Practice retrieving data and running stand alone BLAST. Step 1. Identify genes in the ABA biosynthesis pathway from the Arabidopsis Cyc database http://www.arabidopsis.org/biocyc/index.jsp Step 2. Identify subject database Vitis vinifera (nucleotide) Solanum pennellii (EST). - PowerPoint PPT Presentation
Practice retrieving data and running stand alone BLAST. Step 1. Identify genes in the ABA biosynthesis pathway from the Arabidopsis Cyc database http://www.arabidopsis.org/biocyc/index.jsp Step 2. Identify subject database Vitis vinifera (nucleotide) Solanum pennellii (EST)
Transcript
Practice retrieving data and running stand alone BLAST.
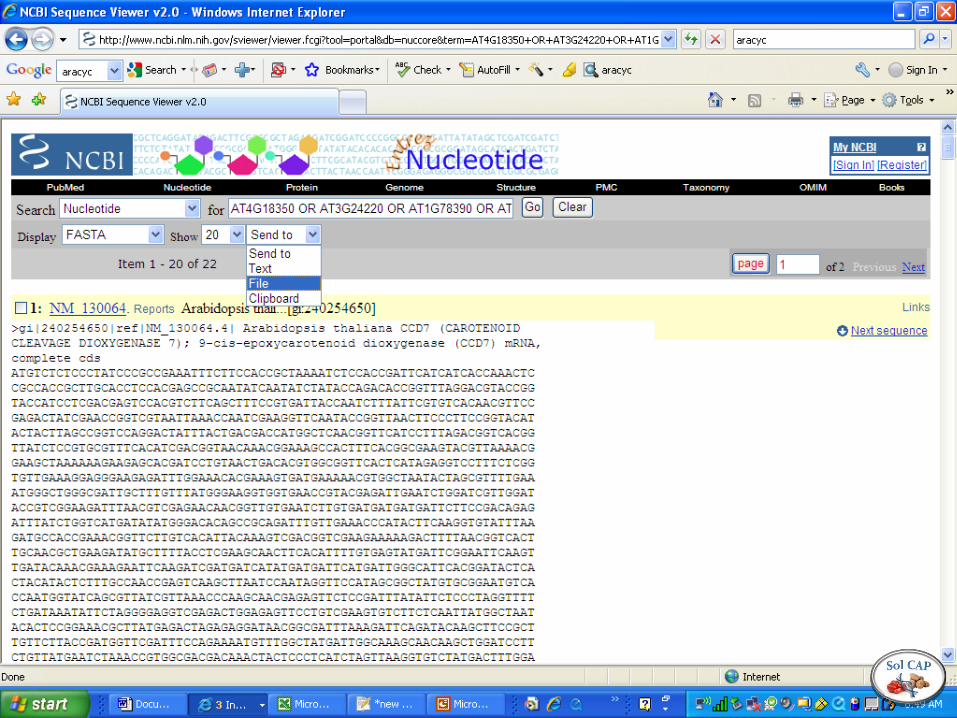
Step 1. Identify genes in the ABA biosynthesis pathway from the Arabidopsis Cyc database
Filter for unique sequences (EXCEL: Data, Filter, Advanced Filter…)
Notepad ++ EDIT, LINE OPPERATIONS, JOIN LINES SEARCH, REPLACE, “space” with “spaceORsapce” Paste into ENTREZ Nucleotide search…
PERL
chomp;next if /^\s/; #(skip if there is a space in start of the line)next if /^Gene/; #(if line starts with “gene”, skip)my @temp = split /\t/; #(data set is tab delimited)$hash{$temp[0]} = 1; #(unique sequence i.d. #0 is first element of the array)
Then invoke BioPerl to query NCBI with the search string: TAIR:AT### AND “complete cds”
Where AT### are the unique accession numbers from AraCyc and “complete cds” eliminates genomic sequence (e.g. complete Ath chrom 4)
See complete script on class site….
Do we want this much sequence?
Use the push pin to highlight all boxes for mRNA (22 sequences) so we don’t get chromosome 4 genomic sequences
Try: Use Unix to verify that the file contains all the sequences…
Q: What command would you use?
A: $ grep –c “>” filename
(lycopersicum [ORGN] AND EST) AND "Solanum pennellii"[porgn:__txid28526]
Try: Use Unix to verify that the file contains all the sequences…
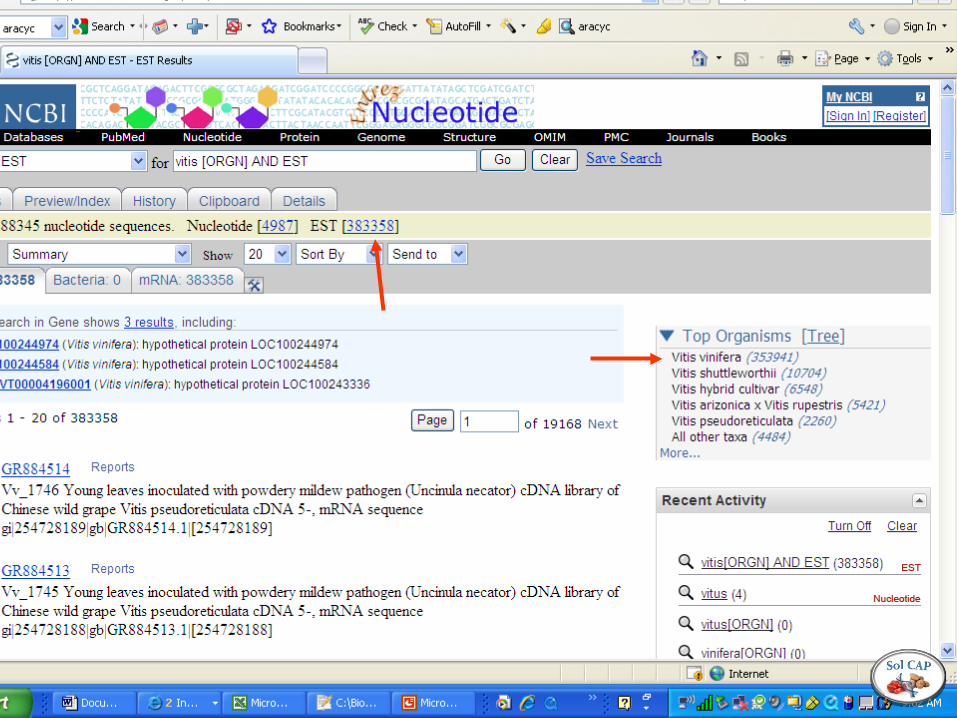
Vitis [ORGN] AND ESTNucleotide
Note syntax of ENTREZ search invoked by organism tree link
For class, I recommend downloading the smaller Nucleotide data set…
Try: Use Unix to verify that the file contains all the sequences…
Now what?
Which file needs to be formatted for BLAST (formatdb)?
Which file will be the query file?
What is the syntax for the BLAST (including PATH)?