Prelim Notes for Numerical Analysis * Wenqiang Feng † Abstract This note is intended to assist my prelim examination preparation. You can download and distribute it. Please be aware, however, that the note contains typos as well as incorrect or inaccurate solutions . At here, I also would like to thank Liguo Wang for his help in some problems. This note is based on the Dr. Abner J. Salgado’s lecture note [4]. Some solutions are from Dr. Steven Wise’s lecture note [5]. * Key words: UTK, PDE, Prelim exam, Numerical Analysis. † Department of Mathematics,University of Tennessee, Knoxville, TN, 37909, [email protected]1
Transcript
Prelim Notes for Numerical Analysis ∗
Wenqiang Feng †
Abstract
This note is intended to assist my prelim examination preparation. You can download and distributeit. Please be aware, however, that the note contains typos as well as incorrect or inaccurate solutions . Athere, I also would like to thank Liguo Wang for his help in some problems. This note is based on the Dr.Abner J. Salgado’s lecture note [4]. Some solutions are from Dr. Steven Wise’s lecture note [5].
∗Key words: UTK, PDE, Prelim exam, Numerical Analysis.†Department of Mathematics,University of Tennessee, Knoxville, TN, 37909, [email protected]
Properties 1.2. (Type of Matrices) Let A= [Aij ] be a square or rectangular matrix, A is called
• Hermitian : if A∗ = A,
• symmetric : if AT = A,
• normal : if ATA = AAT ,when A ∈ Rn×n,if A∗A= AA∗,when A ∈ Cn×n,
• skew hermitian : if A∗ = −A,
• skew symmetric : if AT = −A,
• orthogonal : if ATA = I ,when A ∈ Rn×n,unitary : if A∗A= I ,when A ∈ Cn×n.
Properties 1.3. (Properties of invertible matrices) Let A be n×n square matrix. If A is invertible , then
• det(A) , 0,
• rank(A) = n,
• Ax = b has a unique solution for every b ∈Rn
• the row vectors are linearly independent ,
• the row vectors of A form a basis for Rn.
• the row vectors of A span Rn.
• nullity(A) = 0,
• λi , 0, (λi eigenvalues),
• Ax = 0 has only trivial solution,
• the column vectors are linearly independent ,
• the column vectors of A form a basis for Rn,
• the column vectors of A span Rn.
Properties 1.4. (Properties of conjugate transpose) Let A,B be n × n square matrix and γ be a complexconstant, then
• (A∗)∗ = A,
• (AB)∗ = B∗A∗,
• (A+B)∗ = A∗+B∗,
• det(A∗) = det(A)
• tr(A∗) = tr(A)
• (γA)∗ = γ∗A∗.
Properties 1.5. (Properties of similar matrices) If A ∼ B , then
• det(A) = det(B),
• eig(A) = eig(B),
• A ∼ A,
• rank(A) = rank(B),
• if B ∼ C, then A ∼ C
• B ∼ A
Page 5 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 6
Properties 1.6. (Properties of Unitary Matrices) Let A be a n×n Unitary matrix, then
• A∗ = A−1,
• A∗ is unitary,
• A is diagonalizable,
• A is unitarily similar to a diagonal matrix ,
• the row vectors of A form an orthonormal set,
• A∗ = I ,
• A is an isometry.
• the column vectors of A form an orthonormalset.
Properties 1.7. (Properties of Hermitian Matrices) Let A be a n×n Hermitian matrix, then
• its eigenvalues are real ,
• A is unitarily diagonalizable (Spectral theo-rem ),
• vi∗vj = 0, i , j , vi ,vj eigenvectors,
• A = H + K , H is Hermitian and K is skew-Hermitian,
Properties 1.8. (Properties of positive definite Matrices) Let A ∈ Cn×n be a positive definite Matrix andB ∈ Cn×n, then
• σ (A) ⊂ (0,∞),
• A is invertible,
• if B is invertible, B∗B positive semidefinite ,
• if A is positive semidefinite then diag(A) ≥ 0,
• if A is positive definite then diag(A) > 0.
• B∗B is positive semidefinite
Properties 1.9. (Properties of determinants) Let A,B be n × n square matrix and α be a real constant,then
• det(AT ) = det(A),
• det(αA) = αndet(A),
• det(AB) = det(A)det(B),
• det(A−1) = 1det(A)
= det(A)−1.
Properties 1.10. (Properties of inverse) Let A,B be n×n square matrix and α be a real constant, then
• (A∗)−1 = (A−1)∗,
• (A−1)−1 = A,
• (AB)−1 = B−1A−1,
• (αA)−1 = 1αA−1
• A=
(a bc d
), A−1 = 1
ad−bc
[d −b−c a
].
Properties 1.11. (Properties of Rank) Let A be m × n matrix, B be n ×m matrix and P ,Q are invertiblen×n matrices, then
• rank(A) ≤minm,n,
• rank(A) = rank(A∗),
• rank(A) + dim(ker(A)) = n,
• rank(AQ) = Rank(A) = Rank(PA),
• rank(PAQ) = Rank(A),
• rank(AB) ≥ rank(A) + rank(B)−n,
• rank(AB) ≤minrank(A),rank(B),
• rank(AB) ≤ rank(A) + rank(B).
Page 6 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 7
1.1.2 Similar and diagonalization
Theorem 1.1. (Similar) A is said to be similar to B, if there is a nonsingular matrix X, such that
A= XBX−1, (A ∼ B).
Theorem 1.2. (Diagonalizablea) A matrix is diagonalizable , if and only if there exist a nonsingularmatrix X and a diagonal matrix D such that A= XDX−1.
aBeing diagonalizable has nothing to do with being invertible.
Theorem 1.3. (Diagonalizable) A matrix is diagonalizable , if and only if all its eigenvalues are semisimple.
Theorem 1.4. (Diagonalizable) Suppose dim(A) = n. A is said to be diagonalizable , if and only if A hasn linearly independent eigenvectors .
Corollary 1.1. (Sample question #2, summer, 2013 ) Suppose dim(A) = n. IfA has n distinct eigenvalues, then A is diagonalizable .
Proof. (Sketch) Suppose n= 2, and let λ1,λ2 be distinct eigenvalues of A with corresponding eigenvectorsv1,v2. Now, we will use contradiction to show v1,v2 are lineally independent. Suppose v1,v2 are lineallydependent, then
c1v1 + c2v2 = 0, (1)
with c1,c2 are not both 0. Multiplying A on both sides of (210), then
c1Av1 + c2Av2 = c1λ1v1 + c2λ2v2 = 0. (2)
Multiplying λ1 on both sides of (210), then
c1λ1v1 + c2λ1v2 = 0. (3)
Subtracting (212) form (211), then
c2(λ2 −λ1)v2 = 0. (4)
Since λ1 , λ2 and v2 , 0, then c2 = 0. Similarly, we can get c1 = 0. Hence, we get the contradiction.A similar argument gives the result for n. Then we get A has n linearly independent eigenvectors .
Theorem 1.5. (Diagonalizable) Every Hermitian matrix is diagonalizable , In particular, every realsymmetric matrix is diagonalizable.
1.1.3 Eigenvalues and Eigenvectors
Theorem 1.6. if λ is an eigenvalue of A, then λ is an eigenvalue of A∗.
Theorem 1.7. The eigenvalues of a triangular matrix are the entries on its main diagonal.
Page 7 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 8
Theorem 1.8. Let A be square matrix with eigenvalue λ and the corresponding eigenvector x.
• λn,n ∈Z is an eigenvalue of An with corresponding eigenvector x,
• if A is invertible, then 1/λ is an eigenvalue of A−1 with corresponding eigenvector x.
Theorem 1.9. Let A be n×n square matrix and let λ1,λ2, · · · ,λm be distinct eigenvalues of A with corre-sponding eigenvectors v1,v2, · · · ,vm. Then v1,v2, · · · ,vm are linear independent.
1.1.4 Unitary matrices
Definition 1.1. (Unitary Matrix) A matrix A ∈ Cn×n is said to be unitary a, if
A∗A= I .aA matrix A ∈Rn×n is said to be orthogonal , if
ATA= I .
Theorem 1.10. (Angle preservation) A matrix is unitary , then the transformation defined by A preservesangles.
Proof. For any vectors x,y ∈ Cn that is angle θ is determined from the inner product via cosθ =<x,y>‖x‖‖y‖ .
Since A is unitary (and thus an isometry), then
< Ax,Ay >=< A∗Ax,y >=< x,y > .
This proves the Angle preservation.
Theorem 1.11. (Angle preservation) A matrix is real orthogonal , then A has the transformation formT (θ) for some θ
A=
[1 00 −1
]T (θ) =
[cos(θ) sin(θ)sin(θ) −cos(θ)
](5)
Finally, we can easily establish the diagonalzableility of the unitary matrices.
Theorem 1.12. (Shur Decomposition) A matrix A ∈ Cn×n is similar to a upper triangular matrix and
A= UTU−1, (6)
where U is a unitary matrix , T is an upper triangular matrix .
Proof. see Appendix (??)
Theorem 1.13. (Spectral Theorem for Unitary matrices) A is unitary , then A is diagonalizable and A isunitarily similar to a diagonal matrix .
A= UDU−1 = UDU ∗, (7)
where U is a unitary matrix , D is an diagonal matrix .
Page 8 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 9
Proof. Result follows from 1.12.
Theorem 1.14. (Spectral representiation) A is unitary , then
1. A has a set of n orthogonal eigenvectors,
2. let v1,v2, · · · ,vn be the eigenvalues w.r.t the corresponding orthogonal eigenvectors λ1,λ2, · · · ,λn.The A has the representation as the sum of rank one matrices given by
A=n∑i=1
λivivTi . (8)
Note: this representation is often called the Spectral Representation or Spectral Decomposition of A.
Proof. see Appendix (??)
1.1.5 Hermitian matrices
Definition 1.2. (Hermitian Matrix) A matrix is Hermitian , if
A∗ = A.
Definition 1.3. Let A be Hermitian , then the spectral of A, σ (A), is real.
Proof. Let λ ∈ σ (A) with corresponding eigenvector v. Then
< Av,v > = < λv,v >= λ < v,v > (9)
< Av,v > = < v,A∗v >=< v, λv >= λ < v,v > . (10)
Since < v,v >, 0,therefore λ= λ. Hence λ is real.
Definition 1.4. Let A be Hermitian , then the different eigenvector are orthogonal i.e.
< vi ,vj >= 0, i , j. (11)
Proof. Let λ1,λ2 be the arbitrary two different eigenvalues with corresponding eigenvector v1,v2. Then
Let k be the index, s.t: |λn|= ρ(A) and x = ek ,Ax = Aek = λnek , so ‖Ax‖`2 = |λn|= ρ(A) and
‖A‖2 = supx∈Cn
‖Ax‖`2
‖x‖`2≥ ‖
Ax‖`2
‖x‖`2= ρ(A).
Page 10 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 11
1.1.6 Positive definite matrices
Definition 1.5. (Positive Definite Matrix)
1. A symmetric real matrix A ∈Rn×n is said to be Positive Definite , if
xTAx > 0, ∀x , 0.
2. A Hermitian matrix A ∈ Cn×n is said to be Positive Definite , if
x∗Ax > 0, ∀x , 0.
Theorem 1.18. Let A,B ∈ Cn×n. Then
1. if A is positive definite, then σA ⊂ (0,∞),
2. if A is positive definite, then A is invertible,
3. B∗B is positive semidefinite,
4. if B is invertible, then B∗B is positive definite.
5. if B is positive definite, then diag(B) is nonnegative,
6. if diag(B) strictly positive, thenif B is positive definite.
Problem 1.1. (Sample question #1, summer, 2013 ) Suppose A ∈ Cn×n is hermitian and σ (A) ⊂ (0,∞).Prove A is Hermitian Positive Defined (HPD).
Proof. Since, A is Hermitian, then is Unitary diagonalizable. i.e. A= UDU−1 = UDU ∗, then
x∗Ax = x∗UDU−1x = x∗UDU ∗x = (U ∗x)∗D(U ∗x). (15)
Moreover, since σ (A) ⊂ (0,∞) then x∗Dx > 0 for any nonzero x. Hence
x∗Ax = (U ∗x)∗D(U ∗x) = x∗Dx > 0, for any nonzero x. (16)
1.1.7 Normal matrices
Definition 1.6. (Normal Matrix) A matrix is called normal , if
A∗A= AA∗.
Corollary 1.2. Unitary matrix and Hermitian matrix are normal matrices.
Theorem 1.19. A ∈ Cn×n is normal if and only if every matrix unitarily equivalent to A is normal.
Theorem 1.20. A ∈ Cn×n is normal if and only if every matrix unitarily equivalent to A is normal.
Proof. Suppose A is normal and B = U ∗AU , where U is unitary. Then B∗B = U ∗A∗UU ∗AU = U ∗A∗AU =U ∗AA∗U = U ∗AUU ∗A∗U = BB∗, so B is normal. Conversely, If B is normal, it is easy to get that U ∗A∗AU =U ∗AA∗U , then A∗A= AA∗
Page 11 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 12
Theorem 1.21. (Spectral theorem for normal matrices) If A ∈ Cn×n has eigenvalues λ1, · · · ,λn, countedaccording to multiplicity, the following statements are equivalent.
1. A is normal,
2. A is unitarily diagonalizable,
3.∑ni=1
∑nj=1 |aij |2 =
∑ni=1 |λi |2,
4. There is an orthonormal set of n eigenvectors of A.
1.1.8 Common Theorems
Definition 1.7. (Orthogonal Complement) Suppose S ⊂Rn is a subspace. The (Orthogonal Complement)of S is defined as
S⊥ =y ∈Rn | yT x = 0,∀x ∈ S
Theorem 1.22. Suppose A ∈Rn×n. Then
1. R(A)⊥=N (AT ),
2. R(AT )⊥=N (A).
Proof. 1. For any y ∈ R(A)⊥, then yT y = 0,∀y ∈ R(A). And ∀y ∈ R(A), there exists x, such that Ax = y.Then
yTAx = (AT y)T x = 0.
Since, x is arbitrary, so it must be AT y = 0. Hence
R(A)⊥ ⊂N (AT )
Conversely, suppose y ∈ N (AT ), then AT y = 0 and hence (AT y)T x = yTAx = 0 for any x ∈ Rn. So,y ∈ R(AT )⊥. Therefore
N (AT ) ⊂R(A)⊥
R(A)⊥=N (AT ),
2. Similarly, we can prove R(AT )⊥=N (A),
1.2 Calculus Preliminaries
Definition 1.8. (Taylor formula for one variable) Let f (x) to be n-th differentiable at x0, then there existsa neighborhood B(x0,ε), ∀x ∈ B(x0,ε), s.t.
f (x) = f (x0) + f′(x0)(x − x0) +
f ′′(x0)
2!(x − x0)
2 + · · ·+f (n)(x0)
n!(x − x0)
n+O((x − x0)n+1)
= f (x0) + f′(x0)∆x+
f ′′(x0)
2!∆x2 + · · ·+
f (n)(x0)
n!∆xn+O(∆xn+1). (17)
Page 12 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 13
Definition 1.9. (Taylor formula for two variables) Let f (x,y) ∈ Ck+1(B((x0,y0),ε)), then ∀(x0 +∆x,y0 +∆y) ∈ B((x0,y0),ε)),
Then, we have the fact that if u+ v ∈ Lp then |u+ v|p−1 ∈ Lq, since |u+ v|p−1 <∞ and
∥∥∥|u+ v|p−1∥∥∥Lq
=
(∫U
(|u+ v|p−1
)qdx
) 1q
=
(∫U|u+ v|pdx
) 1p ·(p−1)
= ‖u+ v‖p−1Lp <∞. (51)
Now, we can use Hölder’s inequality for |u+ v| · |u+ v|p−1, i.e.
‖u+ v‖pLp =∫U|u+ v|pdx =
∫U|u+ v||u+ v|p−1dx
≤∫U|u||u+ v|p−1 + |v||u+ v|p−1dx
≤∫U|u||u+ v|p−1dx+
∫U|v||u+ v|p−1dx (52)
≤ ‖u‖Lp∥∥∥|u+ v|p−1
∥∥∥Lq+ ‖v‖Lp
∥∥∥|u+ v|p−1∥∥∥Lq
= (‖u‖Lp + ‖v‖Lp )∥∥∥|u+ v|p−1
∥∥∥Lq
= (‖u‖Lp + ‖v‖Lp )‖u+ v‖p−1Lp .
Page 18 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 19
Since ‖u+ v‖Lp , 0, dividing ‖u+ v‖p−1Lp on both side of (52) yields
‖u+ v‖Lp ≤ ‖u‖Lp + ‖v‖Lp . (53)
Definition 1.21. (Discrete Minkowski’s Inequality) Let 1 ≤ p < ∞ and ak ,bk ∈ Lp(U ). Then u + v ∈Lp(U ) and n∑
k=1
|ak + bk |p1/p
≤
n∑k=1
|ak |p1/p
+
n∑k=1
|bk |p1/p
. (54)
Proof. The idea is similar to the continuous case.
n∑k=1
|ak + bk |p =n∑k=1
|ak + bk | |ak + bk |p−1
≤n∑k=1
|ak | |ak + bk |p−1 + |bk | |ak + bk |p−1
≤
n∑k=1
|ak |p1/p n∑
k=1
[|ak + bk |p−1
]q1/q
+
n∑k=1
|bk |p1/p n∑
k=1
[|ak + bk |p−1
]q1/q (1p+
1q= 1
)
=
n∑k=1
|ak |p1/p n∑
k=1
|ak + bk |p1/q
+
n∑k=1
|bk |p1/p n∑
k=1
|ak + bk |p1/q
=
n∑k=1
|ak |p1/p n∑
k=1
|ak + bk |pp−1p
+
n∑k=1
|bk |p1/p n∑
k=1
|ak + bk |pp−1p
=
n∑k=1
|ak |p1/p
+
n∑k=1
|bk |p1/p
n∑k=1
|ak + bk |pp−1p
.
Diving(∑n
k=1 |ak + bk |p)1− 1
p on both sides of the above equation, we get n∑k=1
|ak + bk |p1/p
≤
n∑k=1
|ak |p1/p
+
n∑k=1
|bk |p1/p
.
Page 19 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 20
Definition 1.22. (Integral Minkowski’s Inequality) Let 1 ≤ p <∞ and u(x,y) ∈ Lp(U ). Then(∫ ∣∣∣∣∣∫ u(x,y)dx∣∣∣∣∣p dy) 1
p
≤∫ (∫
|u(x,y)|pdy) 1p
dx. (55)
Proof. 1. When p = 1, then∫ ∣∣∣∣∣∫ u(x,y)dx∣∣∣∣∣dy ≤ ∫ ∫ ∣∣∣u(x,y)
∣∣∣dxdy = ∫ ∫ ∣∣∣u(x,y)∣∣∣dydx. (56)
Where, the last step follows by Fubini’s theorem for nonnegative measurable functions.2. When 1 < p <∞,
∫ ∣∣∣∣∣∫ u(x,y)dx∣∣∣∣∣p dy
≤∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy=
∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p−1
︸ ︷︷ ︸independent on x
(∫ ∣∣∣u(x,y)∣∣∣dx)dy
=
∫ ∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p−1 ∣∣∣u(x,y)
∣∣∣dxdy=
∫ ∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p−1 ∣∣∣u(x,y)
∣∣∣dydx (Fubini)
=
∫ ∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p−1 ∣∣∣u(x,y)
∣∣∣dydx≤
∫ ∫ (∫ ∣∣∣u(x,y)∣∣∣dx)(p−1)q
dy
1/q (∫ ∣∣∣u(x,y)
∣∣∣p dy)1/p
dx (Hölder’s)
=
∫ ∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy︸ ︷︷ ︸constant
1/q (∫ ∣∣∣u(x,y)
∣∣∣p dy)1/p
dx (1p+
1q= 1)
=
(∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p dy)1/q∫ (∫ ∣∣∣u(x,y)
∣∣∣p dy)1/p
dx
So, we get∫ (∫ ∣∣∣u(x,y)∣∣∣dx)p dy ≤ (∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy)1−1/p∫ (∫ ∣∣∣u(x,y)∣∣∣p dy)1/p
dx.
dividing(∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy)1−1/pon both sides of the above equation yields(∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy)1/p
≤∫ (∫ ∣∣∣u(x,y)
∣∣∣p dy)1/p
dx.
Page 20 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 21
Hence, we proved the result by the following fact(∫ ∣∣∣∣∣∫ u(x,y)dx∣∣∣∣∣p dy)1/p
≤(∫ (∫ ∣∣∣u(x,y)
∣∣∣dx)p dy)1/p
.
Definition 1.23. (Differential Version of Gronwall’s Inequality ) Let η(·) be a nonnegative, absolutelycontinuous function on [0, T], which satisfies for a.e t the differential inequality
η′(t) ≤ φ(t)η(t) +ψ(t), (57)
where φ(t) and ψ(t) are nonnegative, summable functions on [0, T]. Then
η(t) ≤ e∫ t0 φ(s)ds
[η(0) +
∫ t
0ψ(s)ds
],∀0 ≤ t ≤ T . (58)
In particular, if
η′ ≤ φη, on[0,T ] and η(0) = 0, (59)
η(t) = 0,∀0 ≤ t ≤ T . (60)
Proof. Since
η′(t) ≤ φ(t)η(t) +ψ(t),a.e.0 ≤ t ≤ T . (61)
then
η′(s)−φ(s)η(s) ≤ ψ(s),a.e.0 ≤ s ≤ T . (62)
Let
f (s) = η(s)e−∫ s0 φ(ξ)dξ . (63)
By product rule and chain rule, we have
df
ds= η′(s)e−
∫ s0 φ(ξ)dξ − η(s)e−
∫ s0 φ(ξ)dξφ(s), (64)
= (η′(s)− η(s)φ(s))e−∫ s0 φ(ξ)dξ (65)
≤ ψ(s)e−∫ s0 φ(ξ)dξ ,a.e.0 ≤ t ≤ T . (66)
Integral the above equation from 0 to t, then we get∫ t
0η(s)e−
∫ s0 φ(ξ)dξds = η(t)e−
∫ t0 φ(ξ)dξ − η(0) ≤
∫ t
0ψ(s)e−
∫ s0 φ(ξ)dξds,
i.e.
η(t)e−∫ t0 φ(ξ)dξ ≤ η(0) +
∫ t
0ψ(s)e−
∫ s0 φ(ξ)dξds.
Therefore
η(t) ≤ e∫ t0 φ(ξ)dξ
[η(0) +
∫ t
0ψ(s)e−
∫ s0 φ(ξ)dξds
].
Page 21 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 22
Definition 1.24. (Integral Version of Gronwall’s Inequality) Let ξ(·) be a nonnegative, summable func-tion on [0, T], which satisfies for a.e t the integral inequality
ξ(t) ≤ C1
∫ t
0ξ(s)ds+C2, (67)
where C1,C2 ≥ 0. Then
ξ(t) ≤ C2
(1+C1te
C1t), ∀a.e. 0 ≤ t ≤ T . (68)
In particular, if
ξ(t) ≤ C1
∫ t
0ξ(s)ds, ∀a.e. 0 ≤ t ≤ T , (69)
ξ(t) = 0,a.e. (70)
Proof. Let
η(t) :=∫ t
0ξ(s)ds, (71)
then
η′(t) = ξ(t). (72)
Since
ξ(t) ≤ C1
∫ t
0ξ(s)ds+C2, (73)
so
η′(t) ≤ C1η(t) +C2. (74)
By Differential Version of Gronwall’s Inequality, we get
η(t) ≤ e∫ t0 C1ds[η(0) +
∫ t
0C2ds], (75)
i.e.
η(t) ≤ C2teC1t . (76)
Therefore ∫ t
0ξ(s)ds ≤ C2te
C1t . (77)
Taking derivative w.r.t t on both side of the above, we get
ξ(t) ≤ C2eC1t +C2te
C1tC1 = C2(1+C1teC1t). (78)
Page 22 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 23
Definition 1.25. (Discrete Version of Gronwall’s Inequality) If
Proof. We will use induction to prove this discrete Gronwall’s inequality.
1. For n= 0, then
(1+ γ)a1 ≤ a0 + βf0, (81)
so
a1 ≤a0
(1+ γ)+ β
f0(1+ γ)n−k
. (82)
2. Induction Assumption: Assume the discrete Gronwall’s inequality is valid for k = n− 1, i.e.
an ≤a0
(1+ γ)n+ β
n−1∑k=0
fk(1+ γ)n−k
. (83)
3. Induction Result: For k = n, we have
(1+ γ)an+1 ≤ an+ βfn
≤ a0
(1+ γ)n+ β
n−1∑k=0
fk(1+ γ)n−k
+ βfn
≤ a0
(1+ γ)n+ β
n−1∑k=0
fk(1+ γ)n−k
+ βfn
(1+ γ)n−n(84)
=a0
(1+ γ)n+ β
n∑k=0
fk(1+ γ)n−k
.
Dividing 1+ γ on both sides of the above equation gives
an+1 ≤a0
(1+ γ)n+1 + βn∑k=0
fk(1+ γ)n−k+1
. (85)
Definition 1.26. (Interpolation Inequality for Lp-norm) Assume 1 ≤ p ≤ r ≤ q ≤∞ and
1r=θp+
1−θq
. (86)
Suppose also u ∈ Lp(U )∩Lq(U ). Then u ∈ Lr(U ), and
‖u‖Lr (U ) ≤ ‖u‖θLp(U ) ‖u‖1−θLq(U ) . (87)
Page 23 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 24
Proof. If 1 ≤ p < r < q then 1q <
1r <
1p , hence there exists θ ∈ [0,1] s.t. 1
r = θ 1p + (1−θ) 1
q , therefore:
1 =rθp
+r(1−θ)
q=
1prθ
+1q
r(1−θ). (88)
And |u|rθ ∈ Lprθ , |u|r(1−θ) ∈ L
qr(1−θ) , since(∫
U
(|u|rθ
) prθ dx
) rθp
=
(∫U|u|pdx
) rθp
= ‖u‖rθLp(U ) <∞, (89)
(∫U
(|u|r(1−θ)
) qr(1−θ) dx
) r(1−θ)q
=
(∫U|u|qdx
) r(1−θ)q
= ‖u‖r(1−θ)Lq(U )<∞. (90)
Now, we can use Hölder’s inequality for |u|r = |u|rθ |u|r(1−θ), i.e.∫U|u|rdx =
∫U|u|rθ |u|r(1−θ)dx
≤(∫
U
(|u|rθ
) prθ dx
) rθp(∫
U
(|u|r(1−θ)
) qr(1−θ) dx
) r(1−θ)q
. (91)
= ‖u‖rθLp(U ) ‖u‖r(1−θ)Lq(U )
. (92)
Therefore
‖u‖Lr (U ) ≤ ‖u‖θLp(U ) ‖u‖1−θLq(U ) . (93)
Definition 1.27. (Interpolation Inequality for Lp-norm) Assume 1 ≤ p ≤ r ≤ q ≤∞ and f ∈ Lq. Supposealso u ∈ Lp(U )∩Lq(U ). Then u ∈ Lr(U ),
‖u‖Lr (U ) ≤ ‖u‖1/p−1/r1/p−1/q
Lp(U ) ‖u‖1/r−1/q1/p−1/q
Lq(U ). (94)
Proof. If 1 ≤ p < r < q then 1q <
1r <
1p , hence there exists θ ∈ [0,1] s.t. 1
r = θ 1p + (1−θ) 1
q , therefore:
1 =rθp
+r(1−θ)
q=
1prθ
+1q
r(1−θ). (95)
And |u|rθ ∈ Lprθ , |u|r(1−θ) ∈ L
qr(1−θ) , since(∫
U
(|u|rθ
) prθ dx
) rθp
=
(∫U|u|pdx
) rθp
= ‖u‖rθLp(U ) <∞, (96)
(∫U
(|u|r(1−θ)
) qr(1−θ) dx
) r(1−θ)q
=
(∫U|u|qdx
) r(1−θ)q
= ‖u‖r(1−θ)Lq(U )<∞. (97)
Page 24 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 25
Now, we can use Hölder’s inequality for |u|r = |u|rθ |u|r(1−θ), i.e.∫U|u|rdx =
∫U|u|rθ |u|r(1−θ)dx
≤(∫
U
(|u|rθ
) prθ dx
) rθp(∫
U
(|u|r(1−θ)
) qr(1−θ) dx
) r(1−θ)q
. (98)
= ‖u‖rθLp(U ) ‖u‖r(1−θ)Lq(U )
. (99)
Therefore
‖u‖Lr (U ) ≤ ‖u‖θLp(U ) ‖u‖1−θLq(U ) . (100)
Let θ =1/p−1/r1/p−1/q , then we get
‖u‖Lr (U ) ≤ ‖u‖1/p−1/r1/p−1/q
Lp(U ) ‖u‖1/r−1/q1/p−1/q
Lq(U ). (101)
Theorem 1.23. (1D Dirichlet-Poincaré inequality) Let a > 0, u ∈ C1([−a,a]) and u(−a) = 0, then the1D Dirichlet-Poincaré inequality is defined as follows∫ a
−a
∣∣∣u(x)∣∣∣2 dx ≤ 4a2∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Proof. Since u(−a) = 0, then by calculus fact, we have
u(x) = u(x)−u(−a) =∫ x
−au′(ξ)dξ.
Therefore ∣∣∣u(x)∣∣∣ ≤ ∣∣∣∣∣∫ x
−au′(ξ)dξ
∣∣∣∣∣≤
∫ x
−a
∣∣∣u′(ξ)∣∣∣dξ≤
∫ a
−a
∣∣∣u′(ξ)∣∣∣dξ (x ≤ a)
≤(∫ a
−a12dξ
)1/2 (∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
(Cauchy-Schwarz inequality)
= (2a)1/2(∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
.
Therefore ∣∣∣u(x)∣∣∣2 ≤ 2a∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ.
Page 25 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 26
Integration on both sides of the above equation from −a to a w.r.t. x yields∫ a
−a
∣∣∣u(x)∣∣∣2 dx ≤∫ a
−a2a
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξdx=
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ∫ a
−a2adx
= 4a2∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ= 4a2
∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Theorem 1.24. (1D Neumann-Poincaré inequality) Let a > 0, u ∈ C1([−a,a]) and u => a−au(x)dx, then
the 1D Neumann-Poincaré inequality is defined as follows∫ a
−a
∣∣∣u(x)− u(x)∣∣∣2 dx ≤ 2a(a− c)∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Proof. Since, u => a−au(x)dx, then by intermediate value theorem, there exists a c ∈ [−a,a], s.t.
u(c) = u(x).
then by calculus fact, we have
u(x)− u(x) = u(x)−u(c) =∫ x
cu′(ξ)dξ.
Therefore ∣∣∣u(x)− u(x)∣∣∣ ≤ ∣∣∣∣∣∫ x
cu′(ξ)dξ
∣∣∣∣∣≤
∫ x
c
∣∣∣u′(ξ)∣∣∣dξ≤
∫ a
c
∣∣∣u′(ξ)∣∣∣dξ (x ≤ a)
≤(∫ a
c12dξ
)1/2 (∫ a
c
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
(Cauchy-Schwarz inequality)
= (a− c)1/2(∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
.
Therefore ∣∣∣u(x)− u(x)∣∣∣2 ≤ (a− c)∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ.
Page 26 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 27
Integration on both sides of the above equation from −a to a w.r.t. x yields∫ a
−a
∣∣∣u(x)− u(x)∣∣∣2 dx ≤∫ a
−a(a− c)
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξdx=
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ∫ a
−a(a− c)dx
= 2a(a− c)∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ= 2a(a− c)
∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
1.4 Norms’ Preliminaries
1.4.1 Vector Norms
Definition 1.28. (Vector Norms) A vector norm is a function ‖·‖ : Rn 7−R satisfying the following condi-tions for all x,y ∈Rn and α ∈R
Definition 1.31. For A ∈Rm×n, some of the most frequently matrix vector norms are
1. F-norm :‖A‖F =
√√m∑i=1
n∑i=1
|aij |2,
2. 1-norm : ‖A‖1 = max1≤j≤n
m∑i=1
|aij |,
3. ∞-norm : ‖A‖∞ = max1≤i≤m
n∑j=1
|aij |,
4. induced-norm : ‖A‖p = supx∈Rn,x,0
‖Ax‖p‖x‖p
.
