACompared to PLDA, the S-PLDA model introduces a sep-
arate rating variable which is conditionally independent fromthe aspect. In this model a review is assumed to be gen-erated by first choosing a value of θ, and then repeatedly
sampling N aspects and ratings as well as opinion phrases< hn,mn > conditioned on the chosen value of θ. Similarto S-LDA, θ represents the aspect/rating pairs and for everypair, α contains the probability of generating that combina-tion of aspect and rating (Figure 5). The joint probabilitydistribution of S-PLDA is as follows:
P (a, r,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (hn|an,β)P (mn|rn,π)] (6)
P (hn|an,β) and P (mn|rn,π) are multinomial distribu-tions conditioned on the aspect an and rating rn, respec-tively. The same model is presented in [21] as a comparisonpartner.
Figure 5: S-PLDA
4.6 D-PLDASimilar to the step from S-LDA to D-LDA, compared to
S-PLDA, the D-PLDA model adds the dependency betweenratings and aspects. There are various options for dependen-cies between the two latent variables and the two observedvariables. We assume that modifiers depend on the aspectand the rating. To illustrate the importance of this depen-dency, consider the following opinion phrases: ‘low LCDresolution’ and ‘low price’. The modifier ‘low’ expresses anegative opinion for the head term ‘LCD resolution’, whileit is a positive opinion for ‘price’. On the other hand, we as-sume that the rating of an aspect does not affect the choiceof a head term for that aspect.
D-PLDA can be viewed as generative process that firstgenerates an aspect and subsequently generates its rating.In particular, for generating an opinion phrase, this modelfirst generates an aspect an from an LDA model. Then itgenerates a rating rn conditioned on the sampled aspect an.Finally, a head term hn is drawn conditioned on an and amodifier mn is generated conditioned on both the aspect an
and rating rn (Figure 6). D-PLDA specifies the followingjoint distribution:
P (a, r,h,m, θ|α,ω,β,π) = P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (hn|an,β)P (mn|an, rn,π)] (7)
In [21] a similar model is presented. D-PLDA generatesthe modifier conditioned on both aspect and rating, but in[21] only the selected rating generates the modifier.
5. INFERENCE AND ESTIMATIONComputing the posterior distribution of the latent vari-
ables for the LDA models is intractable. Blei et al. [1] pro-posed to obtain a tractable lower bound by modifying the
807
Figure 6: D-PLDA
graphical model through considering a variational Dirich-let parameter for generating θ and a variational multino-mial parameter for generating each latent variable. In agood approximation, the KL-divergence between the varia-tional distribution and the true posterior will be minimum.So, by setting the derivative of the KL-divergence with re-spect to variational parameters equal to zero, the updateequations can be obtained. Using Variational Estimation-Maximization (EM) technique [1], a lower bound on theposterior probability can be obtained.Regarding the computational complexity, each iteration
of variational inference for the basic LDA requires O(Nk)operations [1] where k is the number of topics. Accordingto the variational inference algorithms, S-LDA and D-LDArequire O(5Nk), PLDA and S-PLDA require O(2Nk), andD-PLDA require O(6Nk) operations for each iteration. Asstated in [1], the number of iterations required for a singledocument is on the order of the number of words in thedocument. This means that the total number of operationsfor the LDA models is roughly on the order of O(N2k).When working with conditional distributions, over-fitting
is always a serious problem [1]. A new review is very likelyto contain words that did not appear in any of the reviewsin a training corpus. Maximum likelihood estimate of themodel parameters assign zero probability to such words, andso zero probability to new reviews. Smoothing is a standardapproach to dealing with this problem [1]. We smooth all theparameters which depend on the observed data by assigningpositive probability to all vocabulary terms whether or notthey are observed in the training set.Finally, when estimating model parameters using maxi-
mum likelihood estimation, it is possible to increase the like-lihood by adding parameters, which may however result inover-fitting. Since our goal is to compare the average perfor-mance of different models, we perform our experiments fordifferent values of k. Note that, before applying the modelson reviews, we first apply the Porter Stemmer algorithm [24]and then remove stop words using a standard lists of stopwords2.
6. EXTRACTION OF OPINION PHRASESBag-of-words is a popular representation of documents in
text processing. In the area of aspect-based opinion miningmost of the current works [2, 30, 26, 25, 12, 14, 15, 7, 27, 11]adopt this representation of reviews. However, it is not clearwhether representing a review as a bag of words is sufficientfor this problem. Some of the recent works [29, 21] proposeto preprocess the product reviews to extract opinion phrasesand present LDA models that generate only opinion phrases.These works typically use some simple parsing techniques
2http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words
to extract pairs of frequent noun and nearest adjective, oruse POS patterns, e.g. “[adjective] [noun]”, “[noun] [verb][adjective]”, etc.
In this section, we present a novel method for extractingopinion phrases based on the Stanford Dependency parser[20], which is a parser widely used in the area of text mining.A dependency parser determines the semantic relationshipsbetween words and promises to generate opinion phrasesmore accurately than methods that consider only the prox-imity of words. Dependency parsers provide a simple de-scription of the grammatical relationships in a sentence. Inthe following, we briefly explain the grammatical relations[20] we use:
• Adjectival complement (acomp): An adjectival phrasewhich functions as the complement, e.g., “The auto-mode works amazing” parsed to ‘acomp(works, amaz-ing)’.
• Adjectival modifier (amod): An adjectival phrase thatserves to modify the meaning of a noun phrase, e.g.,“It has a wide screen” parsed to ‘amod(screen, wide)’;
• “And” conjunct (conj and): A relation between twoelements connected by the coordinating conjunction“and”, e.g., “The LCD is small and blurry” parsed to‘conj and(small, blurry)’.
• Copula (cop): A relation between the complement of acopular verb and the copular verb, e.g., “The batteriesare ok” parsed to ‘cop(ok, are)’.
• Direct object (dobj ): A noun phrase which is the ob-ject of the verb, e.g., “I like the auto-focus” parsed to‘dobj(like, auto-focus)’.
• Negation modifier (neg): A relation between a nega-tion word and the word it modifies, e.g., “The shutterlag is’n fast” parsed to ‘neg(fast, n’t)’.
• Noun compound modifier (nn): A noun that serves tomodify the head noun, e.g., “The shutter lag is’n fast”parsed to ‘nn(lag, shutter)’.
• Nominal subject (nsubj ): A noun phrase which is thesyntactic subject of a clause, e.g., “The zoom is disap-pointing” parsed to ‘nsubj(disappointing, zoom)’.
We employ these grammatical relations to define a set ofdependency patterns for extracting opinion phrases. In thefollowing we list the extraction patterns (N indicates a noun,A an adjective, V a verb, h a head term, m a modifier, and <h,m > an opinion phrase). Table 1 shows some examples ofhow these patterns are used for extracting opinion phrases.
1. amod(N,A) →< N,A >
2. acomp(V,A) + nsubj(V,N) →< N,A >
3. cop(A, V ) + nsubj(A,N) →< N,A >
4. dobj(V,N) + nsubj(V,N ′) →< N,V >
5. < h1,m > +conj and(h1, h2) →< h2,m >
6. < h,m1 > +conj and(m1,m2) →< h,m2 >
7. < h,m > +neg(m,not) →< h, not+m >
8. < h,m > +nn(h,N) →< N + h,m >
9. < h,m > +nn(N,h) →< h+N,m >
808
• Is it better to assume dependency between ratings andaspects?
• Is it better to learn from bag-of-words or preprocessthe reviews and learn from opinion phrases?
• Which preprocessing technique for extracting opinionphrases works best?
• Does the answer to the above questions differ for prod-ucts with few reviews and products with many re-views?
We start our investigation with the basic LDA model [1]and then gradually extend the model by considering differ-ent probabilistic assumptions. In summary we discuss fiveLDA-based models with various underlying assumptions forour problem: S-LDA extends LDA by assuming the review isgenerated by a set of aspects and their ratings. D-LDA addsthe dependency between aspects and their ratings. PLDAlearns one latent variable from opinion phrases. S-PLDAlearns both aspects and their corresponding ratings fromopinion phrases. Finally, D-PLDA learns aspects and rat-ings from opinion phrases while considering the dependencybetween the generated aspects and ratings.We also present a novel technique for extracting opinion
phrases from reviews based on dependency parsing. Differ-ent from current preprocessing methods which are mainlybased on syntactic properties our technique is based on thesemantic relationships between words. We conduct exten-sive experiments on a real life dataset from Epinions.com,and based on the results we propose a set of design guidelinesfor LDA models for aspect-based opinion mining.
4. LDA MODELS FOR ASPECT-BASEDOPINION MINING
In this section, we first briefly discuss the basic LDAmodel for the problem of aspect-based opinion mining. Thenwe introduce a series of models based on LDA making dif-ferent probabilistic assumptions.
4.1 LDALatent Dirichlet Allocation (LDA) is a generative proba-
bilistic model of a corpus [1]. The basic idea is that docu-ments are represented as mixtures over latent topics wheretopics are associated with a distribution over the words ofthe vocabulary. Figure 1 shows the graphical model of thismodel. Following the standard graphical model formalism,nodes represent random variables and edges indicate possi-ble dependency. Shaded nodes are observed random vari-ables and unshaded nodes are latent random variables. Fi-nally, a box around groups of random variables is a ‘plate’which denotes replication. The outer plate represents re-views and the inner plate represents words. D and N denotethe number of product reviews and the number of words ineach review, respectively. In our domain, LDA assumes thefollowing generative process:
1. Sample θ ∼ Dir(α).
2. For each word wn, n ∈ {1, 2, ..., N}
(a) Sample a topic zn ∼ Mult(θ)
(b) Sample a word wn ∼ P (wn|zn,β), a multinomialdistribution conditioned on the topic zn.
Translating this process into a joint probability distribu-tion results in the following expression:
P (z,w, θ|α,β) = P (θ|α)N!
n=1
[P (zn|θ)P (wn|zn,β)] (1)
The key inference problem is to compute the posteriordistribution of the latent variables given a review:
P (z, θ|w,α,β) =P (z,w, θ|α,β)
P (w|α,β) (2)
Since this distribution is intractable to compute (due tothe coupling between θ and β), variational inference is usedto approximate this distribution [1]. We will explain theinference and estimation techniques in Section 5.
Some of the current works [2, 30, 26, 25] apply this modelon reviews to extract topics as product aspects. In [2] and[30], the model has been used at the sentence level. The au-thors of [30] further improve the model by considering differ-ent word distributions for aspects, ratings, and backgroundwords. In [26, 25] the basic LDA model is improved byconsidering different topic distributions for local and globaltopics and is applied at the document level.
Figure 1: LDA
4.2 S-LDAThe second model replaces the one latent variable for top-
ics by two separate variables for aspects and ratings. We callthis model Separate-LDA (S-LDA). For every aspect/ratingpair, θ contains the probability of generating that combina-tion of aspect and rating. The variable θ is sampled onceper review. After sampling θ, the latent variables an andrn are sampled independently (conditional independency),and then a word wn is sampled conditioned on the sampledaspect and rating (Figure 2). The joint probability distri-bution of this model is as follows:
P (a, r,w, θ|α,β) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (wn|an, rn,β)] (3)
A model similar to S-LDA has been proposed in [12],learning two Dirichlet distributions (one for aspects and onefor sentiments) per review. While that model further con-siders the syntactic dependency between words and is morean LDA-HMM model, the generation of words conditionedon both aspects and ratings is the same as the generativeprocess of S-LDA.
Figure 2: S-LDA
806
4.3 D-LDADependency-LDA (D-LDA) also models the dependency
between the latent aspects and ratings while learning froma bag-of-words model of reviews (Figure 3). The joint prob-ability distribution of D-LDA considers this dependency:
P (a, r,w, θ|α,β,ω) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (wn|an, rn,β)] (4)
Several models similar to D-LDA have been proposed inthe literature [14, 15, 7, 27, 11]. The model presented in[14] further considers the dependency of the rating from thelocal context. The model proposed in [15] (further extendedin [7]) assumes the dependency of the selected aspect fromthe sampled rating, i.e., the opposite direction of the depen-dency. The authors of [11] also make the same assumptionas [15] and apply the model at the sentence level to extractaspects and ratings.
Figure 3: D-LDA
4.4 PLDAWhile LDA assumes a bag-of-words model, Phrases-LDA
(PLDA) assumes a bag-of-phrases model of product reviews(Figure 4). A review is preprocessed into a bag-of-opinion-phrases < hn,mn > which leads to two observed variableshn (head term) and mn (modifier). Translating this processinto a joint probability distribution results in the expression:
P (z,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (zn|θ)P (hn,mn|zn,β,π)] (5)
In [29] a similar model is applied on opinion phrases toextract topics from reviews. While the generation of opin-ion phrases in [29] is the same as the generative process ofPLDA, their model further assumes that each sentence ofthe review is related to only one topic.
