31
presented by Christian Loza, Srikanth Palla and Liqin Zhang SPAM: Content based methods –Seminar II Different methods Metrics and benchmarks -- Seminar I
| Date post: | 27-Dec-2015 |
| Category: |
Documents |
| Upload: | jeffry-clarke |
| View: | 217 times |
| Download: | 1 times |

presented by Christian Loza, Srikanth Palla and Liqin Zhang
SPAM: Content based methods –Seminar II
Different methods
Metrics and benchmarks
-- Seminar ILiqin Zhang

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Different Methods:
Non-content based approach
remove spam message if contain virus, worms before read.
leaves some messages un-labeled
Content based method:
widely used method
may need lots pre-labeled message
label message based its content
Zdziarski[5] said that it's possible to stop spam, and that content-based filters are the way to do it
Focus on content based method

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Method of content-based
Bayesian based method [6] Centroid-based method[7] Machine learning method [8]
Latent Semantic indexing LSI Contextual Network Graphs (CNG)
Rule based method[9] ripper rule: a list of predefined rules that can be changed
by hand Memory based method[10]
saving cost

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Rule-based method
A list of predefined rules that can be changed by hand ripper rule
Each rule/test associated with a score If an email fails a rule, its score increasedAfter apply all rules, if the score is above a
certain threshold, it is classified as spam

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Rule-based method
Advantage: able to employ diverse and specific rule to check
spamCheck size of the emailNumber of pictures it contains
no training messages are neededDisadvantage:
rules have to be entered and maintained by hand --- can’t be automatically

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent Semantic indexing
Keyword important word for text classification High frequent word in a message Can used as an indicator for the message
Why LSI? Polysemy: word can be used in more than one category
ex: Play
Synonymous: if two words have identical meaning
Based on nearest neighbors based algorithm

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent semantic indexing
consider semantic links between words Search keyword over the semantic space Two words have the same meaning are treated as one
word eliminate synonymous
Consider the overlap between different message, this overlap may indicate: polysemy or stop-word two messages in same category
presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent semantic indexing
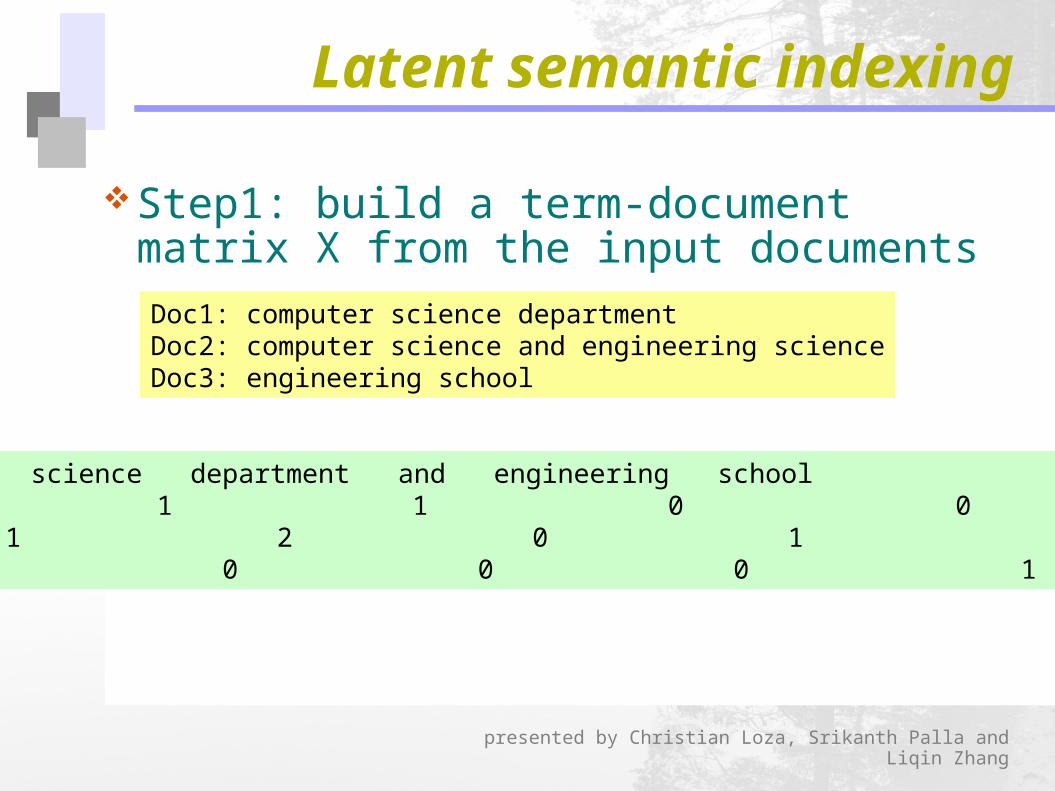
Step1: build a term-document matrix X from the input documents
Doc1: computer science departmentDoc2: computer science and engineering scienceDoc3: engineering school
Computer science department and engineering schoolDoc1 1 1 1 0 0 0Doc2 1 2 0 1 1 0Doc3 0 0 0 0 1 1

