71
Planning for the Web I Data Integration Dan Weld University of Washington June, 2003
| Date post: | 17-Dec-2015 |
| Category: |
Documents |
| Upload: | anissa-hoover |
| View: | 214 times |
| Download: | 0 times |

Planning for the Web IData Integration
Dan WeldUniversity of Washington
June, 2003

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 2
Acknowledgements
• Oren Etzioni• Alon Halevy• Zachary Ives• Rao Kambhampati
Caveat

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 3
My Two Talks for Today• Data Integration
Providing uniform access to disparate data srcs AI meets DB Answering queries using views
Execution in the face of uncertainty, latency• Service Integration
Invoking and composing web services Query and update Planning with incomplete information

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 4
Overview: Data Integration• Motivation / intro• Wrappers / information extraction• Database review• Integrating data sources
Content, completeness, capabilities Reformulation algorithms: Bucket

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 5
What is Data Integration?
Uniform (same query interface to all sources) Access to (queries; eventually updates too) Multiple (we want many, but 2 is hard too) Autonomous (DBA doesn’t report to you) Heterogeneous (data models are different) Structured (or at least semi-structured) Data Sources (not only databases).
A system providing:

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 6
User enters query
Formulate queries
Lycos Excite. . .Collate results
Remove duplicates
Post-process + rank
Download?
Present to user

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 7
Meta-?• Web Search• Shopping• Product Reviews • Chat Finder • Columnists (e.g. jokes, sports, ….)• Email Lookup • Event Finder • People Finder • Restaurant Reviews • Job Listings• Classifieds• Apartment + Real Estate

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
Intuition: Info Integration• Info aggregation … on Steroids!• Want agent such that
•User says what she wants•Agent decides how & when to achieve
it• Example:
Show me all reviews of movies starring Matt Damon that are currently playing in Seattle
Ebert
IMDBFandangoSidewalk

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 9
Info. Aggregation vs. Integration
• More complex queries• Dynamic generation/optimization of execution plan• Applicable to wider range of problems • Much harder to implement efficiently
prices of laptop with …
sort
store1 store2 storeN…
moviesin Seattlestarring …
join
IMDB sidewalk
rev2 …rev1
Join, sortaggregate
revN

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
User must know which sites have relevant info
User must go to each one in turnSlow: Sequential access takes timeConfusing: Each site has a different
interfaceUser must manually integrate
information
Challenges

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 11
Practical Motivation• Enterprise
Business “dashboard’’; web-site construction.• WWW
Comparison shopping Portals integrating data from multiple sources B2B, electronic marketplaces
• Science and culture: Medical genetics: integrating genomic data Astrophysics: monitoring events in the sky. Environment: Puget Sound Regional Synthesis Model Culture: uniform access to all cultural databases
produced by countries in Europe.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 12
ReviewsSh ipp ingO rdersInven toryBooks
m ybooks .com M edia ted S chem a
W es t
...
F edEx
W AN
a lt.books .re v iews
In te rne tIn te rne t In te rne t
UPS
Eas t O rde rs Cus tome rRev iews
NYTimes
...
Mo rgan-Kaufman
P rentic e -Ha ll
The Problem: Data Integration
Uniform query capability across autonomous, heterogeneous data sources on LAN, WAN, or Internet

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 13
Current Solutions• Mostly ad-hoc programming: create a
special solution for every case; pay consultants a lot of money.
• Data warehousing: load all the data periodically into a warehouse. 6-18 months lead time Separates operational DBMS from decision
support DBMS. (not only a solution to data integration).
Performance is good; data may not be fresh. Need to clean, scrub you data.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 14
Data Warehouse Architecture
Datasource
Datasource
Datasource
Relational database (warehouse)
User queries
Data extractionprograms
Data extraction, cleaning/scrubbing
OLAP / Decision support/Data cubes/ data mining

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 15
Warehouse Summary • Pro
Relatively simple Good performance (OLAP support) Mature technology (DB, ETL industries)
• Con Expensive Stale data Risky – most warehouse projects fail
•Rigid architecture•Fixed schema•Must know all queries ahead of time

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 16
Architecture for Virtual Integration
Leave the data in the sources.When a query comes in:
1) Determine which sources are relevant to query.
2) Break query into sub-queries for each source.3) Get answers from sources4) Combine.
Data is fresh.Challenge: performance.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 17
Virtual Integration Architecture
Datasource
wrapper
Datasource
wrapper
Datasource
wrapper
Sources can be: relational, hierarchical (IMS), structured files, web sites.
Mediator:
User queriesMediated schema
Data sourcecatalog
Reformulator
Optimizer
Execution engine

