Optimizing Lattice Boltzmann and Spin Glass codes S. F. Schifano University of Ferrara and INFN-Ferrara PRACE Summer School Enabling Applications on Intel MIC based Parallel Architectures July 8-11, 2013 Casalecchio di Reno, Bologna, Italy S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 1 / 41
Transcript
Optimizing Lattice Boltzmann andSpin Glass codes
S. F. Schifano
University of Ferrara and INFN-Ferrara
PRACE Summer SchoolEnabling Applications on Intel MIC based Parallel Architectures
July 8-11, 2013
Casalecchio di Reno, Bologna, Italy
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 1 / 41
The Lattice Boltzmann Method
Lattice Boltzmann method (LBM) is a class of computational fluiddynamics (CFD) methods.
Simulation of synthetic dynamics described by the discrete Boltzmannequation, instead of the Navier-Stokes equations.
The key idea:
I a set of virtual particles called populations arranged at edges ofa discrete and regular grid
I interacting by propagation and collision reproduce – afterappropriate averaging – the dynamics of fluids.
Relevant features:
“Easy” to implement complex physics.
Good computational efficiency on MPAs.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 2 / 41
The D2Q37 Lattice Boltzmann Model
Correct treatment of:
I Navier-Stokes equations of motion
I heat transport equations
I perfect gas state equation (P = ρT )
D2 model with 37 components of velocity
Suitable to study behaviour of compressible gas and fluids
optionally in presence of combustion1 effects.
1chemical reactions turning cold-mixture of reactants into hot-mixture ofburnt product.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 3 / 41
LBM Computational Scheme
foreach time−stepforeach lattice−point
propagate ( ) ;
collide ( ) ;
endforendfor
Embarrassing parallelismAll sites can be processed in parallel applying in sequence propagate andcollide.
ChallengeEfficient implementation on computing systems to exploit a large fraction ofpeak performance.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 4 / 41
D2Q37 propagation scheme
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 5 / 41
D2Q37 propagation scheme
Gather 37 populations from 37 different lattice-sites.S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 6 / 41
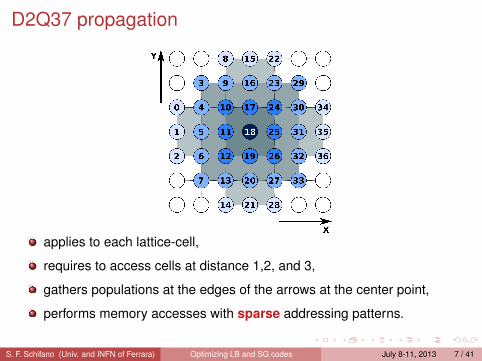
D2Q37 propagation
applies to each lattice-cell,
requires to access cells at distance 1,2, and 3,
gathers populations at the edges of the arrows at the center point,
performs memory accesses with sparse addressing patterns.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 7 / 41
D2Q37: boundary-conditions
we simulate a 2D lattice with period-boundaries along x-direction
at the top and the bottom boundary conditions are enforced:
I to adjust some values at sites y = 0 . . . 2 and y = Ny − 3 . . .Ny − 1I e.g. set vertical velocity to zero
This step (bc) is computed before the collision step.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 8 / 41
D2Q37 collision
collision is computed to each lattice-cell
computational intensive: for the D2Q37 model, andrequires > 7600 DP operations
completely local: arithmetic operations require only the populationsassociate to the site
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 9 / 41
for (t = 0; t < NTHREAD ; t++) {pthread_join (threads [t ] , NULL ) ;
}
#pragma omp p a r a l l e l p r i v a t e ( t i d ){tid = omp_get_thread_num ( ) ;theadFunc ( (void ∗ ) &targv [tid ] ) ;
}
Our implementation uses this approach.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 13 / 41
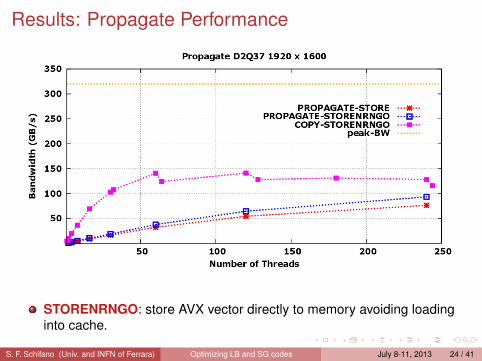
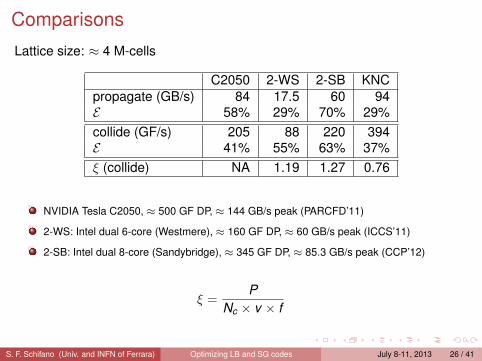
