15
July 20, 2005 Microsoft Tablet PC Microsoft’s Cursive Recognizer Jay Pittman and the entire Microsoft Handwriting Recognition Research and Development Team [email protected]

July 20, 2005 Microsoft Tablet PC
Microsoft’s Cursive Recognizer
Jay Pittmanand the entire
Microsoft Handwriting Recognition
Research and Development [email protected]
July 20, 2005 Microsoft Tablet PC
The Handwriting Recognition Team An experiment:
A research group, but not housed in MSR Positioned inside a product group Our direction and inspiration come directly from the users This isn’t for everyone, but we like it
Just over a dozen researchers Half with PhDs Mostly CS, but 1 Chemistry, 1 Industrial Engineering, 1 Math, 1 Speech Mostly neural network researchers
• Small to moderate experience in other recognition technologies

July 20, 2005 Microsoft Tablet PC
Neural Network Review
Directed acyclic graph Nodes and arcs, each containing a simple value Nodes contain activations, arcs contain weights At run-time, we do a “forward pass” which computes activation from inputs
to hiddens, and then to outputs From the outside, the application only sees the input nodes and output
nodes Node values (in and out) range from 0.0 to 1.0
1.0
0.0
0.0
0.6
1.0
0.8
0.1
1.4
-0.8 0.7
-2.3
0.0
-0.1

July 20, 2005 Microsoft Tablet PC
TDNN: Time Delayed Neural Network
item 2 item 3item 1 item 5 item 6item 4item 1
This is still a normal back-propagation network All the points in the previous slide still apply
The difference is in the connections Connections are limited
Weights are shared
The input is segmented, and the same features are computed for each segment Small detail: edge effects
For the first two and last two columns, the hidden nodes and input nodes that reach outside the range of our input receive zero activations

July 20, 2005 Microsoft Tablet PC
Training We use back-propagation training We collect millions of words of ink data from thousands of
writers Young and old, male and female, left handed and right handed Natural text, newspaper text, URLs, email addresses, street addresses
We collect in nearly two dozen languages around the world
Training on such large databases takes weeks We constantly worry about how well our data reflect our
customers Their writing styles Their text content
We can be no better than the quality of our training sets And that goes for our test sets too

July 20, 2005 Microsoft Tablet PC
Languages We ship now in:
English (US), English (UK), French, German, Spanish, Italian
We have done some initial work in: Dutch, Portuguese, Swedish, Danish, Norwegian, Finnish We cannot predict when we might ship these
Are starting initial research in more Using a completely different approach, we also ship now in:
Japanese, Chinese (Simplified), Chinese (Traditional), Korean

July 20, 2005 Microsoft Tablet PC
Recognizer Architecture
88 8 682263574 4461 575723
9231
51 9 4720
711252 8 7913
5318
792857 6
……
…
1381
8 2 14 3
1717 5 7 4390
716
57914415
Output Matrix
dog 68
clog 57
dug 51
doom 42
divvy 37
ooze 35
cloy 34
doxy 29
client 22
dozy 13
Ink Segments
Top 10 List
d 92
a 88
b 23
c 86
o 77
a 73
l 76
t 5
g 68
t 8
b 6
o 65
g 57
t 12
TDNN
a
b
do
g
ab
t
tc
l
og
t
Lexicon
e
a
…
…
…
…
… Beam Search
ab
de
gh
no
4
5
3
90
12
4
14
7

July 20, 2005 Microsoft Tablet PC
Language Model We get better recognition if we bias our interpretation of
the output matrix with a language model Better recognition means we can handle sloppier cursive
You can write faster, in a more relaxed manner
The lexicon (system dictionary) is the main part But there is also a user dictionary And there are regular expressions for things like dates and currency amounts
We want a generator We ask it: “what characters could be next after this prefix?” It answers with a set of characters
We still output the top letter recognitions In case you are writing a word out-of-dictionary You will have to write more neatly

July 20, 2005 Microsoft Tablet PC
Clumsy lexicon Issue The lexicon includes all the words in the spellchecker The spellchecker includes obscenities
Otherwise they would get marked as misspelled But people get upset if these words are offered as corrections for other misspellings So the spellchecker marks them as “restricted”
We live in an apparently stochastic world We will throw up 6 theories about what you were trying to write If your ink is near an obscene word, we might include that
Dilemma: We want to recognizer your obscene word when you write it
• Otherwise we are censoring, which is NOT our place We DON’T want to offer these outputs when you don’t write them
Solution (weak): We took these words out of the lexicon You can still write them, because you can write out-of-dictionary But you have to write very neat cursive, or nice handprint
Only works at the word level Can’t remove words with dual meanings Can’t handle phrases that are obscene when the individual words are not

