Abstract Interaction in smart environments should beadapted to the users’ preferences, e.g., utilising modalitiesappropriate for the situation. While manual customisation ofa single application could be feasible, this approach wouldrequire too much user effort in the future, when a user inter-acts with numerous applications with different interfaces,such as e.g. a smart car, a smart fridge, a smart shopping assis-tant etc. Supporting user groups, jointly interacting with thesame application, poses additional challenges: humans tendto respect the preferences of their friends and family mem-bers, and thus the preferred interface settings may dependon all group members. This work proposes to decrease themanual customisation effort by addressing the cold-startadaptation problem, i.e., predicting interface preferences ofindividuals and groups for new (unseen) combinations ofapplications, tasks and devices, based on knowledge regard-ing preferences of other users. For predictions we suggestseveral reasoning strategies and employ a classifier selec-tion approach for automatically choosing the most appro-
E. Vildjiounaite (B) · V. Kyllönen · I. Niskanen · J. MäntyjärviVTT Technical Research Centre of Finland, Oulu, Finlande-mail: [email protected]
priate strategy for each interface feature in each new sit-uation. The proposed approach is suitable for cases wherelong interaction histories are not yet available, and it is notrestricted to similar interfaces and application domains, aswe demonstrate by experiments on predicting preferences ofindividuals and groups for three different application proto-types: recipe recommender, cooking assistant and car ser-vicing assistant. The results show that the proposed methodhandles the cold-start problem in various types of unseen sit-uations fairly well: it achieved an average prediction accuracyof 72 ± 1 %. Further studies on user acceptance of predic-tions with two different user communities have shown thatthis is a desirable feature for applications in smart environ-ments, even when predictions are not so accurate and whenusers do not perceive manual customisation as very time-consuming.
Keywords Smart applications · Interface adaptation ·Personalisation · Multi-user adaptation · Internet of things ·Cyber-physical systems
1 Introduction
Currently, people live in smart environments continuously,24/7. We move between smart homes, smart offices, smartcars, smart kitchens, smart shops etc. In these differentsmart environments individual users and user groups aresupported by numerous applications, running on personaldevices and on devices in the environment. The interactionwith these applications should be adapted to the situationand preferences of the user or user group at hand, to be mostcomfortable. Although the most comfortable interaction isnot necessarily the most efficient one, users’ convenience isessential for acceptance of smart applications.
123
322 J Multimodal User Interfaces (2013) 7:321–349
Due to the large number of applications in smart envi-ronments, manually customising the interfaces of all appli-cations would be impractical. Ideally, the interfaces shouldbe adapted automatically, before the interface is first used.Here, the so called cold-start adaptation problem arises—theproblem of predicting interface preferences for situations thathave not occurred so far. This article presents our approachtowards solving different variations of the cold-start adapta-tion problem for interaction with pervasive assistive applica-tions.
For predicting preferences of a target user (or group ofusers) for a target application and context, we use alreadyknown preferences of the target user (or members of the usergroup) for some other application or context (in this article,we will refer to these as initial application and context) andpreferences of other users and user groups for both, initialand target applications and context. The process of usingpreferences, acquired in some other context, for enhancingadaptation to the target context is called mediation of userpreferences [5].
1.1 Variants of the cold-start adaptation problem studied
In our study on mediation of user preferences we take intoaccount the following aspects of smart environments as input,i.e. as parameters to which we want to adapt the interaction:
Multiple applications Individuals and groups will use manydifferent applications. In our experiments we employ fourprototypes of ubiquitous computing applications: a reciperecommender application; a shopping assistant (helps to finddesired food products in a shop); a cooking assistant (pro-vides step-by-step cooking instructions for selected recipe);and a car servicing assistant (provides step-by-step instruc-tions for performing car servicing tasks—e.g., replacementof windscreen wipers). Here, we aim at predicting interac-tion preferences of a target user/user group for a new (unseen)application based on the preferences of the target user/usergroup for other applications—i.e., cross-application medi-ation of preferences. For example, we generate and evalu-ate predictions for preferences for interacting with the carassistance application based on the preferences for a reciperecommender application.
Multiple contexts Users prefer to interact with the sameapplications differently in different contexts. Here, we aimat cross-task mediation of preferences, i.e., prediction of pref-erences of a target user/user group for one task type, based onthe preferences of these users for another task type (thus thetype of task makes up the context). For example, we predictpreferences of a target user/user group for the cooking assis-tant application in the task of “cooking a known recipe” basedon their preferences for the “cooking a new recipe” task. Inour experiments we used several task contexts. In interac-
tion with the cooking guide and the car servicing assistantsthe task types are dealing with a new task vs. dealing with afamiliar task. For the recipe recommender the task types aresearching recipes for cooking and eating alone; for a familydinner; for a party with friends; for cooking in a rented cabinor for cooking near a campfire.
Multiple devices Another important aspect of context insmart environments is availability of various interactiondevices. The preferences depend on the features of thesedevices, e.g., users may prefer to see images on a large screen,but will prefer a text-only interface on a small screen. Here,we aim at cross-device mediation of preferences: predictinginterface settings for a target device, based on known prefer-ences for an initial device.
Multiple users Apart from adaptation to individuals, westudy adaptation to groups of persons, who use an appli-cation together. This is a rather common use case in smartenvironments, but often neglected in existing work. Here, weaim at predicting preferences in two different cases: first, wepredict preferences of a user group interacting with an appli-cation for the first time as a group, based on the preferencesof the group members for personal use of this application.For example, we predict group preferences for the car ser-vicing assistant, based on preferences of the group members,acquired when each person used the application alone. Sec-ond, we aim at predicting preferences of a target group thatuses a new application, not used by its members earlier (thuswe aim at cross-application mediation of group preferences,but we do not assume the target group consists of the samemembers as any of the groups in the initial context). Forexample, we predict group preferences for the car servicingassistant, based on known preferences of the group membersfor the recipe recommender.
In order to account for possibly limited computationalcapabilities of personal devices and smart products in smartenvironments we restrict the complexity of the preferencesthat we aim to predict. In the adaptation we aim at select-ing a value from a known set of options for each interfacefeature. Thereby, we consider an “interface feature” any dis-tinct aspect of interaction that can be described by a set ofoptions. In particular, we study the prediction of interfacepreferences for two types of adaptation problems: choos-ing a subset of items from some set (selecting top N items)and choosing a state of an interface feature from a set ofits possible states (e.g., deciding whether a message shouldbe ignored, displayed fairly unobtrusively or very visibly).For example, such input modality as sensor-based activityrecognition can be an interface feature with the options “on”and “off”. The goal is to predict which of these values thetarget user prefers for the target context and application.Features may also refer more to the interface content than
123
J Multimodal User Interfaces (2013) 7:321–349 323
the interface form. For example, the capability to deliverinformation on a certain topic (e.g., shop offers) may beanother feature. Here, the options could again be “on” and“off”, but the application could also support a more elab-orate model, e.g., specifying different levels of detail. Onevery relevant interface feature is the use of certain modalities.Users do not use all available output or input modalities at alltimes [12,48]. For example, in some situations sensor-basedactivity recognition may annoy users, even if its results arenot used by the application in any way [46]. Besides, dis-abling not-so-desirable input features may prolong batterylife in mobile phones and environmental sensors.
1.2 Contribution
The main contribution of this paper is a fairly lightweightapproach to adapt interaction in smart environments to usersand contexts by using customisation data of user communi-ties. The proposed approach is suitable for predicting inter-face preferences of individuals and groups for two commoncustomisation problems—selecting a subset of interface ele-ments from a larger set of possible options and choosing astate of an interface feature. The proposed method requiresneither domain knowledge (it is data-driven) nor large data-bases of user preferences, which cannot be easily collected inthis domain because it is not yet common to share customi-sation data between personal devices. Thus, users are morelikely to share such data only with acquaintances than withthe whole world.
The proposed method relies on several prediction strate-gies, modelling typical patterns of human behaviour in newsituations, and on choosing the most appropriate strategyfor each interface feature and each context transition (i.e.,change from initial to target context). For selecting the mostappropriate strategy we employ a machine learning approach,called classifier selection [23]: we compare accuracies of dif-ferent strategies on available data of user community and thenselect the most accurate strategy. We perform this selectionfor each feature separately because although preferences forsome interface features may be valid across many contexts,preferences for other features may strongly depend on thecontext.
The feasibility of the proposed approach is confirmed bythe experimental results on predicting preferences of indi-viduals and groups for various types of cold-start adaptationproblem, described above. To the best of our knowledge, weare the first who attempted at predicting individual and groupsettings for significantly different application interfaces anddomains (cooking and car servicing), employing a classifierselection approach for this purpose.
This paper is organised as follows: the next section dis-cusses related work. Sections 3 and 4 describe the userstudies, allowed to collect individual and group preferences
regarding different features of smart applications. Section 5describes the prediction methodology. Section 6 presentsoffline study on mediation of preferences. The results show,which prediction strategies suit better to which types of medi-ation problems (i.e., to which interface features and contexttransitions) and how classifier selection approach allows toincrease prediction accuracy. Section 7 describes two studieson user acceptance of predictions. The last section outlinesconclusions.
2 Related work
Increasing variety of smart applications and their usage con-texts requires, on the one hand, to make interaction context-adaptive. On the other hand, interfaces should adapt to theusers and provide consistent user experience with variousapplications. For example, a user who appreciates silenceshould not be annoyed by audio messages from applications,not dealing with his/her safety, whereas a person on a low-cholesterol diet should be able to see cholesterol amount infood products and recipes in all shopping and recipe rec-ommender applications he/she may use. Due to the consis-tency requirement, ways to generate interfaces for differentapplications in a fairly unified ways were proposed, as forexample in the work [32]. Interaction adaptation was studiedin many works, but rather in a form of context adaptationthan user adaptation, despite that fairly long ago publisheddesign guidelines put users at the first place, suggesting that“multimodal interfaces should adapt to the needs and abili-ties of different users, as well as different contexts of use”[36]. However, a fairly recent survey on multimodal inter-faces [12] still names personalisation in multimodal systemsas a potential capability to enhance human-computer inter-action, not as existing one, and does not list any tools forcreation of multimodal interfaces, supporting user adaption.
Most often interaction is adapted to features of the envi-ronment, such as available interface modalities and deviceproperties [15,26,28,30,33,44]. For example, the works [21]and [41] presented systems, allowing designers to specifyrules for adapting information presentation to contexts, andthe work [3] described a framework for adapting input modal-ities to contexts, but none of these works studied adaptation touser preferences. In case of interaction in the airplane cock-pit [41] personalisation may be hindered by safety require-ments, but the works [3,21] target pervasive environmentswhere users feel better if they can control the applications tosome extent [11,20].
One of the reasons for not giving end users means toinfluence adaptation may be a fear of users’ confusion dueto the limited knowledge regarding multimodal informationprocessing and presentation [42]. It may be indeed difficultfor end users to state their preferences in a fairly generic
123
324 J Multimodal User Interfaces (2013) 7:321–349
way, but we believe (and user studies, described below, con-firm our beliefs) that users would not be so easily confusedin cases when they customise an application at hand, espe-cially when they can experiment with customisation choicesand immediately examine adaptation results. This “try andsee” approach can be time-consuming, however, and thus weattempted at predicting users’ preferences for newly encoun-tered situations.
Our approach differs from earlier works in that we aimat providing users with a greater degree of control overinteraction with smart applications than is typically allowed.Our approach complements user-agnostic works on interfacedesign and context adaptation as it allows to refine adaptation.For example, studies regarding influence of environmentalcontext on users’ abilities to interact with mobile devicesvia various modalities [40] aimed at finding appropriate andinappropriate modalities for different contexts, whereas ourapproach may be employed for finding most appropriatemodalities for each user among the options, allowed for eachcontext. The predicted options may serve as an input to aninfrastructure for interface rendering, or directly map to inter-faces specifically designed for this combination of options.
2.1 Interface adaptation to users and user groups
To the best of our knowledge, the problem of predicting indi-vidual and group preferences in cases when initial and targetinterfaces and application domains may differ significantlywas not studied so far. First, the majority of related work con-siders only adaptation of interfaces to individuals, not groups.Second, it is not so common to allow users to choose differ-ent interaction settings for different contexts, although it wasshown that the users appreciate such possibility at least withrespect to menu customisation [8] and dialogs with digitalartefacts [37,48]. The work of Kong et al. [24] also confirmedthe feasibility of taking into account context-dependent per-sonal preferences: adaptation of a social networking applica-tion was evaluated in a user study with fifty participants. Inthis study the participants were first asked to assign numeri-cal preference scores to different modalities for several con-texts, and then the interface was optimised by taking intoaccount these scores, system capacities and quality of servicerequirements. However, although assigning numerical pref-erence scores to different options is more difficult than choos-ing one of the available options (as our approach requires),Kong et al. [24] did not attempt at predicting preferences fornew contexts. Similarly, Gil et al. [17] studied adaptation oflevels of obtrusiveness of interaction to the users’ profiles,but the profiles were created explicitly. The profiles could bealso updated according to the rules, provided by applicationdesigners, but rule definition was not described in the paper.It is worth noting, however, that designer-defined rules areusually less flexible than data-driven approaches.
We are aware of only one study on mediation of inter-face preferences [47], but only for applications with nearlyidentical interfaces. In this work several mediation strategieswere proposed and compared, but no “one-fits-all” media-tion problems strategy was suggested. In the current work wepropose to employ classifier selection approach for automat-ically selecting most appropriate strategy for each mediationproblem.
The majority of other works on adaptation of interfacesemploy either generic reasoning rules or machine learningmethods, utilising long histories of user behaviour [39]. Typ-ically, the adaptation in one context is based on the inter-action history for the same context. Adaptation to anotherscreen size was studied in the work [16], but in their sys-tem, called SUPPLE, long-term interaction history was usedin adaptation. SUPPLE allows also manual interface cus-tomisation, but assumes that manually provided preferencesfor one context are valid in all other contexts as well. InSUPPLE this assumption was tested only for individuals andfor fairly similar tasks (controlling light intensity, ventila-tor and audio-visual equipment in a classroom), whereas theresults from [47] show that it is not feasible to use straight-forwardly customisation data, acquired in one context, forinterface adaptation to a significantly different context.
