23
Performance Comparison between Two Programming Models of XcalableMP H. Sakagami Fund. Phys. Sim. Div., National Institute for Fusion Science XcalableMP specification Working Group (XMP-WG)

Performance Comparison between Two Programming
Models of XcalableMP �H. Sakagami
Fund. Phys. Sim. Div., National Institute for Fusion ScienceXcalableMP specification Working Group�(XMP-WG)

Dilemma in Parallel Programming �
✿ Life is too short for MPI. T-shirts message@WOMPAT2001
– MPI programming requires too much cost for us to develop, maintain and inherit programs as a software especially in academic institutions.
✿ The free lunch is over. H. Sutter, Dr. Dobb's Journal, 30(3), (2005)
– As the multi-, many-core trend cannot be stopped due to power saving demands and technological limits for clock speed, parallel programming is mandatory.

Dilemma in Parallel Programming �
✿ Life is too short for MPI. T-shirts message@WOMPAT2001
– MPI programming requires too much cost for us to develop, maintain and inherit programs as a software especially in academic institutions.
✿ The free lunch is over. H. Sutter, Dr. Dobb's Journal, 30(3), (2005)
– As the multi-, many-core trend cannot be stopped due to power saving demands and technological limits for clock speed, parallel programming is mandatory.
Another programming model is needed !! • High performance • Easy to program

What’s XcalableMP?✿ XcalableMP (XMP) is a new programming model and
language for distributed memory systems.– to solve the dilemma in parallel programming environment
✿ XMP is proposed by XcalableMP specification Working Group (XMP-WG).– XMP-WG is a special interest group, which is organized to
make a draft on “petascale” parallel language.– academia (U. Tsukuba, U. Tokyo, Kyoto U., Kyusyu U.)– research labs (RIKEN, NIFS, JAXA, JAMSTEC/ES)– industries (Fujitsu, NEC, Hitachi)

What’s XcalableMP?✿ XcalableMP (XMP) is a new programming model and
language for distributed memory systems.– to solve the dilemma in parallel programming environment
✿ XMP is proposed by XcalableMP specification Working Group (XMP-WG).– XMP-WG is a special interest group, which is organized to
make a draft on “petascale” parallel language.– academia (U. Tsukuba, U. Tokyo, Kyoto U., Kyusyu U.)– research labs (RIKEN, NIFS, JAXA, JAMSTEC/ES)– industries (Fujitsu, NEC, Hitachi)
Better environment than MPI !!

Overview of XMP✿ XMP is mainly a directive-based language extension
like OpenMP and HPF based on Fortran90/C.– To reduce code-writing and educational costs
✿ “Performance-aware” for explicit communication, synchronization and work mapping/sharing– All actions are taken only by directives for being “easy-to-
understand” performance tuning.✿ “Two coexistent styles” for parallel programming
– “global view”– “local view”

Programming Model�✿ Global View Model (like as HPF)
– User can describe data distribution, work mapping/sharing and inter-node comm. with adding directives to serial code.
– Typical techniques for data and task parallelization are supported.
✿ Local View Model (like as Coarray Fortran)– PGAS (Partitioned Global Address Space) features and one-
sided communications are supported as coarray. (language extension for C)– Capability to directly call MPI-APIs is also supported.
✿ Two models can be easily combined to achieve best parallel performance with less efforts.