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 18
Research Projects• Garlic (IBM),• Information Manifold (AT&T)• Tsimmis, InfoMaster (Stanford)• Internet Softbot/Razor/Tukwila (U Wash.)• Hermes (Maryland)• Telegraph / Eddies (UC Berkeley)• Niagara (Univ Wisconsin)• DISCO, Agora (INRIA, France)• SIMS/Ariadne (USC/ISI)• Emerac/Havasu (ASU)

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 19
Industry
• Nimble Technology• Enosys Markets• IBM• BEA

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 20
Dimensions to Consider• How many sources are we accessing?• How autonomous are they?• Meta-data about sources?• Is the data structured?• Queries or also updates?• Requirements: accuracy, completeness,
performance, handling inconsistencies.• Closed world assumption vs. open
world?

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 21
OutlineMotivation / introduction• Wrappers / information extraction• Database Review• Integrating data sources
Content, completeness, capabilities Reformulation algorithms: Bucket

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 22
Wrapper Programs• Task
to communicate with the data sources and do format translations.
• Built w.r.t. a specific source.• Can sit either at the source or
mediator.• Often hard to build
(very little science).• Can be “intelligent”
perform source-specific optimizations.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 23
Example<b> Introduction to DB </b><i> Phil Bernstein </i><i> Eric Newcomer </i> Addison Wesley, 1999
<book><title> Introduction to DB </title><author> Phil Bernstein </author><author> Eric Newcomer </author><publisher> Addison Wesley </publisher><year> 1999 </year></book>
Transform:
into:

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 24
Wrapper Construction
• Use PERL, or• Generate wrappers automatically
Get training examples• Human marks up selected pages with GUI tool
Use shallow NLP to create features Favorite learning method
• HMMs, VS on prefix, postfix strings, ?? Boosting Co-training
• See research on information extraction

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 25
SemTag & Seeker• WWW-03 Best Paper Prize• Seeded with TAP ontology (72k
concepts) And ~700 human judgments
• Crawled 264 million web pages• Extracted 434 million semantic tags
Automatically disambiguated

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 26
OutlineMotivation / IntroductionWrappers / Information extraction• Database Review
•Relational algebra, SQL, datalog•Views•Optimization (query planning)
• Integrating data sources Content, completeness, capabilities Reformulation algorithms: Bucket
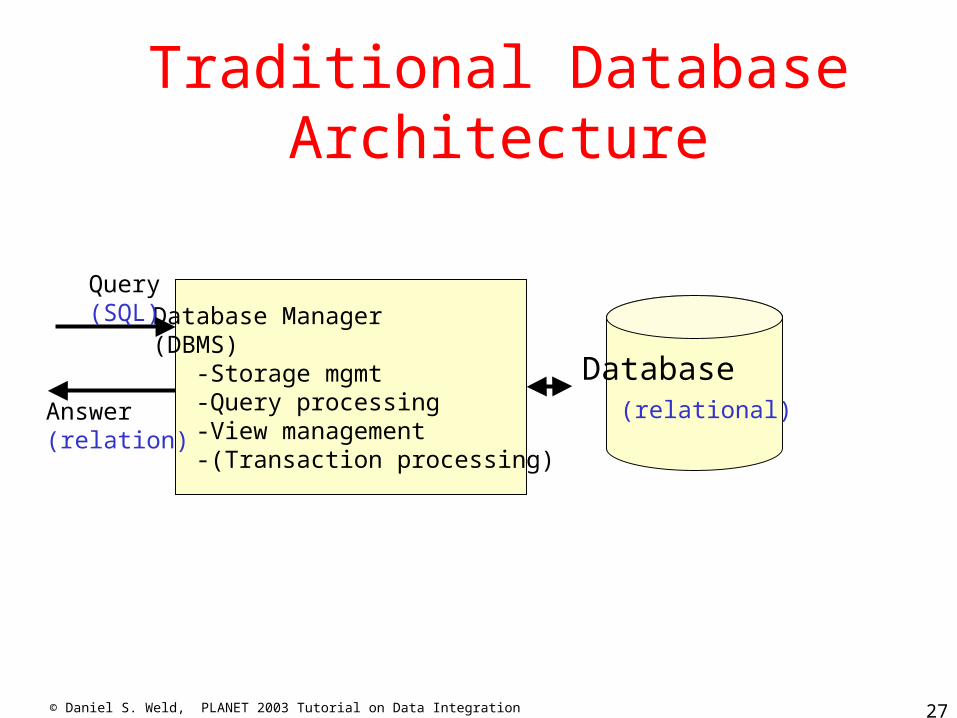
© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 27
Database (relational)
Database Manager(DBMS) -Storage mgmt -Query processing -View management -(Transaction processing)
Query(SQL)
Answer(relation)
Traditional Database Architecture

