25
Predicting Unix Commands With Decision Tables and Decision Trees Kathleen Durant Third International Conference on Data Mining Methods and Databases September 25, 2002 Bologna, Italy
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 213 times |
| Download: | 0 times |

Predicting Unix Commands With Decision Tables and Decision Trees
Kathleen DurantThird International Conference on
Data Mining Methods and Databases
September 25, 2002Bologna, Italy

How Predictable Are a User’s Computer Interactions?
Command sequences The time of day The type of computer your using Clusters of command sequences Command typos

Characteristics of the Problem Time sequenced problem with
dependent variables Not a standard classification
problem Predicting a nominal value rather
than a Boolean value Concept shift

Dataset
Davison and Hirsh – Rutgers university Collected history sessions of 77
different users for 2 – 6 months Three categories of users: professor,
graduate, undergraduate Average number of commands per
sessions: 2184 Average number of distinct commands
per session : 77

Rutgers Study
5 different algorithms implemented C4.5 a decision-tree learner An omniscient predictor The most recent command just issued The most frequently used command of the
training set The longest matching prefix to the current
command Most successful – C4.5
Predictive accuracy 38%

Typical History Session
96100720:13:31 green-486 vs100 BLANK96100720:13:31 green-486 vs100 vi96100720:13:31 green-486 vs100 ls96100720:13:47 green-486 vs100 lpr96100720:13:57 green-486 vs100 vi96100720:14:10 green-486 vs100 make96100720:14:33 green-486 vs100 vis96100720:14:46 green-486 vs100 vi

WEKA System
Provides Learning algorithms Simple format for importing data –
ARFF format Graphical user interface

History Session in ARFF Format@relation user10@attribute ct-2 {BLANK,vi,ls,lpr,make,vis}@attribute ct-1 {BLANK,vi,ls,lpr,make,vis}@attribute ct0 {vi,ls,lpr,make,vis}@data BLANK,vi,lsvi, ls, lprls,lpr, makelpr, make, vismake, vis, vi

Learning Techniques
Decision tree using 2 previous commands as attributes Minimize size of the tree Maximize information gain
Boosted decision trees - AdaBoost Decision table
Match determined by k nearest neighbors Verification by 10-fold cross validation Verification by splitting data into training/test sets
Match determined by majority
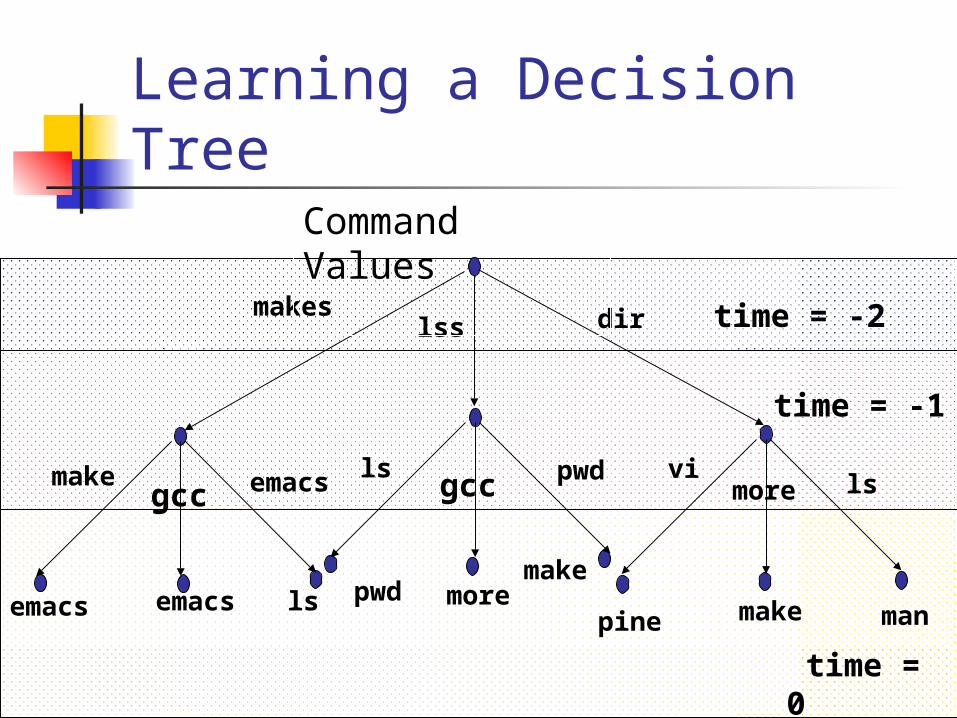
emacs
time = 0
emacs ls pwd moremake
makepine man
lsemacs pwdgcc lsmorevimake
gcc
time = -1
Learning a Decision Tree
time = -2lssmakes dir
Command Values

Boosting a Decision Tree
Decision Tree
Solution Set

Example
Learning a Decision Table
K - Nearest Neighbors (IBk)

Prediction Metrics
Macro-average – average predictive accuracy per person What was the average predictive
accuracy for the users in the study ? Micro-average – average predictive
accuracy for the commands in the study What percentage of the commands in
the study did we predict correctly?

