47
Platform-based Design TU/e 5kk70 Henk Corporaal Bart Mesman Exploiting ILP VLIW architectures (part b) ILP compilation (part a)
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 219 times |
| Download: | 0 times |

Platform-based Design
TU/e 5kk70Henk Corporaal
Bart Mesman
Exploiting ILPVLIW architectures (part b)
ILP compilation (part a)

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
2
What are we talking about?
ILP = Instruction Level Parallelism =
ability to perform multiple operations (or instructions),from a single instruction stream,
in parallel
VLIW = Very Long Instruction Word architecture
operation 1 operation 2 operation 3 operation 4
Instruction format:
operation 5

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
3
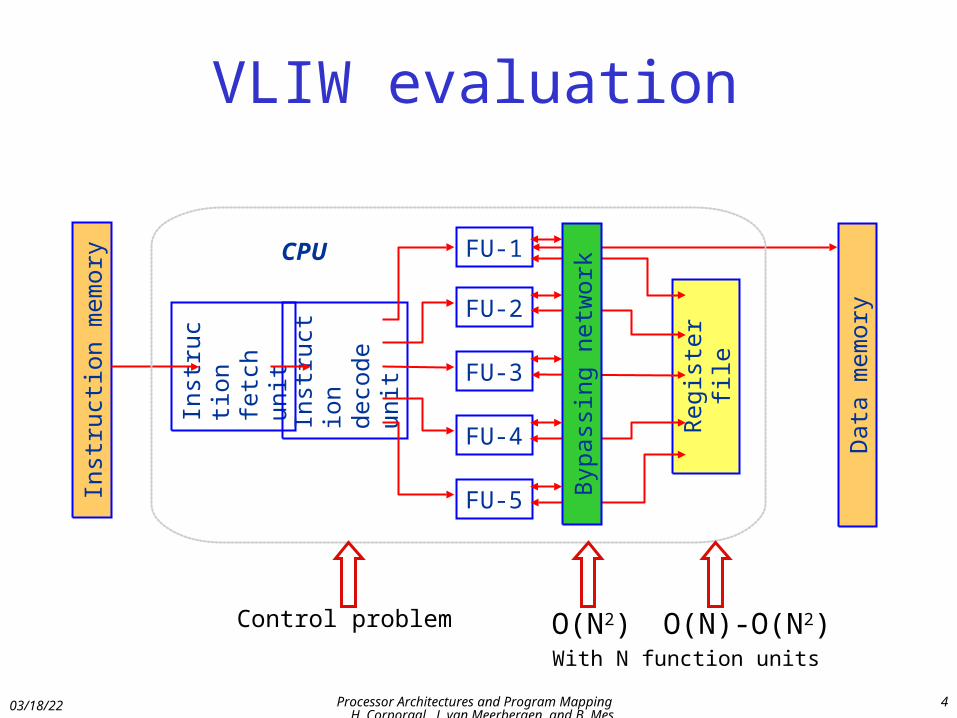
VLIW evaluation
Strong points of VLIW:– Scalable (add more FUs)– Flexible (an FU can be almost anything; e.g. multimedia support)
Weak points:• With N FUs:
– Bypassing complexity: O(N2)– Register file complexity: O(N)– Register file size: O(N2)
• Register file design restricts FU flexibility
Solution: .................................................. ?
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
4
VLIW evaluationIn
stru
ctio
n m
emor
y
Inst
ruct
ion
fetc
h un
it
Inst
ruct
ion
deco
de u
nit
FU-1
FU-2
FU-3
FU-4
FU-5
Reg
iste
r fi
le
Dat
a m
emor
y
CPU
Byp
assi
ng n
etw
ork
Control problem O(N2) O(N)-O(N2) With N function units
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
5
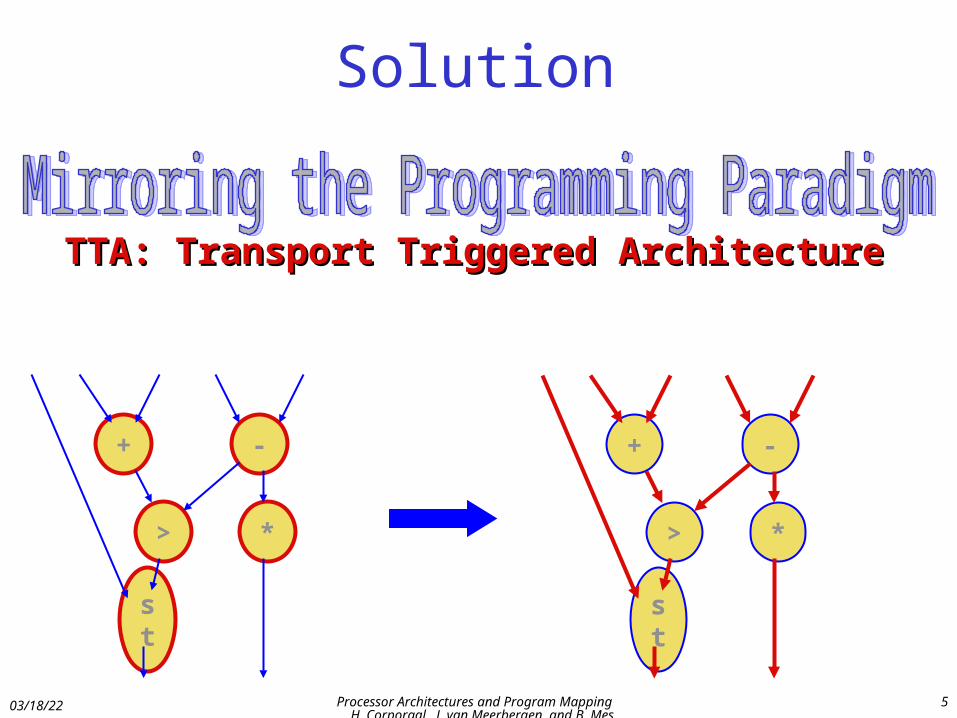
Solution
TTA: Transport Triggered ArchitectureTTA: Transport Triggered Architecture
>
st
*
+ -
>
st
*
+ -
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
6
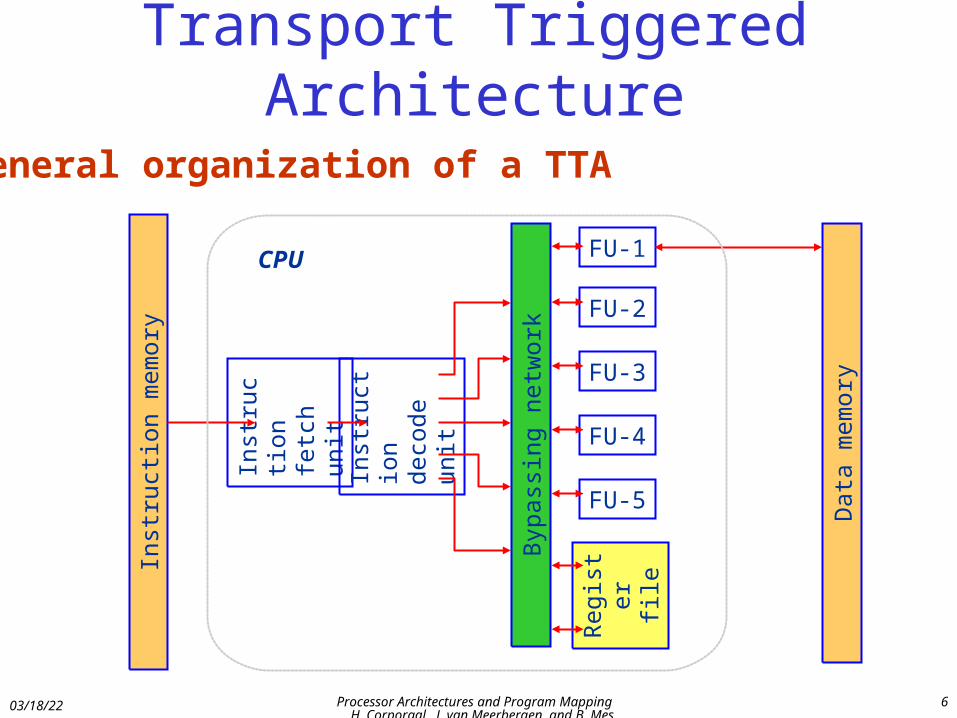
Transport Triggered Architecture
General organization of a TTAIn
stru
ctio
n m
emor
y
Inst
ruct
ion
fetc
h un
it
Inst
ruct
ion
deco
de u
nit
FU-1
FU-2
FU-3
FU-4
FU-5
Reg
iste
r fi
le
Dat
a m
emor
y
CPU
Byp
assi
ng n
etw
ork

