74
Probabilistic Graphical Models Probabilistic Graphical Models Structure learning in Bayesian networks Siamak Ravanbakhsh Fall 2019

Probabilistic Graphical ModelsProbabilistic Graphical ModelsStructure learning in Bayesian networks
Siamak Ravanbakhsh Fall 2019

Learning objectivesLearning objectives
why structure learning is hard?two approaches to structure learning
constraint-based methodsscore based methods
MLE vs Bayesian score

Structure learningStructure learning in BayesNets in BayesNets
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets

Structure learningStructure learning in BayesNets in BayesNets
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
search over the combinatorial space, maximizing a score 2O(n )2

Structure learningStructure learning in BayesNets in BayesNets
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
search over the combinatorial space, maximizing a score
Bayesian model averagingintegrate over all possible structures
2O(n )2

Structure learningStructure learning in BayesNets in BayesNets
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
search over the combinatorial space, maximizing a score
Bayesian model averagingintegrate over all possible structures

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI) I(G) = I(p )D

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI) I(G) = I(p )D
Perfect MAP

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI) I(G) = I(p )D
hypothesis testing
Perfect MAP

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI) I(G) = I(p )D
hypothesis testing
Perfect MAP
X ⊥ Y ∣ Z?

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI) I(G) = I(p )D
hypothesis testing
first attempt: a DAG that is I-map for
Perfect MAP
p D I(G) ⊆ I(p )D
X ⊥ Y ∣ Z?

minimal I-mapminimal I-map from CI test from CI test
input: IC test oracle; an orderingoutput: a minimal I-map G for i=1...n
find minimal s.t.set
X , … ,X 1 n
(X ⊥i X , … ,X −1 i−1 U ∣ U)U ⊆ {X , … ,X }1 i−1
X 1 X nX i
Pa ←X i U X ⊥ NonDesc ∣ Pa i X i X i
a DAG where removing an edge violates I-map property

minimal I-mapminimal I-map from CI test from CI testProblems:
CI tests involve many variablesnumber of CI tests is exponentiala minimal I-MAP may be far from a P-MAP

minimal I-mapminimal I-map from CI test from CI testProblems:
CI tests involve many variablesnumber of CI tests is exponentiala minimal I-MAP may be far from a P-MAP
different orderings give different graphs Example:
D,I,S,G,L(a topological ordering)
L,S,G,I,D L,D,S,I,G

Structure learningStructure learning in BayesNets in BayesNets
Identifiable up to I-equivalence
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
a DAG with the same set of conditional independencies (CI)
I(G) = I(p )D
first attempt: a DAG that is I-map for p D I(G) ⊆ I(p )D
can we find a perfect MAP with fewer IC testsinvolving fewer variables?
second attempt: a DAG that is P-map for

Perfect mapPerfect map from CI test from CI test
only up to I-equivalencethe same set of CIs
same skeletonsame immoralities

Perfect mapPerfect map from CI test from CI test
only up to I-equivalencethe same set of CIs
same skeletonsame immoralities
procedure:
1. find the undirected skeleton using CI tests2. identify immoralities in the undirected graph

Perfect mapPerfect map from CI test from CI test1. finding the undirected skeleton
observation: if X and Y are not adjacent then ORX ⊥ Y ∣ Pa X X ⊥ Y ∣ Pa Y

Perfect mapPerfect map from CI test from CI test1. finding the undirected skeleton
observation: if X and Y are not adjacent then ORX ⊥ Y ∣ Pa X X ⊥ Y ∣ Pa Y
assumption: max number of parents d

Perfect mapPerfect map from CI test from CI test1. finding the undirected skeleton
observation: if X and Y are not adjacent then ORX ⊥ Y ∣ Pa X X ⊥ Y ∣ Pa Y
assumption: max number of parents d
idea: search over all subsets of size d, and check CI above