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 28
Relational Data: Terminology
Name Price Category Manufacturer
gizmo $19.99 gadgets GizmoWorks
Power gizmo $29.99 gadgets GizmoWorks
SingleTouch $149.99 photography Canon
MultiTouch $203.99 household Hitachituple
attributeProduct
Product(Name: string, Price: real, category: enum, Man: string)
schema
relation (Arity=4)

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 29
Relational Algebra
• Operators tuple sets as input, new set as output
• Operations Union, Intersection, difference, .. Selection ( Projection () Cartesian product (X)
•Join ( )
Name Price Category Manufacturer
gizmo $19.99 gadgets GizmoWorks
Power gizmo $29.99 gadgets GizmoWorks
SingleTouch $149.99 photography Canon
MultiTouch $203.99 household Hitachi
City Manufacturer
GizmoWorks
Canon
Hitachi
Tempe
Kyoto
Dayton

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 30
SQL: A query language for Relational Algebra
Many standards out there: SQL92, SQL2, SQL3, SQL99 Select attributes From relations (possibly multiple, joined) Where conditions (selections)
“Find companies that manufacture products bought by Joe Blow”SELECT Company.name FROM Company, Product WHERE Company.name=Product.maker AND Product.name IN (SELECT product FROM Purchase WHERE buyer = “Joe Blow”);
Other features: aggregation, group-by etc.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 31
Deductive Databases• Tables viewed as predicates. • Ops on tables expressed as “datalog” rules
(Horn clauses, without function symbols)
Enames(Name) :- Employe(Name, SSN) [Projection]
Wealthy-Employee(Name) :- Employee(Name,SSN), Salary(SSN,Money),Money> 10 [Selection]Ed(Name, Dname) :- Employee(Name, SSN), E_Dependents(SSN, Dname) [Join]
ERelated(Name,Dname) :- Ed(Name,Dname)ERelated(Name,Dname) :- Ed(Name,D1), ERelated(D1,D2) [Recursion]

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 33
ViewsViews are relations,
except that they are not physically stored.
Uses:• simplify complex queries, &• define conceptually different views of DB for diff. users.
Example: purchases of telephony products:
CREATE VIEW telephony-purchases AS SELECT product, buyer, seller, store FROM Purchase, Product WHERE Purchase.product = Product.name AND Product.category = “telephony”

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 34
A Different ViewCREATE VIEW Seattle-view AS
SELECT buyer, seller, product, store FROM Person, Purchase WHERE Person.city = “Seattle” AND Person.name = Purchase.buyer
We can later use the view: SELECT name, store FROM Seattle-view, Product WHERE Seattle-view.product = Product.name AND Product.category = “shoes”
What’s really happening when we query a view??

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 35
Materialized Views• Views whose corresponding queries have been
executed and the data is stored in a separate database Uses: Caching
• Issues Using views in answering queries
•Normally, views are available in addition to DB– (so, views are local caches)
•In information integration, views may be the only things we have access to.
– An internet source specializing in tom hanks movies can be seen as a view on a database of all movies.
– Except, there is no DB out there which contains all movies..

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 36
DB Inference
• Type 1 Evaluate query on instance of data Exponential in size of query Key is performance in size of data
• Type 2 Query containment Q1 Q2
No matter what data instances Logical entailment

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 37
Query OptimizationImperative execution plan:Declarative query
Ideally: Want to find best plan. Practically: Avoid worst plans!
Purchase Person
Buyer=name
City=‘seattle’ phone>’5430000’
buyer
(Simple Nested Loops)
(Table scan) (Index scan)
SELECT S.buyerFROM Purchase P, Person QWHERE P.buyer=Q.name AND Q.city=‘seattle’ AND Q.phone > ‘5430000’
Inputs:• the query• available memory• statistics about the data
• indexes, • cardinalities, • selectivity factors