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
7
TTA structure; datapath details
Socket
integer RF
floatRF
booleanRF
instruct.unit
immediateunit
load/store unit
integer ALU
float ALU
integer ALU
load/store unit
Data Memory
Instruction Memory

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
8
TTA hardware characteristics
• Modular: building blocks easy to reuse• Very flexible and scalable
– easy inclusion of Special Function Units (SFUs)
• Very low complexity– > 50% reduction on # register ports– reduced bypass complexity (no associative matching)– up to 80 % reduction in bypass connectivity– trivial decoding– reduced register pressure– easy register file partitioning (a single port is enough!)

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
9
TTA software characteristics
• More difficult to schedule !• But: extra scheduling optimizations
add r3, r1, r2
r1 add.o1; r2 add.o2;
add.r r3
That does not look like an
improvement !?!
+o1 o2
r

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
10
Program TTAs
How to do data operations ?1. Transport of operands to FU
• Operand move (s)• Trigger move
2. Transport of results from FU• Result move (s)
How to do Control flow ?1. Jumps: #jump-address pc
2. Branch: #displacement pcd
3. Call: pc r; #call-address pcd
Example Add r3,r1,r2 becomesr1 Oint // operand move to integer unitr2 Tadd // trigger move to integer unit…………. // addition operation in progressRint r3 // result move from integer unit
Trigger Operand
Internal stage
Result
FU Pipeline
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
11
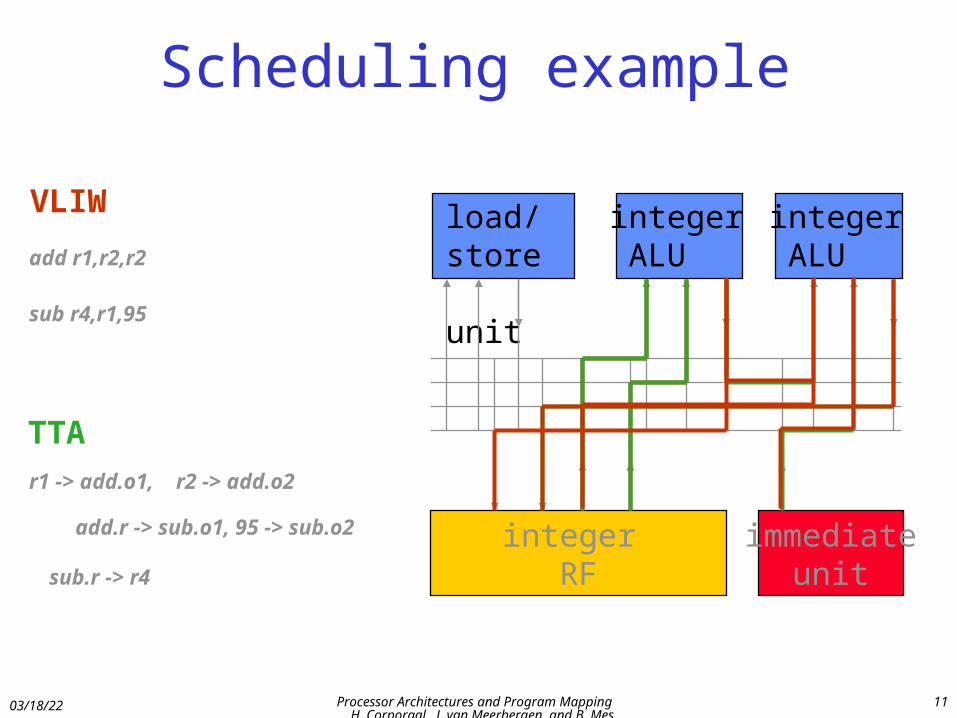
Scheduling example
add r1,r2,r2
sub r4,r1,95
VLIW
r1 -> add.o1, r2 -> add.o2
add.r -> sub.o1, 95 -> sub.o2
sub.r -> r4
TTA
integer RF
immediateunit
integer ALU
integer ALU
load/store unit

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
12
TTA Instruction format
General MOVE field:g : guard specifieri : immediate specifiersrc : sourcedst : desitnation
g i src dst
How to use immediates?
Small, 6 bits
Long, 32 bits
g 1 imm dst
g 0 Ir-1 dst imm
move 1
General MOVE instructions: multiple fields
move 2 move 3 move 4

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
13
Programming TTAs
How to do conditional executionEach move is guarded
Exampler1 cmp.o1 // operand move to compare unitr2 cmp.o2 // trigger move to compare unitcmp.r g // put result in boolean register gg:r3 r4 // guarded move takes place when r1=r2
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
14
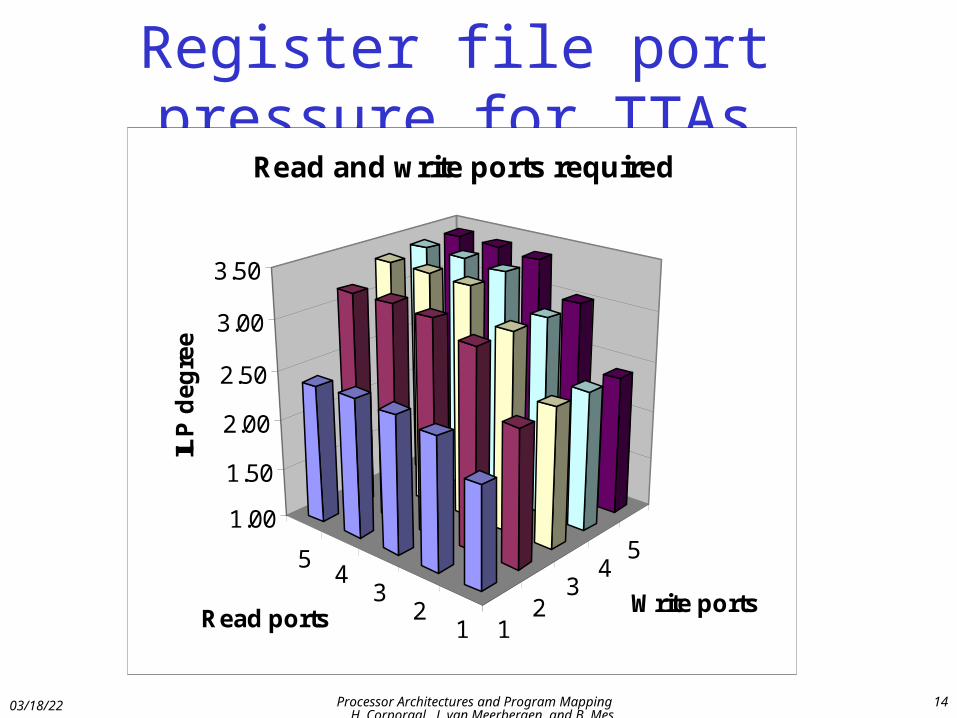
Register file port pressure for TTAs
12
34
5
12
34
51.00
1.50
2.00
2.50
3.00
3.50
ILP
de
gre
e
Read portsWrite ports
Read and write ports required