Figure 4: PLDA
4.5 S-PLDACompared to PLDA, the S-PLDA model introduces a sep-
arate rating variable which is conditionally independent fromthe aspect. In this model a review is assumed to be gen-erated by first choosing a value of θ, and then repeatedly
sampling N aspects and ratings as well as opinion phrases< hn,mn > conditioned on the chosen value of θ. Similarto S-LDA, θ represents the aspect/rating pairs and for everypair, α contains the probability of generating that combina-tion of aspect and rating (Figure 5). The joint probabilitydistribution of S-PLDA is as follows:
P (a, r,h,m, θ|α,β,π) =
P (θ|α)N!
n=1
[P (an|θ)P (rn|θ)P (hn|an,β)P (mn|rn,π)] (6)
P (hn|an,β) and P (mn|rn,π) are multinomial distribu-tions conditioned on the aspect an and rating rn, respec-tively. The same model is presented in [21] as a comparisonpartner.
Figure 5: S-PLDA
4.6 D-PLDASimilar to the step from S-LDA to D-LDA, compared to
S-PLDA, the D-PLDA model adds the dependency betweenratings and aspects. There are various options for dependen-cies between the two latent variables and the two observedvariables. We assume that modifiers depend on the aspectand the rating. To illustrate the importance of this depen-dency, consider the following opinion phrases: ‘low LCDresolution’ and ‘low price’. The modifier ‘low’ expresses anegative opinion for the head term ‘LCD resolution’, whileit is a positive opinion for ‘price’. On the other hand, we as-sume that the rating of an aspect does not affect the choiceof a head term for that aspect.
D-PLDA can be viewed as generative process that firstgenerates an aspect and subsequently generates its rating.In particular, for generating an opinion phrase, this modelfirst generates an aspect an from an LDA model. Then itgenerates a rating rn conditioned on the sampled aspect an.Finally, a head term hn is drawn conditioned on an and amodifier mn is generated conditioned on both the aspect an
and rating rn (Figure 6). D-PLDA specifies the followingjoint distribution:
P (a, r,h,m, θ|α,ω,β,π) = P (θ|α)N!
n=1
[P (an|θ)P (rn|an,ω)P (hn|an,β)P (mn|an, rn,π)] (7)
In [21] a similar model is presented. D-PLDA generatesthe modifier conditioned on both aspect and rating, but in[21] only the selected rating generates the modifier.
5. INFERENCE AND ESTIMATIONComputing the posterior distribution of the latent vari-
ables for the LDA models is intractable. Blei et al. [1] pro-posed to obtain a tractable lower bound by modifying the
807
Word
Phrase
Separate Dependency
49
Aspect-based Opinion Mining
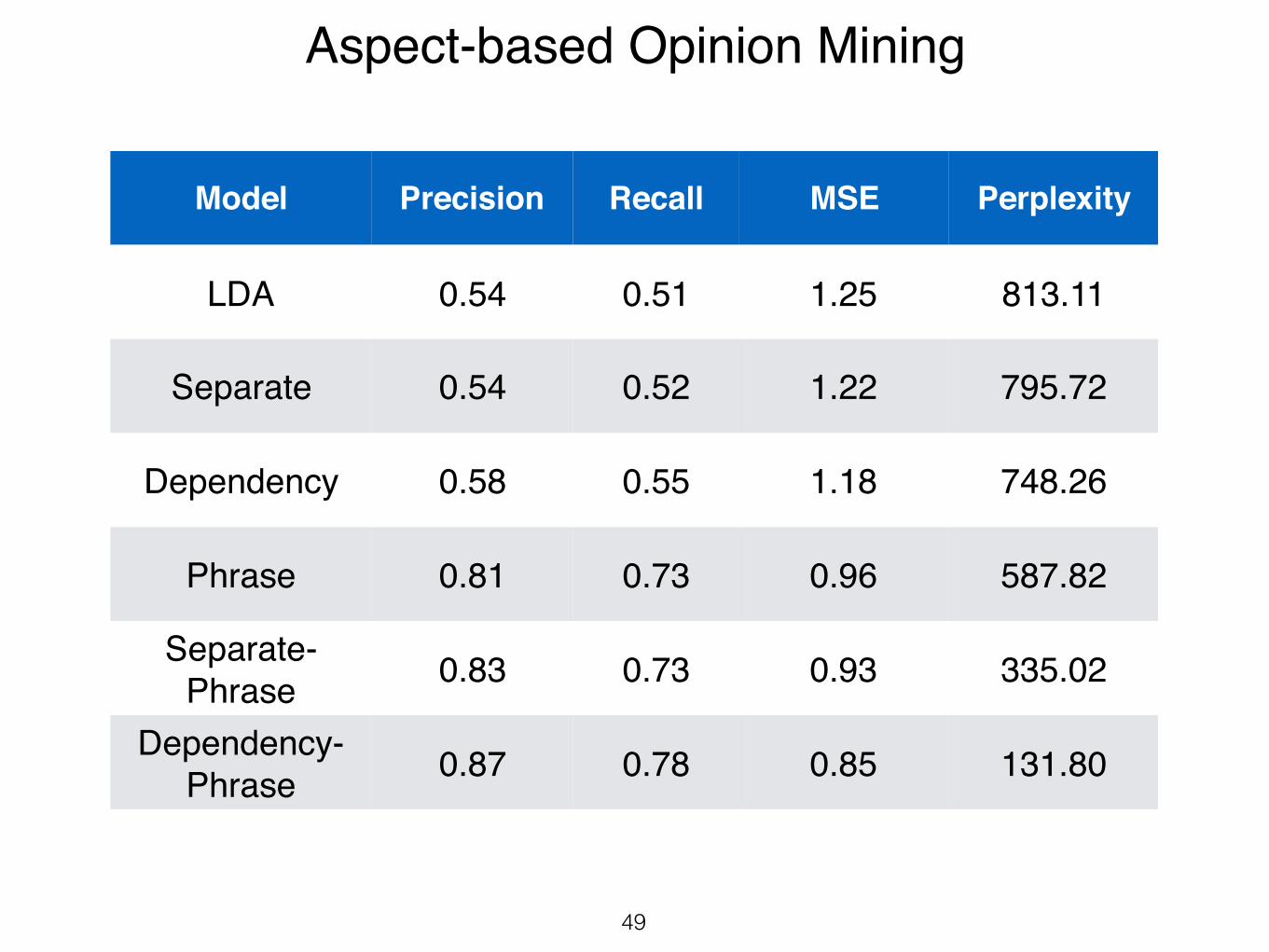
Model Precision Recall MSE Perplexity
LDA 0.54 0.51 1.25 813.11
Separate 0.54 0.52 1.22 795.72
Dependency 0.58 0.55 1.18 748.26
Phrase 0.81 0.73 0.96 587.82
Separate-Phrase 0.83 0.73 0.93 335.02
Dependency-Phrase 0.87 0.78 0.85 131.80
Sentiment Classification
• Binary, multi-class, regression, ranking…
• Popular datasets
• IMDB: 50,000; 3/10 classes
• Stanford Sentiment Treebank: 11,855; 5 classes
50
“The movie was fantastic!”

Let’s use Deep Learning!
51
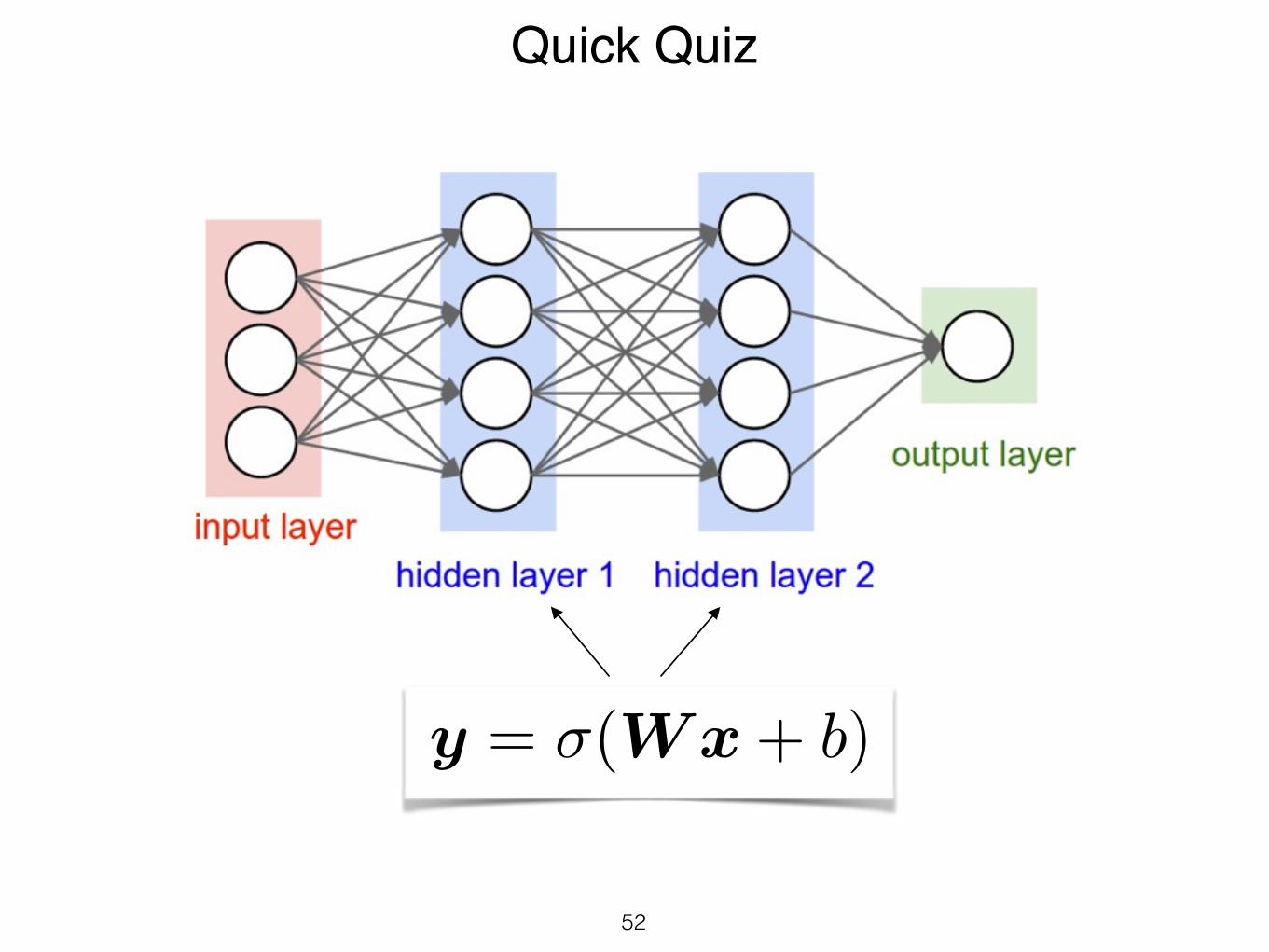
Quick Quiz
52
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
y = �(Wx+ b)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
Quick Quiz
53
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
y = �(Wx+ b)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
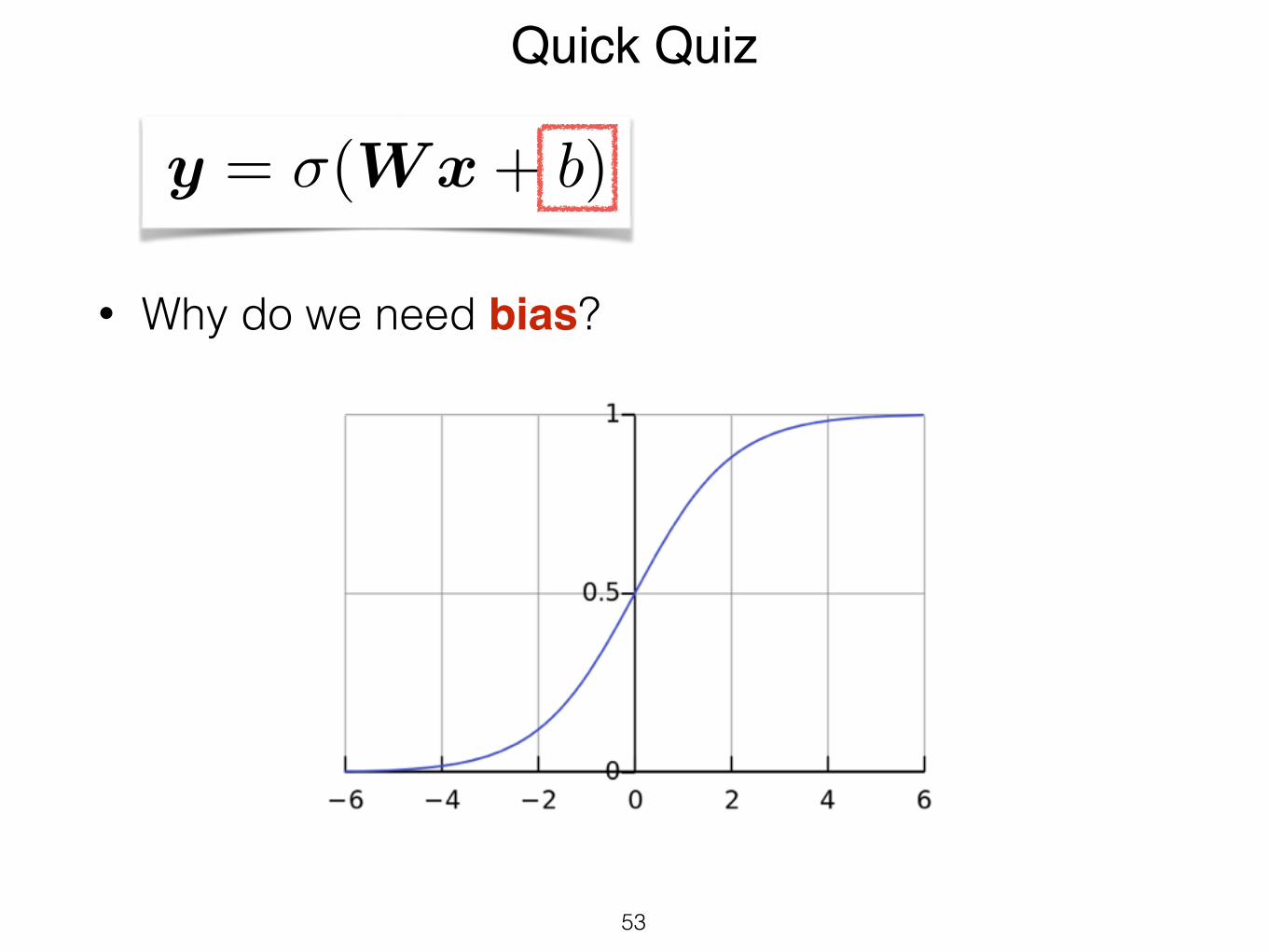
• Why do we need bias?