Perfect mapPerfect map from CI test from CI test1. finding the undirected skeleton
observation: if X and Y are not adjacent then ORX ⊥ Y ∣ Pa X X ⊥ Y ∣ Pa Y
assumption: max number of parents d
idea: search over all subsets of size d, and check CI above
input: CI oracle; bound on #parents d
output: undirected skeleton
initialize H as a complete undirected graph
for all pairs for all subsets U of size (within current neighbors of )
If then remove from Hreturn H
X ,X i j
≤ d
X ⊥i X ∣j U X −i X j
X ,X i j

Perfect mapPerfect map from CI test from CI test1. finding the undirected skeleton
observation: if X and Y are not adjacent then ORX ⊥ Y ∣ Pa X X ⊥ Y ∣ Pa Y
assumption: max number of parents d
idea: search over all subsets of size d, and check CI above
input: CI oracle; bound on #parents d
output: undirected skeleton
initialize H as a complete undirected graph
for all pairs for all subsets U of size (within current neighbors of )
If then remove from Hreturn H
X ,X i j
≤ d
X ⊥i X ∣j U X −i X j
X ,X i j = O((n ) ×2 O((n − 2) )d
O(n )d+2

Perfect mapPerfect map from CI test from CI test2. finding the immoralities
potential immoralityX − Z,Y − Z ∈ H,X − Y ∈ H
YX
Z

Perfect mapPerfect map from CI test from CI test2. finding the immoralities
potential immoralityX − Z,Y − Z ∈ H,X − Y ∈ H
YX
Z

Perfect mapPerfect map from CI test from CI test2. finding the immoralities
potential immoralityX − Z,Y − Z ∈ H,X − Y ∈ H
not immorality only if
X ⊥i X ∣j U⇒ Z ∈ UYX
Z

Perfect mapPerfect map from CI test from CI test2. finding the immoralities
input: CI oracle; bound on #parents d
output: undirected skeleton
initialize H as a complete undirected graph
for all pairs for all subsets U of size (within current neighbors of )
If then remove from Hreturn H
X ,X i j
≤ d
X ⊥i X ∣j U X −i X j
X ,X i j
potential immoralityX − Z,Y − Z ∈ H,X − Y ∈ H
not immorality only if
X ⊥i X ∣j U⇒ Z ∈ U
save the U when removing X-Ysee if Z in U?
if no, then we have immorality
X Y
Z
YX
Z

Perfect mapPerfect map from CI test from CI test3. propagate the constraints
at this point: a mix of directed and undirected edges

Perfect mapPerfect map from CI test from CI test3. propagate the constraints
at this point: a mix of directed and undirected edgesadd directions using the following rules (needed to preserve immoralities / DAG structure)
until convergence
for exact CI tests, this guarantees the exact I-equivalence family

Perfect mapPerfect map from CI test from CI test3. propagate the constraints
at this point: a mix of directed and undirected edgesadd directions using the following rules (needed to preserve immoralities / DAG structure)
until convergenceExample
Ground truth DAG
for exact CI tests, this guarantees the exact I-equivalence family
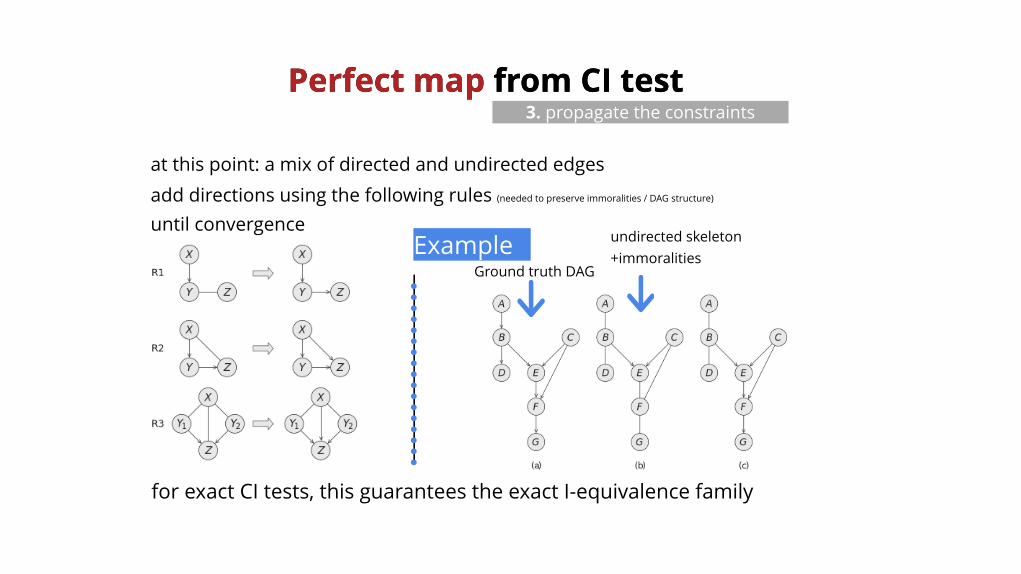
Perfect mapPerfect map from CI test from CI test3. propagate the constraints
at this point: a mix of directed and undirected edgesadd directions using the following rules (needed to preserve immoralities / DAG structure)
until convergenceExample
Ground truth DAG
undirected skeleton+immoralities
for exact CI tests, this guarantees the exact I-equivalence family