July 20, 2005 Microsoft Tablet PC
Regular Expressions Many built-in, callable by ISVs, web pages
Number, date, time, currency amount, phone number, address, URL, email address, file name, phrase list Many components of the above:
• Month, day of month, day of week, year, area code, hour, minute Isolated characters:
• Digit, lowercase letter, uppercase letter None:
• Yields an out-of-dictionary-only system (turns off the language model)
Great for form-filling apps and web pages Accuracy is greatly improved
This is in addition to the ability to load the user dictionary One could load 500 color names for a color field in a form-based app Or 8000 drug names in a prescription app
The regular expression compiler is available at run time Software vendors can add their own regular expressions One could imagine the DMV adding automobile VINs
Example expressions (from the built-in date format): digit = "0123456789"; nummonth = ["0"] "123456789" | "1" "012"; numday = ["0"] "123456789" | "12" digit | "3" "01"; numyear = [ "12" digit ] digit digit ; numyear = "'" digit digit; numdate = nummonth "/" numday ["/" [ "12" digit ] digit digit]; numdate = nummonth "-" numday ["-" [ "12" digit ] digit digit];
July 20, 2005 Microsoft Tablet PC
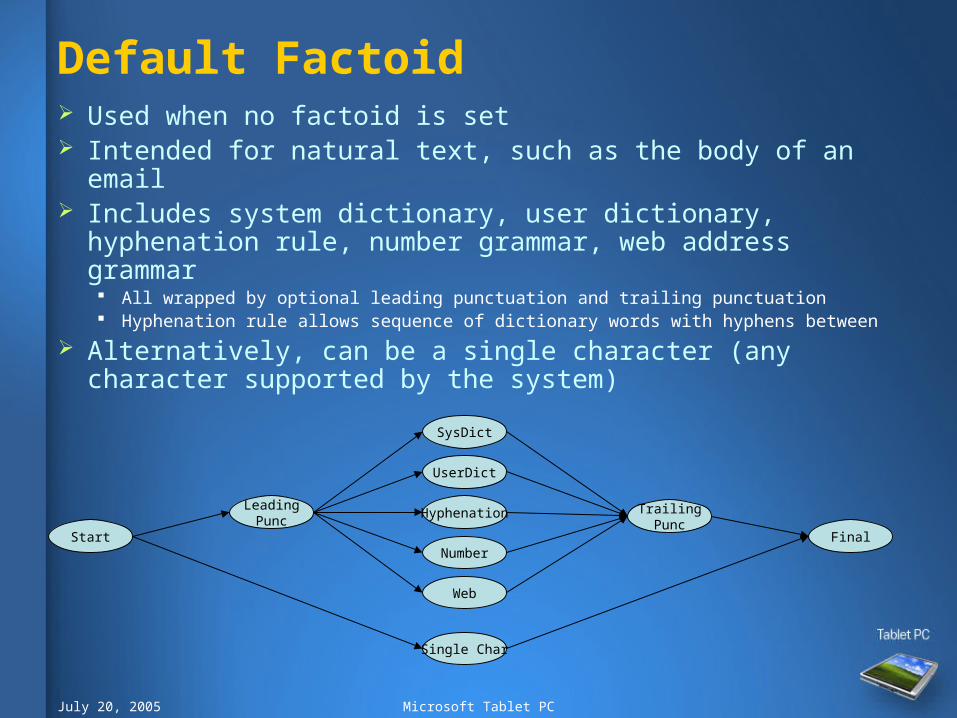
Default Factoid Used when no factoid is set Intended for natural text, such as the body of an email Includes system dictionary, user dictionary, hyphenation
rule, number grammar, web address grammar All wrapped by optional leading punctuation and trailing punctuation Hyphenation rule allows sequence of dictionary words with hyphens between
Alternatively, can be a single character (any character supported by the system)
LeadingPunc
Number
Hyphenation
UserDict
SysDict
TrailingPunc
Web
Single Char
Start Final
July 20, 2005 Microsoft Tablet PC
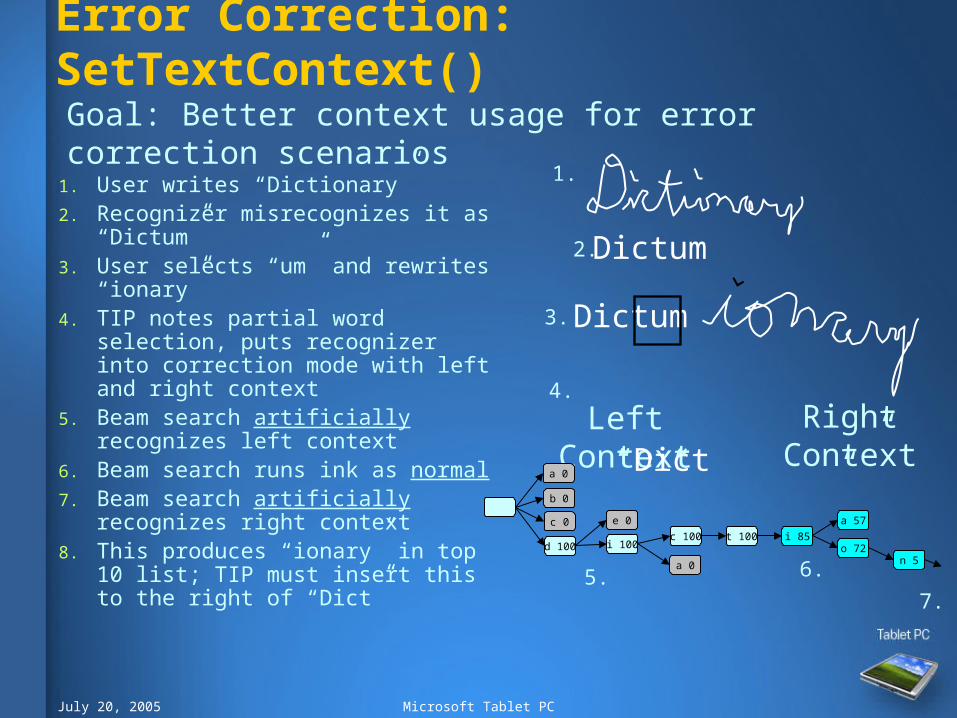
Error Correction: SetTextContext()
Dictum
Dictum
Left Context Right Context“Dict” “”
d 100
a 0
b 0
c 0
i 100
e 0
t 100
n 5
c 100
a 0
i 85
a 57
o 72
1. User writes “Dictionary”2. Recognizer misrecognizes it as
“Dictum”3. User selects “um” and rewrites
“ionary”4. TIP notes partial word selection, puts
recognizer into correction mode with left and right context
5. Beam search artificially recognizes left context
6. Beam search runs ink as normal7. Beam search artificially recognizes
right context8. This produces “ionary” in top 10 list;
TIP must insert this to the right of “Dict”
1.
2.
3.
4.
5. 6.
7.
Goal: Better context usage for error correction scenarios