Corollary 1.7. For all A ∈ Cn×n,
‖A‖2 ≤ ‖A‖F ≤√n‖A‖2 , (107)
1√n‖A‖2 ≤ ‖A‖∞ ≤
√n‖A‖2 , (108)
1√n‖A‖∞ ≤ ‖A‖2 ≤
√n‖A‖∞ , (109)
1√n‖A‖1 ≤ ‖A‖2 ≤
√n‖A‖1 . (110)
Corollary 1.8. For all A ∈ Cn×n, then ‖A‖2 ≤√‖A‖1 ‖A‖∞.
Proof.
‖A‖22 = ρ(A)2 = λ ≤ ‖A‖1 ‖A∗‖1 = ‖A‖1 ‖A‖∞ .
where λ is the eigenvalue of A∗A.
Theorem 1.26. (Matrix 2-norm and Frobenius invariance) (Matrix 2-norm and Frobenius are invariantunder the orthogonal transformation, i.e., if Q is an n×n orthogonal matrix, then
‖QA‖2 = ‖A‖2 , ∀A ∈Rn×n, (111)
‖QA‖F = ‖A‖F , ∀A ∈Rn×n (112)
Page 28 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 29
Theorem 1.27. (Neumann Series) Suppose that A ∈Rn×n. If ‖A‖ < 1, then (I −A) is nonsingular and
(I −A)−1 =∞∑k=0
Ak (113)
with
11+ ‖A‖
≤∥∥∥(I −A)−1
∥∥∥ ≤ 11− ‖A‖
. (114)
Moreover, if A is nonnegative, then (I −A)−1 =∑∞k=0A
k is also nonnegative.
Proof. 1. (I-A) is nonsingular, i.e. (I −A)−1 exits.∥∥∥(I −A)x∥∥∥ ≥ ‖Ix‖ − ‖Ax‖≥ ‖x‖ − ‖A‖‖x‖= (1− ‖A‖)‖x‖= C ‖x‖ .
So, we get if (I −A)x = 0, then x = 0. Therefore, ker(I −A) = 0, then (I −A)−1 exists.
2. Let SN =∑Nk=0A
k , we want to show (I −A)SN → I , as N →∞. First, we would like to show∥∥∥Ak∥∥∥ ≤
‖A‖k .
∥∥∥Ak∥∥∥= sup0,x∈Cn
∥∥∥Akx∥∥∥‖x‖
≤ sup0,x∈Cn
‖A‖∥∥∥Ak−1x
∥∥∥‖x‖
≤ · · · ≤ ‖A‖k .
(I −A)SN = SN −ASN =N∑k=0
Ak −N+1∑k=1
Ak = A0 −AN+1 = I −AN+1.
So ∥∥∥(I −A)SN − I∥∥∥= ∥∥∥−AN+1∥∥∥ ≤ ‖A‖N+1 .
Since ‖A‖ < 1, then ‖A‖N+1→ 0. Therefore,
(I −A)∞∑k=0
Ak = I .
and
(I −A)−1 =∞∑k=0
Ak
3. bounded normSince
1 = ‖I‖=∥∥∥(I −A) ∗ (I −A)−1
∥∥∥ .
So,
(1− ‖A‖)∥∥∥(I −A)−1
∥∥∥ ≤ 1 ≤ (1+ ‖A‖)∥∥∥(I −A)−1
∥∥∥ .
Page 29 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 30
Therefore,
11+ ‖A‖
≤∥∥∥(I −A)−1
∥∥∥ ≤ 11− ‖A‖
.
Lemma 1.1. Suppose that A ∈Rn×n. If (I −A) is singular, then ‖A‖ ≥ 1.
Proof. Converse-negative proposition of If ‖A‖ < 1, then (I −A) is nonsingular.
Theorem 1.28. Let A be a nonnegative matrix. then ρ(A) < 1 if only if I −A is nonsingular and (I −A)−1
is nonnegative.
Proof. 1. By theorem (1.27).
2. ⇐ since I −A is nonsingular and (I −A)−1 is nonnegative, by the Perron- Frobenius theorem, there isa nonnegative eigenvector u associated with ρ(A), which is an eigenvalue, i.e.
Au = ρ(A)u
or
(I −A)−1u =1
1− ρ(A)u.
since I −A is nonsingular and (I −A)−1 is nonnegative, this show that 1− ρ(A) > 0, which implies
ρ(A) < 1.
1.5 Problems
Problem 1.2. (Prelim Jan. 2011#2) Let A ∈ Cm×n and b ∈ Cm. Prove that the vector x ∈ Cn is a leastsquares solution of Ax = b if and only if r⊥range(A), where r = b −Ax.
Solution. We already know, x ∈ Cn is a least squares solution of Ax = b if and only if
Therefore, r⊥range(A). The above way is invertible, hence we prove the result. J
Page 30 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 31
Problem 1.3. (Prelim Jan. 2011#3) Suppose A,B ∈ Rn×n and A is non-singular and B is singular. Provethat
1κ(A)
≤ ‖A−B‖‖A‖
,
where κ(A) = ‖A‖ ·∥∥∥A−1
∥∥∥, and ‖·‖ is an reduced matrix norm.
Solution. Since B is singular, then there exists a vector x , 0, s.t. Bx = 0. Since A is non-singular, thenA−1 is also non-singular. Moreover, A−1Bx = 0. Then, we have
x = x −A−1Bx = (I −A−1B)x.
So
‖x‖=∥∥∥(I −A−1B)x
∥∥∥ ≤ ∥∥∥A−1A−A−1B∥∥∥‖x‖ ≤ ∥∥∥A−1
∥∥∥‖A−B‖‖x‖ .Since x , 0, so
1 ≤∥∥∥A−1
∥∥∥‖A−B‖ .1∥∥∥A−1∥∥∥‖A‖ ≤ ‖A−B‖‖A‖
,
i.e.
1κ(A)
≤ ‖A−B‖‖A‖
.
J
Problem 1.4. (Prelim Aug. 2010#2) Suppose that A ∈Rn×n is SPD.
1. Show that ‖x‖A =√xTAx defines a vector norm.
2. Let the eigenvalues of A be ordered so that 0 < λ1 ≤ λ2 ≤ · · · ≤ λn. Show that√λ1 ‖x‖2 ≤ ‖x‖A ≤
√λn ‖x‖2 .
for any x ∈Rn.
3. Let b ∈ Rn be given. Prove that x∗ ∈ Rn solves Ax = b if and only if x∗ minimizes the quadraticfunction f : Rn→R defined by
f (x) =12xTAx − xT b.
Solution. 1. (a) Obviously, ‖x‖A =√xTAx ≥ 0. When x = 0, then ‖x‖A =
√xTAx = 0; when ‖x‖A =√
xTAx = 0, then we have (Ax,x) = 0, since A is SPD, therefore, x ≡ 0.
(b) ‖λx‖A =√λxTAλx =
√λ2xTAx = |λ|
√xTAx = |λ| ‖x‖A.
(c) Next we will show∥∥∥x+ y∥∥∥
A≤ ‖x‖A+
∥∥∥y∥∥∥A
. First, we would like to show∣∣∣yTAx∣∣∣ ≤ ‖x‖A ∥∥∥y∥∥∥A
.
Page 31 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 32
Since A is SPD, therefore A= RTR, moreover
‖Rx‖2 = (Rx,Rx)1/2 =√(Rx)TRx =
√xTRTRx =
√xTAx = ‖x‖A .
Then ∣∣∣yTAx∣∣∣= ∣∣∣yTRTRx∣∣∣= ∣∣∣(Ry)TRx∣∣∣= ∣∣∣(Rx,Ry)∣∣∣ c.s.≤ ‖Rx‖2 ∥∥∥Ry∥∥∥2
= ‖x‖A∥∥∥y∥∥∥
A.
And ∥∥∥x+ y∥∥∥2A
= (x+ y,x+ y)A = (x,x)A+ 2(x,y)A+ (y,y)A
≤ ‖x‖A+ 2∣∣∣yTAx∣∣∣+ ∥∥∥y∥∥∥
A
≤ ‖x‖A+ 2‖x‖A∥∥∥y∥∥∥
A+
∥∥∥y∥∥∥A
=(‖x‖A+
∥∥∥y∥∥∥A
)2.
therefore ∥∥∥x+ y∥∥∥A≤ ‖x‖A+
∥∥∥y∥∥∥A
.
2. Since A is SPD, therefore A= RTR, moreover
‖Rx‖2 = (Rx,Rx)1/2 =√(Rx)TRx =
√xTRTRx =
√xTAx = ‖x‖A .
Let 0 < λ1 ≤ λ2 ≤ · · · ≤ λn be the eigenvalue of R, then λi =√λi . so∣∣∣λ1
∣∣∣‖x‖2 ≤ ‖Rx‖2 = ‖x‖A ≤ ∣∣∣λn∣∣∣‖x‖2 .
i.e. √λ1 ‖x‖2 ≤ ‖Rx‖2 = ‖x‖A ≤
√λn ‖x‖2 .
3. Since∂∂xi
(xTAx
)=
∂∂xi
(xT
)Ax+ xT
∂∂xi
(Ax)
= [0, · · · ,0,1i,0, · · · ,0]Ax+ xTA
0...010...0
i
= (Ax)i +(AT x
)i= 2 (Ax)i .
and∂∂xi
(xT b
)=
∂∂xi
(xT
)b = [0, · · · ,0,1
i,0, · · · ,0]b = bi .
Therefore,
∇f (x) = 12
2Ax − b = Ax − b.
If Ax∗ = b, then ∇f (x∗) = Ax∗ − b = 0, therefore x∗ minimizes the quadratic function f. Conversely,when x∗ minimizes the quadratic function f, then ∇f (x∗) = Ax∗ − b = 0, therefore Ax∗ = b.
J
Page 32 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 33
2 Direct Method
2.1 For squared or rectangular matrices A ∈ Cm,n,m ≥ n
• vi– right singular vectors, U = [u1,u2, · · · ,um] and U is unitary.
• ui– left singular vectors, V = [v1,v2, · · · ,vn] and V is unitary.
Remark 2.1. 1. SVD works for any matrices, spectral decomposition only works for squared matrices.
2. The spectral decomposition A= XΛX−1 works only if A is non-defective matrices.For a symmetric matrix the following decompositions are equivalent to SVD.
1. Eigen-value decomposition: i.e. A= XΣX−1. When A is symmetric, the eigenvalues are real and theeigenvectors can be chosen to be orthonormal and hence XTX = XXT = I i.e.X−1 = XT . The onlydifference is that the singular values are the magnitudes of the eigenvalues and hence the column of Xneeds to be multiplied by a negative sign if the eigenvalue turns out to be negative to get the singularvalue decomposition. Hence, U=X and σi = |λi |.
2. Orthogonal decomposition: i.e. A= PDP T , where P is a unitary matrix and D is a diagonal matrix.This exists only when matrix A is symmetric and is the same as eigenvalue decomposition.
3. Schur decomposition i.e. A = QSQT , where Q is a unitary matrix and S is an upper triangularmatrix. This can be done for any matrix. When A is symmetric, then S is a diagonal matrix andagain is the same as the eigenvalue decomposition and orthogonal decomposition.
Page 33 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 34
2.1.2 Gram-Schmidt orthogonalization
Definition 2.1. (projection operator) We define the projection operator as
proju(v) =(u,v)(u,u)
u,
where (u,v) is the inner product of the vector u and v. If u = 0, we define
proj0(v) = 0.
Remark 2.2. 1. This operator projects the vector v orthogonally onto the line spanned by vector u.
2. the projection map proj0 is the zero map, sending every vector to the zero vector.
Definition 2.2. (Gram-Schmidt orthogonalization) The Gram-Schmidt process then works as follows:
u1 = v1, q1 =u1
‖u1‖
u2 = v2 −proju1(v2), q2 =
u2
‖u2‖
u3 = v3 −proju1(v3)−proju2
(v3), q3 =u3
‖u3‖
u4 = v4 −proju1(v4)−proju2
(v4)−proju3(v4), q4 =
u4
‖u4‖...
...
uk = vk −k−1∑j=1
projuj (vk), qk =uk‖uk‖
.
A= [a1,a2, · · · ,an] = [q1,q2, · · · ,qn]
r11 · · · r1n
r22...rnn
.
Definition 2.3. (projector) A projector is a square matrix P that satisfies
P 2 = P .
Definition 2.4. (complementary projector) If P is a projector, then
I − P
is also a projector and is called complementary projector.
Definition 2.5. (orthogonal projector) If P is a orthogonal projector if only if
P = P ∗.
The complement of an orthogonal projector is also orthogonal projector.
Page 34 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 35
Definition 2.6. (projection with orthonormal basis) If P is a orthogonal projector, then P = P ∗ and Phas SVD, i.e. P = QΣQ∗. Since an orthogonal projector has some singular values equal to zero (except theidentity map P=I), it is natural to drop the silent columns of Q and use the reduced rather than full SVD,i.e.
P = QQ∗.
The complement projects onto the space orthogonal to range(Q).
Definition 2.7. (Gram- Schmidt projections)
P = I − QQ∗.
The complement projects onto the space orthogonal to range(Q).
Definition 2.8. (Householder reflectors) The householder reflector F is a particular matrix which satisfies
F = I − 2vv∗
‖v‖.
Comparsion 2.1. (Gram- Schmidt and Householder)
Gram− Schmidt AR1R2 · · ·Rn︸ ︷︷ ︸R−1
= Q triangular orthogonalization
Householder Qn · · ·Q2Q1︸ ︷︷ ︸Q∗
A= R orthogonal triangularization
2.1.3 QR Decomposition
Theorem 2.3. (Reduced QR Decomposition) Suppose that A ∈ Cm×n.
A= Qm×n
Rn×n
.
This is called a Reduced QR Decomposition of A. where
• Q ∈ Cm×n– with orthonormal columns.
• R ∈ Cn×n– upper triangular matrix.
Theorem 2.4. (QR Decomposition) Suppose that A ∈ Cm×n.
A= Qm×m
Rm×n
.
This is called a QR Decomposition of A. where
• Q ∈ Cm×m– is unitary.
• R ∈ Cm×n– upper triangular matrix.
Theorem 2.5. (Existence of QR Decomposition) Every A ∈ Cm×n has full and reduced QR decomposition.
Page 35 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 36
Theorem 2.6. (Uniqueness of QR Decomposition) Each A ∈ Cm×n of full rank has a unique reduced QRdecomposition A= QR with rjj > 0.
2.2 For squared matrices A ∈ Cn,n
A problem can be read as
f : D → S
Data → Solution
2.2.1 Condition number
Definition 2.9. (Well posedness ) We say that a problem is well- posed if the solution depends continuouslyon the data, otherwise we say it is ill-posed.
Definition 2.10. (absolute condition number) The absolute condition number κ = κ(x) of the problem fat x is defined as
κ = limδ→0
sup‖δx‖≤δ
∥∥∥f (x+ δx)− f (x)∥∥∥‖δx‖
.
If f is (Freechet) differentiable
κ =∥∥∥Df (x)∥∥∥ .
Example 2.1. f: R2→ R and f (x1,x2) = x1 − x2, then
Df (x) = [∂f
∂x1,∂f
∂x2] = [1,−1].
and
κ =∥∥∥Df (x)∥∥∥∞ = 1.
Definition 2.11. (relative condition number) The absolute condition number κ = κ(x) of the problem fat x is defined as
κ = limδ→0
sup‖δx‖≤δ
‖f (x+δx)−f (x)‖‖δx‖‖f (x)‖‖x‖
=‖x‖∥∥∥f (x)∥∥∥ κ.
Page 36 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 37
Definition 2.12. (condition number of Matrix- Vector Multiplication) The absolute condition of f (x) =Ax
κ = limδ→0
sup‖δx‖≤δ
‖A(x+δx)−A(x)‖‖δx‖‖A(x)‖‖x‖
= ‖A‖ ‖x‖∥∥∥A(x)∥∥∥ .
Theorem 2.7. (condition of Matrix- Vector Multiplication) Since, ‖x‖ =∥∥∥A−1Ax
∥∥∥ ≤ ∥∥∥A−1∥∥∥‖Ax‖, then
‖x‖‖A(x)‖ ≤
∥∥∥A−1∥∥∥. So
κ ≤ ‖A‖∥∥∥A−1
∥∥∥ .
Particularly,
κ = ‖A‖2∥∥∥A−1
∥∥∥2
.
Definition 2.13. (condition number of Matrix) Let A ∈ Cn×n, invertible, the condition number of A is
κ(A)‖·‖ = ‖A‖∥∥∥A−1
∥∥∥ .
particularly,
κ2(A) = ‖A‖2∥∥∥A−1
∥∥∥2=σ1
σn.
where σ1 · · ·σn are singular value of A. So, ‖A‖2 = σ1.
2.2.2 LU Decomposition
Definition 2.14. (LU Decomposition without pivoting) Let A ∈ Cn×n. An LU factorization refers to thefactorization of A, with proper row and/or column orderings or permutations, into two factors, a lowertriangular matrix L and an upper triangular matrix U ,
A= LU .
In the lower triangular matrix all elements above the diagonal are zero, in the upper triangular matrix,all the elements below the diagonal are zero. For example, for a 3-by-3 matrix A, its LU decompositionlooks like this: a11 a12 a13
a21 a22 a23a31 a32 a33
=l11 0 0l21 l22 0l31 l32 l33
u11 u12 u13
0 u22 u230 0 u33
.
Page 37 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 38
Definition 2.15. (LU Decomposition with partial pivoting) The LU factorization with Partial Pivotingrefers often to the LU factorization with row permutations only,
PA= LU ,
where L and U are again lower and upper triangular matrices, and P is a permutation matrix which, whenleft-multiplied to A, reorders the rows of A.
Definition 2.16. (LU Decomposition with full pivoting) An LU factorization with full pivoting involvesboth row and column permutations,
PAQ = LU ,
where L, U and P are defined as before, and Q is a permutation matrix that reorders the columns of A
Definition 2.17. (LDU Decomposition) An LDU decomposition is a decomposition of the form
A= LDU ,
where D is a diagonal matrix and L and U are unit triangular matrices , meaning that all the entries onthe diagonals of L and U are one.
Forexample, for a 3-by-3 matrix A, its LDU decomposition looks like this:a11 a12 a13
a21 a22 a23a31 a32 a33
= 1 0 0l21 1 0l31 l32 1
1 u12 u130 1 u230 0 1
.
Theorem 2.8. (existence of Decomposition) Any square matrix A admits an LUP factorization. If A isinvertible, then it admits an LU (or LDU) factorization if and only if all its leading principal minors arenonsingular. If A is a singular matrix of rank k , then it admits an LU factorization if the first k leadingprincipal minors are nonsingular, although the converse is not true.
2.2.3 Cholesky Decomposition
Definition 2.18. (Cholesky Decomposition) In linear algebra, the Cholesky decomposition or Choleskyfactorization is a decomposition of a Hermitian, positive-definite matrix into the product of a lower trian-gular matrix and its conjugate transpose,
A= LL∗.
Definition 2.19. (LDM Decomposition) Let A ∈ Rn×n and all the leading principal minors det(A(1 :k;1 : k)) , 0;k = 1, · · · ,n−1. Then there exist unique unit lower triangular matrices L and M and a uniquediagonal matrix D = diag(d1, · · · ,dn), such that
A= LDMT .
Page 38 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 39
Definition 2.20. (LDL Decomposition) A closely related variant of the classical Cholesky decompositionis the LDL decomposition,
A= LDL∗,
where L is a lower unit triangular (unitriangular) matrix and D is a diagonal matrix.
Remark 2.3. This decomposition is related to the classical Cholesky decomposition, of the form LL∗, as follows:
A= LDL∗= LD
12D
12 ∗L∗ = LD
12 (LD
12 )∗.
The LDL variant, if efficiently implemented, requires the same space and computational complexity to constructand use but avoids extracting square roots. Some indefinite matrices for which no Cholesky decomposition existshave an LDL decomposition with negative entries in D. For these reasons, the LDL decomposition may be pre-ferred. For real matrices, the factorization has the formA= LDLT and is often referred to as LDLT decomposition(or LDLT decomposition). It is closely related to the eigendecomposition of real symmetric matrices, A=QΛQT .
2.2.4 The Relationship of the Existing Decomposition
From last subsection, If A= A∗, then
1. diagonal elements of A are real and positive .
2. principal sub matrices of A are HPD .
Comparsion 2.2. (Gram- Schmidt and Householder)
A= LDM∗
A= LDM∗ = LDL∗ L=M
A= LDL∗ A= LDL∗ = LD12D
12 ∗L∗ L= LD
12
A= LU A= LU = LL∗ U = L∗
2.2.5 Regular Splittings[3]
Definition 2.21. (Regular Splittings) Let A,M,N be three given matrices satisfying
A=M −N .
The pair of matrices M,N is a regular splitting of A, if M is nonsingular and M−1 and N are nonnegative .
Theorem 2.9. (The eigenvalue radius estimation of Regular Splittings[3]) LetM,N be a regular splittingof A. Then
ρ(M−1N ) < 1
if only if A is nonsingular and A−1 is nonnegative.
Proof. 1. Define G =M−1N , since ρ(G) < 1, then I −G is nonsingular. And then A =M(I −G), so A isnonsingular. So, by Theorem.1.28 satisfied, since G = M−1N is nonsingular and ρ(G) < 1, then wehave (I −G)−1 is nonnegative as is A−1 = (I −G)−1M−1.
Page 39 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 40
2. ⇐: since A,M are nonsingular and A−1 is nonnegative, then A=M(I −G) is nonsingular. Moreover
A−1N =(M(I −M−1N )
)−1N
= (I −M−1N )−1M−1N
= (I −G)−1G.
Clearly, G =M−1N is nonnegative by the assumptions, and as a result of the Perron-Frobenius theo-rem, there is a nonnegative eigenvector x associated with ρ(G) which is an eigenvalue, such that
Gx = ρ(G)x.
Therefore
A−1Nx =ρ(G)
1− ρ(G)x.
Since x and A−1N are nonnegative, this shows that
ρ(G)
1− ρ(G)≥ 0.
and this can be true only when 0 ≤ ρ(G) ≤ 1. Since I −G is nonsingular, then ρ(G) , 1, which impliesthat ρ(G) < 1.
2.3 Problems
Problem 2.1. (Prelim Aug. 2010#1) Prove that A ∈ Cm×n(m > n) and let A = QR be a reduced QRfactorization.
1. Prove that A has rank n if and only if all the diagonal entries of R are non-zero.
2. Suppose rank(A) = n, and define P = QQ∗. Prove that range(P ) = range(A).
3. What type of matrix is P?
Solution. 1. From the properties of reduced QR factorization, we know that Q has orthonormal columns,therefore det(Q) = 1 and R is upper triangular matrix, so det(R) =
∏ni=1 rii . Then
det(A) = det(QR) = det(Q)det(R) =n∏i=1
rii .
Therefore, A has rank n if and only if all the diagonal entries of R are non-zero.
2. (a) range(A) ⊆ range(P ): Let y ∈ range(A), that is to say there exists a x ∈ Cn s.t. Ax = y. Then byreduced QR factorization we have y = QRx. then
P y = P QRx = QQ∗QRx = QRx = Ax = y.
therefore y ∈ range(P ).(b) range(P ) ⊆ range(A): Let v ∈ range(P ), that is to say there exists a v ∈ Cn, s.t. v = P v = QQ∗v.
Claim 2.1.
QQ∗ = A (A∗A)−1A∗.
Page 40 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 41
Proof.
A (A∗A)−1A∗ = QR(R∗Q∗QR
)−1R∗Q∗
= QR(R∗R
)−1R∗Q∗
= QRR−1(R∗
)−1R∗Q∗
= QQ∗.
J
Therefore by the claim, we have
v = P v = QQ∗v = A (A∗A)−1A∗v = A((A∗A)−1A∗v
)= Ax.
where x = (A∗A)−1A∗v. Hence v ∈ range(A).
3. P is an orthogonal projector.J
Problem 2.2. (Prelim Aug. 2010#4) Prove that A ∈ Rn×n is SPD if and only if it has a Cholesky factor-ization.
Solution. 1. Since A is SPD, so it has LU factorization, and L= U , i.e.
A= LU = UTU .
Therefore, it has a Cholesky factorization.
2. if A has Cholesky factorization, i.e A= UTU , then
xTAx = xTUTUx = (Ux)TUx.
Let y = Ux, then we have
xTAx = (Ux)TUx = yT y = y21 + y2
2 + · · ·+ y2n ≥ 0,
with equality only when y = 0, i.e. x=0 (since U is non-singular). Hence A is SPD.J
Problem 2.3. (Prelim Aug. 2009#2) Prove that for any matrix A ∈ Cn×n, singular or nonsingular, thereexists a permutation matrix P ∈Rn×n such that PA has an LU factorization, i.e. PA=LU.
Solution. J
Problem 2.4. (Prelim Aug. 2009#4) Let A ∈ Cn×n and σ1 ≥ σ2 ≥ · · ·σn ≥ 0 be its singular values.
1. Let λ be an eigenvalue of A. Show that |λ| ≤ σ1.
2. Show that∣∣∣det(A)
∣∣∣=∏nj=1σj .
Solution. 1. Since σ1 = ‖A‖2(proof follows by induction), so we need to show |λ| ≤ ‖A‖2.
|λ| ‖x‖2 = ‖λx‖2 = ‖Ax‖ ≤ ‖A‖2 ‖x‖2 .
Therefore,
|λ| ≤ σ1.
Page 41 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 42
2. ∣∣∣det(A)∣∣∣= ∣∣∣det(UΣV ∗)
∣∣∣ ∣∣∣det(U )∣∣∣ ∣∣∣det(Σ)
∣∣∣ ∣∣∣det(V ∗)∣∣∣= ∣∣∣det(Σ)
∣∣∣= n∏j=1
σj .
J
Problem 2.5. (Prelim Aug. 2009#4) Let
Solution. J
Page 42 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 43
3 Iterative Method
3.1 Diagonal dominant
Definition 3.1. (Diagonal dominant of size δ) A ∈ Cn×n has diagonal dominant of size δ > 0 if
|aii | ≥∑j,i
|aij |+ δ.
Properties 3.1. If A ∈ Cn×n is diagonal dominant of size δ > 0 then
1. A−1 exists.
2.∥∥∥A−1
∥∥∥∞ ≤ 1δ .
Proof. 1. Let b = Ax and chose k ∈ (1,2,3, · · · ,n) s.t ‖x‖∞ = |xk |. Moreover, let bk =∑nj=1 akjxj . Since
|aii | ≥∑j,i
|aij |+ δ,
and ∑j,i
|aijxj | ≤∑j,i
|aij ||xj | ≤ ‖x‖∞∑j,i
|aij |.
Then
|bk | =
∣∣∣∣∣∣∣∣n∑j=1
akjxj
∣∣∣∣∣∣∣∣=
∣∣∣∣∣∣∣∣akkxk +n∑j,k
akjxj
∣∣∣∣∣∣∣∣≥ |akkxk | −
∣∣∣∣∣∣∣∣n∑j,k
akjxj
∣∣∣∣∣∣∣∣≥ |akkxk | − ‖x‖∞
∑j,i
|aij |
≥ |akk | ‖x‖∞ − ‖x‖∞∑j,i
|aij |
= δ ‖x‖∞ .
So, ‖Ax‖∞ = ‖b‖∞ ≥ ‖bk‖∞ ≥ δ ‖x‖∞. If Ax = 0, then x = 0. So, ker(A) = 0, and then, A−1 exists.
2. Since ‖Ax‖∞ = ‖b‖∞ ≥ ‖bk‖∞ ≥ δ ‖x‖∞, so ‖Ax‖ ≥ δ ‖x‖∞ and∥∥∥A−1
∥∥∥∞ ≤ 1δ .
3.2 General Iterative Scheme
An iterative scheme for the solution
Ax = b, (115)
Page 43 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 44
is a sequence given by
xk+1 = φ(A,b,xk , · · · ,xk−r).
1. r = 0- two layer scheme.
2. r ≥ 1multi-layer scheme.
3. φ - is a linear function of its arguments then the scheme is linear, otherwise it is nonlinear.
4. convergent if xkk→∞→ x.
Definition 3.2. (General Iterative Scheme) A general linear two layer iterative scheme reads
Bk
(xk+1 − xk
αk
)+Axk = b.
1. αk ∈ R,Bk ∈ Cn×n–iterative parameters
2. If αk = α,Bk = B, then the method is stationary.
3. If Bk = I , then the method is explicit.
If xk → x0, then x0 solves Ax = b. So
Bk
(x0 − x0
αk
)+Ax0 = b,
i.e.
Ax0 = b.
Now, consider the stationary scheme, i.e
B
(xk+1 − xk
α
)+Axk = b.
Then we get
xk+1 = xk +αB−1(b −Axk).
Definition 3.3. (Error Transfer Operator) Let ek = x−xk , where x is exact solution and xk is the approx-imate solution at k step. Then
x = x+αB−1(b −Ax)xk+1 = xk +αB−1(b −Axk).
So, we get
ek+1 = ek +αB−1Aek = (I −αB−1A)ek := T ek .
T = I −αB−1A is the error transfer operator.
After we defined the error transfer operator , the iterative can be written as
xk+1 = T xk +αB−1b.
Page 44 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 45
Theorem 3.1. (sufficient condition for converges) The sufficient condition for converges is
‖T ‖ < 1. (116)
Theorem 3.2. (sufficient & necessary condition for converges) The sufficient & necessary condition forconverges is
ρ(T ) < 1, (117)
where ρ(T ) is the spectral radius of T.
3.3 Stationary cases iterative method
3.3.1 Jacobi Method
Definition 3.4. (Jacobi Method) Let
A= L+D +U .
A Jacobi Method scheme reads
D(xk+1 − xk
)+Axk = b.
i.e. αk = 1,B= D in the general iterative scheme.
Definition 3.5. (Error Transfer Operator for Jacobi Method ) the error transfer operator for Jacobi Methodis as follows
T = I −D−1A.
Remark 3.1. Since
A= L+D +U .
and
D(xk+1 − xk
)+Axk = b.
Then we have
D(xk+1 − xk
)+ (L+D +U )xk = Lxk +Dxk+1 +Uxk = b.
So, the Jacobi iterative method can be written as∑j<i
aijxkj + aiix
k+1i +
∑j>i
aijxkj = bi ,
or
xk+1i =
1aii
bi −∑j,i
aijxkj
.
Page 45 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 46
Theorem 3.3. (convergence of the Jacobi Method) If A is diagonal dominant , then the Jacobi Methodconvergences.
Proof. We want to show If A is diagonal dominant , then∥∥∥TJ∥∥∥ < 1, then Jacobi Method convergences. From
the definition of T, we know that T for Jacobi Method is as follows
TJ = I −D−1A.
In the matrix form is
T =
1 0
. . .0 1
−
1a11
0. . .
0 1ann
a11 · · · a1n
.... . .
...an1 · · · ann
= [tij
]=
tij = 0, i = j,tij = −
aijaii
, i , j..
So,
‖T ‖∞ = maxi
∑j
|tij |= maxi
∑i,j
|aijaii|.
Since A is diagonal dominant, so
|aii | ≥∑j,i
|aij |+ δ.
Therefore,
1 ≥∑j,i
|aij ||aii |
+δ|aii |
.
Hence, ‖T ‖∞ < 1
3.3.2 Gauss-Seidel Method
Definition 3.6. (Gauss-Seidel Method) Let
A= L+D +U .
A Gauss-Seidel Method scheme reads
(L+D)(xk+1 − xk
)+Axk = b.
i.e. αk = 1,B= L+D in the general iterative scheme.