Cross-context mediation of user preferences was not exten-sively studied in other domains either. The problem emergedin the domain of recommender systems, but it is relativelyrecent, so that surveys on recommender systems do notspecifically address it [25,27,34]. Currently, the majority ofwork on mediation of preferences is concerned with han-dling semantic heterogeneity of preferences’ descriptions(i.e., in different systems the same types of preferencesmay be described in different terms) and resolving conflictsbetween preferences on the same issue, retrieved from differ-ent systems [9]. Only few works studied whether preferences,acquired in different contexts, indeed enhance adaptation toa target context. Berkovsky et al. [5] suggested to apply col-laborative filtering for mediating ranks, acquired by differ-ent recommender systems, and proposed several mediationstrategies: (1) to use ratings from different contexts as if theybelong to the same context; (2) to compute user similarity ina way reflecting correlations between contexts; (3) to gener-ate recommendations in all contexts independently, and thento combine their ranks in a context-dependent way. The pro-posed strategies were evaluated by mediating movie ranksin movie recommender systems. Anand and Bharadwaj [2]also studied how to use ratings, acquired by one collabora-tive filtering-based movie recommender system, in anothersystem, and proposed to learn user similarity measures foreach dataset of movie ratings with genetic algorithm.
123
J Multimodal User Interfaces (2013) 7:321–349 325
Baltrunas et al. [4] studied context-dependency of pref-erences in tourist guides for a variety of context types,such as weather, company, available time and budget, travelgoal, prior knowledge about the area etc. Preferences fordifferent categories of attractions were acquired by askingusers to imagine themselves in a certain context. Data analy-sis revealed that some context types (such as available time,crowdedness and knowledge of the surroundings) influenceratings of all categories of attractions, whereas influence ofsome other context types depends on a category. After thatBaltrunas et al. suggested a fairly simple model to predictpersonal preferences in a new (for this person) context: influ-ence of each context type was modelled as positive or nega-tive shift, learned from the training data of other users whoalready ranked tourist attractions in this context.
However, unlike our work, the above-listed works studiedmediation in initial and target applications of the same kind.Our aim is to find a method, capable of mediating user pref-erences both across fairly similar contexts/applications andacross significantly different ones. The probability that users,similar in one context, would remain similar in very differ-ent context too, is much lower. Thus, collaborative filtering isnot guaranteed to work for mediation across significantly dif-ferent contexts. Other differences between our work and theworks [2,5] is that both works studied mediation of individ-ual preferences in cases when fairly large datasets of movieratings were available, while we aim at predicting both indi-vidual and group preferences and to use fairly small datasetsin predictions.
The work of Blanco-Fernandez et al. [7] studied media-tion of individual preferences in less similar domains thanthe two above-listed works: TV viewing histories served asinitial domain, and the target domain was recommendationof tourist attractions. First fairly generic user interests (suchas interest in animals or water sports) were inferred from TVviewing histories, and then tourist attractions, belonging tothe same categories (e.g., zoo for animals’ lovers and div-ing for water sport funs) were recommended. Thus the work[7] largely relied on the assumption that generic user interestsare context-independent, whereas our approach does not relyon any assumptions regarding context-dependency or inde-pendency of preferences. Another difference between ourapproach and the work [7] is that in the work [7] neighboursfor collaborative filtering were found in both initial and tar-get domains. This is impossible in the cold-start adaptationproblem because preferences of the target user for the targetcontext are unknown.
2.3 Adaptation to groups
Prediction of group preferences was mainly studied in thedomain of recommender systems for movies, tourist attrac-
tions and TV programmes, e.g., in the works [22,29,43,50].Typically, group preferences are inferred from individualpreferences of group members in one of the following ways:(1) merging individual preferences into a joint profile andthen using this profile in ranking; (2) calculating individ-ual ranks for each group member and using them in deci-sion making. We did not test the former approach becausethe work [50] has shown that it does not succeed very wellin cases when individual preferences differ from each othersignificantly. For the latter approach several ways to com-bine individual preferences were proposed, e.g., to averageindividual ranks or to use preferences of one group memberwhile ignoring others [29,43]. We adopted this approach andselected strategies for combining individual ranks, suitablefor our application prototypes.
Additionally, for predicting preferences of a target groupin the target context we use knowledge regarding preferencesof other groups in the target context. This approach allowsfor cases when group choices differ from personal prefer-ences of all group members. This may happen, e.g., if groupis interested in other aspects of the application then individ-ual group members when they interact with the applicationalone. An example for this phenomenon can be found in thecooking domain: when a person cooks alone, she may beinterested in learning a new recipe and thus in strictly fol-lowing its instructions, whereas a group of friends, cookingtogether, may be more interested in chatting or in modify-ing a recipe. However, existing cooking assistive applicationsrarely take into account social aspects; especially the desiresto have fun together or to relax are neglected [18]. Similarly,although many works address the problem of recipe recom-mendation to groups, typically they study only adaptation ofrecipe selection, not adaptation of a recommender interface,as e.g., in the work [6].
Social science research into group behaviour suggestedthat there are four basic types of social relationships: commu-nal sharing, authority ranking, equality matching, and marketpricing [14]. Communal sharing relationships are based onthe conception that people are equivalent and undifferenti-ated. Thus being kind and altruistic is natural to this typeof relationship. Authority ranking relationships are based onordering people along some axis, for example, position (bossvs. subordinate), age, experience etc. Thus groups with thistype of relationship have a clear leader. Equality matchingrelationships are based on a model of even balance and tak-ing turns; for example, on agreements of the kind “I’ll cookif you clean afterwards”. In this type of relationship equal-ity is independent of needs or status of group members andof their efforts: cleaning may take longer time than cook-ing or vice versa. Market pricing relationships are based onmore fine-grain estimation of things, such as rates and pro-portions. For example, an agreement of the kind “I’ll cook ifyou clean afterwards” may not work if cooking takes longer
123
326 J Multimodal User Interfaces (2013) 7:321–349
than cleaning. Masthoff and Gatt [29] discussed how dif-ferent types of relationships between group members mayaffect their satisfaction with recommender systems, and pro-posed to model emotional contagion between group membersas a linear function of their individual satisfactions, whereweights depend on relationship type. The model feasibilitywas confirmed via acquisition of self-reports of group mem-bers; however, ways to estimate the model parameters fromthe group actions were not suggested.
Other works, considering influence of social factors ongroup choices, proposed learning methods, requiring signif-icantly larger datasets than could be available for address-ing the cold-start problem in user interface adaptation. Chenet al. [10] attempted at learning (with a genetic algorithm)the degrees of influence of group members on group rat-ings, based on ratings of group members and on ratings ofthe subgroups of the target group. Thus this approach is notcapable of predicting ratings of any group. Furthermore, itrequires fairly long-term system use for collecting ratings ofseveral subgroups. Due to the difficulty to acquire such data,Chen et al. did not do it themselves: the proposed methodwas tested on simulated data. The work of Vildjiounaite etal. [45] attempted learning of influence of family memberson choice of TV programmes in another, more latent way:presence of family members, along with other context data,served as input to CBR (Case-Based Reasoning) and SVM(Support Vector Machines) methods, utilising TV viewinghistory of this family. The proposed approach was tested onreal data of 20 families, but data collection during 2–4 weekswas required before recommendations could be provided,which is a fairly long time.
Importance of social factors was also demonstrated inthe domain of computer-supported learning. Analysis ofposts to forums in virtual classrooms shows that membersof small groups write posts, aimed at maintaining groupcoherence, nearly as frequently as posts regarding groupperformance [38]. Larger groups also get fairly frequentlyengaged in informal communications, such as sharing per-sonal life aspects or other interesting information [35]. Inone-to-one communications with computer tutors social fac-tors also play important role: various studies suggest thatcapability of a pedagogical agent to engage in off-task com-munications helps students to feel more comfortable or tomake stronger effort to understand learning material [19].However, it was also shown that some students prefer ped-agogical agents that do not attempt at off-task communica-tions [19], but we did not find works reporting experimentson predicting students’ preferences regarding tutors’ capa-bilities. Although it was shown that configuring interactionaccording to students’ preferences does not necessarily resultin increased performance [31], performance is not the onlyaspect to consider, especially in applications, providing assis-tance with tasks that are not obligatory to fulfil. Users tend to
ignore even obligatory security measures if they are inconve-nient [49]. Thus in the next sections we will propose methodsto make smart applications more convenient and capable ofrespecting social rules.
3 Overview of data acquisition
Interface preferences and opinions of the test subjects regard-ing feasibility of the proposed adaptation approach wereacquired during four user studies. The studies were per-formed with the following applications: first study—cookingand car assistants; second study: recipe recommender; thirdstudy: shopping assistant; fourth study: another version ofthe cooking assistant. During all studies we first asked thesubjects to tell us certain general information, e.g., occu-pation, age group, experience in cooking and car servicing,experience with computer aids. During the first three stud-ies we also interviewed the subjects regarding their diets andeating habits. Then we asked the subjects to fulfil the tasksand to fill in study-specific questionnaire. After that we inter-viewed the subjects in order to better understand reasons fortheir choices and answers.
User preferences, collected during the two first studies,were used for development and offline evaluation of pref-erence mediation mechanisms, aimed at addressing differ-ent variants of the cold-start problem, listed in the Introduc-tion. The third and the forth studies aimed at evaluating useracceptance of predictions. 21 subjects constituted the keyuser group, participated in the first three studies. In addition,friends and acquaintances of this key group participated in thesecond study. The majority of the subjects in this user com-munity were well acquainted with each other and had nothingagainst sharing their preferences with this community, butnot with the whole world. All subjects reported themselvesas more experienced in cooking than in car servicing, buttheir prior experience with computer aids in cooking, shop-ping and car servicing domains was limited to informationsearch in the web.
The last study took place in another country and with newsubjects. These persons also appeared to be fairly experi-enced in cooking (the majority reported that they cook almostevery day), but more diverse with respect to their use of com-puter aids: only 10 study participants said that they neverused computers or mobile phones as cooking aids prior tothis study.
Table 1 presents a brief description of the user groups, andFig. 1 shows where the second and the last studies took place.
All preferences, used in this work, were acquired when anindividual or a group was dealing with a target context forthe first time, for example, when a group was using an appli-cation together first time. Although user preferences maychange during long-term use, this dataset is suited well for
123
J Multimodal User Interfaces (2013) 7:321–349 327
Table 1 Test subjects,participated in the four userstudies
User groups Applications
Cook and car Recipe Shop Cook II
Community I
Key group
21 Subjects: 11 females, 10 males, distributedequally among age groups <30, 30–50 and >50years old. Occupation: biologists, accountants,businessmen, physicists, travel agent, musicians,SW developers, worker etc.
X X X
Extra subjects
23 Subjects: 10 females, 13 males, 9 persons <30,5 persons >50, 10 persons aged from 30 to 50 yearsold. Occupation: painter, teacher, worker, doctor,accountants, businessmen, SW developers etc.
X
Community II
24 Subjects: 17 females, 7 males: 9 persons<30, 8 persons >50, 7 persons aged from 30 to50 years old. Occupation: workers, housewives,secretaries, managers, teachers, SW developer,chef etc.
X
Fig. 1 Left young subjects fillin a questionnaire in “mobilecooking” context. Right kitchenafter the study with the secondversion of the cooking assistant
studying the cold-start adaptation problem. We believe thatthe collected preferences are fairly realistic, because theywere acquired during fulfilment of practical tasks (e.g., thesubjects had indeed to change a windscreen wiper or to find asuitable recipe together with another person). The way howwe collected interface preferences (giving the subjects anapplication with default interface settings first and then usingpersonal preferences for previous task for the next task) mighthave caused everybody to have similar settings for differentcontexts, but this did not happen, as we will show below. Set-tings for social context appeared to be of special interest, asmany subjects actively discussed desirable and undesirablebehaviour of smart applications in social context during allstudies.
The applications aim at guiding the users step-by-stepthrough cooking and car servicing tasks. The cooking andcar assistants have similar interfaces (shown in Fig. 2) andfunctionality, which includes the following:
• Delivery of instructions how to perform every taskstep;
123
328 J Multimodal User Interfaces (2013) 7:321–349
Fig. 2 Instructions and reminders in the mobile cooking (left) and car servicing (right) assistants
• Delivery of context-triggered reminders, e.g., to addwater or to stir a meal; to check that two parts are cor-rectly fixed to each other before starting to attach a thirdpart;
• Delivery of complimentary information: health and tooltips, e.g., suggestions to replace certain recipe ingredientsby healthier food products or to buy most appropriatelubricant for car servicing;
• Delivery of explanations, e.g., that interface change wascaused by a message from a sensor-augmented object.
The cooking and car assistants deliver information via GUI(text and images) and audio messages (if audio output isenabled). Information delivery is triggered by both explicituser input (GUI controls and speech commands) and implicitinput (recognition of users’ actions by sensors). Recognitionof certain users’ actions is achieved by analysis of motiondata from sensor-augmented objects, sent via Bluetooth. Forexample, significant tilt of a chopping board shows thatsausages were put to boiling water and thus previous cookingstep (“cut sausages”) is finished. Thus the tilt detection trig-gers displaying of next step instructions. On the other hand,failure to detect certain event within instructions-dependenttimeout may trigger a reminder regarding a required action.During this study audio and sensor data processing was per-formed by the laptop, but the test subjects believed that thephone is doing it.
