Predictive Analytics for Customer Targeting A Telemarketing Banking Example Pedro Écija Serrano ¦ Independent actuarial and data analytics consultant ¦ [email protected]¦ https://datadriven.ie/
Transcript
Predictive Analytics for Customer Targeting
A Telemarketing Banking Example
Pedro Écija Serrano ¦ Independent actuarial and data analytics consultant ¦ [email protected] ¦ https://datadriven.ie/
Agenda• The Problem (3)• The Solutions (21)• The Insight (17)• The End? (1)
Predictive Analytics for Customer Targeting
• Acknowledgement: [Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. They made the database public.
• Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science. They host this dataset and many more!
• The goal is to identify customers likely to purchase a bank deposit in future sales campaigns.
• 41,188 calls.• 11% purchased the product.• 20 input variables.
Predictive Analytics for Customer Targeting
What we know:• Age• Job• Marital Status• Education• Default: has the customer defaulted on a loan?• Housing: has the customer got a mortgage?• Loan: has the customer got a personal loan?• Contact: if the customer was called to a landline or a mobile phone• Month: calendar month of the last contact the bank had with the customer• Day_Of_Week: day of the week of the last contact the bank had with the customer• Duration: call duration of the last contact the bank had with the customer – Not used• Campaign: number of times the bank contacted the client in the last sales campaign• Pdays: number of days since the bank contacted the client for a previous sales campaign• Previous: number of contacts with the client prior to the last sales campaign• Poutcome: outcome of the previous sales campaign (whether the customer bought the product or not)• Emp.var.rate: employment variation rate• Cons.price.idx: consumer price index• Cons.conf.idx: consumer confidence index• Euribor3m: Euribor’s three month rate• Nr. Employed: number of individuals employed by the bank?
Predictive Analytics for Customer Targeting
There are too many customers that do not buy the product. This is known as class imbalance and will affect the performance of the classifiers, which will be biased towards non-buyers as there are so many more than buyers.
I have considered the following to address this issue:• Doing nothing• Over sampling• Under sampling• Balanced sampling• Generating synthetic data (with SMOTE)
Predictive Analytics for Customer Targeting
• Naive Bayes• Support Vector Machines
– Linear kernel– Polynomial kernel– Radial kernel– Sigmoid kernel
• Decision Tree• Currently in quarantine:
– Random Forests– K Nearest Neighbours– Gradient Boosting
Dataset divided in training set (2/3) and testing set (1/3)To address the class imbalance problem, we can do the following for all the above methods:• Nothing• Over sample• Under sample• Balance sample• Generate synthetic data
Predictive Analytics for Customer Targeting
Naive BayesIt uses conditional probabilities, based on Bayes’ theorem,
allocating an observation to its most probable class.
It assumes variables are normally distributed and not correlated, which is rarely the case. However the classifier normally does a good job even when assumptions are not met.
We end up with the following classifiers:• VNB – Vanilla naive Bayes• OSNB – Over sampled naive Bayes• USNB – Under sampled naive Bayes• BNB – Balanced sampled naive Bayes• SynthNB – Syntethic data naive Bayes
Predictive Analytics for Customer Targeting
Support Vector MachinesIt constructs hyperplanes in a multidimensional space
that separates cases of different class labels
To find an optimal hyperplane, SVM uses an iterative training algorithm used to minimise an error function.
The hyper plane does not need to be a straight line. The kernel trick allows for non-linear classification. Possible kernels are:
• Linear• Polynomial• Radial• Sigmoid
Predictive Analytics for Customer Targeting
Support Vector MachinesThe combination of methods to solve the class imbalance problem and
kernels results in the following different classifiers:
Do nothing Over sample Under sample Balanced sample
Synthetic data
Linear VSVMLin OSSVMLin USSVMLin BSSVMLin SynthSVMLin
Decision TreeIt splits the dataset into subsets based on an attribute value test.
It continues through recursive partitioning until the dataset has been explained.
