68
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Parallel Programming in C with MPI and OpenMP Michael J. Quinn Michael J. Quinn
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | hayden-sellers |
| View: | 28 times |
| Download: | 1 times |

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Parallel Programmingin C with MPI and OpenMP
Michael J. QuinnMichael J. Quinn

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Chapter 8
Matrix-vector MultiplicationMatrix-vector Multiplication

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Chapter Objectives
Review matrix-vector multiplicaitonReview matrix-vector multiplicaiton Propose replication of vectorsPropose replication of vectors Develop three parallel programs, each Develop three parallel programs, each
based on a different data decompositionbased on a different data decomposition

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Outline
Sequential algorithm and its complexitySequential algorithm and its complexity Design, analysis, and implementation of Design, analysis, and implementation of
three parallel programsthree parallel programs Rowwise block stripedRowwise block striped Columnwise block stripedColumnwise block striped Checkerboard blockCheckerboard block

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
2 1 0 4
3 2 1 1
4 3 1 2
3 0 2 0
1
3
4
1
=
Sequential Algorithm
22 1 50
4
1
3
594
1
92 1 0 4 1
3
4
1
33
1
92 3 131
4
141
1
14
1
3
4
1
3 2 1 1
44
1
133
3
171 4 192
1
19
1
3
4
1
4 3 1 2
3 3
1
3
30 112
4
110 1 11
1
3
4
13 0 2 0

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Storing Vectors
Divide vector elements among processesDivide vector elements among processes Replicate vector elementsReplicate vector elements Vector replication acceptable because Vector replication acceptable because
vectors have only vectors have only nn elements, versus elements, versus nn22 elements in matriceselements in matrices

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Rowwise Block Striped Matrix
Partitioning through domain decompositionPartitioning through domain decomposition Primitive task associated withPrimitive task associated with
Row of matrixRow of matrix Entire vectorEntire vector
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
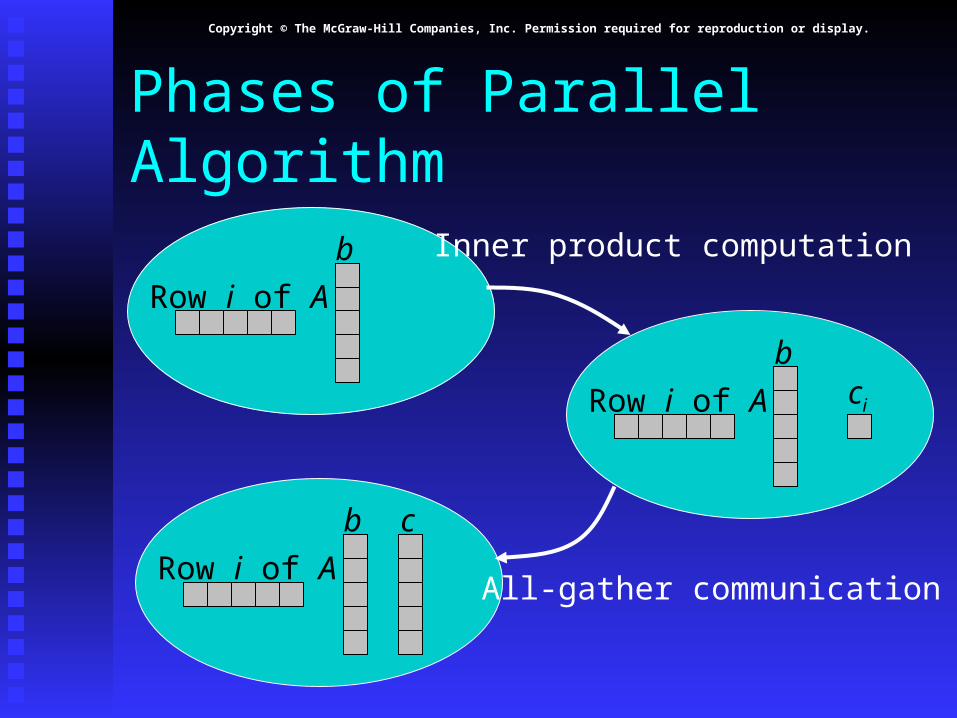
Phases of Parallel Algorithm
Row i of A
b
Row i of A
bci
Inner product computation
Row i of A
b c
All-gather communication