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent semantic indexing
Step2: Singular value Decomposition (SVD) is performed on matrix X To extract a set of linearly independent FACTORS
that describe the matrix Generalize the terms have the same meaning Three new matrices TSD are produced to reduce
the vocabulary’s size

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent Semantic indexing
Two document can be compared by finding the distance between two document vector, stored in matrix X1
Text classification is done by finding the nearest neighbors – assign to category with max document

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Spam:
Un-spam:
Test:
Nearest neighbors method classify the test message to be UN-SPAM

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Latent Semantic Indexing
Advantage: Entire training set can be learned at same time No intermediate model need to be build Good for the training set is predefined
Disadvantage: When new document added, matrix X changed, and TSD
need to be re-calculated Time consuming Real classifier need the ability to change training set

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Contextual network Graphs
A weighted, bipartite, undirected graph of term and document nodes
d1 d2t2
t1
t3
w11
w12
w13
w21
w22
w23
At any time, for each node, the sum of the weigh is 1
t1: W11+w21 = 1d1: w11+w12+w13 = 1

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Contextual network graphs
When new document d is added, energizing the weights at node d, and may need re-balance the weights at the connected node
The document is classified to the one with maximum of energy (weight) average for each class

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Comparison Bayesian, LSI,CNG, centroid, rule-
based
noYesYesYesYesAutomatic update model
noNoYesYesNoSemantic
Test against rule
Recalculation of centroid
Addition nodes to graph
Recalculation matrices
Update statistics
Learning
Predefined rules
Cosine similarity
TF-IDF
Energy re-balancing
Generalization/contextual data
Statistical/probabilities
Classification
RuleCentroidCNGLSIBayesian

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Result

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Result and conclusion:
LSI & CNG super Bayesian approach 5% accuracy, and reduce false positive and negatives up to 71%
LSI & CNG shows better performance even with small document set

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Comparison content based and non-content based
Non-content based: dis-adv:
depends on special factor like email address, IP address, special protocol,
leaves some un-classified Adv: detect spam before reading message with
high accuracy

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Content based: Disadvantage:
need some training message not 100% correct classified due to the spammer also
know the anti-spam tech. Advantage:
leaves no message unclassified

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Improvement for spam
Combine both method [1] proposes an email network based algorithm, which with
100% accuracy, but leaves 47% unclassified, if combine with content based method, can improve the performance.
Build up multi-layers[11]
[11] Chris Miller, A layered Approach to enterprise antispam