Definition 3.7. (Error Transfer Operator for Gauss-Seidel Method ) The error transfer operator for Gauss-Seidel Method is as follows
T = I − (L+D)−1A
= I − (L+D)−1(L+D +U )
= −(L+D)−1U .
Page 46 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 47
Remark 3.2. The Gauss-Seidel method is an iterative technique for solving a square system of n linear equationswith unknown x:
Ax = b.
It is defined by the iteration
L∗x(k+1) = b−Ux(k),
where the matrix A is decomposed into alower triangular component L∗, and a strictly upper triangularcomponent U: A= L∗+U .
In more detail, write out A, x and b in their components:
A=
a11 a12 · · · a1na21 a22 · · · a2n
......
. . ....
an1 an2 · · · ann
, x =
x1x2...xn
, b =
b1b2...bn
.
Then the decomposition of A into its lower triangular component and its strictly upper triangular component isgiven by:
A= L∗+U where L∗ =
a11 0 · · · 0a21 a22 · · · 0
......
. . ....
an1 an2 · · · ann
, U =
0 a12 · · · a1n0 0 · · · a2n...
.... . .
...0 0 · · · 0
.
The system of linear equations may be rewritten as:
L∗x = b−Ux
The Gauss-Seidel method now solves the left hand side of this expression for x, using previous value for x on theright hand side. Analytically, this may be written as:
x(k+1) = L−1∗ (b−Ux(k)).
However, by taking advantage of the triangular form of L∗, the elements of x(k+1) can be computed sequentiallyusing forward substitution:
x(k+1)i =
1aii
bi −∑j<i
aijx(k+1)j −
∑j>i
aijx(k)j
, i, j = 1,2, . . . ,n.
The procedure is generally continued until the changes made by an iteration are below some tolerance, such as asufficiently small residual.
Theorem 3.4. (convergence of the Gauss-Seidel Method) If A is diagonal dominant , then the Gauss-SeidelMethod convergences.
Proof. We want to show If A is diagonal dominant , then ‖TGS‖ < 1, then Gauss-Seidel Method conver-gences. From the definition of T, we know that T for Gauss-Seidel Method is as follows
TGS = −(L+D)−1U .
Page 47 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 48
Next, we will show ‖TGS‖ < 1. Since A is diagonal dominant, so
|aii | ≥∑j,i
|aij |+ δ =∑j>i
|aij |+∑j<i
|aij |+ δ.
So,
|aii | −∑j<i
|aij | ≥∑j>i
|aij |+ δ,
which implies
γ =maxi
∑j>i |aij |
|aii | −∑j<i |aij
|≤ 1.
Now, we will show ‖TGS‖ < γ . Let x ∈ Cn and y = T x, i.e.
y = TGSx = −(L+D)−1Ux.
Let i0 be the index such that∥∥∥y∥∥∥∞ = |yi0 |, then we have
|((L+D)y)i0 |= |(Ux)i0 |= |∑j>i0
ai0jxj | ≤∑j>i0
|ai0j ||xj | ≤∑j>i0
|ai0j | ‖x‖∞ .
Moreover
|((L+D)y)i0 |= |∑j<i0
ai0jyj + ai0i0yj | ≥ |ai0i0yj | − |∑j<i0
ai0jyj |= |ai0i0 |∥∥∥y∥∥∥∞ − |∑
j<i0
ai0jyj | ≥ |ai0i0 |∥∥∥y∥∥∥∞ −∑
j<i0
|ai0j |∥∥∥y∥∥∥∞ .
Therefore, we have
|ai0i0 |∥∥∥y∥∥∥∞ −∑
j<i0
|ai0j |∥∥∥y∥∥∥∞ ≤∑
j>i0
|ai0j | ‖x‖∞ ,
which implies ∥∥∥y∥∥∥∞ ≤∑j>i0|ai0j |
|ai0i0 | −∑j<i0|ai0j |
‖x‖∞ .
So,
‖TGSx‖∞ ≤ γ ‖x‖∞ ,
which implies
‖TGS‖∞ ≤ γ < 1.
3.3.3 Richardson Method
Definition 3.8. (Richardson Method) Let
A= L+D +U .
A Richardson Method scheme reads
I
(xk+1 − xk
ω
)+Axk = b.
i.e. αk = ω , 1,B= I in the general iterative scheme.
Page 48 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 49
Definition 3.9. (Error Transfer Operator for Gauss-Seidel Method ) The error transfer operator for Gauss-Seidel Method is as follows
TRC = I −ω(B)−1A= I −ωA.
Remark 3.3. Richardson iteration is an iterative method for solving a system of linear equations. Richardsoniteration was proposed by Lewis Richardson in his work dated 1910. It is similar to the Jacobi and Gauss-Seidelmethod. We seek the solution to a set of linear equations, expressed in matrix terms as
Ax = b.
The Richardson iteration is
x(k+1) = (I −ωA)x(k) +ωb.
where α is a scalar parameter that has to be chosen such that the sequence x(k) converges.It is easy to see that the method has the correct fixed points, because if it converges, then x(k+1) ≈ x(k)andx(k)
has to approximate a solution of Ax = b.
Theorem 3.5. (convergence of the Richardson Method) Let A = A∗ > 0 (SPD). If 0 < ω < 2λmax
, then theRichardson Method convergences. Moreover, the best acceleration parameter is given by
ωopt =2
λmin +λmax,
in which, similarly, λmin is the smallest eigenvalue of ATA.
Proof. 1. From the above lemma, we know that the error transform operator is as follows
TRC = I −ω(B)−1A= I −ωA.
Let λ ∈ σ (A), then ν := 1−ωλ ∈ σ (T ). From the sufficient and & necessary condition for convergence,we know if σ (T ) < 1, then Richardson Method convergences, i.e.
|1−ωλ| < 1,
which implies
−1 < 1−ωλmax ≤ 1−ωλmin < 1.
So, we get −1 < 1−ωλmax, i.e.
ω <2
λmax.
2. The minimum is attachment at |1−ωλmax|= |1−ωλmin|(Figure.1), i.e.
ωλmax − 1 = 1−ωλmin.
Therefore, we get
ωopt =2
λmin +λmax.
Page 49 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 50
ωoptω
1
1λmin
|1−λmin|
1λmax
|1−λmax|
Figure 1: The curve of ρ(TRC) as a function of ω
3.3.4 Successive Over Relaxation (SOR) Method
Definition 3.10. (SOR Method) Let
A= L+D +U .
A SOR Method scheme reads
(ωL+D)
(xk+1 − xk
ω
)+Axk = b.
i.e. αk = ω , 1,B= ωL+D in the general iterative scheme.
Remark 3.4. For Gauss-seidel method, we have
Lxk+1 +Dxk+1 +Uxk = b.
If we relax the contribution of the diagonal part, i.e. let ω > 0,
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 58
3.5.4 Steepest Descent Method
Definition 3.16. (Steepest Descent Method) Steepest Descent iterative Method is going to chooseα1,α2, · · · ,αk , s.t. the error
∥∥∥ek+1∥∥∥A
is minimal for(xk+1 − xk
αk+1
)+Axk = b.
Theorem 3.14. (optimal αk+1 of Steepest Descent iterative Method) The optimal αk+1 of Steepest Descentiterative Method is as follows
αk+1 =
∥∥∥Aek∥∥∥22∥∥∥Aek∥∥∥2A
=
∥∥∥rk∥∥∥22∥∥∥rk∥∥∥2A
.
Proof. From the iterative scheme (xk+1 − xk
αk+1
)+Axk = b = Ax,
we get
ek+1 = ek +αk+1Aek .
Therefore ∥∥∥ek+1∥∥∥2
A= (Aek+1,ek+1)
= (Aek +αk+1A2ek ,ek +αk+1Ae
k)
=∥∥∥ek∥∥∥2
A− 2αk+1
∥∥∥Aek∥∥∥2
2+α2
k+1
∥∥∥Aek∥∥∥2
A
When αk+1 minimize the residuals, the
(∥∥∥ek+1
∥∥∥2
2)′ = −2
∥∥∥Aek∥∥∥2
2+ 2αk+1
∥∥∥Aek∥∥∥2
A= 0, i.e.
αk+1 =
∥∥∥Aek∥∥∥22∥∥∥Aek∥∥∥2A
=
∥∥∥rk∥∥∥22∥∥∥rk∥∥∥2A
.
The last step, we use the fact Aek = rk .
Theorem 3.15. (convergence of Steepest Descent iterative Method) The Steepest Descent iterative Methodconverges for any x0 (A= A∗ > 0,B= B∗ > 0) and∥∥∥ek∥∥∥
A≤ ρn0
∥∥∥e0∥∥∥A
, with ρ0 =κ2(A)− 1κ2(A) + 1
.
Proof. Same as convergence of minimal residuals iterative Method.
Page 58 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 59
3.5.5 Conjugate Gradients Method
Definition 3.17. (Conjugate Gradients Method) Conjugate Gradients Method iterative Method is a three-layer iterative method which is going to choose α1,α2, · · · ,αk and τ1,τ2, · · · ,τk , s.t. the error
∥∥∥ek+1∥∥∥A
isminimal for
B(xk+1 − xk) + (1−αk+1)(x
k − xk−1)
αk+1τk+1+Axk = b.
3.5.6 Another look at Conjugate Gradients Method
If A is SPD, we know that solving Ax = b is equivalent to minimize the following quadratic functional
Φ(x) =12(Ax,x)− (f ,x).
In fact, the minimum value of Φ is −12 (A
−1f ,f ) at x = A−1f and the residual rk is the negative gradient ofΦ at xk , i.e.
rk = −∇Φ(xk).
• Richardson method is always using the increment along the negative gradient of Φ to correct theresult, i.e.
xk+1 = xk +αkrk .
• Conjugate Gradients Method is using the increment along the direction pk which is not parallel tothe gradient of Φ to correct the result.
Definition 3.18. (A-Conjugate) The direction pk is call A-Conjugate, if (pj ,Apk) = 0 when j , k. Inparticular,
(pk+1,Apk) = 0, ∀k ∈N.
Let p0,p1, · · · ,pm be the linearly independent series and x0 be the initial guess, then we can constructthe following series
xk+1 = xk +αkpk , 0 ≤ k ≤m.
where αk is nonnegative. And then the minimum functional Φ(x) of xk+1 on k+ 1 dimension hyperplaneis
x = x0 +k∑j=0
γjpj , γj ∈R
if and only if pj is A-Conjugate and
αk =(rk ,pk)
(pk+1,Apk).
Page 59 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 60
Properties 3.2. (properties of pk and rk) the pk and rk come from the Conjugate Gradients methodhave the following properties:
• (pj ,rj) = 0, 0 ≤ i < j ≤ k
• (pi ,Apj) = 0, i , j 0 ≤ i, j ≤ k
• (r i ,rj) = 0, i , j 0 ≤ i, j ≤ k
Theorem 3.16. (convergence of Conjugate Gradients iterative Method) The Conjugate Gradients iterativeMethod converges for any x0 (A= A∗ > 0,B= B∗ > 0) and
∥∥∥ek∥∥∥A≤ 2ρn0
∥∥∥e0∥∥∥A
, with ρ0 =
√κ2(A)− 1√κ2(A) + 1
.
Definition 3.19. (Krylov subspace) In linear algebra, the order-k Krylov subspace generated by an n-by-nmatrix A and a vector b of dimension n is the linear subspace spanned by the images of b under the first k-1powers of A (starting from A0 = I), that is,
Kk(A,b) = span b,Ab,A2b, . . . ,Ak−1b.
Theorem 3.17. (Conjugate Gradients iterative Method in Krylov subspace) For Conjugate Gradientsiterative Method, we have
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 61
3.6 Problems
Problem 3.1. (Prelim Jan. 2011#1) Consider a linear system Ax = b with A ∈Rn×n. Richardson’s methodis an iterative method
Mxk+1 = Nxk + b
withM = 1w ,N =M−A= 1
w I−A, where w is a damping factor chosen to make M approximate A as well aspossible. Suppose A is positive definite and w > 0. Let λ1 and λn denote the smallest and largest eigenvalueof A.
1. Prove that Richardson’s method converges if and only if w < 2λn
.
2. Prove that the optimal value of w is w0 =2
λ1+λn.
Solution. 1. Since M = 1w ,N =M −A= 1
w I −A, then we have
xk+1 = (I −wA)xk + bw.
So TR = I − wA, From the sufficient and & necessary condition for convergence, we should haveρ(TR) < 1. Since λi are the eigenvalue of A, then we have 1 − λiw are the eigenvalues of TR. HenceRichardson’s method converges if and only if |1−λiw| < 1, i.e
−1 < 1−λnw < · · · < 1−λ1w < 1,
i.e. w < 2λn
.
2. the minimal attaches at |1−λnw|= |1−λ1w| (Figure. B2), i.e
λnw − 1 = 1−λ1w,
i,e
w0 =2
λ1 +λn.
J
woptw
1
1λ1
|1−λ1|
1λn
|1−λn|
Figure 2: The curve of ρ(TR) as a function of w
Page 61 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 62
Problem 3.2. (Prelim Aug. 2010#3) Suppose that A ∈Rn×n is SPD and b ∈Rn is given. Then nth Krylovsubspace us defined as
Kn :=⟨b,Ab,A2b, · · · ,Ak−1b
⟩.
Letxj
n−1
j=0,x0 = 0, denote the sequence of vectors generated by the conjugate gradient algorithm. Prove
that if the method has not already converged after n − 1 iterations, i.e. rn−1 = b −Axn−1 , 0, then the nth
iterate xn us the unique vector in Kn that minimizes
φ(y) =∥∥∥x∗ − y∥∥∥2
A,
where x∗ = A−1b.
Solution. J
Problem 3.3. (Prelim Jan. 2011#1)
Solution. J
Page 62 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 63
4 Eigenvalue Problems
Definition 4.1. (Gerschgorin disks) Let A ∈ Cn×n, the Gerschgorin disks of A are
Di = ξ ∈ C : |ξ − aii | <Ri where Ri =∑i,j
|aij |.
Theorem 4.1. Every eigenvalue of A lies within at least one of the Gerschgorin discs Di
Proof. Let λ be an eigenvalue of A and let x = (xj) be a corresponding eigenvector. Let i ∈ 1, · · · ,n bechosen so that |xi | = maxj |xj |. (That is to say, choose i so that xi is the largest (in absolute value) numberin the vector x) Then |xi | > 0, otherwise x = 0. Since x is an eigenvector, Ax = λx, and thus:∑
j
aijxj = λxi ∀i ∈ 1, . . . ,n.
So, splitting the sum, we get ∑j,i
aijxj = λxi − aiixi .
We may then divide both sides by xi (choosing i as we explained, we can be sure that xi , 0) and take theabsolute value to obtain
|λ− aii |=∣∣∣∣∣∣∑j,i aijxjxi
∣∣∣∣∣∣ ≤∑j,i
∣∣∣∣∣aijxjxi
∣∣∣∣∣ ≤∑j,i
|aij |= Ri
where the last inequality is valid because ∣∣∣∣∣xjxi∣∣∣∣∣ ≤ 1 for j , i.
Corollary 4.1. The eigenvalues of A must also lie within the Gerschgorin discs Di corresponding to thecolumns of A.
Proof. Apply the Theorem to AT .
Definition 4.2. (Reyleigh Quotient) Let A ∈Rn×n, x ∈Rn. The Reyleigh Quotient is
R(x) =(Ax,x)(x,x)
.
Remark 4.1. If x is an eigenvector of A, then Ax = λx and
R(x) =(Ax,x)(x,x)
= λ.
Page 63 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 64
Properties 4.1. (properties of Reyleigh Quotient) Reyleigh Quotient has the following properties:
1.
∇R(x) = 2(x,x)
[Ax −R(x)x]
2. R(x) minimizes
f (α) = ‖Ax −αx‖2 .
Proof. 1. From the definition of the gradient, we have
∇R(x) =[∂r(x)
∂x1,∂r(x)
∂x2, · · · ,
∂r(x)
∂xn
].
By using the quotient rule, we have
∂r(x)
∂xi=
∂∂xi
((Ax,x)(x,x)
)=
∂∂xi
(xTAx
xT x
)=
∂∂xi
(xTAx
)xT x − xTAx ∂
∂xi
(xT x
)(xT x)2 ,
where∂∂xi
(xTAx
)=
∂∂xi
(xT
)Ax+ xT
∂∂xi
(Ax)
= [0, · · · ,0,1i,0, · · · ,0]Ax+ xTA
0...010...0
i
= (Ax)i + (Ax)i = 2 (Ax)i .
Similarly,
∂∂xi
(xT x
)=
∂∂xi
(xT
)x+ xT
∂∂xi
(x)
= [0, · · · ,0,1i,0, · · · ,0]x+ xT
0...010...0
i
= 2xi .
Therefore, we have
∂r(x)
∂xi=
2 (Ax)ixT x
− xTAx2xi(xT x)2
=2xT x
((Ax)i −R(x)xi) .
Page 64 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 65
Properties 4.2. (properties of QR algorithm) QR algorithm has the following properties:
1. Ak is similar to Ak−1
2. Ak−1 =(Ak−1
)∗and Ak =
(Ak
)∗3. If Ak−1 is tridiagonal, then Ak is tridiagonal.
Proof. 1. Since QkRk = Ak−1 , so Rk =(Qk
)−1Ak−1 and Ak = RkQk =
(Qk
)−1Ak−1Qk .
Page 65 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 66
2. Since Q is unitary, so Q∗ =Q−1 and A= A∗, so(Ak
)∗=
((Qk
)−1Ak−1Qk
)∗=
(Qk
)∗ (Ak−1
)∗ ((Qk
)−1)∗=
(Qk
)−1 (Ak−1
)∗ (Qk
)=
(Qk
)−1Ak−1
(Qk
)= Ak .
Similarly, (Ak−1
)∗=
(QkAk
(Qk
)−1)∗=QkAk
(Qk
)−1= Ak−1.
3. since Ak is similar to Ak−1.
4.3 Power iteration algorithm
Algorithm 4.3. (Power iteration algorithm)
• v0: an arbitrary nonzero vector
• compute vk = Avk−1
Remark 4.2. This algorithm generates a sequence of vectors
v0,Av0,A2v0,A3v0, · · · .
If we want to prove that this sequence converges to an eigenvector of A, the matrix needs to be such that it has aunique largest eigenvalue λ1,
|λ1| > |λ2| ≥ · · · |λm| ≥ 0.
There is another technical assumption. The initial vector v0 needs to be chosen such that qT1 v0 , 0 . Otherwise,
if v0 is completely perpendicular to the eigenvector q1, the algorithm will not converge.
Algorithm 4.4. (improved Power iteration algorithm)
• v0: an arbitrary nonzero vector with∥∥∥v0
∥∥∥2= 1
• compute wk = Avk−1
• compute vk = wk
‖wk‖2• compute λk =R(vk)
Theorem 4.2. (Convergence of power algorithm) If A = A∗, qT1 v0 , 0 and |λ1| > |λ2| ≥ · · · |λm| ≥ 0, then
the convergence to the eigenvector of improved Power iteration algorithm is linear, while the convergence tothe eigenvalue is still quadratic, i.e.
∥∥∥vk − (±q1)∥∥∥
2= O
(∣∣∣∣∣λ2
λ1
∣∣∣∣∣k)∥∥∥λk −λ1
∥∥∥2= O
(∣∣∣∣∣λ2
λ1
∣∣∣∣∣2k).
Page 66 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 67
Proof. let q1,q2, · · · ,qn be the orthogonal basis of R. Then v0 can be rewritten as
v0 =∑
αjqj .
Moreover, following the power algorithm, we have
w1 = Av0 =∑
αjAqj =∑
αjλjqj .(Aqj = λjqj)
v1 =
∑αjλjqj√∑α2j λ
2j
w2 = Av1 =
∑αjλjAqj√∑α2j λ
2j
=
∑αjλ
2j qj√∑
α2j λ
2j
v2 =
∑αjλ
2j qj√∑
α2j λ
2·2j
· · ·
wk =
∑αjλ
kj qj√∑
α2j λ
2·(k−1)j
vk =
∑αjλ
kj qj√∑
α2j λ
2·kj
.
vk can be rewritten as
vk =
∑αjλ
kj qj√∑
α2j λ
2·kj
=α1λ
k1q1 +
∑j>1αjλ
kj qj√
α21λ
2k1 +
∑j>1α
2j λ
2kj
=α1λ
k1
|α1λk1|·q1 +
∑j>1
αjα1
(λjλ1
)kqj√
1+∑j>1
( αjα1
)2(λjλ1
)2k
= ±1q1 +
∑j>1
αjα1
(λjλ1
)kqj√
1+∑j>1
( αjα1
)2(λjλ1
)2k.
Therefore, ∥∥∥vk − (±q1)∥∥∥
2≤
∣∣∣∣∣∣∣∣∑j>1
αjα1
(λjλ1
)kqj
∣∣∣∣∣∣∣∣ ≤ C(∣∣∣∣∣λ2
λ1
∣∣∣∣∣)k = O(∣∣∣∣∣λ2
λ1
∣∣∣∣∣k).From Taylor formula ∥∥∥λk −λ1
∥∥∥2= |R(vk)−R(q1)|= O
∥∥∥vk − q1
∥∥∥2
2= O
(∣∣∣∣∣λ2
λ1
∣∣∣∣∣2k).Remark 4.3. This shows that the speed of convergence depends on the gap between the two largest eigenvalues
of A. In particular, if the largest eigenvalue of A were complex (which it can’t be for the real symmetric matriceswe are considering), then λ2 = λ1 and the algorithm would not converge at all.
Page 67 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 68
4.4 Inverse Power iteration algorithm
Algorithm 4.5. (inverse Power iteration algorithm)
• v0: an arbitrary nonzero vector with∥∥∥v0
∥∥∥2= 1
• compute wk = A−1vk−1
• compute vk = wk
‖wk‖2• compute λk =R(vk)
Algorithm 4.6. (Improved inverse Power iteration algorithm)
• v0: an arbitrary nonzero vector with∥∥∥v0
∥∥∥2= 1
• compute wk = (A−µI)−1vk−1
• compute vk = wk
‖wk‖2• compute λk =R(vk)
Remark 4.4. Improved inverse Power iteration algorithm is a shift µ.
Theorem 4.3. (Convergence of power algorithm) If A = A∗, qT1 v0 , 0 and |λ1| > |λ2| ≥ · · · |λm| ≥ 0, If we
update the estimate µ for the eigenvalue with the Rayleigh quotient at each iteration we can get a cubicallyconvergent algorithm, i.e. ∥∥∥vk+1 − (±qJ )
∥∥∥2= O
(∥∥∥vk − (±qJ )∥∥∥3
2
)∥∥∥λk −λJ∥∥∥2
= O(|λk −λJ |3
).
4.5 Problems
Problem 4.1. (Prelim Aug. 2013#1)
Solution. J
Page 68 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 69
5 Solution of Nonlinear problems
Definition 5.1. (convergence with Order p) An iterative scheme converges with order p>0 if there is aconstant C > 0, such that
|x − xk+1| ≤ C|x − xk |p. (118)
5.1 Bisection method
Definition 5.2. (Bisection method) The method is applicable for solving the equation f(x) = 0 for the realvariable x, where f is a continuous function defined on an interval [a, b] and f(a) and f(b) have oppositesigns i.e. f (a)f (b) < 0. In this case a and b are said to bracket a root since, by the intermediate valuetheorem, the continuous function f must have at least one root in the interval (a, b).
Algorithm 1 Bisection method1: a0← a,b0← b2: while k > 0 do3: ck←
ak−1+bk−12
4: if f (ak)f (ck) < 0 then5: ak← ak−16: bk← ck7: end if8: if f (bk)f (ck) < 0 then9: ak← ck
10: bk← bk−111: end if12: xk← ck← ak+bk
213: end while
5.2 Chord method
Definition 5.3. (Chord method) The method is applicable for solving the equation f(x) = 0 for the realvariable x, where f is a continuous function defined on an interval [a, b] and f(a) and f(b) have oppositesigns i.e. f (a)f (b) < 0. Instead of the [a,b] segment halving, we?ll divide it relation f (a) : f (b), It givesthe approach of a root of the equation
xk+1 = xk −[ηk
]−1f (xk).
where
ηk =f (b)− f (a)
b − a
Page 69 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 70
Algorithm 2 Chord method
1: x1 = a− f (a)f (b)−f (a) (b − a), x0 = 0
2: ηk = f (b)−f (a)b−a
3: while |xk+1 − xk | < ε do4: xk+1← xk −
[ηk
]−1f (xk)
5: end while
5.3 Secant method
Definition 5.4. (Secant method) The method is applicable for solving the equation f(x) = 0 for the realvariable x, where f is a continuous function defined on an interval [a, b] and f(a) and f(b) have oppositesigns i.e. f (a)f (b) < 0. Instead of the [a,b] segment halving, we?ll divide it relation f (xk) : f (xk−1), Itgives the approach of a root of the equation
xk+1 = xk −[ηk
]−1f (xk).
where
ηk =f (xk)− f (xk−1)
xk − xk−1
Algorithm 3 Secant method
1: x1 = a− f (a)f (b)−f (a) (b − a)
2: ηk = f (xk)−f (xk−1)xk−xk−1 ,x0 = 0
3: while |xk+1 − xk | < ε do4: xk+1← xk −
[ηk
]−1f (xk)
5: end while
5.4 Newton’s method
Definition 5.5. (Newton’s method) The method is applicable for solving the equation f(x) = 0 for the realvariable x, where f is a continuous function defined on an interval [a, b] and f(a) and f(b) have oppositesigns i.e. f (a)f (b) < 0. Instead of the [a,b] segment halving, we?ll divide it relation f ′(xk), It gives theapproach of a root of the equation
xk+1 = xk −[ηk
]−1f (xk).
where
ηk = f ′(xk)
Remark 5.1. This scheme needs f ′(xk) , 0.
Page 70 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 71
Algorithm 4 Newton’s method
1: x1 = a− f (a)f (b)−f (a) (b − a)
2: ηk = f ′(xk),x0 = 03: while |xk+1 − xk | < ε do4: xk+1← xk −
[ηk
]−1f (xk)
5: end while
Theorem 5.1. (convergence of Newton’s method) Let f ∈ C2,f (x∗) = 0,f ′(x) , 0 and f ′′(x∗) is boundedin a neighborhood of x∗. Provide x0 is sufficient close to x∗, then newton’s method converges quadratically,i.e. ∣∣∣xk+1 − x∗
∣∣∣ ≤ C ∣∣∣xk − x∗∣∣∣2 .
Proof. Let x∗ be the root of f (x). From the Taylor expansion, we know
0 = f (x∗) = f (xk) + f ′(xk)(x∗ − xk) + 12f ′′(θ)(x∗ − xk)2,
where θ is between x∗ and xk . Define ek = x∗ − xk , then
0 = f (x∗) = f (xk) + f ′(xk)(ek) +12f ′′(θ)(ek)2.
so [f ′(xk)
]−1f (xk) = −(ek)− 1
2
[f ′(xk)
]−1f ′′(θ)(ek)2.
From the Newton’s scheme, we havexk+1 = xk −[f ′(xk)
]−1f (xk)
x∗ = x∗
So,
ek+1 = ek +[f ′(xk)
]−1f (xk) = −1
2
[f ′(xk)
]−1f ′′(θ)(ek)2,
i.e.
ek+1 = −f ′′(θ)
2[f ′(xk)
] (ek)2,
By assumption, there is a neighborhood of x, such that∣∣∣f (z)∣∣∣ ≤ C1,∣∣∣f ′(z)∣∣∣ ≤ C2,
Therefore, ∣∣∣ek+1∣∣∣ ≤ ∣∣∣f ′′(θ)∣∣∣∣∣∣∣2 [
f ′(xk)]∣∣∣∣ (ek)2 ≤ C1
2C2
∣∣∣ek ∣∣∣2 .
This implies ∣∣∣xk+1 − x∗∣∣∣ ≤ C ∣∣∣xk − x∗∣∣∣2 .
Page 71 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 72
5.5 Newton’s method for system
Theorem 5.2. If F : R→Rn is integrable over the interval [a,b], then∥∥∥∥∥∥∫ b
aF(t)dt
∥∥∥∥∥∥ ≤∫ b
a‖F(t)‖dt.
Theorem 5.3. Suppose F : Rn→Rm is continuously differentiable and a,b ∈ Rn. Then
F(b) = F(a) +
∫ 1
0J(a+θ(b − a))(b − a)dθ,
where J is the Jacobian of F.
Theorem 5.4. Suppose J : Rm → Rn×n is a continuous matrix-valued function. If J(x*) is nonsingular,then there exists δ > 0 such that, for all x ∈ Rm with ‖x − x∗‖ < δ, J(x) is nonsingular and∥∥∥J(x)−1
∥∥∥ < 2∥∥∥J(x∗)−1
∥∥∥ .
Theorem 5.5. Suppose J : Rn→Rm. Then F is said to be Lipschitz continuous on S ⊂Rn if there exists apositive constant L such that ∥∥∥J(x)− J(y)∥∥∥ ≤ L∥∥∥x − y∥∥∥Theorem 5.6. (convergence of Newton’s method) Suppose F : Rn→Rn is continuously differentiable andF(x∗) = 0.
1. the Jacobian J(x∗) of F at x∗ is nonsingular, and
2. J is Lipschitz continuous on a neighborhood of x∗,
then, for all x0 sufficiently close to x∗,∣∣∣x0 − x∗
∣∣∣ < ε, Newton’s method converges quadratically to x∗, i.e∣∣∣xk+1 − xk∣∣∣ ≤ C ∣∣∣xk − x
∣∣∣2 .
Proof. Let x∗ be the root of F(x) i.e. F(x∗)=0. From the Newton’s scheme, we havexk+1 = xk −[J(xk)
]−1F(xk)
x∗ = x∗
Therefore, we have
x∗ − xk+1 = x∗ − xk +[J(xk)
]−1(F(xk)−F(x∗))
= x∗ − xk +[J(xk)
]−1 (F(xk)−F(x∗)+J(x∗)(x∗ − xk)− J(x∗)(x∗ − xk)
)=
(I −
[J(xk)
]−1J(x∗)
)(x∗ − xk
)−[J(xk)
]−1 (F(xk)−F(x∗) + J(x∗)(x∗ − xk)
).