Macro-average Results
35
36
37
38
39
40
41
42
43
44
45
Ibk Decision Table
Majority Match Decision TablePercentage SplitDecision TableDecision Trees
Boosted DecisionTrees

Micro-average Results
35
36
37
38
39
40
41
42
43
44
45
Ibk Decision Table
Majority Match Decision TablePercentage SplitDecision TableDecision Trees
Boosted DecisionTrees

Results: Decision Trees Decision trees – expected results
Compute-intensive algorithm Predictability results are similar to
simpler algorithms No interesting findings
Duplicated the Rutger’s study results

Results: AdaBoost AdaBoost – very disappointing
Unfortunately none or few boosting iterations performed
Only 12 decision trees were boosted Boosted trees predictability only increased by
2.4% on average Correctly predicted 115 more commands
than decision trees ( out of 118,409 wrongly predicted commands)
Very compute intensive and no substantial increase in predictability percentage

Results: Decision Tables Decision table – satisfactory results
good predictability results relatively speedy Validation is done incrementally Potential candidate for an online
system

Summary of Prediction Results
Ibk decision table produced the highest micro-average
Boosted decision trees produced the highest macro-average
Difference was negligible 1.37% - micro-average 2.21% - macro-average

Findings Ibk decision tables can be used in an
online system Not a compute-intensive algorithm Predictability is better or as good as
decision trees Consistent results achieved on fairly
small log sessions (> 100 commands) No improvement in prediction for larger
log sessions (> 1000 commands) due to concept shift

Summary of Benefits
Automatic typo correction Savings in keystrokes is on
average 30% Given an average command length is
3.77 characters Predicted command can be issued
with 1 keystroke

Questions

The algorithm.
Let Dt(i) denote the weight of example i in round t.
• Initialization: Assign each example (xi, yi) E the weight D1(i) := 1/n.
• For t = 1 to T:
• Call the weak learning algorithm with example set E and weight s given by Dt.
• Get a weak hypothesis ht : X .
• Update the weights of all examples.
• Output the final hypothesis, generated from the hypotheses of rounds 1 to T.
AdaBoost Description
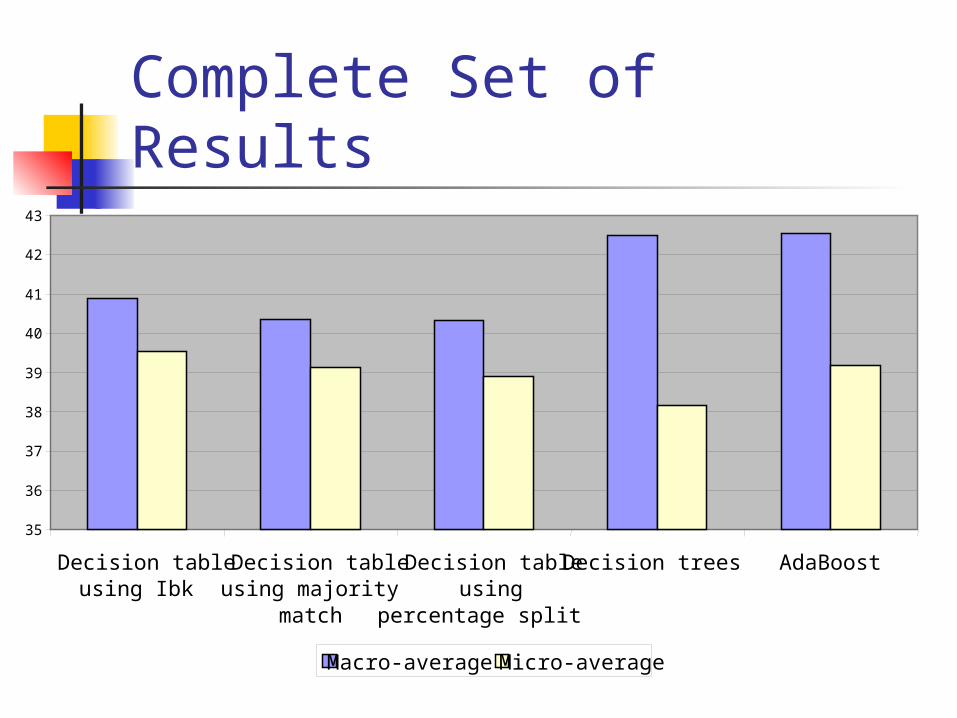
Complete Set of Results
35
36
37
38
39
40
41
42
43
Decision tableusing Ibk
Decision tableusing majority
match
Decision tableusing
percentage split
Decision trees AdaBoost
Macro-average Micro-average

Learning a Decision Tree
Command at time = t-2
ls make
Command at t-1
make dir grep
dir …
grep
grep
ls pwd
Command at t-1 Command at t-1
emacs ls pwd
grep
grep
Predicted Commands time = t

