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Metrics and Benchmarks

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Measurements --- Metrics
Accuracy: the percentage of correct classified correct/(correct + un-correct)
False positive: if a message is a spam, but misclassify to un-spam. Goal:
Improve accuracyPrevent false positive
SpamNo spam
Correct
Un-correctFalse positive
presented by Christian Loza, Srikanth Palla and Liqin Zhang
Measurements -- Metrics
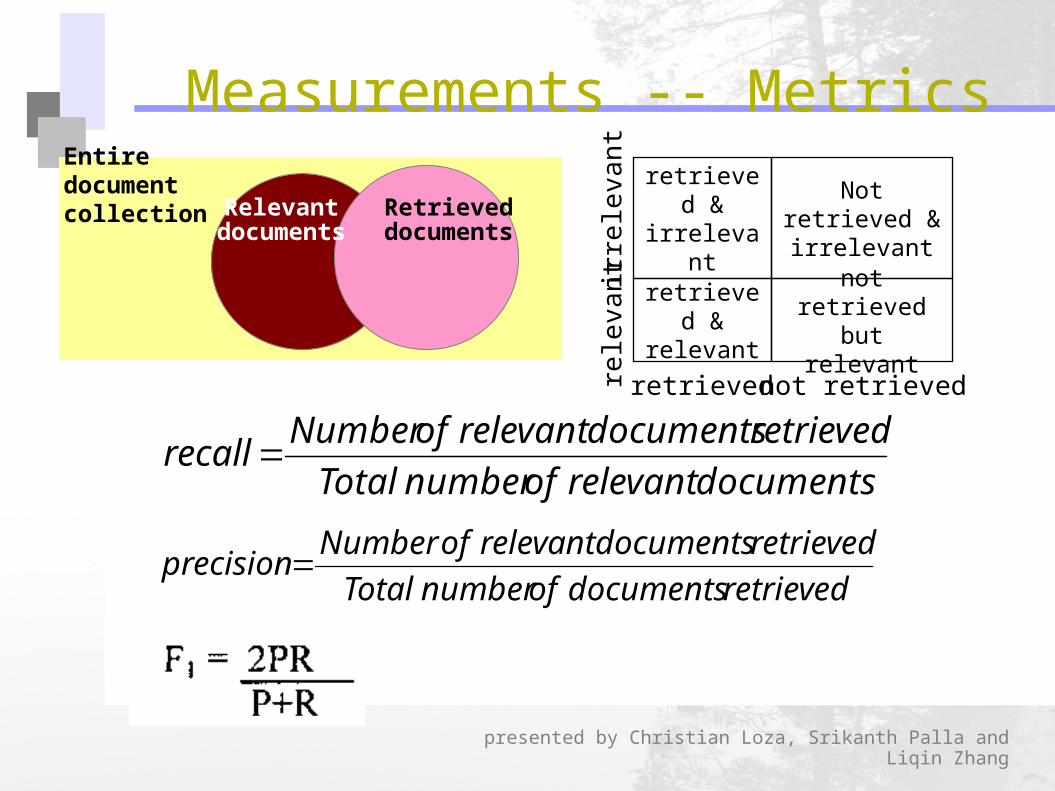
Relevant documents
Retrieved documents
Entire document collection
retrieved & relevant
not retrieved but relevant
retrieved & irrelevant
Not retrieved & irrelevant
retrieved not retrieved
rele
vant
irre
leva
nt
documents relevant of number Total
retrieved documents relevant of Number recall
retrieved documents of number Total
retrieved documents relevant of Number precision

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Data set for spam:
Non-content based: Email network:
One author’s email corpus, formed by 5,486 messages IP address: -- none
Content based:

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Data set for spam
LSI & CNG: Corpus of varying size (250 ~ 4000) Spam and un-spam emails in equal amount
Bayesian based: Corpus of 1789 email 211 spam, 1578 non-spam
Cetroid based: Totally 200 email message 90 spam, 110 non-spam
presented by Christian Loza, Srikanth Palla and Liqin Zhang
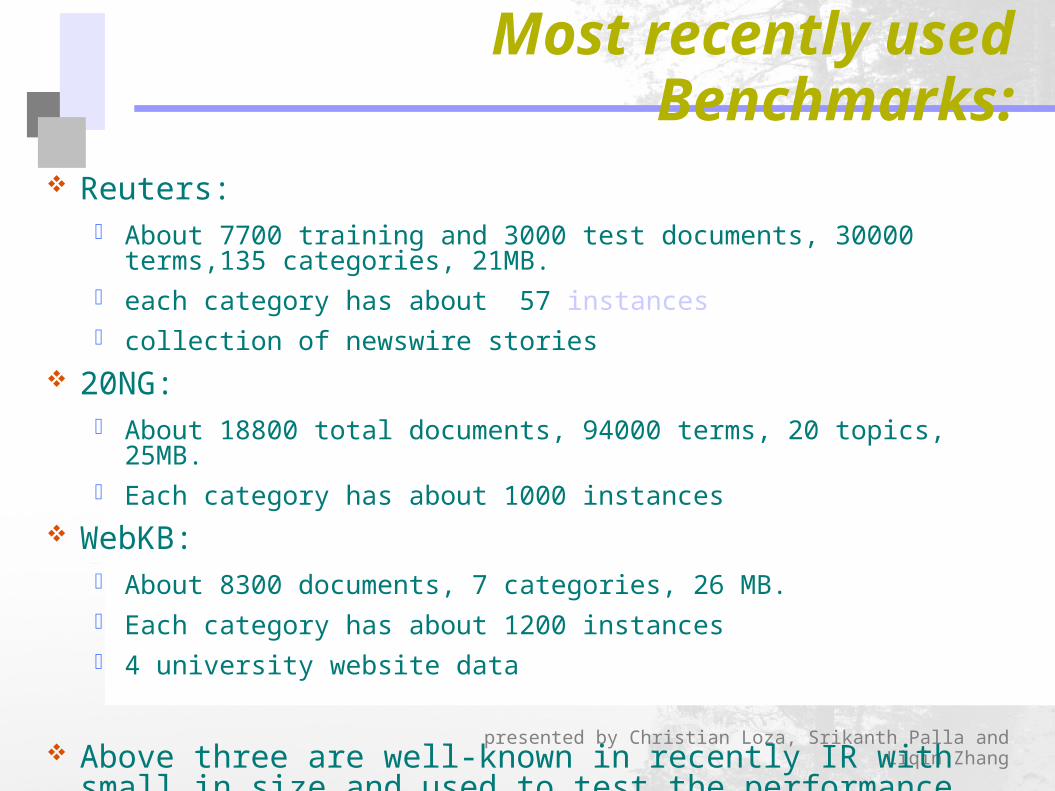
Most recently used Benchmarks:
Reuters: About 7700 training and 3000 test documents, 30000 terms,135 categories,
21MB. each category has about 57 instances collection of newswire stories
20NG: About 18800 total documents, 94000 terms, 20 topics, 25MB. Each category has about 1000 instances
WebKB: About 8300 documents, 7 categories, 26 MB. Each category has about 1200 instances 4 university website data
Above three are well-known in recently IR with small in size and used to test the performance and CPU scalability