So, ∥∥∥x∗ − xk+1∥∥∥ ≤ ∥∥∥∥I − [J(xk)
]−1J(x∗)
∥∥∥∥∥∥∥x∗ − xk∥∥∥+ ∥∥∥∥[J(xk)
]−1∥∥∥∥∥∥∥F(xk)−F(x∗) + J(x∗)(x∗ − xk)∥∥∥ . (119)
Page 72 of 236
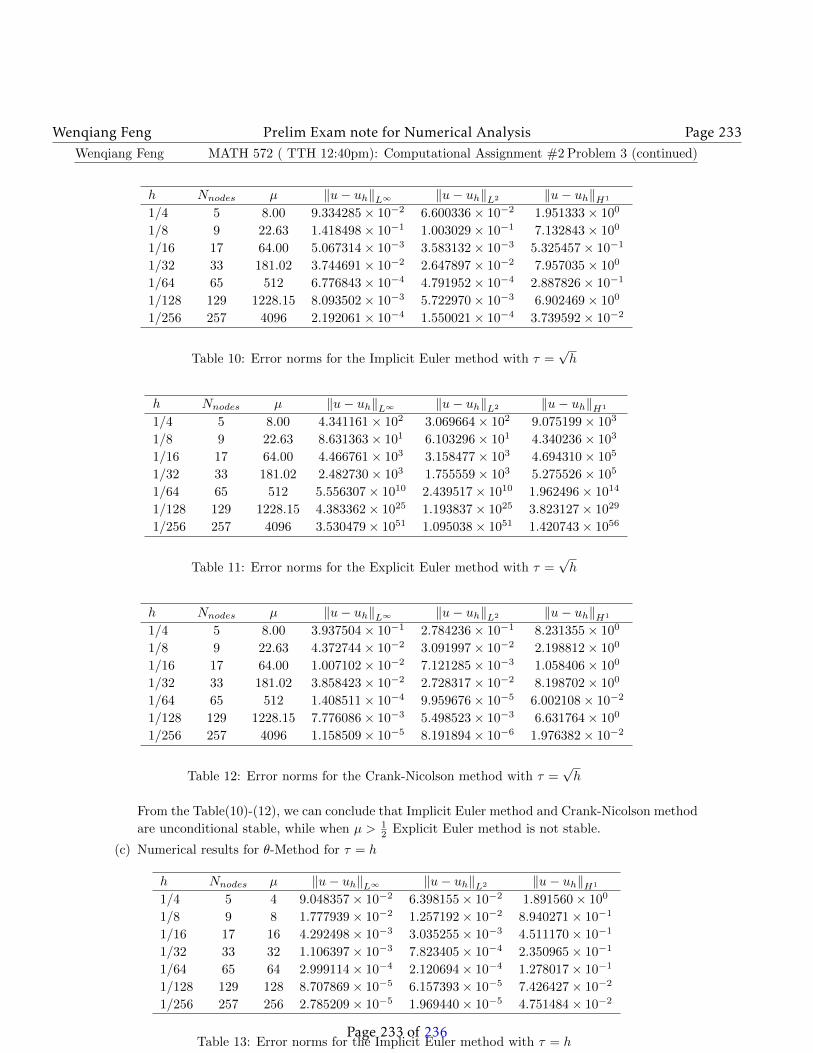
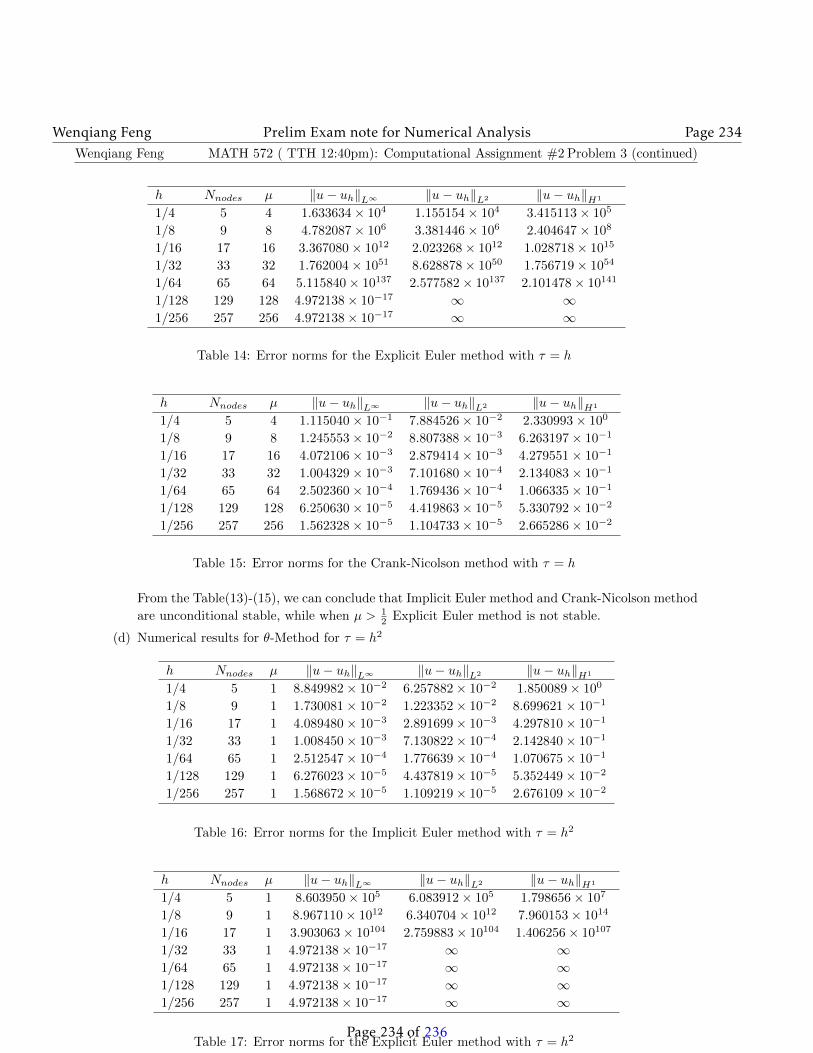
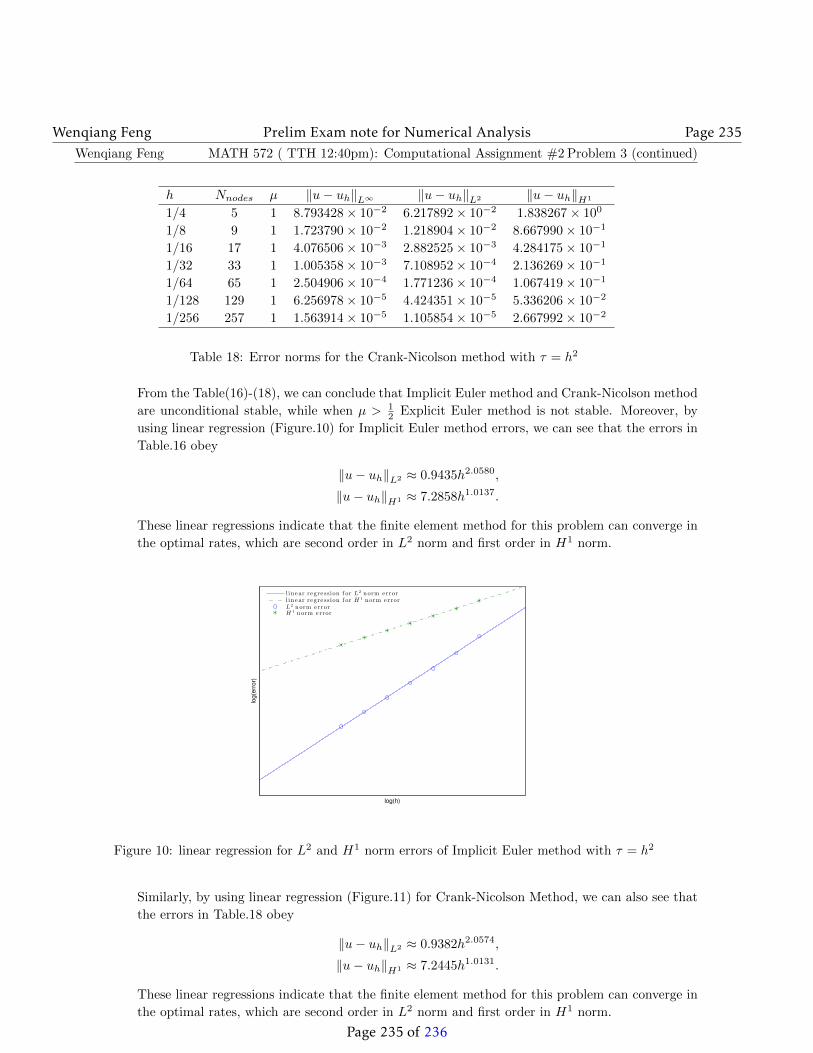
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 73
Now, we will estimate∥∥∥∥I − [J(xk)
]−1J(x∗)
∥∥∥∥ and∥∥∥F(xk)−F(x∗) + J(x∗)(x∗ − xk)
∥∥∥.∥∥∥∥I − [J(xk)]−1J(x∗)
∥∥∥∥ =∥∥∥∥[J(xk)
]−1[J(xk)
]−[J(xk)
]−1J(x∗)
∥∥∥∥=
∥∥∥∥[J(xk)]−1 (
J(xk)− J(x∗))∥∥∥∥ (120)
≤∥∥∥∥[J(xk)
]−1∥∥∥∥∥∥∥J(xk)− J(x∗)∥∥∥
≤ L∥∥∥∥[J(xk)
]−1∥∥∥∥∥∥∥x∗ − xk∥∥∥ .
In the last step of the above equation, we use the J is Lipschitz continuous(If J is not Lipschitz contin-uous, we can only get the Newton method converges linearly to x∗). Since F : Rn → Rn is continuouslydifferentiable, therefore
From (119), (120) and (121), we have∥∥∥x∗ − xk+1∥∥∥ ≤ 3
2L∥∥∥∥[J(xk)
]−1∥∥∥∥∥∥∥x∗ − xk∥∥∥2 ≤ 3L
∥∥∥[J(x∗)]−1∥∥∥∥∥∥x∗ − xk
∥∥∥2. (122)
Page 73 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 74
Remark 5.2. From the last step of the above proof process, we can get the condition of ε. such as, If∥∥∥x∗ − xk∥∥∥ ≤ 1
L∥∥∥[J(x∗)]−1
∥∥∥ ,
then ∥∥∥x∗ − xk+1∥∥∥ ≤ 1
2
∥∥∥x∗ − xk∥∥∥ . (123)
5.6 Fixed point method
In fact, Chord, scant and Newton’s method can be consider as fixed point iterative, since
xk+1 = xk −[ηk
]−1f (xk) = φ(xk).
Theorem 5.7. x is a fixed point of φ and Uδ = z : |x − z| ≤ δ. If φ is differentiable on Uδ and q < 1 such∣∣∣φ′(z)∣∣∣ ≤ q < 1 for all z ∈Uδ, then
1. φ(Uδ) ⊂Uδ2. φ is contraction.
5.7 Problems
Problem 5.1. (Prelim Jan. 2011#4) Let f : Ω ⊂ Rn → Rn be twice continuously differentiable. Supposex∗ ∈Ω is a solution of f (x) = 0, and the Jacobian matrix of f, denoted Jf , is invertible at x∗.
1. Prove that if x0 ∈Ω is sufficiently close to x∗, then the following iteration converges to x∗:
xk+1 = xk − Jf (x0)−1f (xk).
2. Prove that the convergence is typically only linear.
Solution. Let x∗ be the root of f(x) i.e. f(x∗)=0. From the Newton’s scheme, we havexk+1 = xk −[J(x0)
]−1f(xk)
x∗ = x∗
Therefore, we have
x∗ − xk+1 = x∗ − xk +[J(x0)
]−1(f(xk)− f(x∗))
= x∗ − xk −[J(x0)
]−1J(ξ)(x∗ − xk).
therefore ∣∣∣x∗ − xk+1∣∣∣ ≤ ∣∣∣∣∣1− J(ξ)
J(x0)
∣∣∣∣∣ ∣∣∣x∗ − xk∣∣∣
From theorem
Page 74 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 75
Theorem 5.8. Suppose J : Rm → Rn×n is a continuous matrix-valued function. If J(x*) is nonsingular, thenthere exists δ > 0 such that, for all x ∈ Rm with ‖x − x∗‖ < δ, J(x) is nonsingular and∥∥∥J(x)−1
∥∥∥ < 2∥∥∥J(x∗)−1
∥∥∥ .
we get ∣∣∣x∗ − xk+1∣∣∣ ≤ 1
2
∣∣∣x∗ − xk∣∣∣ .
Which also shows the convergence is typically only linear.J
Problem 5.2. (Prelim Aug. 2010#5) Assume that f : R → R,f ∈ C2(R),f ′(x) > 0 for all x ∈ R, andf ′′(x) > 0, for all x ∈R.
1. Suppose that a root ξ ∈ R exists. Prove that it is unique. Exhibit a function satisfying the assump-tions above that has no root.
2. Prove that for any starting guess x0 ∈ R, Newton’s method converges, and the convergence rate isquadratic.
Solution. 1. Let x1 and x2 are the two different roots. So, f (x1) = f (x2) = 0, then by Mean valuetheorem, we have that there exists η ∈ [x1,x2], such f ′(η) = 0 which contradicts f ′(x) > 0.
2. example f (x) = ex.
3. Let x∗ be the root of f (x). From the Taylor expansion, we know
0 = f (x∗) = f (xk) + f ′(xk)(x∗ − xk) + 12f ′′(θ)(x∗ − xk)2,
where θ is between x∗ and xk . Define ek = x∗ − xk , then
0 = f (x∗) = f (xk) + f ′(xk)(ek) +12f ′′(θ)(ek)2.
so [f ′(xk)
]−1f (xk) = −(ek)− 1
2
[f ′(xk)
]−1f ′′(θ)(ek)2.
From the Newton’s scheme, we havexk+1 = xk −[f ′(xk)
]−1f (xk)
x∗ = x∗
So,
ek+1 = ek +[f ′(xk)
]−1f (xk) = −1
2
[f ′(xk)
]−1f ′′(θ)(ek)2,
i.e.
ek+1 = −f ′′(θ)
2[f ′(xk)
] (ek)2,
By assumption, there is a neighborhood of x, such that∣∣∣f (z)∣∣∣ ≤ C1,∣∣∣f ′(z)∣∣∣ ≤ C2,
Page 75 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 76
Therefore,
∣∣∣ek+1∣∣∣ ≤ ∣∣∣f ′′(θ)∣∣∣∣∣∣∣2 [
f ′(xk)]∣∣∣∣ (ek)2 ≤ C1
2C2
∣∣∣ek ∣∣∣2 .
This implies ∣∣∣xk+1 − x∗∣∣∣ ≤ C ∣∣∣xk − x∗∣∣∣2 .
J
Problem 5.3. (Prelim Aug. 2010#4) Let f : Rn → R be twice continuously differentiable. Suppose x∗ isa isolated root of f and the Jacobian of f at x∗(J(x∗)) is non-singular. Determine conditions on ε so that if‖x0 − x∗‖2 < ε then the following iteration converges to x∗:
xk+1 = xk − Jf (x0)−1f (xk), k = 0,1,2, · · · .
Solution. J
Problem 5.4. (Prelim Aug. 2009#5) Consider the two-step Newton method
yk = xk −f (xk)
f ′(xk),xk+1 = yk −
f (yk)
f ′(xk)
for the solution of the equation f (x) = 0. Prove
1. If the method converges, then
limk→∞
xk+1 − x∗
(yk − x∗)(xk − x∗)=f ′′(xk)
f ′(xk),
where x∗ is the solution.
2. Prove the convergence is cubic, that is
limk→∞
xk+1 − x∗
(xk − x∗)3 =12
(f ′′(xk)
f ′(xk)
).
3. Would you say that this method is faster than Newton’s method given that its convergence is cubic?
Solution. 1. First, we will show that if xk ∈ [x − h,x+ h], then yk ∈ [x − h,x+ h]. By Taylor expansionformula, we have
0 = f (x∗) = f (xk) + f′(xk)(x
∗ − xk) +12!f ′′(ξk)(x
∗ − xk)2,
where ξ is between x and xk . Therefore, we have
f (xk) = −f ′(xk)(x∗ − xk)−12!f ′′(ξk)(x
∗ − xk)2.
Plugging the above equation to the first step of the Newton’s method, we have
yk = xk + (x∗ − xk) +12!f ′′(ξk)
f ′(xk)(x∗ − xk)2.
Page 76 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 77
then
yk − x∗ =12!f ′′(ξk)
f ′(xk)(x∗ − xk)2. (124)
Therefore, ∣∣∣yk − x∗∣∣∣= ∣∣∣∣∣ 12!f ′′(ξk)
f ′(xk)(x∗ − xk)2
∣∣∣∣∣ ≤ 12
∣∣∣∣∣ f ′′(ξk)f ′(xk)
∣∣∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ .Since we can choose the initial value very close to x∗, shah that∣∣∣∣∣ f ′′(ξ)f ′(xk)
∣∣∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ ≤ 1
Then, we have that ∣∣∣yk − x∗∣∣∣ ≤ 12
∣∣∣(x∗ − xk)∣∣∣ .Hence, we proved the result, that is to say, if xk → x∗, then yk ,ξk → x∗.
2. Next, we will show if xk ∈ [x−h,x+h], then xk+1 ∈ [x−h,x+h]. From the second step of the Newton’sMethod, we have that
xk+1 − x∗ = yk − x∗ −f (yk)
f ′(xk)
=1
f ′(xk)((yk − x∗)f ′(xk)− f (yk))
=1
f ′(xk)[(yk − x∗)(f ′(xk)− f ′(x∗))− f (yk) + (yk − x∗)f ′(x∗)]
By mean value theorem, we have there exists ηk between x∗ and xk , such that
f ′(xk)− f ′(x∗) = f ′′ηk(xk − x∗),
and by Taylor expansion formula, we have
f (yk) = f (x∗) + f ′(x∗)(yk − x∗) +(yk − x∗)2
2f ′′(γk)
= f ′(x∗)(yk − x∗) +(yk − x∗)2
2f ′′(γk),
where γ is between yk and x∗. Plugging the above two equations to the second step of the Newton’smethod, we get
xk+1 − x∗ =1
f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)− f ′(x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk) + (yk − x∗)f ′(x∗)
]=
1f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk)
]. (125)
Taking absolute values of the above equation, then we have∣∣∣xk+1 − x∗∣∣∣ =
∣∣∣∣∣∣ 1f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk)
]∣∣∣∣∣∣≤ A |xk − x∗|
∣∣∣yk − x∗∣∣∣+ A2
∣∣∣yk − x∗∣∣∣ ∣∣∣yk − x∗∣∣∣≤ 1
2|xk − x∗|+
18|xk − x∗|=
58|xk − x∗| .
Hence, we proved the result, that is to say, if yk → x∗, then xk+1,ηk ,γk → x∗.
Page 77 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 78
3. Finally, we will prove the convergence order is cubic. From (215), we can get that
xk+1 − x∗
(xk − x∗)(yk − x∗)=
f ′′ηkf ′(xk)
−(yk − x∗)f ′′(γk)2(xk − x∗)f ′(xk)
.
By using (214), we have
xk+1 − x∗
(xk − x∗)(yk − x∗)=
f ′′ηkf ′(xk)
− 14f ′′(ξk)
f ′(xk)(x∗ − xk)
f ′′(γk)
f ′(xk).
Taking limits gives
limk→∞
xk+1 − x∗
(xk − x∗)(yk − x∗)=f ′′(x∗)
f ′(x∗).
By using (214) again, we have
1yk − x∗
=2
(x∗ − xk)2f ′(xk)
f ′′(ξk).
Hence
limk→∞
xk+1 − x∗
(xk − x∗)3 =12
(f ′′(x∗)
f ′(x∗)
)2
.
J
Page 78 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 79
6 Euler Method
In this section, we focus on y′ = f (t,y),y(t0) = y0.
Where f is Lipschitz continuous w.r.t. the second variable, i.e
|f (t,x)− f (t,y)| ≤ λ|x − y|, λ > 0. (126)
In the following, We will let y(tn) to be the numerical approximation of yn and en = yn − y(tn) to be theerror.
Definition 6.1. (Order of the Method) A time stepping scheme
yn+1 = Φ(h,y0,y1, · · · ,yn) (127)
is of order of p ≥ 1 , if
yn+1 −Φ(h,y0,y1, · · · ,yn) = O(hp+1). (128)
Definition 6.2. (Convergence of the Method) A time stepping scheme
yn+1 = Φ(h,y0,y1, · · · ,yn) (129)
is convergent , if
limh→0
maxn
∥∥∥y(tn)− yn∥∥∥= 0. (130)
6.1 Euler’s method
Definition 6.3. (Forward Euler Methoda)
yn+1 = yn+ hf (tn,yn), n= 0,1,2, · · · . (131)
aForward Euler Method is explicit.
Theorem 6.1. (Forward Euler Method is of order 1 a) Forward Euler Method
y(tn+1) = y(tn) + hf (tn,y(tn)), (132)
is of order 1 .
aYou can also use multi-step theorem to derive it.
Theorem 7.2. (s-step method convergent order) The multistep method (187) is of order p ≥ 1 if and onlyif
1.∑sm=0 am = 0, (i.e.ρ(1) = 0),
2.∑sm=0m
kam = k∑sm=0m
k−1bm,k = 1,2, · · · ,p,
3.∑sm=0m
p+1am , (p+ 1)∑sm=0m
pbm.
Where,
ρ(w) :=s∑
m=0
amwm and σ (w) :=
s∑m=0
bmwm. (190)
Lemma 7.1. (Root Condition) If the roots |λi | ≤ 1 for each i = 1, · · · ,m and all roots with value 1 aresimple root then the difference method is said to satisfy the root condition.
Theorem 7.3. (The Dahlquist equivalence theorem) The multistep method (187) is convergent if and onlyif
1. consistency: multistep method (187)is order of p ≥ 1 ,
2. stability: the polynomial ρ(w) satisfies the root condition .
7.3 Method of A-stable verification for Multistep Methods
Theorem 7.4. Explicit Multistep Methods can not be A-stable.
Theorem 7.5. (Dahlquist second barrier) The highest oder of an A-stable multistep method is 2 .
7.4 Problems
Problem 7.1. Find the order of the following quadrature formula.∫ 1
0f (τ)dτ =
16f (0) +
23f (
12) +
16f (1), Simpson Rule.
Solution. Since the quadrature formula (209) is order of p if it is exact for every f ∈ Pp−1. we can chose
Page 89 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 90
the simplest basis (1,τ ,τ2,τ3, · · · ,τp−1), and the order conditions read that
p∑j=1
bjcmj =
∫ b
aτmw(τ)dτ , m= 0,1, · · · ,p − 1. (191)
Checking the order condition by the following procedure,
1 =
∫ 1
01dτ =
16
1+23
1+16
1 = 1.
12=
∫ 1
0τdτ =
16
0+23
(12
)+
16
1 =12
.
13=
∫ 1
0τ2dτ =
16
02 +23
(12
)2+
16
12 =13
.
14=
∫ 1
0τ3dτ =
16
03 +23
(12
)3+
16
13 =14
.
15=
∫ 1
0τ4dτ ,
16
04 +23
(12
)4+
16
14 =5
24.
we can get the order of the Simpson rule quadrature formula is 4. J
Problem 7.2. Recall Simpson’s quadrature rule:∫ b
af (τ)dτ =
b − a6
[f (a) + 4f (
a+ b2
) + f (b)
]+O(|b − a|4), Simpson Rule.
Starting from the identity
y(tn+1)− y(tn−1) =
∫ tn+1
tn−1
f (s;y(s))ds. (192)
use Simpson’s rule to derive a 3-step method. Determine its order and whether it is convergent.
Solution. 1. The derivation of the a 3-step methodsince,
And ak < 0,ck < 0,uk−1 −uk ≤ 0,uk+1 −uk ≤ 0, so uk−1 = uk = uk+1, that is to say, uk−1 and uk+1 is alsothe maximum points. Bu using the same argument again, we get uk−2 = uk−1 = uk = uk+1 = uk+2.Repeating the process, we get
u1 = u2 = · · ·= un−1 = un.
Therefore, If u ∈Rn is such that (Au)i=2,··· ,n−1 = 0, then ui ≤maxu1,un
Theorem 9.2. (Discrete Poincaré inequality) Let Ω= (0,1) and Ωh be a uniform grid of size h. If Y ∈ Uhis a mesh function on Ωh such that Y (0) = 0, then there is a constant C, independent of Y and h, for which
‖Y ‖2,h ≤ C∥∥∥δY ∥∥∥
2,h.
Page 97 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 98
Proof. I consider the following uniform partition (Figure. A1) of the interval (0,1) with N points.
x1 = 0 x2 xN−1 xN = 1
Figure 3: One dimension’s uniform partition
Since the discrete 2-norm is defined as follows
‖v‖22,h = hdN∑i=1
|vi |2,
where d is dimension. So, we have
‖v‖22,h = hN∑i=1
|vi |2,∥∥∥δv∥∥∥2
2,h= h
N∑i=2
∣∣∣∣vi−1 − vih
∣∣∣∣2 .
Since Y (0) = 0, i.e. Y1 = 0,
N∑i=2
(Yi−1 −Yi) = Y1 −YN = −YN .
Then, ∣∣∣∣∣∣∣N∑i=2
(Yi−1 −Yi)
∣∣∣∣∣∣∣= |YN |.and
|YN | ≤N∑i=2
|Yi−1 −Yi |=N∑i=2
h
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣ ≤ N∑i=2
h2
1/2 N∑
i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2
1/2
.
Therefore
|YK |2 ≤
K∑i=2
h2
K∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2
= h2(K − 1)K∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
1. When K = 2,
|Y2|2 ≤ h2∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 .
2. When K = 3,
|Y3|2 ≤ 2h2(∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 + ∣∣∣∣∣Y2 −Y3
h
∣∣∣∣∣2) .
Page 98 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 99
3. When K = N ,
|YN |2 ≤ (N − 1)h2(∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 + ∣∣∣∣∣Y2 −Y3
h
∣∣∣∣∣2 + · · ·+ ∣∣∣∣∣YN−1 −YNh
∣∣∣∣∣2) .
Sum over |Yi |2 from 2 to N, we get
N∑i=2
|Yi |2 ≤N (N − 1)
2h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
Since Y1 = 0, so
N∑i=1
|Yi |2 ≤N (N − 1)
2h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
And then
1(N − 1)2
N∑i=1
|Yi |2 ≤N
2(N − 1)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2 = (12+
12(N − 1)
)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
Since h= 1N−1 , so
h2N∑i=1
|Yi |2 ≤(
12+
12(N − 1)
)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
then
hN∑i=1
|Yi |2 ≤(
12+
12(N − 1)
)hN∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
i.e,
‖Y ‖22,h ≤(
12+
12(N − 1)
)∥∥∥δY ∥∥∥22,h
.
since N ≥ 2, so
‖Y ‖22,h ≤∥∥∥δY ∥∥∥2
2,h.
Hence,
‖Y ‖2,h ≤ C∥∥∥δY ∥∥∥
2,h.
Theorem 9.3. (Von Neumann stability analysis method) For the difference scheme
Un+1j =
∑p∈N
αpUnj−p,
we have the corresponding Fourier transform is as follows
Un+1(ξ) =∑p∈N
αpe−ipξUn(ξ) := G(λ,ξ)Un(ξ).
Where λ = τh2 is CFL number and G(λ,ξ) is called Growth factor . If
∣∣∣G(λ,ξ)∣∣∣ ≤ 1, then the difference
scheme is stable.
Page 99 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 100
9.1 Problems
Problem 9.1. (Prelim Jan. 2011#7) Consider the Crank-Nicholson scheme applied to the diffusion equation
∂u∂t
=∂2u
∂x2
where t > 0,−∞ < x <∞.
1. Show that the amplification factor in the Von Neumann analysis of the scheme us
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
2. Use the results of part 1 to show that the scheme is stable.
Solution. 1. The Crank-Nicholson scheme for the diffusion equation is
un+1j −unj∆t
=12
un+1j−1 − 2un+1
j + un+1j+1
∆x2 +unj−1 − 2unj + u
nj+1
∆x2
Let µ= ∆t
∆x2 , then the scheme can be rewrote as
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
),
i.e.
−µ
2un+1j−1 + (1+ µ)un+1
j −µ
2un+1j+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
By using the Fourier transform, i.e.
un+1j = g(ξ)unj , unj = eij∆xξ ,
then we have
−µ
2g(ξ)unj−1 + (1+ µ)g(ξ)unj −
µ
2g(ξ)unj+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
And then
−µ
2g(ξ)ei(j−1)∆xξ + (1+ µ)g(ξ)eij∆xξ −
µ
2g(ξ)ei(j+1)∆xξ =
µ
2ei(j−1)∆xξ + (1−µ)eij∆xξ +
µ
2ei(j+1)∆xξ ,
i.e.
g(ξ)(−µ
2e−i∆xξ + (1+ µ)−
µ
2ei∆xξ
)ej∆xξ =
(µ2e−i∆xξ + (1−µ) +
µ
2ei∆xξ
)ej∆xξ ,
i.e.
g(ξ) (1+ µ−µcos(∆xξ)) = 1−µ+ µcos(∆xξ).
therefore,
g(ξ) =1−µ+ µcos(∆xξ)1+ µ−µcos(∆xξ)
.
hence
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
Page 100 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 101
2. since z = 2 ∆t∆x2 (cos(∆xξ)− 1), then z < 0, then we have
1+12z < 1− 1
2z,
therefore g(ξ) < 1. Since −1 < 1, then
12z − 1 <
12z+ 1.
Therefore,
g(ξ) =1+ 1
2z
1− 12z
> −1.
hence∣∣∣g(ξ)∣∣∣ < 1. So, the scheme is stable.
J
Problem 9.2. (Prelim Jan. 2011#8) Consider the explicit scheme
un+1j = unj + µ
(unj−1 − 2unj + u
nj+1
)−bµ∆x
2
(unj+1 −u
nj−1
),0 ≤ n ≤N ,1 ≤ j ≤ L.
for the convention-diffusion problem∂u∂t =
∂2u∂x2 − b ∂u∂x for 0 ≤ x ≤ 1, 0 ≤ t ≤ t∗
u(0, t) = u(1, t) = 0 for 0 ≤ t ≤ t∗
u(x,0) = g(x) for 0 ≤ x ≤ 1,
where b > 0, µ = ∆t(∆x)2 ,∆x = 1
L+1 , and ∆t = t∗N . Prove that, under suitable restrictions on µ and ∆x, the
error grid function en satisfy the estimate
‖en‖∞ ≤ t∗C(∆t+∆x2
),
for all n such that n∆t ≤ t∗, where C > 0 is a constant.
Solution. Let u be the exact solution and unj = u(n∆t, j∆x). Then from Taylor Expansion, we have
un+1j = unj +∆t
∂∂tunj +
12(∆t)2 ∂
2
∂t2u(ξ1, j∆x), tn ≤ ξ1 ≤ tn+1,
unj−1 = unj −∆x∂∂xunj −
16(∆x)3 ∂
3
∂x3 unj +
124
(∆x)4 ∂4
∂x4 u(n∆t,ξ2), xj−1 ≤ ξ2 ≤ xj ,
unj+1 = unj +∆x∂∂xunj +
16(∆x)3 ∂
3
∂x3 unj +
124
(∆x)4 ∂4
∂x4 u(n∆t,ξ3), xj ≤ ξ3 ≤ xj+1.
Then the truncation error T of this scheme is
T =un+1j − unj∆t
−unj−1 − 2unj + u
nj+1
∆x2 + bunj+1 − u
nj−1
∆x= O(∆t+ (∆x)2).
Therefore
en+1j = enj + µ
(enj−1 − 2enj + e
nj+1
)−bµ∆x
2
(enj+1 − e
nj−1
)+ c∆t(∆t+ (∆x)2),
Page 101 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 102
i.e.
en+1j =
(µ+
bµ∆x
2
)enj−1 + (1− 2µ)enj +
(µ−
bµ∆x
2
)enj+1 + c∆t(∆t+ (∆x)2).
Then ∣∣∣∣en+1j
∣∣∣∣ ≤ ∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣ ∣∣∣∣enj−1
∣∣∣∣+ ∣∣∣(1− 2µ)∣∣∣ ∣∣∣∣enj ∣∣∣∣+ ∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣ ∣∣∣∣enj+1
∣∣∣∣+ c∆t(∆t+ (∆x)2).
Therefore∥∥∥∥en+1j
∥∥∥∥∞ ≤∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣∥∥∥∥enj−1
∥∥∥∥∞+∣∣∣(1− 2µ)
∣∣∣∥∥∥∥enj ∥∥∥∥∞+
∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣∥∥∥∥enj+1
∥∥∥∥∞+ c∆t(∆t+ (∆x)2).
∥∥∥en+1∥∥∥∞ ≤ ∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣‖en‖∞+∣∣∣(1− 2µ)
∣∣∣‖en‖∞+
∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣‖en‖∞+ c∆t(∆t+ (∆x)2).
If 1− 2µ ≥ 0 and µ− bµ∆x2 ≥ 0, i.e. µ ≤ 12 and 1− 1
2b∆x > 0, then∥∥∥en+1∥∥∥∞ ≤
(µ+
bµ∆x
2
)‖en‖∞+ ((1− 2µ))‖en‖∞+
(µ−
bµ∆x
2
)‖en‖∞+ c∆t(∆t+ (∆x)2)
= ‖en‖∞+ c∆t(∆t+ (∆x)2).
Then
‖en‖∞ ≤∥∥∥en−1
∥∥∥∞+ c∆t(∆t+ (∆x)2)
≤∥∥∥en−2
∥∥∥∞+ c2∆t(∆t+ (∆x)2)
≤...