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Agglomeration and Mapping
Static number of tasksStatic number of tasks Regular communication pattern (all-gather)Regular communication pattern (all-gather) Computation time per task is constantComputation time per task is constant Strategy:Strategy:
Agglomerate groups of rowsAgglomerate groups of rows Create one task per MPI processCreate one task per MPI process

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Complexity Analysis
Sequential algorithm complexity: Sequential algorithm complexity: ((nn22)) Parallel algorithm computational Parallel algorithm computational
complexity: complexity: ((nn22/p/p)) Communication complexity of all-gather: Communication complexity of all-gather:
(log(log p + n p + n)) Overall complexity: Overall complexity: ((nn22/p + /p + log log pp))

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Isoefficiency Analysis
Sequential time complexity: Sequential time complexity: ((nn22)) Only parallel overhead is all-gatherOnly parallel overhead is all-gather
When When nn is large, message transmission time is large, message transmission time dominates message latencydominates message latency
Parallel communication time: Parallel communication time: ((nn)) nn22 CpnCpn nn Cp Cp and and M(n) M(n) = = nn22
System is not highly scalableSystem is not highly scalable
pCppCpCpM 222 //)(

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Block-to-replicated Transformation

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Allgatherv

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Allgatherv
int MPI_Allgatherv ( void *send_buffer, int send_cnt, MPI_Datatype send_type, void *receive_buffer, int *receive_cnt, int *receive_disp, MPI_Datatype receive_type, MPI_Comm communicator)

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Allgatherv in Action

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function create_mixed_xfer_arrays
First arrayFirst array How many elements contributed by each How many elements contributed by each
processprocess Uses utility macro BLOCK_SIZEUses utility macro BLOCK_SIZE
Second arraySecond array Starting position of each process’ blockStarting position of each process’ block Assume blocks in process rank orderAssume blocks in process rank order

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function replicate_block_vector
Create space for entire vectorCreate space for entire vector Create “mixed transfer” arraysCreate “mixed transfer” arrays Call Call MPI_AllgathervMPI_Allgatherv

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function read_replicated_vector
Process Process pp-1-1 Opens fileOpens file Reads vector lengthReads vector length
Broadcast vector length (root process = Broadcast vector length (root process = pp-1)-1) Allocate space for vectorAllocate space for vector Process Process pp-1 reads vector, closes file-1 reads vector, closes file Broadcast vectorBroadcast vector

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function print_replicated_vector
Process 0 prints vectorProcess 0 prints vector Exact call to Exact call to printfprintf depends on value of depends on value of
parameter parameter datatypedatatype

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Run-time Expression
: inner product loop iteration time: inner product loop iteration time Computational time: Computational time: nnn/pn/p All-gather requires All-gather requires log log pp messages with messages with
latency latency Total vector elements transmitted:Total vector elements transmitted:
(2(2log log pp -1) / 2-1) / 2log log pp Total execution time: Total execution time: nnn/pn/p + + log log pp + +
(2(2log log pp -1) / (2-1) / (2log log pp ))

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Benchmarking ResultsExecution Time (msec)Execution Time (msec)
pp PredictedPredicted ActualActual SpeedupSpeedup MflopsMflops
11 63.463.4 63.463.4 1.001.00 31.631.6
22 32.432.4 32.732.7 1.941.94 61.261.2
33 22.322.3 22.722.7 2.792.79 88.188.1
44 17.017.0 17.817.8 3.563.56 112.4112.4
55 14.114.1 15.215.2 4.164.16 131.6131.6
66 12.012.0 13.313.3 4.764.76 150.4150.4
77 10.510.5 12.212.2 5.195.19 163.9163.9
88 9.49.4 11.111.1 5.705.70 180.2180.2
1616 5.75.7 7.27.2 8.798.79 277.8277.8

