Oregon State University School of Electrical Engineering and Computer Scie End-User Programming of Intelligent Learning Agents Prasad Tadepalli, Ron Metoyer, and Margaret Burnett In conjunction with the EUSES Consortium: E nd U sers S haping E ffective S oftware
Transcript
Oregon State UniversitySchool of Electrical Engineering and Computer Science
End-User Programming of Intelligent Learning Agents
Prasad Tadepalli, Ron Metoyer, and Margaret Burnett
In conjunction with the EUSES Consortium:
End Users Shaping Effective Software
2
Prasad Tadepalli:Machine Learning
• Scaling Average-reward Reinforcement Learning to large spaces
Relational Learning
• Relational learning from prior knowledge and sparse user input
• Relational Reinforcement Learning
3
• NSF CAREER Award winner (2003).
• Complexities of animated content.– Creating characters for training.– Emphasis on usability and realism.
• Real-time simulation of evacuation dynamics for large crowds.
• An ITR project by Oregon State, Carnegie Mellon, Drexel, Nebraska, & Penn State.
• Principal architect: • Forms/3, FAR
end-user programming support.
• Co-architect: • Functions for Excel users (a Microsoft Research
project).
5
Motivation
• Task Training– Sports– Military
Boston Dynamics Inc.
Electronic Arts
Who creates the training content?
6
Current Approaches
• Joystick Control: – User does all (once, not reusable).
• Scripting Languages– User does all (reusable program).
• Programming by Demonstration – User and system share.
• Autonomous Agents – System does all.
7
Application:Quarterback Training
• QB’s can benefit from 3D training content• Coaches:
– Do not program or animate.– Need responsive, semi-intelligent agents that perform
football tasks.
• Agents:– Should get better over time.– Should do so with few examples.
• Agent behavior: – Must morph over time (different opponents).
8
End-User Programming by Demonstration
• Generalizing from demonstrations is still an active area of research:– Some viable approaches for particular
assumptions, but not a solved problem.
• Other systems allow demonstrating only reactive behaviors.– Not used to train people strategy.– Largely distinct from machine learning.
9
Our Approach to End-User Programming
• Our approach: demonstrate goals and strategies to achieve the goals.– Allows generalization and planning by agents.– Thus, suited to training:
• Agents can simulate both “good” characters for training (desirable strategies) ...
• and “bad” characters (strategies we know they employ).
10
Example
• Goal: Get the football to Character A.– Demonstration: Start state, goal state.– Research issue: “What is relevant”?
• Any trees are ignorable background.• Character A can be any character.• The football is a unique object.
Start: Goal:
11
• Strategy 1: Pass it directly.– Demonstration: Passing to A.– “What’s relevant” issues arise again.
• Strategy 2: Pass it to B who passes to A.– New issue: recursiveness. (Need to learn a general
strategy of “get it to someone who can get it to closer to A”.)
Example (cont.)
12
Machine Learning Challenges
• Learning must be on-line.
• Users can only give a few examples.
• Provide a predictable model of generalization.
• Must include support for debugging.
• Must allow safety checks.
• Expressive representation language.
13
Strategy Languages
• Some high-level languages exist to express strategies, e.g., Golog, CML.
• Our plan: simpler rule-based languages, suitable for learning.– Starting point: our previous work on a
decomposition-rule language:
IF Condition(s) and Goal(s)
Then Subgoals(s1,s2,..sn)
While invariant conditions hold.
14
Requirements of the Learning Algorithms
• Follow HCI findings: – User motivation, attention, trust.
• Need transparent generalization procedure, e.g., no neural nets.
• Treat user input as examples of high-level specification of strategy...– ...and fill in the details. – User “steers” agent behaviors to correct faulty
generalizations.
• Assertions to monitor behavior.– Provided, Inferred, and propagated.
15
Learning from Exercises
• Generate examples automatically by searching for successful plans.
• Bottom-up learning of skills.– Learn how to solve simple problems
first.– Compose known strategies for solving
subgoals to solve more complex goals.
16
Oops! That’s Not Right!
• Debugging by end-user programmers.– When the agents pick the right strategy but
it doesn’t work right.– When the agents pick the wrong strategies.
• These provide negative examples to the learning component.
17
How to Support Debugging?
• User/system collaboration.– User helps narrow the problem. – System revises its rules and runs them on the
example until the user is satisfied.
• Testing and Assertions– Used for quality control, but designed
specifically for end users.– Assertions will be used to rule out bad
generalizations.