≤∥∥∥e0
∥∥∥∞+ cn∆t(∆t+ (∆x)2)
= ct∗(∆t+ (∆x)2).
J
Problem 9.3. (Prelim Aug. 2010#8) Consider the Crank-Nicolson scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)for approximating the solution to the heat equation ∂u
∂t =∂2u∂x2 on the intervals 0 ≤ x ≤ 1 and 0 ≤ t ≤ t∗ with
the boundary conditions u(0, t) = u(1, t) = 0.
1. Show that the scheme may be written in the form un+1 = Aun, where A ∈Rm×msym (the space of m×m
symmetric matrices) and
‖Ax‖2 ≤ ‖x‖2 ,
for any x ∈Rm, regardless of the value of µ.
2. Show that
‖Ax‖∞ ≤ ‖x‖∞ ,
for any x ∈ Rm, provided µ ≤ 1.(In other words, the scheme may only be conditionally stable in themax norm.)
Page 102 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 103
Solution. 1. the scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)can be rewritten as
−µ
2un+1j−1 + (1+ µ)un+1
j −µ
2un+1j+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
By using the boundary, we have
Cun+1 = Bun
where
C =
1+ µ −µ2−µ2 1+ µ −µ2
. . .. . .
. . .−µ2 1+ µ −µ2
−µ2 1+ µ
,B=
1−µ µ2µ
2 1−µ µ2
. . .. . .
. . .µ2 1−µ µ
2µ2 1−µ
,
un+1 =
un+1
1un+1
2...
un+1m
and un =
un1un2...unm
.
So, the scheme may be written in the form un+1 = Aun, where A = C−1B. By using the Fouriertransform, i.e.
un+1j = g(ξ)unj , unj = eij∆xξ ,
then we have
−µ
2g(ξ)unj−1 + (1+ µ)g(ξ)unj −
µ
2g(ξ)unj+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
And then
−µ
2g(ξ)ei(j−1)∆xξ + (1+ µ)g(ξ)eij∆xξ −
µ
2g(ξ)ei(j+1)∆xξ =
µ
2ei(j−1)∆xξ + (1−µ)eij∆xξ +
µ
2ei(j+1)∆xξ ,
i.e.
g(ξ)(−µ
2e−i∆xξ + (1+ µ)−
µ
2ei∆xξ
)ej∆xξ =
(µ2e−i∆xξ + (1−µ) +
µ
2ei∆xξ
)ej∆xξ ,
i.e.
g(ξ) (1+ µ−µcos(∆xξ)) = 1−µ+ µcos(∆xξ).
therefore,
g(ξ) =1−µ+ µcos(∆xξ)1+ µ−µcos(∆xξ)
.
hence
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
Moreover,∣∣∣g(ξ)∣∣∣ < 1, therefore, ρ(A) < 1.
‖Ax‖2 ≤ ‖A‖2 ‖x‖2 = ρ(A)‖x‖2 ≤ ‖x‖2 .
Page 103 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 104
then we get µ < 1. The above process is invertible, therefore, we prove the result. J
Problem 9.5. (Prelim Aug. 2010#9)
Solution. J
Page 105 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 106
10 Finite Element Method
Theorem 10.1. (1D Dirichlet-Poincaré inequality) Let a > 0, u ∈ C1([−a,a]) and u(−a) = 0, then the1D Dirichlet-Poincaré inequality is defined as follows∫ a
−a
∣∣∣u(x)∣∣∣2 dx ≤ 4a2∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Proof. Since u(−a) = 0, then by calculus fact, we have
u(x) = u(x)−u(−a) =∫ x
−au′(ξ)dξ.
Therefore ∣∣∣u(x)∣∣∣ ≤ ∣∣∣∣∣∫ x
−au′(ξ)dξ
∣∣∣∣∣≤
∫ x
−a
∣∣∣u′(ξ)∣∣∣dξ≤
∫ a
−a
∣∣∣u′(ξ)∣∣∣dξ (x ≤ a)
≤(∫ a
−a12dξ
)1/2 (∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
(Cauchy-Schwarz inequality)
= (2a)1/2(∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
.
Therefore ∣∣∣u(x)∣∣∣2 ≤ 2a∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ.
Integration on both sides of the above equation from −a to a w.r.t. x yields∫ a
−a
∣∣∣u(x)∣∣∣2 dx ≤∫ a
−a2a
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξdx=
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ∫ a
−a2adx
= 4a2∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ= 4a2
∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Theorem 10.2. (1D Neumann-Poincaré inequality) Let a > 0, u ∈ C1([−a,a]) and u => a−au(x)dx, then
the 1D Neumann-Poincaré inequality is defined as follows∫ a
−a
∣∣∣u(x)− u(x)∣∣∣2 dx ≤ 2a(a− c)∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Page 106 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 107
Proof. Since, u => a−au(x)dx, then by intermediate value theorem, there exists a c ∈ [−a,a], s.t.
u(c) = u(x).
then by calculus fact, we have
u(x)− u(x) = u(x)−u(c) =∫ x
cu′(ξ)dξ.
Therefore ∣∣∣u(x)− u(x)∣∣∣ ≤ ∣∣∣∣∣∫ x
cu′(ξ)dξ
∣∣∣∣∣≤
∫ x
c
∣∣∣u′(ξ)∣∣∣dξ≤
∫ a
c
∣∣∣u′(ξ)∣∣∣dξ (x ≤ a)
≤(∫ a
c12dξ
)1/2 (∫ a
c
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
(Cauchy-Schwarz inequality)
= (a− c)1/2(∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ)1/2
.
Therefore ∣∣∣u(x)− u(x)∣∣∣2 ≤ (a− c)∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ.
Integration on both sides of the above equation from −a to a w.r.t. x yields∫ a
−a
∣∣∣u(x)− u(x)∣∣∣2 dx ≤∫ a
−a(a− c)
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξdx=
∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ∫ a
−a(a− c)dx
= 2a(a− c)∫ a
−a
∣∣∣u′(ξ)∣∣∣2 dξ= 2a(a− c)
∫ a
−a
∣∣∣u′(x)∣∣∣2 dx.
Definition 10.1. (symmetric, continuous and coercive) We consider the bilinear form a : H ×H →R ona normed space H.
1. a(·, ·) is said to be symmetric provided that
a(u,v) = a(v,u), ∀u,v ∈H .
2. a(·, ·) is said to continuous or bounded , if there exists a constant C s.t.∣∣∣a(u,v)∣∣∣= C ‖u‖‖v‖ , ∀u,v ∈H .
3. a(·, ·) is said to be coercive provided there exists a constant α s.t.∣∣∣a(u,u)∣∣∣ ≥ α ‖u‖2 , ∀u ∈H .
Page 107 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 108
Proof.
Theorem 10.3. (Lax-Milgram Theorem[1]) Given a Hilbert spaceH , a continuous, coercive bilinear forma(·, ·) and a continuous functional F ∈H ′ , there exists a unique u ∈H s.t.
a(u,v) = F(v), ∀v ∈H .
Theorem 10.4. (Céa Lemma[1]) Suppose V is subspace of H. a(·, ·) is continuous and coercive bilinearform on V. Given F ∈ V ′ , u ∈ V , s.t.
a(u,v) = F(v), ∀v ∈ V .
For the finite element variational problem
a(uh,v) = F(v), ∀v ∈ Vh,
we have
‖u −uh‖V ≤Cα
minv∈Vh‖u − v‖V ,
where C is the continuity constant and α is the coercivity constant of a(·, ·) on V.
Proof.
10.1 Finite element methods for 1D elliptic problems
Theorem 10.5. (Convergence of 1d FEM) The linear basis FEM solution uh for−u′′(x) = f (x), x ∈ I =x ∈ [a,b]
,
u(a) = u(b) = 0.
has the following properties
‖u −uh‖L2(I) ≤ Ch2∥∥∥u′′∥∥∥
L2(I),∥∥∥u′ −u′h∥∥∥L2(I)
≤ Ch∥∥∥u′′∥∥∥
L2(I).
Proof. 1. Define the first degree Taylor polynomial on Ii = [xi ,xi+1] as
Q1u(x) = u(xi) + u′(x)(x − xi).
Then we have ∣∣∣u(x)−Q1u(x)∣∣∣= ∫
I
∣∣∣x − y∣∣∣u′′(y)dy.
Page 108 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 109
2. For the linear basis we have the Element solution uh(xi) = u(xi) and uh(xi+1) = u(xi+1) on elementIi = [xi ,xi+1]. and
u′h(x) =uh(xi+1)−uh(xi)
h=u(xi+1)−u(xi)
h=
1h
∫ xi+1
xi
u′(y)dy =1h
∫Ii
u′(y)dy,
u′(x) = u′(x)hh=
1h
∫ xi+1
xi
u′(x)dy =1h
∫Ii
u′(x)dy.
Page 109 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 110
Therefore
u′h(x)−u′(x) =
1h
∫Ii
u′(y)−u′(x)dy
=1h
∫Ii
∫ y
xu′′(ξ)dξdy.
so ∥∥∥u′ −u′h∥∥∥2L2(Ii )
=
∫Ii
(u′h(x)−u
′(x))2dx
=1h2
∫Ii
(∫Ii
∫ y
xu′′(ξ)dξdy
)2
dx
≤ 1h2
∫Ii
(∫Ii
∫Ii
u′′(ξ)dξdy
)2
dx
=1h2
(∫Ii
∫Ii
u′′(ξ)dξdy
)2 ∫Ii
dx
=1h
(∫Ii
dy
∫Ii
u′′(ξ)dξ
)2
=1h
(h
∫Ii
u′′(ξ)dξ
)2
= h
(∫Ii
u′′(ξ)dξ
)2
≤ h
(∫Ii
12dξ
)1/2 (∫Ii
∣∣∣u′′(ξ)∣∣∣2 dξ)1/22
≤ h2(∫
Ii
∣∣∣u′′(ξ)∣∣∣2 dξ)
hence ∥∥∥u′ −u′h∥∥∥L2(Ii )≤ Ch
∥∥∥u′′∥∥∥L2(Ii )
.
Therefore, ∥∥∥u′ −u′h∥∥∥L2(I)≤ Ch
∥∥∥u′′∥∥∥L2(I)
.
Page 110 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 111
10.2 Problems
Problem 10.1. (Prelim Jan. 2008#8) Let Ω ⊂R2 be a bounded domain with a smooth boundary. Considera 2-D poisson-like equation −∆u+ 3u = x2y2, in Ω,
u = 0, on ∂Ω.
1. Write the corresponding Ritz and Galerkin variational problems.
2. Prove that the Galerkin method has a unique solution uh and the following estimate is valid
‖u −uh‖H1 ≤ C infvh∈Vh
‖u − vh‖H1 ,
with C independent of h, where Vh denotes a finite element subspace of H1(Ω) consisting of contin-uous piecewise polynomials of degree k ≥ 1.
Solution. 1. For this pure Dirichlet Problem, the test functional space v ∈ H10 . Multiple the test func-
tion on the both sides of the original function and integral on Ω, we get
−∫Ω
∆uvdx+
∫Ω
uvdx =
∫Ω
xyvdx.
Integration by part yields ∫Ω
∇u∇vdx+∫Ω
uvdx =
∫Ω
xyvdx.
Let
a(u,v) =∫Ω
∇u∇vdx+∫Ω
uvdx, f (v) =∫Ω
xyvdx.
Then, the
(a) Ritz variational problem is: find uh ∈H10 , such that
J(uh) = min12a(uh,uh)− f (uh).
(b) Galerkin variational problem is: find uh ∈H10 , such that
a(uh,uh) = f (uh).
2. Next, we will use Lax-Milgram to prove the uniqueness.
(a) ∣∣∣a(u,v)∣∣∣ ≤ ∫
Ω
|∇u∇v|dx+∫Ω
|uv|dx
≤ ‖∇u‖L2(Ω) ‖∇v‖L2(Ω) + ‖u‖L2(Ω) ‖v‖L2(Ω)
≤ ‖∇u‖L2(Ω) ‖∇v‖L2(Ω) +C ‖∇u‖L2(Ω) ‖∇v‖L2(Ω)
≤ C ‖∇u‖L2(Ω) ‖∇v‖L2(Ω)
≤ C ‖u‖H1(Ω) ‖v‖H1(Ω)
Page 111 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 112
(b)
a(u,u) =
∫Ω
(∇u)2dx+
∫Ω
u2dx
So, ∣∣∣a(u,u)∣∣∣ =
∫Ω
|∇u|2 dx+∫Ω
|u|2 dx
= ‖∇u‖2L2(Ω)+ ‖u‖2L2(Ω)
= ‖u‖2H1(Ω).
(c) ∣∣∣f (v)∣∣∣ ≤ ∫Ω
∣∣∣xyv∣∣∣dx≤ max |xy|
∫Ω
|v|dx
≤ C
(∫Ω
12dx
)1/2 (∫Ω
|v|2 dx)1/2
≤ C ‖v‖L2(Ω) ≤ C ‖v‖H1(Ω) .
by Lax-Milgram theorem, we get that e Galerkin method has a unique solution uh. Moreover,
a(vh,vh) = f (vh).
And from the weak formula, we have
a(u,vh) = f (vh).
then we get the Galerkin Orthogonal (GO)
a(u −uh,vh) = 0.
Then by coercivity
‖u −uh‖2H1(Ω)≤
∣∣∣a(u −uh,u −uh)∣∣∣
=∣∣∣a(u −uh,u − vh) + a(u −uh,vh −uh)
∣∣∣=
∣∣∣a(u −uh,u − vh)∣∣∣
≤ ‖u −uh‖H1(Ω) ‖u − vh‖H1(Ω) .
Therefore,
‖u −uh‖H1 ≤ C infvh∈Vh
‖u − vh‖H1 ,
J
Page 112 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 113
Problem 10.2. (Prelim Aug. 2006#9) Let Ω :=(x,y) : x2 + y2 < 1
, consider the poisson problem−∆u+ 2u = xy, in Ω,
u = 0, on ∂Ω.
1. Define the corresponding Ritz and Galerkin variational formulations.
2. Suppose that the Galerkin variational problem has solution, prove that the Ritz variation problemmust also have a solution. Is the converse statement true?
3. Let VN be an N-dimension subspace of W 1,2(Ω). Define the Galerkin method for approximating thesolution of the poisson equation problem, and prove that the Galerkin method has a unique solution.
4. Let uN denote the Galerkin solution, prove that
‖u −uN ‖E ≤ C infvN∈VN
‖u − vN ‖E ,
where
‖v‖E :=∫Ω
(|∇v|2 + 2v2
)dxdy.
Solution. J
References
[1] S. C. Brenner and R. Scott, The mathematical theory of finite element methods, vol. 15, Springer, 2008.108
[2] A. Iserles, A First Course in the Numerical Analysis of Differential Equations (Cambridge Texts in AppliedMathematics), Cambridge University Press, 2008. 80, 84, 86, 92, 151
[3] Y. Saad, Iterative methods for sparse linear systems, Siam, 2003. 2, 39
[4] A. J. Salgado, Numerical math lecture notes: 571-572. UTK, 2013-14. 1
[5] S. M. Wise, Numerical math lecture notes: 571-572. UTK, 2012-13. 1
Page 113 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 114
Appendices
A Numerical Mathematics Preliminary Examination Sample Question,Summer, 2013
A.1 Numerical Linear Algebra
Problem A.1. (Sample#1) Suppose A ∈ Cn×nher , and ρ(A) ⊂ (0,∞). Prove that A is Hermitian Positive
Definite.
Solution. Since A ∈ Cn×nher , then the eigenvalue of A are real. Let λ be arbitrary eigenvalue of A, then
(Ax,x) = (λx,x) = λ(x,x),
(Ax,x) = (x,A∗x) = (x,Ax)(x,λx) = λ(x,x),
and then λ= λ, so λ is real. Moreover, since ρ(A) ⊂ (0,∞), then we have λ is positive.
x∗Ax = x∗λx = λx∗x = λ(x21 + x
22 + · · ·+ x
2n) > 0.
for all x , 0. Hence, A is Hermitian Positive Definite. J
Problem A.2. (Sample#2) Suppose dim(A) = n. If A has n distinct eigenvalues , then A is diagonalizable.
Solution. (Sketch) Suppose n = 2, and let λ1,λ2 be distinct eigenvalues of A with corresponding eigen-vectors v1,v2. Now, we will use contradiction to show v1,v2 are lineally independent. Suppose v1,v2 arelineally dependent, then
c1v1 + c2v2 = 0, (210)
with c1,c2 are not both 0. Multiplying A on both sides of (210), then
c1Av1 + c2Av2 = c1λ1v1 + c2λ2v2 = 0. (211)
Multiplying λ1 on both sides of (210), then
c1λ1v1 + c2λ1v2 = 0. (212)
Subtracting (212) form (211), then
c2(λ2 −λ1)v2 = 0. (213)
Since λ1 , λ2 and v2 , 0, then c2 = 0. Similarly, we can get c1 = 0. Hence, we get the contradiction.A similar argument gives the result for n. Then we get A has n linearly independent eigenvectors . J
Problem A.3. (Sample#5) Let u,v ∈ Cn and set A := In+ uv∗ ∈ Cn×n.
1. Suppose A is invertible. Prove that A−1 = In+αuv∗, for some α ∈ C. Give the expression for α.
2. For what u and v is A singular ?
3. Suppose A is singular. What is the null space of A, N(A), in this case?
Page 114 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 115
Solution. 1. If uv∗ = 0, then the proof is trivial. Assume uv∗ , 0, then
A−1A = (In+αuv∗) (In+ uv
∗)
= In+ uv∗+α(uv∗+ u(v∗u)v∗)
= In+ (1+α+αv∗u)uv∗
= In.
i.e.
1+α+αv∗u = 0,
i.e.
α = − 11+ v∗u
,1 , −v∗u.
2. For 1 = −v∗u, the A is singular.
3. If A is singular, then v∗u = −1.
Claim A.1. N(A)=span(u).
Proof. (a) ⊆ let w ∈N (A), then we have
Aw = (In+ uv∗)w = w+ uv∗w = 0
Then we have w = −v∗wu, hence w ∈ span(u).(b) ⊇ Let w ∈ span(u), then we have w = βu, then
Aw = (In+ uv∗)βu = β(u+ uv∗u) = β(u+ (v∗u)u) = 0.
hence span(u) ∈ w.J
J
Problem A.4. (Sample #6) Suppose that A ∈Rn×n is SPD.
1. Show that ‖x‖A =√xTAx defines a vector norm.
2. Let the eigenvalues of A be ordered so that 0 < λ1 ≤ λ2 ≤ · · · ≤ λn. Show that√λ1 ‖x‖2 ≤ ‖x‖A ≤
√λn ‖x‖2 .
for any x ∈Rn.
3. Let b ∈ Rn be given. Prove that x∗ ∈ Rn solves Ax = b if and only if x∗ minimizes the quadraticfunction f : Rn→R defined by
f (x) =12xTAx − xT b.
Solution. 1. (a) Obviously, ‖x‖A =√xTAx ≥ 0. When x = 0, then ‖x‖A =
√xTAx = 0; when ‖x‖A =√
xTAx = 0, then we have (Ax,x) = 0, since A is SPD, therefore, x ≡ 0.
(b) ‖λx‖A =√λxTAλx =
√λ2xTAx = |λ|
√xTAx = |λ| ‖x‖A.
Page 115 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 116
(c) Next we will show∥∥∥x+ y∥∥∥
A= ‖x‖A+
∥∥∥y∥∥∥A
. First, we would like to show∣∣∣yTAx∣∣∣ ≤ ‖x‖A ∥∥∥y∥∥∥A
.
Since A is SPD, therefore A= RTR, moreover
‖Rx‖2 = (Rx,Rx)1/2 =√(Rx)TRx =
√xTRTRx =
√xTAx = ‖x‖A .
Then ∣∣∣yTAx∣∣∣= ∣∣∣yTRTRx∣∣∣= ∣∣∣(Ry)TRx∣∣∣= ∣∣∣(Rx,Ry)∣∣∣ c.s.≤ ‖Rx‖2 ∥∥∥Ry∥∥∥2
= ‖x‖A∥∥∥y∥∥∥
A.
And ∥∥∥x+ y∥∥∥2A
= (x+ y,x+ y)A = (x,x)A+ 2(x,y)A+ (y,y)A
≤ ‖x‖A+ 2∣∣∣yTAx∣∣∣+ ∥∥∥y∥∥∥
A
≤ ‖x‖A+ 2‖x‖A∥∥∥y∥∥∥
A+
∥∥∥y∥∥∥A
=(‖x‖A+
∥∥∥y∥∥∥A
)2.
therefore ∥∥∥x+ y∥∥∥A= ‖x‖A+
∥∥∥y∥∥∥A
.
2. Since A is SPD, therefore A= RTR, moreover
‖Rx‖2 = (Rx,Rx)1/2 =√(Rx)TRx =
√xTRTRx =
√xTAx = ‖x‖A .
Let 0 < λ1 ≤ λ2 ≤ · · · ≤ λn be the eigenvalue of R, then λi =√λi . so∣∣∣λ1
∣∣∣‖x‖2 ≤ ‖Rx‖2 = ‖x‖A ≤ ∣∣∣λn∣∣∣‖x‖2 .
i.e. √λ1 ‖x‖2 ≤ ‖Rx‖2 = ‖x‖A ≤
√λn ‖x‖2 .
3. Since
∂∂xi
(xTAx
)=
∂∂xi
(xT
)Ax+ xT
∂∂xi
(Ax)
= [0, · · · ,0,1i,0, · · · ,0]Ax+ xTA
0...010...0
i
= (Ax)i +(AT x
)i= 2 (Ax)i .
and
∂∂xi
(xT b
)=
∂∂xi
(xT
)b = [0, · · · ,0,1
i,0, · · · ,0]b = bi .
Page 116 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 117
Therefore,
∇f (x) = 12
2Ax − b = Ax − b.
If Ax∗ = b, then ∇f (x∗) = Ax∗ − b = 0, therefore x∗ minimizes the quadratic function f. Conversely,when x∗ minimizes the quadratic function f, then ∇f (x∗) = Ax∗ − b = 0, therefore Ax∗ = b.
J
Problem A.5. (Sample#9) Suppose that the spectrum of A ∈Rn×nsym is denoted ρ(A) = λ1,λ2, · · · ,λn ⊂R.
Let S = x1, · · · ,xn be the orthonormal basis of eigenvectors of A, with Axk = λkxk , for k = 1, · · · ,n. TheRayleigh quotient of x ∈Rn
∗ is defined as
R(x) :=xTAxxT x
.
Prove the following facts:
1.
R(x) :=
∑nj=1λjα
2j∑n
j=1α2j
where αj = xT xj .
2.
minλ∈ρ(A)
λ ≤ R(x) ≤ maxλ∈ρ(A)
λ.
Solution. 1. First, we need to show that x =∑nj=1αjxj is the unique representation of x w.r.t. the or-
thonormal basis S. Since S = x1, · · · ,xn is the orthonormal basis of eigenvectors of A, then∑nj=1 xT xjxj
is the representation of x. Assume∑nj=1βjxj is another representation of x. Then we have
∑nj=1(βj −
αj)xj = 0, since xj . 0, so α = β. Now , we have
xTAx = xTAn∑j=1
αjxj
= xTn∑j=1
αjAxj
= xTn∑j=1
αjλjxj
=n∑j=1
αjλjxT xj
=n∑j=1
λjα2j .
Similarly, we have xT x =∑nj=1α
2j . Hence,
R(x) :=xTAxxT x
=
∑nj=1λjα
2j∑n
j=1α2j
.
Page 117 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 118
2. Since,
R(x) :=xTAxxT x
=
∑nj=1λjα
2j∑n
j=1α2j
.
, then
minjλj
∑nj=1α
2j∑n
j=1α2j
≤ R(x) ≤maxjλj
∑nj=1α
2j∑n
j=1α2j
,
i.e.
minjλj ≤ R(x) ≤max
jλj .
Hence
minλ∈ρ(A)
λ ≤ R(x) ≤ maxλ∈ρ(A)
λ.
J
Problem A.6. (Sample #31) Let A ∈ Rn×n be symmetric positive define (SPD). Let b ∈ Rn. Considersolving Ax = b using the iterative method
Mxn+1 = Nxn+ b, n= 0,1,2, · · ·
where A=M −N , M is invertible, and x0 ∈Rn us arbitrary.
1. If M +MT −A is SPD, prove that the method is convergent.
2. Prove that the Gauss-Seidel Method converges.
Solution. 1. From the problem, we get
xn+1 =M−1Nxn+M−1b.
LetG =M−1N =M−1(M−A) = I−M−1A, If we can prove that ρ(G) < 1, then this method converges.Let λ be any eigenvalue of G and x be the corresponding eigenvector, i.e.
Gx = λx.
then
(I −M−1A)x = λx,
i.e.
(M −A)x = λMx,
i.e.
(1−λ)Mx = Ax.
(a) λ , 1. If λ= 1, then Ax = 0, for any x, so A= 0 which contradicts to A is SPD.
Page 118 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 119
(b) λ ≤ 1. Since, (1−λ)Mx = Ax. then
(1−λ)x∗Mx = x∗Ax.
So we have
x∗Mx =1
1−λx∗Ax.
taking conjugate transpose of which yields
x∗M∗x =1
1−λx∗A∗x =
1
1−λx∗Ax.
Then, we have
x∗(M +M∗ −A)x =
(1
1−λ+
1
1−λ− 1
)x∗Ax
=
(λ
1−λ+
1
1−λ
)x∗Ax
=1−λ2
|1−λ|2x∗Ax.
Since M +M∗ −A and A are SPD, then x∗(M +M∗ −A)x > 0, x∗Ax > 0. Therefore,
1−λ2 > 0.
i.e.
|λ| < 1.
2.
Jacobi Method: MJ = D,NJ = −(L+U )
Gauss-Seidel Method: MGS = D + L,NGS = −U .
where A = L+D +U . Since A is SPD, then MGS +MTGS −A = D + L+DT + LT −A = D + LT −U is
SPD. Therefore, From the part 1, we get that the Gauss-Seidel Method converges.J
Problem A.7. (Sample #32) Let A ∈ Rn×n be symmetric positive define (SPD). Let b ∈ Rn. Considersolving Ax = b using the iterative method
Mxn+1 = Nxn+ b, n= 0,1,2, · · ·
where A=M −N , M is invertible, and x0 ∈Rn us arbitrary. Suppose that M+MT −A is SPD. Show thateach step of this method reduces the A-norm of en = x−xn, whenever en , 0. Recall that, the A-norm of anyy ∈Rn is defined via ∥∥∥y∥∥∥
A=
√yTAy.
Page 119 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 120
Solution. Let ek = xk − x. And rewrite the scheme to the canonical form B=M,α = 1, then
B
(xk+1 − xk
α
)+Axk = b = Ax.
so, we get
B
(ek+1 − ek
α
)+Aek = 0.
Let vk+1 = ek+1 − ek , then
1αBvk+1 +Aek = 0.
Taking the conjugate transport of the above equation, then we get
1αB∗vk+1 +A ∗ ek = 1
αB∗vk+1 +Aek = 0.
therefore
1α(B+B∗
2)vk+1 +Aek = 0.
Let Bs =B+B∗
2 . Then take the inner product of both sides with vk+1,
1α(Bsv
k+1,vk+1) + (Aek ,vk+1) = 0.
Since
ek =12(ek+1 + ek)− 1
2(ek+1 − ek) = 1
2(ek+1 + ek)− 1
2vk+1.
Therefore,
0 =1α(Bsv
k+1,vk+1) + (Aek ,vk+1)
=1α(Bsv
k+1,vk+1) +12(A(ek+1 + ek),vk+1)− 1
2(Avk+1,vk+1)
=1α((Bs −
α2A)vk+1,vk+1) +
12(A(ek+1 + ek),vk+1)
=1α((Bs −
α2A)vk+1,vk+1) +
12(∥∥∥ek+1
∥∥∥2
A−∥∥∥ek∥∥∥2
A)
By assumption, Q = Bs − α2A= M+MT −A2 > 0, i.e. there exists m > 0, s.t.
(Qy,y) ≥m∥∥∥y∥∥∥2
2.
Therefore,
mα
∥∥∥vk+1∥∥∥2
2+
12(∥∥∥ek+1
∥∥∥2
A−∥∥∥ek∥∥∥2
A) ≤ 0.
i.e.
2mα
∥∥∥vk+1∥∥∥2
2+
∥∥∥ek+1∥∥∥2
A≤
∥∥∥ek∥∥∥2
A.
Page 120 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 121
Hence ∥∥∥ek+1∥∥∥2
A≤
∥∥∥ek∥∥∥2
A.
and ∥∥∥ek+1∥∥∥2
A→ 0.
J
Problem A.8. (Sample #33) Consider a linear system Ax = b with A ∈ Rn×n. Richardson’s method is aniteration method
Mxk+1 = Nxk + b
with M = 1w I ,N = M −A = 1
w I −A, where w is a damping factor chosen to make M approximate A aswell as possible. Suppose A is positive definite and w > 0. Let λ1 and λn denote the smallest and largesteigenvalues of A.
1. Prove that Richardson’s method converges if only if w < 2λn
.
2. Prove that the optimal value value of w is w0 =2
λ1+λn.
Solution. 1. From the scheme of the Richardson’s method, we know that
xk+1 = (I −wA)xk +wb.
So the error transfer operator is T = I −wA. Then if λi is the eigenvalue of A, then 1−wλi should bethe eigenvalue of T . The sufficient and necessary condition of convergence is ρ(T ) < 1, i.e.
|1−wλi | < 1
for all i. Therefore, we have
w <2λi
.
Since λn denote the largest eigenvalues of A, then 2λn≤ 2λi
. Hence, we need
w <2λn
.
conversely, if w < 2λn
, then ρ(T ) < 1, then the scheme converges.
2. The minimum is attachment at |1−ωλn|= |1−ωλ1|(Figure.1), i.e.
ωλn − 1 = 1−ωλ1.
Therefore, we get
ωopt =2
λ1 +λn.
J
Page 121 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 122
Problem A.9. (Sample #34) Let A ∈ Cn×n. Define
Sn := I +A+A2 + · · ·+An.
1. Prove that the sequence Sn∞n=0 converges if only if A is convergent.
2. Prove that if A is convergent, then I −A is non-singular and
limn→∞
Sn = (I −A)−1.
Solution. 1. From the problem, we know that
Sn := I +A+A2 + · · ·+An = A0 +A+A2 + · · ·+An =n∑k=0
Ak .
Moreover, ∥∥∥Ak∥∥∥= sup0,x∈Cn
∥∥∥Akx∥∥∥‖x‖
≤ sup0,x∈Cn
‖A‖∥∥∥Ak−1x
∥∥∥‖x‖
≤ · · · ≤ ‖A‖k .
From the properties of geometric series, Sn converges if only if |A| < 1. Therefore, we get if |A| < 1then A is convergent. Conversely, if A is convergent, then |A| < 1. Hence Sn converges.
If A is convergent, then ‖A‖ , 0. Therefore, if∥∥∥(I −A)x∥∥∥= 0, then ‖x‖= 0, i.e. ker(I −A) = 0. Hence,
I −A is non-singular. From the definition of Sn, we get
(I −A)Sn =n∑k=0
Ak −n+1∑k=1
Ak = A0 −An+1 = I −An+1.
Taking limit on both sides of the above equation with the fact |A| < 1, then we get
(I −A) limn→∞
Sn = I .
Since I −A is non-singular, then we have
limn→∞
Sn = (I −A)−1.
J
Problem A.10. (Sample #40) Show that if λ is an eigenvalue of A∗A, where A ∈ Cn×n, then
0 ≤ λ ≤ ‖A‖‖A∗‖
Solution. Since x∗A∗Ax = (Ax)∗(Ax) = λx∗x ≥ 0, therefore λ ≥ 0, and λ is real. Since
A∗Ax = λx.
so
0 ≤ λ‖x‖= ‖λx‖= ‖A∗Ax‖ ≤ ‖A∗‖‖A‖‖x‖ .