Relevant optimizations for performancesApplications running on Xeon-Phi can approach peak performance if codesexploits relevant hardware features:
core parallelism:all cores has to be kept active and working in parallel, e.g. runningdifferent functions or working on different data-sets (MIMD/multi-task orSPMD parallelism);
hyper-threading:cores have to execute at least 2, up-to 4, threads to keep hardwarepipelines busy and hide memory accesses latency;
vector programming:each core has to process data-set using vector (streaming) instructions(SIMD parallelism); in the case of Xeon-Phi up-to 8 double-precisionvalues can be processed by each vector instructions.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 14 / 41
Portions of vector used by each thread are kept at minimum distance of 4096bytes (1 page) to avoid two threads to access the same TLB entry.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 15 / 41
AVX512 Memory Copy Benchmark
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 16 / 41
AVX512 Memory Copy Benchmark: Native VS Offload
possible TLB conflicts ? Try to set PHI_USE_2MB_BUFFERS env var.S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 17 / 41
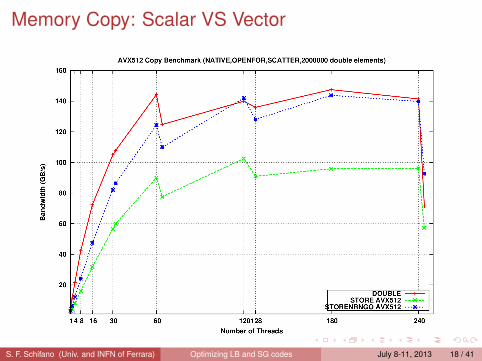
Memory Copy: Scalar VS Vector
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 18 / 41
Memory Copy: Scalar VS Vector
#pragma omp p a r a l l e l for p r i v a t e ( i )for ( i=0; i < (NTHR∗S ) ; i++ ) {
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 30 / 41
The Edwards-Anderson (EA) ModelThe system variables are spins (±1), arranged in D-dimensional(usually D=3) lattice of size L .
Spins si interacts only with its nearest neighbours
Pair of spins (si , sj ) share a coupling term Jij
The energy of a configuration {S} is computed as:
E({S}) =∑〈ij〉
Jijsisj
Each configuration {S} has a probability given by the Boltzmann factor:
P({S}) ∝ e−E({S})
kT
Average of macroscopic observable (magnetization) are defined as:
〈M〉 =∑{S}
M({S})P({S}) where M({S}) =∑
i
si
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 31 / 41
Spin Glass Monte Carlo Algorithms
A lattice size L has 2L3different configurations (e.g. L = 80⇒ 2803)
pratically impossible to manage to generate all configurations
not all configurations have the same probability and are equallyimportant.
Monte Carlo algorithms, like the Metropolis and Heatbath, are adopted:
configurations are generated according to their probability
observables average are computed as unweighted sums ofMonte Carlo generated configurations:
〈M〉 ∼∑
i
M({SMCi })
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 32 / 41
Metropolis Algorithm for EA
Require: set of {S} and {J}1: loop // loop on Monte Carlo steps2: for all si ∈ {S} do3: s′i = (si == 1) ? − 1 : 1 // flip tentatively value of si
4: ∆E =∑〈ij〉(Jij · s′i · sj )− (Jij · si · sj ) // compute energy change
5: if ∆E ≤ 0 then6: si = s′i // accept new value of si7: else8: ρ = rnd() // compute a random number 0 ≤ ρ ≤ 1, ρ ∈ Q9: if ρ < e−β∆E then // β = 1/T , T = Temperature
10: si = si ‘ // accept new value of si11: end if12: end if13: end for14: end loop
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 33 / 41
the approach to the thermal equilibriuma slowly converging process.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 34 / 41
Spin-glass is Computer Challenging
To bring a lattice L = 48 . . . 128 to the thermal equilibrium, typicalstate-of-the-art simulation-campaign steps are:
simulation of Hundreds (Thousands) systems, samples, with differentinitial values of spins and couplings,
for each sample the simulation is repeated 2-4 times with different initialspin-values (coupling values kept fixed), replicas.
Each simulation may requires 1012 . . . 1013 Monte Carlo update steps.