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Columnwise Block Striped Matrix
Partitioning through domain decompositionPartitioning through domain decomposition Task associated withTask associated with
ColumnColumn of matrix of matrix Vector Vector elementelement

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Proc 4
Processor 0’s initial computation
Processor 1’s initial computation
Proc 2
Proc 3
Matrix-Vector Multiplicationc0 = a0,0 b0 + a0,1 b1 + a0,2 b2 + a0,3 b3 + a4,4 b4
c1 = a1,0 b0 + a1,1 b1 + a1,2 b2 + a1,3 b3 + a1,4 b4
c2 = a2,0 b0 + a2,1 b1 + a2,2 b2 + a2,3 b3 + a2,4 b4
c3 = a3,0 b0 + a3,1 b1 + a3,2 b2 + a3,3 b3 + b3,4 b4
c4 = a4,0 b0 + a4,1 b1 + a4,2 b2 + a4,3 b3 + a4,4 b4

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
All-to-all Exchange (Before)
P0 P1 P2 P3 P4

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
All-to-all Exchange (After)
P0 P1 P2 P3 P4

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Phases of Parallel AlgorithmC
olum
n i o
f A
b
Col
umn
i of
A
b ~cMultiplications
Col
umn
i of
A
b ~c
All-to-all exchange
Col
umn
i of
A
b c
Reduction

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Agglomeration and Mapping
Static number of tasksStatic number of tasks Regular communication pattern (all-to-all)Regular communication pattern (all-to-all) Computation time per task is constantComputation time per task is constant Strategy:Strategy:
Agglomerate groups of columnsAgglomerate groups of columns Create one task per MPI processCreate one task per MPI process

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Complexity Analysis
Sequential algorithm complexity: Sequential algorithm complexity: ((nn22)) Parallel algorithm computational Parallel algorithm computational
complexity: complexity: ((nn22/p/p)) Communication complexity of all-to-all: Communication complexity of all-to-all:
((p + n/pp + n/p)) Overall complexity: Overall complexity: ((nn22/p + /p + log log pp))