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 38
Reserves Sailors
sid=sid
bid=100 rating > 5
sname
(Simple Nested Loops)
(On-the-fly)
(On-the-fly)
(Scan;write to temp T1)
(Sort-Merge Join)
Reserves
Sailors
sid=sid
bid=100
sname(On-the-fly)
rating > 5 (On-the-fly)
SELECT S.snameFROM Reserves R, Sailors SWHERE R.sid=S.sid AND R.bid=100 AND S.rating>5
Goal of optimization: To find more efficient plans that compute the same answer.
Reserves Sailors
sid=sid
bid=100
sname(On-the-fly)
rating > 5
(Use hashindex; donot writeresult to temp)
Pipelined hash join

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
Relational Algebra Equivalences
• Allow us to choose different join orders and to ‘push’ selections and projections ahead of joins.
c cn c cnR R1 1 ... . . .
c c c cR R1 2 2 1 (Commute)
Projections: RR anaa ...11 (Cascade)
Joins: R (S T) (R S) T (Associative)
(R S) (S R) (Commute)
Selections:

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 40
• Q(u,x) :- R(u,v), S(v,w), T(w,x) R S T
• Many ways of doing a single join R S Symmetric vs. asymmetric join operations
• Nested join, hash join, double pipe-lined hash join etc.
Processing costs alone vs. proc. + transfer costs• Get R and S together vs, get R, get just the tuples of S that will join with R
(“semi-join”)
• Many orders in which to do the join (R join S) join T (S join R) join T (T join S) join R etc.
• All with different costs
Optimizing Joins
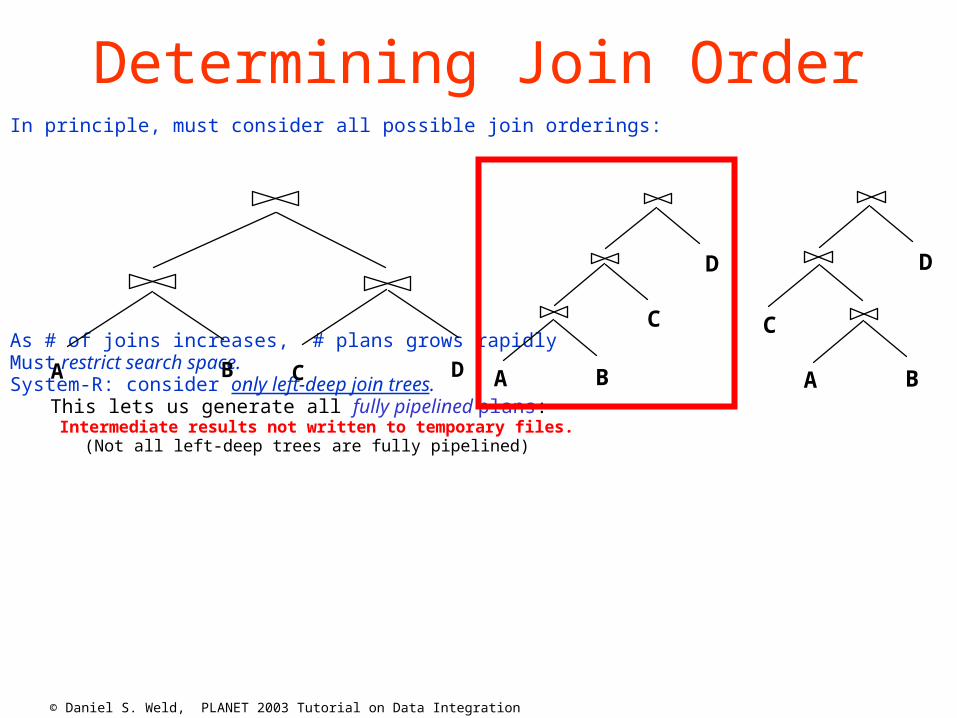
© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
Determining Join OrderIn principle, must consider all possible join orderings:
As # of joins increases, # plans grows rapidlyMust restrict search space.System-R: consider only left-deep join trees.
This lets us generate all fully pipelined plans:Intermediate results not written to temporary files.
(Not all left-deep trees are fully pipelined)
BA
C
D
BA
C
D
C DBA