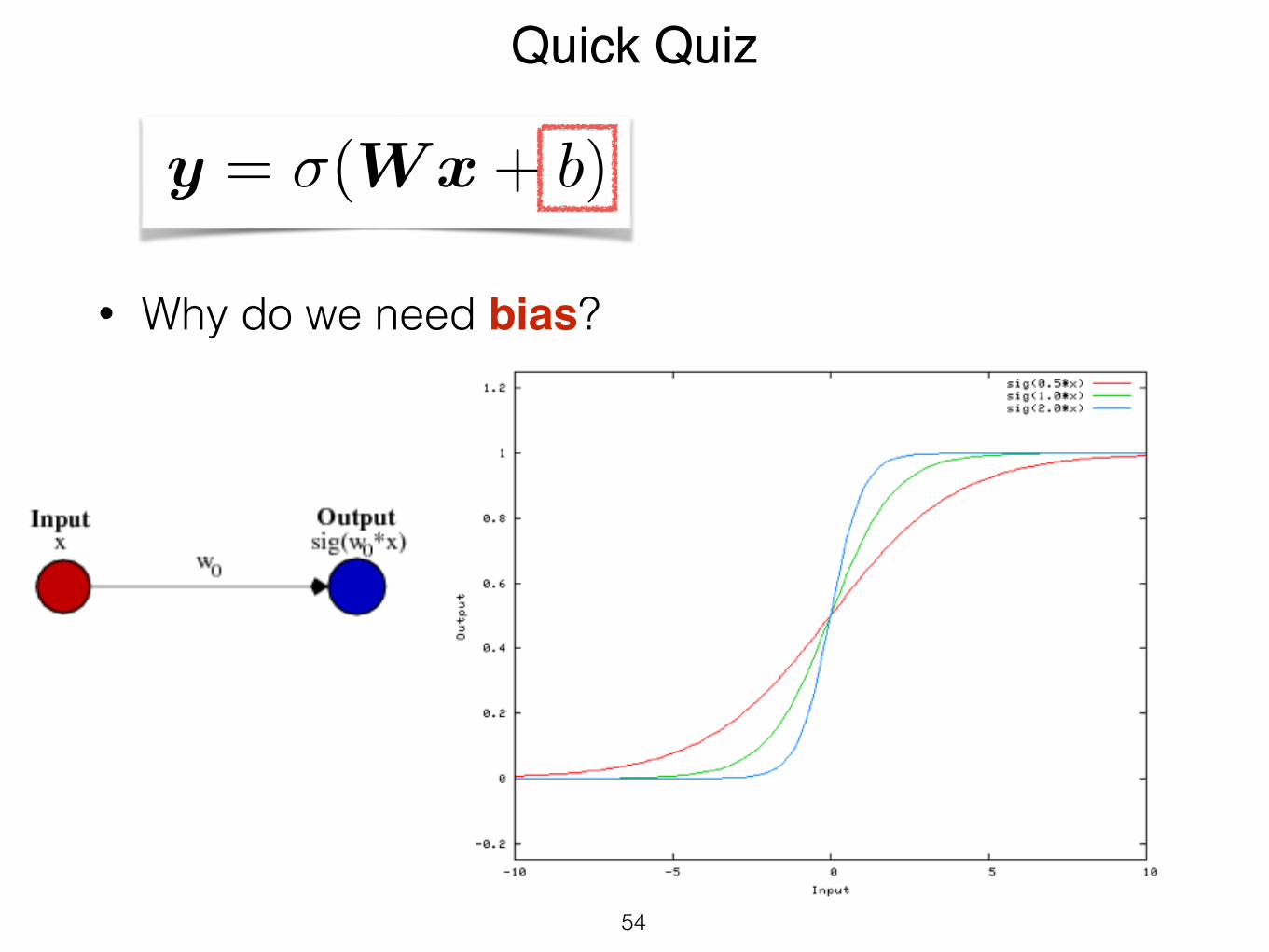
Quick Quiz
54
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
y = �(Wx+ b)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
• Why do we need bias?
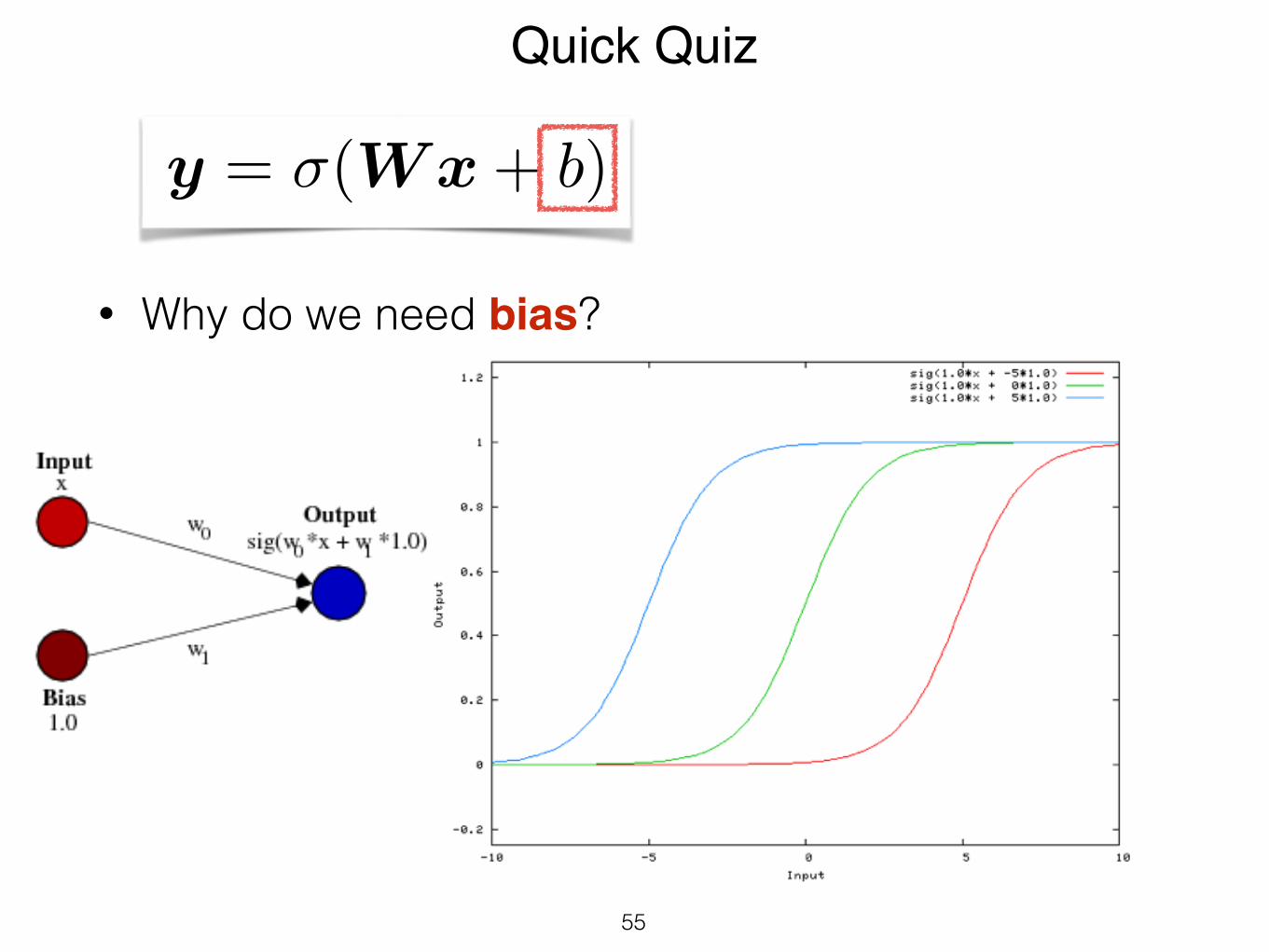
Quick Quiz
55
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
y = �(Wx+ b)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
• Why do we need bias?

Quick Quiz
56
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
y = �(Wx+ b)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
• What’s the role / function of bias?
• True / False: It's sufficient for symmetry breaking in a neural network to initialize all W to 0, provided biases are random.