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Isoefficiency Analysis
Sequential time complexity: Sequential time complexity: ((nn22)) Only parallel overhead is all-to-allOnly parallel overhead is all-to-all
When When nn is large, message transmission is large, message transmission time dominates message latencytime dominates message latency
Parallel communication time: Parallel communication time: ((nn)) nn22 CpnCpn nn CpCp Scalability function same as rowwise Scalability function same as rowwise
algorithm: algorithm: CC22pp
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
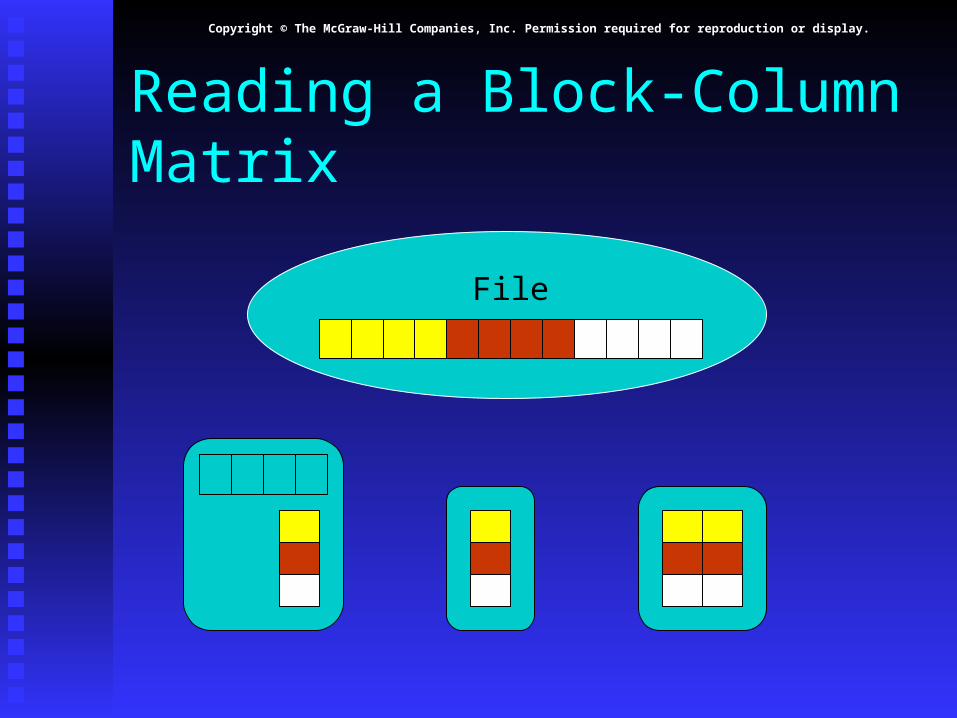
Reading a Block-Column Matrix
File
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
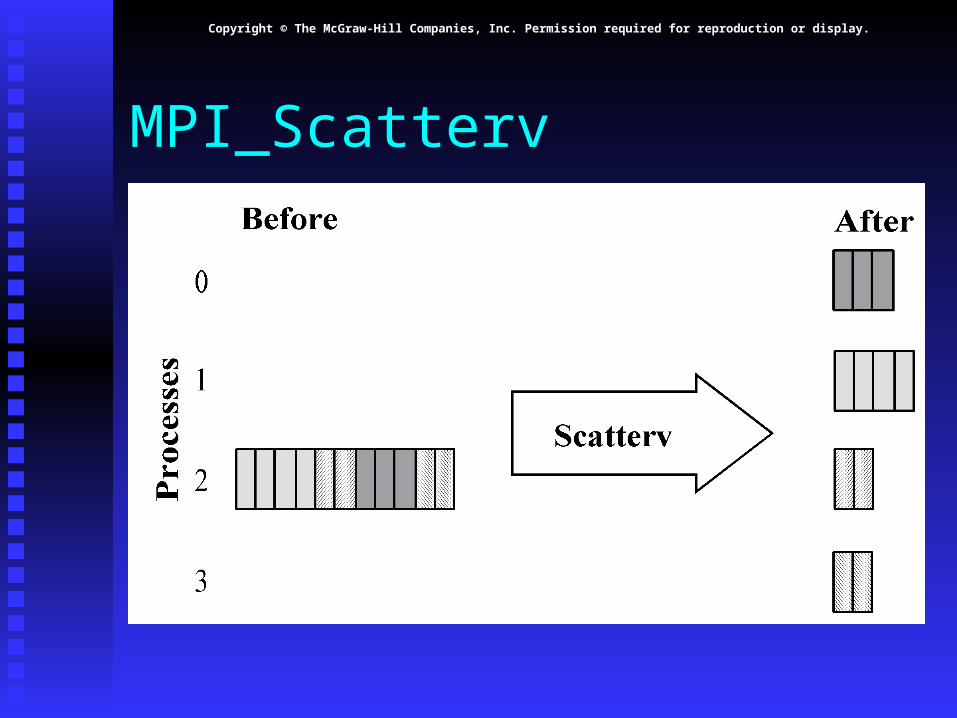
MPI_Scatterv

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Scatterv
int MPI_Scatterv ( void *send_buffer, int *send_cnt, int *send_disp, MPI_Datatype send_type, void *receive_buffer, int receive_cnt, MPI_Datatype receive_type, int root, MPI_Comm communicator)

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Printing a Block-Column Matrix
Data motion opposite to that we did when Data motion opposite to that we did when reading the matrixreading the matrix
Replace “scatter” with “gather”Replace “scatter” with “gather” Use “v” variant because different processes Use “v” variant because different processes
contribute different numbers of elementscontribute different numbers of elements