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
15
Summary of TTA Advantages
• Better usage of transport capacity– Instead of 3 transports per dyadic operation, about 2 are
needed– # register ports reduced with at least 50%– Inter FU connectivity reduces with 50-70%
• No full connectivity required
• Both the transport capacity and # register ports become independent design parameters; this removes one of the major bottlenecks of VLIWs
• Flexible: Fus can incorporate arbitrary functionality• Scalable: #FUS, #reg.files, etc. can be changed• FU splitting results into extra exploitable concurrency• TTAs are easy to design and can have short cycle times
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
16
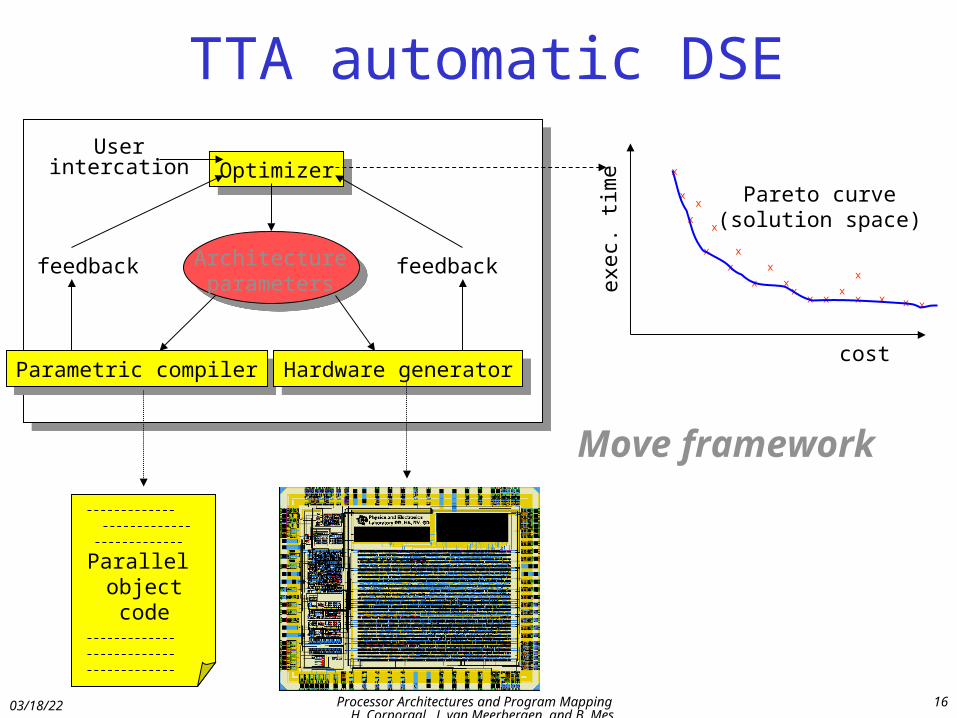
TTA automatic DSE
Architectureparameters
OptimizerOptimizer
Parametric compilerParametric compiler Hardware generatorHardware generator
feedbackfeedback
Userintercation
Parallel object code chip
Pareto curve(solution space)
cost
exec
. tim
e
x
x
x
x
xx
x
xx
x
x
x
x
x
x
xx x
x
x
Move framework
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
17
Overview• Enhance performance: architecture methods• Instruction Level Parallelism• VLIW• Examples
– C6
– TM
– TTA
• Clustering and Reconfigurable components• Code generation• Hands-on
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
18
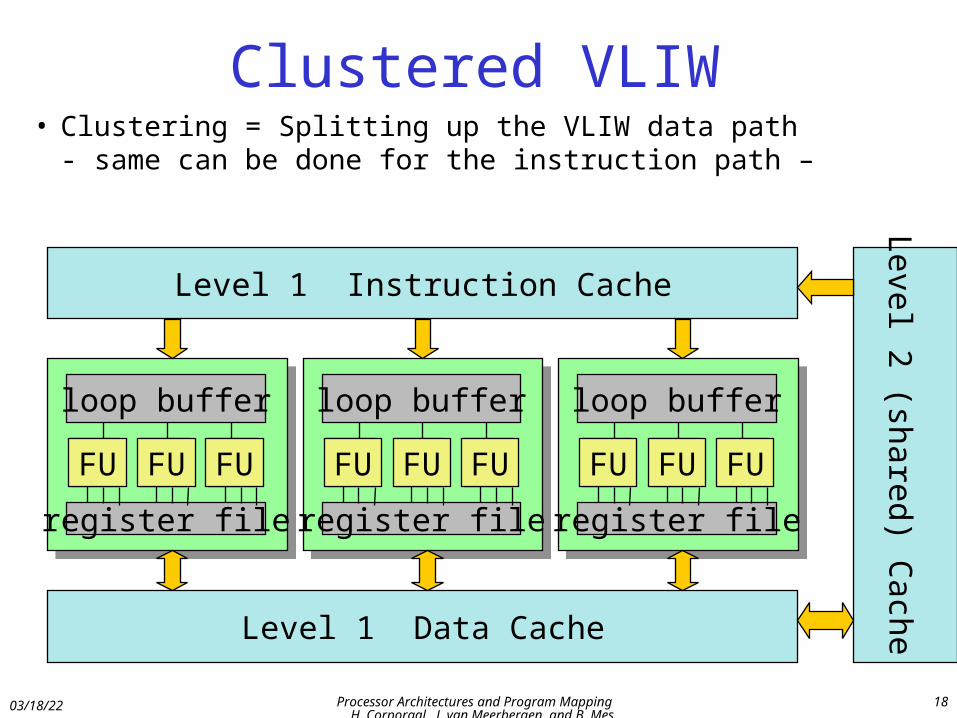
Clustered VLIW• Clustering = Splitting up the VLIW data path
- same can be done for the instruction path –
FU FU FU
loop buffer
register file
FU FU FU
loop buffer
register file
FU FU FU
loop buffer
register file
Level 1 Instruction Cache
Level 1 Data Cache
Level 2 (shared) C
ache

