17
cting Sequential Rati Elicited from Humans Aviv Zohar & Eran Marom
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 0 times |

Predicting Sequential Rating Predicting Sequential Rating
Elicited from Humans Elicited from Humans
Aviv Zohar & Eran Marom

2
MotivationRecommender systems base
recommendations on information collected from users
Humans are not consistent when rating itemsFraming problem (scaling)Relative ratings, not absoluteShort memory
Most recommender systems usually ignore the sequential aspect of the rating process
We wanted to find out if we can use this information to better predict unseen future ratings

3
Collected Data12 quotes of different qualities were
chosenEach user rates all quotes in a random
orderQuotes are easy and quick to rankA total of 500 people completed the surveyBinned the ratings to 5 values
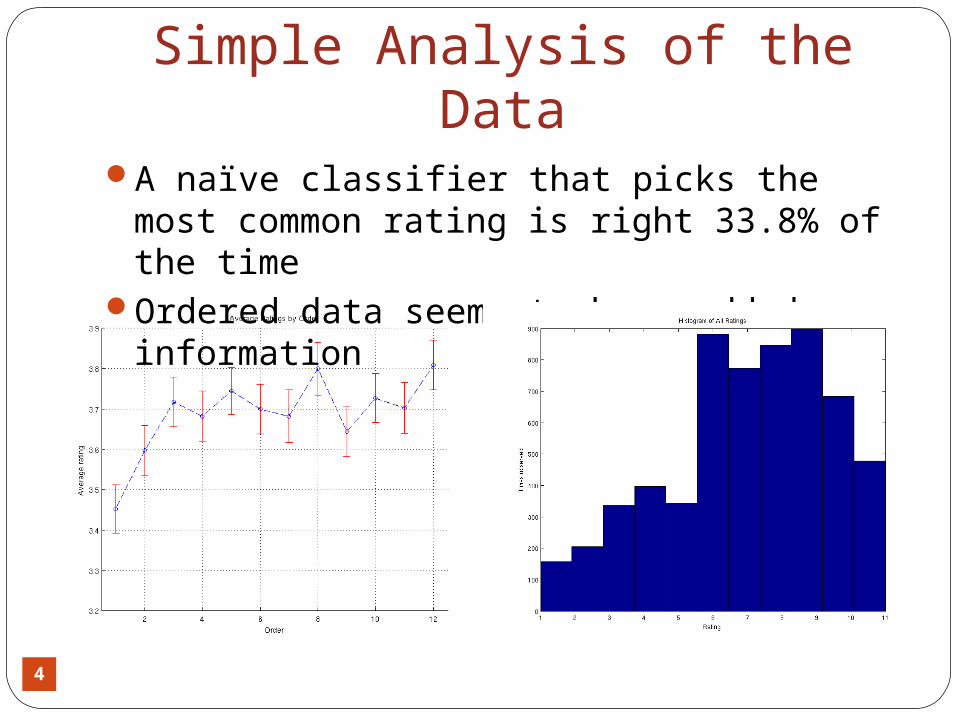
4
Simple Analysis of the DataA naïve classifier that picks the most
common rating is right 33.8% of the time Ordered data seems to have added
information

5
The Graphical Model
q
r
t
Quote type/quality(unknown)
Quote rating
Person type(unknown)
q1 q2 q3
t1
r11 r2
1 r31 r4
1
q4
t2
r12 r2
2 r32 r4
2
jikj
ji
ji qtrr
,,,Pr 1
kqPr
jtPr
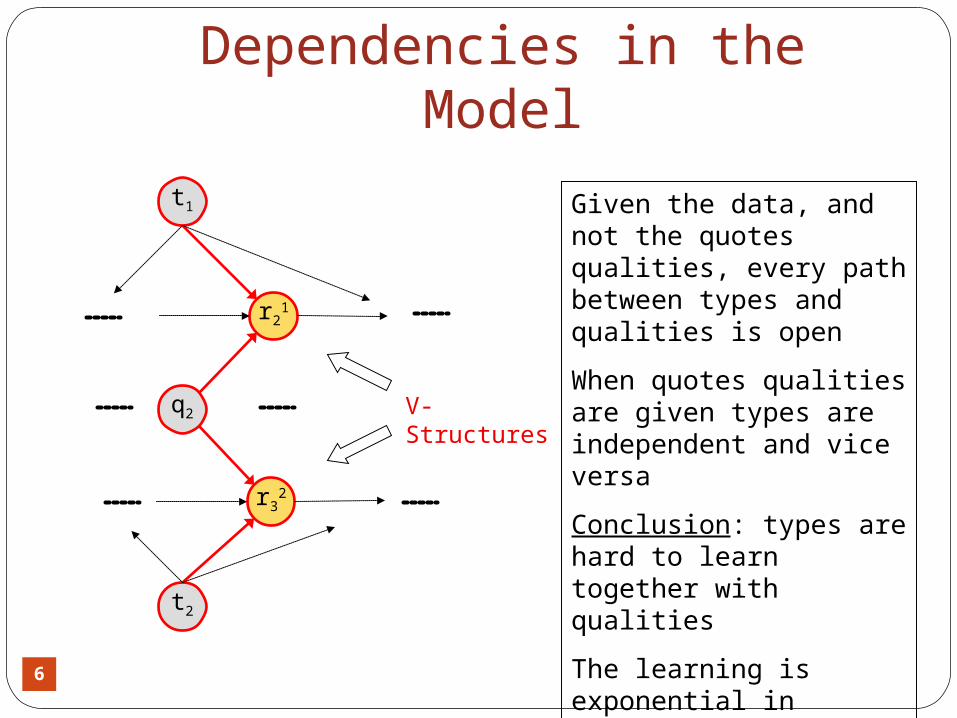
6
Dependencies in the Model
V-Structuresq2
t1
r21
t2
r32
Given the data, and not the quotes qualities, every path between types and qualities is open
When quotes qualities are given types are independent and vice versa
Conclusion: types are hard to learn together with qualities
The learning is exponential in min(NPeople,NQuotes)