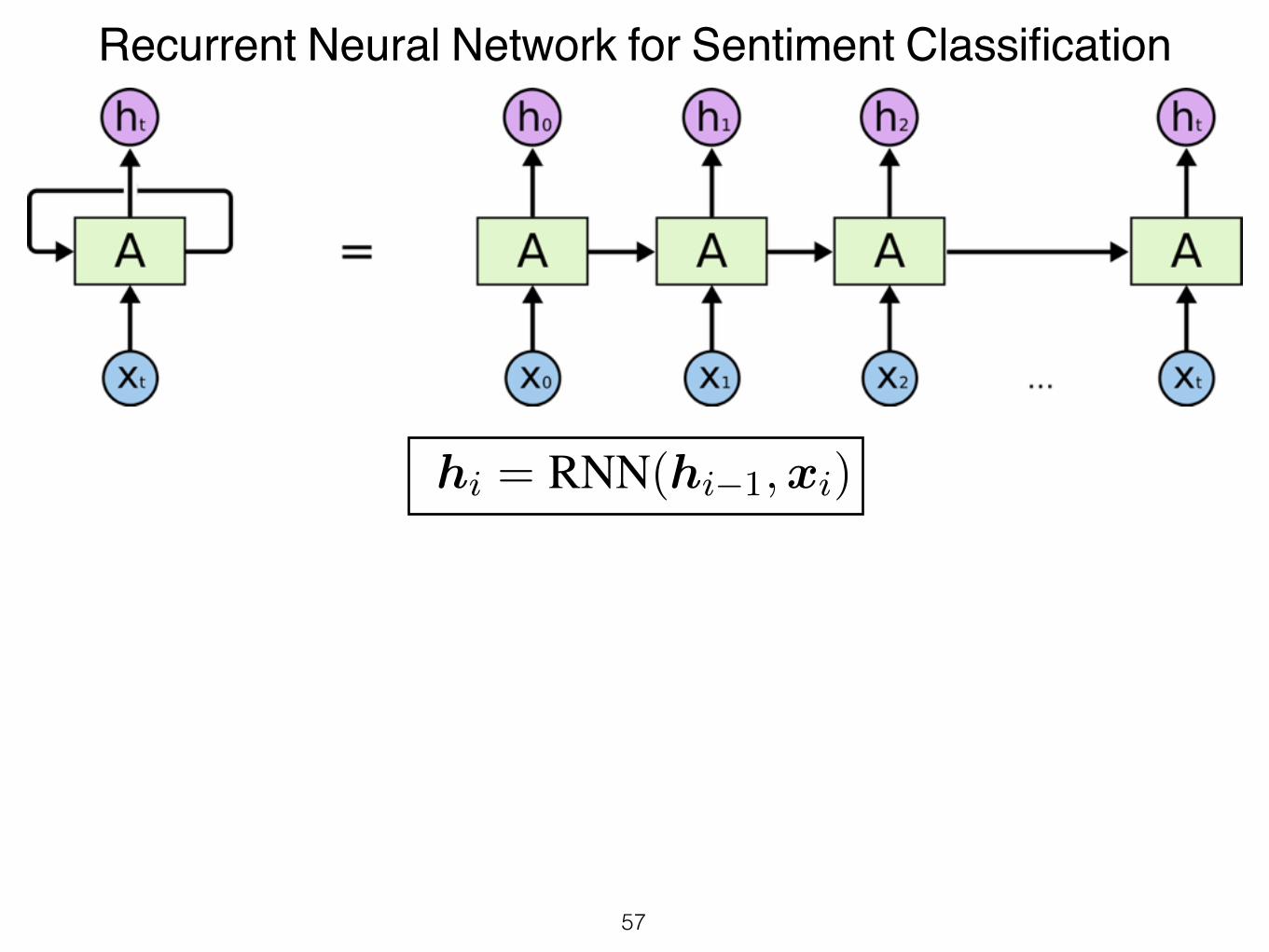
Recurrent Neural Network for Sentiment Classification
57
hi = RNN(hi�1,xi)
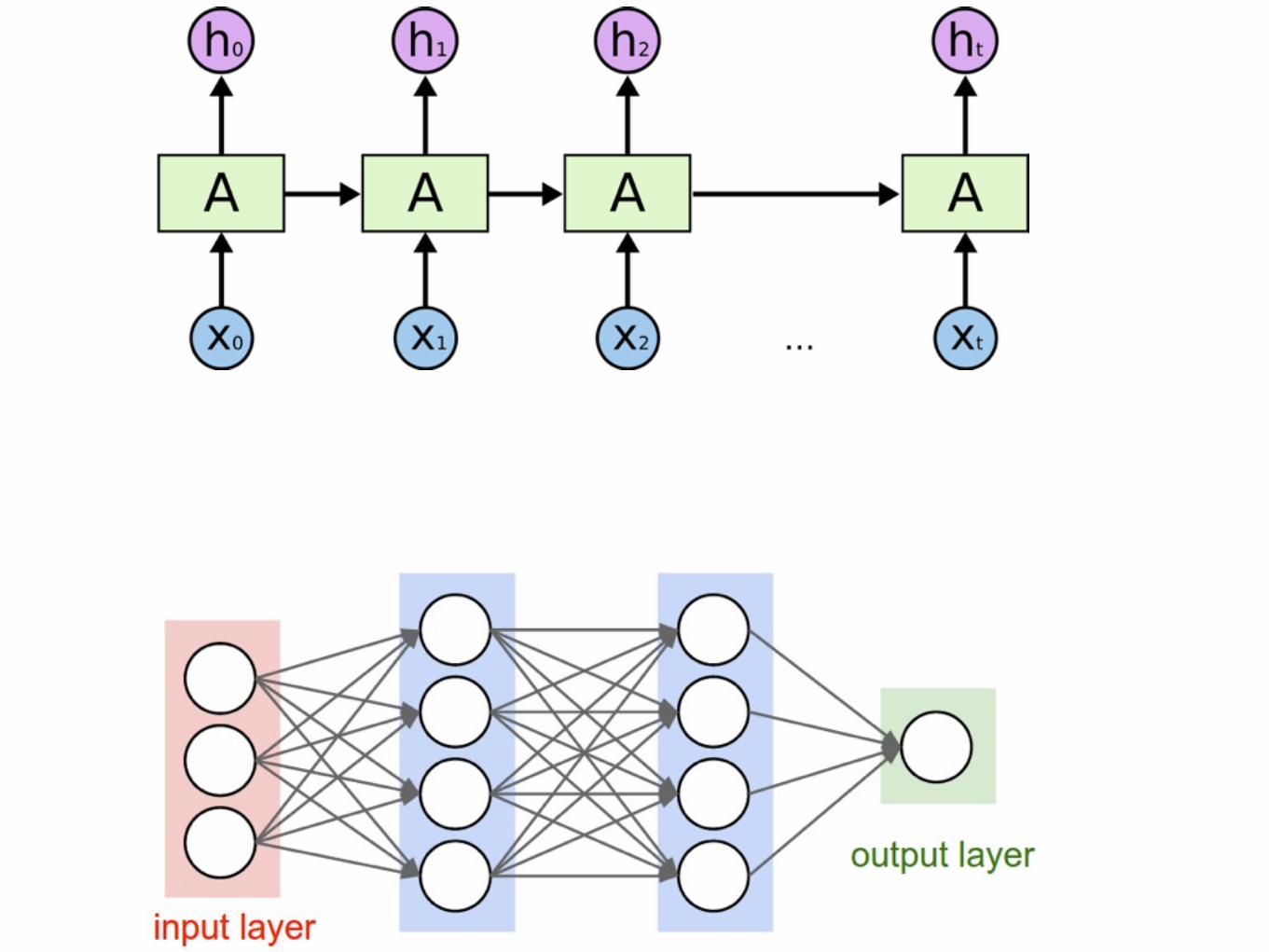
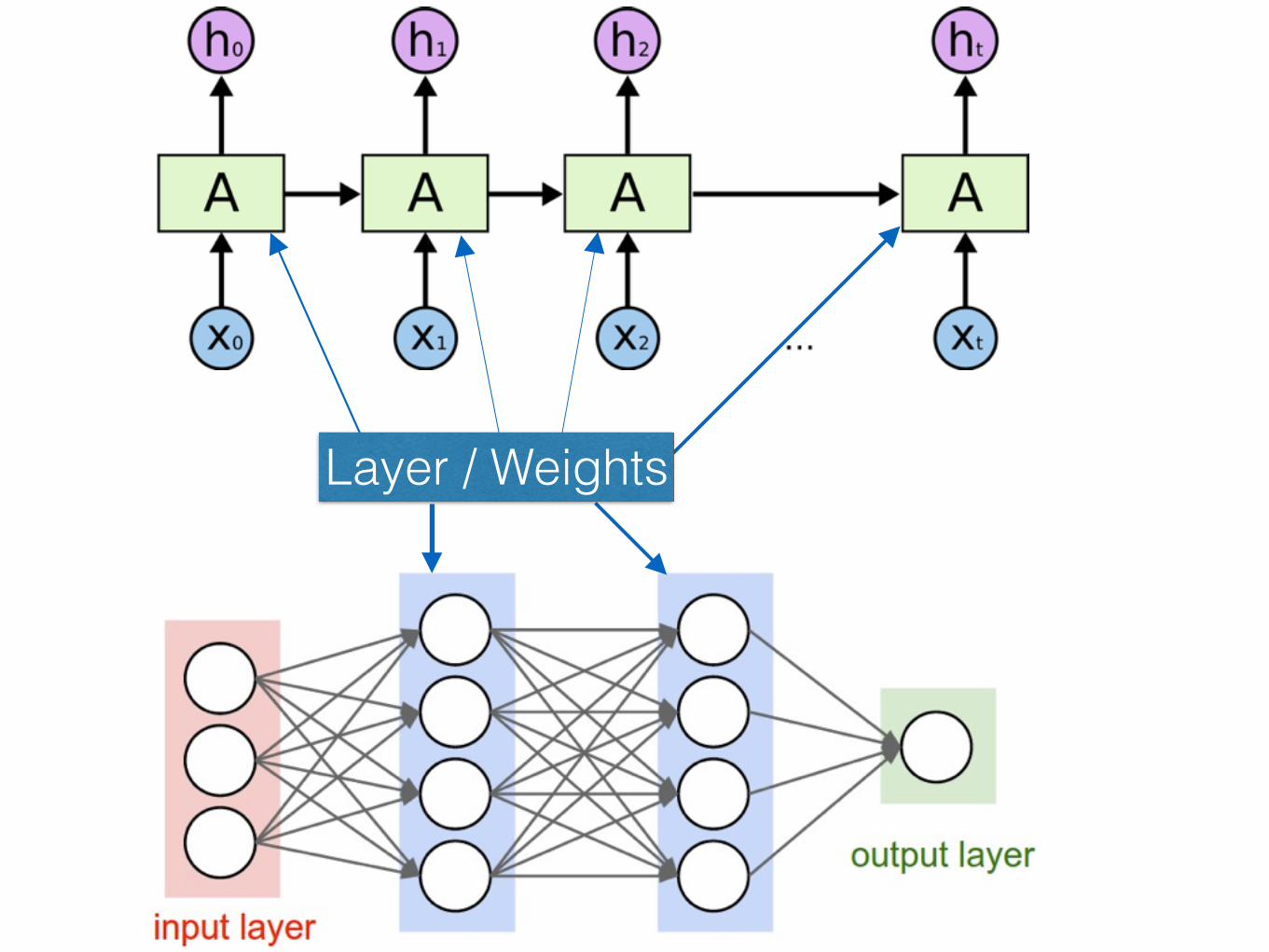
Layer / Weights
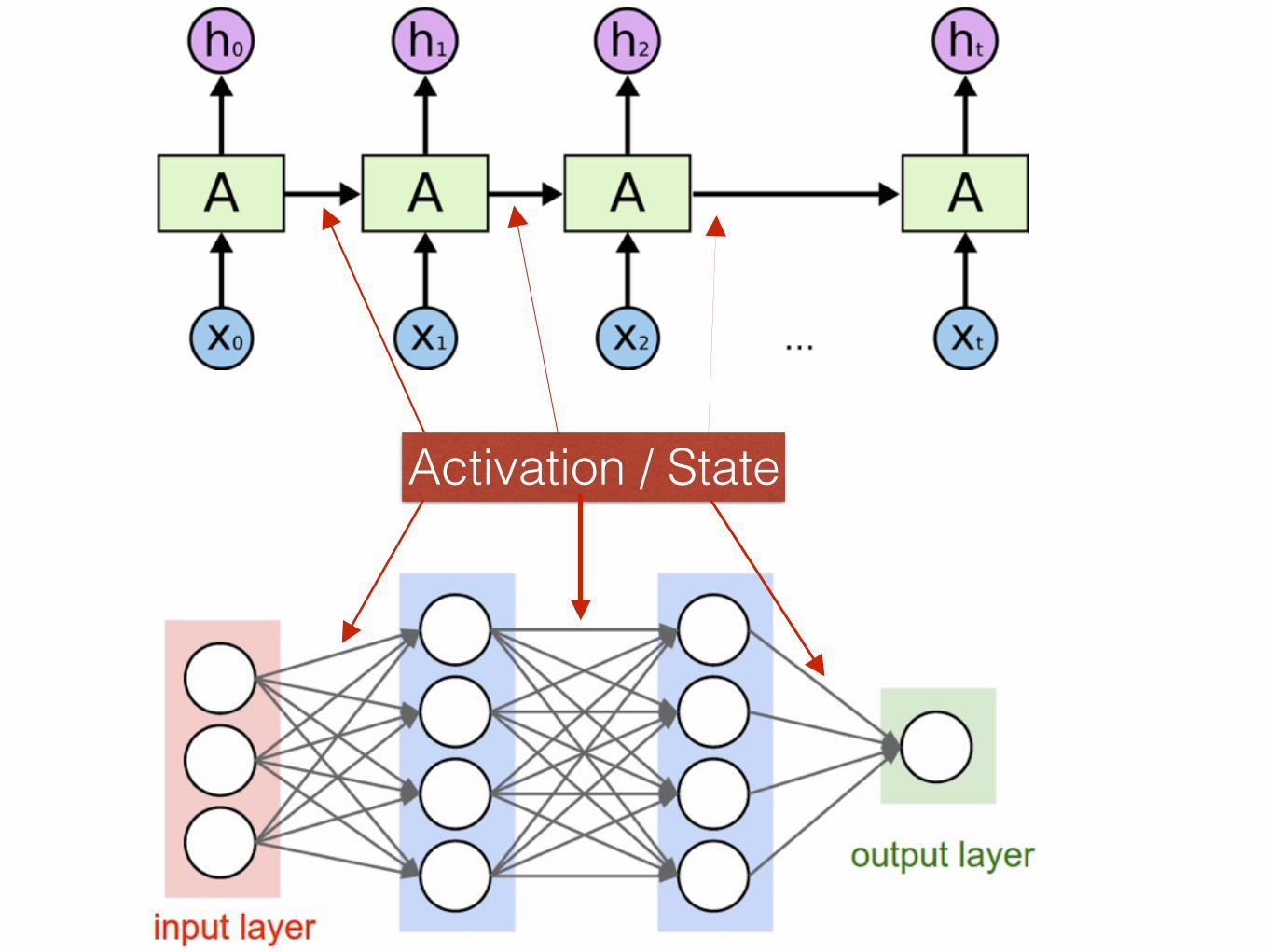
Activation / State

Recurrent Neural Network for Sentiment Classification
61
hi = RNN(hi�1,xi)
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
hi = tanh(Whi�1 +Uxi)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
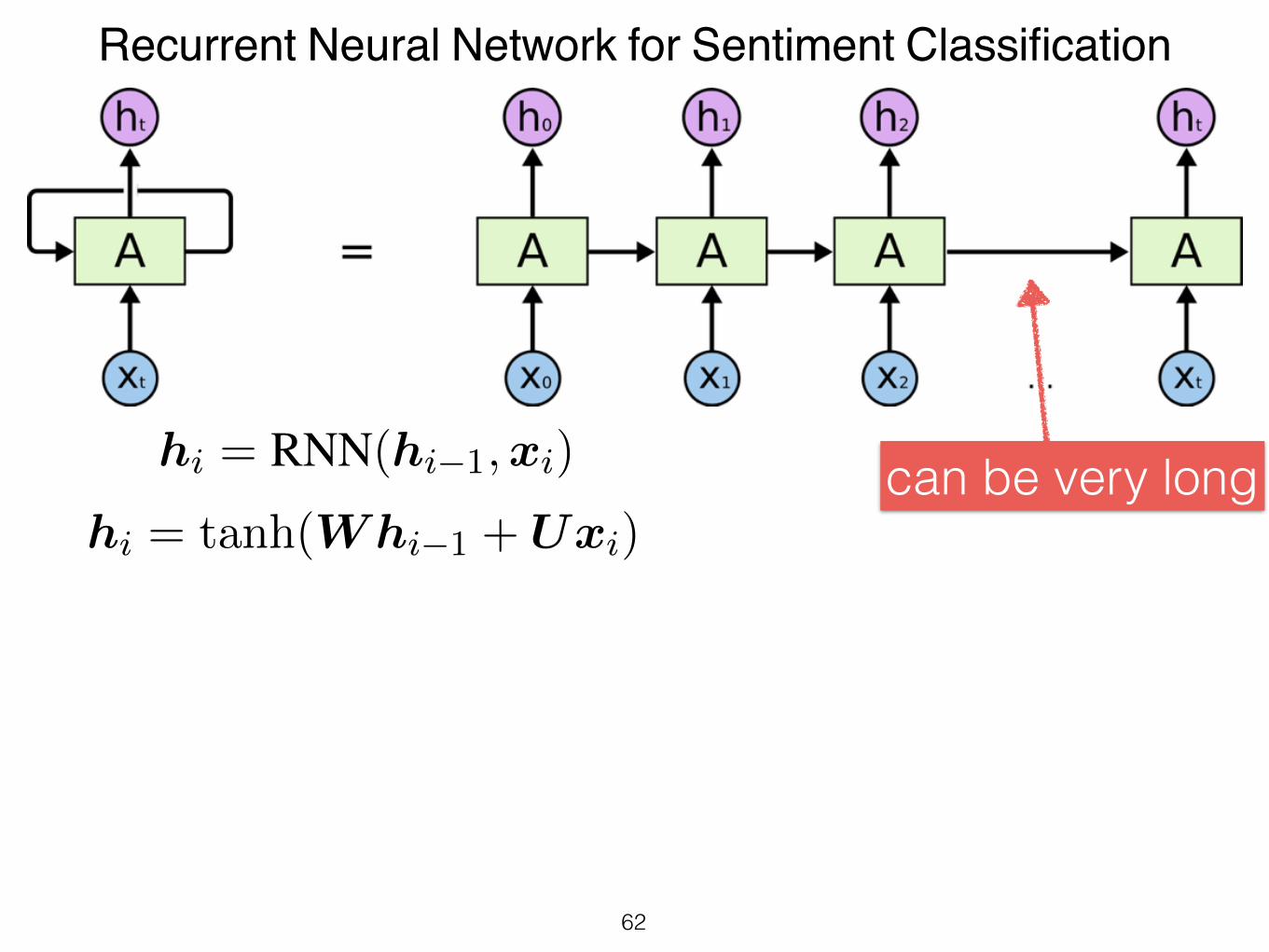
Recurrent Neural Network for Sentiment Classification
62
hi = RNN(hi�1,xi)
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
hi = tanh(Whi�1 +Uxi)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
can be very long
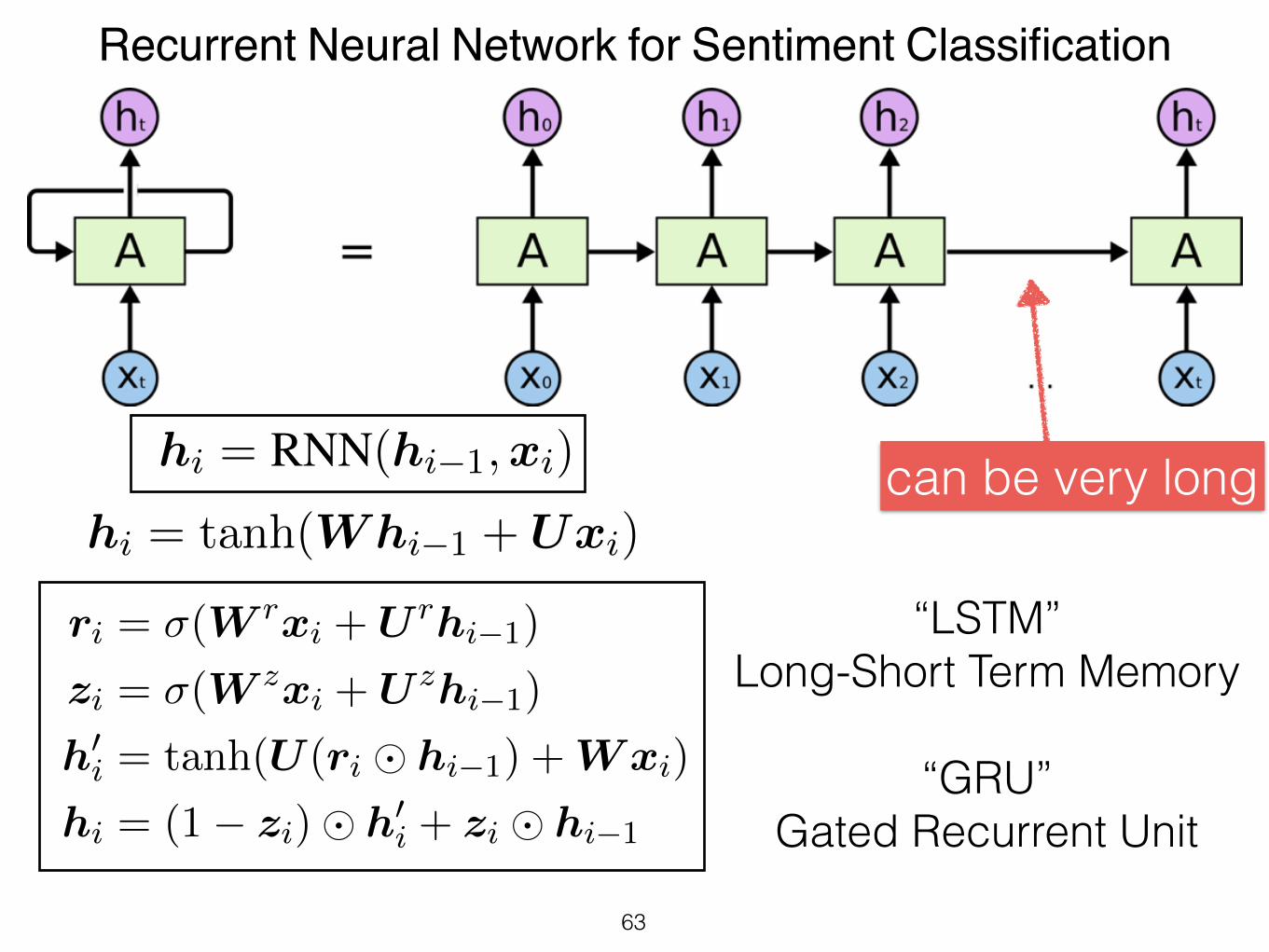
Recurrent Neural Network for Sentiment Classification
63
hi = RNN(hi�1,xi)
9
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
ACL 2016 Submission ***. Confidential review copy. DO NOT DISTRIBUTE.
hi = tanh(Whi�1 +Uxi)
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprint
arXiv:1409.0473.
Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk,Philemon Brakel, and Yoshua Bengio. 2015.End-to-end attention-based large vocabulary speechrecognition. arXiv preprint arXiv:1508.04395.
Frederic Bastien, Pascal Lamblin, Razvan Pascanu,James Bergstra, Ian Goodfellow, Arnaud Bergeron,Nicolas Bouchard, David Warde-Farley, and YoshuaBengio. 2012. Theano: new features and speed im-provements. arXiv preprint arXiv:1211.5590.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEE
Transactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. InInnovations in Machine Learning, pages 137–186.Springer.
James Bergstra, Olivier Breuleux, Frederic Bastien,Pascal Lamblin, Razvan Pascanu, Guillaume Des-jardins, Joseph Turian, David Warde-Farley, andYoshua Bengio. 2010. Theano: a cpu and gpumath expression compiler. In Proceedings of the
Python for scientific computing conference (SciPy),volume 4, page 3. Austin, TX.
Nicolas Boulanger-Lewandowski, Yoshua Bengio, andPascal Vincent. 2013. Audio chord recognition withrecurrent neural networks. In ISMIR, pages 335–340.
Peter F Brown, Vincent J Della Pietra, Stephen A DellaPietra, and Robert L Mercer. 1993. The mathemat-ics of statistical machine translation: Parameter esti-mation. Computational linguistics, 19(2):263–311.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprint
arXiv:1511.05960.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228.
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014a. On the proper-ties of neural machine translation: Encoder-decoderapproaches. arXiv preprint arXiv:1409.1259.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014b. Learningphrase representations using rnn encoder-decoderfor statistical machine translation. arXiv preprint
arXiv:1406.1078.
Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho,and Yoshua Bengio. 2014. End-to-end continuousspeech recognition using attention-based recurrentnn: First results. arXiv preprint arXiv:1412.1602.
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vy-molova, Kaisheng Yao, Chris Dyer, and GholamrezaHaffari. 2016. Incorporating structural alignmentbiases into an attentional neural translation model.arXiv preprint arXiv:1601.01085.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, ThomasLamar, Richard M Schwartz, and John Makhoul.2014. Fast and robust neural network joint modelsfor statistical machine translation. In ACL (1), pages1370–1380. Citeseer.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-
chine Learning Research, 12:2121–2159.
Ian J Goodfellow, David Warde-Farley, Mehdi Mirza,Aaron Courville, and Yoshua Bengio. 2013. Max-out networks. arXiv preprint arXiv:1302.4389.
Alex Graves. 2012. Sequence transductionwith recurrent neural networks. arXiv preprint
arXiv:1211.3711.
Alex Graves. 2013. Generating sequenceswith recurrent neural networks. arXiv preprint
arXiv:1308.0850.
Aria Haghighi, John Blitzer, John DeNero, and DanKlein. 2009. Better word alignments with su-pervised itg models. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL
and the 4th International Joint Conference on Natu-
ral Language Processing of the AFNLP: Volume 2-
Volume 2, pages 923–931. Association for Compu-tational Linguistics.
Karl Moritz Hermann, Tomas Kocisky, EdwardGrefenstette, Lasse Espeholt, Will Kay, Mustafa Su-leyman, and Phil Blunsom. 2015. Teaching ma-chines to read and comprehend. In Advances in Neu-
ral Information Processing Systems, pages 1684–1692.
Sepp Hochreiter and Jurgen Schmidhuber. 1997.Long short-term memory. Neural computation,9(8):1735–1780.
Nal Kalchbrenner and Phil Blunsom. 2013. Recur-rent continuous translation models. In EMNLP, vol-ume 3, page 413.