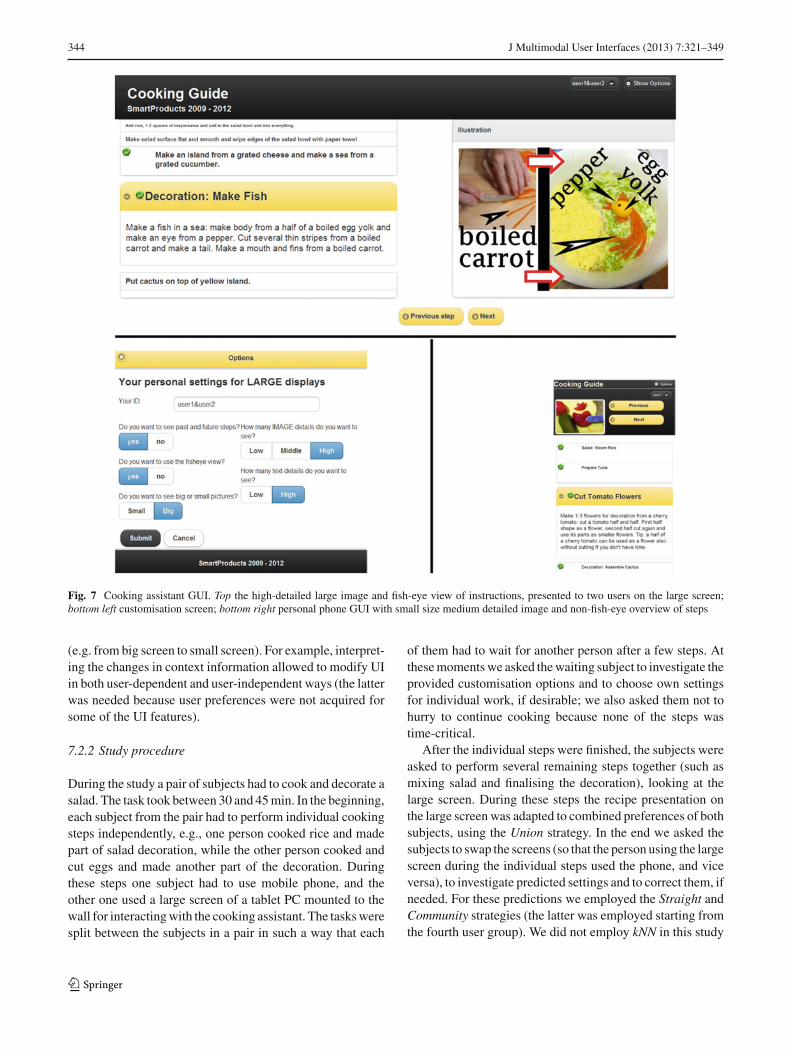
The interfaces can be customised via controls in the bot-tom of the GUI on the main screen, allowing to disable/enablepotentially annoying features (audio output, reminders andtips), to select the level of instructions’ details and tohide/show images, so that text can be displayed in a largerfont. After additional navigation it’s possible also to fur-ther customise the output (e.g., to enable audio output forinstructions and reminders, but to disable it for tips) and todisable/enable two inputs: sensor-based activity recognitionand speech processing.
In Fig. 2 the cooking assistant instructs to cook “Hal-loween sausages” recipe, and the car assistant shows instruc-
tions for replacing a windscreen wiper. In addition to theinstructions, during the study the cooking and car assistantsdelivered also a health or a tool tip and a reminder. Delivery ofa health tip depended on the user: an advice to dilute ketchup(used for painting sausages) to make it less salty was givento the users on low-salt diet, and an advice to add garlic (as ithelps against viruses)—to others. The car assistant gave a tipto use certain type of windscreen washing liquid, allowingwipers to last longer in our climate. Audio presentation oftips (if enabled) took place shortly after audio presentationof instructions.
We also demonstrated how sensor-based recognition ofuser actions may facilitate hands-free operation: cuttingboard tilt indicated that sausages were put to boiling water,and triggered transition to the “cook [sausages]” step, wherecooking timer was activated. After cooking time expired, thecooking assistant reminded not to overcook sausages as theymay deform. In the car assistant acceleration of a wiper indi-cated that “remove old [wiper]” step was complete, and nextstep instructions were shown. As a reminder, the car assistantsuggested to check whether a wiper was properly attached toa shaft. Reminders were delivered via text boxes, as Fig. 2shows, and audio messages: “Sorry, may I interrupt? Haveyou done . . .”
Initially we assumed that it should be sufficient to cus-tomise only application output. However, initial user studieswith a cooking assistant application [46] have shown thatinput should be also customised because some users feelmore comfortable with an application if it does not “listen”to them constantly, even if “listening” results are not used inany way. Besides, input adaptation helps to prolong batterylife in a phone and in sensor nodes.
The applications ran on Nokia N900 phones, but heavydata processing (analysis of sensor data and audio data)was performed by the laptop as it was faster. For speechrecognition we used Microsoft SDK (http://www.microsoft.com/en-us/download/details.aspx?id=10121), and for text-to-speech conversion we used eSpeak open source software(http://espeak.sourceforge.net/).
The procedure in the study with the cooking and car assistantswas as follows. Subjects had to deal with the cooking taskalone and then in groups of three persons. After that theyperformed the car servicing task alone and then in groups.The cooking task was to boil and decorate sausages for Hal-loween, and the car servicing task was to replace a windscreenwiper: we used real wipers and a shaft, but disconnected themfrom a car and placed on a table for user convenience.
Altogether we created ten groups of three persons, wellacquainted with each other. The majority of the subjects wereincluded in one group only, but several subjects were includedin two groups. Choice of group members mainly dependedon how well they all knew each other because we wanted tocreate natural atmosphere and to facilitate free exchange ofopinions: not-so-well acquainted users may be reluctant toexpress their wishes or to insist on respecting them.
A mobile phone was given to each user as personal devicefor the individual tasks. For the group tasks the whole groupshared one phone.
In the beginning of interaction with each new application(e.g., when a subject was asked to perform the first cookingtask) each subject was given an application with its defaultinterface (i.e., settings chosen by application developers) andasked to explore how the interface can be customised and tochange default settings if he/she wishes so. After each subjectperformed a task alone, he/she was asked to start instructionsagain and to create, if needed, another set of interface settingsfor the case when this task would become familiar to him/ her,e.g., when he/she will cook a well-known recipe. Similarly,when a group first interacted with an application it had thedefault interface settings, but the group was reminded that it
is possible to create and store one more set of interface set-tings, which would be used next time when the same groupwill be gathered together. In order to reduce influence of nav-igation cost on preferences acquisition, we used paper formsto collect preferences for those interface features which werenot directly customisable in the application. Thus for eachapplication we acquired one set of group settings per groupand two sets of individual settings per subject: one set fornew cooking/car servicing task, and another one for a well-known task. During the interviews the subjects confirmedthat the chosen tasks were not familiar to them prior to thestudy.
4.1.3 Preferences summary
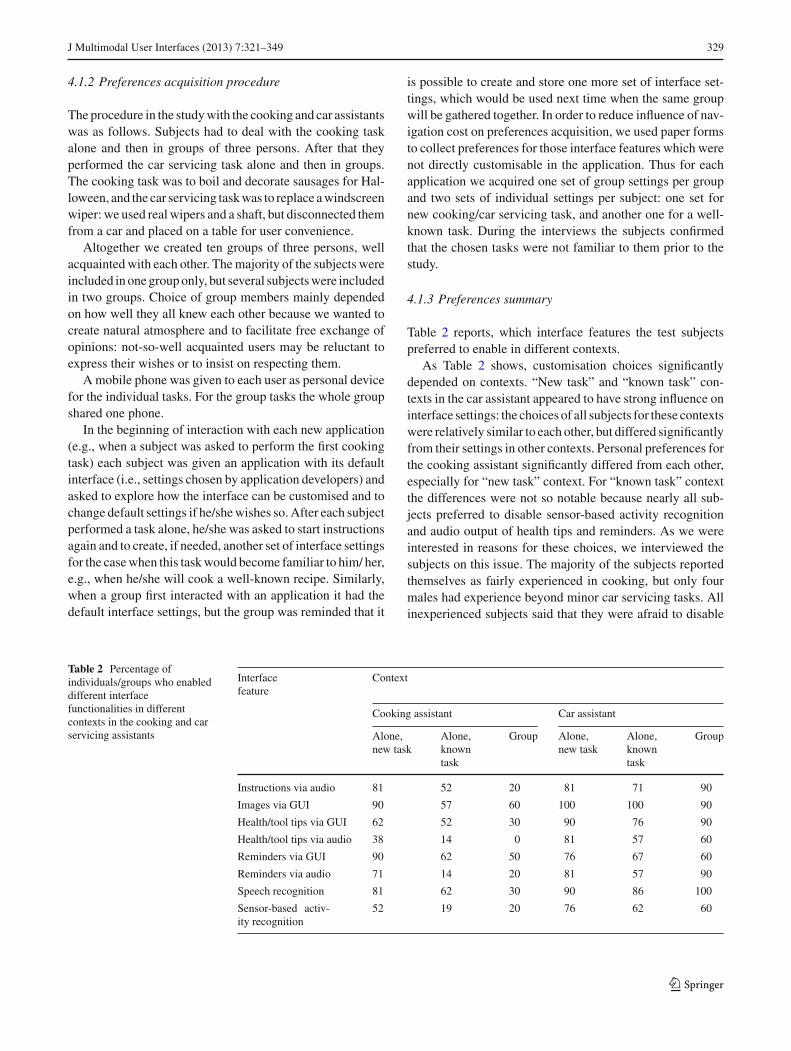
Table 2 reports, which interface features the test subjectspreferred to enable in different contexts.
As Table 2 shows, customisation choices significantlydepended on contexts. “New task” and “known task” con-texts in the car assistant appeared to have strong influence oninterface settings: the choices of all subjects for these contextswere relatively similar to each other, but differed significantlyfrom their settings in other contexts. Personal preferences forthe cooking assistant significantly differed from each other,especially for “new task” context. For “known task” contextthe differences were not so notable because nearly all sub-jects preferred to disable sensor-based activity recognitionand audio output of health tips and reminders. As we wereinterested in reasons for these choices, we interviewed thesubjects on this issue. The majority of the subjects reportedthemselves as fairly experienced in cooking, but only fourmales had experience beyond minor car servicing tasks. Allinexperienced subjects said that they were afraid to disable
Table 2 Percentage ofindividuals/groups who enableddifferent interfacefunctionalities in differentcontexts in the cooking and carservicing assistants
Interfacefeature
Context
Cooking assistant Car assistant
Alone,new task
Alone,knowntask
Group Alone,new task
Alone,knowntask
Group
Instructions via audio 81 52 20 81 71 90
Images via GUI 90 57 60 100 100 90
Health/tool tips via GUI 62 52 30 90 76 90
Health/tool tips via audio 38 14 0 81 57 60
Reminders via GUI 90 62 50 76 67 60
Reminders via audio 71 14 20 81 57 90
Speech recognition 81 62 30 90 86 100
Sensor-based activ-ity recognition
52 19 20 76 62 60
123
330 J Multimodal User Interfaces (2013) 7:321–349
Table 3 Summary of personalpreferences regarding multi-useradaptation in the cooking andcar assistants
Option to answer Default Deviceowner
Democratic Intersection Union Any other, what?
Cooking assistant
Number of personswho have chosen thisoption
1 5 4 6 3 2—show just text andimages via GUI
Car assistant
Number of personswho have chosen thisoption
8 2 3 1 1 6—of a man even if he isnot a driver
anything in the car assistant because “mistakes would havebad consequences”, whereas choices of experienced subjectsdepended on their tastes. During customisation of cookingassistant all subjects were guided by personal tastes. Explana-tions regarding disabling sensor-based activity recognition inboth applications can be grouped as “it’s too fine-grain track-ing”, “I don’t follow instructions precisely” and “computersdo not have rights to check what we are doing”. The expla-nations for disabling audio output in both assistants were“I prefer reading” and “it’s just too much”. Other reasonsfor disabling audio in the cooking assistant were “I want torelax”, “I want to feel like left alone” and “even if food getsburnt, it is not the end of the world”.
Group choices also strongly depended on domains. Weobserved that group members freely exchanged opinions andrespected wishes of each other. During customisation of thecar assistant groups tended to delegate responsibility andrights to choose interface settings to a leader, usually mostexperienced or most brave male. During customisation ofthe cooking assistant the subjects appeared to be more con-cerned with etiquette than usability. For example, many sub-jects said that reminders is a useful feature for individuals andeven more so for groups (as groups get distracted from cook-ing more frequently than individuals). Several subjects evennamed reminders as the most useful interface feature. Never-theless if any group member said that reminders would annoyhim/her, others immediately agreed to disable reminders. Themain reason for disabling audio interaction in groups was “Idon’t want to be disturbed when I chat with friends”. Fromthese explanations we concluded that in cooking domain thesubjects did not worry about mistakes very much and valuedenjoyment higher than efficiency.
In order to find good ways to combine personal interac-tion preferences of the group members, the questionnaireincluded the question “When you start the application insome group for the first time, how it should use personalpreferences of the group members? Please select from thefollowing options:”
• default: use default settings suggested by applicationdevelopers, ignoring all personal choices;
• device owner: use settings of a phone owner, ignoringpreferences of other group members;
• democratic: choose settings via majority voting betweenindividual settings of group members;
• intersection: enable an interface feature only if everybodyin a group would enable it alone;
• union: enable an interface feature if anyone in a groupwould enable it alone;
• anything else, what?
Table 3 shows the summaries of the answers to these ques-tions.
4.2 Recipe recommender prototype
This study took place half year after the study with the cook-ing and car assistants.
4.2.1 Application interface, functionality and customisation
The recipe recommender retrieves recipes from a website(http://allrecipes.com/), but shows the recipes in its owninterface. The first page allows users to query recipes andto view a list of retrieved results. The query is built fromuser-provided lists of desirable ingredients and meal types,as well as undesirable ones. The retrieved list of recipe namesis shown along with some additional information about arecipe (e.g., cooking time and calories). Other details canbe accessed by clicking on the recipe and are presented indedicated pages.
Additionally, the application provides recipe sharing func-tionality. When one user finds a suitable recipe, he/ she sendsit to another device by clicking on “Share” or “Voting” but-tons in the upper part of the GUI, shown in Fig. 3. (“Share”button allows sending a recipe proposal or replying to thereceived proposal in one click; in this case it is assumedthat the recipe is evaluated as “quite good”. “Voting” buttonopens another screen, allowing evaluation of a recipe on afiner scale, from “very good” to “very bad”.) When anotheruser receives this proposal, she checks the recipe and repliesalso by clicking on “Share” or “Voting” buttons. This reply
Fig. 3 Recipe recommender interface. Left customised first page of a recipe with a health tip in the laptop GUI; right top customised first page ofa recipe with a health tip in the phone GUI; right bottom customisation screen of the phone
is sent back to the phone of the person who proposed therecipe.
In this study we employed two versions of the recipe rec-ommender: one designed for a laptop and one for a NokiaN900 phone. The interfaces of both versions are fairly simi-lar to each other, except that more information can fit in thelaptop screen without scrolling than in the phone screen.
The customisable interface features are the types of infor-mation that are shown when the first page for recipe details isaccessed. Thereby, users can customize the information pre-sented on this page; more recipe details can be accessed onthe next pages. For the laptop version the users can select fiveinformation chunks out of 12 provided options, and for thephone screen the users can select three information chunks.These 12 information options were chosen because they wereconsidered important by many recipe sites. Available optionsinclude:
• six types of nutritional data (calories, cholesterol etc.)• times: total; preparation time (for actions like cutting,
peeling etc.); and cooking time (e.g., frying time)• cuisine: country of recipe origin• way to cook: bake, fry etc.• “extra”: warnings regarding possible caveats, e.g., that
this recipe requires to use a blender
Users can also choose font size and specify whether com-ments of a recipe provider should be shown on top or bottomof this first page or not shown at all. Further, the user candisable/enable display of shop offers (discounts for prod-ucts) and health tips (advices regarding healthy lifestyle).If enabled, shop offers are displayed in the bottom of the“recipe list” page. Health tips are recipe-related. If they are
enabled, then the laptop version shows them right below therecipe name. The phone version replaces the recipe name bya health tip shortly after opening a first recipe page, as shownon the right half of Fig. 3.