Global View Model✿ A node array is declared corresponding to a actual
processor/core set.– !$xmp nodes p(4)
✿ A template is declared with shape specification and it is distributed onto the node array.– !$xmp template t(16)– !$xmp�distribute t(block) onto p
✿ Data are aligned to the template for distribution. �– !$xmp align a(i) with t(i)
✿ Loops are also aligned to it for work mapping.– !$xmp loop on t(i)
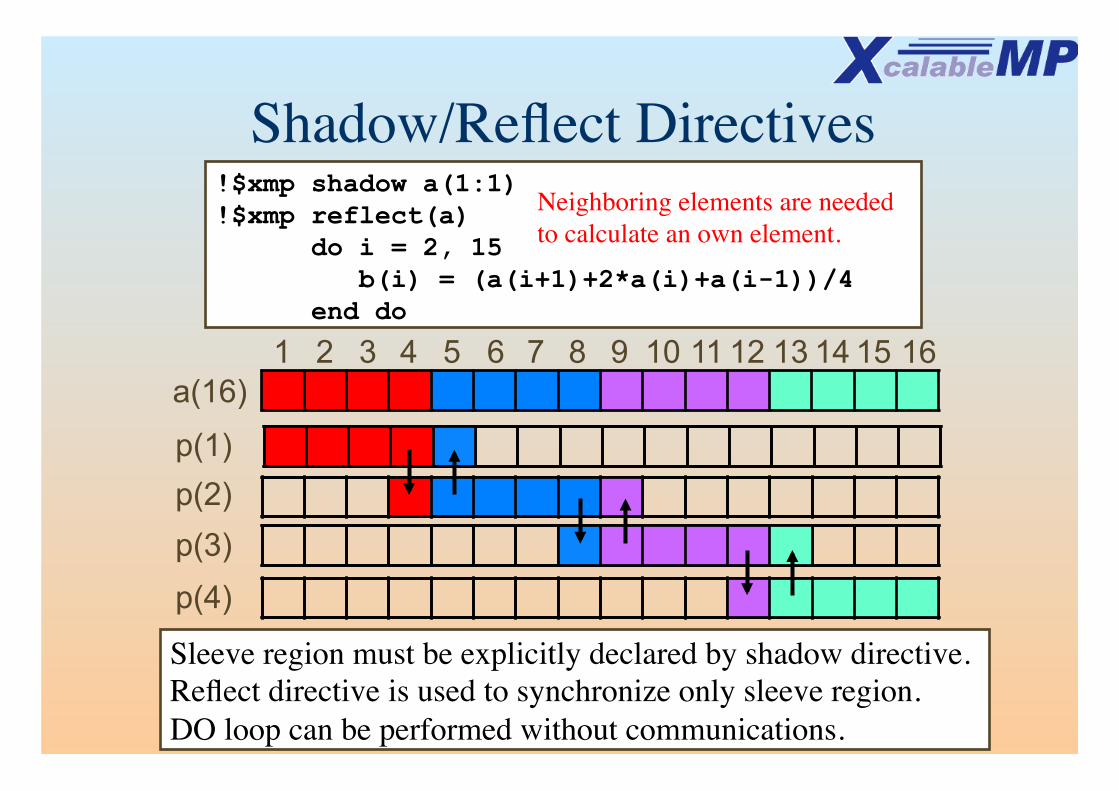
Shadow/Reflect Directives �
p(4) p(3) p(2)
a(16) 1 2 3 4 5 6 7 8 9 10 11 12 13 14
p(1)
15 16
!$xmp shadow a(1:1) !$xmp reflect(a) do i = 2, 15 b(i) = (a(i+1)+2*a(i)+a(i-1))/4 end do
Sleeve region must be explicitly declared by shadow directive.Reflect directive is used to synchronize only sleeve region.DO loop can be performed without communications.
Neighboring elements are needed�to calculate an own element.

Local View Model✿ We adopt coarray as our PGAS feature and one-sided
communications for local data (put/get).– In Fortran, coarray is extended for task parallelism.
real :: r[*] ! Scalar coarray!real :: x(n)[*] ! Array coarray !! Coarrays always have assumed co-size!real :: t ! Local scalar!real :: s(n) ! Local array!integer :: g,p ! Local scalar !! Remote array references!! GET communication!t = r[g] !x(:) = x(:)[g]!! PUT communication!r[p] = r!x(:)[p] = s(:)

Three Dimensional Fluid Code✿ IMPACT-3D
– simulate implosion process in laser fusion✿ Three dimensional Eulerian fluid
– compressible– inviscid
✿ Three dimensional Cartesian coordinate and cubic grid– asymmetric flow across the origin
✿ 5-point stencil for spatial differentiation– typical stencil scheme
✿ Explicit fractional time step for time integration

Non-uniform Implosion✿ Rayleigh-Taylor instability

Domain Decomposition✿ The domain is decomposed in Y and Z directions.✿ Communications between neighboring subdomains
are needed to exchange boundary data.✿ Reduction communications are needed to determine
the maximum flow velocity.
total amount of communicated data per domain:
(lz·lx)/nz + (lx·ly)/ny

Programs with Global View Modelinteger parameter :: lx=2048, ly=2048, lZ=2048!integer parameter :: ny=16, nz=16!!$XMP NODES proc(ny,nz) !!$XMP TEMPLATE t(lx,ly,lz)!!$XMP DISTRIBUTE t(*,BLOCK,BLOCK) ONTO proc!real*8 :: physval(6,lx,ly,lz)!!$XMP ALIGN (*,*,i,j) WITH t(*,i,j) :: physval!!$XMP SHADOW (0,0,1,1) :: physval !!!$XMP LOOP (iy,iz) ON t(*,iy,iz)!do iz = 1, lz! do iy = 1, ly! do ix = 1, lx! ...!end do!
!$XMP REFLECT (physval) width(0,0,1,0)!!!$XMP REFLECT (physval) width(0,0,0,1)!!!!!$XMP LOOP (iy,iz) ON t(*,iy,iz)!do iz = 1, lz! do iy = 1, ly! do ix = 1, lx! wram = max( wram, ... )!end do!!$XMP REDUCTION(max:wram)!