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
19
Clustered VLIW
Why clustering?
• Timing: faster clock
• Lower Cost– silicon area– T2M
• Lower Energy
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
20
CLB
CLB
CLB
CLB
SwitchMatrix
ProgrammableInterconnect I/O Blocks (IOBs)
ConfigurableLogic Blocks (CLBs)
D Q
SlewRate
Control
PassivePull-Up,
Pull-Down
Delay
Vcc
OutputBuffer
InputBuffer
Q D
Pad
D QSD
RDEC
S/RControl
D QSD
RDEC
S/RControl
1
1
F'
G'
H'
DIN
F'
G'
H'
DIN
F'
G'
H'
H'
HFunc.Gen.
GFunc.Gen.
FFunc.Gen.
G4G3G2G1
F4F3F2F1
C4C1 C2 C3
K
Y
X
H1 DIN S/R EC
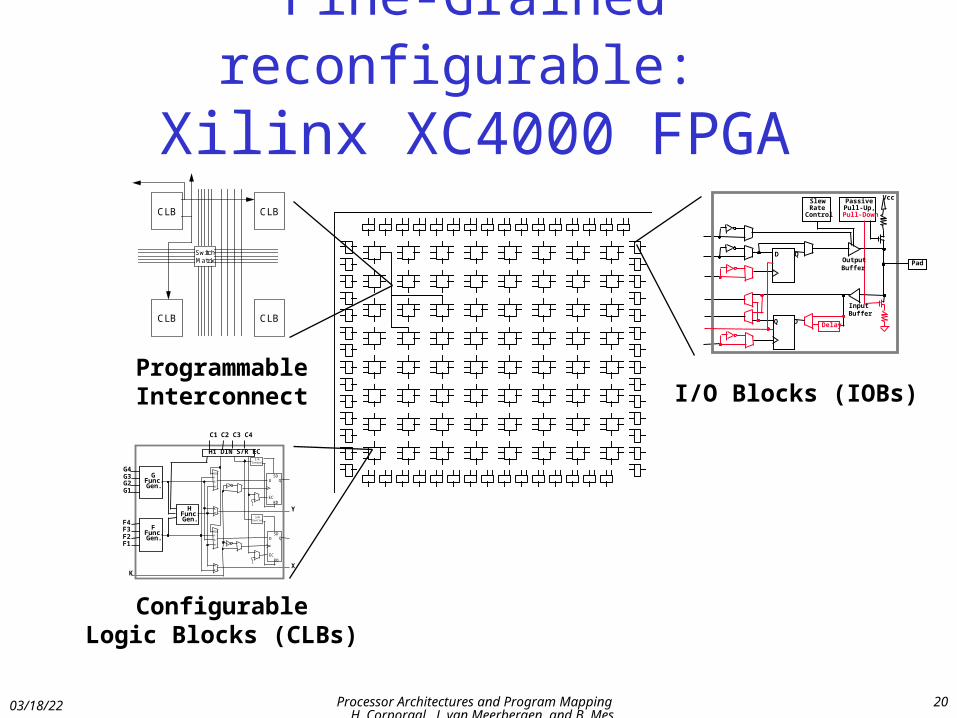
Fine-Grained reconfigurable: Xilinx XC4000 FPGA
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
21
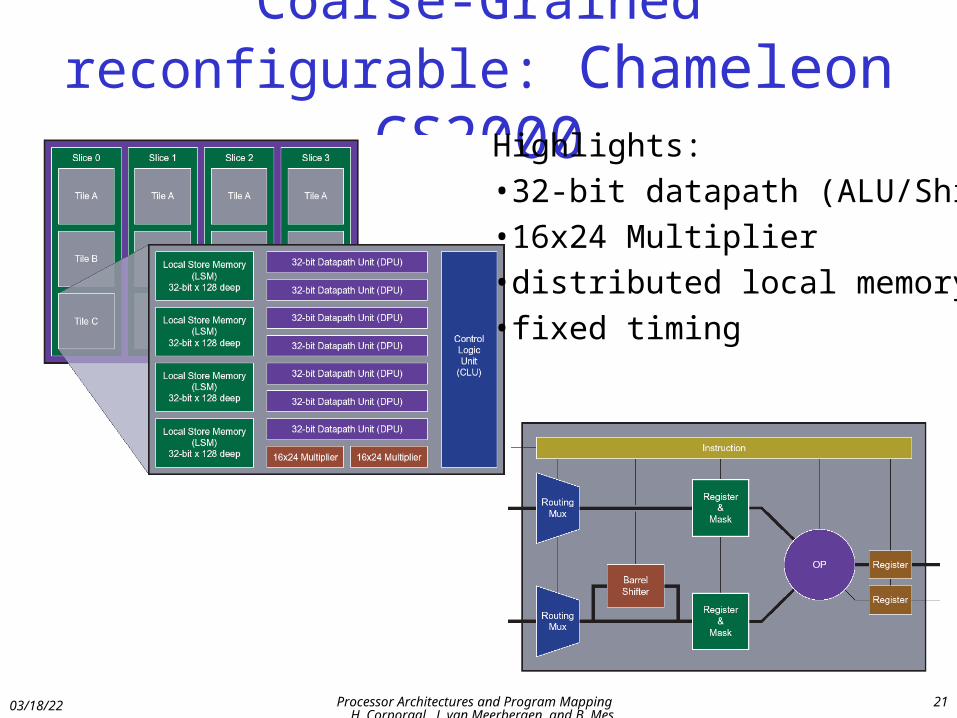
Coarse-Grained reconfigurable: Chameleon CS2000
Highlights:•32-bit datapath (ALU/Shift)•16x24 Multiplier•distributed local memory•fixed timing
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
22
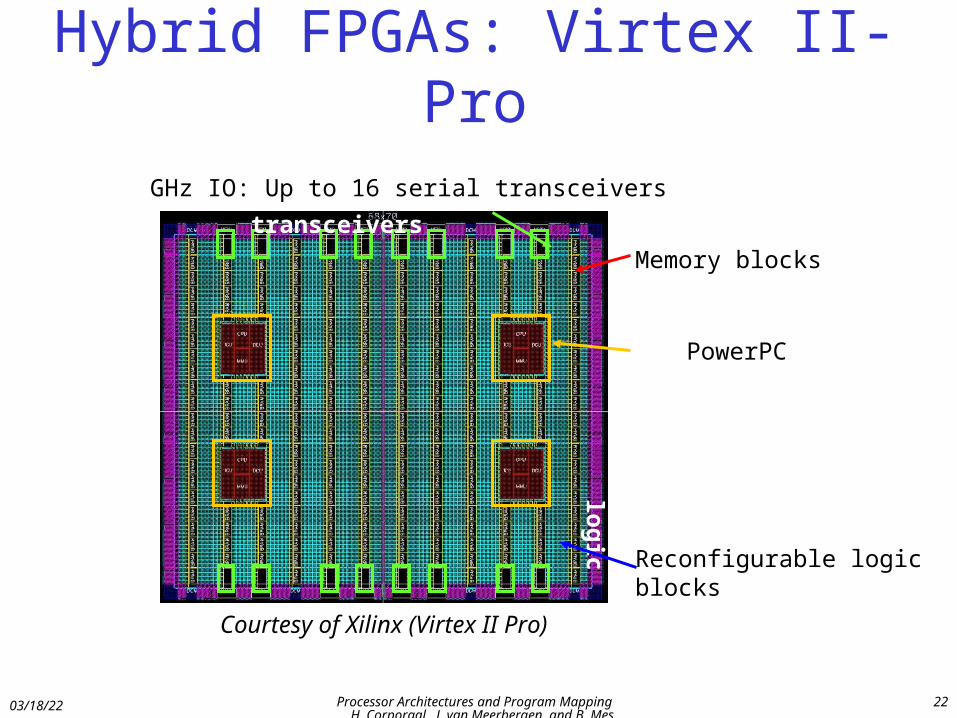
Hybrid FPGAs: Virtex II-Pro
ReConfig
.logic
Up to 16 serial transceivers
PowerP
Cs
Courtesy of Xilinx (Virtex II Pro)
PowerPC
Reconfigurable logicblocks
Memory blocks
GHz IO: Up to 16 serial transceivers
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
23
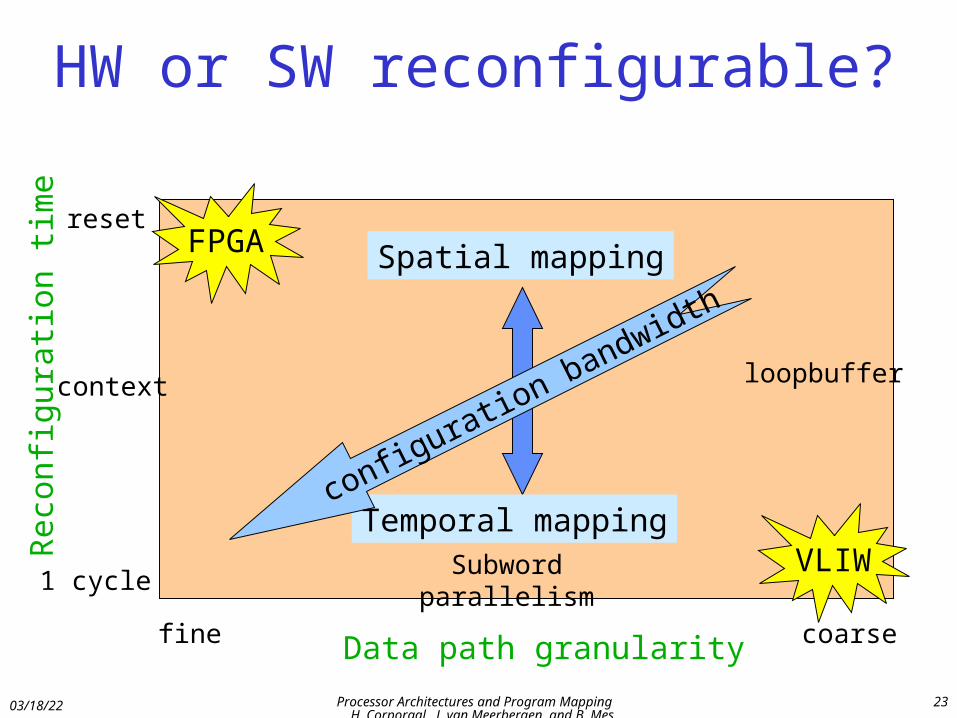
HW or SW reconfigurable?
Data path granularityfine coarse
Rec
onfi
gura
tion
tim
e
1 cycleSubword parallelism
loopbuffercontext
reset
Spatial mapping
Temporal mapping
FPGA
VLIW
configuration bandwidth
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
24
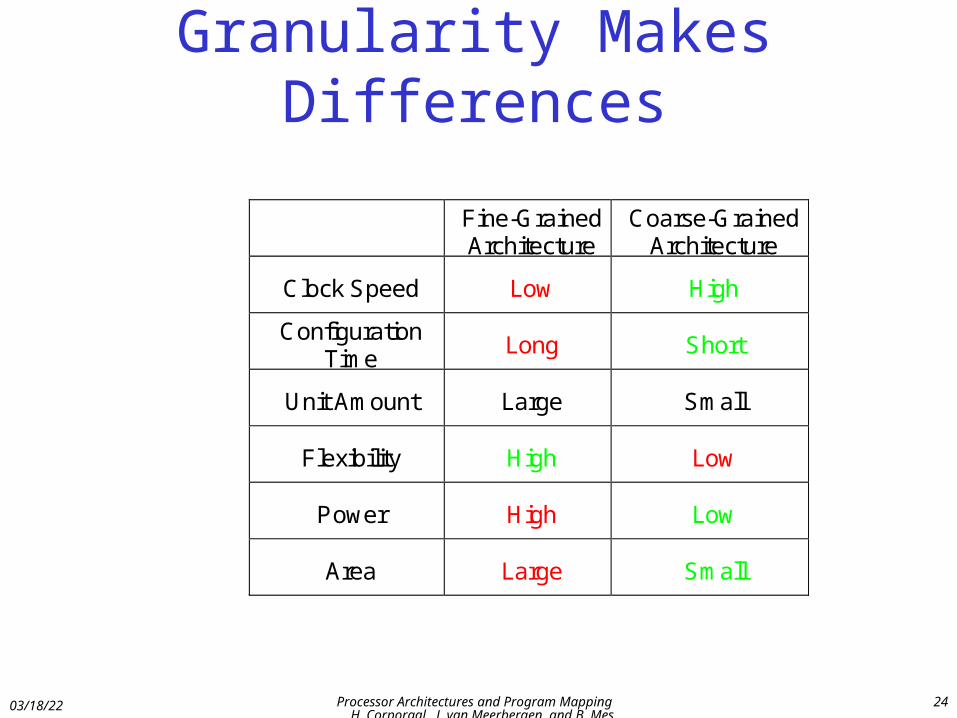
Granularity Makes Differences
Fine-Grained Architecture
Coarse-Grained Architecture
Clock Speed Low High
Configuration Time
Long Short
Unit Amount Large Small
Flexibility High Low
Power High Low
Area Large Small
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
25
Overview• Enhance performance: architecture methods• Instruction Level Parallelism• VLIW• Examples
– C6
– TM
– TTA
• Clustering and Reconfigurable components• Code generation• Hands-on