Perfect mapPerfect map from CI test from CI test3. propagate the constraints
at this point: a mix of directed and undirected edgesadd directions using the following rules (needed to preserve immoralities / DAG structure)
until convergenceExample
Ground truth DAG
undirected skeleton+immoralities using rules R1,R2,R3
for exact CI tests, this guarantees the exact I-equivalence family

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
measure the deviance of from
conditional mututal information
statistics
p (X ∣D Z)p (Y ∣Z)D p (X,Y ∣Z)D
d (D) =I E [D(p (X,Y ∣Z)∣∣p (X∣Z)p (Y ∣Z))]Z D D D
χ2

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
measure the deviance of from
conditional mututal information
statistics
p (X ∣D Z)p (Y ∣Z)D p (X,Y ∣Z)D
d (D) =I E [D(p (X,Y ∣Z)∣∣p (X∣Z)p (Y ∣Z))]Z D D D
χ2
d (D) =χ2 ∣D∣ ∑x,y,z p (z)p (x∣z)p (y∣z)D D D
(p (x,y,z)−p (z)p (x∣z)p (y∣z))D D D D2
using frequencies in thedataset

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
measure the deviance of from
conditional mututal information
statistics
p (X ∣D Z)p (Y ∣Z)D p (X,Y ∣Z)D
d (D) =I E [D(p (X,Y ∣Z)∣∣p (X∣Z)p (Y ∣Z))]Z D D D
χ2
d (D) =χ2 ∣D∣ ∑x,y,z p (z)p (x∣z)p (y∣z)D D D
(p (x,y,z)−p (z)p (x∣z)p (y∣z))D D D D2
using frequencies in thedataset
large deviance rejects the null hypothesis (of conditional independence)

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
measure the deviance of from
conditional mututal information
statistics
p (X ∣D Z)p (Y ∣Z)D p (X,Y ∣Z)D
d (D) =I E [D(p (X,Y ∣Z)∣∣p (X∣Z)p (Y ∣Z))]Z D D D
χ2
d (D) =χ2 ∣D∣ ∑x,y,z p (z)p (x∣z)p (y∣z)D D D
(p (x,y,z)−p (z)p (x∣z)p (y∣z))D D D D2
using frequencies in thedataset
large deviance rejects the null hypothesis (of conditional independence)
d(D) > tpick a threshold

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
measure the deviance of from
conditional mututal information
statistics
p (X ∣D Z)p (Y ∣Z)D p (X,Y ∣Z)D
d (D) =I E [D(p (X,Y ∣Z)∣∣p (X∣Z)p (Y ∣Z))]Z D D D
χ2
d (D) =χ2 ∣D∣ ∑x,y,z p (z)p (x∣z)p (y∣z)D D D
(p (x,y,z)−p (z)p (x∣z)p (y∣z))D D D D2
using frequencies in thedataset
large deviance rejects the null hypothesis (of conditional independence)
d(D) > tpick a threshold
p-value is the probability of false rejection pvalue(t) = P ({D : d(D) > t} ∣ X ⊥ Y ∣ Z)

