21
Performance Concepts Mark A. Magumba
| Date post: | 29-Dec-2015 |
| Category: |
Documents |
| Upload: | calvin-knight |
| View: | 212 times |
| Download: | 0 times |

Performance Concepts
Mark A. Magumba

Introduction• Research done on 1058 correspondents in 2006 found that 75%
OF them would not return to a website that took longer than 4 seconds to load, the same research five years earlier showed people were willing to wait 8 seconds for a page to load
• People tend to value predictability of a system. For instance if a system slows down only once a week to a user this may seem like the system overall is slow
• Perceived performance is how well a system appears to perform• Perceived performance can be improved by communicating with
the user by giving estimates of how long a task will take e.g. visually through a progress bar

Determining Performance During Design
• When designing a system performance must be considered when the system works well but also when it is in a special state for instance what performance is required – When some component failure has occurred– When the system is in maintenance– When patches are being installed– When batch jobs are being run

Ways of determining performance in the design phase
• Generally it is difficult to determine the performance of a system at the design phase however some methods can be employed like– Using the experience of vendors– Prototyping– Ensuring system scalability

Managing Bottlenecks
• The performance of the system as a whole is determined by certain components which may be overloaded known as bottlenecks
• For instance a system may have very fast networks but very slow hard disks, the fast network speeds are immaterial then as performance will be degraded by the hard disks
• The hard disks in this case would be a performance bottleneck

Benchmarking
• Benchmarking measures the comparative performance of test component against an industry standard via a test program.
• The following table shows some common bench mark tests
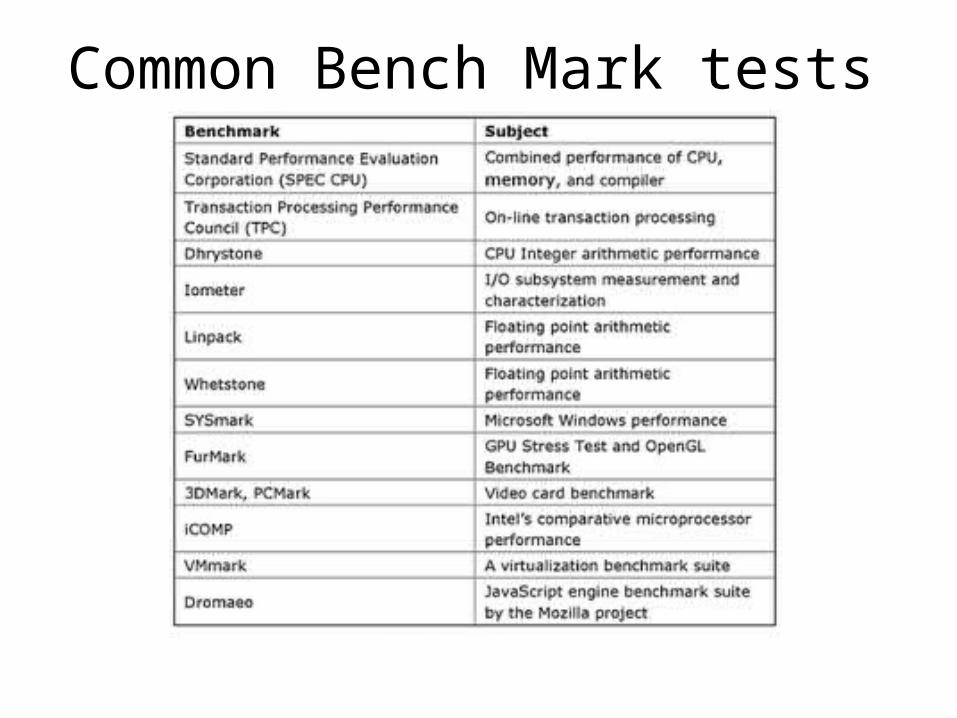
Common Bench Mark tests

Performing performance Tests
• There are three general methods for doing performance tests of whole systems – Load testing: it’s a test to see how well a system
operates under a particular load– Stress testing: Is a test to see how well a system
operates under extreme load, it is a test to see at where (the bottle necks) and when (the load) a particular system breaks
– Endurance testing: Is a measure to see how a system behaves when subjected to the expected load for a sustained period of time