J
Page 122 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 123
Problem A.11. (Sample #41) Suppose A ∈ Cn×n and A is invertible. Prove that
κ2 ≤√λnλ1
.
where λn is the largest eigenvalue of B := A∗A, and λ1 is the smallest eigenvalue of B.
Solution. Since κ2 = ‖A‖2∥∥∥A−1
∥∥∥2
and ‖A‖2 = maxρ(A) =√λn. therefore
κ2 = ‖A‖2∥∥∥A−1
∥∥∥2=
√λn√λ1
.
J
Problem A.12. (Sample #34) Let A= [ai,j ] ∈ Cn×n be invertible and b ∈ Cn. Prove that the classical Jacobiiteration method for approximating the solution to Ax = b is convergent, for any starting value x0, if A isstrictly diagonally dominant, i.e. ∣∣∣ai,i ∣∣∣ <∑
k,i
∣∣∣ai,k ∣∣∣ , ∀ i = 1, · · · ,n.
Solution. The Jacobi iteration scheme is as follows
D(xk+1 − xk) +Axk = b.
This scheme can be rewritten as
xk+1 = (I −D−1A)xk +D−1b.
We want to show If A is diagonal dominant , then∥∥∥TJ∥∥∥ < 1, then Jacobi Method convergences. From the
definition of T, we know that T for Jacobi Method is as follows
TJ = I −D−1A.
In the matrix form is
T =
1 0
. . .0 1
−
1a11
0. . .
0 1ann
a11 · · · a1n
.... . .
...an1 · · · ann
= [tij
]=
tij = 0, i = j,tij = −
aijaii
, i , j..
So,
‖T ‖∞ = maxi
∑j
|tij |= maxi
∑i,j
|aijaii|.
Since A is diagonal dominant, so
|aii | ≥∑j,i
|aij |.
Therefore,
1 ≥∑j,i
|aij ||aii |
.
Hence, ‖T ‖∞ < 1 J
Page 123 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 124
Problem A.13. (Sample #35) Let A = [ai,j ] ∈ Cn×n be invertible and b ∈ Cn. Prove that the classicalGauss-Seidel iteration method for approximating the solution to Ax = b is convergent, for any startingvalue x0, if A is strictly diagonally dominant, i.e.∣∣∣ai,i ∣∣∣ <∑
k,i
∣∣∣ai,k ∣∣∣ , ∀ i = 1, · · · ,n.
Solution. The Jacobi iteration scheme is as follows
We want to show If A is diagonal dominant , then ‖TGS‖ < 1, then Jacobi Method convergences. From thedefinition of T, we know that T for Gauss-Seidel iteration Method is as follows
TGS = −(L+D)−1U .
Since A is diagonal dominant, so So,
|aii | −∑j<i
|aij | ≥∑j>i
|aij |,
which implies
γ =maxi
∑j>i |aij |
|aii | −∑j<i |aij
|≤ 1.
Now, we will show ‖TGS‖ < γ . Let x ∈ Cn and y = T x, i.e.
y = TGSx = −(L+D)−1Ux.
Let i0 be the index such that∥∥∥y∥∥∥∞ = |yi0 |, then we have
|((L+D)y)i0 |= |(Ux)i0 |= |∑j>i0
ai0jxj | ≤∑j>i0
|ai0j ||xj | ≤∑j>i0
|ai0j | ‖x‖∞ .
Moreover
|((L+D)y)i0 |= |∑j<i0
ai0jyj + ai0i0yj | ≥ |ai0i0yj | − |∑j<i0
ai0jyj |= |ai0i0 |∥∥∥y∥∥∥∞ − |∑
j<i0
ai0jyj | ≥ |ai0i0 |∥∥∥y∥∥∥∞ −∑
j<i0
|ai0j |∥∥∥y∥∥∥∞ .
Therefore, from the above two equations, we have
|ai0i0 |∥∥∥y∥∥∥∞ −∑
j<i0
|ai0j |∥∥∥y∥∥∥∞ ≤∑
j>i0
|ai0j | ‖x‖∞ ,
which implies
∥∥∥y∥∥∥∞ ≤∑j>i0|ai0j |
|ai0i0 | −∑j<i0|ai0j |
‖x‖∞ .
Page 124 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 125
So,
‖TGSx‖∞ ≤ γ ‖x‖∞ ,
which implies
‖TGS‖∞ ≤ γ < 1.
J
Problem A.14. (Sample #38) Let A ∈ Cn×n be invertible and suppose b ∈ Cn∗ satisfies Ax = b. let the
perturbations δx,δb ∈ Cn satisfy Aδx = δb, so that A(x+ δx) = b+ δb.
1. Prove the error (or perturbation) estimate
1κ(A)
‖δb‖‖b‖≤ ‖δx‖‖x‖≤ κ(A) ‖δb‖
‖b‖.
2. Show that for any invertible matrix A, the upper bound for ‖δb‖‖b‖ above can be attained for suitablechoice of b and δb. (In other words, the upper bound is sharp.)
Solution. 1. Since Ax = b and Aδx = δb, then x = A−1b and
‖δb‖= ‖Aδx‖ ≤ ‖A‖‖δx‖ ,‖x‖=∥∥∥A−1b
∥∥∥ ≤ ∥∥∥A−1∥∥∥‖b‖ .
Therefore
‖δb‖‖A‖
≤ ‖δx‖ ,1∥∥∥A−1∥∥∥‖b‖ ≤ 1
‖x‖.
Hence
1κ(A)
‖δb‖‖b‖≤ ‖δx‖‖x‖
.
Similarly, since Ax = b and Aδx = δb, then δx = A−1δb and
‖b‖= ‖Ax‖ ≤ ‖A‖‖x‖ ,‖δx‖=∥∥∥A−1δb
∥∥∥ ≤ ∥∥∥A−1∥∥∥‖δb‖ .
Therefore
1‖x‖≤ ‖A‖‖b‖
.
Hence,
‖δx‖‖x‖≤ κ(A) ‖δb‖
‖b‖.
So,
1κ(A)
‖δb‖‖b‖≤ ‖δx‖‖x‖≤ κ(A) ‖δb‖
‖b‖.
Page 125 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 126
2. Since Ax = b and Aδx = δb, then x = A−1b and
1‖b‖≤
∥∥∥A−1∥∥∥
‖x‖,‖δb‖= ‖Aδx‖ ≤ ‖A‖‖δx‖ .
Hence,
‖δb‖‖b‖≤ κ(A) ‖δx‖
‖x‖
So the upper bound for ‖δb‖‖b‖ above can be attained for suitable choice of b and δb, since x and δx aredependent on b and δb, respectively.
J
Problem A.15. (Sample #39) Let A ∈ Rn×n,b ∈ Rn. Suppose x and x solove Ax = b and (A+ δA)x =b+ δb, respectively. Assuming that
∥∥∥A−1∥∥∥‖δA‖ < 1, show that
‖δx‖‖x‖≤
κ(A)
1−κ2(A)‖δA‖2‖A‖2
(‖δA‖‖A‖
+‖δb‖‖b‖
)
where δx = x − x.
Solution. Since∥∥∥A−1
∥∥∥‖δA‖ < 1, then we have∥∥∥A−1δA∥∥∥ ≤ ∥∥∥A−1
∥∥∥‖δA‖ < 1.
Therefore, ∥∥∥∥(I −A−1δA)−1
∥∥∥∥ ≤ 1
1−∥∥∥A−1δA
∥∥∥ .∥∥∥∥(I +A−1δA)−1
∥∥∥∥ ≤ 1
1−∥∥∥A−1δA
∥∥∥ .
δx = x+ δx − x= (A+ δA)−1(b+ δb)−A−1b
= (A+ δA)−1AA−1(b+ δb)−A−1b
= (A+ δA)−1(A−1
)−1A−1(b+ δb)−A−1b
= (A−1A+A−1δA)−1A−1(b+ δb)−A−1b
= (I +A−1δA)−1A−1(b+ δb)−A−1b
= (I +A−1δA)−1 (
A−1(b+ δb)− (I +A−1δA)A−1b)
= (I +A−1δA)−1 (
A−1δb −A−1δAA−1b)
Page 126 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 127
Therefore,
‖δx‖ ≤1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1δb∥∥∥+ ∥∥∥A−1δAA−1b
∥∥∥)≤ 1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1∥∥∥‖δb‖+ ∥∥∥A−1
∥∥∥‖δA‖∥∥∥A−1b∥∥∥)
=1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1∥∥∥‖δb‖+ ∥∥∥A−1
∥∥∥‖δA‖‖x‖)=
κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δb‖‖A‖
+‖δA‖‖x‖‖A‖
)
Dividing ‖x‖ on both sides of the above equation yields
‖δx‖‖x‖
≤κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δb‖‖A‖‖x‖
+‖δA‖‖A‖
)
Since ‖b‖= ‖Ax‖ ≤ ‖A‖‖x‖, then we have
‖δx‖‖x‖
≤κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δb‖‖b‖
+‖δA‖‖A‖
)≤
κ(A)
1−∥∥∥A−1
∥∥∥2 ‖δA‖2
(‖δb‖‖b‖
+‖δA‖‖A‖
)≤
κ(A)
1− ‖A−1‖2‖A‖2‖δA‖2‖A‖2
(‖δb‖‖b‖
+‖δA‖‖A‖
)
=κ(A)
1−κ2(A)‖δA‖2‖A‖2
(‖δb‖‖b‖
+‖δA‖‖A‖
).
J
Problem A.16. (Sample #39) Let A ∈ Rn×n,b ∈ Rn. Suppose x and x solove Ax = b and (A+ δA)x = b,respectively. Assuming that
∥∥∥A−1∥∥∥‖δA‖ < 1, show that
‖δx‖‖x‖≤
κ(A)
1−κ2(A)‖δA‖2‖A‖2
‖δA‖‖A‖
.
where δx = x − x.
Solution. Since∥∥∥A−1
∥∥∥‖δA‖ < 1, then we have∥∥∥A−1δA∥∥∥ ≤ ∥∥∥A−1
∥∥∥‖δA‖ < 1.
Therefore, ∥∥∥∥(I −A−1δA)−1
∥∥∥∥ ≤ 1
1−∥∥∥A−1δA
∥∥∥ .∥∥∥∥(I +A−1δA)−1
∥∥∥∥ ≤ 1
1−∥∥∥A−1δA
∥∥∥ .
Page 127 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 128
δx = x+ δx − x= (A+ δA)−1b −A−1b
= (A+ δA)−1AA−1b −A−1b
= (A+ δA)−1(A−1
)−1A−1b −A−1b
= (A−1A+A−1δA)−1A−1b −A−1b
= (I +A−1δA)−1A−1b −A−1b
= (I +A−1δA)−1 (
A−1b − (I +A−1δA)A−1b)
= (I +A−1δA)−1 (−A−1δAA−1b
)Therefore,
‖δx‖ ≤1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1δAA−1b∥∥∥)
≤ 1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1∥∥∥‖δA‖∥∥∥A−1b
∥∥∥)=
1
1−∥∥∥A−1δA
∥∥∥ (∥∥∥A−1∥∥∥‖δA‖‖x‖)
=κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δA‖‖x‖‖A‖
)
Dividing ‖x‖ on both sides of the above equation yields
‖δx‖‖x‖
≤κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δA‖‖A‖
)
Since ‖b‖= ‖Ax‖ ≤ ‖A‖‖x‖, then we have
‖δx‖‖x‖
≤κ(A)
1−∥∥∥A−1δA
∥∥∥(‖δA‖‖A‖
)≤
κ(A)
1−∥∥∥A−1
∥∥∥2 ‖δA‖2
(‖δA‖‖A‖
)≤
κ(A)
1− ‖A−1‖2‖A‖2‖δA‖2‖A‖2
(‖δA‖‖A‖
)
=κ(A)
1−κ2(A)‖δA‖2‖A‖2
‖δA‖‖A‖
.
J
Problem A.17. (Sample #40) Show that if λ is an eigenvalue of A∗A, where A ∈ Cn×n, then
0 ≤ λ ≤ ‖A∗‖‖A‖ .
Page 128 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 129
Problem A.18. (Sample #41) Suppose A ∈ Cn×n is invertible. Show that
κ2(A) =
√λnλ1
,
where λn is the largest eigenvalue of B := A∗A, and λ1 is the smallest eigenvalue of B.
Problem A.19. (Sample #42) Suppose A ∈ Cn×n and A is invertible. Prove that
κ2 ≤√κ1(A)κ∞(A).
Solution.
Claim A.2.
‖A‖22 ≤ ‖A‖1 ‖A‖∞ .
Proof.
‖A‖22 = ρ(A)2 = λ ≤ ‖A‖1 ‖A∗‖1 = ‖A‖1 ‖A‖∞ .
where λ is the eigenvalue of A∗A. J
Since κ2 = ‖A‖2∥∥∥A−1
∥∥∥2, κ1 = ‖A‖1
∥∥∥A−1∥∥∥
1and κ∞ = ‖A‖∞
∥∥∥A−1∥∥∥∞.
‖A‖2∥∥∥A−1
∥∥∥2≤
√‖A‖1 ‖A‖∞
√∥∥∥A−1∥∥∥
1
∥∥∥A−1∥∥∥∞ ≤√
‖A‖1∥∥∥A−1
∥∥∥1 ‖A‖∞
∥∥∥A−1∥∥∥∞ =
√κ1(A)κ∞(A).
J
Problem A.20. (Sample #44) Suppose A,B ∈Rn×n and A is non-singular and B is singular. Prove that
1κ(A)
≤ ‖A−B‖‖A‖
,
where κ(A) = ‖A‖ ·∥∥∥A−1
∥∥∥, and ‖·‖ is an reduced matrix norm.
Solution. Since B is singular, then there exists a vector x , 0, s.t. Bx = 0. Since A is non-singular, thenA−1 is also non-singular. Moreover, A−1Bx = 0. Then, we have
x = x −A−1Bx = (I −A−1B)x.
So
‖x‖=∥∥∥(I −A−1B)x
∥∥∥ ≤ ∥∥∥A−1A−A−1B∥∥∥‖x‖ ≤ ∥∥∥A−1
∥∥∥‖A−B‖‖x‖ .Since x , 0, so
1 ≤∥∥∥A−1
∥∥∥‖A−B‖ .1∥∥∥A−1∥∥∥‖A‖ ≤ ‖A−B‖‖A‖
,
i.e.1
κ(A)≤ ‖A−B‖‖A‖
.
J
Page 129 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 130
A.2 Numerical Solutions of Nonlinear Equations
Problem A.21. (Sample #1) Let xn be a sequence generated by Newton’s method. Suppose that the initialguess x0 is well chosen so that this sequence converges to the exact solution x∗. Prove that if f (x∗) =f ′(x∗) = · · ·= f m−1(x∗) = 0,f m(x∗) , 0, xn converges linearly to x∗ with
limk→∞
ek+1
ek=m− 1m
.
Solution. Newton’s method scheme is read as follows
xk+1 = xk −f (xk)
f ′(xk).
Let ek = xk − x∗, then
ek+1 = xk+1 − x∗
= xk −f (xk)
f ′(xk)− x∗
= ek −f (xk)
f ′(xk).
Therefore,
ek+1
ek= 1−
f (xk)
ekf ′(xk).
Since x0 is well chosen so that this sequence converges to the exact solution x∗, therefore we have the Taylorexpansion for f (xk),f ′(xk) at x∗, i.e.
f (xk) = f (x∗) + f′(x∗)e
k + · · ·+f (m−1)(x∗)
(m− 1)!
(ek
)m−1+f (m)(ξk)
m!
(ek
)m=
f (m)(ξk)
m!
(ek
)m, ξk ∈ [x∗,xk ].
f ′(xk) = f ′(x∗) + f′′(x∗)e
k + · · ·+f (m−1)(x∗)
(m− 2)!
(ek
)m−2+f (m)(ηk)
(m− 1)!
(ek
)m−1
=f (m)(ηk)
(m− 1)!
(ek
)m−1, ηk ∈ [x∗,xk ].
Hence,
limk→∞
ek+1
ek= 1−
f (xk)
ekf ′(xk)= 1−
f (m)(ξk)m!
(ek
)mf (m)(ηk)(m−1)!
(ek
)m−1ek
=m− 1m
= 1− 1m
f (m)(ξk)
f (m)(ηk)= 1− 1
m=m− 1m
,
since when k→∞ then ξk ,ηk → x∗. J
Page 130 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 131
Problem A.22. (Sample #2) Let f : Ω ⊂Rn→Rn be twice continuously differentiable. Suppose x∗ ∈Ω isa solution of f(x) = 0, and the Jacobian matrix of f, denoted Jf, is invertible at x∗.
1. Prove that if x0 ∈Ω is sufficiently close to x∗, then the following iteration converges to x∗:
xk+1 = xk −(Jf(x
0))−1
f(xk).
2. Prove that the convergence is typically linear.
Solution. J
Problem A.23. (Sample #3) Let a ∈ Rn and R > 0 be given. Suppose that f : B(a,R) → Rn, fi ∈C2(B(a,R)), for each i = 1, · · · ,n. Suppose that there is a point ξ ∈ B(a,R), such that f(ξ) = 0, andthat the Jacobian matrix Jf(x) is invertible, with estimate
∥∥∥[Jf(x)]−1∥∥∥
2≤ β, for any x ∈ B(a,R). Prove that
the sequence xk defined by Newton’s method,
Jf(xk) (xk+1 − xk) = −f(xk),
converges (at least) Linear to the root ξ as k→∞, provided x0 is sufficiently close to ξ.
Solution. J
Problem A.24. (Sample #6) Assume that f : R→ R,f ∈ C2(R),f ′(x) > 0 for all x ∈ R, and f ′′(x) > 0,for all x ∈R.
1. Suppose that a root ξ ∈ R exists. Prove that it is unique. Exhibit a function satisfying the assump-tions above that has no root.
2. Prove that for any starting guess x0 ∈ R, Newton’s method converges, and the convergence rate isquadratic.
Solution. 1. Let x1 and x2 are the two different roots. So, f (x1) = f (x2) = 0, then by Mean valuetheorem, we have that there exists η ∈ [x1,x2], such f (η) = 0 which contradicts f ′(x) > 0.
2. example f (x) = ex.
3. Let x∗ be the root of f (x). From the Taylor expansion, we know
0 = f (x∗) = f (xk) + f ′(xk)(x∗ − xk) + 12f ′′(θ)(x∗ − xk)2,
where θ is between x∗ and xk . Define ek = x∗ − xk , then
0 = f (x∗) = f (xk) + f ′(xk)(ek) +12f ′′(θ)(ek)2.
so [f ′(xk)
]−1f (xk) = −(ek)− 1
2
[f ′(xk)
]−1f ′′(θ)(ek)2.
From the Newton’s scheme, we havexk+1 = xk −[f ′(xk)
]−1f (xk)
x∗ = x∗
Page 131 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 132
So,
ek+1 = ek +[f ′(xk)
]−1f (xk) = −1
2
[f ′(xk)
]−1f ′′(θ)(ek)2,
i.e.
ek+1 = −f ′′(θ)
2[f ′(xk)
] (ek)2,
By assumption, there is a neighborhood of x, such that∣∣∣f ′′(z)∣∣∣ ≤ C1,∣∣∣f ′(z)∣∣∣ ≤ C2,
Therefore,
∣∣∣ek+1∣∣∣ ≤ ∣∣∣f ′′(θ)∣∣∣∣∣∣∣2 [
f ′(xk)]∣∣∣∣ (ek)2 ≤ C1
2C2
∣∣∣ek ∣∣∣2 .
This implies ∣∣∣xk+1 − x∗∣∣∣ ≤ C ∣∣∣xk − x∗∣∣∣2 .
J
Problem A.25. (Sample #8) Consider the two-step Newton method
yk = xk −f (xk)
f ′(xk),xk+1 = yk −
f (yk)
f ′(xk)
for the solution of the equation f (x) = 0. Prove
1. If the method converges, then
limk→∞
xk+1 − x∗
(yk − x∗)(xk − x∗)=f ′′(xk)
f ′(xk),
where x∗ is the solution.
2. Prove the convergence is cubic, that is
limk→∞
xk+1 − x∗
(xk − x∗)3 =12
(f ′′(xk)
f ′(xk)
).
3. Would you say that this method is faster than Newton’s method given that its convergence is cubic?
Solution. 1. First, we will show that if xk ∈ [x − h,x+ h], then yk ∈ [x − h,x+ h]. By Taylor expansionformula, we have
0 = f (x∗) = f (xk) + f′(xk)(x
∗ − xk) +12!f ′′(ξk)(x
∗ − xk)2,
where ξ is between x and xk . Therefore, we have
f (xk) = −f ′(xk)(x∗ − xk)−12!f ′′(ξk)(x
∗ − xk)2.
Page 132 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 133
Plugging the above equation to the first step of the Newton’s method, we have
yk = xk + (x∗ − xk) +12!f ′′(ξk)
f ′(xk)(x∗ − xk)2.
then
yk − x∗ =12!f ′′(ξk)
f ′(xk)(x∗ − xk)2. (214)
Therefore, ∣∣∣yk − x∗∣∣∣= ∣∣∣∣∣ 12!f ′′(ξk)
f ′(xk)(x∗ − xk)2
∣∣∣∣∣ ≤ 12
∣∣∣∣∣ f ′′(ξk)f ′(xk)
∣∣∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ .Since we can choose the initial value very close to x∗, shah that∣∣∣∣∣ f ′′(ξ)f ′(xk)
∣∣∣∣∣ ∣∣∣(x∗ − xk)∣∣∣ ≤ 1
Then, we have that ∣∣∣yk − x∗∣∣∣ ≤ 12
∣∣∣(x∗ − xk)∣∣∣ .Hence, we proved the result, that is to say, if xk → x∗, then yk ,ξk → x∗.
2. Next, we will show if xk ∈ [x−h,x+h], then xk+1 ∈ [x−h,x+h]. From the second step of the Newton’sMethod, we have that
xk+1 − x∗ = yk − x∗ −f (yk)
f ′(xk)
=1
f ′(xk)((yk − x∗)f ′(xk)− f (yk))
=1
f ′(xk)[(yk − x∗)(f ′(xk)− f ′(x∗))− f (yk) + (yk − x∗)f ′(x∗)]
By mean value theorem, we have there exists ηk between x∗ and xk , such that
f ′(xk)− f ′(x∗) = f ′′ηk(xk − x∗),
and by Taylor expansion formula, we have
f (yk) = f (x∗) + f ′(x∗)(yk − x∗) +(yk − x∗)2
2f ′′(γk)
= f ′(x∗)(yk − x∗) +(yk − x∗)2
2f ′′(γk),
where γ is between yk and x∗. Plugging the above two equations to the second step of the Newton’smethod, we get
xk+1 − x∗ =1
f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)− f ′(x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk) + (yk − x∗)f ′(x∗)
]=
1f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk)
]. (215)
Page 133 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 134
Taking absolute values of the above equation, then we have
∣∣∣xk+1 − x∗∣∣∣ =
∣∣∣∣∣∣ 1f ′(xk)
[f ′′ηk(xk − x∗)(yk − x∗)−
(yk − x∗)2
2f ′′(γk)
]∣∣∣∣∣∣≤ A |xk − x∗|
∣∣∣yk − x∗∣∣∣+ A2
∣∣∣yk − x∗∣∣∣ ∣∣∣yk − x∗∣∣∣≤ 1
2|xk − x∗|+
18|xk − x∗|=
58|xk − x∗| .
Hence, we proved the result, that is to say, if yk → x∗, then xk+1,ηk ,γk → x∗.
3. Finally, we will prove the convergence order is cubic. From (215), we can get that
xk+1 − x∗
(xk − x∗)(yk − x∗)=
f ′′ηkf ′(xk)
−(yk − x∗)f ′′(γk)2(xk − x∗)f ′(xk)
.
By using (214), we have
xk+1 − x∗
(xk − x∗)(yk − x∗)=
f ′′ηkf ′(xk)
− 14f ′′(ξk)
f ′(xk)(x∗ − xk)
f ′′(γk)
f ′(xk).
Taking limits gives
limk→∞
xk+1 − x∗
(xk − x∗)(yk − x∗)=f ′′(x∗)
f ′(x∗).
By using (214) again, we have
1yk − x∗
=2
(x∗ − xk)2f ′(xk)
f ′′(ξk).
Hence
limk→∞
xk+1 − x∗
(xk − x∗)3 =12
(f ′′(x∗)
f ′(x∗)
)2
.
J
A.3 Numerical Solutions of ODEs
Problem A.26. (Sample #1) Show that, if z is a non-zero complex number that iix on the boundary of thelinear stability domain of the two-step BDF method
yn+2 −43yn+1 +
13yn =
23hf (xn+2,yn+2),
then the real part of z must be positive. Thus deduce that this method is A-stable.
Solution. For our this problem
ρ(w) :=s∑
m=0
amwm = −2+w+w2 and σ (w) :=
s∑m=0
bmwm = 1+w+w2. (216)
Page 134 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 135
By making the substitution with ξ = w − 1 i.e. w = ξ + 1, then
ρ(w) :=s∑
m=0
amwm = ξ2 + 3ξ and σ (w) :=
s∑m=0
bmwm = ξ2 + 3ξ + 3. (217)
So,
ρ(w)− σ (w)ln(w) = ξ2 + 3ξ − (3+ 3ξ + ξ2)(ξ − ξ2
2+ξ3
3· · · )
=
+3ξ +ξ2
−3ξ −3ξ2 −ξ3
+ 32ξ
2 + 32ξ
3 + 12ξ
4
−ξ3 −ξ4 −13ξ
5
= −12ξ2 +O(ξ3).
Therefore, by the theorem
ρ(w)− σ (w)ln(w) = −12ξ2 +O(ξ3).
J
A.4 Numerical Solutions of PDEs
Problem A.27. (Sample #1) Let V be a Hilbert space with inner product (·, ·)V and norm ‖v‖V =√(v,v)V ,
∀v ∈ V . Suppose a : V ×V →R is a symmetric bilinear form that is
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 139
Problem A.30. (Sample #8) 1D Discrete Poincaré inequality: Let Ω= (0,1) and Ωh be a uniform grid ofsize h. If Y ∈ Uh is a mesh function on Ωh such that Y (0) = 0, then there is a constant C, independent of Yand h, for which
‖Y ‖2,h ≤ C∥∥∥δY ∥∥∥
2,h.
Solution. I consider the following uniform partition (Figure. A1) of the interval (0,1) with N points.
x1 = 0 x2 xN−1 xN = 1
Figure A1: One dimension’s uniform partition
Since the discrete 2-norm is defined as follows
‖v‖22,h = hdN∑i=1
|vi |2,
where d is dimension. So, we have
‖v‖22,h = hN∑i=1
|vi |2,∥∥∥δv∥∥∥2
2,h= h
N∑i=2
∣∣∣∣vi−1 − vih
∣∣∣∣2 .
Since Y (0) = 0, i.e. Y1 = 0,
N∑i=2
(Yi−1 −Yi) = Y1 −YN = −YN .
Then, ∣∣∣∣∣∣∣N∑i=2
Yi−1 −Yi
∣∣∣∣∣∣∣= |YN |.and
|YN | ≤N∑i=2
|Yi−1 −Yi |=N∑i=2
h
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣ ≤ N∑i=2
h2
1/2 N∑
i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2
1/2
.
Therefore
|YK |2 ≤
K∑i=2
h2
K∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2
= h2(K − 1)K∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
1. When K = 2,
|Y2|2 ≤ h2∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 .
Page 139 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 140
2. When K = 3,
|Y3|2 ≤ 2h2(∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 + ∣∣∣∣∣Y2 −Y3
h
∣∣∣∣∣2) .
3. When K = N ,
|YN |2 ≤ (N − 1)h2(∣∣∣∣∣Y1 −Y2
h
∣∣∣∣∣2 + ∣∣∣∣∣Y2 −Y3
h
∣∣∣∣∣2 + · · ·+ ∣∣∣∣∣YN−1 −YNh
∣∣∣∣∣2) .
Sum over |Yi |2 from 2 to N, we get
N∑i=2
|Yi |2 ≤N (N − 1)
2h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
Since Y1 = 0, so
N∑i=1
|Yi |2 ≤N (N − 1)
2h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
And then
1(N − 1)2
N∑i=1
|Yi |2 ≤N
2(N − 1)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2 = (12+
12(N − 1)
)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
Since h= 1N−1 , so
h2N∑i=1
|Yi |2 ≤(
12+
12(N − 1)
)h2
N∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
then
hN∑i=1
|Yi |2 ≤(
12+
12(N − 1)
)hN∑i=2
∣∣∣∣∣Yi−1 −Yih
∣∣∣∣∣2.
i.e,
‖Y ‖22,h ≤(
12+
12(N − 1)
)∥∥∥δY ∥∥∥22,h
.
since N ≥ 2, so
‖Y ‖22,h ≤∥∥∥δY ∥∥∥2
2,h.
Hence,
‖Y ‖2,h ≤ C∥∥∥δY ∥∥∥
2,h.
J
Problem A.31. (Sample #12) Discrete maximum principle: Let A = tridiagai ,bi ,cini=1 ∈ Rn×n be atridiagional matrix with the properties that
bi > 0, ai ,ci ≤ 0, ai + bi + ci = 0.
Prove the following maximum principle: If u ∈Rn is such that (Au)i=2,··· ,n−1 ≤ 0, then ui ≤maxu1,un.
Page 140 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 141
Solution. Without loss generality, we assume uk ,k = 2, · · · ,n− 1 is the maximum value.
1. For (Au)i=2,··· ,n−1 < 0:I will use the method of contradiction to prove this case. Since (Au)i=2,··· ,n−1 < 0, so
And ak < 0,ck < 0,uk−1 −uk ≤ 0,uk+1 −uk ≤ 0, so uk−1 = uk = uk+1, that is to say, uk−1 and uk+1 is alsothe maximum points. Bu using the same argument again, we get uk−2 = uk−1 = uk = uk+1 = uk+2.Repeating the process, we get
u1 = u2 = · · ·= un−1 = un.
Therefore, If u ∈Rn is such that (Au)i=2,··· ,n−1 = 0, then ui ≤maxu1,unJ
Problem A.32. (Sample #14) Consider the Crank-Nicolson scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)for approximating the solution to the heat equation ∂u
∂t =∂2u∂x2 on the intervals 0 ≤ x ≤ 1 and 0 ≤ t ≤ t∗ with
the boundary conditions u(0, t) = u(1, t) = 0.
1. Show that the scheme may be written in the form un+1 = Aun, where A ∈Rm×msym (the space of m×m
symmetric matrices) and
‖Ax‖2 ≤ ‖x‖2 ,
for any x ∈Rm, regardless of the value of µ.
2. Show that
‖Ax‖∞ ≤ ‖x‖∞ ,
for any x ∈ Rm, provided µ ≤ 1.(In other words, the scheme may only be conditionally stable in themax norm.)
Page 141 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 142
Solution. 1. the scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)can be rewritten as
−µ
2un+1j−1 + (1+ µ)un+1
j −µ
2un+1j+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
By using the boundary, we have
Cun+1 = Bun
where
C =
1+ µ −µ2−µ2 1+ µ −µ2
. . .. . .
. . .−µ2 1+ µ −µ2
−µ2 1+ µ
,B=
1−µ µ2µ
2 1−µ µ2
. . .. . .
. . .µ2 1−µ µ
2µ2 1−µ
,
un+1 =
un+1
1un+1
2...
un+1m
and un =
un1un2...unm
.