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
26
Compiler basics
• Overview– Compiler trajectory / structure / passes– Control Flow Graph (CFG)– Mapping and Scheduling– Basic block list scheduling– Extended scheduling scope– Loop scheduling– Loop transformations
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
27
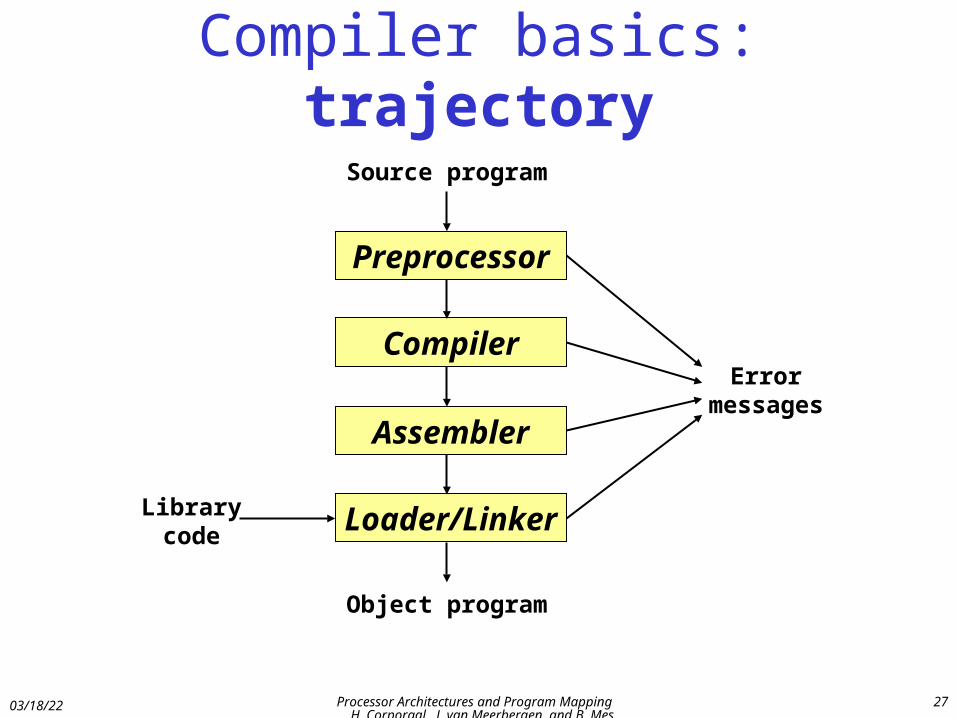
Compiler basics: trajectory
Preprocessor
Compiler
Assembler
Loader/Linker
Source program
Object program
Error messages
Library code
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
28
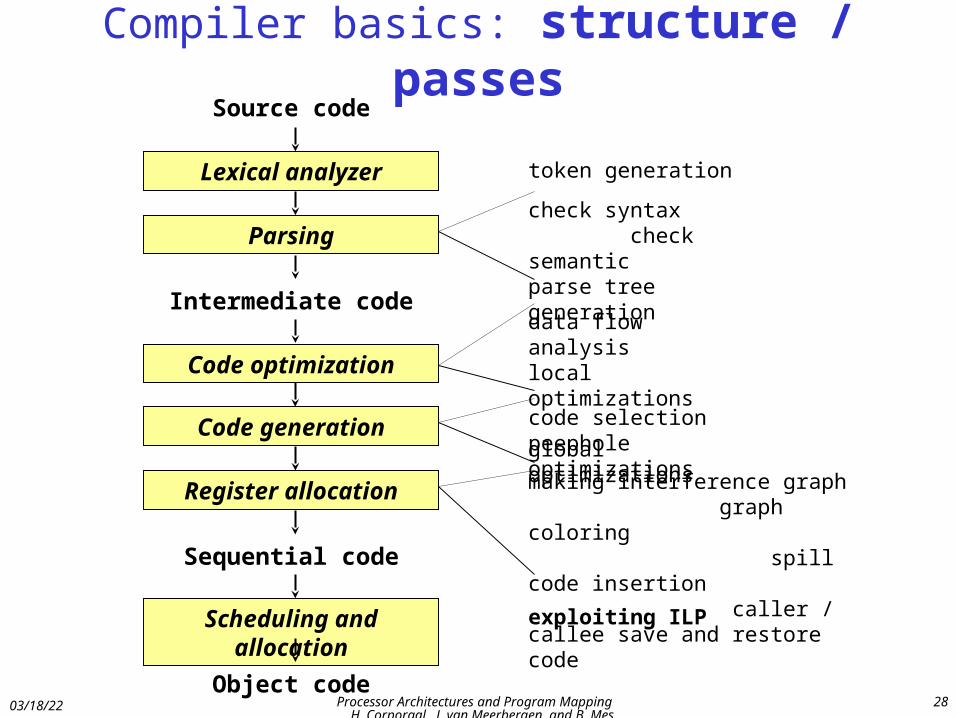
Compiler basics: structure / passes
Lexical analyzer
Parsing
Code optimization
Register allocation
Source code
Sequential code
Intermediate code
Code generation
Scheduling and allocation
Object code
token generation
check syntax check semantic parse tree generation
data flow analysis local optimizations global optimizationscode selection peephole optimizations
making interference graph graph coloring spill code insertion caller / callee save and restore code
exploiting ILP