7
Likelihood of the Data
quotes
k
people rankings
ji
people N
k q
N
j
N
ijikj
ji
jik
N
jj kkqtrrqt
DataLikelihood
1 1 1,1
1
,,,PrPrPr
Pr
,
peoplepeople
people
Nm
NNm rrtrrtData 1
1111 ,,,,
qtrr
q
t
prev ,,Pr
Pr
Pr

8
EM - Learning Parameters(known types)
Expectation
Maximization
quotes people
kk
quotes
quotes
N
k
N
jkj
ji
jik
k
N
kk
N
qtrrqz
Dataq
Dataqq
1 11
1
1
,,,PrPr1
,Pr
,Pr
quotes
k
kk
kk
N
k
nk
quotes
n
kjji
kjji
ji
kjji
ji
n
DataqqN
q
qtr
qtrrqtrr
1
1
1
11
1
,Pr1
Pr
,,#
,,,#,,Pr

9
Selecting Strict People Types Cleverly
Using additional information on usersClustering using ratings

10
How to Predict the Next Rating
q1 q2 q3
?
r1 r2 ? ?
q4
We want to predict this
Unknown, can be estimated from previous ratings
We have a prior from past data

11
How to Predict the Next Rating
Use the previous ratings by the user to estimate the user type, and then predict the following rating
1
1111
Stepn Expectatio theFrom
11111
,Pr,,,PrPr1
,Pr
,Pr,Pr,,,Pr,,Pr
i
k qkkkki
t qiiiiiii
k
i
Dataqqtrrtz
rrt
DataqrrtqtrrDatarrr
,,Prmaxarg 11 Datarrrprediction iir
ii

12
ExperimentsLearning Process:
Initialized with random, almost uniform, priors
Final network selected by max likelihood from 100 EM runs
Score: percentage of correct predictions5-fold cross validation was used

13
Results for Learning with Strictly Selected People
TypesTo check if the order information helps us
with prediction, tests were repeated with scrambled order
Only a slight difference was foundTrue order – 37.98%Permuted order – 37.40%
The type of each person is better estimated with each new rating given –so we’ll make less mistakes over time

14
Adaptively Assigning People Types
Multi-phase EMAlternating between optimal selection of
types and optimal selection of parameters

15
Results for Learning with Dynamic Adaptation of
People TypesAverage score is still 0.5% better for the
ordered runCould not see improvements in predictions
compared to constant people types deduced from k-means
General rise in score with progress of ratings is seen, though other underlying aspects of the data have effect
PermutatedOrdered

16
Numerical Problems when Increasing the Data Size
Insufficient data for learning the parameter space11 rating values, 3 quote types, 2 person
typesNumber of parameters to learn:
1112323795Number of predictions from 500 people:
500126000Precision problems
Alas, using more than 400 people implies such small probabilities that we have to use infinite precision tools

17
Conclusions and Possible Extensions
A significant improvement is already gained by very naïve predictors, but still we can do better
Adding order dependencies improves predictions only slightly
Multi-phase learning could be done using strict quotes qualities while using types probabilities for each person
Model can be extended to encompass more aspects of sequential information
More data may yield better resultsAlgorithms ran fast – system is scalable
to larger data sets

