Thus, unlike the majority of works on recommender appli-cations, that study how to adapt lists of recommendations tousers and contexts, we collected preferences regarding adapt-ing presentation of details of a selected list item to users andcontexts (i.e., how to better show recipe data after a userclicks this recipe in the list), which is a largely unexploredissue because most of recipe recommender websites weredesigned for desktops and thus recipe assessment on a phonescreen often requires a lot of scrolling [39].
4.2.2 Preferences acquisition procedure
During the study with the recipe recommender the subjectsfirst interacted with it individually and then in pairs. Eachtime when the participants were given new task, they wereasked to customise the GUI for this task, if desirable. Eachsubject was first given the interface with the following defaultsettings: small font, first page shows ingredients, commentsare shown on top of it, no information chunks selected, healthtips and shop offers disabled. For the next task the subjectswere given the interface with their previous settings insteadof default ones. The majority of the subjects used defaultfont size and left ingredients at the first page, but carefullyinvestigated other features.
The first task, given to every subject individually, was tofind several recipes for individual cooking (context “alone”),first on the phone and then on the laptop. After that everycouple (there were 16 couples among subjects) was giventwo phones and asked to find two recipes which they would
123
332 J Multimodal User Interfaces (2013) 7:321–349
like to cook and eat together (context “family”). The spouseswere asked to stay several meters away from each other, touse only their own phone for recipe search and to use recipesharing functionality of the application instead of oral discus-sions. After a group task had been performed with the mobilephone, we asked the same pairs to customise the laptop GUIfor the same task. After that we selected 20 pairs of friendsfrom among the subjects, and asked them to follow the sameprocedure, however with the goal to find two recipes for eat-ing together and possibly with other guests (assuming thatthese two friends may host a party tonight—context “party”).Then the process was repeated for the laptop GUI.
Thus in this study we did not have same groups as in theexperiments with the cooking and car assistants. The majorityof the groups, interacting with the cooking and car assistants,included a couple or a pair of friends who took part as agroup in the second experiment. However, two groups inthe study with the cooking and car assistants included threesubjects that were later involved in a study with the reciperecommender in different groups.
All subjects performed at least one group task (eitherwith their spouse or with a friend). Many subjects com-pleted both group tasks, but not all because some subjectswere single, while few others knew only own spouses in thisgroup. These subjects were asked to perform the remain-ing sharing task on their phones alone, having in mind amissing partner or a friend. After the tasks “family” and“party” we asked the corresponding pairs to sit togetherand to do one more search using one phone only (context
“one phone”). The groups were again given a default inter-face and asked to customise it, speaking aloud, so that weobserved how the subjects find compromises between theirpreferences.
Finally, all subjects again performed a task individuallyon the phone. They were asked to find a recipe and to cus-tomise the interface for a “mobile cooking” context, i.e., forcooking in a camping. This was also a realistic problem forthe subjects, because all subjects cook in rented cottages andin camps fairly often.
In total we acquired interface preferences of 44 subjectsfor the cases when they search for recipes for cooking andeating (1) alone; (2) with their families; (3) with their friends;(4) in a rented cabin or near campfire. Preferences for threeformer contexts were acquired for both laptop and phoneversions, and preferences for the latter context were acquiredfor the phone only. In addition, we acquired preferences of36 pairs for the “one phone” context.
Preferences SummaryA summary of the acquired preferences is presented in
Table 4. Table 4 does not present preferences regarding com-ments, font size and whether the first page should show ingre-dients or preparation because preferences regarding thesefeatures appeared to be task-independent and not so muchdependent on screen size either. Thus for the majority of thecontext transitions predictions regarding these features aretrivial.
During this study we again observed that customisationchoices significantly depended on the context. “Mobile” and
Table 4 Percentage ofindividuals/groups who enableddifferent interfacefunctionalities in differentcontexts in the reciperecommender application
Interface feature Context
Phone Laptop
Alone Family Party Mobile 2 Users,1 phone
Alone Family Party
Information chunks
Calories 30 30 5 9 17 55 68 5
Fat 7 16 0 0 14 30 39 0
Cholesterol 14 27 7 6 22 23 34 7
Carbohydrates 11 9 0 2 6 25 23 0
Fiber 9 7 2 2 8 16 14 2
Protein 9 16 0 2 8 16 23 0
Preparation time 23 20 58 27 33 57 48 90
Cooking time 11 9 16 14 11 27 18 32
Total time 64 61 61 77 75 84 82 73
Cuisine 20 20 30 5 25 39 34 89
Way to cook 70 55 59 93 67 77 73 99
Extra 32 32 56 66 22 55 48 100
Shop offers 55 59 70 59 53 27 32 48
Health tips 41 41 2 7 31 43 43 2
123
J Multimodal User Interfaces (2013) 7:321–349 333
“party” contexts appeared to have strong influence on inter-face settings: the choices of all subjects for these contextswere relatively similar to each other, but differed signifi-cantly from their settings in other contexts. In the “mobile”context the choices are influenced by the specifics of cookingoutside of home, where only a limited selection of cookingappliances is available and everybody is hungry after outdooractivities. In the “party” context the choices are influenced bythe desire to cook something unusual (therefore more sub-jects have chosen recipe cuisine as additional informationon the detail page), but not terribly tiring (therefore sub-jects have chosen preparation time) and not terribly expen-sive (therefore, subjects have enabled shop offers). Nutri-tional information for these contexts was chosen by few sub-jects only, because of their strict diets or strict diets of theirfriends.
Preferences of the subjects for “alone” and “family” con-texts varied a lot. For the “alone” context many subjectshave chosen information chunks according to their personalcooking and eating habits, while for the “family” contextthe majority of the subjects replaced at least one of thepersonal choices with information reflecting their partner’sneeds or tastes. For example, several persons were interestedin cholesterol percentage only in “family” context becausethey cared about their spouses. However, we observed thatnot all of these spouses have chosen cholesterol on their owndevices, and concluded that “family” context will be the mostchallenging one for predictions.
For the laptop, many subjects have selected the same threeinformation chunks as for the phone plus two more chunks.Several persons, who had selected “total time” informationon the phone, however, have chosen preparation and cookingtimes for the laptop instead. Significantly lower number ofsubjects enabled shop offers for the laptop than for the phonebecause laptops are typically used for recipe search fromhome. As this may happen long before or long after shopping,interest in shop offers decreases.
In this study, the test subjects had to agree with each otheron preferences only in the “one phone” context. The phoneinterface allows selecting three information chunks only. Theindividual choices of the subjects fully overlapped only in afew pairs. In the other cases, a compromise had to be nego-tiated. In this situation the majority of the pairs selected oneor two most characteristic chunks (way to cook and/or totaltime). The remaining chunks were either nutrition-relatedinformation of the highest interest to this pair or more spe-cific recipe data (such as cuisine or preparation time—tounderstand required manual efforts). In order to find goodways to combine personal preferences of the group mem-bers, we included in the questionnaire two questions—firstone regarding choosing states of interface features, customis-able independently on each other, and the second questionregarding selecting a subset of interface elements.
The first question, referring to independent interface fea-tures, and the options to answer were the same as for thecooking and car assistants. The second question was “whenyou start the application in some group for the first time,how to select information chunks from personal choices ofthe group members in cases when these choices differ fromeach other? Please select from the following options:”
• default: use default settings suggested by applicationdevelopers, ignoring all personal choices
• device owner: use settings of a phone owner, ignoringpreferences of other group members
• equality: enable the ones most popular among the groupmembers (estimated by majority voting); if there is stillspace left for more chunks, enable “favourite” chunks ofthose group members whose choices were not taken intoaccount as much as choices of other group members (forexample, a chunk can be considered as a “favourite” oneif it was chosen in many contexts)
• high health: enable all nutrition-related chunks; if thereis still space left for more chunks, enable the ones mostpopular among the group members
• low health: enable all chunks not related to recipe nutri-tion; if there is still space left for more chunks, enablenutrition-related chunks, most popular among the groupmembers
• anything else, what?
We asked the subjects to consider multi-user adaptation alsofor groups of three and more persons when answering thesequestions. Table 5 summarises answers to these questionsand shows that again there was no winner among the strate-gies. Some of the subjects suggested to combine informa-tion chunks also in context-dependent way, and some othersubjects suggested to apply “high health” strategy only toinformation related to strict diets and allergens.
5 Prediction method: reasoning strategies and theirautomatic selection
We used the acquired data to study how preferences forunseen contexts can be derived from preferences for othercontexts, i.e., how to address the cold-start adaptation prob-lem. The results of the user studies suggest that a suitablemediation method should satisfy the following requirements:
• it should be capable of predicting preferences of a tar-get user/group for a target context both in cases whenthe target context and application are very similar to theinitial context and application and in cases where targetand initial contexts and applications differ significantly;
123
334 J Multimodal User Interfaces (2013) 7:321–349
Table 5 Summary of personalpreferences regarding multi-useradaptation in reciperecommender
Option to answer Default Deviceowner
Democratic Intersection Union Any other, what?
For independent GUI elements
Number of personswho have chosen thisoption
3 6 11 13 8 3—show nothing
Option to answer Default Deviceowner
Equality Lowhealth
Highhealth
Any other, what?
For selecting a subset of GUI elements
Number of personswho have chosen thisoption
2 6 11 10 3 7—“high health”, butonly for real danger5—depends on task(“family” or “party”)
• it should be capable of working with fairly small datasetsof preferences;
• it should be capable of adapting to specifics of each con-text transition (i.e., differences between initial and tar-get contexts), as no “one fits all” reasoning strategy wasfound during the user studies, as previous section shows.
The second requirement forbids the use of data intensivemachine learning approaches. Instead, we propose predictionmethod for cases when only the following data is available:(1) preferences of the target user for one initial context orfor a few initial contexts; and (2) preferences of a certainnumber of other users/groups, called non-target users, forthe same initial context(s) and for the target context. For thepredictions we use heuristic strategies, based on typical waysof human behaviour. The strategies and the rationale behindthem are explained below.
5.1 Classifier selection
Humans exhibit a mixture of several characteristic behav-iours when encountering a new situation. First of all, anindividual may behave in a new situation in a same way asin other situations. Second, an individual may behave in asame way as the majority of other persons behave in thissituation. Third, an individual may behave in a same wayas persons, most similar to him/her. Use of preferences ofsimilar persons for predictions is a basis of a popular usermodelling approach, called collaborative filtering [5], andthus we used this approach for predictions too, in the form ofthe kNN (k Nearest Neighbours) strategy below. However,using collaborative filtering as the only prediction strategyis not suitable for predicting preferences, because users thatare similar in one context can become very distinct regardingtheir preferences in another context. For example, if two per-sons are interested in recipe nutrition data, it means that theyare somehow similar to each other in the cooking domain,
but it does not guarantee that they will express similar atti-tudes to interface of the car assistant—e.g., it is unclear, willthey make same or different choices regarding enabling tooltips. Whether somebody’s choices in the target context willbe more similar to his/her choices in the initial context, orchoices of the majority of the other users in the target context,or choices of similar users, depends on specifics of the targetcontext and on similarity between the initial and the targetcontexts.
As we aim at using no domain knowledge, we propose tolearn from the database of user preferences, which behaviouris most typical for each context transition. Furthermore, wepropose to detect such patterns for each interface feature sep-arately, because during the user studies we observed that thetarget context may strongly influence preferences regardingcertain interface features, while preferences regarding otherfeatures may remain same as in the initial context.
In order to automatically determine best prediction strat-egy for each case, we employ a popular machine learn-ing method, called classifier selection [23]. It works as fol-lows: first a set of algorithms, called a classifier pool, istrained on one part of dataset and then validated on anotherpart. Then the most accurate (according to these validationresults) classifier is used for each test case. Classifier selec-tion approaches vary in the ways how training and validationdata are selected, but none of them guarantees an improve-ment in recognition rates for all test cases relative to the bestclassifier for each.
As we aim at using fairly small datasets and our strate-gies do not require training, we use as validation data pref-erences of all non-target individuals or groups, i.e., for everycustomisable interface feature we calculate average accura-cies of all prediction strategies using the data of all non-target users. Then for the target individual/group for everycustomisable interface feature we select a strategy withthe highest average accuracy for this feature. Our classi-fier pool and classifier selection approach are illustrated byFig. 4.
123
J Multimodal User Interfaces (2013) 7:321–349 335
Classifierpool
Use incascade
with kNN orCommunitymethods at2d stageNo
kNN
Community
Union
Straight/Democratic
Intersection
No
Temporarily excludefrom classifier pool
Use ”As Is”
Initialcontext(task,
domain,UI,
social)
Targetcontext(task,
domain,UI,
social)
Profilesfor targetcontext
Profilesfor initialcontext
Makepredictions
for otherusers/
groups andcalculate
accuraciesof all
classifiersfor all UIelements
Target user(s)profile(s) forinitial context
Take bestclassifiers
forevery UIelement
Makepredictions
andcombine
them
Classifier selection
Finalcombination
Yes
Yes
UIsettings
fortarget
context
Suits tocurrent
number ofusers?
Canpredict
competeUI?
Canpredictpart of
UI?
Yes
No
Data
Fig. 4 Classifier selection process
5.2 Strategies in the classifier pool
Guided by the observations and questionnaires, obtained dur-ing the user studies, we included in the classifier pool thefollowing strategies:
(1) Straight/Democratic In case of predicting individualpreferences, this strategy assumes that in a target contexta user will have the same preferences as in the initial con-text. In case of predicting group choices, we use the fol-lowing rule: if the majority of group members would selectsome interface feature individually (e.g., select certain infor-mation chunk in the recipe recommender system or enableaudio output in the cooking assistant), do the same in socialcontext. This strategy suits for cases when interface featuresare equally important for initial and target contexts. Use ofthe Straight strategy for individuals requires knowing theirpreferences for the initial context, but does not require know-ing anybody’s preferences for the target context. Use of theDemocratic strategy for groups requires knowing individualpreferences for the target context, but not choices of othergroups for the target context.
