Order Preserving Order Preserving Encryption for Numeric Encryption for Numeric Data Data Rakesh Agrawal Rakesh Agrawal Jerry Kiernan Jerry Kiernan Ramakrishnan Srikant Ramakrishnan Srikant Yirong Xu Yirong Xu IBM Almaden Research Center IBM Almaden Research Center
Transcript
Order Preserving Encryption Order Preserving Encryption for Numeric Datafor Numeric Data
IBM Almaden Research CenterIBM Almaden Research Center
OutlineOutline
Motivation and IntroductionMotivation and Introduction OPES encryptionOPES encryption Modeling the distributionModeling the distribution Experimental evaluationExperimental evaluation
MotivationMotivation
Encryption is rapidly becoming a Encryption is rapidly becoming a requirement in a myriad of business requirement in a myriad of business settings (e.g., health care, financial, settings (e.g., health care, financial, retail, government), driven by retail, government), driven by legislations (e.g. SB1386, HIPAA)legislations (e.g. SB1386, HIPAA)
Encrypting databases unleashes a host Encrypting databases unleashes a host of problems:of problems:– Performance slowdownPerformance slowdown– Incompatibility with standard database Incompatibility with standard database
featuresfeatures E.g. comparison predicates and the use of indexesE.g. comparison predicates and the use of indexes
– Changes to applications for encryptionChanges to applications for encryption Encryption functions now appear in queriesEncryption functions now appear in queries
if (p1 < p2) then (c1 < c2)if (p1 < p2) then (c1 < c2)
Order Preserving Order Preserving Encryption FunctionEncryption Function
E is an order preserving encryption function,and p1 and p2 are two plaintext values, and
c1 = E(p1)c2 = E(p2)
Threat ModelThreat Model
The storage system used by the DBMS is The storage system used by the DBMS is untrusted, i.e. vulnerable to compromiseuntrusted, i.e. vulnerable to compromise
The DBMS software is trustedThe DBMS software is trusted Ciphertext only attackCiphertext only attack
– The adversary has access to all (but only) The adversary has access to all (but only) encrypted values encrypted values
Guard against percentile exposureGuard against percentile exposure– An adversary should not be able to get even An adversary should not be able to get even
an estimate of true valuesan estimate of true values
Design GoalsDesign Goals
Query results from OPES will be Query results from OPES will be sound and completesound and complete
Comparison operations will be Comparison operations will be performed without decrypting the performed without decrypting the operandsoperands
Standard database indexes can Standard database indexes can be used over encrypted databe used over encrypted data
Tolerate updatesTolerate updates
Integration of Integration of Encryption and Query Encryption and Query