can be very long
ri = �(W rxi +U
rhi�1)
zi = �(W zxi +U
zhi�1)
h
0i = tanh(U(ri � hi�1) +Wxi)
hi = (1� zi)� h
0i + zi � hi�1
“LSTM” Long-Short Term Memory
“GRU” Gated Recurrent Unit
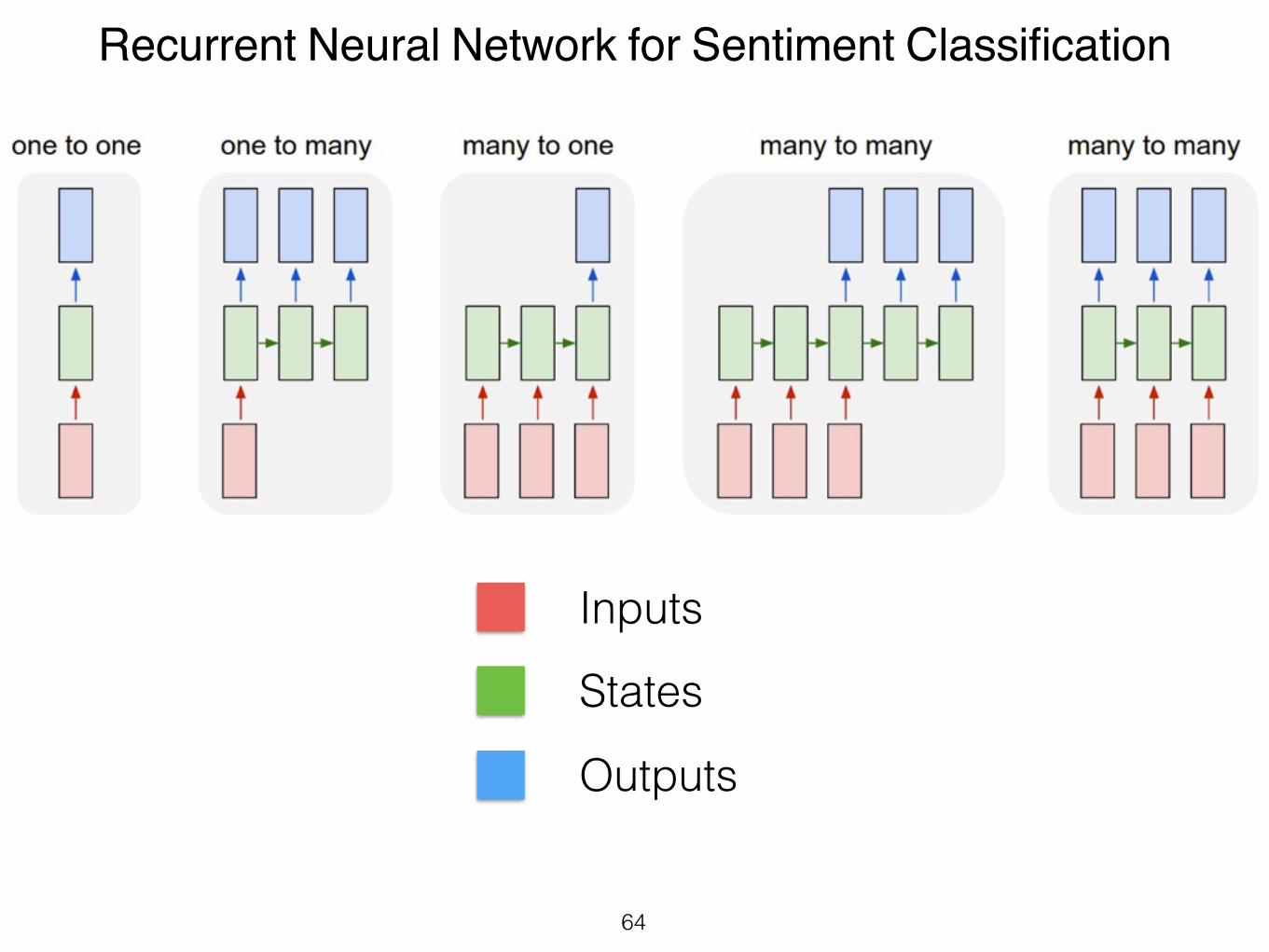
Recurrent Neural Network for Sentiment Classification
64
Inputs
States
Outputs

IMDB
65
Model 3 folds
Unigrams 82.8
Unigrams and Osgood 82.8
Unigrams and Turney 83.2
Unigrams, Turney, Osgood 82.8
Lemmas 84.1
Lemmas and Osgood 83.1
Lemmas and Turney 84.2
Lemmas, Turney, Osgood 83.8
Pang et al. 2002 (SVM on unigrams) 82.9
Hybrid SVM (Turney and Lemmas) 84.4
Hybrid SVM (Turney/Osgood and Lemmas) 84.6

IMDB
66
Model 3 foldsUnigrams 82.8Unigrams and Osgood 82.8Unigrams and Turney 83.2Unigrams, Turney, Osgood 82.8Lemmas 84.1
Lemmas and Osgood 83.1Lemmas and Turney 84.2Lemmas, Turney, Osgood 83.8
Pang et al. 2002 (SVM on unigrams) 82.9Hybrid SVM (Turney and Lemmas) 84.4Hybrid SVM (Turney/Osgood and Lemmas) 84.6
LSTM 84.9
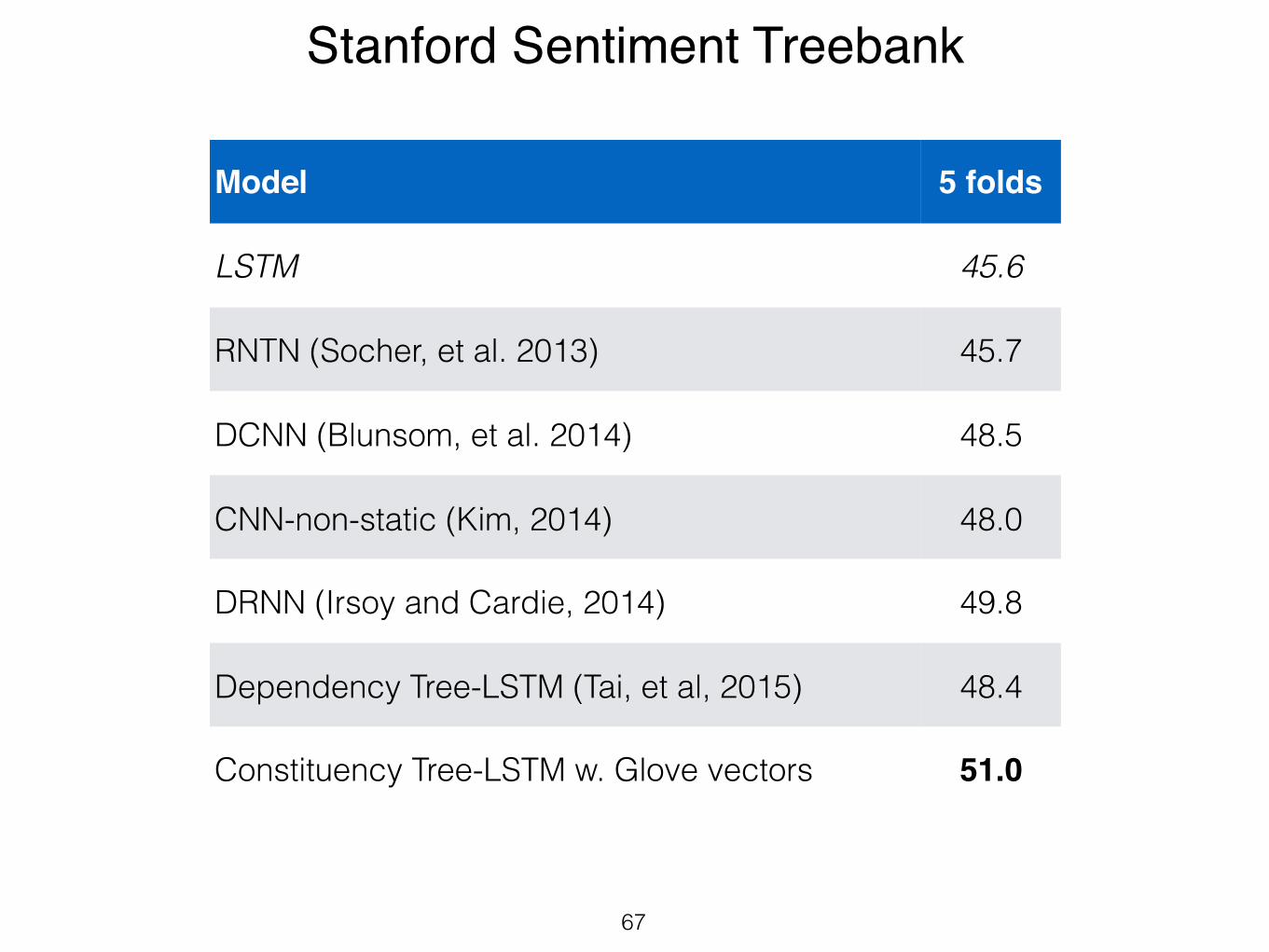
Stanford Sentiment Treebank
67
Model 5 folds
LSTM 45.6
RNTN (Socher, et al. 2013) 45.7
DCNN (Blunsom, et al. 2014) 48.5
CNN-non-static (Kim, 2014) 48.0
DRNN (Irsoy and Cardie, 2014) 49.8
Dependency Tree-LSTM (Tai, et al, 2015) 48.4
Constituency Tree-LSTM w. Glove vectors 51.0

Other Important (Big) Topics
• Domain Adaptation
• Bias in the system
68

Related materials
• Survey
• Opinion mining and sentiment analysis, Bo Pang and Lillian Lee, 2008
• Topic Model for Opinion Mining
• On the Design of LDA Models for Aspect-based Opinion Mining
• Modeling online reviews with multi-grain topic models
• Neural Network for Sentiment Classification
• The Unreasonable Effectiveness of RNN, Andrej Karpathy
• Recurrent Neural Networks Tutorial, WildML
• Understanding LSTM Networks, Christopher Olah
69

• Thank you!
• Questions?
70

Backup Slides
Deep Learning for NLP
72
Sentence Level Recurrent Topic Model: Letting Topics Speak for Themselves Fei Tian, Bin Gao, Di He, Tie-Yan Liu, 2016
document di, i 2 {1, 2, · · · ,M}, it is composed of Ni sen-tences and its jth sentence sij consists of Tij words. Sim-ilar to LDA, we assume there is a K-dimensional Dirichletprior distribution Dir(↵) for topic mixture weights of eachdocument. With these notations, the generative process fordocument di can be written as below:
1. Sample the multinomial parameter ✓i from Dir(↵);2. For the jth sentence of document di sij = (y1, · · · , yTij ),
j 2 {1, · · · , Ni}, where yt 2 W is the tth word for sij :(a) Draw the topic index kij of this sentence from ✓i;(b) For t = 1, · · · , Tij :
i. Compute LSTM hidden state ht =f(ht�1;yt�1;kij);
ii. 8w 2 W , draw yt from
P (w|yt�1, · · · , y1; kij) / g(w0;ht;yt�1;kij)(1)
Here we use bold characters to denote the distributed rep-resentations for the corresponding items. For example, ytand kij denote the embeddings for word yt and topic kij , re-spectively. h0 is a zero vector and y
0
is a fake starting word.Function f is the LSTM unit to generate hidden states, forwhich we omit the details due to space restrictions. Functiong typically takes the following form:
g(w0;ht;yt�1;kij) = �(w0 · (W1ht +W2yt�1 +W3kij + b)),(2)
where �(x) = 1/(1 + exp(�x)), w0 denotes the output em-bedding for word w. W
1
,W
2
,W
3
are feedforward weightmatrices and b is the bias vector.
Then the probability of observing document di can be writ-ten as:
P (di|↵,⇥) =
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ikP (sij |k,⇥)d✓
=
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ik
TijY
t=1
P (yt|yt�1, · · · , y1; k)d✓
(3)where P (sij |k,⇥) is the probability of generating sentencesij under topic k, and it is decomposed through the probabil-ity chain rule; P (yt|yt�1
, · · · , y1
; k) is specified in equation(1) and (2); ⇥ represents all the model parameters, includingthe distributed representations for all the words and topics, aswell as the weight parameters for LSTM.
To sum up, we use Figure 1 to illustrate the generative pro-cess of SLRTM, from which we can see that in SLRTM, thehistorical words and topic of the sentence jointly affect theLSTM hidden state and the next word.
3.2 Stochastic Variational Inference and LearningAs the computation of the true posterior of hidden variablesin equation (3) is untractable, we adopt mean field variationalinference to approximate it. Particularly, we use multinomialdistribution q�ij (kij) and Dirichlet distribution q�i(✓i) as thevariational distribution for the hidden variables kij and ✓i,and we denote the variational parameters for document di
as �i = {�j , �}, 8i, j, with the subscript i omitted. Thenthe variational lower bound of the data likelihood [Blei et al.,2003] can be written as:
Figure 1: The illustration of the SLRTM generative process.
L(D;�,⇥,↵) =
MX
i=1
NiX
j=1
{Eq[logP (sij |kij ,⇥)] + Eq[logp(kij |✓i)q(kij)
]}
+
MX
i=1
Eq[log p(✓i)� log q(✓i)]
(4)where p(·) is the true distribution for corresponding variables.
The introduction of LSTM-RNN makes the optimizationof (4) computationally expensive, since we need to updateboth the model parameters ⇥ = {⇥
1
, · · · ,⇥D} and varia-tional parameters � after scanning the whole corpus. Consid-ering that mini-batch (containing several sentences) inferenceand training are necessary to optimize the neural network,we leverage the stochastic variational inference algorithm de-veloped in [Hoffman et al., 2010; Hoffman et al., 2013] toconduct inference and learning in a variational Expectation-Maximization framework.1 The detailed algorithm is givenin Algorithm 1. The execution of the whole inference andlearning process includes several epochs of iteration over alldocuments di, i = {1, 2, · · · ,M} with Algorithm 1 (startingwith t = 0).
In Algorithm 1, (x) is the digamma function. Equation(5) guarantees the estimate of �k is unbiased. In equation (6),⇢t is set as ⇢t = (⌧
0
+ t)
�, where ⌧
0
� 0, 2 (0.5, 1],to make sure �
(t) will converge [Hoffman et al., 2010]. Dueto space limit, we omit the derivation details for the updatingequations in Algorithm 1, as well as the forward/backwardpass details for LSTM [Hochreiter and Schmidhuber, 1997].
1We did not use any recently developed algorithms for infer-ence and learning under deep neural networks such as variationalautoencoder [Kingma and Welling, 2013] because they are designedfor continuous hidden states while our model includes discrete vari-ables.