18
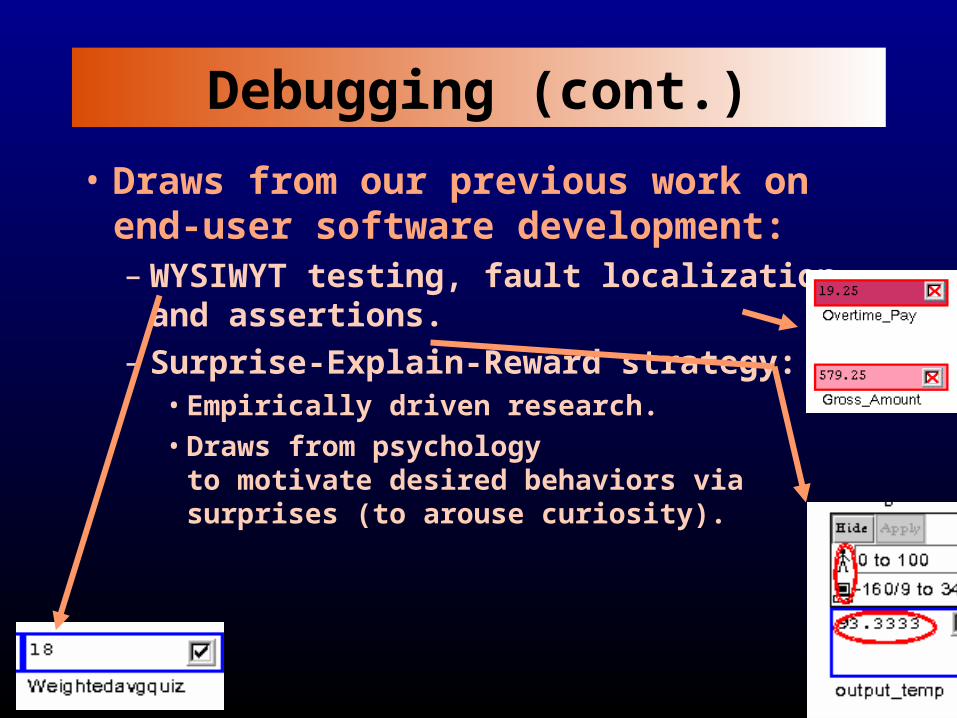
Debugging (cont.)
• Draws from our previous work on end-user software development: – WYSIWYT testing, fault localization,
and assertions.– Surprise-Explain-Reward strategy:
• Empirically driven research.• Draws from psychology
to motivate desired behaviors viasurprises (to arouse curiosity).
19
Research Issues
• How to learn from a small number of examples?
• How to let the user “speak” his/her own language?
• How to motivate the users and earn their trust?
• How to facilitate debugging and maintenance in a natural way?
• How to make learning safe?
20
Summary: The Research Question
• Is it possible to empower end users...
• ...to program in evolving task-training environments...
• ...using machine learning and programming by demonstration?
21
(The End)
22
Leftovers
23
24
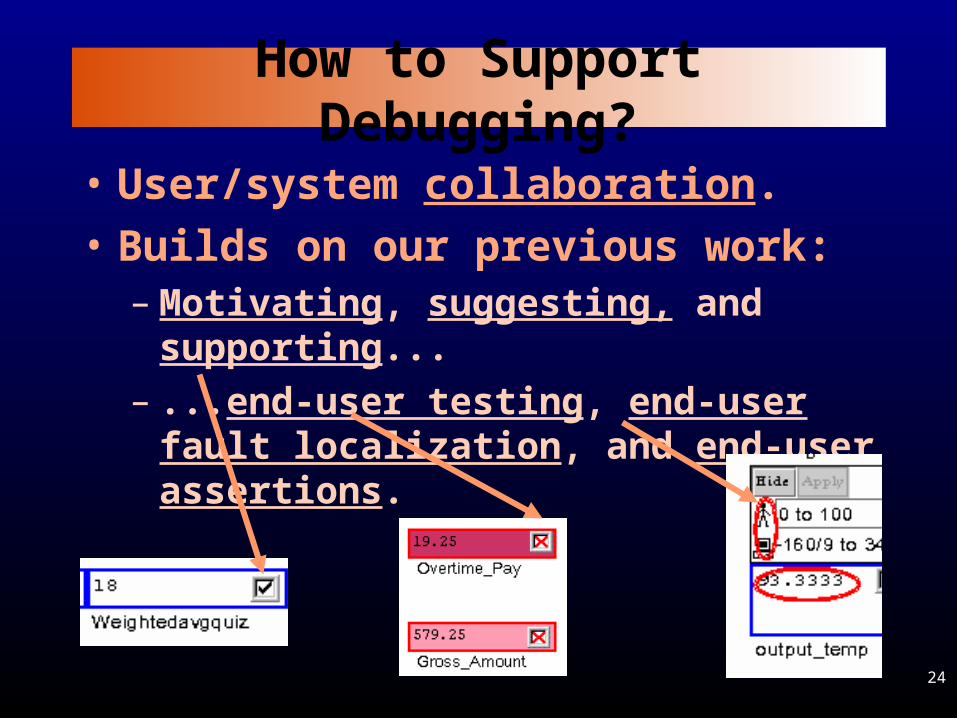
How to Support Debugging?
• User/system collaboration.
• Builds on our previous work: – Motivating, suggesting, and supporting...– ...end-user testing, end-user fault
localization, and end-user assertions.
25
Web Navigation (**possibly cut)
Navigation of the web to satisfy a goal:• Students trying to find an appropriate
school that match their interests and constraints.
• Shoppers looking for bargain purchases.• Traders searching for appropriate stocks
to buy and sell. In each case, the system should learn to retrieve the target information efficiently.
26
Debugging
• Negative examples are used to specialize over-general rules.
• Maintain confidences of rules based on their support among the training examples and suggest possible incorrect rules.
• Encourage users to enter assertions to correct errors.
• Verify assertions during rule evaluation and warn the user if they are not valid.