Graph of response time against number of users for typical system

Performance testing methodology• Performance testing usually employs a group of
servers to act as injectors. These simulate users• Another server group known as conductors
evaluate the test performance• It is important that the test environment matches
the production environment as much as possible otherwise results will be unreliable
• Where the cost of setting up a complete test environment is prohibitive it is possible to use a temporary test environment for instance by renting servers from your vendors

Sources of Performance Metrics• Kernel Counters– Most operating systems contain counters that store
performance information. Tools are provided to retrieve this information for instance on windows you have the perfmon tool and on UNIX systems that sar tool
• SNMP counters– SNMP is the standard network management protocol
and accumulates information about devices in a Management Information Base. This information can be accessed via a Network Management System. SNMP also provides for tarps which is a special message type sent when a device counter exceeds its normal limit

Sources of Performance Metrics
• Logging. Stores system event information of infrastructure components sometimes on a dedicated log server. Logging usually generates a lot of information but the level of logging is usually configurable
• Analyzing logs is fundamentally different from monitoring using tools like SNMP as these are able to react in real time, log files are analysed after some time has elapsed

Performance Patterns• Performance patterns– There are several ways to improve performance at
the infrastructure level but it is important to note that 80% of performance issues do not originate from the infrastructure but from poorly configured applications
• Increasing performance in upper layers– Database and application tuning can provide
higher performance boosts than infrastructure upgrades

Infrastructure Optimizations• Caching– Improves infrastructure performance by keeping
frequently accessed instructions and data in memory to improve access times examples include• Disk caching• Web proxies• Operational Data Store
– Is a smaller database that is a subset of an organization’s larger database whose purpose is to improve access times to a particular subset of frequently queried data
• In memory databases

Infrastructure Optimizations
• Scalability– Implies the ease with which configuration changes
can be made to a system in response to changes in number of users. A system whose performance improves proportionally to increase in capacity is said to scale well

Vertical VS Horizontal Scaling• Vertical scaling (scaling up) involves adding capacity to a single
system component for instance increasing the number of CPUs• The problem is that this usually has an upper limit also the cost
of adding a single component can quickly become very high• Horizontal scaling (scaling out) which involves adding more
servers to a system. This usually leads to higher management complexity and may increase latency and affect throughput between nodes
• Horizontal scaling works best when a system is partitioned in layers
• In general scaling is best achieved by using more components (horizontally) rather than using very fast components (vertically) and this approach also suffers some performance penalty due to increased overhead
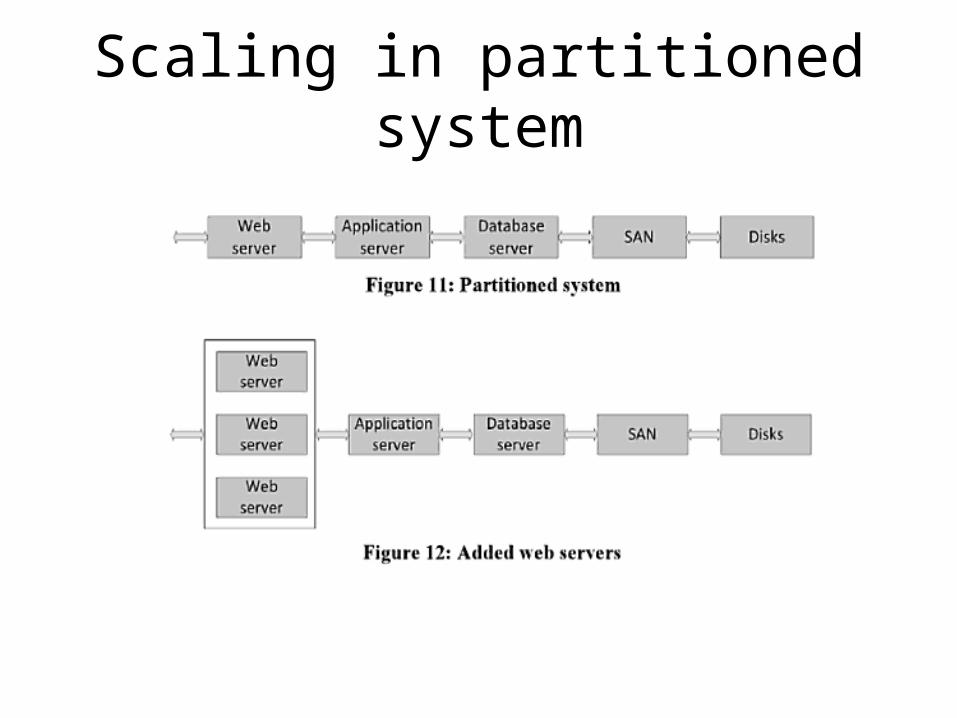
Scaling in partitioned system