Deep Learning for NLP
73
document di, i 2 {1, 2, · · · ,M}, it is composed of Ni sen-tences and its jth sentence sij consists of Tij words. Sim-ilar to LDA, we assume there is a K-dimensional Dirichletprior distribution Dir(↵) for topic mixture weights of eachdocument. With these notations, the generative process fordocument di can be written as below:
1. Sample the multinomial parameter ✓i from Dir(↵);2. For the jth sentence of document di sij = (y1, · · · , yTij ),
j 2 {1, · · · , Ni}, where yt 2 W is the tth word for sij :(a) Draw the topic index kij of this sentence from ✓i;(b) For t = 1, · · · , Tij :
i. Compute LSTM hidden state ht =f(ht�1;yt�1;kij);
ii. 8w 2 W , draw yt from
P (w|yt�1, · · · , y1; kij) / g(w0;ht;yt�1;kij)(1)
Here we use bold characters to denote the distributed rep-resentations for the corresponding items. For example, ytand kij denote the embeddings for word yt and topic kij , re-spectively. h0 is a zero vector and y
0
is a fake starting word.Function f is the LSTM unit to generate hidden states, forwhich we omit the details due to space restrictions. Functiong typically takes the following form:
g(w0;ht;yt�1;kij) = �(w0 · (W1ht +W2yt�1 +W3kij + b)),(2)
where �(x) = 1/(1 + exp(�x)), w0 denotes the output em-bedding for word w. W
1
,W
2
,W
3
are feedforward weightmatrices and b is the bias vector.
Then the probability of observing document di can be writ-ten as:
P (di|↵,⇥) =
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ikP (sij |k,⇥)d✓
=
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ik
TijY
t=1
P (yt|yt�1, · · · , y1; k)d✓
(3)where P (sij |k,⇥) is the probability of generating sentencesij under topic k, and it is decomposed through the probabil-ity chain rule; P (yt|yt�1
, · · · , y1
; k) is specified in equation(1) and (2); ⇥ represents all the model parameters, includingthe distributed representations for all the words and topics, aswell as the weight parameters for LSTM.
To sum up, we use Figure 1 to illustrate the generative pro-cess of SLRTM, from which we can see that in SLRTM, thehistorical words and topic of the sentence jointly affect theLSTM hidden state and the next word.
3.2 Stochastic Variational Inference and LearningAs the computation of the true posterior of hidden variablesin equation (3) is untractable, we adopt mean field variationalinference to approximate it. Particularly, we use multinomialdistribution q�ij (kij) and Dirichlet distribution q�i(✓i) as thevariational distribution for the hidden variables kij and ✓i,and we denote the variational parameters for document di
as �i = {�j , �}, 8i, j, with the subscript i omitted. Thenthe variational lower bound of the data likelihood [Blei et al.,2003] can be written as:
Figure 1: The illustration of the SLRTM generative process.
L(D;�,⇥,↵) =
MX
i=1
NiX
j=1
{Eq[logP (sij |kij ,⇥)] + Eq[logp(kij |✓i)q(kij)
]}
+
MX
i=1
Eq[log p(✓i)� log q(✓i)]
(4)where p(·) is the true distribution for corresponding variables.
The introduction of LSTM-RNN makes the optimizationof (4) computationally expensive, since we need to updateboth the model parameters ⇥ = {⇥
1
, · · · ,⇥D} and varia-tional parameters � after scanning the whole corpus. Consid-ering that mini-batch (containing several sentences) inferenceand training are necessary to optimize the neural network,we leverage the stochastic variational inference algorithm de-veloped in [Hoffman et al., 2010; Hoffman et al., 2013] toconduct inference and learning in a variational Expectation-Maximization framework.1 The detailed algorithm is givenin Algorithm 1. The execution of the whole inference andlearning process includes several epochs of iteration over alldocuments di, i = {1, 2, · · · ,M} with Algorithm 1 (startingwith t = 0).
In Algorithm 1, (x) is the digamma function. Equation(5) guarantees the estimate of �k is unbiased. In equation (6),⇢t is set as ⇢t = (⌧
0
+ t)
�, where ⌧
0
� 0, 2 (0.5, 1],to make sure �
(t) will converge [Hoffman et al., 2010]. Dueto space limit, we omit the derivation details for the updatingequations in Algorithm 1, as well as the forward/backwardpass details for LSTM [Hochreiter and Schmidhuber, 1997].
1We did not use any recently developed algorithms for infer-ence and learning under deep neural networks such as variationalautoencoder [Kingma and Welling, 2013] because they are designedfor continuous hidden states while our model includes discrete vari-ables.
document di, i 2 {1, 2, · · · ,M}, it is composed of Ni sen-tences and its jth sentence sij consists of Tij words. Sim-ilar to LDA, we assume there is a K-dimensional Dirichletprior distribution Dir(↵) for topic mixture weights of eachdocument. With these notations, the generative process fordocument di can be written as below:
1. Sample the multinomial parameter ✓i from Dir(↵);2. For the jth sentence of document di sij = (y1, · · · , yTij ),
j 2 {1, · · · , Ni}, where yt 2 W is the tth word for sij :(a) Draw the topic index kij of this sentence from ✓i;(b) For t = 1, · · · , Tij :
i. Compute LSTM hidden state ht =f(ht�1;yt�1;kij);
ii. 8w 2 W , draw yt from
P (w|yt�1, · · · , y1; kij) / g(w0;ht;yt�1;kij)(1)
Here we use bold characters to denote the distributed rep-resentations for the corresponding items. For example, ytand kij denote the embeddings for word yt and topic kij , re-spectively. h0 is a zero vector and y
0
is a fake starting word.Function f is the LSTM unit to generate hidden states, forwhich we omit the details due to space restrictions. Functiong typically takes the following form:
g(w0;ht;yt�1;kij) = �(w0 · (W1ht +W2yt�1 +W3kij + b)),(2)
where �(x) = 1/(1 + exp(�x)), w0 denotes the output em-bedding for word w. W
1
,W
2
,W
3
are feedforward weightmatrices and b is the bias vector.
Then the probability of observing document di can be writ-ten as:
P (di|↵,⇥) =
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ikP (sij |k,⇥)d✓
=
Z
✓⇠Dir(↵)
NiY
j=1
KX
k=1
✓ik
TijY
t=1
P (yt|yt�1, · · · , y1; k)d✓
(3)where P (sij |k,⇥) is the probability of generating sentencesij under topic k, and it is decomposed through the probabil-ity chain rule; P (yt|yt�1
, · · · , y1
; k) is specified in equation(1) and (2); ⇥ represents all the model parameters, includingthe distributed representations for all the words and topics, aswell as the weight parameters for LSTM.
To sum up, we use Figure 1 to illustrate the generative pro-cess of SLRTM, from which we can see that in SLRTM, thehistorical words and topic of the sentence jointly affect theLSTM hidden state and the next word.
3.2 Stochastic Variational Inference and LearningAs the computation of the true posterior of hidden variablesin equation (3) is untractable, we adopt mean field variationalinference to approximate it. Particularly, we use multinomialdistribution q�ij (kij) and Dirichlet distribution q�i(✓i) as thevariational distribution for the hidden variables kij and ✓i,and we denote the variational parameters for document di
as �i = {�j , �}, 8i, j, with the subscript i omitted. Thenthe variational lower bound of the data likelihood [Blei et al.,2003] can be written as:
Figure 1: The illustration of the SLRTM generative process.
L(D;�,⇥,↵) =
MX
i=1
NiX
j=1
{Eq[logP (sij |kij ,⇥)] + Eq[logp(kij |✓i)q(kij)
]}
+
MX
i=1
Eq[log p(✓i)� log q(✓i)]
(4)where p(·) is the true distribution for corresponding variables.
The introduction of LSTM-RNN makes the optimizationof (4) computationally expensive, since we need to updateboth the model parameters ⇥ = {⇥
1
, · · · ,⇥D} and varia-tional parameters � after scanning the whole corpus. Consid-ering that mini-batch (containing several sentences) inferenceand training are necessary to optimize the neural network,we leverage the stochastic variational inference algorithm de-veloped in [Hoffman et al., 2010; Hoffman et al., 2013] toconduct inference and learning in a variational Expectation-Maximization framework.1 The detailed algorithm is givenin Algorithm 1. The execution of the whole inference andlearning process includes several epochs of iteration over alldocuments di, i = {1, 2, · · · ,M} with Algorithm 1 (startingwith t = 0).
In Algorithm 1, (x) is the digamma function. Equation(5) guarantees the estimate of �k is unbiased. In equation (6),⇢t is set as ⇢t = (⌧
0
+ t)
�, where ⌧
0
� 0, 2 (0.5, 1],to make sure �
(t) will converge [Hoffman et al., 2010]. Dueto space limit, we omit the derivation details for the updatingequations in Algorithm 1, as well as the forward/backwardpass details for LSTM [Hochreiter and Schmidhuber, 1997].
1We did not use any recently developed algorithms for infer-ence and learning under deep neural networks such as variationalautoencoder [Kingma and Welling, 2013] because they are designedfor continuous hidden states while our model includes discrete vari-ables.

Deep Learning for NLP
• Can syntax help?
• Can structure help?
• How does syntactic structure guide the composition of the meaning of a sentence?
• How can we use it in Deep Learning for NLP?
74
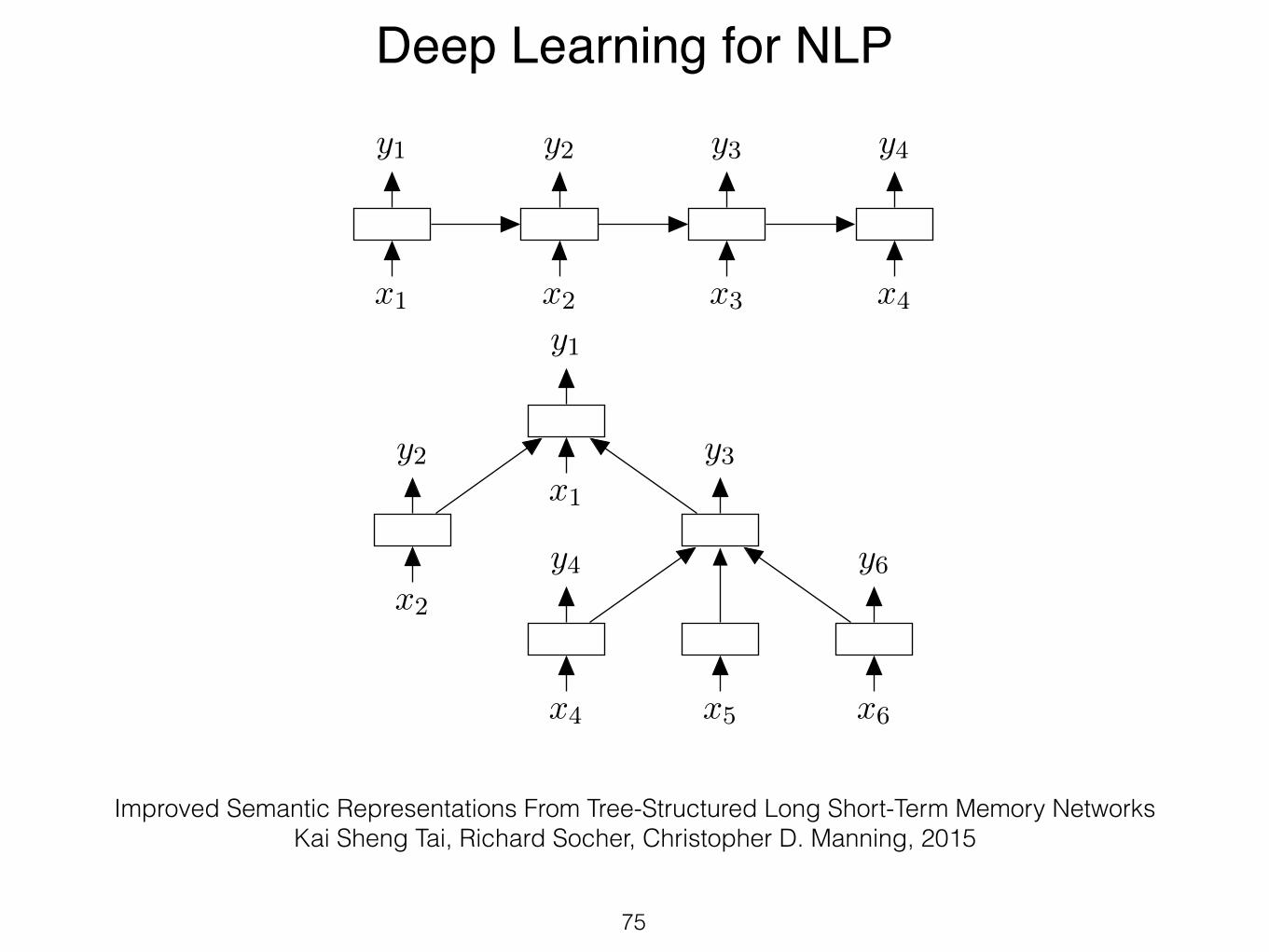
Deep Learning for NLP
75
Improved Semantic Representations FromTree-Structured Long Short-Term Memory Networks
Kai Sheng Tai, Richard Socher*, Christopher D. ManningComputer Science Department, Stanford University, *MetaMind Inc.