(2) Community This strategy assumes that in a target con-text a target user/group will have the same preferences asthe majority of other users/groups in the target context. TheCommunity strategy is suited for cases when attitudes towardscertain interface features are strongly affected by context anddo not depend on attitudes towards other features. For exam-ple, many groups disabled health tips in the cooking assistantGUI even if every group member would have enabled themalone. In such cases the Community strategy predicts prefer-ences much more accurately than the Democratic strategy.The Community strategy is also suited for cases where onlyfairly large number of examples permits to detect that somefeature has special value in the target context. In our tests
similarity-based strategies (based on formulas 1 and 2) alsofailed to accurately predict disabling of health tips in thecooking assistant GUI by groups. This happened becausethe similarity calculation was based on eight features, andoften neighbouring groups appeared to be similar in theirattitudes towards other features, but dissimilar in their atti-tudes towards health tips.
Community strategy requires to know preferences of non-target individuals or groups for the target context, but doesnot require any knowledge regarding their preferences forinitial context(s).
(3) kNN If we need to predict choices of an individual,we find k similar individuals; if we need to predict groupchoices, we find k groups of similar users and apply majorityvoting to decisions of these individuals or groups regardingevery customisable feature of a target interface, i.e., we seta feature to a certain state (for example, enable tool tips) ifthis state was chosen by the majority of individuals or inthe majority of groups of similar users. Similarly, we selecta subset of interface elements, most popular among simi-lar users/groups. Thus in case of predicting group choiceskNN ignores personal preferences of members of the targetgroup for the target interface even if these preferences areknown.
Similarity between users or groups in context C is cal-culated as average of distances between all pairs of groupmembers; distance between two users is calculated as cosinemeasure:
SimC (G1, G2) = 1
J · K
∑J
j=1
∑K
k=1
∑Ni=1 Wi · sim(U ji , Uki )√∑N
i=1 U j2i ·
√∑Ni=1 Uk2
i
(1)
In Formula (1) G1 and G2 denote two groups; J and Kare sizes of these groups (can be one when we find similar
123
336 J Multimodal User Interfaces (2013) 7:321–349
individuals); Wi denotes importance of interface feature i,and U ji denotes the preference value of User j towards thefeature i. Users j and k belong to different groups. In casewhen decisions serve as preferences values, these values canbe either one (information chunk was selected; audio out-put was enabled etc.) or zero, and sim(U ji , Uki ) is equal toone if both users have selected the same feature state, andzero otherwise. In this study we used equal weights for allinterface features.
The kNN strategy is based on the assumption that users,who are similar in one context, remain similar in other con-texts too. This assumption is a basis for predicting prefer-ences of a target group for application A when preferencesof individuals or other groups for application A are known. Inthis case context C in the Formula (1) denotes use of the appli-cation A, and U ji - personal preference values for the appli-cation A, too. One may also assume that users with similarpreferences for features of application B would have similarpreferences for features of application A. If this assumptionwould hold, settings of a target group for application A couldbe predicted based on preferences of individuals for applica-tion B and settings of other groups for application A. In thiscase context C in the Formula (1) denotes use of applicationA, but U ji denotes the preference value for the applicationB.
The kNN strategy is well suited for cases when certaininterface features are either much more important or muchless appropriate in the target context than in the initial con-text and when users’ attitudes towards these features dependon attitudes towards other interface features. For example, inour study information on recipe cuisine was selected in the“party” context by subjects who did not select this infor-mation for individual use of the application. The reasonwas interest in exotic recipes for parties. However, cuisinewas more frequently selected in cases when none of theparty participants was interested in diet-related nutritionalinformation alone than in cases when somebody was inter-ested in it. Similarly, disabling of some functionality (e.g.,application-initiated messages) may depend on the generalattitudes of individuals and group members towards this cat-egory of functionality, e.g., in our study shop offers in therecipe recommender systems were disabled in the majorityof the groups where group members also disabled remindersin the cooking assistant.
Attempts to improve user similarity measures constitutesignificant part of research in the domain of collaborativefiltering. However, these works do not deal with as signifi-cant differences between initial and target domains as we do,and typically use larger databases than we use. Due to thesecond reason we did not attempt at learning user similar-ity measures from the data, as is frequently done [2,27,47].Due to the first reason we employed kNN, which does nottake into account the degree of similarity between the tar-
get user/group and the neighbours; it simply uses majorityvoting between all neighbours. The more conventional col-laborative filtering approach would be to estimate preferencevalue Uτi of a target user T regarding feature i according tothe formula (2):
Uτi = U τ + k ·N∑
j=1
w j · (U ji − U j ) (2)
In the formula (2) U ji is a preference value of user j forthe feature i, U j and U τ are means of preference values ofthe users j and T respectively; w j is the weight of the user j,calculated as a cosine distance between users j and T, and k isa normalisation factor. For brevity, in the rest of this paper wewill call this approach, based on formula (2), “conventionalcollaborative filtering” or “CF”. The decision to employ kNNinstead of CF was made after preliminary tests, where wecompared accuracies of these two methods and found thatalthough CF often outperforms kNN in cases when initial andtarget contexts are fairly similar to each other, kNN achieveshigher prediction accuracy in cases when initial and targetcontexts differ significantly. We will present the results inthe next section.
(4) Union This strategy is applicable only to predicting groupchoices. It is based on the following rule: first rank prefer-ences according to some criteria, e.g., by their usefulness orpopularity. Then check these preferences in the order from thehighest to lowest ranks. If any group member would selectthe higher ranked interface element or feature state alone,do the same in social context irrespectively of preferences ofother group members. For example, when an interface featurecan take just two states (enabled or disabled), let’s assumethe “enabled” state has the higher rank of the two. Then thefeature would be enabled if any of the group members wouldenable it alone.
The Union strategy is suited for cases where users tendto enable even the most annoying interface features, if theyhelp to avoid mistakes: for example, in the car assistant weranked as “most useful” reminders delivered via GUI andrepeated (until the users react) audio messages, as “mediumuseful” GUI-only reminded and as “least useful” disabledreminders. The Union strategy first checked whether anygroup member has chosen the “most useful” reminders forpersonal use, and if so, selected this option also for groupuse. Similarly, in the study with another version of the cook-ing assistant, described in the “Control study” section, weranked from “most useful” to “least useful” high detailed,medium detailed and low detailed illustrations to cookinginstructions respectively, and Union strategy enabled highdetailed images if any group member have chosen them forpersonal use, else checked whether medium detailed imagesshould be enabled, and would enable low detailed imagesonly as last possibility.
123
J Multimodal User Interfaces (2013) 7:321–349 337
The Union strategy is also suited for groups includingpersons with special needs, respected by other group mem-bers. For example, we could use Union strategy to ensurethat information regarding recipe allergens and cholesterolis selected with high priority. In this study, however, we didnot want to rely on specific domain knowledge and rankedinformation chunks in the same order they were retrievedfrom the web (usually, the highest rank was given to cookingtime or calories).
(5) Intersection This strategy is also applicable only to pre-dictions of group choices. It checks the same ranked list ofoptions as the Union strategy, but in the reverse order, i.e., itenables the “least useful” option if any group member wouldselect it for individual use. This strategy suits for tasks wherethe cost of mistakes is not as high as the cost of annoyinganyone in a group—for example, when friends want to enjoybeing together and do not worry too much about the cook-ing result. Indeed, in our tests this strategy fairly accuratelypredicted group choices for reminders and sensor-basedactivity tracking in the cooking assistant: often groups dis-abled these features if just one group member preferred thisoption.
5.3 Meta strategies
From the description of the strategies it becomes clear that theclassifier pool cannot always contain all five strategies. Forexample, the Straight strategy is applicable only when initialand target interfaces contain overlapping elements. Strate-gies that use personal preferences of group members for pre-dicting group settings cannot be employed if these personalpreferences are not known (this may be the case with cross-application mediation of group preferences).
Even when some strategy is applicable, it may be unableto predict preferences for all interface features. The Straightstrategy provides full solutions only when initial and targetinterfaces do not contain non-overlapping elements. Also,the Straight strategy alone cannot suggest which elementsshould be added or removed when the number of elementsin the target interface is not equal to the number of elementsin the initial interface, as in laptop-to-phone-and-back pre-dictions of personal preferences for information chunks inthe recipe recommender application. When a group searchesfor recipes using one phone only and the personal choices ofgroup members for information chunks differ, Democratic,Union and Intersection strategies may suggest more or lessinformation chunks than fit in the target interface. Anotherexample where one strategy is incapable of providing a fullsolution is the case of predicting group choices in groupswith an even number of members. In the study with the reciperecommender groups always consisted of two persons, so theDemocratic strategy did not always help to make decisions
also regarding features, customisable independently on eachother and all other features (e.g., shop offers).
In cases when some strategy could provide only a par-tial solution, we used it together with another strategy in acascaded way, as Fig. 4 shows. Unless explicitly stated, wepresent in this paper results of using kNN at the second stagebecause use of Community strategy resulted in a lower accu-racy. When it is possible to show more information chunksthan certain strategy returns, we additionally enable chunks,most popular among neighbouring individuals or groups; andif we need to remove elements, we remove the least popularones. For example, when we apply the Democratic strategyto choose information chunks for two users, searching for arecipe using only one phone, we do the following: first wetake all personal choices returned by the Democratic strategy,and then from the remaining personal choices we select theones most popular among neighbouring groups. So if one userselected “total time”, “extra” and “calories” information forpersonal use, and another one selected “total time”, “extra”and “protein”, we select “total time” and “extra” informa-tion, then count votes of other user groups for “calories” and“protein” and select the winner. Similarly, if some strategycannot resolve conflicts between preferences of group mem-bers, we enable a feature in question if it was enabled by themajority of neighbours.
6 Offline tests with interface preferences
6.1 Protocol
The data, collected in the two user studies, describedabove, was used for testing the proposed classifier selectionapproach with the classifier pool, described above. We aimedat predicting preferences regarding features, presented in theTables 2 and 4. The experiments followed leave-one-out pro-tocol: for every target user/group classifier selection was per-formed using data of all other individuals/groups. Predictionaccuracy was calculated by matching predicted values withthe collected data. In all tests we parameterized the kNN strat-egy with a neighbourhood size of five individuals/groups. Inthe tests on cross-application mediation of group preferences,reported in the Table 8, we assumed that personal preferencesof group members for the target application were unknown.
In the tests with the recipe recommender, reported in theTables 6 and 7, we used the data generated by all 44 partic-ipants in the second user study. In the majority of tasks inthe study with the recipe recommender each of the subjectsused individual phone for interacting with the application,and predictions of preferences for these tasks were basedonly on individual preferences of this user. Use of prefer-ences of another group member for “party” and “family”contexts would probably increase prediction accuracy, but
123
338 J Multimodal User Interfaces (2013) 7:321–349
Table 6 Prediction accuracy for cross-task mediation of individual and group preferences in the mobile applications
targetprofiles
initialprofiles
fam
ily,
phon
epa
rty,
phon
e
2 us
ers,
1 ph
one
65
alon
e,kn
own
task
family,phone - 73 73
-party,phone 65 - 70
alone,phone 68 72 72
-
averageclassifierselection
community
mob
ile,
phon
e
87
86
87
alon
e,ph
one
73
67
-
mobile,phone 62 78 -63
all tasks,phone 65 75 8770
68
74
targetprofiles
initialprofiles
alone,new task 65
grou
p
76
65
alone,knowntask
application:recipe recommender
alone,new&knowntasks
application:cooking assistant
84
alon
e,kn
own
task
-
-
targetprofiles
initialprofiles
alone,new task 74
grou
p
81
74
alone,knowntask
alone,new&knowntasks
application:car assistant
65 75 8768 71
50 60 70 77 53
65 69averageclassifierselection
62 73 community
84 76averageclassifierselection
74 78 community
averagebaseline:
CF ordemocratic
62 59 71 77 72 70 55
averagebaseline:
CF ordemocratic
62 83
averagebaseline:
CF ordemocratic
Columns “alone, phone”, “family, phone”, “party, phone” and “mobile, phone” present accuracies, averaged over 44 subjects. Column “2 users,1 phone” presents accuracy, averaged over 36 groups. Columns “alone, known task” present accuracies, averaged over 21 individuals. Columns“group” present accuracies, average over 10 groups
All columns present accuracies,averaged over 44 subjects
Initial and target profiles Target screen: laptop Target screen: phone Average
Alone Family Party Alone Family Party
Classifier selection 73 71 85 71 70 68 73
Baseline: CF 66 65 87 56 53 59 64
Community 63 61 87 50 60 70 65
this hypothesis could not be tested on the complete dataset.In the tests with the cooking and car assistants, reported inthe Table 6, we used data of 21 subjects from the key usergroup (see “Overview of data acquisition” section). Samedata was used in all tests on cross-application mediation ofpreferences, reported in the Table 8. In the study with thecooking and car assistants we had 10 groups of three per-sons, and in the study with the recipe recommender we had14 pairs from the key user group and 22 pairs from additionalsubjects.
For comparison, we additionally evaluated two alterna-tive approaches. First, we calculated the average accuracyof the Community strategy, as default settings of applica-tions can be acquired via observations over large numbersof users and can be used then for absolutely new userstoo. Second, we evaluated (as a baseline) fairly traditionalway to predict individual and group preferences. For pre-dicting group preferences we used as the baseline Demo-cratic strategy in cases when individual preferences of the
group members for the target context were known (results ofthese tests are presented in the columns “2 users, 1 phone”and “group” in the Table 6). In all other tests we used asthe baseline conventional collaborative filtering (CF), basedon the formula (2). In the formula (2) we used mean voteof the target user/group Uτ = 0 because the mean votefor the target context is unknown, while using mean votefor the initial context resulted in lower accuracy. We usedDemocratic strategy as a baseline whenever it was applicablebecause using CF in all cases decreased the accuracy of thebaseline.
6.2 Prediction accuracies
Table 7 presents the accuracy of cross-device mediationof preferences in the recipe recommender, and Tables 6and 8 present accuracies of the cross-task and cross-application mediation respectively for three mobile applica-tions, described above. Cross-task mediation of preferences
123
J Multimodal User Interfaces (2013) 7:321–349 339
Table 8 Prediction accuracy of individual and group preferences for cross-application mediation of individual and group preferences for the mobileapplications
targetprofiles
initialprofiles
54 60 6956
fam
ily,
phon
epa
rty,
pho n
e2
u ser
s,1
p ho n
e
alon
e,ph
one
66 71
alone, new&known tasks
alone,known task
68 60 6457 65 71
54 59 64 65 72
53 59 66
average classifierselection
recipe recommender cooking assistant car assistant
average baseline:CF 52 62 4053 62 64 57average baseline:
CF 62 62 70
Columns “group” present accuracies, averaged over 10 groups. Column “2 users, 1 phone” presents accuracy, averaged over 14 groups. Othercolumns present accuracies, averaged over 21 subjects
for the laptop-based version of the recipe recommender wasalso tested and resulted in a slightly higher accuracy than forthe phone version, because it is easier to predict correctlythe choice of five GUI elements out of 12 options than thechoice of three elements. Each table presents accuracies ofthe classifier selection approach for each context transitionseparately and then the average of these accuracies over eachcolumn, i.e., the average prediction accuracy of the classi-fier selection approach for the corresponding target context.Accuracies of two alternative approaches are presented forcomparison too.