Users have a plaintext view of an encrypted database
Plaintext queries are translated into equivalent queries over encrypted data
Tables are encrypted using standard as well as order
preserving encryption
Comparison operators are directly applied over encrypted columns
We hereafter strictly focus on the OPES
algorithms
OutlineOutline
Motivation and IntroductionMotivation and Introduction OPES encryptionOPES encryption Modeling the distributionModeling the distribution Experimental evaluationExperimental evaluation
ApproachApproach
Plaintext data has unknown Plaintext data has unknown distributiondistribution
User selects the target User selects the target (ciphertext) distribution(ciphertext) distribution
Ciphertext values exhibit the Ciphertext values exhibit the target distributiontarget distribution
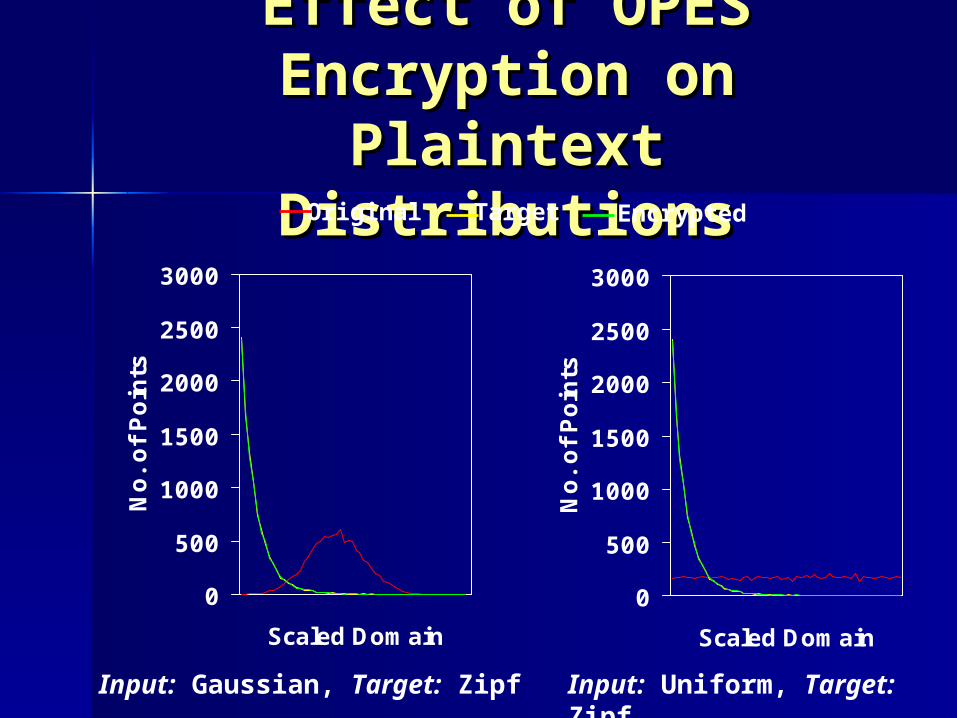
Effect of OPES Effect of OPES Encryption on Encryption on
Plaintext DistributionsPlaintext Distributions
Input: Gaussian, Target: Zipf
Original EncryptedTarget
0
500
1000
1500
2000
2500
3000
Scaled Domain
No. of Poin
ts
Input: Uniform, Target: Zipf
0
500
1000
1500
2000
2500
3000
Scaled Domain
No. of Poin
ts
OPES Key GenerationOPES Key Generation
Sample of source values from the plaintext distribution
Sample of source values from the plaintext distribution
Sample of target values from the ciphertext distribution
Sample of target values from the ciphertext distribution
OPES Key Generation
OPES Key
OPES KeysOPES Keys
SourceUniform Uniform
TargetSource to uniform
Target to uniform
Two Step EncryptionTwo Step Encryption
Source (plaintext) to uniformSource (plaintext) to uniform Uniform to target (ciphertext)Uniform to target (ciphertext)
OPES EncryptionOPES Encryption
SourceUniform Uniform
Target
Encrypt
Decrypt
Step I Step II
Step II
Step I
OutlineOutline
Motivation and IntroductionMotivation and Introduction OPES encryptionOPES encryption Modeling the distributionModeling the distribution Experimental evaluationExperimental evaluation
Modeling the Modeling the DistributionDistribution HistogramsHistograms
– Equi-depth, equi-width, waveletsEqui-depth, equi-width, wavelets Number of buckets required unreasonably largeNumber of buckets required unreasonably large Over fitting the modelOver fitting the model
ParametricParametric– Poor estimation for irregular distributionsPoor estimation for irregular distributions
Hybrid [Konig and Weikum 99]Hybrid [Konig and Weikum 99]– Query result size estimationQuery result size estimation– ApproachApproach
Partition the data into bucketsPartition the data into buckets Model the distribution within a bucket as a splineModel the distribution within a bucket as a spline Fixed number of bucketsFixed number of buckets
Our ApproachOur Approach