We obtain the following classifiers:•VTree•OSTree•USTree•BSTree•SynthTree
Predictive Analytics for Customer Targeting
Predictive Analytics for Customer Targeting
Predictive Analytics for Customer Targeting
Focusing on the bottom left corner
Predictive Analytics for Customer Targeting
Focusing on the mid tier classifiers
Predictive Analytics for Customer Targeting
Focusing on the top right corner
Predictive Analytics for Customer Targeting
Focusing on methods where nothing was done for class imbalance
Predictive Analytics for Customer Targeting
Focusing on methods with synthetic data
Predictive Analytics for Customer Targeting
Focusing on under sampled methods
Predictive Analytics for Customer Targeting
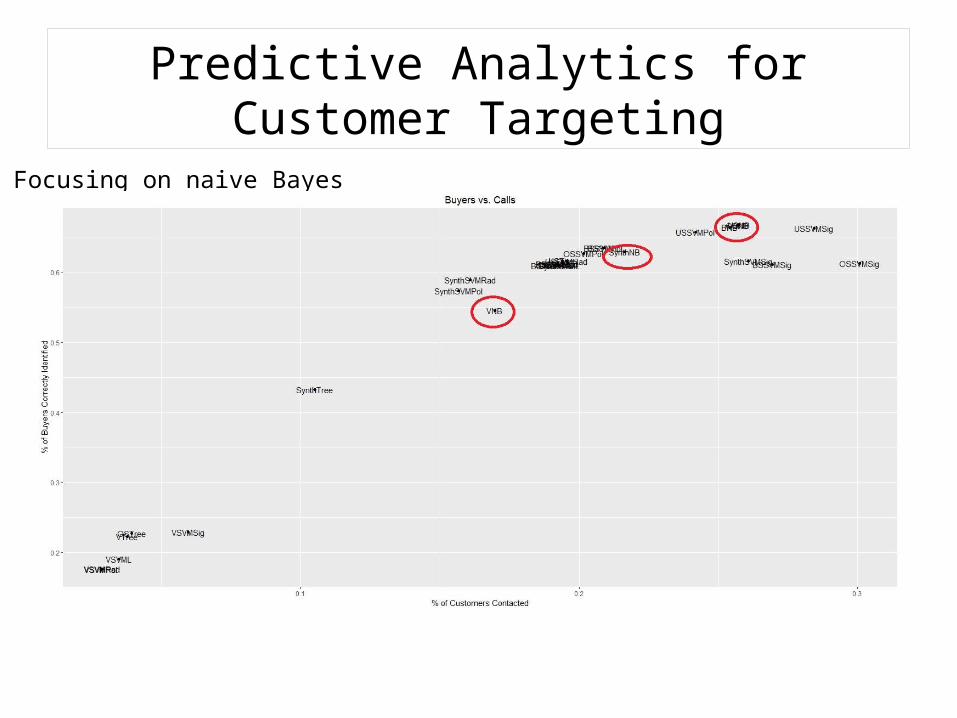
Focusing on naive Bayes
Predictive Analytics for Customer Targeting
Focusing on SVM Sigmoid
Predictive Analytics for Customer Targeting
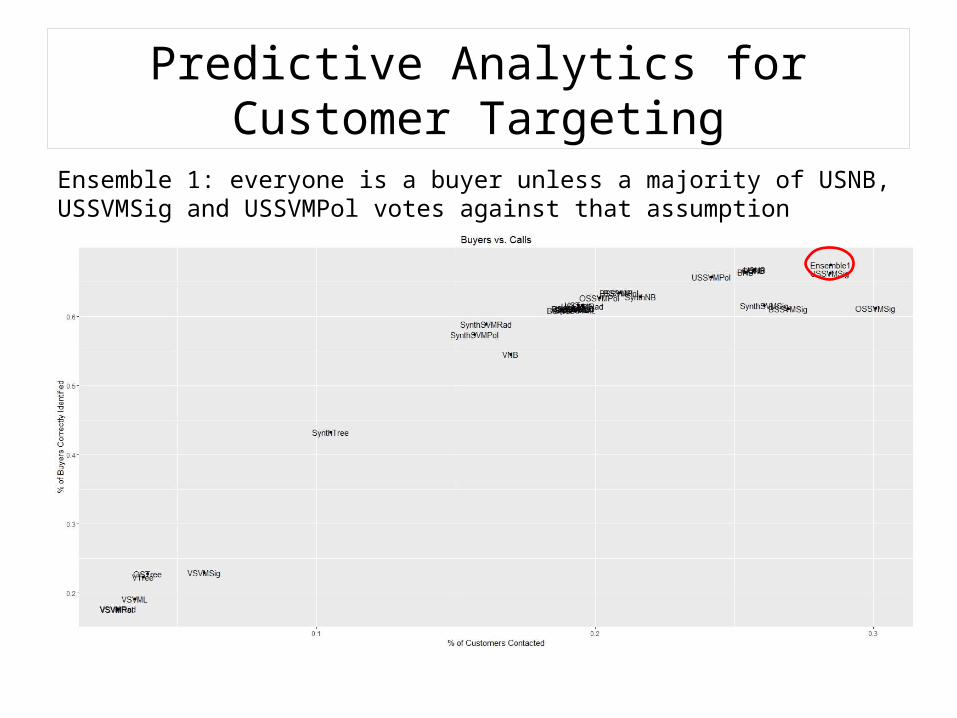
Ensemble 1: everyone is a buyer unless a majority of USNB, USSVMSig and USSVMPol votes against that assumption
Predictive Analytics for Customer Targeting
Ensemble 2: everyone is a buyer unless USNB and USSVMSig agree to the opposite
Predictive Analytics for Customer Targeting
Putting it all in context: the testing data set has 1,516 buyers among 13,729 customers
USNBBuyers: 1,011Calls: 3,529
VSVMRadBuyers: 273Calls: 399
SynthTreeBuyers: 654Calls: 1,442
Ensemble 1Buyers: 1,023Calls: 3,913
Ensemble 2Buyers: 1,052Calls: 4,256
Predictive Analytics for Customer Targeting
Comparison of percentage of buyers per call
Predictive Analytics for Customer Targeting
So, are the results good at all?We can predict...