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
Cost Estimation• For each plan considered, estimate cost:
Estimate cost of each operation in plan tree.• Depends on input cardinalities.
Estimate size of result for each op in tree!• Use information about the input relations.• Selectivity (Histograms)• For selections and joins, assume independence
of predicates.
• System R cost estimation approach. Very inexact, but works ok in practice. More sophisticated techniques known now.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 44
Key Lessons in Optimization
• Classic planning / execution scenario Uncertainty / replanning key for data
integration • Main points
Disk IO as cost metric Algebraic rules / use in query transformation.. Join ordering via dynamic programming Estimating cost of plans
• Size of intermediate results.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 45
Integrator vs. DBMSNo common schema
Sources with heterogeneous schemas Semi-structured sources
Legacy Sources Not relational-complete Access/process limitations
Autonomous sources Uncontrolled source content overlap Lack of source statistics
Tradeoffs: plan cost, coverage, quality, … Multi-objective cost models
Unpredictable run-time behavior Makes query execution hard
Reprise

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 46
OutlineMotivationWrappers / information extractionDatabase Review• Integrating data sources
Content, completeness, capabilities Reformulation algorithms: Bucket

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration
Remnder: Info Integration• Want agent such that
•User says what she wants•Agent decides how & when to achieve
it• Example:
Show me all reviews of movies starring Matt Damon that are currently playing in Seattle
Ebert
IMDBFandangoSidewalk

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 48
Data Source Catalog• Contains meta-information about sources:
Logical source contents (books, new cars). Source capabilities (can answer SQL
queries?) Source completeness (has all books). Physical properties of source and
network. Statistics about the data (like in an RDBMS) Source reliability Mirror sources? Update frequency.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 49
Content Descriptions
• User queries refer to the mediated schema.
• Source data is stored in a local schema.• Content descriptions provide
semantic mappings between different schemas.
• Data integration system uses the descriptions to translate user
queries into queries on the sources.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 50
Desiderata for Source Descriptions
• Expressive power: distinguish between sources with closely related data. Enable pruning of access to irrelevant sources.
• Easy addition: make it easy to add new data sources.
• Reformulation: be able to reformulate a user query into a query on the sources efficiently and effectively.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 51
Reformulation Problem• Given:
A query Q posed over the mediated schema Descriptions of the data sources
• Find: A query Q’ over the data source relations,
such that:•Q’ provides only correct answers to Q, and•Q’ provides all possible answers from to Q
given the sources.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 52
Approaches to Specifying Source Descriptions
• Global-as-view: express the mediated schema relations as a set of views over the data source relations
• Local-as-view: express the source relations as views over the mediated schema.
• Can be combined with no additional cost.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 53
Global-as-ViewMediated schema: Movie(title, dir, year, genre), Schedule(cinema, title, time).
Create View Movie AS select * from S1 [S1(title,dir,year,genre)] union select * from S2 [S2(title, dir,year,genre)] union [S3(title,dir), S4(title,year,genre)] select S3.title, S3.dir, S4.year, S4.genre from S3, S4 where S3.title=S4.title

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 55
Global-as-View: Example 3Mediated schema: Movie(title, dir, year, genre), Schedule(cinema, title, time).Source S4: S4(cinema, genre)
Create View Movie AS select NULL, NULL, NULL, genre from S4 Create View Schedule AS select cinema, NULL, NULL from S4.
But what if we want to find which cinemas are playing comedies?

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 56
Global-as-View Summary
Very easy conceptually. Query reformulation view unfolding.
Can build hierarchies of mediated schemas.
Sometimes loose information. Not always natural.
Adding sources is hard. Need to consider all other sources that are
available. May need to modify every global view defn

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 57
Local-as-View: example 1Mediated schema: Movie(title, dir, year, genre), Schedule(cinema, title, time).
Create Source S1 AS [S1(title, dir, year, genre)] select * from MovieCreate Source S3 AS [S3(title, dir)] select title, dir from MovieCreate Source S5 AS [S5(title, dir, year)] select title, dir, year from Movie where year > 1960 AND genre=“Comedy”

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 58
Local-as-View: Example 2Mediated schema: Movie(title, dir, year, genre), Schedule(cinema, title, time).Source S4: S4(cinema, genre)
Create Source S4 select cinema, genre from Movie m, Schedule s where m.title=s.title. Now if we want to find which cinemas are playing
comedies, there is hope!

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 59
Local-as-View Summary
• Very flexible. You have the power of the entire query
language to define the contents of the source.
• Hence, can easily distinguish between contents of closely related sources.
• Adding sources is easy: They’re independent of each other.
• Query reformulation: Answering queries using views!

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 60
The General Problem• Given a set of views V1,…,Vn, and a
query Q, can we answer Q using only the answers to V1,…,Vn? Many, many papers on this problem. Great survey on the topic: (Halevy, 2001).
• The best performing algorithm: MiniCon (Pottinger & Levy, 2000).