Programs with Local View Modelinteger parameter :: lx=2048, ly=2048, lZ=2048!integer parameter :: ny=16, nz=16!integer parameter :: lsy=ly/ny, lsz=lz/nz!real*8, allocatable :: physval(:,:,:,:)[:]!!allocate( physval(6,lx,0:lsy+1,0:lsz+1)[*] )!!do iz = 1, lsz! do iy = 1, lsy! do ix = 1, lx! ...!end do!
physval(:,:,lsy+1,:)[linym] = physval1(:,:,1,:)!physval(:,:,0,:)[linyp] = physval1(:,:,lsy,:)!sync all!!physval(:,:,:,lsz+1)[linzm] = physval1(:,:,:,1)!physval(:,:,:,0)[linzp] = physval1(:,:,:,lsz)!sync all!
sync all!physval(:,:,lsy+1,:) = physval1(:,:,1,:)[linyp]!physval(:,:,0,:) = physval1(:,:,lsy,:)[linym]!!sync all!physval(:,:,:,lsz+1)= physval1(:,:,:,1)[linzp] !physval(:,:,:,0)= physval1(:,:,:,lsz)[linzm] !
PUT communication
GET communication
wramc = wram!sync all !if( THIS_IMAGE().eq. 1 ) then! do i = 2, ny*nz! wrami(i) = wramc[i]! end do! do i = 2, ny*nz! wram = max( wram, wrami(i) )! end do! wramc = wram!end if!sync all !if( THIS_IMAGE().ne. 1 ) then! do i = 2, ny*nz! wram = wramc[1]! end do!end if!

Programs with MPIinteger parameter :: lx=2048, ly=2048, lZ=2048!integer parameter :: ny=16, nz=16!integer parameter :: lsy=ly/ny, lsz=lz/nz!real*8 :: physval(6,lx,0:lsy+1,0:lsz+1)!!do iz = 1, lsz! do iy = 1, lsy! do ix = 1, lx! ...!end do!
call MPI_ISEND( physval(1,1,1,1), ..., lrkzm,!call MPI_ISEND( physval(1,1,1,lsz), ..., lrkzp, !call MPI_IRECV( physval(1,1,1,lsz+1), ..., lrkzp,!call MPI_IRECV( physval(1,1,1,0), ..., lrkzm,!call MPI_WAITALL( ...!
call MPI_ALLREDUCE( wram, ...!
buff(:,:,:) = physval(:,:,1,:)!call MPI_ISEND( buff, ..., lrkym,!buff(:,:,:) = physval(:,:,lsy,:)!call MPI_ISEND( buff, ..., lrkyp, !call MPI_IRECV( buff, ..., lrkyp,!physval(:,:,lsz+1,:) = buff(:,:,:)!call MPI_IRECV( physval(1,1,1,0), ..., lrkym,!physval(:,:,0,:) = buff(:,:,:)!call MPI_WAITALL( ...!
Z neighboring comminication
Y neighboring communication