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Benchmarks
OHSUMED: 348566 document, 230000 terms and 308511 topics, 400 MB. Each category has about 1 instance Abstract from medical journals
Dmoz: 482 topics, 300 training document for each topic, 271MB Each category has less than 1 instance taken from Dmoz(http://dmoz.org/) topic tree
Large dataset, used to test the memory scalability of a model

presented by Christian Loza, Srikanth Palla and Liqin Zhang
Sources
Slide 1, image: ttp://www.ecommerce-guide.com
Slide 1, image: ttp://www.email-firewall.jp/products/das.html

presented by Christian Loza, Srikanth Palla and Liqin Zhang
References
Anti-spam Filtering: A centroid-based Classification Approach, Nuanwan Soonthornphisaj, Kanokwan Chaikulseriwat, Piyan Tang-On, 2002
Centroid-Based Document Classification: Analysis & Experimental Results, Eui-Hong (Sam) and George Karypis, 2000
Multi-dimensional Text classification, Thanaruk Theeramunkog, 2002
Improving centroid-based text classification using term-distribution-based weighting system and clustering, Thanaruk Theeramunkog and Verayuth Lertnattee
Combining Homogeneous Classifiers for Centroid-based text classifications, Verayuth Lertnattee and Thanaruk Theeramunkog

presented by Christian Loza, Srikanth Palla and Liqin Zhang
References
[1] P Oscar Boykin and Vwani Roychowdhury, Personal Email Networks: An Effective Anti-Spam Tool, IEEE COMPUTER, volume 38, 2004
[2] Andras A. Benczur and Karoly Csalogany and Tamas Sarlos and Mate Uher, SpamRank - Fully Automatic Link Spam Detection, citeseer.ist.psu.edu/benczur05spamrank.html
[3]. R. Dantu, P. Kolan, “Detecting Spam in VoIP Networks”, Proceedings of USENIX, SRUTI (Steps for Reducing Unwanted Traffic on the Internet) workshop, July 05(accepted)
[4]. IP addresses in email clients ttp://www.ceas.cc/papers-2004/162.pdf
[5] Plan for Spam ttp:// ww.paulgraham.com/spam.html

presented by Christian Loza, Srikanth Palla and Liqin Zhang
References
[6] M. Sahami, S. Dumais, D. Heckerman, and E. Horvitz. 1998, “A Bayesian Approach to Filtering Junk E-Mail”, Learning for Text Categorization – Papers from the AAAI Workshop, pages 55–62, Madison Wisconsin. AAAI Technical Report WS-98-05
[7] N. Soonthornphisaj, K. Chaikulseriwat, P Tang-On, “Anti-Spam Filtering: A Centroid Based Classification Approach”, IEEE proceedings ICSP 02
[8] Spam Filtering Using Contextual Networking Graphs www.cs.tcd.ie/courses/csll/dkellehe0304.pdf
[9] W.W. Cohen, “Learning Rules that Classify e-mail”, In Proceedings of the AAAI Spring Symposium on Machine Learning in Information Access, 1996
[10] G. Sakkis, I. Androutsopoulos, G. Paliouras, V. Karkaletsis, C.D. Spyropoulos, P. Stamatopoulos, “A memory based approach to anti-spam filtering for mailing lists”, Information Retrieval 2003

