Load Balancing
• To take advantage of scaling usually some load balancing is applied
• Load balancing is the spreading of the application load across multiple identical servers operating in parallel
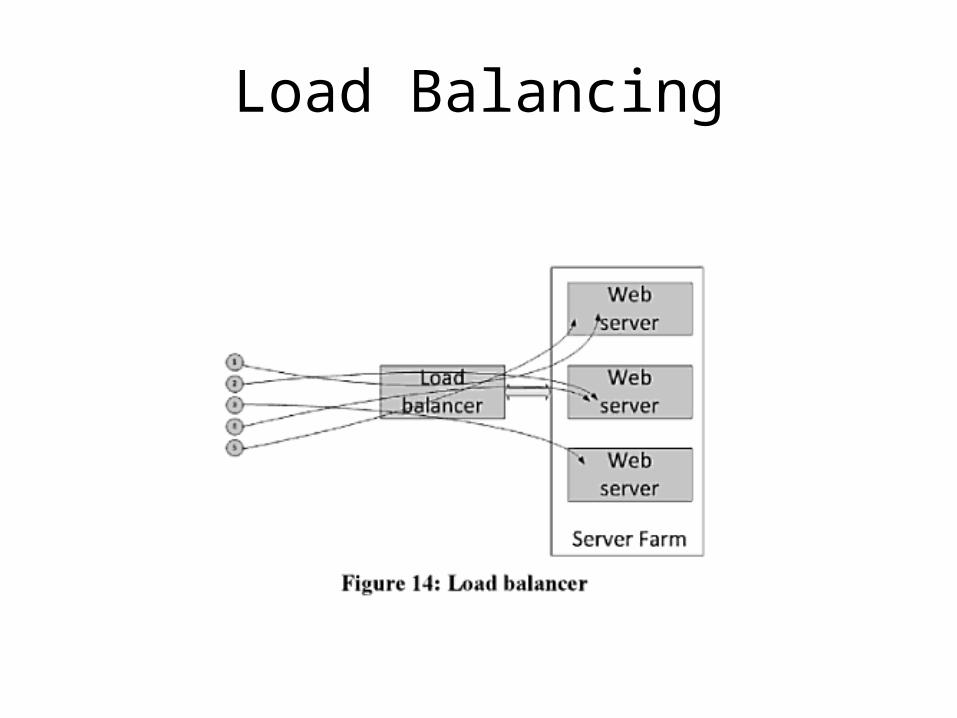
Load Balancing

• High performance clusters– In this arrangement several standard computers
are grouped together via high speed connections to emulate an infinitely powerful super computer
• Grids– Grids are high performance clusters spread
geographically. • They rely on the idle processor time of the participating
computers. • The computers communicate over the internet and in
this case the network is a possible bottleneck• Security is also an important consideration and in some
cases computations must be done twice

Design for use• In the case of special purpose performance critical systems some
guarantees must be made and these will call for specific design decisions
• Designing for an interactive system for instance will call for a different set of requirements than for a batch system
• In some cases special products may be required like custom operating systems and hardware
• Most vendors will provide architects with standard system implementation plans and in most cases it is advisable that these are followed, it is also a good idea to have vendors verify system plans
• When possible try to spread system load over time to avoid unnecessary spikes
• Some systems have offline copies of data available to improve performance of I/O expensive operations

















