Probabilistic Query Expansion Using Query Logs Hang Cui Tianjin University, China Ji-Rong Wen Microsoft Research Asia, China Jian-Yun Nie University of Montreal Wei-Ying Ma Microsoft Research Asia, China
Transcript
Probabilistic Query Expansion Using Query Logs
Hang CuiTianjin University, China
Ji-Rong WenMicrosoft Research Asia, China
Jian-Yun NieUniversity of Montreal
Wei-Ying MaMicrosoft Research Asia, China
Outline
MotivationsCentral ideas
Establishing correlations between query terms and document terms
Query expansion based on term correlations
Evaluations
Conclusions
Motivations
More severe challenges on web searching Very short queries (less than two words) Inconsistency of term usages on two sides
The Web is not well-organized Users express queries with their own vocabulary
Most search engines are keyword based.
Previous query expansion techniques focus on one side only – documents
Our solution – concentrate on both sides
Big gap between the query space and the document space
Query space and document space.
For each document, measure the cosine value of the internal angle between the two spaces.
Big gap: 73.68 degree on avera
ge (Cos A=0.28)
Cosine Similarity
0
2000
4000
6000
8000
10000
12000
0-0.1 0.1-0.2
0.2-0.3
0.3-0.4
0.4-0.5
0.5-0.6
0.6-0.7
0.7-0.8
0.8-0.9
0.9-1
Similarity Range
Nu
mb
er o
f D
ocu
men
ts
Outline
Motivations
Central ideasEstablishing correlations between query terms and document terms
Query expansion based on term correlations
Evaluations
Conclusions
Principle of exploiting query logs
Query logs Means to explore the query side. session= := <query text> [clicked document]
Central idea Log-based query expansion. Probabilistic correlations between query terms
and index terms in the clicked documents against the respective queries.
Assumption
Assumption The clicked documents are relevant to the given
query.
Reasonable because: Users do not click documents randomly. Stable from a statistical view Our previous work on query clustering proved
it.
Compared with Local Feedback and Relevance Feedback
1
2
3
4
N
Local Feedback
…..
…..
Relevance Feedback
Feedback
User A
User B
User C
Log-Based Query Expansion
Expansion
Terms
Expansion
Terms
ExpansionTerms
Clicked
Clicked
ClickedClicked
Characteristic of the log-based query expansion
Local technique in general. Feasibility in computation.
No initial retrieval.
Reflecting most users’ intentions An example
Evolve with the accumulations of user usages
Outline
Motivations
Central ideas
Establishing term correlations Query expansion based on term correlations
Evaluations
Conclusions
Query sessions as a bridge
Query Sessions
Netscape
Bill Gates
Java
Microsoft
Programming
Windows
OS
#Doc1#Doc2*Query1
#Doc3*Query2
#Doc1#Doc4*Query3
Document SpaceQuery Space
Correlations between query terms and document terms
Bill Gates
Java
Windows
Netscape
Microsoft
Programming
OS
0.83
0.890.24
0.17
0.670.04
Query Space Document Space
Term-Term Probabilistic correlations
Term-Term Correlations are represented as the conditional probability:
Query Term
Index Term
#Doc1#Doc2*Query
Term-Term probabilistic correlations (Cont)
)(
),()|(
)()(
)()()(
qi
qk
qi
qikq
ik wf
DwfwDP
)(max)|(
)(
)()(
dtk
Dt
djk
kdj W
WDwP
k
Estimate of the two conditional probabilities.