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function MPI_Gatherv

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Gathervint MPI_Gatherv ( void *send_buffer, int send_cnt, MPI_Datatype send_type, void *receive_buffer, int *receive_cnt, int *receive_disp, MPI_Datatype receive_type, int root, MPI_Comm communicator)

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function MPI_Alltoallv

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Alltoallvint MPI_Gatherv ( void *send_buffer, int *send_cnt, int *send_disp, MPI_Datatype send_type, void *receive_buffer, int *receive_cnt, int *receive_disp, MPI_Datatype receive_type, MPI_Comm communicator)

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Count/Displacement Arrays
MPI_Alltoallv requires two pairs of MPI_Alltoallv requires two pairs of count/displacement arrayscount/displacement arrays
First pair for values being sentFirst pair for values being sent send_cnt: number of elementssend_cnt: number of elements send_disp: index of first elementsend_disp: index of first element
Second pair for values being receivedSecond pair for values being received recv_cnt: number of elementsrecv_cnt: number of elements recv_disp: index of first elementrecv_disp: index of first element
create_mixed_xfer_arrays builds these

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Function create_uniform_xfer_arrays
First arrayFirst array How many elements received from each How many elements received from each
process (always same value)process (always same value) Uses ID and utility macro block_sizeUses ID and utility macro block_size
Second arraySecond array Starting position of each process’ blockStarting position of each process’ block Assume blocks in process rank orderAssume blocks in process rank order

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Run-time Expression
: inner product loop iteration time: inner product loop iteration time Computational time: Computational time: nnn/pn/p All-gather requires All-gather requires pp-1 messages, each of -1 messages, each of
length aboutlength about n n//pp 8 bytes per element8 bytes per element Total execution time:Total execution time:
nnn/pn/p + ( + (pp-1)(-1)( + (8 + (8nn//pp)/)/))
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
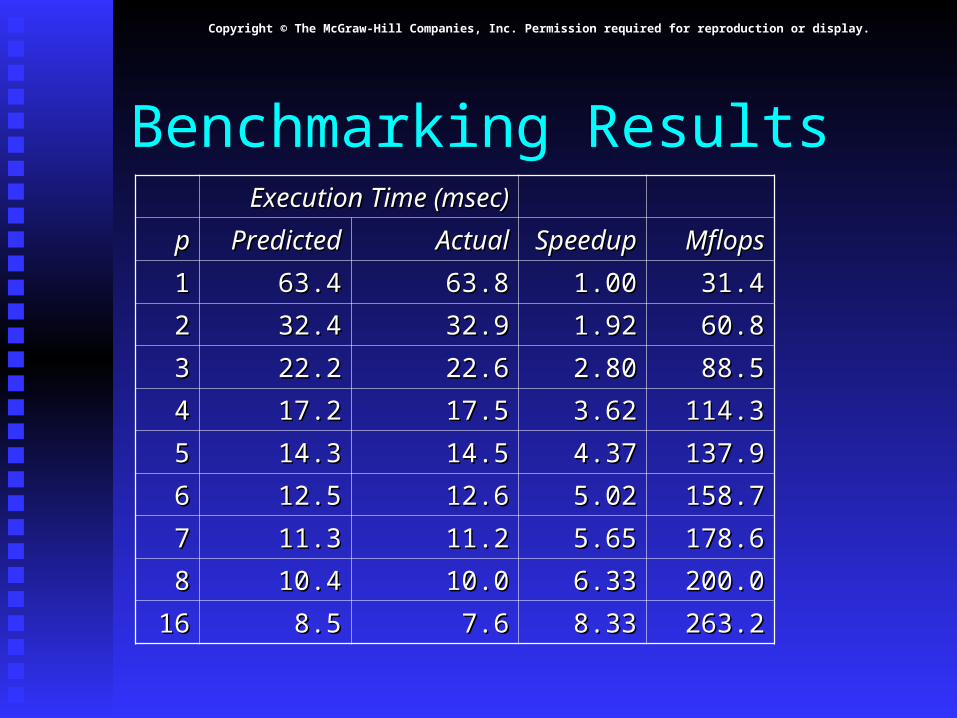
Benchmarking ResultsExecution Time (msec)Execution Time (msec)
pp PredictedPredicted ActualActual SpeedupSpeedup MflopsMflops
11 63.463.4 63.863.8 1.001.00 31.431.4
22 32.432.4 32.932.9 1.921.92 60.860.8
33 22.222.2 22.622.6 2.802.80 88.588.5
44 17.217.2 17.517.5 3.623.62 114.3114.3
55 14.314.3 14.514.5 4.374.37 137.9137.9
66 12.512.5 12.612.6 5.025.02 158.7158.7
77 11.311.3 11.211.2 5.655.65 178.6178.6
88 10.410.4 10.010.0 6.336.33 200.0200.0
1616 8.58.5 7.67.6 8.338.33 263.2263.2