July 20, 2005 Microsoft Tablet PC
Calligrapher The Russian recognition company Paragraph sold itself
to SGI (Silicon Graphics, Incorporated), who then sold it to Vadem, who sold it to Microsoft.
In the purchase we obtained: Calligrapher
• Cursive recognizer that shipped on the first Apple Newton (but not the second) Transcriber
• Handwriting app for handheld computers (shipped on PocketPC)
Calligrapher has a very similar architecture• Instead of a TDNN it employs a hand-built HMM• The lexicon and beam search similar in nature (many small differences)
We combined our system with Calligrapher We use a voting system (neural nets) to combine each recognizer’s top 10 list They are very different, and make different mistakes We get the best of both worlds If either recognizer outputs a single-character “word” we forget these lists and run
the isolated character recognizer

July 20, 2005 Microsoft Tablet PC
Personalization Ink shape personalization
Simple concept: just do same training on this customer’s ink• Start with components already trained on massive database of ink samples• Train further on specific user’s ink samples
Explicit training• User must go to a wizard and copy a short script• Do have labels from customer• Limited in quantity, because of tediousness
Implicit training• Data is collected in the background during normal use• Doesn’t have labels from customer• We must assume correctness of our recognition result using our confidence measure• We get more data
Much of the work is in the infrastructure:• GUI, database, management of different user’s trained networks, etc.
Lexicon personalization: Harvesting Simple concept: just add the user’s new words to the lexicon Examples (at Microsoft): RTM, dev, SDET, dogfooding, KKOMO, featurization Happens when correcting words in the TIP Also scan Word docs and outgoing email (avoid spam)
July 20, 2005 Microsoft Tablet PC
Best Job at Microsoft Bill Gates makes more money, but I have more fun
No one hassles me for money or slots
I remember senior people at several research institutions saying “waste of time and money” Insert here
I still have a sense of wonder that it works at all It’s as if your dog starting talking to you
People tell me it recognizes their writing when no one else can But I also know there are others who get poor recognition I wonder if Gary Trudeau has tried it
People will adapt to a recognizer, if they use it enough Just as they adapt to the people they live with and work with My physician in Issaquah gets perfect recognition on a Newton
Biggest complaint: we don’t yet ship their language Other complaints:
Weak on URLs, email addresses, slashes Some handprint gets poor recognition Adaptation to my handwriting style (coming)

