803 × 10 ns× 1011 MC-steps ≈ 16 years
Exploiting of parallelism is necessary.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 35 / 41
Parallel Simulation of Spin Glass
Several levels of parallelism can be exploited in Monte CarloSpin Glass simulations.
The lattice can be divided in a checkerboard scheme: alghorithm is firstapplied to all white spins, and then to all blacks (order is irrelevant).
SIMD instructions can be used to update up to V ≤ L3/2 (white or black)spins in parallel (internal parallelism).
The lattice can be divided in several sub-lattices and allocated todifferent cores. Boundaries need to be updated after updating the bulk(internal parallelism).
Several lattices (samples or replicas) can be simulated in parallel usingmultispin-coding approach (external parallelism).
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 36 / 41
Multispin Encoding (1)
Multispin encoding (for the EA model) allows to simulate severalsystems in parallel.
Assuming to run simulation on a k -bit architecture (k = 32,64,128,256,512):
spins and couplings are represented by binary values {0,1}
a k -bit architectural word hosts k -spins of k different systems
Metropolis update procedure can be bit-wise coded (no conditionalstatements, only bit-wise operations)
Require: ρ pseudo-random numberRequire: ψ = int (−(1/4β) log ρ), encoded on two bitsRequire: η = ( not Xi ), encoded on two bits
c1 = (ψ[0] and η[0])c2 = (ψ[1] and η[1]) or ((ψ[1] or η[1]) and c1)
s′i = si xor (c2 or not Xi [2]) // update value of spin si
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 37 / 41
Multispin Encoding (2)We enhanced multispin encoding approach combining it withSIMD-instructions to exploit both internal- and external-parallelism.
the 512-bit SIMD-word is divided in V = 8 . . . 512 slots
each slot hosts one spin-values of a system
each slot hosts w spin-values of different lattices.
V = internal-parallelism degree, w = external-parallelism degree.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 38 / 41
Random Number Generation
At each MC-step V (pseudo-)random numbers are needed.Same random value can be shared among the w lattice-replicas.
The Parisi-Rapuano generator is a popular choise for Spin Glass simulations:
WHEEL[K] = WHEEL[K-24] + WHEEL[K-55]
ρ = WHEEL[K] ⊕WHEEL[K-61]
WHEEL is an array of unsigned integer
SIMD instructions can be used to generate severalrandom numbers in parallel.
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 39 / 41
Spin Glass Simulation on MIC
Lattice is split in C (number of cores) sub-lattices of contigous planes,and each one (of L× L× L/C sites) is mapped on a different core.
each core first update all the white spins and then all the blacks
w/b spins are stored in half-plane data-structures (of L2/2 spins)
1: update the boundaries half-plane (indexes (0) and ((L3/C)− 1)).2: for all i ∈ [1..((L3/C)− 2)] do3: update half-planes (i)4: end for5: exchange half-plane (0) to the previous core and half-plane ((L3/C)− 1)
to the next core.
This approach requires only data exchange across the cores.
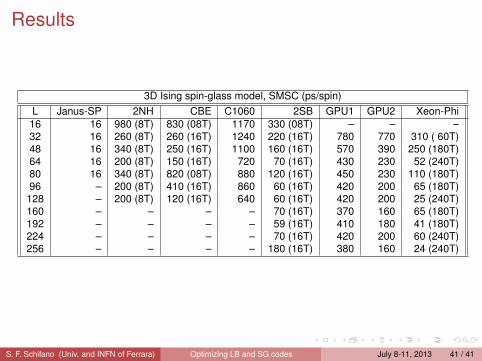
S. F. Schifano (Univ. and INFN of Ferrara) Optimizing LB and SG codes July 8-11, 2013 40 / 41












































![Improving computational efficiency of lattice Boltzmann ... · 1.1 The lattice Boltzmann method The lattice Boltzmann method [7] [20] is a relative new technique to CFD. Classical](https://static.documents.pub/doc/80x56/5f03952b7e708231d409c3df/improving-computational-efficiency-of-lattice-boltzmann-11-the-lattice-boltzmann.jpg)
![From Lattice Boltzmann Method to Lattice Boltzmann Flux … · From Lattice Boltzmann Method to Lattice Boltzmann Flux Solver Yan Wang 1, ... flows [8,13–15], compressible flows](https://static.documents.pub/doc/80x56/5cadf91b88c9938f4d8c0cd6/from-lattice-boltzmann-method-to-lattice-boltzmann-flux-from-lattice-boltzmann.jpg)