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Checkerboard Block Decomposition Associate primitive task with each element of the Associate primitive task with each element of the
matrix matrix AA Each primitive task performs one multiplyEach primitive task performs one multiply Agglomerate primitive tasks into rectangular Agglomerate primitive tasks into rectangular
blocksblocks Processes form a 2-D gridProcesses form a 2-D grid Vector Vector bb distributed by blocks among processes in distributed by blocks among processes in
first column of gridfirst column of grid

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Tasks after Agglomeration

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Algorithm’s Phases

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
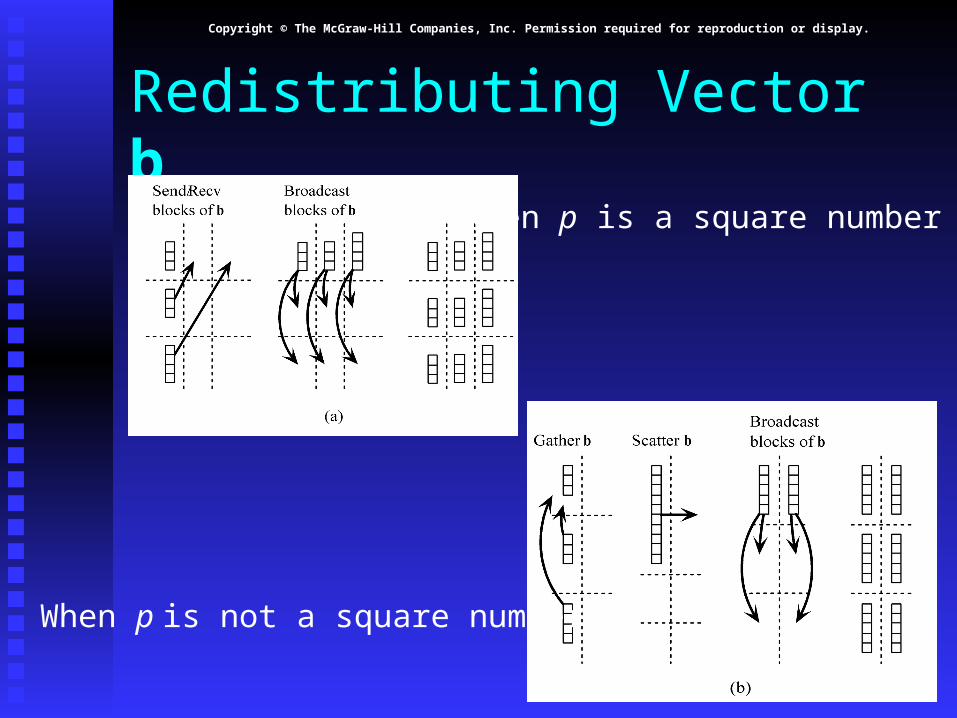
Redistributing Vector b
Step 1: Move Step 1: Move b b from processes in first row to from processes in first row to processes in first columnprocesses in first column If If pp square square
First column/first row processes send/receive First column/first row processes send/receive portions of portions of bb
If If pp not square not squareGather Gather bb on process 0, 0 on process 0, 0Process 0, 0 broadcasts to first row procsProcess 0, 0 broadcasts to first row procs
Step 2: First row processes scatter Step 2: First row processes scatter bb within columns within columns
Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Redistributing Vector b
When p is a square number
When p is not a square number