[email protected], [email protected], [email protected]
AbstractBecause of their superior ability to pre-serve sequence information over time,Long Short-Term Memory (LSTM) net-works, a type of recurrent neural net-work with a more complex computationalunit, have obtained strong results on a va-riety of sequence modeling tasks. Theonly underlying LSTM structure that hasbeen explored so far is a linear chain.However, natural language exhibits syn-tactic properties that would naturally com-bine words to phrases. We introduce theTree-LSTM, a generalization of LSTMs totree-structured network topologies. Tree-LSTMs outperform all existing systemsand strong LSTM baselines on two tasks:predicting the semantic relatedness of twosentences (SemEval 2014, Task 1) andsentiment classification (Stanford Senti-ment Treebank).
1 IntroductionMost models for distributed representations ofphrases and sentences—that is, models where real-valued vectors are used to represent meaning—fallinto one of three classes: bag-of-words models,sequence models, and tree-structured models. Inbag-of-words models, phrase and sentence repre-sentations are independent of word order; for ex-ample, they can be generated by averaging con-stituent word representations (Landauer and Du-mais, 1997; Foltz et al., 1998). In contrast, se-quence models construct sentence representationsas an order-sensitive function of the sequence oftokens (Elman, 1990; Mikolov, 2012). Lastly,tree-structured models compose each phrase andsentence representation from its constituent sub-phrases according to a given syntactic structureover the sentence (Goller and Kuchler, 1996;Socher et al., 2011).
x1 x2 x3 x4
y1 y2 y3 y4
x1
x2
x4 x5 x6
y1
y2 y3
y4 y6
Figure 1: Top: A chain-structured LSTM net-work. Bottom: A tree-structured LSTM networkwith arbitrary branching factor.
Order-insensitive models are insufficient tofully capture the semantics of natural languagedue to their inability to account for differences inmeaning as a result of differences in word orderor syntactic structure (e.g., “cats climb trees” vs.“trees climb cats”). We therefore turn to order-sensitive sequential or tree-structured models. Inparticular, tree-structured models are a linguisti-cally attractive option due to their relation to syn-tactic interpretations of sentence structure. A nat-ural question, then, is the following: to what ex-tent (if at all) can we do better with tree-structuredmodels as opposed to sequential models for sen-tence representation? In this paper, we work to-wards addressing this question by directly com-paring a type of sequential model that has recentlybeen used to achieve state-of-the-art results in sev-eral NLP tasks against its tree-structured general-ization.
Due to their capability for processing arbitrary-length sequences, recurrent neural networks
arX
iv:1
503.
0007
5v3
[cs.C
L] 3
0 M
ay 2
015
Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks Kai Sheng Tai, Richard Socher, Christopher D. Manning, 2015
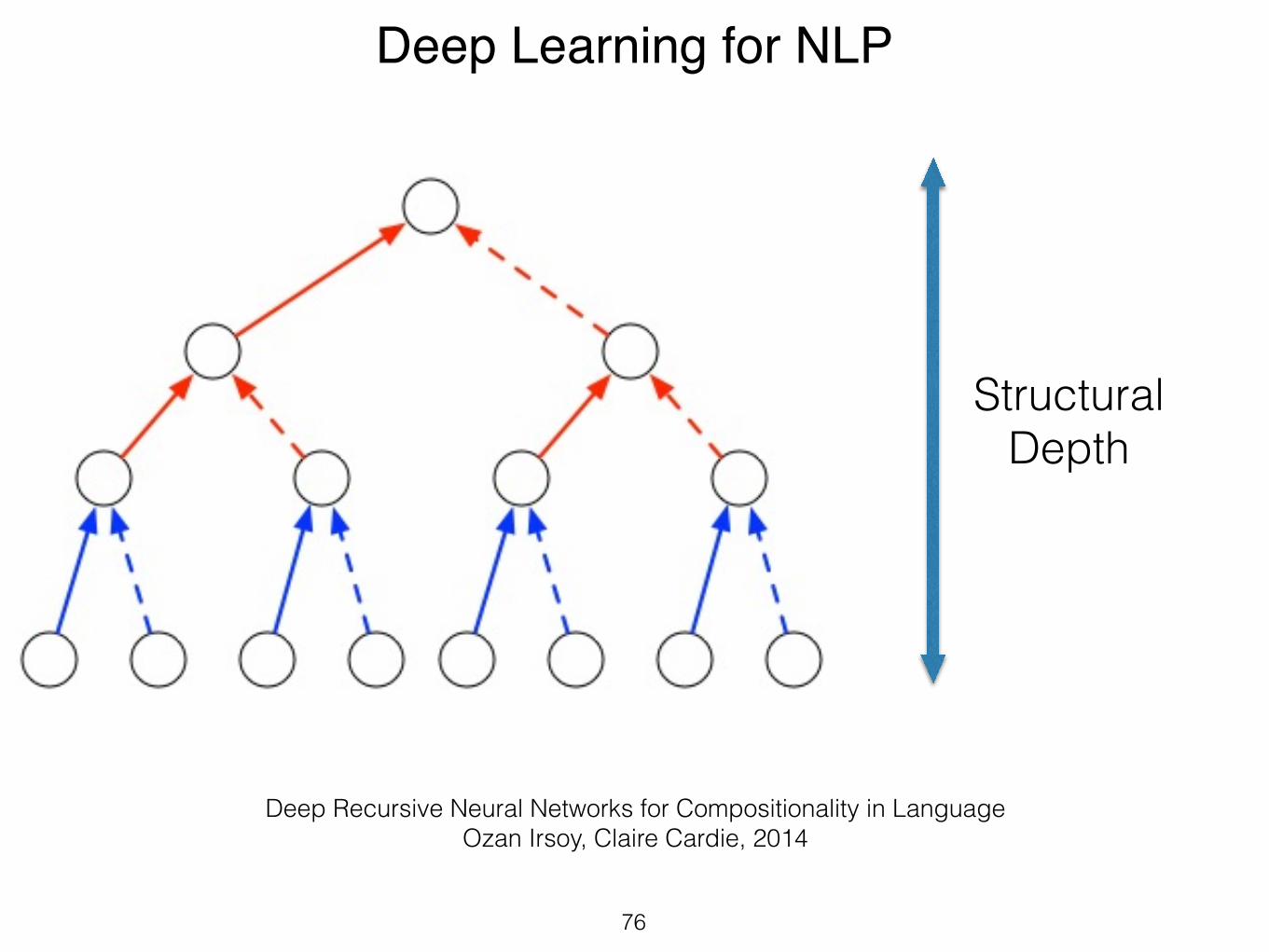
Deep Learning for NLP
76
Deep Recursive Neural Networks for Compositionality in Language Ozan Irsoy, Claire Cardie, 2014
Structural Depth
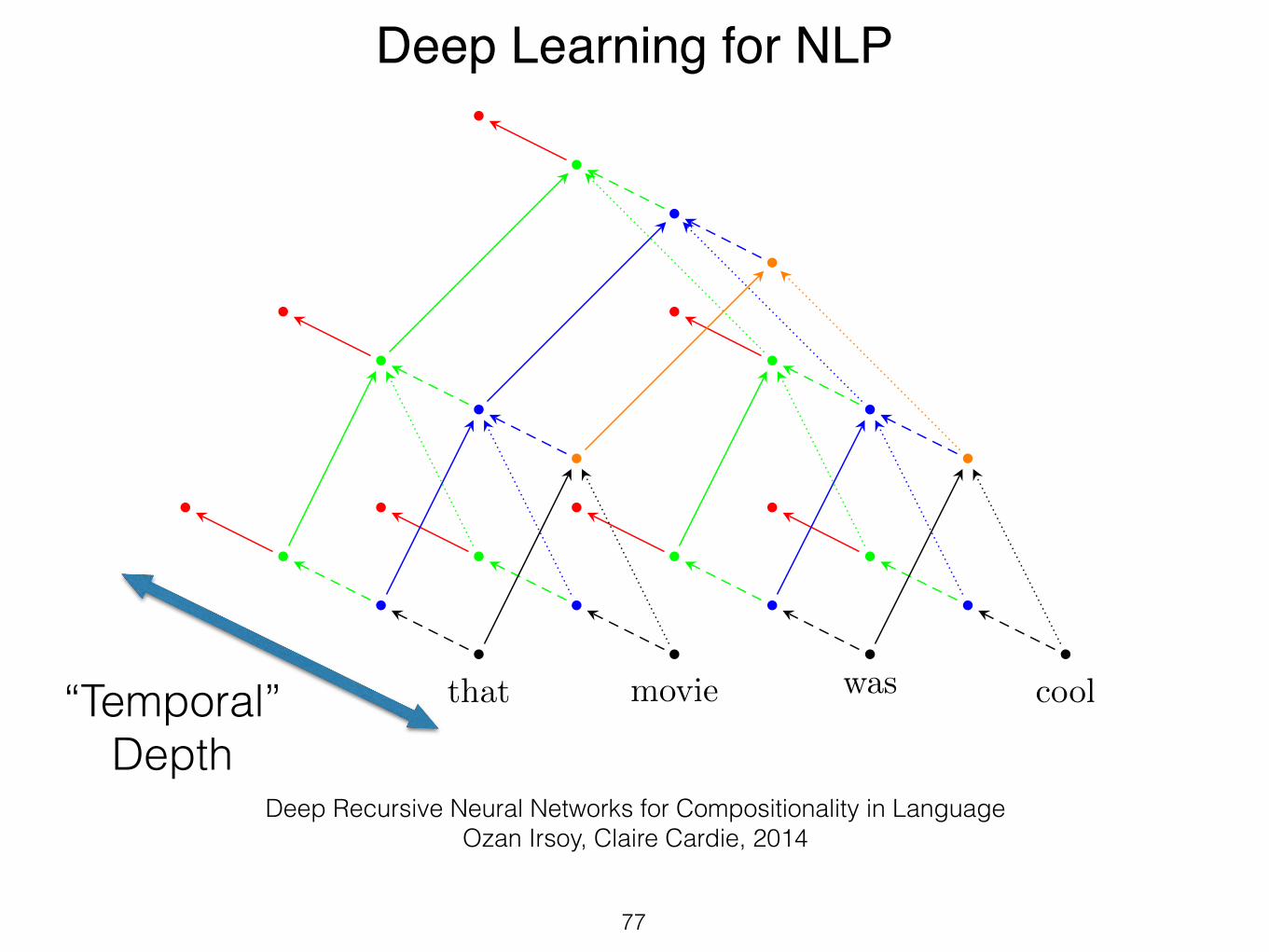
Deep Learning for NLP
77
Deep Recursive Neural Networks for Compositionality in Language Ozan Irsoy, Claire Cardie, 2014
that
movie
was
cool
Figure 2: Operation of a 3-layer deep recursive neural network. Red and black points denoteoutput and input vectors, respectively; other colors denote intermediate memory representations.Connections denoted by the same color-style combination are shared (i.e. share the same set ofweights).
the same computation recursively to compute the contribution of children to their parents, and thesame computation to produce an output response, we are, in fact, representing every internal node(phrase) in the same space [6, 8]. However, in the more conventional stacked deep learners (e.g. deepfeedforward nets), an important benefit of depth is the hierarchy among hidden representations:every hidden layer conceptually lies in a different representation space and potentially is a moreabstract representation of the input than the previous layer [1].
To address these observations, we propose the deep recursive neural network, which is constructedby stacking multiple layers of individual recursive nets:
h
(i)⌘
= f(W
(i)L
h
(i)l(⌘) +W
(i)R
h
(i)r(⌘) + V
(i)h
(i�1)⌘
+ b
(i)) (4)
where i indexes the multiple stacked layers, W (i)L
, W (i)R
, and b
(i) are defined as before within eachlayer i, and V
(i) is the weight matrix that connects the (i� 1)th hidden layer to the ith hidden layer.
Note that the untying that we described in Section 2.2 is only necessary for the first layer, since wecan map both x 2 X and h
(1) 2 H(1) in the first layer to h
(2) 2 H(2) in the second layer using sep-arate V
(2) for leaves and internals (V xh(2) and V
hh(2)). Therefore every node is represented in thesame space at layers above the first, regardless of their “leafness”. Figure 2 provides a visualizationof weights that are untied or shared.
For prediction, we connect the output layer to only the final hidden layer:
y
⌘
= g(Uh
(`)⌘
+ c) (5)
where ` is the total number of layers. Intuitively, connecting the output layer to only the last hiddenlayer forces the network to represent enough high level information at the final layer to support thesupervised decision. Connecting the output layer to all hidden layers is another option; however, inthat case multiple hidden layers can have synergistic effects on the output and make it more difficultto qualitatively analyze each layer.
Learning a deep RNN can be conceptualized as interleaved applications of the conventional back-propagation across multiple layers, and backpropagation through structure within a single layer.During backpropagation a node ⌘ receives error terms from both its parent (through structure), andfrom its counterpart in the higher layer (through space). Then it further backpropagates that errorsignal to both of its children, as well as to its counterpart in the lower layer.
4
“Temporal” Depth

Character level?
• In RNN, we use random initialized word vectors
• It doesn’t capture lexical similarity
• “compose” & “composition”
78

