Hybrid [Konig and Weikum 99]Hybrid [Konig and Weikum 99]– Partition the data into bucketsPartition the data into buckets– Model the distribution within each Model the distribution within each
bucket as a linear splinebucket as a linear spline The number of buckets is not The number of buckets is not
fixedfixed We use MDL to determine the We use MDL to determine the
number of bucket boundariesnumber of bucket boundaries
MDLMDL
The best model for encoding data The best model for encoding data minimizes the sum of the cost ofminimizes the sum of the cost of– Describing the modelDescribing the model– Describing data in terms of the Describing data in terms of the
modelmodel
Model CostsModel Costs
Data CostData Cost– Using a mapping M from [pUsing a mapping M from [pll,p,phh) to [f) to [fll,f,fhh), ),
the cost of encoding pthe cost of encoding pii is is C(pC(pii)=log(f)=log(fii-E(i))-E(i)) DC(pDC(pll,p,phh) = C(p) = C(pll)+C(p)+C(pl+1l+1)+…+C(p)+…+C(ph-1h-1))
Incremental Model CostIncremental Model Cost– Fixed cost for each additional bucketFixed cost for each additional bucket
Boundary valueBoundary value Boundary parametersBoundary parameters
– SlopeSlope– Scale factorScale factor
Computing BoundariesComputing Boundaries
Growth phaseGrowth phase– [p[pll,p,phh) with h-l-1 sorted points {p) with h-l-1 sorted points {pl+1l+1,p,pl+2l+2,…,p,…,ph-1h-1}}
Compute spline for [pCompute spline for [pll,p,phh) ) Compute [fCompute [fll,f,fhh) using the spline) using the spline
– Find further split point pFind further split point pss with f with fss having the having the maximum deviation from the expected valuemaximum deviation from the expected value
Prune phasePrune phase– LB(pLB(pll,p,phh)=DC(p)=DC(pll,p,phh)-DC(p)-DC(pll,p,pss)-DC(p)-DC(pss,p,phh)-IMC)-IMC– GB(pGB(pll,p,phh)=LB(p)=LB(pll,p,phh)+GB(p)+GB(pll,p,pss)+GB(p)+GB(pss,p,phh))– if (GB > 0), the split at pif (GB > 0), the split at pss is retained is retained
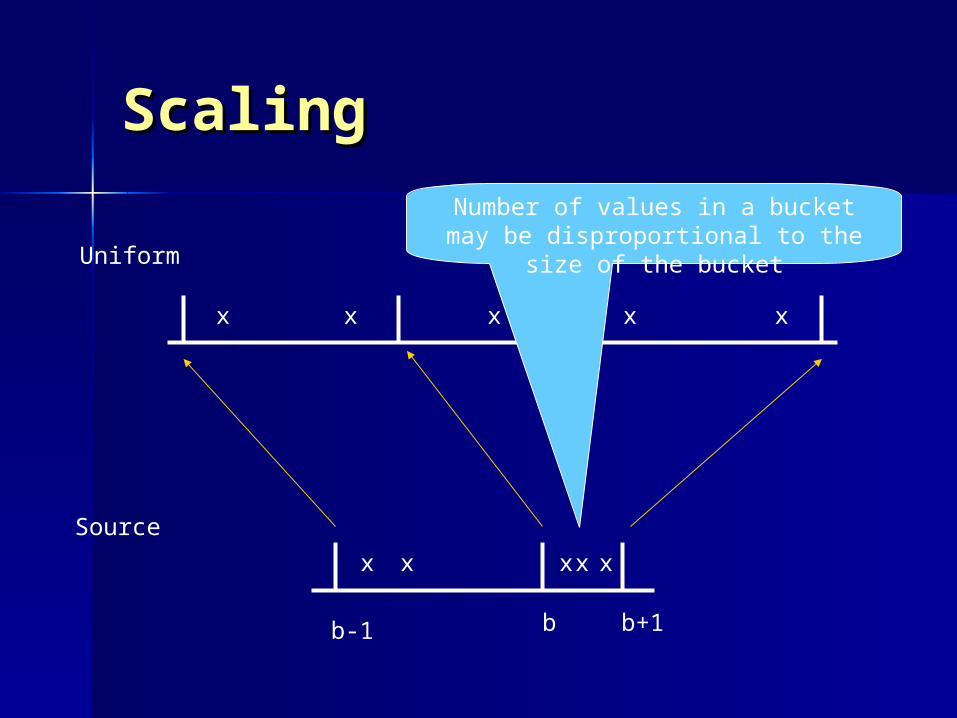
ScalingScaling
Source
Uniform
xx xx x
x x x x x
b-1 b b+1
Number of values in a bucket may be disproportional to the size of the bucket
UpdatesUpdates
The scale factor ensures that The scale factor ensures that each distinct plaintext value each distinct plaintext value maps to distinct ciphertext valuesmaps to distinct ciphertext values
Encrypted values need not be Encrypted values need not be recomputed unless the recomputed unless the distribution of plaintext values distribution of plaintext values changeschanges
Quality of EncryptionQuality of Encryption
KS Statistical TestKS Statistical Test– Can we disprove, to a certain Can we disprove, to a certain
required level of significance, the required level of significance, the null hypothesis that two data sets null hypothesis that two data sets are drawn from the same are drawn from the same distribution function?distribution function?