The entry “all tasks, phone” in Tables 6 and 8 denotesthe case when we used in predictions not just one initialcontext, but data of all available initial contexts of the cho-sen initial application. For example, for predicting individualpreferences for the “mobile” context of the recipe recom-mender all available initial contexts were “alone”, “family”and “party” contexts; for predicting group preferences for“2 users, 1 phone” case all available initial contexts were“alone”, “family”, “party” and “mobile” contexts. Similarly,the entry “alone, new & known tasks” for the cooking andcar assistants denotes the case when we used both availableindividual initial profiles for predicting group preferences. Insuch cases similarity between users/groups for kNN strategywas calculated as an average of similarities over all profiles.The issue whether order of task execution would affect pref-erences or not requires further study.
Results in the tables are in the good agreement with ourobservation, made during the study: settings of individuals
and groups differed from each other (otherwise Communitystrategy would succeed better).
Prediction accuracies in the Table 8 are on average lowerthan that in the Table 6, partially because cross-applicationmediation is more challenging than cross-task mediation, andpartially due to the smaller database size. Nevertheless incross-application mediation classifier selection achieved anaverage accuracy of 67 ± 1% (at 95 % confidence level),which is a fairly good result considering significant differ-ences between initial and target interfaces and applicationdomains.
6.3 Discussion
Classifier selection accuracy, averaged over all tests, equalsto 72 ± 1 %. The baseline and Community strategies achievedequal average accuracies of 64 ± 1 %. Success of the clas-sifier selection in cases where initial and target contexts dif-fered significantly can be partially explained by the fact thatfor such context transitions kNN worked better than the con-ventional CF. For example, an average accuracy of CF forcross-application mediation of preferences was 59 ± 1 %,while an average accuracy of kNN was 66 ± 1%. This resultsuggests that although persons, similar to each other in onecontext, to some extent remain similar also in another con-text, degree of their similarity changes. On the other hand,CF outperformed kNN in some cases where initial and targetcontexts did not differ significantly, although on average alsoin these cases accuracy of kNN was not significantly lower.
123
340 J Multimodal User Interfaces (2013) 7:321–349
However, there are two more reasons why classifier selec-tion was notably more accurate than the baseline in manycases. First, classifier selection is beneficial when usersindeed apply different decision making strategies to differ-ent features. In such cases classifier selection achieves higheraccuracy than any strategy in the classifier pool alone. Forexample, this was the case with cross-task mediation of pref-erences for the “mobile” and “party” target contexts of therecipe recommender: “mobile” context caused nearly all sub-jects to select the “way to cook” information chunk, whilethe “party” context caused many subjects to enable shopoffers and disable health tips. Thus the Community strategyappeared to be most suitable for predictions regarding thesefeatures. On the other hand, the Straight strategy appearedto be most suitable for predictions regarding the “cookingtime” information chunk. The kNN strategy was most usefulfor other interface features because choices for other fea-tures depended on whether a person was strongly interestedin nutrition information or not.
Second, classifier selection is beneficial for those contexttransitions where one strategy suits better than other strate-gies for all features. In such cases classifier selection achievesmore or less the same accuracy as this best strategy. This wasthe case with cross-application mediation of personal pref-erences for the car assistant. Here, the Community strategyappeared to be the most appropriate one. kNN and CF weresignificantly less accurate in this case because users, whoare similar to each other in the cooking domain, appearedto be not so similar in the car servicing domain. Anotherexample for this phenomenon is cross-device mediation ofpreferences. As the majority of the subjects selected the samethree information chunks for the phone and laptop screensplus two more chunks for the laptop, the most appropriatestrategy appeared to be Straight in combination with kNN:first Straight suggested same information chunks as werechosen in the initial interface, and then kNN either removedor added two chunks.
Classifier selection approach has also limitations. Asmany other machine learning methods, classifier selectionmay fail for outliers. It may also fail in cases when no stablebehavioural patterns exist (e.g., if groups would not respectsame social rules) or when the database size is too small tocorrectly detect the best prediction strategies. The latter rea-son caused failure in case of predicting group preferencesfor the cooking and car assistants, both in cases when grouppreferences were predicted based on individual preferencesof group members for the same application and in cases whengroup preferences were mediated from another application.For all these cases the Community strategy worked fairly well.However, classifier selection often resulted in other strategiesbecause data of only nine non-target groups was available,and small deviations in settings of these groups made choiceof the best strategy somewhat random. This effect was espe-
cially visible when group preferences were predicted basedon individual preferences of group members because morestrategies were applicable to this case: the Intersection strat-egy suited best of all for the cooking assistant, while Demo-cratic and Union strategies suited fairly well for the car assis-tant, but classifier selection failed to recognise the real win-ners.
The classifier selection approach was outperformed bythe baseline also in one of the cases when initial and tar-get contexts did not differ significantly and conventional CFachieved higher accuracy than kNN. For the cross-task medi-ation of individual preferences for the cooking assistant CFserved as the baseline and achieved 70 % prediction accu-racy, while accuracy of the classifier selection was 5 % lower.This happened because individual preferences for cookingfamiliar recipe differed from the settings for cooking newrecipe and varied between the test subjects. Neither Straightnor Community strategy can cope with such cases reasonablyaccurately and thus classifier selection resulted in kNN, butit did not succeed very well either.
7 User perception of predictions
For some target contexts in our offline tests the average pre-diction accuracy was as low as 52 %. However, predictionaccuracy is not the only factor affecting user satisfaction [25].This section presents the results of the third and the fourthuser studies, aimed at understanding whether users wouldin general desire predictions in every new context or wouldprefer some other option.
7.1 Study with the shopping assistant
This user study was arranged half a year after the study withthe recipe recommender application.
7.1.1 Application interface, functionality and customisation
Figure 5 shows the interface of the mock-up of a mobileshopping assistant application, modelled after the recipe rec-ommender application and running on a Nokia N900 phone.The interfaces of the shopping assistant and the recipe rec-ommender are similar to each other in their look and in someother aspects. The shopping assistant also shows in the firstpage (the “shopping list” page) the list of items, returnedupon user query. For example, a user can query by high-leveldescriptors of food products he/she wants to buy (such as“salad”), and the shopping assistant would present a list ofavailable options for this product (such as various availablesalads). After a user clicks on an item in the list, a first pageof item details opens and shows the item description accord-
123
J Multimodal User Interfaces (2013) 7:321–349 341
Fig. 5 Shopping assistant: left first screen of an item, right customisation screen
ing to the user preferences. Shop offers are shown in the“shopping list” page too.
However, the interface of the shopping assistant differsfrom that of the recipe recommender in several aspects. First,the shopping assistant does not show health tips. As we wereafraid that after previous studies it would be too easy to pre-dict for every test subject whether he/she would like to seehealth tips or not, we decided to show concise descriptionof an item in place of health tips: as Fig. 5 shows, if thisoption is enabled, then shortly after opening the first pagethe item name is replaced by the description. Users can getthe name back by clicking on “hide” button. Second, theseapplications do not offer same information chunks: half ofthe available information chunks are the same six types ofnutritional data as in the recipe recommender, but the restcomprises shopping-specific information such as item price,weight, best before date, country of origin, production com-pany and “extra”—any other useful information, for examplewhether an item contains food additives (E numbers), aller-gens, fresh vegetables or fruits etc. Third, the shopping assis-tant can co-operate with the devices recognising whether anitem is placed in a shopping basket or not (e. g., via scan-ning of RFID tags): when the phone receives a “collected”event and an ID of the item, the name of this item in the list isgreyed out, and the text of the “Take” button (in the upper leftcorner of the GUI, shown in Fig. 5) changes into “in the cart”text. The user can override erroneous recognition by pressingthis button; then it is set back to the “Take” state. Withoutautomatic recognition a user should press the “Take” buttonto manually indicate that the item is in the basket.
Just as with the recipe recommender application, users candisable or enable shop offers and customise the first pageof item details. They can choose whether this page shouldshow textual description of an item (e.g., ingredients) or amap of its location (as presented in Fig. 5). The users canalso disable or enable showing concise items’ descriptions.Again, just as in the phone version of the recipe recommenderapplication, users can select three information chunks outof 12 available options. The users can also disable/enable
use of sensor-based activity recognition: if someone prefersto manually indicate that the item is in the basket, she candisable automatic recognition of this event and use “Take”button instead.
7.1.2 Study procedure
In this study we were not aiming at developing and evaluat-ing a realistic shopping assistant or at selecting informationchunks, allowing to describe various food products in suf-ficient details—we were only aiming at understanding sub-jects’ attitudes towards interface preference predictions. Thestudy was performed as follows: we asked the subjects toselect and place into a basket two ready-made cold snacks(salads, smoked fish etc.) from a predefined list of items,suggested by us: one snack for “eating alone” context andanother one for “a family dinner” context. Both tasks wereperformed by the subjects individually. The study took placein an ordinary room, therefore the map in Fig. 5 does not showtypical supermarket environment. During the study we saidto the subjects that detection of “in the basket” event is per-formed by using the same RFID tags as are used by cashiersfor scanning prices, but in practice we simulated scanningusing “Wizard of Oz” method: when a subject put an item toa basket, an experimenter sent to the phone a message withan ID of the item, and receiving of this message triggeredrequired actions in the phone interface. Navigation was alsosimulated: we prepared maps for a few locations where weplaced mock-ups of food products.
During the study interface preferences for every sub-ject were predicted with the classifier selection approachas described above. When the subjects received the phonewith predicted settings, we asked them to investigate and,if needed, to correct the settings. We planned to explain tothe subjects that their settings were predicted, based on pre-viously collected data, only when they start to fill in ques-tionnaires. However, many subjects noticed that the phoneremembered their interest in nutrition data already when theyinvestigated the predicted settings.
123
342 J Multimodal User Interfaces (2013) 7:321–349
Predictions were based on preferences of the subjects forthe mobile recipe recommender for “alone” and “family”contexts and their individual preferences for “known task”context, acquired for cooking and car assistants. For pre-dicting preferences for “alone” and “family” contexts of theshopping assistant we used as initial preferences personalprofiles for the corresponding contexts of the recipe rec-ommender, concatenated with the profiles of the same userfor the cooking and car assistants. As we only predictedpreferences of individuals, the classifier pool consisted ofthe Straight, kNN and Community strategies. Straight strat-egy was used in cascade with the kNN strategy because theStraight strategy alone was only applicable to “shop offers”and nutrition-related information preferences, acquired forthe recipe recommender, and to preferences for sensor-based activity recognition, acquired for the cooking and carassistants. As preferences for the target application in thisstudy were collected incrementally and as classifier selec-tion did not work well with small datasets in the offlinetests, strategies were added incrementally too. For first threetest subjects we only used the Straight strategy, whereverit was applicable, and random decisions in other cases. Forexample, first we selected as many information chunks asStraight strategy could suggest (e.g., if a user have chosenone nutrition-related information chunk in the recipe rec-ommender, then same chunk was selected also for the shop-ping assistant) and then selected remaining chunks randomly.For the next users we added the Community strategy to theclassifier pool and started to use in cascade with Straightstrategy kNN instead of random decisions. From the 15thuser on we added the kNN strategy alone, because the data-base became large enough for proper selection of nearestneighbours.
After completing the “shopping task” the subjects wereasked to fill in the questionnaire, containing questions regard-ing acceptance of presentation style (Q1), acceptance of pre-dictions (Q2, Q3, Q7, Q8) and acceptance of manual cus-tomisation (Q4–Q6):
Q1: I liked the way how products were describedQ2: It’s good that the shopping assistant transfers settingsfrom one application to another automaticallyQ3: It’s good that the shopping assistant transfers settingsfrom one task to another automaticallyQ4: It was difficult to understand, which interface fea-tures could be changed and howQ5: During previous studies with three applications cus-tomisation process took too long timeQ6: I was able to customise all interface features whichI wanted to customiseQ7: Next (new) application should predict my settingsQ8: Next (new) application should be launched with set-tings provided by its developers (e.g., companies selling
Fig. 6 Average grades for the answers; question number is shown inevery bar. Striped bar refers to presentation style; grey bars refer topredictions and black bars refer to manual customisation
food products, such as Valio; companies selling homeappliances, such as Philips; car manufactures etc.)
The subjects had to answer by choosing one of fiveoptions: from “Strongly Disagree” to “Strongly Agree”. Inorder to summarise the answers, we assigned numerical val-ues to each option, ranging from “-2” for “Strongly Disagree”option to “2” for “Strongly Agree” option.
7.1.3 Study results
Figure 6 presents the average grade for the answers to thequestionnaire.
Overall prediction accuracy in these tests was 68 ± 2 %for “alone” context and 63 ± 2 % for “family” context, rang-ing from 42 % for the first user and to 100 % for some otherusers. For the two first test subjects predictions whether toenable or disable sensors were incorrect: the Straight strat-egy suggested to disable sensor-based recognition of “in thecart” event because these subjects disabled sensors in thecooking and the car assistants. It appeared, however, thatmany more subjects prefer to enable sensors for shoppingthan for cooking because in shopping RFID tags are alreadyused for scanning prices. The third subject has chosen toenable sensor-based activity recognition in the past, and hischoice for this feature in the shopping assistant was predictedcorrectly. Starting from the fourth subject, the Communitystrategy was added to the classifier pool and started to sug-gest enabling sensor-based activity recognition in the shop-ping assistant irrespectively of user choices for the cookingand car assistant, which increased prediction accuracy. TheCommunity strategy also correctly predicted choices of manysubjects regarding short description of a product, price andbest before date: fairly many subjects have chosen theseoptions. The majority of the subjects, interested in nutritioninformation for the recipe recommender, appeared to be inter-ested in the same kind of information also in the shopping
123
J Multimodal User Interfaces (2013) 7:321–349 343
assistant, but interests of several subjects changed during thetime between two studies: some subjects have chosen totalfat percentage instead of cholesterol and vice versa, one sub-ject gave up the idea to reduce weight and thus lost interestin nutrition, another one got interested in protein percentage.