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
29
Compiler basics: structure Simple compilation example
Lexical analyzer
Syntax analyzer
Intermediate code generator
position := initial + rate * 60
id := id + id * 60
:=
+id
*id
60id
Code optimizer
Code generator
temp1 := intoreal(60)temp2 := id3 * temp1temp3 := id2 + temp2id1 := temp3
temp1 := id3 * 60.0id1 := id2 + temp1
movf id3, r2mulf #60, r2, r2movf id2, r1addf r2, r1movf r1, id1
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
30
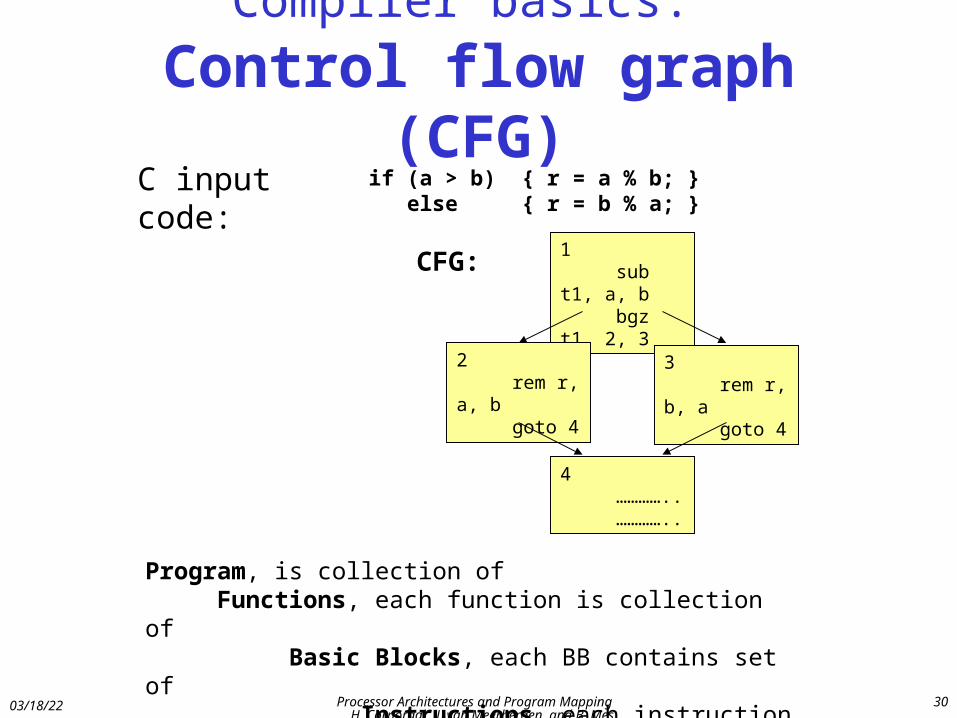
Compiler basics: Control flow graph (CFG)
C input code:
CFG: 1 sub t1, a, b bgz t1, 2, 3
4 ………….. …………..
3 rem r, b, a goto 4
2 rem r, a, b goto 4
Program, is collection of Functions, each function is collection of Basic Blocks, each BB contains set of Instructions, each instruction consists of several Transports,..
if (a > b) { r = a % b; } else { r = b % a; }

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
31
• Machine independent optimizations
• Machine dependent optimizations
Compiler basics: Basic optimizations

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
32
• Machine independent optimizations– Common subexpression elimination
– Constant folding
– Copy propagation
– Dead-code elimination
– Induction variable elimination
– Strength reduction
– Algebraic identities• Commutative expressions
• Associativity: Tree height reduction– Note: not always allowed(due to limited precision)
Compiler basics: Basic optimizations

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
33
• Machine dependent optimization example
What’s the optimal implementation of a*34 ?
– Use multiplier: mul Tb, Ta, 34• Pro: No thinking required
• Con: May take many cycles
– Alternative:SHL Tc, Ta, 1ADD Tb, Tc, TzeroSHL Tc, Tc, 4ADD Tb, Tb, Tc
• Pros: May take fewer cycles• Cons:• Uses more registers• Additional instructions ( I-cache load / code size)
Compiler basics: Basic optimizations

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
34
• Register Organization Conventions needed for parameter passing and register usage across function calls
Compiler basics: Register allocation
r31
r21
r20
r11
r10
r1
r0
Callee saved registers
Caller saved registers
Argument and result transfer
Hard-wired 0
Temporaries

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
35
Register allocation using graph coloring
Given a set of registers, what is the most efficient mapping of registers to program variables in terms of execution time of the program?
• A variable is defined at a point in program when a value is assigned to it.
• A variable is used at a point in a program when its value is referenced in an expression.
• The live range of a variable is the execution range between definitions and uses of a variable.