– If not, then the ciphertext If not, then the ciphertext distribution cannot be distinguished distribution cannot be distinguished from the specified target distributionfrom the specified target distribution
DuplicatesDuplicates
AssumptionsAssumptions– A large number of duplicates may leak A large number of duplicates may leak
information about the distribution of information about the distribution of valuesvalues
Alternatively,Alternatively,– Map duplicates to distinct valuesMap duplicates to distinct values– if (f = M(p), f’ = M(p+1))if (f = M(p), f’ = M(p+1))
[f,f’) = M(p)[f,f’) = M(p)– Equality expressed as a rangeEquality expressed as a range– Equi-joins can no longer be expressedEqui-joins can no longer be expressed
However, many numeric attributes (e.g., However, many numeric attributes (e.g., salarysalary) ) may rarely be used in joinsmay rarely be used in joins
OutlineOutline
Motivation and IntroductionMotivation and Introduction OPES encryptionOPES encryption Modeling the distributionModeling the distribution Experimental evaluationExperimental evaluation
CensusCensus– UCI KDD archive, PUMS census data UCI KDD archive, PUMS census data
(30,000) records(30,000) records GaussianGaussian ZipfZipf UniformUniform
Source:Source: GaussianGaussian
Target:Target: ZipfZipf
DefaultDefault
Percentile ExposurePercentile Exposure
Source Source distributiodistributionn
Target Target distributiodistributionn
Average Average change in change in percentilepercentile
CensusCensus GaussianGaussian 3737
CensusCensus ZipfZipf 77
CensusCensus UniformUniform 3838
GaussianGaussian ZipfZipf 4545
GaussianGaussian UniformUniform 1717
ZipfZipf UniformUniform 4444
Time to the Build Time to the Build ModelModel
0
0.1
0.2
0.3
0.4
0.5
10K 100K 1M 10M
Dataset size
Tim
e p
er
tuple
(m
sec.
)
ZipfUniformGaussian
Insertion OverheadInsertion Overhead
0
20
40
60
80
100
1 10 100
1000
10,000
Tuples inserted
% o
verh
ead
10K100K1M10M
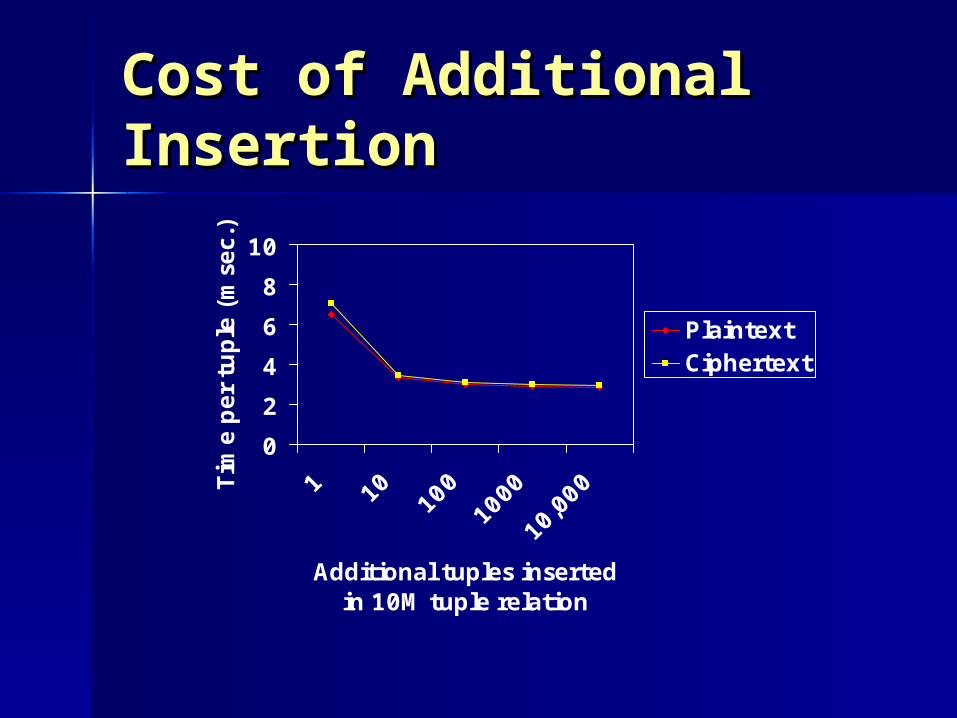
Cost of Additional Cost of Additional InsertionInsertion
0
2
4
6
8
10
1 10 100
1000
10,000
Additional tuples inserted in 10M tuple relation
Tim
e p
er
tuple
(m
sec.