As Fig. 6 shows, the subjects were not very happy withpresentation of products and provided customisation choices(Q1 and Q6). During interviews we understood that the mainreason was the limited choice of information chunks: somesubjects wanted to see separately information regarding vita-mins, food additives (E numbers) and allergens, whereasother subjects wanted to know how long time a product canbe stored without refrigerator. Several subjects suggested tostore settings separately for different categories of food prod-ucts (e.g., for chocolates vs. snacks). Customisation for everytask separately, use of information chunks and the possibil-ity to enable/disable sensors were approved. The answers tothe Q5 show that the subjects found customisation duringprevious studies fairly tiring.
The answers to the questions 2, 3 and 7 show that pre-diction of interface preferences is desirable feature. Sev-eral subjects said that next time they would prefer tosee settings, provided by application developers (Q8), butwould like to be able to change them any time. Interest-ingly enough, acceptance of predictions did not significantlydepend on their accuracy: for example, settings of one sub-ject, who strongly disapproved predictions, were predictedwith 100 % accuracy. This person explained that he gener-ally does not like his phone to do anything automatically.On the other hand, several subjects, whose settings were pre-dicted with fairly low accuracy, answered “Strongly Agree”to the questions 2, 3 and 7. One of these subjects explainedthe reason as “predicted settings were quite logical, a newapplication may succeed better”. Several subjects asked howpredictions work and then said that they “trust choices offriends more than choices of food companies or manufac-tures of home appliances and cars”.
7.2 Control study
The key user group participated in two fairly time-consumingstudies prior to the study on their acceptance of predictions,which may have biased their perception. Thus we decided tostudy the acceptance of predictions with another user group.This group is briefly described in “Overview of data acqui-sition” section.
For this study we developed a new version of the cookingassistant, which also provided step-by-step cooking instruc-tions. Interface customisation in this version differed fromthe earlier version because it would be infeasible to attemptat predicting preferences of absolutely unknown test sub-jects regarding the large number of customisable interfacefeatures from the original cooking assistant. Another differ-
ence from the earlier version was a greater degree of inter-face adaptation to events, happened during cooking process.In both versions contextual changes triggered automatic dis-playing of next step instructions, and in the earlier versioncontext changes also triggered notifications. However, inthe earlier version context changes did not influence inter-face layout, whereas in the new version the interface layoutcould significantly change when two users started to worktogether.
7.2.1 Application interface, functionality and customisation
As Fig. 7 shows, this cooking assistant also shows recipeinstructions in textual and visual forms, as well as overviewof steps, but its customisation is not exactly the same. Theusers can customise the GUI of this version in the followingways:
• choose image size (large or small);• choose level of image details (high, medium and low): as
Fig. 7 shows, highly detailed image could suit to userswho do not like to read long texts, e.g., children. Mediumdetailed image could suit to users who prefer visualinstructions to texts, but prefer normal texts to comics-like style, employed in the highly detailed images. Low-detailed image is intended for users who prefer textualinstructions to visual ones or are already well acquaintedwith the recipe;
• choose level of text details (high and low): high detailedtext could suit to users who like precise instructions,while low detailed text could suit for users who arealready well acquainted with the recipe or prefer to feelfree and to be creative;
• to choose, whether past and future steps will be shown oronly current step of cooking instructions will be shown,and to choose how past and future steps will be shown:just titles in equal font size, as Fig. 7 presents for thephone, or as concise instructions in fish-eye view, as Fig. 7presents for the large screen.
Similar to the previous version, in this cooking assistant dis-playing of certain step instructions was also triggered by theassociated events. For example, the smart steamer notifiedthe application when rice was cooked, and the instructionsto rinse the rice appeared automatically. In this version weused semantic user and context models, expressed in OWL.This approach allowed to describe context, concepts andrelationships between concepts in a structured way and toperform reasoning by using semantic rules. Furthermore, thisapproach provided a unified way of dynamic adaptation ofdifferent UI features to various events, such as joining ofanother person, use of cooking appliances, changing a device
123
344 J Multimodal User Interfaces (2013) 7:321–349
Fig. 7 Cooking assistant GUI. Top the high-detailed large image and fish-eye view of instructions, presented to two users on the large screen;bottom left customisation screen; bottom right personal phone GUI with small size medium detailed image and non-fish-eye overview of steps
(e.g. from big screen to small screen). For example, interpret-ing the changes in context information allowed to modify UIin both user-dependent and user-independent ways (the latterwas needed because user preferences were not acquired forsome of the UI features).
7.2.2 Study procedure
During the study a pair of subjects had to cook and decorate asalad. The task took between 30 and 45 min. In the beginning,each subject from the pair had to perform individual cookingsteps independently, e.g., one person cooked rice and madepart of salad decoration, while the other person cooked andcut eggs and made another part of the decoration. Duringthese steps one subject had to use mobile phone, and theother one used a large screen of a tablet PC mounted to thewall for interacting with the cooking assistant. The tasks weresplit between the subjects in a pair in such a way that each
of them had to wait for another person after a few steps. Atthese moments we asked the waiting subject to investigate theprovided customisation options and to choose own settingsfor individual work, if desirable; we also asked them not tohurry to continue cooking because none of the steps wastime-critical.
After the individual steps were finished, the subjects wereasked to perform several remaining steps together (such asmixing salad and finalising the decoration), looking at thelarge screen. During these steps the recipe presentation onthe large screen was adapted to combined preferences of bothsubjects, using the Union strategy. In the end we asked thesubjects to swap the screens (so that the person using the largescreen during the individual steps used the phone, and viceversa), to investigate predicted settings and to correct them, ifneeded. For these predictions we employed the Straight andCommunity strategies (the latter was employed starting fromthe fourth user group). We did not employ kNN in this study
123
J Multimodal User Interfaces (2013) 7:321–349 345
because we were interested in studying user acceptance ofpredictions of moderate accuracy.
After that the subjects filled in the questionnaire, contain-ing questions regarding acceptance of presentation style (Q1,Q2), acceptance of predictions (Q3, Q4) and acceptance ofmanual customisation (Q5–Q8):
Q1: I liked the way how cooking instructions were pre-sented to me on my deviceQ2: I liked the way how cooking instructions were pre-sented to both of us on a large screenQ3: It’s good that the cooking guide transfers settingsfrom one screen to another automaticallyQ4: It’s good that the cooking guide combines settingsof two users automaticallyQ5: If I would have cooking guide at home, I wouldappreciate possibility to change its settingsQ6: It was difficult to understand, which interface fea-tures could be changed and howQ7: Process of changing settings took too long timeQ8: I was able to customise all interface features whichI wanted to customise
The subjects had to choose for their answer one of fiveoptions: from “Strongly Disagree” to “Strongly Agree”. Inorder to summarise the answers, we assigned numerical val-ues to each option, ranging from “−2” for “Strongly Dis-agree” option to “2” for “Strongly Agree” option.
7.2.3 Study results
Figure 8 presents the summary of the answers to the ques-tionnaire.
During the study four test subjects were too interestedin cooking process to properly investigate customisable fea-tures. These subjects immediately said that default settings
Fig. 8 Average grades for the answers; question number is shown inevery bar. Striped bars refer to presentation style; grey bars refer topredictions and black bars refer to manual customisation
for the large screen are very good (all these subjects startedfrom the large screen), and then approved their predicted set-tings for the phone also without careful investigation. Othersubjects appeared to be more interested in the adaptation andtook an effort to investigate and modify default and predictedsettings. Each interface option was chosen by at least twosubjects, only low-detailed image was chosen just once (ona phone). The majority of the subjects preferred large sizehigh-detailed images and did not read instructions carefully,but several subjects appeared to prefer textual instructions tovisual ones: they have chosen med-detailed images, and oneof these subjects had chosen small image size for the largescreen—unusual choice because text area was fairly largealso with large images. Small image size was more commonchoice for a phone among young subjects (elder subjects didnot see small images well enough).
The average accuracy of the predictions in these testswas 63 % for cross-device mediation of individual prefer-ences and 92 % for group preferences. Prediction errors forgroups happened when preferences of group members forpast/ future steps differed from each other. In these casesUnion strategy suggested to show most detailed option: forexample, when one person preferred to see a fish-eye viewof past and future steps, and another one did not like to seethe past/ future steps at all, the Union strategy neverthelesssuggested to show the fish-eye view of past and future steps,and the second subject got confused and unable to quicklylocate instructions for the current step on the screen. Con-flicting preferences for levels of text and image details andimage size did not cause problems in the large screen: noneof the subjects complained about most detailed option cho-sen by Union strategy, probably because again we selectedfor the study a recipe, unknown to the subjects prior to thestudy.
As Fig. 8 shows, the majority of the subjects liked thepossibility to customise the cooking assistant and wanted tocustomise it to an even greater extent, such as to add audiointerface, an option to click on images for enlarging them(instead of zooming, which is inconvenient with dirty hands)and an option to click on step name in order to navigate tothis step. The two latter options are apparently required verymuch in practice, but we think that these features do not needto be customisable—they can be present in all interfaces. Asanswers to Q7 show, the majority of the subjects thought thatcustomisation did not take too long time. Despite that, theywell accepted cross-device predictions. Predictions for usergroups also received positive grade, but lower than for cross-device predictions due to the difficulty to satisfy both usersin cases when their preferences conflicted, which is a typicalproblem in user modelling [50].
During this study we have not observed any dependencyof acceptance of predictions on their accuracy either: fairlyoften the dissatisfied group member did not ask to correct pre-
123
346 J Multimodal User Interfaces (2013) 7:321–349
dicted settings. Instead, he/she complained during the inter-view. This behaviour may be due to the fact that fairly manypairs in this study consisted of persons who did not cooktogether frequently, if ever, prior to this study (for example,one pair consisted of mother and daughter, who said thatthey never cooked together earlier). Thus problem of findingappropriate implicit indicators of satisfaction of user groupsrequires further study.
8 Conclusion
This work studied a problem of predicting preferences ofindividuals and groups for adapting application interfaces,so far largely ignored by the research in related domains.As number of assistive applications in smart environmentsmay be fairly large, such predictions (if reasonably accu-rate) would decrease manual customisation effort, requiredfor adapting the applications to different users’ tasks, screensizes and user groups.
In particular, we presented a method for predicting a bestset of interface features from a list of options, created by inter-action designers. This list may include input/output modali-ties or various content presentation choices, such as level ofdetails, GUI layout features or levels of information visibil-ity (obtrusiveness). The proposed approach does not requireheavy computations and thus suits to ubiquitous comput-ing devices, which may have limited computing capabilities.This approach does not require collecting personal prefer-ences of large user communities and thus, depending on pri-vacy concerns of the users, can be realised in peer-to-peerfashion or as a cloud service. The experimental results showthat the proposed method is applicable to fairly wide rangeof applications and contexts and capable of recognising twoimportant preference types: the ones that strongly depend oncontext and the ones that strongly depend on a person andthus remain valid in many contexts. Adaptation to the formertype of preferences helps users to perform tasks with greaterpleasure or efficiency, whereas adaptation to the latter type ofpreferences enables consistent user experience with differentapplications.
This work was mainly concerned with a problem of inter-face adaptation at the moments of launching a new applica-tion, starting a new task or dealing with a new user group.This is more challenging problem than a problem of adaptinginterface to already encountered contexts, as in the latter caseinterface can be adapted according to the stored users’ set-tings for the appropriate context. On the other hand, in caseswhen adaptation takes place at the moment of starting newtask or new application, consistency between different inter-face versions is lesser problem than when adaptation takesplace in the course of using an application. In our study withthe shopping assistant adaptation took place only when the
test subjects started new task, and the subjects were less sur-prised by interface changes than in the second study with thecooking assistant, when adaptation to a new user group tookplace in the middle of cooking (when two subjects joint in thefront of a large screen). However, whenever adaptation takesplace, it is important to ensure that the users understand thereason for interface changes and have means to easily correctnew settings.
In this work we studied predictions of individual andgroup choices for a target situation without using any spe-cific domain knowledge (e.g., that interest in cholesterol levelmay be caused by health problems, whereas interest in pro-tein percentage is rather caused by eating habits; and thatgroups are more likely to take into account problems thanhabits). We proposed several prediction strategies, allowingto handle two common interface adaptation problems: select-ing a subset of most useful interface elements from a set ofmany possibilities, and selecting a state of an interface feature(e.g., enabled/disabled audio alarm), customisable indepen-dently on other features. As interface preferences depend onmany factors, for example on users’ goals and social rules,we proposed to employ classifier selection approach: try allapplicable prediction strategies in turn and for every inter-face feature select a strategy (or combination of strategies)that most accurately predicted choices of other users/groupsin a community regarding this interface feature.
The proposed approach was evaluated from the two pointsof view: how accurate predictions can be and whether usersaccept them or not. Prediction accuracy was evaluated offline,using interface settings of 44 users for the recipe recom-mender application and interface settings of the subset of thisgroup (21 persons) for the mobile cooking and car servicingassistants. Then user acceptance of predictions was studiedwith the same user group of 21 persons using shopping assis-tant application, and with another user group, consisting of24 persons, with another version of the cooking assistant.
In the offline tests the proposed classifier selectionapproach achieved a fairly high average prediction accuracyof 72 ± 1%, despite that the three applications, employed inthe offline tests, significantly differed in their interfaces anddomains. The accuracy of the classifier selection exceededaverage accuracies of all classifiers alone. The accuracy of thebaseline was also exceeded by 8 % on average. In the tests oncross-application mediation of preferences the average accu-racy of the classifier selection was 67±1%, which exceededthe accuracy of the baseline by almost 10 %. Comparingthese results with state of the art systems was not possible.The majority of the research on predicting preferences (e.g.,in movie recommendation domain) typically aims at predict-ing ratings, whereas interface adaptation requires predictingdecisions. However, when recommender systems are evalu-ated using some other metrics than differences between pre-dicted and actual ratings, 70–75 % of success is often consid-
123
J Multimodal User Interfaces (2013) 7:321–349 347
ered a good result. For example, the collaborative filtering—based recommender system for movies, presented in [1], wasevaluated by its precision in the top five recommendations,and precision level of 65–75 % was reported as sufficientlyhigh. The work [7] described a cross-domain recommendersystem for tourist attractions and reported that 75 % of theusers rated the system recommendations as “positive” and“very positive”, which was also considered a good result.
From the offline tests we draw several conclusions. First,the tests show that database of preferences, required forthe proposed approach, should not be too small: the pro-posed approach was not robust enough when database con-tained preferences of 10 groups only. However, the proposedapproach appeared to be more robust when database con-sisted of data from 14 groups, and fairly reliable when thedatabase included preferences of more than 21 individualsand groups.