So, the scheme may be written in the form un+1 = Aun, where A = C−1B. By using the Fouriertransform, i.e.
un+1j = g(ξ)unj , unj = eij∆xξ ,
then we have
−µ
2g(ξ)unj−1 + (1+ µ)g(ξ)unj −
µ
2g(ξ)unj+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
And then
−µ
2g(ξ)ei(j−1)∆xξ + (1+ µ)g(ξ)eij∆xξ −
µ
2g(ξ)ei(j+1)∆xξ =
µ
2ei(j−1)∆xξ + (1−µ)eij∆xξ +
µ
2ei(j+1)∆xξ ,
i.e.
g(ξ)(−µ
2e−i∆xξ + (1+ µ)−
µ
2ei∆xξ
)ej∆xξ =
(µ2e−i∆xξ + (1−µ) +
µ
2ei∆xξ
)ej∆xξ ,
i.e.
g(ξ) (1+ µ−µcos(∆xξ)) = 1−µ+ µcos(∆xξ).
therefore,
g(ξ) =1−µ+ µcos(∆xξ)1+ µ−µcos(∆xξ)
.
hence
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
Moreover,∣∣∣g(ξ)∣∣∣ < 1, therefore, ρ(A) < 1.
‖Ax‖2 ≤ ‖A‖2 ‖x‖2 = ρ(A)‖x‖2 ≤ ‖x‖2 .
Page 142 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 143
Problem B.1. (Prelim Jan. 2011#1) Consider a linear system Ax = b with A ∈Rn×n. Richardson’s methodis an iterative method
Mxk+1 = Nxk + b
withM = 1w ,N =M−A= 1
w I−A, where w is a damping factor chosen to make M approximate A as well aspossible. Suppose A is positive definite and w > 0. Let λ1 and λn denote the smallest and largest eigenvalueof A.
1. Prove that Richardson’s method converges if and only if w < 2λn
.
2. Prove that the optimal value of w is w0 =2
λ1+λn.
Solution. 1. Since M = 1w ,N =M −A= 1
w I −A, then we have
xk+1 = (I −wA)xk + bw.
So TR = I − wA, From the sufficient and & necessary condition for convergence, we should haveρ(TR) < 1. Since λi are the eigenvalue of A, then we have 1 − λiw are the eigenvalues of TR. HenceRichardson’s method converges if and only if |1−λiw| < 1, i.e
−1 < 1−λnw < · · · < 1−λ1w < 1,
i.e. w < 2λn
.
2. the minimal attaches at |1−λnw|= |1−λ1w| (Figure. B2), i.e
λnw − 1 = 1−λ1w,
i,e
w0 =2
λ1 +λn.
J
woptw
1
1λ1
|1−λ1|
1λn
|1−λn|
Figure B2: The curve of ρ(TR) as a function of w
Page 148 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 149
Problem B.2. (Prelim Jan. 2011#2) Let A ∈ Cm×n and b ∈ Cm. Prove that the vector x ∈ Cn is a leastsquares solution of Ax = b if and only if r⊥range(A), where r = b −Ax.
Solution. We already know, x ∈ Cn is a least squares solution of Ax = b if and only if
Therefore, r⊥range(A). The above way is invertible, hence we prove the result. J
Problem B.3. (Prelim Jan. 2011#3) Suppose A,B ∈ Rn×n and A is non-singular and B is singular. Provethat
1κ(A)
≤ ‖A−B‖‖A‖
,
where κ(A) = ‖A‖ ·∥∥∥A−1
∥∥∥, and ‖·‖ is an reduced matrix norm.
Solution. Since B is singular, then there exists a vector x , 0, s.t. Bx = 0. Since A is non-singular, thenA−1 is also non-singular. Moreover, A−1Bx = 0. Then, we have
x = x −A−1Bx = (I −A−1B)x.
So
‖x‖=∥∥∥(I −A−1B)x
∥∥∥ ≤ ∥∥∥A−1A−A−1B∥∥∥‖x‖ ≤ ∥∥∥A−1
∥∥∥‖A−B‖‖x‖ .Since x , 0, so
1 ≤∥∥∥A−1
∥∥∥‖A−B‖ .1∥∥∥A−1∥∥∥‖A‖ ≤ ‖A−B‖‖A‖
,
i.e.
1κ(A)
≤ ‖A−B‖‖A‖
.
J
Problem B.4. (Prelim Jan. 2011#4) Let f : Ω ⊂ Rn → Rn be twice continuously differentiable. Supposex∗ ∈Ω is a solution of f (x) = 0, and the Jacobian matrix of f, denoted Jf , is invertible at x∗.
1. Prove that if x0 ∈Ω is sufficiently close to x∗, then the following iteration converges to x∗:
xk+1 = xk − Jf (x0)−1f (xk).
2. Prove that the convergence is typically only linear.
Page 149 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 150
Solution. Let x∗ be the root of f(x) i.e. f(x∗)=0. From the Newton’s scheme, we havexk+1 = xk −[J(x0)
]−1f(xk)
x∗ = x∗
Therefore, we have
x∗ − xk+1 = x∗ − xk +[J(x0)
]−1(f(xk)− f(x∗))
= x∗ − xk −[J(x0)
]−1J(ξ)(x∗ − xk).
therefore ∣∣∣x∗ − xk+1∣∣∣ ≤ ∣∣∣∣∣1− J(ξ)
J(x0)
∣∣∣∣∣ ∣∣∣x∗ − xk∣∣∣
From theorem
Theorem B.1. Suppose J : Rm → Rn×n is a continuous matrix-valued function. If J(x*) is nonsingular, thenthere exists δ > 0 such that, for all x ∈ Rm with ‖x − x∗‖ < δ, J(x) is nonsingular and∥∥∥J(x)−1
∥∥∥ < 2∥∥∥J(x∗)−1
∥∥∥ .
we get ∣∣∣x∗ − xk+1∣∣∣ ≤ 1
2
∣∣∣x∗ − xk∣∣∣ .
Which also shows the convergence is typically only linear.J
Problem B.5. (Prelim Jan. 2011#5) Consider
y′(t) = f (t,y(t)), t ≥ t0,y(t0) = y0,
where f : [t0, t∗]×R→R is continuous in its first variable and Lipschitz continuous in its second variable.Prove that Euler’s method converges.
Therefore, Forward Euler Method is order of 1 .From (219), we get
y(tn+1) = y(tn) + hf (tn,y(tn)) +O(h2), (220)
Page 150 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 151
Subtracting (220) from (218), we get
en+1 = en+ h[f (tn,yn)− f (tn,y(tn))] + ch2.
Since f is lipschitz continuous w.r.t. the second variable, then
|f (tn,yn)− f (tn,y(tn))| ≤ λ|yn − y(tn)|, λ > 0.
Therefore, ∥∥∥en+1
∥∥∥ ≤ ‖en‖+ hλ‖en‖+ ch2
= (1+ hλ)‖en‖+ ch2.
Claim:[2]
‖en‖ ≤cλh[(1+ hλ)n − 1],n= 0,1, · · ·
Proof for Claim (221): The proof is by induction on n.
1. when n= 0, en = 0, hence ‖en‖ ≤ cλh[(1+ hλ)n − 1],
2. Induction assumption:
‖en‖ ≤cλh[(1+ hλ)n − 1]
3. Induction steps: ∥∥∥en+1
∥∥∥ ≤ (1+ hλ)‖en‖+ ch2
≤ (1+ hλ)cλh[(1+ hλ)n − 1] + ch2
=cλh[(1+ hλ)n+1 − 1].
So, from the claim (221), we get ‖en‖ → 0, when h→ 0. Therefore Forward Euler Method is convergent. J
Problem B.6. (Prelim Jan. 2011#6) Consider the scheme
yn+2 + yn+1 − 2yn = h (f (tn+2,yn+2) + f (tn+1,yn+1) + f (tn,yn))
for approximating the solution to
y′(t) = f (t,y(t)), t ≥ t0,y(t0) = y0,
what’s the order of the scheme? Is it a convergent scheme? Is it A-stable? Justify your answers.
Solution. For our this problem
ρ(w) :=s∑
m=0
amwm = −2+w+w2 and σ (w) :=
s∑m=0
bmwm = 1+w+w2. (221)
By making the substitution with ξ = w − 1 i.e. w = ξ + 1, then
ρ(w) :=s∑
m=0
amwm = ξ2 + 3ξ and σ (w) :=
s∑m=0
bmwm = ξ2 + 3ξ + 3. (222)
Page 151 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 152
So,
ρ(w)− σ (w)ln(w) = ξ2 + 3ξ − (3+ 3ξ + ξ2)(ξ − ξ2
2+ξ3
3· · · )
=
+3ξ +ξ2
−3ξ −3ξ2 −ξ3
+ 32ξ
2 + 32ξ
3 + 12ξ
4
−ξ3 −ξ4 −13ξ
5
= −12ξ2 +O(ξ3).
Therefore, by the theorem
ρ(w)− σ (w)ln(w) = −12ξ2 +O(ξ3).
Hence, this scheme is order of 1. Since,
ρ(w) :=s∑
m=0
amwm = −2+w+w2 = (w+ 2)(w − 1). (223)
And w = −1 or w = −2 which does not satisfy the root condition. Therefore, this scheme is not stable.Hence, it is also not A-stable. J
Problem B.7. (Prelim Jan. 2011#7) Consider the Crank-Nicholson scheme applied to the diffusion equa-tion
∂u∂t
=∂2u
∂x2
where t > 0,−∞ < x <∞.
1. Show that the amplification factor in the Von Neumann analysis of the scheme us
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
2. Use the results of part 1 to show that the scheme is stable.
Solution. 1. The Crank-Nicholson scheme for the diffusion equation is
un+1j −unj∆t
=12
un+1j−1 − 2un+1
j + un+1j+1
∆x2 +unj−1 − 2unj + u
nj+1
∆x2
Let µ= ∆t
∆x2 , then the scheme can be rewrote as
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
),
i.e.
−µ
2un+1j−1 + (1+ µ)un+1
j −µ
2un+1j+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
By using the Fourier transform, i.e.
un+1j = g(ξ)unj , unj = eij∆xξ ,
Page 152 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 153
then we have
−µ
2g(ξ)unj−1 + (1+ µ)g(ξ)unj −
µ
2g(ξ)unj+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
And then
−µ
2g(ξ)ei(j−1)∆xξ + (1+ µ)g(ξ)eij∆xξ −
µ
2g(ξ)ei(j+1)∆xξ =
µ
2ei(j−1)∆xξ + (1−µ)eij∆xξ +
µ
2ei(j+1)∆xξ ,
i.e.
g(ξ)(−µ
2e−i∆xξ + (1+ µ)−
µ
2ei∆xξ
)ej∆xξ =
(µ2e−i∆xξ + (1−µ) +
µ
2ei∆xξ
)ej∆xξ ,
i.e.
g(ξ) (1+ µ−µcos(∆xξ)) = 1−µ+ µcos(∆xξ).
therefore,
g(ξ) =1−µ+ µcos(∆xξ)1+ µ−µcos(∆xξ)
.
hence
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
2. since z = 2 ∆t∆x2 (cos(∆xξ)− 1), then z < 0, then we have
1+12z < 1− 1
2z,
therefore g(ξ) < 1. Since −1 < 1, then
12z − 1 <
12z+ 1.
Therefore,
g(ξ) =1+ 1
2z
1− 12z
> −1.
hence∣∣∣g(ξ)∣∣∣ < 1. So, the scheme is stable.
J
Page 153 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 154
Problem B.8. (Prelim Jan. 2011#8) Consider the explicit scheme
un+1j = unj + µ
(unj−1 − 2unj + u
nj+1
)−bµ∆x
2
(unj+1 −u
nj−1
),0 ≤ n ≤N ,1 ≤ j ≤ L.
for the convention-diffusion problem∂u∂t =
∂2u∂x2 − b ∂u∂x for 0 ≤ x ≤ 1, 0 ≤ t ≤ t∗
u(0, t) = u(1, t) = 0 for 0 ≤ t ≤ t∗
u(x,0) = g(x) for 0 ≤ x ≤ 1,
where b > 0, µ = ∆t(∆x)2 ,∆x = 1
L+1 , and ∆t = t∗N . Prove that, under suitable restrictions on µ and ∆x, the
error grid function en satisfy the estimate
‖en‖∞ ≤ t∗C(∆t+∆x2
),
for all n such that n∆t ≤ t∗, where C > 0 is a constant.
Solution. Let u be the exact solution and unj = u(n∆t, j∆x). Then from Taylor Expansion, we have
un+1j = unj +∆t
∂∂tunj +
12(∆t)2 ∂
2
∂t2u(ξ1, j∆x), tn ≤ ξ1 ≤ tn+1,
unj−1 = unj −∆x∂∂xunj +
12(∆x)2 ∂
2
∂x2 unj −
16(∆x)3 ∂
3
∂x3 unj +
124
(∆x)4 ∂4
∂x4 u(n∆t,ξ2), xj−1 ≤ ξ2 ≤ xj ,
unj+1 = unj +∆x∂∂xunj +
12(∆x)2 ∂
2
∂x2 unj +
16(∆x)3 ∂
3
∂x3 unj +
124
(∆x)4 ∂4
∂x4 u(n∆t,ξ3), xj ≤ ξ3 ≤ xj+1.
Then the truncation error T of this scheme is
T =un+1j − unj∆t
−unj−1 − 2unj + u
nj+1
∆x2 + bunj+1 − u
nj−1
∆x= O(∆t+ (∆x)2).
Therefore
en+1j = enj + µ
(enj−1 − 2enj + e
nj+1
)−bµ∆x
2
(enj+1 − e
nj−1
)+ c∆t(∆t+ (∆x)2),
i.e.
en+1j =
(µ+
bµ∆x
2
)enj−1 + (1− 2µ)enj +
(µ−
bµ∆x
2
)enj+1 + c∆t(∆t+ (∆x)2).
Then ∣∣∣∣en+1j
∣∣∣∣ ≤ ∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣ ∣∣∣∣enj−1
∣∣∣∣+ ∣∣∣(1− 2µ)∣∣∣ ∣∣∣∣enj ∣∣∣∣+ ∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣ ∣∣∣∣enj+1
∣∣∣∣+ c∆t(∆t+ (∆x)2).
Therefore∥∥∥∥en+1j
∥∥∥∥∞ ≤∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣∥∥∥∥enj−1
∥∥∥∥∞+∣∣∣(1− 2µ)
∣∣∣∥∥∥∥enj ∥∥∥∥∞+
∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣∥∥∥∥enj+1
∥∥∥∥∞+ c∆t(∆t+ (∆x)2).
∥∥∥en+1∥∥∥∞ ≤ ∣∣∣∣∣µ+ bµ∆x
2
∣∣∣∣∣‖en‖∞+∣∣∣(1− 2µ)
∣∣∣‖en‖∞+
∣∣∣∣∣µ− bµ∆x2
∣∣∣∣∣‖en‖∞+ c∆t(∆t+ (∆x)2).
Page 154 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 155
If 1− 2µ ≥ 0 and µ− bµ∆x2 ≥ 0, i.e. µ ≤ 12 and 1− 1
2b∆x > 0, then∥∥∥en+1∥∥∥∞ ≤
(µ+
bµ∆x
2
)‖en‖∞+ ((1− 2µ))‖en‖∞+
(µ−
bµ∆x
2
)‖en‖∞+ c∆t(∆t+ (∆x)2)
= ‖en‖∞+ c∆t(∆t+ (∆x)2).
Then
‖en‖∞ ≤∥∥∥en−1
∥∥∥∞+ c∆t(∆t+ (∆x)2)
≤∥∥∥en−2
∥∥∥∞+ c2∆t(∆t+ (∆x)2)
≤...
≤∥∥∥e0
∥∥∥∞+ cn∆t(∆t+ (∆x)2)
= ct∗(∆t+ (∆x)2).
J
B.2 Numerical Mathematics Preliminary Examination Aug. 2010
Problem B.9. (Prelim Aug. 2010#1) Prove that A ∈ Cm×n(m > n) and let A = QR be a reduced QRfactorization.
1. Prove that A has rank n if and only if all the diagonal entries of R are non-zero.
2. Suppose rank(A) = n, and define P = QQ∗. Prove that range(P ) = range(A).
3. What type of matrix is P?
Solution. 1. From the properties of reduced QR factorization, we know that Q has orthonormal columns,therefore det(Q) = 1 and R is upper triangular matrix, so det(R) =
∏ni=1 rii . Then
det(A) = det(QR) = det(Q)det(R) =n∏i=1
rii .
Therefore, A has rank n if and only if all the diagonal entries of R are non-zero.2. (a) range(A) ⊆ range(P ): Let y ∈ range(A), that is to say there exists a x ∈ Cn s.t. Ax = y. Then by
reduced QR factorization we have y = QRx. then
P y = P QRx = QQ∗QRx = QRx = Ax = y.
therefore y ∈ range(P ).(b) range(P ) ⊆ range(A): Let v ∈ range(P ), that is to say there exists a v ∈ Cn, s.t. v = P v = QQ∗v.
Claim B.1.
QQ∗ = A (A∗A)−1A∗.
Proof.
A (A∗A)−1A∗ = QR(R∗Q∗QR
)−1R∗Q∗
= QR(R∗R
)−1R∗Q∗
= QRR−1(R∗
)−1R∗Q∗
= QQ∗.
Page 155 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 156
J
Therefore by the claim, we have
v = P v = QQ∗v = A (A∗A)−1A∗v = A((A∗A)−1A∗v
)= Ax.
where x = (A∗A)−1A∗v. Hence v ∈ range(A).
3. P is an orthogonal projector.J
Problem B.10. (Prelim Aug. 2010#4) Prove that A ∈Rn×n is SPD if and only if it has a Cholesky factor-ization.
Solution. 1. Since A is SPD, so it has LU factorization, and L= U , i.e.
A= LU = UTU .
Therefore, it has a Cholesky factorization.
2. if A has Cholesky factorization, i.e A= UTU , then
xTAx = xTUTUx = (Ux)TUx.
Let y = Ux, then we have
xTAx = (Ux)TUx = yT y = y21 + y2
2 + · · ·+ y2n ≥ 0,
with equality only when y = 0, i.e. x=0 (since U is non-singular). Hence A is SPD.J
Problem B.11. (Prelim Aug. 2010#8) Consider the Crank-Nicolson scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)for approximating the solution to the heat equation ∂u
∂t =∂2u∂x2 on the intervals 0 ≤ x ≤ 1 and 0 ≤ t ≤ t∗ with
the boundary conditions u(0, t) = u(1, t) = 0.
1. Show that the scheme may be written in the form un+1 = Aun, where A ∈Rm×msym (the space of m×m
symmetric matrices) and
‖Ax‖2 ≤ ‖x‖2 ,
for any x ∈Rm, regardless of the value of µ.
2. Show that
‖Ax‖∞ ≤ ‖x‖∞ ,
for any x ∈ Rm, provided µ ≤ 1.(In other words, the scheme may only be conditionally stable in themax norm.)
Page 156 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 157
Solution. 1. the scheme
un+1j = unj +
µ
2
(un+1j−1 − 2un+1
j + un+1j+1 + unj−1 − 2unj + u
nj+1
)can be rewritten as
−µ
2un+1j−1 + (1+ µ)un+1
j −µ
2un+1j+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
By using the boundary, we have
Cun+1 = Bun
where
C =
1+ µ −µ2−µ2 1+ µ −µ2
. . .. . .
. . .−µ2 1+ µ −µ2
−µ2 1+ µ
,B=
1−µ µ2µ
2 1−µ µ2
. . .. . .
. . .µ2 1−µ µ
2µ2 1−µ
,
un+1 =
un+1
1un+1
2...
un+1m
and un =
un1un2...unm
.
So, the scheme may be written in the form un+1 = Aun, where A = C−1B. By using the Fouriertransform, i.e.
un+1j = g(ξ)unj , unj = eij∆xξ ,
then we have
−µ
2g(ξ)unj−1 + (1+ µ)g(ξ)unj −
µ
2g(ξ)unj+1 =
µ
2unj−1 + (1−µ)unj +
µ
2unj+1.
And then
−µ
2g(ξ)ei(j−1)∆xξ + (1+ µ)g(ξ)eij∆xξ −
µ
2g(ξ)ei(j+1)∆xξ =
µ
2ei(j−1)∆xξ + (1−µ)eij∆xξ +
µ
2ei(j+1)∆xξ ,
i.e.
g(ξ)(−µ
2e−i∆xξ + (1+ µ)−
µ
2ei∆xξ
)ej∆xξ =
(µ2e−i∆xξ + (1−µ) +
µ
2ei∆xξ
)ej∆xξ ,
i.e.
g(ξ) (1+ µ−µcos(∆xξ)) = 1−µ+ µcos(∆xξ).
therefore,
g(ξ) =1−µ+ µcos(∆xξ)1+ µ−µcos(∆xξ)
.
hence
g(ξ) =1+ 1
2z
1− 12z
,z = 2∆t
∆x2 (cos(∆xξ)− 1).
Moreover,∣∣∣g(ξ)∣∣∣ < 1, therefore, ρ(A) < 1.
‖Ax‖2 ≤ ‖A‖2 ‖x‖2 = ρ(A)‖x‖2 ≤ ‖x‖2 .
Page 157 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 158
Problem B.13. (Prelim Jan. 2008#8) Let Ω ⊂R2 be a bounded domain with a smooth boundary. Considera 2-D poisson-like equation −∆u+ 3u = x2y2, in Ω,
u = 0, on ∂Ω.
1. Write the corresponding Ritz and Galerkin variational problems.
2. Prove that the Galerkin method has a unique solution uh and the following estimate is valid
‖u −uh‖H1 ≤ C infvh∈Vh
‖u − vh‖H1 ,
with C independent of h, where Vh denotes a finite element subspace of H1(Ω) consisting of contin-uous piecewise polynomials of degree k ≥ 1.
Solution. 1. For this pure Dirichlet Problem, the test functional space v ∈ H10 . Multiple the test func-
tion on the both sides of the original function and integral on Ω, we get
−∫Ω
∆uvdx+
∫Ω
uvdx =
∫Ω
xyvdx.
Integration by part yields ∫Ω
∇u∇vdx+∫Ω
uvdx =
∫Ω
xyvdx.
Let
a(u,v) =∫Ω
∇u∇vdx+∫Ω
uvdx, f (v) =∫Ω
xyvdx.
Then, the(a) Ritz variational problem is: find uh ∈H1
0 , such that
J(uh) = min12a(uh,uh)− f (uh).
(b) Galerkin variational problem is: find uh ∈H10 , such that
a(uh,uh) = f (uh).
2. Next, we will use Lax-Milgram to prove the uniqueness.(a) ∣∣∣a(u,v)
∣∣∣ ≤ ∫Ω
|∇u∇v|dx+∫Ω
|uv|dx
≤ ‖∇u‖L2(Ω) ‖∇v‖L2(Ω) + ‖u‖L2(Ω) ‖v‖L2(Ω)
≤ ‖∇u‖L2(Ω) ‖∇v‖L2(Ω) +C ‖∇u‖L2(Ω) ‖∇v‖L2(Ω)
≤ C ‖∇u‖L2(Ω) ‖∇v‖L2(Ω)
≤ C ‖u‖H1(Ω) ‖v‖H1(Ω)
Page 160 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 161
(b)
a(u,u) =
∫Ω
(∇u)2dx+
∫Ω
u2dx
So, ∣∣∣a(u,u)∣∣∣ =
∫Ω
|∇u|2 dx+∫Ω
|u|2 dx
= ‖∇u‖2L2(Ω)+ ‖u‖2L2(Ω)
= ‖u‖2H1(Ω).
(c) ∣∣∣f (v)∣∣∣ ≤ ∫Ω
∣∣∣xyv∣∣∣dx≤ max |xy|
∫Ω
|v|dx
≤ C
(∫Ω
12dx
)1/2 (∫Ω
|v|2 dx)1/2
≤ C ‖v‖L2(Ω) ≤ C ‖v‖H1(Ω) .
by Lax-Milgram theorem, we get that e Galerkin method has a unique solution uh. Moreover,
a(vh,vh) = f (vh).
And from the weak formula, we have
a(u,vh) = f (vh).
then we get the Galerkin Orthogonal (GO)
a(u −uh,vh) = 0.
Then by coercivity
‖u −uh‖2H1(Ω)≤
∣∣∣a(u −uh,u −uh)∣∣∣
=∣∣∣a(u −uh,u − vh) + a(u −uh,vh −uh)
∣∣∣=
∣∣∣a(u −uh,u − vh)∣∣∣
≤ ‖u −uh‖H1(Ω) ‖u − vh‖H1(Ω) .
Therefore,
‖u −uh‖H1 ≤ C infvh∈Vh
‖u − vh‖H1 ,
J
C Project 1 MATH571
Page 161 of 236
COMPUTATIONAL ASSIGNMENT # 1
MATH 571
1. Instability of Gram–Schmidt
The purpose of the first part of your assignment is to investigate the instability of theclassical Gram–Schmidt orthogonalization process. Lecture 9 in BT is somewhat related tothis and could be a good source of inspiration.
1.– Write a piece of code that implements the classical Gram–Schmidt process, see Algo-rithm 7.1 in BT. Ideally, this should be implemented in the form of a QR factorization,that is, given a matrix A ∈ Rm×n your method should return two matrices Q ∈ Rm×n
and R ∈ Rn×n, where the matrix Q has (or at least should have) orthonormal columnsand A = QR.
2.– With the help of the developed piece of code, test the algorithm on a matrix A = R20×10
with:• entries uniformly distributed over the interval [0, 1].• entries given by
ai,j =
(2i− 21
19
)j−1
.
• entries given by
ai,j =1
i + j − 1,
this is the so-called Hilbert matrix.3.– For each one of these cases compute Q?Q. Since Q, in theory, has orthonormal columns
what should you get? What do you actually get?4.– Implement the modified Gram-Schmidt process (Algorithm 8.1 in BT) and repeat steps
1.—3. What do you observe?
2. Linear Least Squares
The purpose of the second part of your assignment is to observe the so-called Runge’sphenomenon and try to mitigate it using least squares. Lecture 11 on BT might give somehints on how to proceed. Consider the function
f(x) =1
1 + 25x2,
on the interval [−1, 1]. Do the following:
1.– Choose N ∈ N (not too large ≈ 10 should suffice) and on an equally spaced grid of pointsconstruct a polynomial that interpolates f . In other words, given the grid of points
xi = −1 +2i
N, i = 0, N,
Date: Due October 16, 2013.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 162
Page 162 of 236
you must find a polynomial pN of degree N such that
pN(xi) = f(xi), i = 0, N.
2.– Even though f and pN coincide at the nodes, how do they compare on the whole interval?You can, for instance plot them or look at their values on a grid that consists of 2Npoints.
3.– We are going to, instead of interpolating, construct a least squares fit for f . In otherwords, we choose n ∈ N, n < N , and construct a polynomial qn of degree n such that
N∑
i=0
|qn(xi)− f(xi)|2
is minimal.4.– If our least squares polynomial is defined as qn(x) =
∑nj=0 Qjx
j, then the minimalityconditions lead to the overdetermined system
(1) Aq = y, Ai,j = xj−1i , Qj = Qj, yi = f(xi),
which, since all the points xi are different has full rank (Can you prove this? ). Thismeans that the least squares solution can be found, for instance, using the QR algorithmwhich you developed on the first part of the assignment. This gives you the coefficientsof the polynomial.
5.– How does qn and f compare? Keeping N fixed, vary n and try to find an empiricalrelation for the n (in terms of N) which optimizes the least squares fit.
Remark. Equation (1) is also the system of equations you obtain when trying to computethe interpolating polynomial of point 1.–. In this case, however, the system will be square.You can still use the QR algorithm to solve this system.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 163
Page 163 of 236
MATH 571: Coding Assignment #1Due on Wednesday, October 16, 2013
TTH 12:40pm
Wenqiang Feng
1
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 164
Page 164 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1
Contents
Problem 1 3
Problem 2 5
Page 2 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 165
Page 165 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1
Problem 1
1. See Listing 3.
2. See Listing 2.
3. We should get the Identity square matrices. But we did not get the actual Identity square matrices
through the Gram-Schmidt Algorithm. For case 1-2, we only get the matrices which diag(Q∗Q) =
n︷ ︸︸ ︷
1, · · · , 1 and the other elements approximate to 0 in the sense of C × 10−16 ∼ 10−17. For case 3,
Classical Gram-Schmidt Algorithm is not stable for case 3, since some elements of matrix Q∗Q do not
approximate to 0, then the matrix Q∗Q is not diagonal any more.
4. For case 1-2, we also did not get the actual Identity square matrices by using the Modified Gram-
Schmidt Algorithm. We only get the matrices which diag(Q∗Q) = n︷ ︸︸ ︷
1, · · · , 1 and the other elements
approximate to 0 in the sense of C × 10−17 ∼ 10−18. For case 3, the Modified Gram-Schmidt Algo-
rithm works well for case 3, we get the matrix which diag(Q∗Q) = n︷ ︸︸ ︷
1, · · · , 1 and the other elements
approximate to 0 in the sense of C × 10−8 ∼ 10−13. So, Modified Gram-Schmidt Algorithm is more
stable than the Classical one.
Listing 1 shows the main function for problem1.
Listing 1: Main Function of Problem1
%Main function
clc
clear all
m=20;n=10;
5 fun1=@(i,j) ((2*i-21)/19)ˆ(j-1);
fun2=@(i,j) 1/(i+j);
A1=rand(m,n);
A2=matrix_gen(m,n,fun1);
A3=matrix_gen(m,n,fun2);
10 % Test for the random case 1
[CQ1,CR1]=gschmidt(A1)
[MQ1,MR1]=mgschmidt(A1)
q11=CQ1’*CQ1
q12=MQ1’*MQ1
15 % Test for case 2
[CQ2,CR2]=gschmidt(A2)
[MQ2,MR2]=mgschmidt(A2)
q21=CQ2’*CQ2
q22=MQ2’*MQ2
20 % Test for case 3
[CQ3,CR3]=gschmidt(A3)
[MQ3,MR3]=mgschmidt(A3)
q31=CQ3’*CQ3
q32=MQ3’*MQ3
Listing 2 shows the matrices generating function.
Problem 1 continued on next page. . . Page 3 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 166
Page 166 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 1 (continued)
Table 1: The L2 norm of the Least squares polynomial fit
Fix N = 10, vary n( Figure 2-Figure 11).
Listing 5 shows main function of problem2.1.
Listing 5: Main Function of Problem2.1
% Main function of A2
clc
clear all
N=10;
5 n=N;
fun= @(x) 1./(1+25*x.ˆ2);
x=-1:2/N:1;
y=fun(x);
10 x1=-1:2/(2*N):1;
a = polyfit(x,y,n);
p = polyval(a,x1)
plot(x,y,’o’,x1,p,’-’)
15 for m=1:10
least_squares(x, y, m)
end
Listing 6 shows Polynomial Least Squares Fitting Algorithm.
Listing 6: Polynomial Least Squares Fitting Algorithm
%Main function for pro#2.5
clc
clear all
for N=3:15
5 j=1;
for n=1:N%3:N;
fun= @(x) 1./(1+25*x.ˆ2);
Problem 2 continued on next page. . . Page 6 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 169
Page 169 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2 (continued)
x=-1:2/N:1;
b=fun(x);
10
A=MatrixGen(x,n);
cof=GSsolver(A,b);
q=0;
for i=1:n+1
15 q=q+cof(i)*(x.ˆ(i-1));
end
error(j)=norm(q-b);
j=j+1;
error
20 end
end
function A=MatrixGen(x,n)
25 m=size(x,2);
A=zeros(m,n+1);
for i=1:m
for j=1:n+1
A(i,j)=x(i).ˆ(j-1);
30 end
end
function x=GSsolver(A,b)
35 [Q,R]=mgschmidt(A);
x= R\(Q’*b’);
Page 7 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 170
Page 170 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 1: Runge’s phenomenon of Polynomial interpolation with 2N points.
Figure 2: Least Square polynomial of degree=1, N=10.
Page 8 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 171
Page 171 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 3: Least Square polynomial of degree=2, N=10.
Figure 4: Least Square polynomial of degree=3, N=10.
Page 9 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 172
Page 172 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 5: Least Square polynomial of degree=4, N=10.
Figure 6: Least Square polynomial of degree=5, N=10.
Page 10 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 173
Page 173 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 7: Least Square polynomial of degree=6, N=10.
Figure 8: Least Square polynomial of degree=7, N=10.