)
PlaintextCiphertext
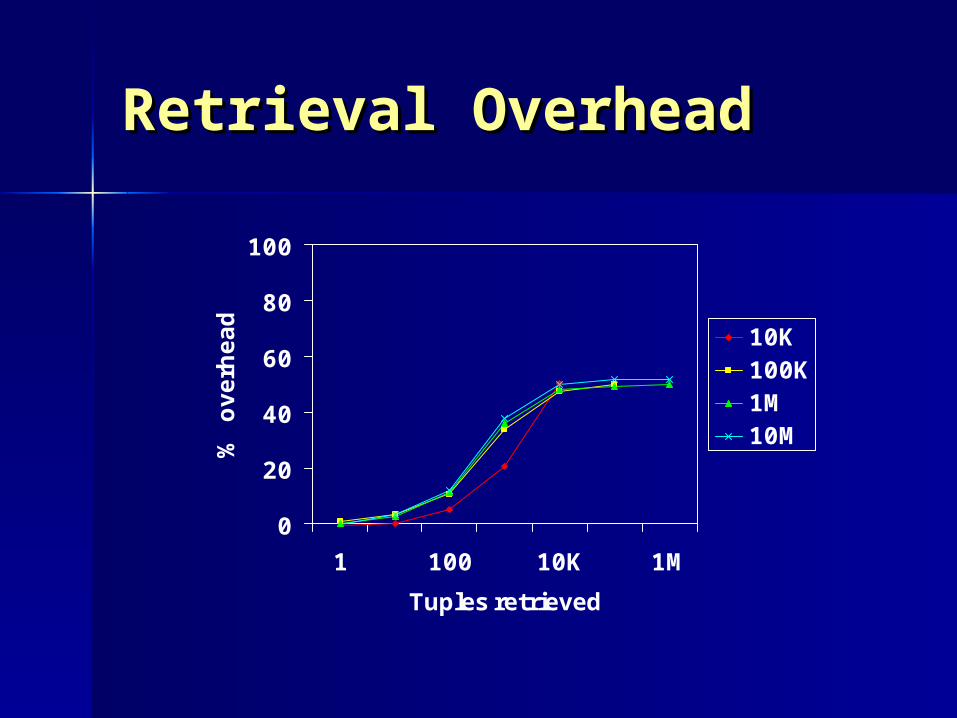
Retrieval OverheadRetrieval Overhead
0
20
40
60
80
100
1 100 10K 1M
Tuples retrieved
% o
verh
ead
10K100K1M10M
Retrieval TimeRetrieval Time
0.001
0.01
0.1
1
10
1
10
100
1000
10K
100K
1M
Tuples retrieved (10M tuple relation)
Tim
e p
er
tuple
(m
sec.