Second, the tests show that in many cases the kNN methodpredicts interface preferences reasonably accurate, and thususers, who customised one application in similar ways, tosome extent remain similar to each other also in other con-texts. However, the tests show that the degree of similar-ity between individuals and groups may significantly changewhen context changes: we compared kNN, which ignoresdegree of similarity between neighbours when making pre-dictions, with more frequently used in the recommender sys-tems CF (collaborative filtering) approach that takes thisdegree of similarity into account. Although the accuraciesof both methods were similar to each other in cases of sim-ilar initial and target contexts, kNN was significantly betterwhen initial and target contexts differed significantly, as forexample in tests on cross-application mediation of prefer-ences.
Third, the tests show that we need to find better ways to uselonger interaction histories: in our tests longer interaction his-tory did not always increase prediction accuracy. We wouldbe interested to employ more sophisticated machine learningmethods, for example, for detecting, which initial contextsare most similar to the target context. It would be also inter-esting to detect latent factors affecting users’ choices, e.g.,it may happen that a person generally prefers reactive appli-cations to proactive ones. For predicting group preferencesit could be useful to detect group leaders from the data (i.e.,users who significantly influence group choices): this wouldrequire data where each user participates in group work inseveral groups. Collecting more data would also allow study-ing how user similarity measure could be adapted to specificsof each context transition. For example, the work [47]suggested to learn user similarity measure by differential evo-lution algorithm. The results show that such learning can beindeed beneficial in cases when users’ preferences are fairlysimilar to each other in the initial context, but differ signifi-cantly in the target context.
The tests also show that it is feasible to employ theCommunity strategy for predicting preferences of new users(i.e., users whose preferences are not known for any con-text) because prediction accuracy of this strategy alone wasnot dramatically low: 64 ± 1 % on average. Neverthelesswe suggest employing classifier selection whenever possiblebecause the Community strategy succeeds well only in con-texts that significantly influence users’ choices. In other con-texts the Community strategy may predict standard choicesfairly accurately, but at the cost of producing significantlyhigher number of erroneous predictions for not-so-typicalusers. In contrast, the classifier selection results in smootherdistribution of errors among users and thus may result inhigher overall satisfaction.
During studies on user acceptance of predictions 76 % ofthe subjects expressed their approval of predictions. Partlythis may be due to the fairly high average prediction accuracy,achieved in the studies on user acceptance. With a greaternumber of customisable features in the target interfaces pre-diction accuracy may decrease, or use of larger databases ofinterface settings would be needed for maintaining predictionaccuracies on the same level. On the other hand, the work [13]has shown that when a screen size is small, even a predictionaccuracy as low as 50 % is already beneficial for users. Ourtests on user acceptance of predictions with two different usercommunities are in agreement with this finding: in these testsfor some of the subjects prediction accuracy was as low as 42%, but nevertheless they accepted predictions. On the otherhand, we found that a high accuracy of predictions does notguarantee user acceptance: first, some persons may simplydislike any automated actions of their applications. Second,during the last study in cases of conflicting user preferencesit happened that only one person in a pair liked the predictedsettings, while another one disliked, but did not do or sayanything. Unfortunately during the study with the first usercommunity we did not study acceptance of predictions forgroups, but we believe that for this user community erro-neously predicted group settings would be a lesser problem:in all cases when group settings were chosen by the subjectsmanually, all subjects exchanged their opinions freely andwith humour.
It is also worth noting that although there are four majortypes of relationships in the groups [14], we observed justtwo of them in our studies. The groups in the first user com-munity displayed “community sharing” behaviour type inthe cooking domain: preferences of all group members wereequally respected. In interactions with the car assistant thegroups rather followed “authority ranking” behavioural pat-tern: more experienced persons and male group memberswere treated as authority. In the second user community wenoticed both behavioural patterns in interactions with thecooking assistant: in some groups we observed equality ofmembers, whereas in other groups more experienced per-
123
348 J Multimodal User Interfaces (2013) 7:321–349
sons were treated as authority. During the studies we did notobserve trading of preferences, corresponding to “equalitymatching” and “market pricing” relations: group memberssacrificed own wishes without attempting at trading them.One of the reasons is that test subjects in our studies were fam-ily members and close friends, whereas trading is more com-mon in not-so-warm relations. Another reason could be dura-tion of studies: trading of interface preferences may requirelong-term records of gives-and-takes.
One more issue with respect to user satisfaction in socialcontext is a problem of dealing with low-confidence predic-tions. During the user studies with the first user communityseveral subjects suggested that in such cases devices shouldbehave so that the device owner would look more polite thanthe device: e.g., a phone should use settings of the deviceowner, and the device owner would look well sacrificing his/her preferences. However, this issue requires further study.
In summary, it can be said that the proposed methodachieved a fairly high average prediction accuracy and thatboth user communities accepted predictions fairly well,despite the differences in their attitudes to the applications:the first user community was less happy with the num-ber of customisable options than the second one, and per-ceived manual customisation as much more time-consumingprocess than the second community. We believe these resultsto be promising enough to warrant further research in thisdirection, moreover that the problem of predicting inter-face preferences will become ever more important with theincrease of smart environments.
Acknowledgments This research was carried out within the SmartProducts EU project, Grant Number 231204. We would like to thankall test subjects for their good will and thorough comments, and wewould like to thank Steven Luitjens, Wenzhu Zou (Philips Research,The Netherlands) and Niklas Lochschmidt (TUD) for their efforts toconduct the control study.
References
1. Adomavicius G, Kwon Y (2007) New recommendation techniquesfor multicriteria rating systems. IEEE Intell Syst 22(3):48–55
2. Anand D, Bharadwaj K (2010) Adaptive user similarity measuresfor recommender systems: a genetic programming approach. In:Proceedings of ICCSIT, pp 121–125
3. Avouac P-A, Lalanda P, Nigay L (2012) Adaptable multi-modal interfaces in pervasive environments. In: Proceedings ofIEEE consumer communications and networking conference,pp 544–548
4. Baltrunas L, Ludwig B, Peer S, Ricci F (2012) Context relevanceassessment and exploitation in mobile recommender systems. PersUbiquitous Comput 16(5):507–526
5. Berkovsky Sh, Kuflik T, Ricci F (2008) Mediation of user modelsfor enhanced personalisation in recommender systems. UMUAI18:245–286
6. Berkovsky Sh, Freyne J (2010) Group-based recipe recommen-dations: analysis of data aggregation strategies. In: ProceedingsRecSys2010, pp 111–118
7. Blanco-Fernandez Y, Lopez-Nores M, Pazos-Arias JJ, Gil-Solla A,Ramos-Cabrer M (2010) Exploiting digital TV users’ preferencesin a tourism recommender system based on semantic reasoning.IEEE Trans Consumer Electron 56(2):904–912
8. Böhmer M, Bauer G (2010) Exploiting the icon arrangementon mobile devices as information source for context-awareness.Mobile HCI
9. Carmagnola F, Cena F, Gena C (2011) User model interoperability:a survey. UMUAI 21:285–331
10. Chen Y-L, Cheng L-C, Chuang C-N (2008) A group recommenda-tion system with consideration of interactions among group mem-bers. Expert Syst Appl 34(3):2082–2090
11. Dey A, Newberger A (2009) Support for context-aware intelligi-bility and control. In: Proceedings of the SIGCHI conference onhuman factors in computing systems (CHI), pp 859–868
12. Dumas B, Lalanne D, Oviatt Sh (2009) Multimodal interfaces:a survey of principles, models and frameworks. In: Lalanne D,Kohlas J (eds) Human machine interaction. Springer, Berlin, pp3–26
13. Findlater L, Mcgrenere J (2008) Impact of screen size on perfor-mance, awareness, and user satisfaction with adaptive graphicaluser interfaces. In: Proceedings of CHI 08, pp 1247–1256
14. Fiske AP (1992) The four elementary forms of sociality: frameworkfor a unified theory of social relations’. Psychol Rev 99:689–723
15. Florins M, Simarro FM, Vanderdonckt J, Michotte B (2006) Split-ting rules for graceful degradation of user interfaces. In: Proceed-ings of IUI, pp 264–266
16. Gajos K, Weld D, Wobbrock J (2010) Automatically generatingpersonalized user interfaces with Supple. Artif Intell 174:910–950
17. Gil M, Giner P, Pelechano V (2012) Personalization for unobtrusiveservice interaction. Pers Ubiquitous Comput 16(5):543–561
18. Grimes A, Harper R (2008) Celebratory technology: new directionsfor food research in HCI, CHI
19. Gulz A, Haake M, Silvervarg A, Sjödén B, Veletsianos G(2011) Building a social conversational pedagogical agent—designchallenges and methodological approaches. In: Perez-Marin D,Pascual-Nieto I (eds) Conversational agents and natural languageinteraction: techniques and effective practices. IGI Global, pp 128–155
20. van der Heijden H (2003) Ubiquitous computing, user control, anduser performance: conceptual model and preliminary experimentaldesign. In: Proceedings of the research symposium on emergingelectronic markets, pp 107–112
21. Horchani M, Caron B, Nigay L, Panaget F (2007) Natural multi-modal dialogue systems: a configurable dialogue and presentationstrategies component. In: ICMI, pp 291–298
22. Jameson A, Smyth B (2007) Recommendation to groups. In:Brusilovsky P, Kobsa A, Nejdl W (eds) The adaptive web, pp 596–627
23. Ko A, Sabourin R, Britto A (2008) From dynamic classifier selec-tion to dynamic ensemble selection. Pattern Recognit 41:1718–1731
24. Kong J, Zhang WY, Yu N, Xia XJ (2011) Design of human-centricadaptive multimodal interfaces. Int J Hum Comput Stud 69:854–869
25. Konstan JA, Riedl J (2012) Recommender systems: from algo-rithms to user experience. User Model User Adapt Interact 22(1–2):101–123
26. Limbourg Q, Vanderdonckt J, Michotte B, Bouillon L, López-Jaquero V (2005) Usixml: a language supporting multi-path devel-opment of user interfaces. In: Bastide R, Palanque P, Roth J (eds)Engineering human computer interaction and interactive systems,vol 3425 of, Lecture Notes in Computer Science, pp 134–135
27. Lü L, Medo M, Yeung Ch, Zhang Y-Ch, Zhang Z-K, Zhou T (2012)Recommender systems review article. Phys Rep 519(1):1–49
123
J Multimodal User Interfaces (2013) 7:321–349 349
28. Luyten K, Thys K, Vermeulen J, Coninx K (2007) A genericapproach for multi-device user interface rendering with UIML.Comput Aided Des User Interfaces 175–182
29. Masthoff J, Gatt A (2006) In pursuit of satisfaction and the pre-vention of embarrassment: affective state in group recommendersystems. User Model User Adapt Interact 16(3–4):281–319
30. Meskens J, Luyten K, Coninx K (2010) Jelly: a multi-device designenvironment for managing consistency across devices. In: Proceed-ings of AVI, pp 289–296
31. Moreno R, Mayer RE, Spire HA, Lester JC (2001) The case forsocial agency in computer-based teaching: do students learn moredeeply when they interact with animated pedagogical agents? Cog-nit Instr 19(2):177–213
32. Nichols J, Myers B, Harris T, Rosenfeld R, Shriver S, Higgins M,Hughes J (2002) Requirements for automatically generating multi-modal interfaces for complex appliances. In: Proceedings of the 4thIEEE conference on multimodal, interfaces, 2002, pp 377–382
34. Park D, Kim H, Choi I, Kim J (2012) A literature review andclassification of recommender systems research. Expert Syst Appl39(11):10059–10072
35. Perez-Mateo M, Guitert M (2012) Which social elements are vis-ible in virtual groups? Addressing the categorization of socialexpressions. Comput Educ 58(4):1234–1246
36. Reeves LM, Lai J, Larson JA, Oviatt S, Balaji TS, Buisine Sp,Collings P, Cohen P, Kraal B, Martin J-C, McTear M, Raman T,Stanney KM, Su H, Wang QY (2004) Guidelines for multimodaluser interface design. Commun ACM 47(1):57–59
37. Reis T, de Sá M, Carriço L (2008) Multimodal interaction: realcontext studies on mobile digital artefacts. In: Proceedings of hapticand audio interaction design HAID 2008
38. Remesal A, Colomina R (2013) Social presence in online smallcollaborative group work: a socioconstructivist account. ComputEduc 60:357–367
39. Ricci F (2011) Mobile recommender systems. Intl J Inf TechnolTour 12(3):205–231
40. Ronkainen S, Koskinen E, Liu Y, Korhonen P (2010) Environmentanalysis as a basis for designing multimodal and multidevice userinterfaces. Hum Comput Interact 25(2):148–193
41. Rousseau C, Bellik Y, Vernier F, Bazalgette D (2006) A frameworkfor the intelligent multimodal presentation of information. SignalProcess 86(12):3696–3713
42. Sarter N (2006) Multimodal information presentation: design guid-ance and research challenges. Int J Ind Ergon 36:439–445
43. Senot Ch, Kostadinov D, Bouzid M, Picault J, Aghasaryan ABernier C (2010) Analysis of strategies for building group profiles.In: Proceedings of UMAP
44. Trewin Sh, Zimmermann G, Vanderheiden G (2003) Abstractuser interface representations: how well do they support universalaccess? In: Proceedings of the conference on universal usability,2003, pp 77–84
45. Vildjiounaite E, Kyllönen V, Hannula T, Alahuhta P (2009) Unob-trusive dynamic modelling of TV programme preferences in afinnish household. Multimed Syst 3:143–157
46. Vildjiounaite E, Kantorovitch J, Kyllönen V, Niskanen I, HillukkalaM, Virtanen K, Vuorinen O, Mäkelä S, Keränen T, Peltola J, Män-tyjärvi J, Tokmakoff A (2011) Designing socially acceptable mul-timodal interaction in cooking assistants. Proc IUI 11:415–418
47. Vildjiounaite E, Kyllönen V, Mäntyjärvi J (2011) If their car talksto them, shall a kitchen talk too? Cross-context mediation of inter-action preferences. In: Proceedings of EICS 2011, pp 111–116
48. Wasinger R, Wahlster W (2006) Multi-modal human-environmentinteraction. In: Aarts E, Encarnação J (eds) True visions. Springer,Berlin, pp 291–306
49. Safeguards in a world of ambient intelligence. Wright D, GutwirthS, Friedewald M, Vildjiounaite E, Punie Y (2008) Springer, Berlin
50. Yu Z, Zhou X, Hao Y, Gu J (2006) TV program recommendationfor multiple viewers based on user profile merging. User ModelUser Adapt Interact 16:63–68