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
large deviance rejects the null hypothesis (of conditional independence)
d(D) > tpick a threshold
p-value is the probability of false rejection pvalue(t) = P ({D : d(D) > t} ∣ X ⊥ Y ∣ Z)
over all possible datasets

conditional independence (CI) testconditional independence (CI) test
how to decide from the datasetX ⊥ Y ∣ Z D
large deviance rejects the null hypothesis (of conditional independence)
d(D) > tpick a threshold
p-value is the probability of false rejection pvalue(t) = P ({D : d(D) > t} ∣ X ⊥ Y ∣ Z)
over all possible datasets
it is possible to derive the distribution of deviance measures
e.g., distributionreject a hypothesis (CI) for small p-values (.05)
χ2
.05
.95

Structure learningStructure learning in BayesNets in BayesNets
family of methods
constraint-based methodsestimate cond. independencies from the data
find compatible BayesNets
search over the combinatorial space, maximizing a score
Bayesian model averagingintegrate over all possible structures

Mutual informationMutual information
how much information does X encode about Y?
reduction in the uncertainty of X after observing Y

Mutual informationMutual information
how much information does X encode about Y?
I(X,Y ) = H(X) − H(X∣Y )
reduction in the uncertainty of X after observing Y
conditional entropy p(x)H(p(y∣x))∑x

Mutual informationMutual information
how much information does X encode about Y?
I(X,Y ) = H(X) − H(X∣Y ) = H(Y ) − H(Y ∣X)
reduction in the uncertainty of X after observing Y
symmetric = I(Y ,X)
conditional entropy p(x)H(p(y∣x))∑x

Mutual informationMutual information
how much information does X encode about Y?
I(X,Y ) = H(X) − H(X∣Y ) = H(Y ) − H(Y ∣X)
reduction in the uncertainty of X after observing Y
symmetric = I(Y ,X)
I(X,Y ) = p(x, y) log( )∑x,y p(x)p(y)p(x,y)
conditional entropy p(x)H(p(y∣x))∑x

Mutual informationMutual information
how much information does X encode about Y?
I(X,Y ) = H(X) − H(X∣Y ) = H(Y ) − H(Y ∣X)
reduction in the uncertainty of X after observing Y
symmetric = I(Y ,X)
= D (p(x, y)∥p(x)p(y))KL
I(X,Y ) = p(x, y) log( )∑x,y p(x)p(y)p(x,y)
positive
conditional entropy p(x)H(p(y∣x))∑x

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i
= log p(x ∣∑i∑(x ,Pa )∈Di x ii Pa ; θ )x i i∣Pa i

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i
= log p(x ∣∑i∑(x ,Pa )∈Di x ii Pa ; θ )x i i∣Pa i
= N p (x,Pa ) log p(x ∣∑i∑x ,Pa i x iD x i i Pa ; θ )x i i∣Pa i
using the empirical distribution

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i
= log p(x ∣∑i∑(x ,Pa )∈Di x ii Pa ; θ )x i i∣Pa i
= N p (x,Pa ) log p(x ∣∑i∑x ,Pa i x iD x i i Pa ; θ )x i i∣Pa i
use MLE estimate ℓ(D, θ ) =∗ N p (x ,Pa ) log p (x ∣∑i∑x ,Pa i x iD i xi D i Pa )xi
using the empirical distribution