)
PlaintextCiphertext
Related WorkRelated Work
Polynomial functionsPolynomial functions– Ignores the distribution of plaintext/ciphertext valuesIgnores the distribution of plaintext/ciphertext values
Database as a serviceDatabase as a service– Requires post processing of query resultsRequires post processing of query results
Privacy homomorphismsPrivacy homomorphisms– Comparison operations not investigatedComparison operations not investigated
Keyword searches on encrypted dataKeyword searches on encrypted data– Designed for keyword retrievalDesigned for keyword retrieval– Range queries not supportedRange queries not supported
Smartcard-based schemesSmartcard-based schemes– Infeasible for large rangesInfeasible for large ranges
Order-preserving hashingOrder-preserving hashing– Protecting the hash values from cryptanalysis is not a Protecting the hash values from cryptanalysis is not a
concern, nor is deciphering plaintext values from hash concern, nor is deciphering plaintext values from hash valuesvalues
– Designed for static collectionsDesigned for static collections
Closing RemarksClosing Remarks
Ensuring safety without impeding the Ensuring safety without impeding the flow of information is a hard problemflow of information is a hard problem
Current choicesCurrent choices– Plaintext databasePlaintext database– Encrypted databases with loss of Encrypted databases with loss of
functionality or performancefunctionality or performance Our approach focused on the trade-off Our approach focused on the trade-off
between security and efficiencybetween security and efficiency We developed an algorithm which We developed an algorithm which
could easily be integrated with current could easily be integrated with current systemssystems
BackupBackup
EncodeEncode
Encode(p) = z(spEncode(p) = z(sp22+p)+p)
p p [0,p [0,phh), s = q/(2r), ), s = q/(2r), z > 0
distribution has density function qp + r
p is the source (target) value
s is the quadratic coefficient
z is the scale factor
DecodeDecode
z z z z22 + 4zsf + 4zsf
2zs2zs
ff [0, [0, f fhh), s = q/(2r), z > ), s = q/(2r), z > 00
f is the flattened value
s is the quadratic coefficient
z is the scale factor
Decode (f) =Decode (f) =
Order Preserving Order Preserving EncryptionEncryption
CipherteCiphertextxt
PlaintextPlaintext
11 2800028000
22 3500035000
…… ……
CCnn PPnn
Compute distinct Compute distinct attribute values in attribute values in ascending orderascending order
Ciphertext is the Ciphertext is the index valueindex value
• Effectively hides the Effectively hides the distribution of plaintext distribution of plaintext valuesvalues
•The key size is The key size is proportional to the proportional to the number of distinct number of distinct attribute valuesattribute values
•Any updates require Any updates require recomputing the key and recomputing the key and ciphertext valuesciphertext values
NoNo NameName PositioPositionn
SalarySalary LocatioLocationn
…… …… …… …… ……
Target Distribution Target Distribution RequirementRequirement Why isn’t the source-to-uniform Why isn’t the source-to-uniform
transformation sufficient for order transformation sufficient for order preserving encryption?preserving encryption?
It is, butIt is, but– The target distribution may cause an The target distribution may cause an
adversary to make incorrect assumptions adversary to make incorrect assumptions about the source distributionabout the source distribution
– The organization of the source distribution The organization of the source distribution cannot be inferred from the targetcannot be inferred from the target
Quadratic CoefficientQuadratic Coefficient
bb11 bb22
xx xx xx xx xx xx xx xx……
vvb1b1 – v – vb2b2
v v ==
xx xx
ii11 jj11 ii22 jj22
jj22 – i – i22 jj11 – i – i11vvj2j2 – v – vi2i2 vvj1j1 – v – vi1i1
--
q =q = s s = = 2 2 jj11 – i – i11
vvj1j1 – v – vi1i1
qq
Scale Factor Scale Factor ConstraintsConstraints
for all p [0,w) : M(p+1) – M(p) 2
wf = Kn
Ensures that there is a distinct mapped value for each input value
The width of a bucket in the mapped space is a function of the number of elements n in the bucket
K is the minimum width needed across buckets
Scale FactorScale Factor
Kn
sw2 + wz =
K = max [x(swi2+w)], i = 1, …, m,
x = 2, s 0
2/(1 + s(2w – 1)), s < 0
The scale factor will stretch short buckets to the width of the largest
bucket, further increasing the dimension of a bucket by a factor of the number of
elements in the bucket
SlopeSlope
b-1 b
The values within a single bucket are unevenly distributed within the bucket





















































![[A3] SHASTY Srikant and SRIDHAR Sanjay_Transit Oriented Development](https://static.documents.pub/doc/80x56/577ce47a1a28abf1038e703b/a3-shasty-srikant-and-sridhar-sanjaytransit-oriented-development.jpg)