•Nearly 18% of buyers with 3% of calls using VSVMRad
•More than 22% of buyers with 4% of calls thanks to VTree
•43% of buyers with a bit more than 10% of calls using SynthTree
•Almost 60% of buyers with 16% of calls using SynthSVMRad
•Nearly 67% of buyers with 26% of calls using USNB
•Close to 70% of buyers with 31% of calls using Ensemble 2
Predictive Analytics for Customer Targeting
So, are the results good at all?Applying the results to the original dataset:
Method Buyers Calls
VSVMRad 801 1,195
VTree 1,010 1,566
SynthTree 1,956 4,325
SynthSVMRad 2,668 6,632
USNB 3,021 10,586
Ensemble 2 3,143 12,769
Calling everybody 4,530 41,188
Predictive Analytics for Customer Targeting
After all that, what can we say about buyers? Is there a typical buyer? What conditions favour a sale?
Image source: Pixabay / Gerd Altmann
Predictive Analytics for Customer Targeting
According to the USTree, the following is important:
•Not employing more than 5,088 people
•Not contacting customers in August, December, July, June, May or November
•The consumer price index being lower than 94
•Previous contact with the customer happening less than 506 days ago
Predictive Analytics for Customer Targeting
Image source: Pixabay / No attribution required
Predictive Analytics for Customer Targeting
We have no easy way to learn from SVM what predictors are more important so we focus on the distributions of buyers vs. non buyers in the original dataset plus the probabilities USNB has calculated for each class.
USNB predicts more buyers than any other method we have tried so far so it may give us more information too.
Predictive Analytics for Customer TargetingAge
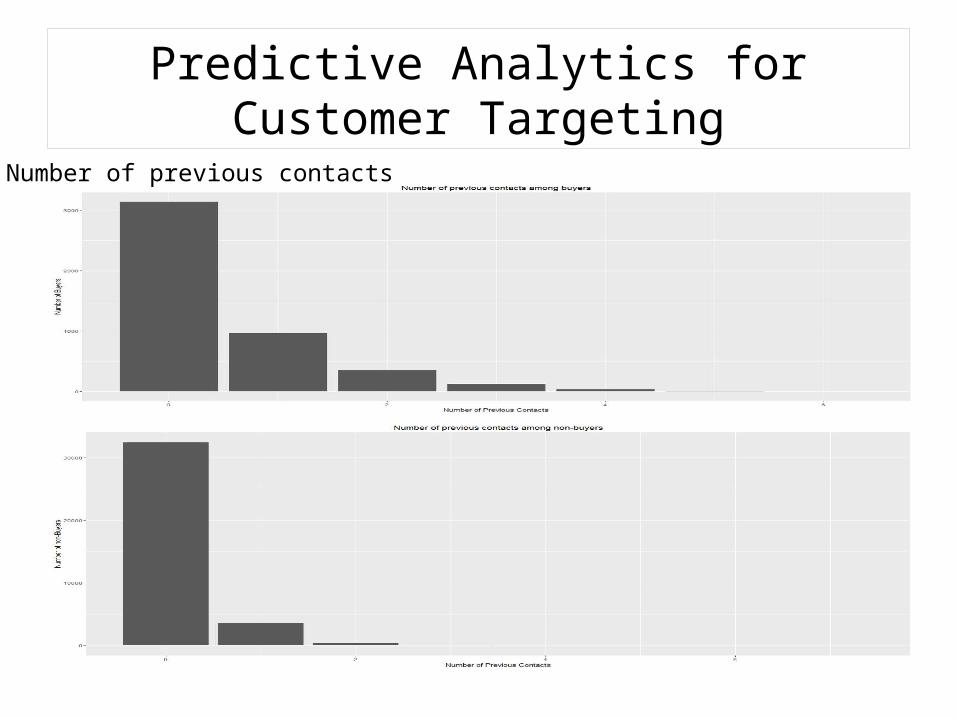
Predictive Analytics for Customer TargetingNumber of previous contacts