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
36
Program:
a := c := b := := bd := := a := c := d
a b c dLive Ranges
Register allocation using graph coloring
Example:
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
37
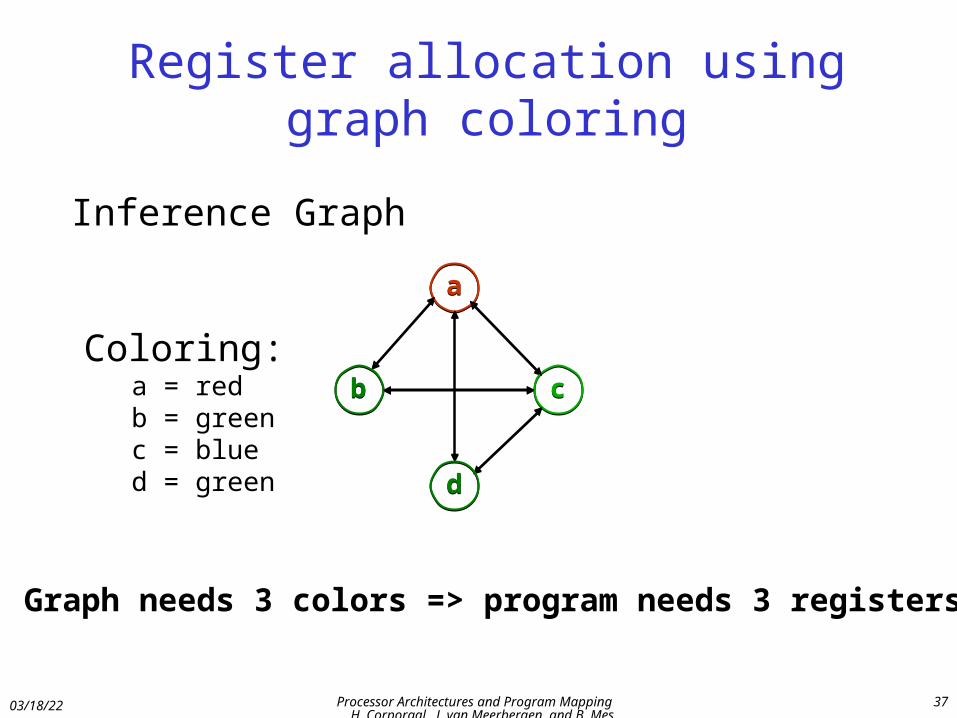
Register allocation using graph coloring
a
b c
d
Inference Graph
a
b c
d
Coloring:a = redb = greenc = blued = green
Graph needs 3 colors => program needs 3 registers

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
38
Register allocation using graph coloringSpill/ Reload code Spill/ Reload code is needed when there are not enough colors (registers) to color the interference graph
Example: Only two registers available !!
Program:
a := c := store cb := := bd := := aload c := c := d
a b c dLive Ranges

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
39
Register allocation for a monolithic RF
Scheme of the optimistic register allocator
Renumber Build Spill costs Simplify Select
Spill code
The Select phase selects a color (= machine register) for a variable that minimizes the heuristic:
h1 = fdep(col, var) + caller_callee(col, var)
where: fdep(col, var) : a measure for the introduction of false dependencies caller_callee(col, var) : cost for mapping var on a caller or callee saved register

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
40
• CISC era– Code size important– Determine shortest sequence of code
• Many options may exist
– Pattern matchingExample M68029:
D1 := D1 + M[ M[10+A1] + 16*D2 + 20 ] ADD ([10,A1], D2*16, 20) D1
• RISC era– Performance important– Only few possible code sequences– New implementations of old architectures optimize RISC part of
instruction set only; for e.g. i486 / Pentium / M68020
Compiler basics: Code selection
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
41
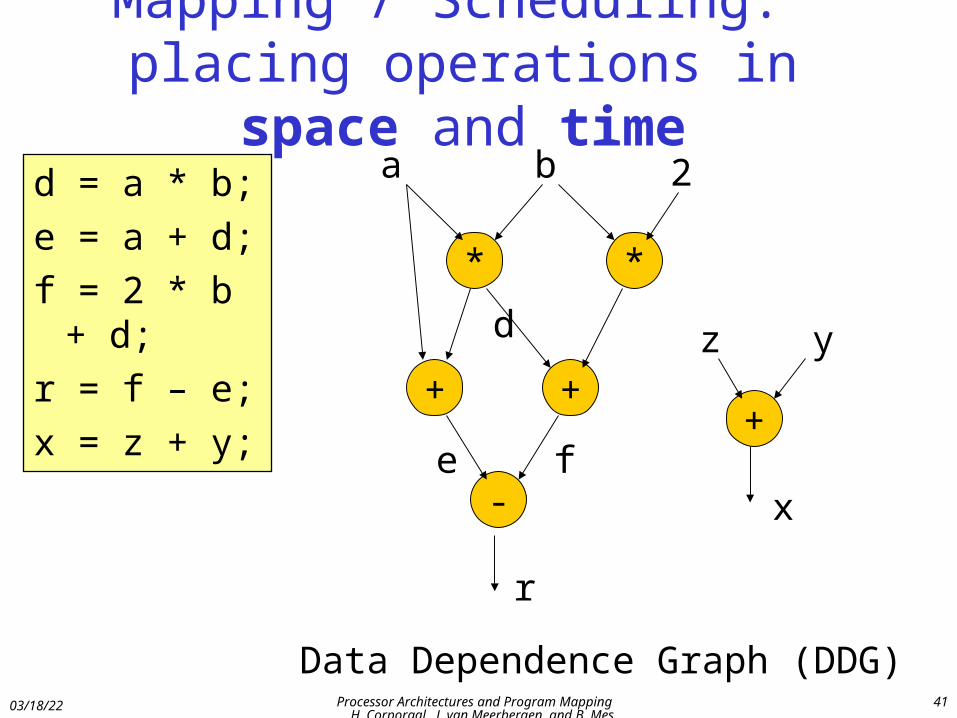
Mapping / Scheduling: placing operations in space and time
d = a * b;
e = a + d;
f = 2 * b + d;
r = f – e;
x = z + y;
* *
+ +
-
+
a b 2
z yd
e f
r
x
Data Dependence Graph (DDG)

