Page 1
1
11/25/2014S. Joo ([email protected] ) 1
CS 4649/7649Robot Intelligence: Planning
Sungmoon Joo
School of Interactive Computing
College of Computing
Georgia Institute of Technology
Partially Observable MDP
Some slides adapted from Dr. Mike Stilman’s lecture slides
• Three lectures left
- Nov. 25th : POMDP and Summary of Planning under Uncertainties
- Dec. 2nd : Extension of Planning/Control: Language, Hybrid System
- Dec. 4th : Wrap up
• Due Reminder:
- Project report: Due Dec. 4th
- Project report review: Due Dec. 11th
- Project presentation & presentation evaluation: Dec. 11th
11/25/2014S. Joo ([email protected] ) 2
Administrative
Page 2
2
10/21/2014S. Joo ([email protected] ) 3
Two Sources of Error
• Sensing & State Estimation Uncertainty
– Sensors have noise
– You don’t know exactly what the state is (e.g. mapping, localization,…)
• Action Execution Uncertainty
– Your actuators do not do what you tell them to
– The system responds differently than you expect
: Friction gears, air resistance, etc.
Reality
11/25/2014S. Joo ([email protected] ) 4
Reality
(uncertainty)
(uncertainty)
Estimated
state
Page 3
3
11/25/2014S. Joo ([email protected] ) 5
Reality
(uncertainty)
(uncertainty)
Estimated
state
State Estimation
Plan, (Control) Policy
MDP
11/25/2014S. Joo ([email protected] ) 6
Reality
(uncertainty)
(uncertainty)
Estimated
state
MDP
POMDP
Page 4
4
11/25/2014S. Joo ([email protected] ) 7
Markov Decision Process (MDP)
Markov Chain-Markov Property
Markov Decision Process(MDP)
Hidden Markov Model(HMM)
Partially Observable MDP(POMDP)
Mathematical FrameworksAction Uncertainty
Observation
Uncertainty
Both
11/25/2014S. Joo ([email protected] ) 8
POMDP
MDP
Don’t get to observe the state itself, instead get sensory measurements
Uncertainty about action outcome
Uncertainty about the state due to
imperfect observation
Page 5
5
11/25/2014S. Joo ([email protected] ) 9
State Estimation – Belief State
(ex. Kalman Filter)
11/25/2014S. Joo ([email protected] ) 10
Belief States: Example
Kalman Filter: Gaussian(Mean & Covariance)
Continuous Belief States
Page 6
6
11/25/2014S. Joo ([email protected] ) 11
POMDP
(uncertainty)
(uncertainty)
Belief state
11/25/2014S. Joo ([email protected] ) 12
POMDP
MDP
MDP
)o )
Page 7
7
11/25/2014S. Joo ([email protected] ) 13
POMDP
• Probability distributions over
states of the underlying MDP
(i.e. belief state)
• The agent keeps an internal
belief state, b, that summarizes
its experience(observation &
control input history). The agent
uses a state estimator, SE, for
updating the belief state b’ based
on the last action a t-1, the
current observation o at t, and the
previous belief state b at t-1.
11/25/2014S. Joo ([email protected] ) 14
Converting POMDP to Belief-States MDP
Current belief distribution
Previous actionCurrent observation
Page 8
8
11/25/2014S. Joo ([email protected] ) 15
Converting POMDP to Belief-States MDP
Normalizing Factor
How?
s2 s1s1
s2
s2 s2
11/25/2014S. Joo ([email protected] ) 16
Converting POMDP to Belief-States MDP
s2 s1s1
s2
s2 s2
s2 s2
s2 s2s1s1 s1
Page 9
9
11/25/2014S. Joo ([email protected] ) 17
Total Probability
If {Bn: n = 1,2,3…} is a finite or countably infinite partition of a sample space,and each event Bn is measurable, then for any event A of the same probabilityspace, the following holds
The T.P. can also be stated for conditional probabilities. Taking the Bn as above, and assuming C is an event independent with any of the Bn
11/25/2014S. Joo ([email protected] ) 18
Converting POMDP to Belief-States MDP
s2 s1 s1
s2
s2 s2
s2 s2
s2 s2 s1 s1s1
s2 s1s1
Page 10
10
11/25/2014S. Joo ([email protected] ) 19
Converting POMDP to Belief-States MDP
State Estimation
s2 s1s1
s2
s2 s2
11/25/2014S. Joo ([email protected] ) 20
POMDP to MDP
Action update
Page 11
11
11/25/2014S. Joo ([email protected] ) 21
POMDP to MDP
Observation
update
11/25/2014S. Joo ([email protected] ) 22
POMDP Example
Page 12
12
11/25/2014S. Joo ([email protected] ) 23
POMDP Example
11/25/2014S. Joo ([email protected] ) 24
POMDP Example
= =
Page 13
13
11/25/2014S. Joo ([email protected] ) 25
POMDP Example
(conditioned on A1 and O2)
11/25/2014S. Joo ([email protected] ) 26
POMDP Example
Page 14
14
11/25/2014S. Joo ([email protected] ) 27
POMDP Example
11/25/2014S. Joo ([email protected] ) 28
POMDP Example
T.P.
Page 15
15
11/25/2014S. Joo ([email protected] ) 29
POMDP Example
11/25/2014S. Joo ([email protected] ) 30
POMDP Example
Page 16
16
11/25/2014S. Joo ([email protected] ) 31
How to Solve Belief-State MDP?