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i
= log p(x ∣∑i∑(x ,Pa )∈Di x ii Pa ; θ )x i i∣Pa i
= N p (x,Pa ) log p(x ∣∑i∑x ,Pa i x iD x i i Pa ; θ )x i i∣Pa i
use MLE estimate ℓ(D, θ ) =∗ N p (x ,Pa ) log p (x ∣∑i∑x ,Pa i x iD i xi D i Pa )xi
= N p (x ,Pa ) log + log p (x )∑i∑x ,Pa i x iD i x i
(p (x )p (Pa )D i D x i
p (x ,Pa )D i x iD i )
using the empirical distribution

MLE in Bayes-nets MLE in Bayes-nets mutual information formmutual information form
log-likelihood ℓ(D; θ) = log p(x ∣∑x∈D∑i i Pa ; θ )x i i∣Pa i
= log p(x ∣∑i∑(x ,Pa )∈Di x ii Pa ; θ )x i i∣Pa i
= N p (x,Pa ) log p(x ∣∑i∑x ,Pa i x iD x i i Pa ; θ )x i i∣Pa i
use MLE estimate ℓ(D, θ ) =∗ N p (x ,Pa ) log p (x ∣∑i∑x ,Pa i x iD i xi D i Pa )xi
= N p (x ,Pa ) log + log p (x )∑i∑x ,Pa i x iD i x i
(p (x )p (Pa )D i D x i
p (x ,Pa )D i x iD i )
using the definition of mutual information = N I (X ,Pa ) −∑i D i X iH (X )D i
using the empirical distribution

Optimal solution for Optimal solution for treestreeslikelihood score ℓ(D, θ ) =∗ N I (X ,Pa ) −∑i D i X i
H (X )D i

Optimal solution for Optimal solution for treestreeslikelihood score ℓ(D, θ ) =∗ N I (X ,Pa ) −∑i D i X i
H (X )D i
does not depend on structure

Optimal solution for Optimal solution for treestreeslikelihood score ℓ(D, θ ) =∗ N I (X ,Pa ) −∑i D i X i
H (X )D i
does not depend on structure
I (X ,X )D i j

Optimal solution for Optimal solution for treestreeslikelihood score ℓ(D, θ ) =∗ N I (X ,Pa ) −∑i D i X i
H (X )D i
structure learning algorithms use mutual information in the structure search:
Chow-Liu algorithm: find the max-spanning tree: edge-weights = mutual information
add direction to edges later
make sure each node has at most one parent (i.e., no v-structure)
does not depend on structure
I (X ,X )D i j
I (X ,X ) =D j i I (X ,X )D i j

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θlog
score (G,D) =B log P (D∣G) + log P (G)

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
logscore (G,D) =B log P (D∣G) + log P (G)
G

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
assuming local and global parameter independence
factorizes to the marginal likelihood of each node
logscore (G,D) =B log P (D∣G) + log P (G)
G

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
assuming local and global parameter independence
factorizes to the marginal likelihood of each node
logscore (G,D) =B log P (D∣G) + log P (G)
G
for Dirichlet-multinomial has closed form