AMD Opteron Cluster Results✿ Local view communications are better even GASNet is
installed with MPI conduit.✿ Global view model, local view model and MPI show
almost same performance.
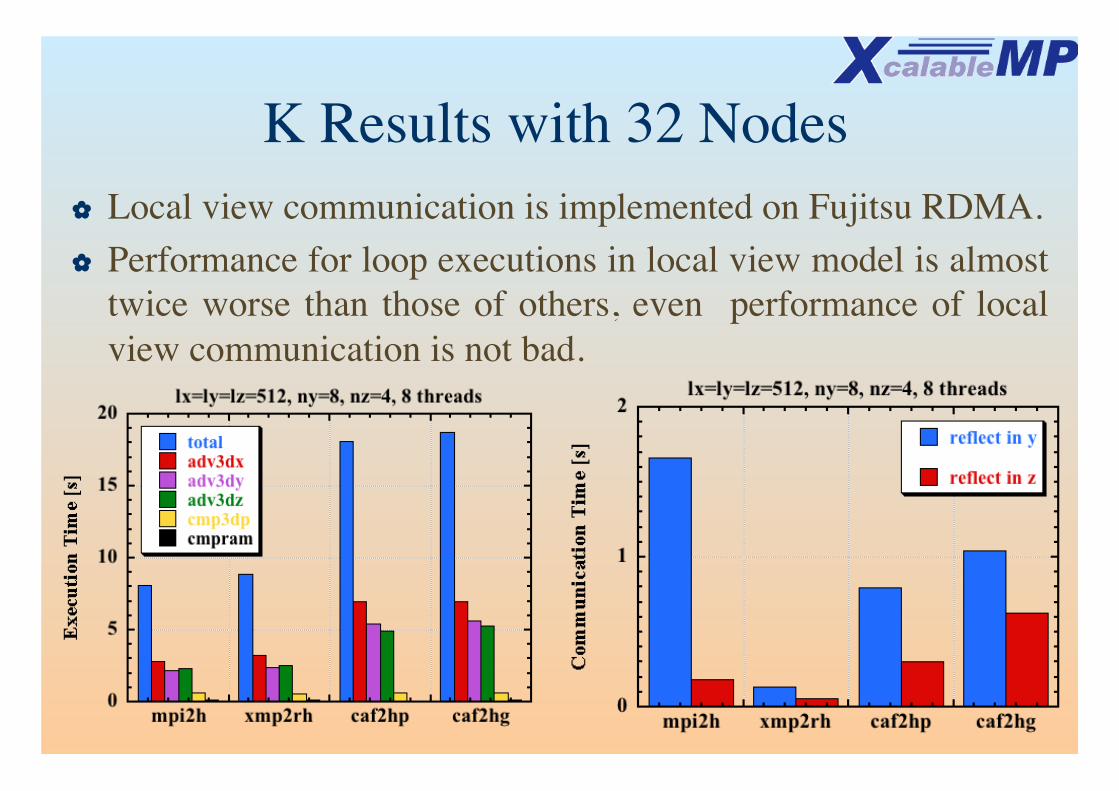
K Results with 32 Nodes✿ Local view communication is implemented on Fujitsu RDMA.✿ Performance for loop executions in local view model is almost
twice worse than those of others, even performance of local view communication is not bad.

Pointer Array✿ In local view model, allocatable array is converted to pointer
array, and it prevents native compiler optimizations, such as SIMDize, prefetch.– The compiler thinks that variables are overlapped.
REAL ( KIND= 8 ), ALLOCATABLE( :, :, :, : ) :: XMP__physval1, XMP__physval2!DO iz1 = XMP_loop_lb15 , XMP_loop_ub16 , 1! DO iy2 = XMP_loop_lb18 , XMP_loop_ub19 , 1! DO ix = 1 , lx , 1! wu0 = XMP__physval( 2, ix, iy2, iz1 ) / XMP__physval( 1, ix, iy2, iz1 )! ...! XMP_physval2( ... ) = ...!
REAL ( KIND= 8 ) , POINTER( :, :, :, : ) :: physval1, physval2!DO iz = 1 , lsz , 1! DO iy = 1 , lsy , 1! DO ix = 1 , lx , 1! wu0 = physval1( 2, ix, iy, iz ) / physval1( 1, ix, iy, iz )! ...! physval2( ... ) = ...!

Hardware Monitor Results �✿ SIMDize can be forced with “noalias” compiler option, but
prefetch instructions are still suppressed.model
compiler options �SIMD(%)� Mem throughput/
PEAK(%)MFLOPS/PEAK(%) �
mpi2h-Kfast,openmp,
simd=2,prefetch_stride �55.6463� 52.6238� 16.9820 �
xmp2rh-Kfast,openmp,
simd=2,prefetch_stride42.0179 � 53.4455� 16.8888�
caf2hp-Kfast,openmp,
simd=2,prefetch_stride0.2263� 25.9905� 6.9371 �
caf2hp-Kfast,openmp,
simd=2,prefetch_stride,noalias
16.0009� 22.7666� 7.1871�

K Results with 2048 Nodes✿ Discontinuous coarray communications may have
serious problems in the large size application at this moment.

Restriction�under Current Local View Model on K✿ Maximum size of coarray
– 2GB for each✿ Maximum size of data transfer
– 16MB at once✿ Module variable with parameters
✿ Coexistence with directives of global view model✿ Using 16,383 nodes (more than 10,000 nodes?)
module phys! integer, parameter :: lx = 2048! integer, parameter :: ly = 2048! integer, parameter :: lz = 2048! real( kind=8) :: physval(6,lx,ly,lz)[*]!end module phys!

Summary✿ Performance comparison between the global view and
local view models in XcalableMP have been done on cluster system and K computer.
✿ On cluster system, both models can achieve almost same performance of MPI program.
✿ But the local view model can not achive comparable performance of the global view model and MPI on K computer.– We can expect much improvement of Omni XMP compiler.
*This work was partially supported by JSPS Grant-in-Aid for Scientific Research (C)(25400539). Part of the research was funded by MEXT’s program for the Development and Improvement for the Next Generation Ultra High-Speed Computer System, under its Subsidies for Operating the Specific Advanced Large Research Facilities.

