11/25/2014S. Joo ([email protected] ) 32
Solving a POMDP
Page 17
17
11/25/2014S. Joo ([email protected] ) 33
Solving a POMDP
11/25/2014S. Joo ([email protected] ) 34
Solving a POMDP: Step1
Page 18
18
11/25/2014S. Joo ([email protected] ) 35
Solving a POMDP: Step1
11/25/2014S. Joo ([email protected] ) 36
Solving a POMDP: Step1
Page 19
19
11/25/2014S. Joo ([email protected] ) 37
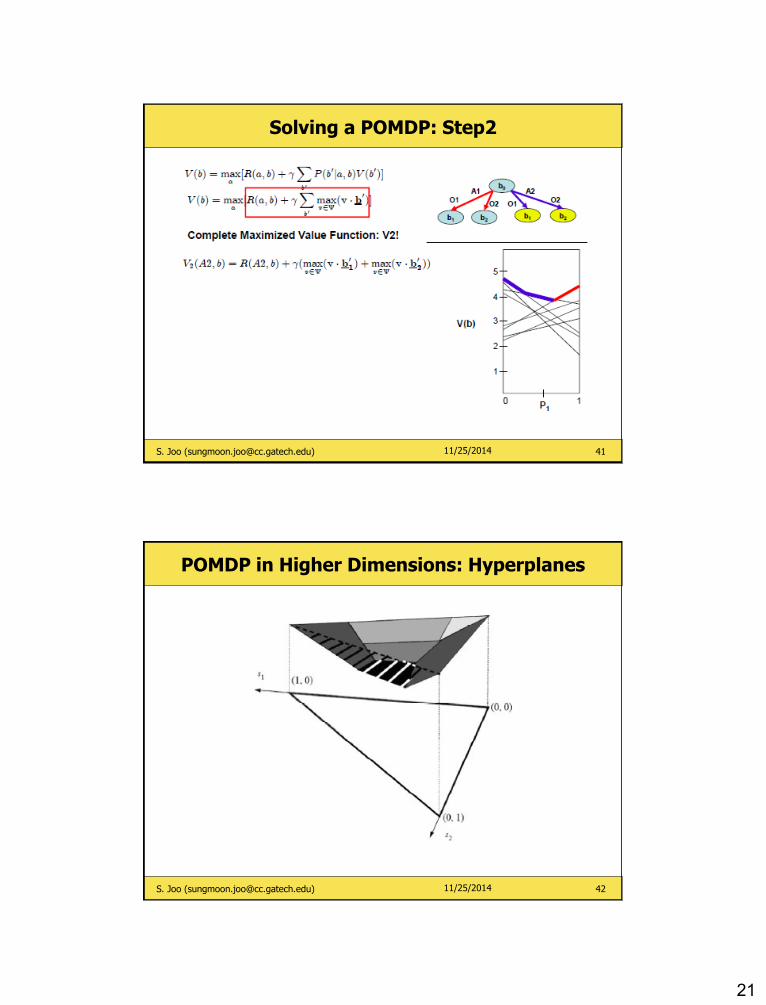
Solving a POMDP: Step2
11/25/2014S. Joo ([email protected] ) 38
Solving a POMDP: Step2
Page 20
20
11/25/2014S. Joo ([email protected] ) 39
Solving a POMDP: Step2
11/25/2014S. Joo ([email protected] ) 40
Solving a POMDP: Step2
Page 21
21
11/25/2014S. Joo ([email protected] ) 41
Solving a POMDP: Step2
11/25/2014S. Joo ([email protected] ) 42
POMDP in Higher Dimensions: Hyperplanes
Page 22
22
11/25/2014S. Joo ([email protected] ) 43
POMDP Summary
• Complex but Powerful technique
- State explodes upon conversion to MDP
- State becomes difficult to understand upon conversion to MDP
- Unique cohesive method that trades off:
: Value of ascertaining state
: Value of pursuing a goal
• Exist more efficient algorithms:
- Witness Algorithm (Littman ‘94)
- Policy Iteration (Sondik, Hansen ‘97)
• Typically complexity is still prohibitive for large problems
11/25/2014S. Joo ([email protected] ) 44
● Canonical solution method 1 – Covered today
- Run value iteration, but now the state space is the space of probability
distributions
:value and optimal action for every possible probability distribution
:will automatically trade off information gathering actions versus actions
that affect the underlying state
● Canonical solution method 2 – Finite-horizon/MPC-style
- Search over sequences of actions with limited look-ahead
- Branching over actions and observations
● Canonical solution method 3 – LQG-style
- Plan in the MDP
- Run probabilistic inference (filtering) to track probability distribution
- Choose optimal action for MDP for what is currently the most likely state
POMDP Summary
Page 23
23
11/25/2014S. Joo ([email protected] ) 45
• Robot’s trajectory matters !
• Trade-off : Control Objective vs Probing Dual Control
Control objective
Probing
Trade-off
GoalObstacle
Active Monocular SLAM Example
11/25/2014S. Joo ([email protected] ) 46
Active Monocular SLAM Example
Scenario
Page 24
24
11/25/2014S. Joo ([email protected] ) 47
Active Monocular SLAM Example
Sungmoon Joo, “SLAM-based nonlinear optimal control approach to robot navigation with limited resources”
11/25/2014S. Joo ([email protected] ) 48
Active Monocular SLAM Example