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Complexity Analysis
Assume Assume pp is a square number is a square number If grid is 1 If grid is 1 pp, devolves into , devolves into
columnwise block stripedcolumnwise block striped If grid is If grid is pp 1, devolves into rowwise 1, devolves into rowwise
block stripedblock striped

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Complexity Analysis (continued)
Each process does its share of computation: Each process does its share of computation: ((nn22//pp))
Redistribute Redistribute bb: : ((nn / / pp + log + log pp((nn / / pp )) = )) = ((nn log log pp / / pp))
Reduction of partial results vectors:Reduction of partial results vectors: ((nn log log pp / / pp))
Overall parallel complexity:Overall parallel complexity: ((nn33//pp + + nn log log pp / / pp))

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Isoefficiency Analysis
Sequential complexity: Sequential complexity: ((nn22)) Parallel communication complexity:Parallel communication complexity:
((nn log log pp / / pp)) Isoefficiency function:Isoefficiency function:
nn22 CnCn p p log log pp nn C C p p log log pp
This system is much more scalable than the This system is much more scalable than the previous two implementationsprevious two implementations
pCpppCpppCM 2222 log/log/)log(

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Creating Communicators
Want processes in a virtual 2-D gridWant processes in a virtual 2-D grid Create a custom communicator to do thisCreate a custom communicator to do this Collective communications involve all Collective communications involve all
processes in a communicatorprocesses in a communicator We need to do broadcasts, reductions We need to do broadcasts, reductions
among subsets of processesamong subsets of processes We will create communicators for processes We will create communicators for processes
in same row or same columnin same row or same column

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
What’s in a Communicator?
Process groupProcess group ContextContext AttributesAttributes
Topology (lets us address processes Topology (lets us address processes another way)another way)
Others we won’t considerOthers we won’t consider

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Creating 2-D Virtual Grid of Processes
MPI_Dims_createMPI_Dims_create Input parametersInput parameters
Total number of processes in desired gridTotal number of processes in desired gridNumber of grid dimensionsNumber of grid dimensions
Returns number of processes in each dimReturns number of processes in each dim MPI_Cart_createMPI_Cart_create
Creates communicator with cartesian topologyCreates communicator with cartesian topology

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Dims_create
int MPI_Dims_create ( int nodes, /* Input - Procs in grid */ int dims, /* Input - Number of dims */
int *size) /* Input/Output - Size of each grid dimension */

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Cart_createint MPI_Cart_create ( MPI_Comm old_comm, /* Input - old communicator */
int dims, /* Input - grid dimensions */
int *size, /* Input - # procs in each dim */
int *periodic, /* Input - periodic[j] is 1 if dimension j wraps around; 0 otherwise */
int reorder, /* 1 if process ranks can be reordered */
MPI_Comm *cart_comm) /* Output - new communicator */

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Using MPI_Dims_create and MPI_Cart_create
MPI_Comm cart_comm;int p;int periodic[2];int size[2];...size[0] = size[1] = 0;MPI_Dims_create (p, 2, size);periodic[0] = periodic[1] = 0;MPI_Cart_create (MPI_COMM_WORLD, 2, size, 1, &cart_comm);

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Useful Grid-related Functions
MPI_Cart_rankMPI_Cart_rank Given coordinates of process in Cartesian Given coordinates of process in Cartesian
communicator, returns process rankcommunicator, returns process rank MPI_Cart_coordsMPI_Cart_coords
Given rank of process in Cartesian Given rank of process in Cartesian communicator, returns process’ communicator, returns process’ coordinatescoordinates

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Cart_rank
int MPI_Cart_rank ( MPI_Comm comm, /* In - Communicator */ int *coords, /* In - Array containing process’ grid location */ int *rank) /* Out - Rank of process at specified coords */