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 61
Movie,
Schedule
Example Query:Q(x):- r1(x,y) & r2(y,x)
Views:V1(a):-r1(a,b)V2(d):-r2(c,d)V3(f):- r1(f,g) & r2(g,f)
Create Source V1 as select a from r1
Create Source V3 as select r1.arg1 from r1, r2 where r1.arg1 = r2.arg2

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 62
Bucket Algorithm (1)1) For each subgoal in the query, place
relevant views in the subgoal’s bucketQuery:Q(x):- r1(x,y) & r2(y,x)Views:V1(a):-r1(a,b)V2(d):-r2(c,d)V3(f):- r1(f,g) & r2(g,f)
r1(x,y) r2(y,x)
V1(x),V3(x) V2(x), V3(x)
Buckets:

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 63
Bucket Algorithm (2)2) For every combo in the Cartesian product of
the buckets, “check containment of the query”
Candidate rewritings:Q’1(x) :- V1(x) & V2(x)
Q’2(x) :- V1(x) & V3(x)
Q’3(x) :- V3(x) & V2(x)
Q’4(x) :- V3(x) & V3(x)
r1(x,y)
V1(x),V3(x)
r2(y,x)
V2(x), V3(x)
Bucket Algorithm will check all possible combinations
r1(x,y)
r2(y,x)
Q(x):-r1(x,y) & r2(y,x) Q’4(x):-r1(x,a) & r2(a,x) & r1(x,b) & r2(b,x)

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 64
Modeling Source Capabilities
• Negative capabilities: A web site may require certain inputs (in an
HTML form).• Positive capabilities:
A source may be an ODBC compliant system. Need to decide placement of operations
according to capabilities.• Problem: how to describe and exploit
source capabilities.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 65
&cites(x, y)
Example #1: Access PatternsMediated schema relation: cites(paper1, paper2)
Create Source S1 as S1($x,y) :- cites(x, y) select * from cites given paper1
Create Source S2 as S2(x) :- cites(x, y) select paper1 from cites Query: Q(x) :- cites(x, “W03”)
Select paper1 from cites where paper2=“W03”

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 66
Example #2: Access PatternsCreate Source S1 as select * from Cites given paper1Create Source S2 as select paperID from UW-PapersCreate Source S3 as select paperID from AwardPapers given paperIDQuery: select * from AwardPapers

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 67
Example #2: Solutions• Can’t go directly to S3 (it requires a
binding).• Can go to S1, get UW papers,
and check if they’re in S3.• Can
go to S1, get UW papers, feed them to S2, and then check if they’re in S3.
• Can go to S1, feed results into S2, feed results
into S2 again, then check if they’re in S3.• Note: we can’t a priori decide when to stop.
Need recursive query processing.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 68
Algorithms
• Inverse Rules [Duschka & Genesereth]• Minicon [Pottinger & Levy]

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 69
Complexity of finding maximally-contained plans
• Complexity depends on sources, not query Sources as unions of conjunctive
queries (NP-hard)•Disjunctive descriptions
Sources as recursive queries (Undecidable) True source contents
Advertised description

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 70
Matching Objects Across Sources
• How do I know that D. Weld in source 1 is the same as Daniel S. Weld in source 2?
• If uniform keys across sources, easy.• If not:
Domain specific solutions • (e.g., maybe look at the address, …).
Use IR techniques (Cohen, 98). • Judge similarity as you would between documents.
Use concordance tables. • These are time-consuming to build, but you can
then sell them for lots of money.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 71
Schema Mapping Problem• Types of structures:
Database schemas, XML DTDs, ontologies, …,
• Input: Two (or more) structures, S1 and S2
(perhaps) Data instances for S1 and S2
Background knowledge• Output:
A mapping between S1 and S2
Should enable translating between data instances.

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 72
Semantic Mappings between Schemas
• Source schemas = XML DTDs
house
location contact
house
address
name phone
num-baths
full-baths half-baths
contact-info
agent-name agent-phone
1-1 mapping non 1-1 mapping

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 73
Summary• Data Integration
Providing uniform access to disparate data srcs AI meets DB
• Modeling Data Sources GAV, LAV
• Query Reformulation Answering queries using views Bucket algorithm [Inverse rules, Minicon]
• Schema Matching

© Daniel S. Weld, PLANET 2003 Tutorial on Data Integration 74
Next Talk• Executing data integration plans
Variable latency, Poor info on size & speed of remote sources Adaptive execution
• Service integration Invoking and composing web services Query and update Planning with incomplete information

