))(
),()|(()|(
)()(
)()()()()(
SD
qi
qk
qi
qik
kdj
qi
dj
kwf
DwfDwPwwP
Outline
MotivationsCentral ideasEstablishing term correlations
Query expansion based on term correlationsEvaluationsConclusions
Query expansion based on term correlations
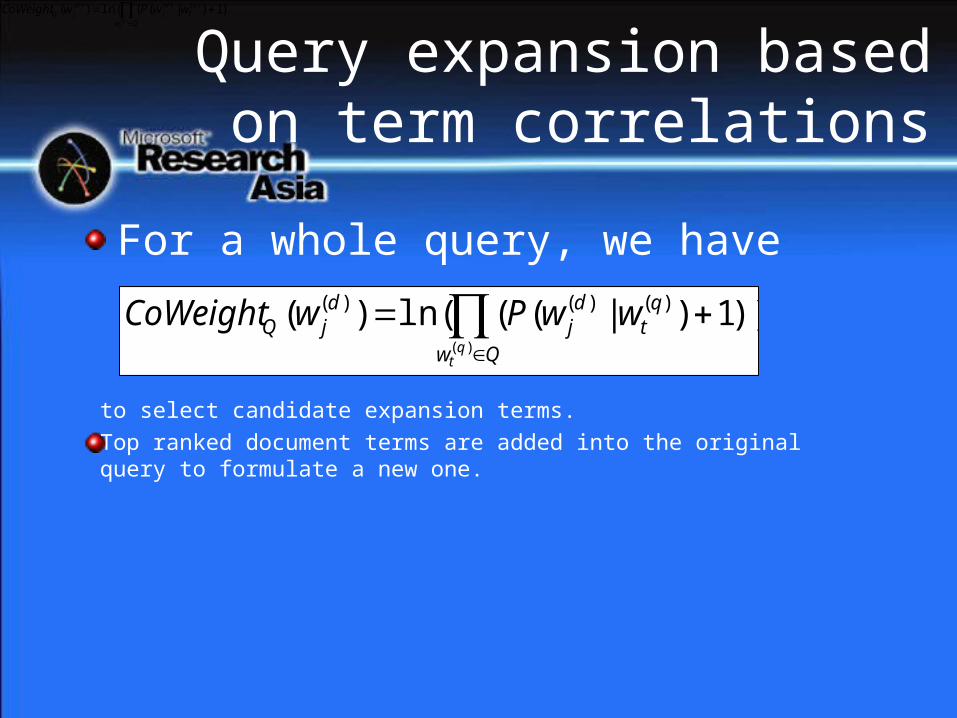
For a whole query, we have
Qw
qt
dj
djQ
qt
wwPwCoWeight)(
))1)|((ln()( )()()(
Qw
qt
dj
djQ
qt
wwPwCoWeight)(
))1)|((ln()( )()()(
to select candidate expansion terms.
Top ranked document terms are added into the original query to formulate a new one.
Outline
Motivations
Central ideas
Establishing term correlations
Query expansion based on term correlations
EvaluationsConclusions
Data and methodology
Data Two month query logs (Oct 2000-Dem 2000) 41,942 documents 30 evaluation queries (mostly are short queries)
Document relevance judged by human assessors.
Comparing our method with the baseline and the Local Context Analysis (LCA)
Experiment I---Retrieval effectiveness
Average Improvement 75.42% over
Baseline 38.95% over
LCA
Significant improvement from a statistical view
0
10
20
30
40
50
60
70
10 20 30 40 50 60 70 80 90 100
Number of Ret r i eved Documents
Aver
age
Prec
isio
n
Basel i neOn Log ExpLCA Exp
Experiment II---Quality of expansion terms
Examining 50 expansion terms obtained by the log-based method and LCA.
LC Analysis (base)
Log Based
Improvement (%)
Relevant Terms (%)
23.27 30.73 +32.03
Example – “Steve Jobs” “Apple Computer”, “CEO”, “Macintosh”, “Microsoft”,
“GUI”, “Personal Computers”
Experiment III---Impact of phrases
For TREC queries, phrases may not be as effective as expected.
Not the case in short query context. A example.
Phrases are extracted from user logs.
Experiments show 11.37% improvement when using phrases in average.
Experiment IV---Impact of number of expansion terms
The more expansion terms, the better?
The best performance can be achieved by adding 40 to 60 expansion terms.
Average Preci si on f or Var i ous Number ofExpansi on Terms
0. 250. 260. 270. 280. 290. 3
0. 310. 32
10 20 30 40 50 60 70 80 90 100
Number of Expansi on Terms
Aver
age
Prec
isio
n
Summary for evaluation
The log-based query expansion produces significant improvements over the baseline and LCA in terms of precision and recall.
Query expansion is of great importance for short queries on the Web.
Phrases can improve the performance of search engines.
Outline
Motivations
Central ideas
Establishing term correlations
Query expansion based on term correlations
Evaluations
Conclusions
Conclusions
We show how big the gap exists between the query space and the document space.
A new log-based query expansion method considering both sides of the problem.
Experimental results show our solution is effectual for short queries in Web searching.
User log mining is a promising direction for future research.