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
assuming local and global parameter independence
factorizes to the marginal likelihood of each node
logscore (G,D) =B log P (D∣G) + log P (G)
G
for Dirichlet-multinomial has closed form
score (G,D) ≈B ℓ(D, θ ) −∗G log(∣D∣)K2
1Bayesian Information Criterion (BIC)
for large sample size
any exp-family member
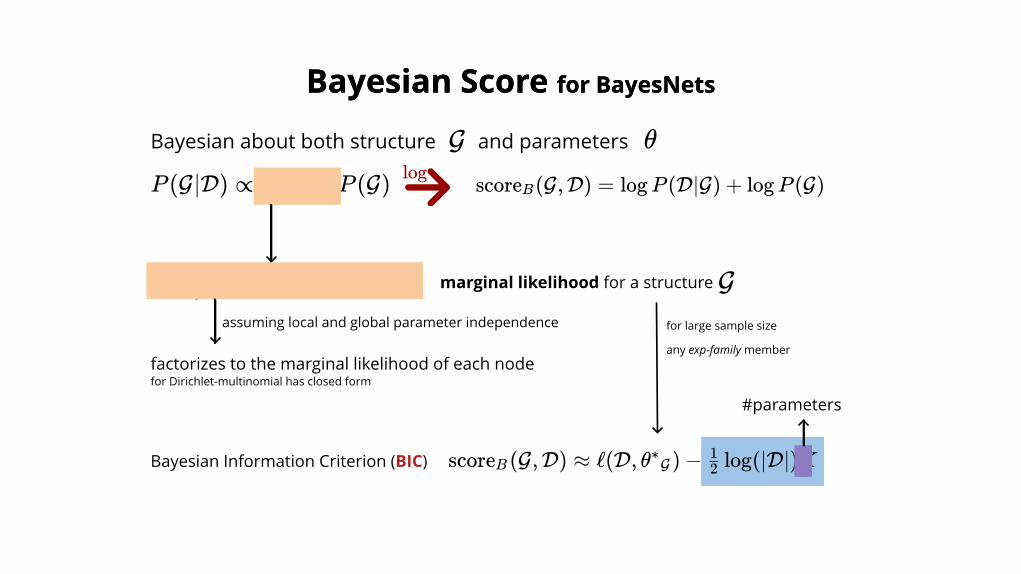
Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
assuming local and global parameter independence
factorizes to the marginal likelihood of each node
logscore (G,D) =B log P (D∣G) + log P (G)
G
for Dirichlet-multinomial has closed form
score (G,D) ≈B ℓ(D, θ ) −∗G log(∣D∣)K2
1Bayesian Information Criterion (BIC)
#parameters
for large sample size
any exp-family member

Bayesian about both structure and parameters
Bayesian Score Bayesian Score for BayesNetsfor BayesNets
P (G∣D) ∝ P (D∣G)P (G)
G θ
P (D∣θ,G)P (θ ∣∫θ∈Θ G
G)dθ marginal likelihood for a structure
assuming local and global parameter independence
factorizes to the marginal likelihood of each node
logscore (G,D) =B log P (D∣G) + log P (G)
G
for Dirichlet-multinomial has closed form
score (G,D) ≈B ℓ(D, θ ) −∗G log(∣D∣)K2
1Bayesian Information Criterion (BIC)
#parameters
for large sample size
any exp-family member
Akaike Information Criterion (AIC) ℓ(D, θ ) −∗G K2
1

Bayesian Score Bayesian Score for BayesNetsfor BayesNets
Example
G 1
G 2
= ∣D∣
The Bayesian score is biased towards simpler structures

Bayesian Score Bayesian Score for BayesNetsfor BayesNets
Example The Bayesian score is biased towards simpler structures
= ∣D∣
data sampled from ICU alarm Bayesnet
Bayesian score of the true model (509 params.)simplified model (359 params)
simplified model (214 params)

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)
local search using: edge additionedge deletionedge reversal

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)
local search using: edge additionedge deletionedge reversal
O(N )2 possible moves

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)
local search using: edge additionedge deletionedge reversal
O(N )2 possible moves
collect sufficient statistics (frequencies)estimate the score

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)
local search using: edge additionedge deletionedge reversal
use the decomposition of the score
O(N )2 possible moves
collect sufficient statistics (frequencies)estimate the score

Structure searchStructure search
is NP-hardarg max Score(D,G)G
use heuristic search algorithms (discussed for MAP inference)
local search using: edge additionedge deletionedge reversal
use the decomposition of the score
O(N )2 possible moves
collect sufficient statistics (frequencies)estimate the score
example ICU-alarm network

SummarySummary
Structure learning is NP-hardMake assumptions to simplify:

SummarySummary
Structure learning is NP-hardMake assumptions to simplify:
constraint-based methods:limit the max number of parents
rely on CI tests
identifies the I-equivalence class

SummarySummary
Structure learning is NP-hardMake assumptions to simplify:
constraint-based methods:limit the max number of parents
rely on CI tests
identifies the I-equivalence class
score based methods:tree structure
use a Bayesian score + heuristic search
finds a locally optimal structure

