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
42
How to map these operations?
* *
+ +
-+
a b 2
z y
d
e f
rx
Architecture constraints:• One Function Unit• All operations single cycle latency
*
*
+
+
-
+
cycle 1
2
3
4
5
6
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
43
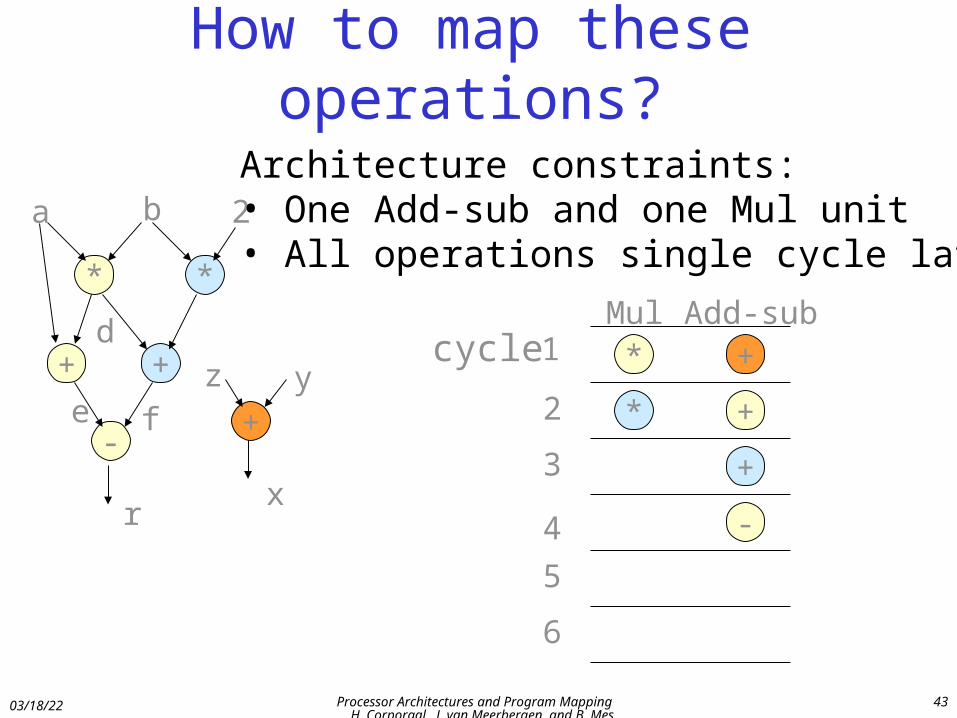
How to map these operations?
* *
+ +
-+
a b 2
z y
d
e f
rx
Architecture constraints:• One Add-sub and one Mul unit• All operations single cycle latency
*
* +
+
-
+cycle 1
2
3
4
5
6
Mul Add-sub
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
44
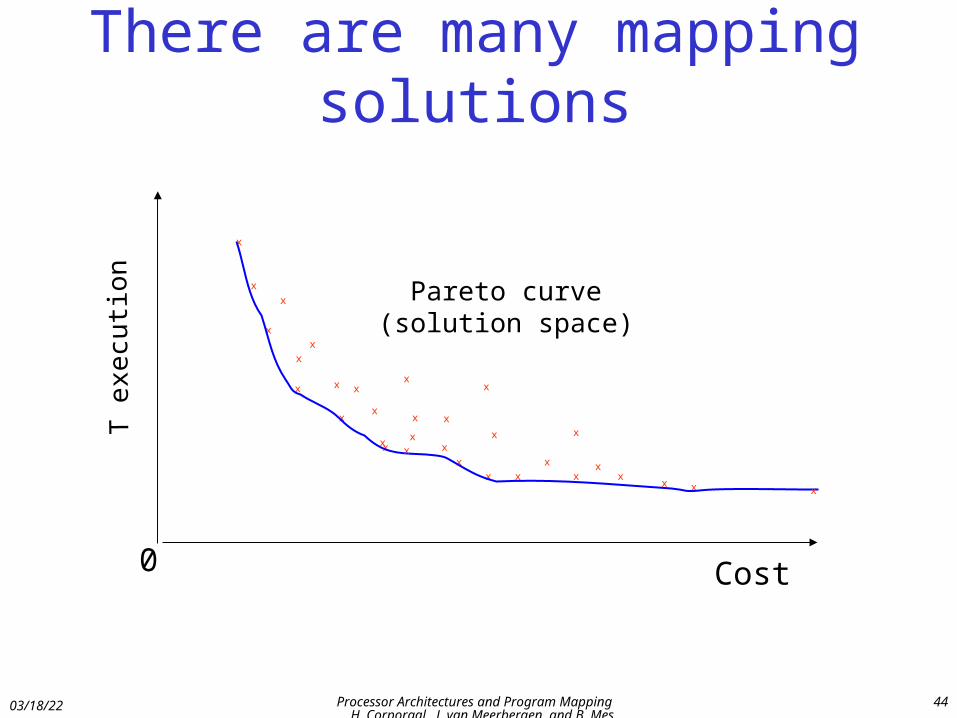
There are many mapping solutions
Pareto curve(solution space)
T e
xecu
tion
x
x
x
x
xx
x
xx
x
x
x
x
x
x
xxx
x
x
xx
x
x
x
x
x
xx
x
xx
Cost0

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
45
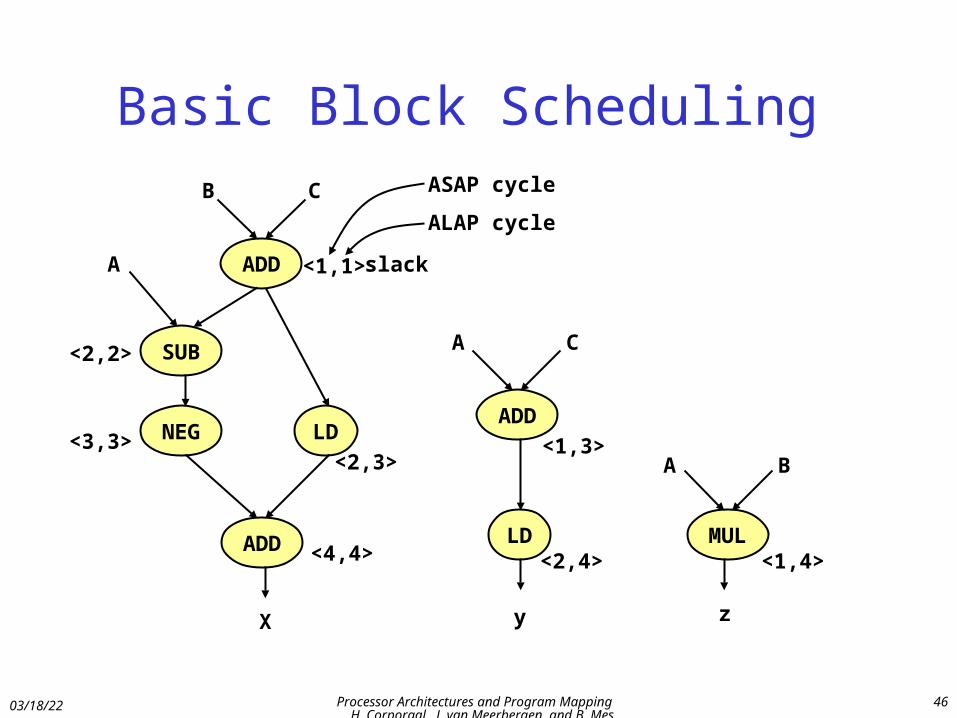
Basic Block Scheduling
• Make a dependence graph
• Determine minimal length
• Determine ASAP, ALAP, and slack of each operation
• Place each operation in first cycle with sufficient resources
Note:– Scheduling order sequential
– Priority determined by used heuristic; e.g. slack
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
46
Basic Block Scheduling
ADD
LD
A C
y
<1,3>
<2,4>MUL
A B
z
<1,4>
ADD
ADD
SUB
NEG LD
A
B C
X
<3,3>
<4,4>
<2,2>
<2,3>
<1,1>
ASAP cycle
ALAP cycle
slack

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
47
Cycle based list schedulingproc Schedule(DDG = (V,E))beginproc ready = { v | (u,v) E } ready’ = ready sched = current_cycle = 0 while sched V do for each v ready’ do if ResourceConfl(v,current_cycle, sched) then cycle(v) = current_cycle sched = sched {v} endif endfor current_cycle = current_cycle + 1 ready = { v | v sched (u,v) E, u sched } ready’ = { v | v ready (u,v) E, cycle(u) + delay(u,v) current_cycle} endwhileendproc

