Predictive Analytics for Customer TargetingCalling a landline or a mobile phone
Predictive Analytics for Customer TargetingCalling on a specific day of the week
Predictive Analytics for Customer TargetingDefaulting customers
Predictive Analytics for Customer TargetingEducation levels
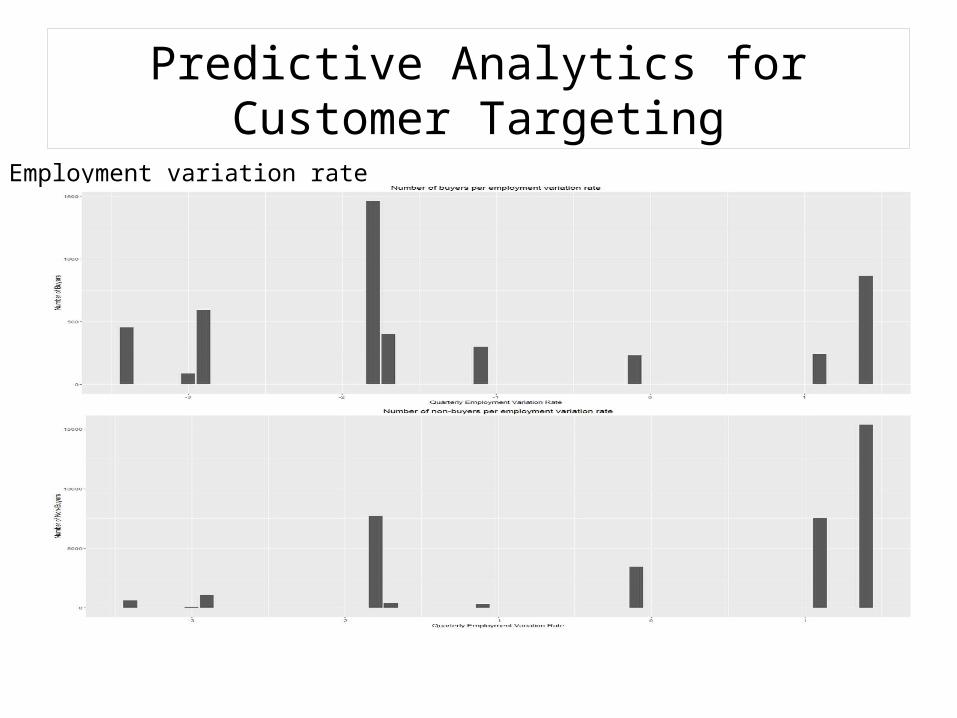
Predictive Analytics for Customer TargetingEmployment variation rate
Predictive Analytics for Customer TargetingJob
Predictive Analytics for Customer TargetingMarital status
Predictive Analytics for Customer TargetingCalendar month
Predictive Analytics for Customer TargetingPrevious outcome
Predictive Analytics for Customer Targeting
Did we learn anything this time?
Timing is a very important factor:
• Customers are more inclined to buy the product when economic conditions deteriorate.
• Specific months seem more favourable. This could be linked to a specific political situation in Portugal, tax considerations, holidays or be related to other variables such as employment rates, interest rates, etc.
The prototype buyer is an existing customer, well educated, mobile phone user, with no family responsibilities (student or retired) and who has not defaulted in a loan before.
Predictive Analytics for Customer Targeting
The End?
Is there anything else that we can do to further improve the results?
•Feature engineering•Try other ways to overcome class imbalance•Save KNN, Random Forest and Gradient Boosting from the quarantine!•Try other classification algorithms (logistic regression, Boosted C5.0, etc)•Further explore already tried methods with more parameter tuning•More ensembles•Neural network?
However, we should consider that exploring the above will deliver small increments of predictive power and require additional hours of work with long computing times. Would it be worth the effort?