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Cart_coords
int MPI_Cart_coords ( MPI_Comm comm, /* In - Communicator */ int rank, /* In - Rank of process */ int dims, /* In - Dimensions in virtual grid */ int *coords) /* Out - Coordinates of specified process in virtual grid */

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI_Comm_split
Partitions the processes of a communicator into Partitions the processes of a communicator into one or more subgroupsone or more subgroups
Constructs a communicator for each subgroupConstructs a communicator for each subgroup Allows processes in each subgroup to perform Allows processes in each subgroup to perform
their own collective communicationstheir own collective communications Needed for columnwise scatter and rowwise Needed for columnwise scatter and rowwise
reducereduce

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Header for MPI_Comm_splitint MPI_Comm_split ( MPI_Comm old_comm, /* In - Existing communicator */
int partition, /* In - Partition number */
int new_rank, /* In - Ranking order of processes in new communicator */
MPI_Comm *new_comm) /* Out - New communicator shared by processes in same partition */

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Example: Create Communicators for Process RowsMPI_Comm grid_comm; /* 2-D process grid */
MPI_Comm grid_coords[2]; /* Location of process in grid */
MPI_Comm row_comm; /* Processes in same row */
MPI_Comm_split (grid_comm, grid_coords[0], grid_coords[1], &row_comm);

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Run-time Expression
Computational time: Computational time: n/n/pp n/n/pp Suppose Suppose pp a square number a square number Redistribute Redistribute bb
Send/recv: Send/recv: + 8 + 8 n/n/pp / / Broadcast: log Broadcast: log p ( p ( + 8 + 8 n/n/pp / / ))
Reduce partial results:Reduce partial results:log log p ( p ( + 8 + 8 n/n/pp / / ))

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
BenchmarkingProcsProcs PredictedPredicted
(msec)(msec)Actual Actual (msec)(msec)
SpeedupSpeedup MegaflopsMegaflops
11 63.463.4 63.463.4 1.001.00 31.631.6
44 17.817.8 17.417.4 3.643.64 114.9114.9
99 9.79.7 9.79.7 6.536.53 206.2206.2
1616 6.26.2 6.26.2 10.2110.21 322.6322.6

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Comparison of Three Algorithms
02468
1012
0 5 10 15 20
Processors
Spee
dup
Rowwise BlockStripedColumnwise BlockStripedCheckerboardBlock

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Summary (1/3)
Matrix decomposition Matrix decomposition communications needed communications needed Rowwise block striped: all-gatherRowwise block striped: all-gather Columnwise block striped: all-to-all exchangeColumnwise block striped: all-to-all exchange Checkerboard block: gather, scatter, broadcast, reduceCheckerboard block: gather, scatter, broadcast, reduce
All three algorithms: roughly same number of messagesAll three algorithms: roughly same number of messages Elements transmitted per process variesElements transmitted per process varies
First two algorithms: First two algorithms: ((nn) elements per process) elements per process Checkerboard algorithm: Checkerboard algorithm: (n/(n/p) elementsp) elements
Checkerboard block algorithm has better scalabilityCheckerboard block algorithm has better scalability

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Summary (2/3)
Communicators with Cartesian topologyCommunicators with Cartesian topology CreationCreation Identifying processes by rank or coordsIdentifying processes by rank or coords
Subdividing communicatorsSubdividing communicators Allows collective operations among Allows collective operations among
subsets of processessubsets of processes

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
Summary (3/3)
Parallel programs and supporting functions Parallel programs and supporting functions much longer than C counterpartsmuch longer than C counterparts
Extra code devoted to reading, distributing, Extra code devoted to reading, distributing, printing matrices and vectorsprinting matrices and vectors
Developing and debugging these functions Developing and debugging these functions is tedious and difficultis tedious and difficult
Makes sense to generalize functions and put Makes sense to generalize functions and put them in libraries for reusethem in libraries for reuse

Copyright © The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
MPI Application Development
C and Standard Libraries
MPI Library
Application-specific Library
Application

