Page 11 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 174
Page 174 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 9: Least Square polynomial of degree=8, N=10.
Figure 10: Least Square polynomial of degree=9, N=10.
Page 12 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 175
Page 175 of 236
Wenqiang Feng MATH 571 ( TTH 12:40pm): Coding Assignment #1 Problem 2
Figure 11: Least Square polynomial of degree=10, N=10.
Page 13 of 13
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 176
Page 176 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 177
D Project 2 MATH571
Page 177 of 236
COMPUTATIONAL ASSIGNMENT # 2
MATH 571
1. Convergence of Classical Schemes
The purpose of this part of your assignment is to investigate the convergence properties of classical iterativeschemes. To do so, develop:
1. A piece of code [x,K] = Jacobi(M,f, ε) that implements the Jacobi method.2. A piece of code [x,K] = SOR(M,f, ω, ε) that implements the SOR method. Notice that the number ω
should be an input parameter1.
Your implementations should take as input a square matrix M ∈ RN×N , a right hand side vector f ∈ RN
and a tolerance ε > 0. The output should be a vector x ∈ RN — an approximate solution to Mx = f andan integer K — the number of iterations.2
For n ∈ N set N = 2n− 1 and consider the following matrices:
• The nonsymmetric matrix A ∈ RN×N :
Ai,i = 3, i = 1, N, Ai,i+1 = −1, i = 1, N − 1, Ai,i−n = −1, i = n+ 1, N.
• The tridiagonal matrix J ∈ RN×N :
J1,1 = 1 = −J1,2, Ji,i = 2 +1
N2, Ji,i+1 = Ji,i−1 = −1, i = 2, N − 1, JN,N = 1 = −JN,N−1.
• The tridiagonal matrix S ∈ RN×N :
Si,i = 3, i = 1, N, Si,i+1 = −1, i = 1, N − 1, Si,i−1 = −1, i = 2, N.
For different values of n ∈ 2, . . . , 50 and for each M ∈ A, J, S, choose a vector x ∈ RN and definefM = Mx.
i) Run Jacobi(M,fM , ε) and record the number of iterations. How does the number of iterations dependon N?
ii) Run SOR(M,fM , 1, ε). How does the number of iterations depend on N?iii) Try to find the optimal value of ω, that is the one for which the number of iterations is minimal.iv) How does the number of iterations between Jacobi(M,fM , ε), SOR(M,fM , 1, ε) and SOR(M,fM , ω) with
an optimal ω compare? What can you conclude?
2. The Method of Alternating Directions
In this section we will study the Alternating Directions Implicit (ADI) method. Given A ∈ RN×N ,A = A? > 0 and f ∈ RN we wish to solve Ax = f . Assume that we have the following splitting of the matrixA:
A = A1 +A2, Ai = A?i > 0, i = 1, 2, A1A2 = A2A1.
Date: Due November 26, 2013.1Recall that for ω = 1 we obtain the Gauß–Seidel method so you obtain two methods for one here ;-)2As stopping criterion you can use either
‖xk+1 − xk‖ < ε,
or, since we are just trying to learn,
‖xk+1 − x‖ < ε,
where x is the exact solution.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 178
Page 178 of 236
Then, we propose the following scheme
(I + τA1)xk+1/2 − xk
τ+Axk = f,(1)
(I + τA2)xk+1 − xk+1/2
τ+Axk+1/2 = f.(2)
1. Write a piece of code [x,K] = ADI(A, f, ε, A1, A2, τ) that implements the ADI scheme described above.As before, the input should be a matrix A ∈ RN , a right hand side f ∈ RN and a tolerance ε > 0. Inaddition, the scheme should take parameters A1, A2 ∈ RN and τ > 0.
Notice that, in general, we need to invert (I+ τAi). In practice these matrices are chosen so that theseinversions are easy.
2. Let n ∈ 4, . . . , 50 and set N = n2. Define the matrices Λ,Σ ∈ RN×N as follows:
for i = 1, nfor j = 1, nI = i+ n(j − 1);Λ[I, I] = Σ[I, I] = 3;if i < n
Λ[I, I + 1] = −1;endif
if i > 1Λ[I, I − 1] = −1;
endif
if j < nΣ[I, I + n] = −1;
endif
if j > 1Σ[I, I − n] = −1;
endif
endfor
endfor
3. Set A = Λ + Σ.4. Are the matrices Λ and Σ SPD? Do they commute?5. Choose x ∈ RN and set f = Ax. Run ADI(A, f, ε,Λ,Σ, τ) for different values of τ . Which one seems to
be the optimal one?The following are not obligatory but can be used as extra credit:
6. Write an expression for xk+1 in terms of xk only. Hint: Try adding and subtracting (1) and (2). Whatdo you get?
7. From this expression find the equation that controls the error ek = x− xk.8. Assume that (A1A2x, x) ≥ 0, show that in this case [x, y] = (A1A2x, y) is an inner product. If that is the
case we will denote ‖x‖B = [x, x]1/2.9. Under this assumption we will show convergence of the ADI scheme. To do so:
• Take the inner product of the equation that controls the error with ek+1 + ek.• Add over k = 1,K. We should obtain
And ak < 0, ck < 0, uk−1 − uk ≤ 0, uk+1 − uk ≤ 0, so uk−1 = uk = uk+1, that is to say, uk−1 and uk+1
is also the maximum points. Bu using the same argument again, we get uk−2 = uk−1 = uk = uk+1 =
uk+2. Repeating the process, we get
u1 = u2 = · · · = un−1 = un.
Therefore, If u ∈ Rn is such that (Au)i=2,··· ,n−1 = 0, then ui ≤ maxu1, un
Problem 3
Prove the following discrete Poincare inequality: Let Ω = (0, 1) and Ωh be a uniform grid of size h. If Y ∈ Uhis a mesh function on Ωh such that Y (0) = 0, then there is a constant C, independent of Y and h, for which
‖Y ‖2,h ≤ C∥∥δY
∥∥2,h
.
Proof: I consider the following uniform partition (Figure. 2) of the interval (0, 1) with N points.
Page 4 of 6
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 193
Page 193 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Exam problem 4-5 Problem 3
x1 = 0 x2 xN−1 xN = 1
Figure 2: One dimension’s uniform partition
Since the discrete 2-norm is defined as follows
‖v‖22,h = hdN∑
i=1
|vi|2,
where d is dimension. So, we have
‖v‖22,h = h
N∑
i=1
|vi|2,∥∥δv∥∥22,h
= h
N∑
i=2
∣∣∣∣vi−1 − vi
h
∣∣∣∣2
.
Since Y (0) = 0, i.e. Y1 = 0,
N∑
i=2
Yi−1 − Yi = Y1 − YN = −YN .
Then,
∣∣∣∣∣N∑
i=2
Yi−1 − Yi∣∣∣∣∣ = |YN |.
and
|YN | ≤N∑
i=2
|Yi−1 − Yi| =N∑
i=2
h
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣ ≤(
N∑
i=2
h2
)1/2( N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2)1/2
.
Therefore
|YK |2 ≤(
K∑
i=2
h2
)(K∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2)
= h2(K − 1)K∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
1. When K = 2,
|Y2|2 ≤ h2∣∣∣∣Y1 − Y2
h
∣∣∣∣2
.
2. When K = 3,
|Y3|2 ≤ 2h2
(∣∣∣∣Y1 − Y2
h
∣∣∣∣2
+
∣∣∣∣Y2 − Y3
h
∣∣∣∣2).
3. When K = N ,
|YN |2 ≤ (N − 1)h2
(∣∣∣∣Y1 − Y2
h
∣∣∣∣2
+
∣∣∣∣Y2 − Y3
h
∣∣∣∣2
+ · · ·+∣∣∣∣YN−1 − YN
h
∣∣∣∣2).
Page 5 of 6
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 194
Page 194 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Exam problem 4-5 Problem 3
Sum over |Yi|2 from 2 to N, we get
N∑
i=2
|Yi|2 ≤N(N − 1)
2h2
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
Since Y1 = 0, so
N∑
i=1
|Yi|2 ≤N(N − 1)
2h2
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
And then
1
(N − 1)2
N∑
i=1
|Yi|2 ≤N
2(N − 1)h2
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
=
(1
2+
1
2(N − 1)
)h2
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
Since h = 1N−1 , so
h2N∑
i=1
|Yi|2 ≤(
1
2+
1
2(N − 1)
)h2
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
then
hN∑
i=1
|Yi|2 ≤(
1
2+
1
2(N − 1)
)h
N∑
i=2
∣∣∣∣Yi−1 − Yi
h
∣∣∣∣2
.
i.e,
‖Y ‖22,h ≤(
1
2+
1
2(N − 1)
)∥∥δY∥∥22,h
.
since N ≥ 2, so
‖Y ‖22,h ≤∥∥δY
∥∥22,h
.
Hence,
‖Y ‖2,h ≤ C∥∥δY
∥∥2,h
.
Page 6 of 6
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 195
Page 195 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 196
F Project 1 MATH572
Page 196 of 236
COMPUTATIONAL ASSIGNMENT # 1
MATH 572
Adaptive Solution of Ordinary Differential Equations
All the theorems about convergence that we have had in class state that, under certain conditions,
limh→0+
maxn‖y(tn)− yn‖ = 0.
While this is good and we should not use methods that do not satisfy this condition, this type of result isof little help in practice. In other words, we usually compute with a fixed h and, even if we know y(tn), wedo not know the exact solution at the next time step and, thus, cannot assess how small the local error
en+1 = y(tn+1)− yn+1
is. Here we will study two strategies to estimate this quantity. Your assignment will consist in implementingthese two strategies and use them for the solution of a Cauchy problem
y′ = f(t, y) t ∈ (t0, T ), y(t0) = y0,
where
1. f = y − t, (t0, T ) = (0, 10), y0 = 1 + δ, with δ ∈ 0, 10−3.2. f = λy + sin t− λ cos t, (t0, T ) = (0, 5), y0 = 0, λ ∈ 0,±5,±10.3. f = 1− y
t , (t0, T ) = (2, 20), y0 = 2.4. The Fresnel integral is given by
φ(t) =
∫ t
0
sin(s2)ds.
Set it as a Cauchy problem and generate a table of values on [0, 10]. If possible obtain a plot of thefunction.
5. The dilogarithm function
f(x) = −∫ x
0
ln(1− t)t
dt
on the interval [−2, 0].
Step Bisection. The local error analysis that is usually carried out with the help of Taylor expansionsyields, for a method of order s, that
‖en+1‖ ≤ Chs+1.
The constant C here is independent of h but it might depend on the exact solution y and the current steptn. To control the local error we will assume that C does not change as n changes. Let v denote the value ofthe approximate solution at tn+1 obtained by doing one step of length h from tn. Let u be the approximatesolution at tn+1 obtained by taking two steps of size h/2 from tn. The important thing here is that both uand v are computable. By the assumption on C we have
y(tn+1) = v + Chs+1,
y(tn+1) = u+ 2C(h/2)s+1,
which implies
‖en+1‖ ≤ Chs+1 =‖u− v‖1− 2−s
.
Notice that the quantity on the right of this expression is completely computable. In a practical realizationone can then monitor ‖u− v‖ to make sure that it is below a prescribed tolerance. If it is not, the time step
Date: Due March 13, 2014.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 197
Page 197 of 236
can be reduced (halved) to improve the local truncation error. On the other hand, if this quantity is wellbelow the prescribed tolerance, the time step can be doubled.
Implement this strategy for the fourth order ERK scheme
012
12
12 0 1
21 0 0 1
16
13
13
16
Adaptive Runge-Kutta-Fehlberg Method. The Runge-Kutta-Fehlberg method is an attempt at devis-ing a procedure to automatically choose the step size. It consists of a fourth order and a fifth order methodwith cleverly chosen parameters so that they use the same nodes and, thus, the function evaluations are atthe same points. The result is a fifth order method that has an estimate for the local error. The methodcomputes two sequences yn and yn of fifth and fourth order, respectively, by
c Abᵀ
bᵀ=
014
14
38
332
932
1213
19322197 − 7200
219772962197
1 439216 −8 3680
513 − 8454104
12 − 8
27 2 − 35442565
18594104 − 11
4016135 0 6656
128252856156430 − 9
50255
25216 0 1408
256521974104 − 1
5 0
The quantity
en+1 = yn+1 − yn+1 = h6∑
i=1
(bi − bi)f(tn + cih, ξi)
can be used as an estimate of the local error. An algorithm to control the step size is based on the size of‖yn+1 − yn+1‖ which, in principle, is controlled by Ch5.
Implement this scheme.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 198
Page 198 of 236
MATH 572: Computational Assignment #2Due on Thurday, March 13, 2014
TTH 12:40pm
Wenqiang Feng
1
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 199
Page 199 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2
Contents
Adaptive Runge-Kutta Methods Formulas 3
Problem 1 3
Problem 2 4
Problem 3 7
Problem 4 8
Problem 5 8
Adaptive Runge-Kutta Methods MATLAB Code 10
Page 2 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 200
Page 200 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2
Adaptive Runge-Kutta Methods Formulas
In this project, we consider two adaptive Runge-Kutta Methods for the following initial-value ODE problem
y′(t) = f(t, y)
y(t0) = y0,(1)
The formula for the fourth order Runge-Kutta (4th RK) method can be read as following
y(t0) = y0,
K1 = hf(ti, yi)
K2 = hf(ti + h2 , yi + K1
2 )
K3 = hf(ti + h2 , yi + K2
2 )
K4 = hf(ti + h, yi +K3)
yi+1 = yi + 16 (K1 +K2 +K3 +K4)
(2)
And the Adaptive Runge-Kutta-Fehlberg (RKF) Method can be wrote as
y(t0) = y0,
K1 = hf(ti, yi)
K2 = hf(ti + h4 , yi + K1
4 )
K3 = hf(ti + 3h8 , yi + 3
32K1 + 932K2)
K4 = hf(ti + 12h13 , yi + 1932
2197K1 − 72002197K2 + 7296
2197K3)
K5 = hf(ti + h, yi + 439216K1 − 8K2 + 3680
513 K3 − 8454104K4)
K6 = hf(ti + h2 , yi − 8
27K1 + 2K2 − 35442565K3 + 1859
4104K4 − 1140 )
yi+1 = yi + 16135K1 + 6656
12825K3 + 2856156430K4 − 9
50K5 + 255K6
yi+1 = yi + 25216K1 + 1408
2656K3 + 21974104K4 − 1
5K5.
(3)
The error
E =1
h|yi+1 − yi+1| (4)
will be used as an estimator. If E ≤ Tol, y will be kept as the current step solution and then move to the
next step with time step size δh. If E > Tol, recalculate the current step with time step size δh, where
δ = 0.84
(Tol
E
)1/4
.
Problem 1
1. The 4th RK method and RKF method for Problem 1.1
(a) Results for Problem 1.1. From the figure (Fig.1) we can see that the 4th RK method and
RKF method are both convergent for Problem 1.1. The 4th RK method is convergent with 4
steps and RKF method with 2 steps and reached error 4.26× 10−14.
Problem 1 continued on next page. . . Page 3 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 201
Page 201 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 1 (continued)
(b) Figures (Fig.1)
0 1 2 3 4 5 6 7 8 9 101
2
3
4
5
6
7
8
9
10
11
x
y
Problem.1.1,With steps =4,error=0.000000e+00
Runge−Kutta−4th
0 1 2 3 4 5 6 7 8 9 100
2
4
6
8
10
12
x
y
Problem.1.1,with step=2,error=4.263256e−14
Runge−Kutta−Fehlberg
Figure 1: The 4th RK method and RKF method for Problem 1.1
2. The 4th RK method and RKF method for Problem 1.2
(a) Results for Problem 1.2. From the figure (Fig.2) we can see that the 4th RK method and
RKF method are both convergent for Problem 1.2. The 4th RK method is convergent with 404
steps and reached error 9.9× 10−6. RKF method with 29 steps and reached error 2.3× 10−9.
(b) Figures (Fig.2)
0 1 2 3 4 5 6 7 8 9 100
5
10
15
20
25
30
35
x
y
Problem.1.2,With steps =404,error=9.904222e−06
Runge−Kutta−4th
0 1 2 3 4 5 6 7 8 9 100
5
10
15
20
25
30
35
x
y
Problem.1.2,with step=29,error=2.285717e−09
Runge−Kutta−Fehlberg
Figure 2: The 4th RK method and RKF method for Problem 1.2
Problem 2
1. The 4th RK method and RKF method for Problem 2.1
Problem 2 continued on next page. . . Page 4 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 202
Page 202 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 2 (continued)
(a) Results for Problem 2.1. From the figure (Fig.3) we can see that the 4th RK method and
RKF method are both convergent for Problem 2.1. The 4th RK method is convergent with 24
steps and reached error 7.1× 10−6. RKF method with 8 steps and reached error 9.4× 10−10.
(b) Figures (Fig.3)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
x
y
Problem.2.1,With steps =24,error=7.066631e−06
Runge−Kutta−4th
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
x
y
Problem.2.1,with step=8,error=9.351243e−10
Runge−Kutta−Fehlberg
Figure 3: The 4th RK method and RKF method for Problem 2.1
2. The 4th RK method and RKF method for Problem 2.2
(a) Results for Problem 2.2. From the figure (Fig.4) we can see that the 4th RK method and
RKF method are both divergent for Problem 2.2.
(b) Figures (Fig.4)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−7
−6
−5
−4
−3
−2
−1
0x 10
10
x
y
Problem.2.2,With steps =10002,error=8.087051e+00
Runge−Kutta−4th
0 0.5 1 1.5 2 2.5 3 3.5−3.5
−3
−2.5
−2
−1.5
−1
−0.5
0x 10
6
x
y
Problem.2.2,with step=1001,error=3.725290e−09
Runge−Kutta−Fehlberg
Figure 4: The 4th RK method and RKF method for Problem 2.2
3. The 4th RK method and RKF method for Problem 2.3
Problem 2 continued on next page. . . Page 5 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 203
Page 203 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 2 (continued)
(a) Results for Problem 2.3. From the figure (Fig.5) we can see that the 4th RK method and
RKF method are both convergent for Problem 2.3. The 4th RK method is convergent with 96
steps and reached error 9.98× 10−6. RKF method with 69 steps and reached error 1.3× 10−11.
(b) Figures (Fig.5)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
y
Problem.2.3,With steps =96,error=9.980755e−06
Runge−Kutta−4th
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
y
Problem.2.3,with step=69,error=1.327621e−11
Runge−Kutta−Fehlberg
Figure 5: The 4th RK method and RKF method for Problem 2.3
(c) The 4th RK method and RKF method for Problem 2.4
i. Results for Problem 2.4. From the figure (Fig.6) we can see that the 4th RK method and
RKF method are both divergent for Problem 2.4.
ii. Figures (Fig.6)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−6
−5
−4
−3
−2
−1
0x 10
21
x
y
Problem.2.4,With steps =10002,error=1.967067e+13
Runge−Kutta−4th
0 0.5 1 1.5−18
−16
−14
−12
−10
−8
−6
−4
−2
0x 10
5
x
y
Problem.2.4,with step=1001,error=1.396984e−09
Runge−Kutta−Fehlberg
Figure 6: The 4th RK method and RKF method for Problem 2.4
(d) The 4th RK method and RKF method for Problem 2.5
i. Results for Problem 2.5. From the figure (Fig.7) we can see that the 4th RK method
and RKF method are both convergent for Problem 2.5. The 4th RK method is convergent
Problem 2 continued on next page. . . Page 6 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 204
Page 204 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 2 (continued)
with 88 steps and reached error 8.77× 10−6. RKF method with 114 steps and reached error
2.57× 10−10.
ii. Figures (Fig.7)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
y
Problem.2.5,With steps =88,error=8.777162e−06
Runge−Kutta−4th
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
y
Problem.2.5,with step=114,error=2.566889e−10
Runge−Kutta−Fehlberg
Figure 7: The 4th RK method and RKF method for Problem 2.5
Problem 3
1. The 4th RK method and RKF method for Problem 3
(a) Results for Problem 3. From the figure (Fig.8) we can see that the 4th RK method and RKF
method are both convergent for Problem 3. The 4th RK method is convergent with 4 steps and
reached error 1.77× 10−15. RKF method with 2 steps and reached error 2× 10−15.
(b) Figures (Fig.8)
2 4 6 8 10 12 14 16 18 202
3
4
5
6
7
8
9
10
11
x
y
Problem.3.0,With steps =4,error=1.776357e−15
Runge−Kutta−4th
2 4 6 8 10 12 14 16 18 202
3
4
5
6
7
8
9
10
11
x
y
Problem.3.0,with step=2,error=3.552714e−15
Runge−Kutta−Fehlberg
Figure 8: The 4th RK method and RKF method for Problem 3
Problem 3 continued on next page. . . Page 7 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 205
Page 205 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 3 (continued)
Problem 4
1. The 4th RK method and RKF method for Problem 4
(a) Results for Problem 4. From the figure (Fig.9) we can see that the 4th RK method and RKF
method are both convergent for Problem 4. The 4th RK method is convergent with 438 steps and
reached error 9.9× 10−6. RKF method with 134 steps and reached error 3.68× 10−14.
(b) Figures (Fig.9)
0 1 2 3 4 5 6 7 8 9 100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
x
y
Problem.4.0,With steps =438,error=9.928746e−06
Runge−Kutta−4th
0 1 2 3 4 5 6 7 8 9 100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
x
y
Problem.4.0,with step=134,error=3.685940e−14
Runge−Kutta−Fehlberg
Figure 9: The 4th RK method and RKF method for Problem 4
Problem 5
1. The 4th RK method and RKF method for Problem 5
(a) Results for Problem 5. Since, x = 0 is the singular point for the problems and y0 = limx→0− =
1. So, the schemes do not work for the interval [−2, 0]. But schemes works for the interval [−2, 0−δ]and δ > 1× 1016. I changed the problem to the following
f ′(x) = ln(1+x)x , x ∈ [δ, 2]
f(δ) = 0.
The (Fig.8) gives the result for the interval [δ, 2] and δ = 1× 1010.
(b) Figures (Fig.10)
Problem 5 continued on next page. . . Page 8 of 15
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 206
Page 206 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 5 (continued)
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 213
Page 213 of 236
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 214
G Project 2 MATH572
Page 214 of 236
COMPUTATIONAL ASSIGNMENT #2
MATH 572
The purpose of this assignment is to explore techniques for the numerical solution of boundary value andinitial boundary value problems and to introduce some ideas that we did not discuss in class but, nevertheless,are quite important. You should submit the solution of at least two (2) of the following problems. Submittingthe solution to the third can be used for extra credit.
The Convection diffusion equation. Upwinding.
Let Ω = (0, 1) and consider the following two point boundary value problem:
−εu′′ + u′ = 0, u(0) = 1, u(1) = 0.
Here ε > 0 is a constant. We are interested in what happens when ε 1.
• Find the exact solution to this problem. Is it monotone?• Compute a finite difference approximation of this problem on a uniform grid of size h = 1/N using centered
differences: That is, set U0 = 1, UN = 0 and
(1) βiUi−1 + αiUi + γiUi+1 = 0, 0 < i < N,
where αi, βi, γi are defined in terms of ε and h. Set ε ∈ 1, 10−1, 10−3, 10−6 and compute the solution fordifferent values of h. What do you observe for h > ε? For h ≈ ε? For h < ε?
• Show that
Ui = 1, Ui =
( 2εh + 12εh − 1
)i, i = 0, N
are two linearly independent solutions of the difference equation. Find the dicrete solution U of theproblem in terms of U and U . Using this representation, determine the relation between ε and h thatensures that there are no oscillations in U . Does this coincide with your observations of the previous item?
Hint: Consider the sign of2εh +1
2εh −1
.
• Replace the centered difference approximation of the first derivative u′ by the up-wind difference u′(xi) ≈h−1(u(xi)− u(xi−1)). Repeat the previous two items and draw conclusions.
• Show that, using an up-wind approximation the arising matrix satisfies a discrete maximum principle.
Date: Due April 24, 2014.
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 215
Write a piece of code that, for a given a and f computes the finite element solution to this problem over amesh Th = IjNj=1, Ij = [xj−1, xj ] with hj = xj − xj−1 not necessarily uniform.
• Set a = 1 and choose f so that u = x3. Compute the finite element solution on a sequence of uniformmeshes of size h = 1/N and verify the estimate
(3) ‖u− U‖H1(0,1) ≤ Ch = CN−1.
• Set a = 1 and f = − 34√x
and notice that f /∈ L2(0, 1). This problem, however, is still well posed. Show
this. For this case repeat the previous item. What do you observe?• Set a(x) = 1 if 0 ≤ x < 1/π and a(x) = 2 otherwise. Choose f ≡ 1 and compute the exact solution.
Repeat the first item. What do you observe? Recall that to compute the exact solution we must includethe interface conditions: u and au′ are continuous.
The last two items show that in the case when either the right hand side or the coefficient in the equationare not smooth, the solution does not satisfy u′′ ∈ L2(0, 1) and so the error estimate (3) cannot be obtainedwith uniform meshes. Notice, also, that in both cases the solution is smooth except perhaps at very fewpoints, so that if we were able to handle these, problematic, points we should be able to recover (3). Thepurpose of a posteriori error estimates is exactly this.
Let us recall the weak formulation of (2). Define:
A(v, w) =
∫ 1
0
av′w′, L(v) =
∫ 1
0
fv,
then we need to find u such that u− 1 ∈ H10 (0, 1) and
A(u, v) = L(v) ∀v ∈ H10 (0, 1).
If U is the finite element solution to (2) and v ∈ H10 (0, 1), we have
A(u− U, v) = A(u, v)−A(U, v) = L(v)−A(U, v) =
∫ 1
0
fv −∫ 1
0
aU ′v′ =
N∑
j=1
∫
Ij
fv − aU ′v′.
Let us now consider each integral separately. Integrating by parts we obtain
∫
Ij
fv − aU ′v′ =
∫
Ij
fv +
∫
Ij
(aU ′)′v − aU ′v∣∣xj
xj−1
so that adding up we get
A(u− U, v) =
N∑
j=1
∫
Ij
(f + (aU ′)′) v +
N−1∑
j=1
v(xj)j(a(xj)U′(xj)),
where
j(w(x)) = w(x+ 0)− w(x− 0)
is the so-called jump. Let us now set v = w − Ihw, where Ih is the Lagrange interpolation operator. In thiscase then v(xj) = 0 (why?) and
‖v‖L2(Ij) = ‖w − Ihw‖L2(Ij) ≤ chj‖w′‖L2(Ij).
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 216
Page 216 of 236
Consequently,
A(u− U,w − Ihw) ≤ C∑
Ij∈Thhj‖f + (aU ′)′‖L2(Ij)‖w′‖L2(Ij)
≤ C
∑
Ij∈Thh2j‖f + (aU ′)′‖2L2(Ij)
1/2 ∑
Ij∈Th‖w′‖L2(Ij)
1/2
= C
∑
Ij∈Thh2j‖f + (aU ′)′‖2L2(Ij)
1/2
‖w′‖L2(0,1)
What is the use of all this? Define rj = hj‖f + (aU ′)′‖L2(Ij) then, using Galerkin orthogonality we obtain
‖u− U‖2H1(0,1) ≤1
c1A(u− U, u− U) =
1
c1A(u− U, u− U − Ih(u− U)) ≤ C
N∑
j=1
r2j
1/2
‖u− U‖H1(0,1).
In other words, we bounded the error in terms of computable and local quantities rj . This allows us todevise an adaptive method:
• (Solve) Given Th find U .• (Estimate) Compute the rj ’s.• (Mark) Choose ` for which r` is maximal.• (Refine) Construct a new mesh by bisecting I` and leaving all the other elements unchanged.
Implement this method and show that (3) is recovered.
You might also want to try choosing a set of minimal cardinality M so that∑j∈M r2j ≥ 1
2
∑Nj=1 r
2j and
bisecting the cells Ij with j ∈M.
Numerical methods for the heat equation
Let Ω = (0, 1) and T = 1. Consider the heat equation
ut − u′′ = f in Ω, u|∂Ω = 0, u|t=0 = u0.
Choose f and u0 so that the exact solution reads:
u(x, t) = sin(3πx)e−2t,
Implement a finite difference discretization of this problem in sapce and, in time, the θ-method:
Uk+1i − Uki
τ− θ∆hU
ki − (1− θ)∆hU
k+1i = fk+1
i .
In doing so you obtained:
• The explicit Euler method, θ = 1.• The implicit Euler method, θ = 0.• The Crank-Nicolson method, θ = 1
2 .
For each one of them compute the discrete solution U at T = 1 and measure the L2, H1 and L∞ norms ofthe error. You should do this on a series of meshes and verify the theoretical error estimates. The time stepmust be chosen as:
• τ =√h.
• τ = h.• τ = h2.
What can you conclude?
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 217
Page 217 of 236
MATH 572: Computational Assignment #2Due on Thurday, April 24, 2014
TTH 12:40pm
Wenqiang Feng
1
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 218
Page 218 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2
Contents
The Convection Diffusion Equation 3
Problem 1 3
A Posterior Error Estimation 8
Problem 2 8
Heat Equation 13
Problem 3 13
Page 2 of 19
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 219
Page 219 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2
The Convection Diffusion Equation
Problem 1
1. The exact solution
From the problem, we know that the characteristic function is
−ελ2 + λ = 0.
So, λ = 0, 1ε . Therefore, the general solution is
u = c1e0x + c2e
1ε x = c1 + c2e
1ε x.
By using the boundary conditions, we get the solution is
u(x) = 1− 1
1− e 1ε
+1
1− e 1ε
e1ε x.
And u(x) is monotone.
2. Central Finite difference scheme
I consider the following partition for finite difference method:
x0
0
x1 xN−1 xN
1
Figure 1: One dimension’s uniform partition for finite difference method
Then, the central difference scheme is as following:
−εUi−1 − 2Ui + Ui+1
h2+Ui+1 − Ui−1
2h= 0, i = 1, 2, · · · , N − 1. (1)
U0 = 1, UN = 0. (2)
So
(a) when i = 1, we get
−εU0 − 2U1 + U2
h2+U2 − U0
2h= 0,
i.e.
−(ε
h2+
1
2h
)U0 +
2ε
h2U1 +
(1
2h− ε
h2
)U2 = 0.
Since, U0 = 1, so we get
2ε
h2U1 +
(1
2h− ε
h2
)U2 =
(ε
h2+
1
2h
). (3)
(b) when i = 2, · · · , N − 2, we get
−εUi−1 − 2Ui + Ui+1
h2+Ui+1 − Ui−1
2h= 0.
i.e.
−(ε
h2+
1
2h
)Ui−1 +
2ε
h2Ui +
(1
2h− ε
h2
)Ui+1 = 0. (4)
Problem 1 continued on next page. . . Page 3 of 19
Wenqiang Feng Prelim Exam note for Numerical Analysis Page 220
Page 220 of 236
Wenqiang Feng MATH 572 ( TTH 12:40pm): Computational Assignment #2 Problem 1 (continued)
3. when i = N − 1
−εUN−2 − 2UN−1 + UNh2
+UN − UN−2
2h= 0,
i.e.
−(ε
h2+
1
2h
)UN−2 +
2ε
h2UN−1 +
(1
2h− ε
h2
)UN = 0.
Since UN = 0, then,
−(ε
h2+
1
2h
)UN−2 +
2ε
h2UN−1 = 0. (5)
From (3)-(5), we get the algebraic system is
AU = F,
where
A =
2εh2
12h − ε
h2
−(εh2 + 1
2h
)2εh2
12h − ε
h2
. . .. . .
. . .
−(εh2 + 1
2h
)2εh2
12h − ε
h2
−(εh2 + 1
2h
)2εh2
,
U =
U1
U2
...
UN−2UN−1
, F =
εh2 + 1
2h...
0...
.
4. Numerical Results of Central Difference Method
h Nnodes ‖u− uh‖l∞,ε=1 ‖u− uh‖l∞,ε=10−1 ‖u− uh‖l∞,ε=10−3 ‖u− uh‖l∞,ε=10−6