48
Prof. Panos Ipeirotis Search and the New Economy Session 1 Basics of Web Search Engines
| Date post: | 16-Dec-2015 |
| Category: |
Documents |
| Upload: | clinton-rich |
| View: | 215 times |
| Download: | 1 times |

Prof. Panos Ipeirotis
Search and the New Economy
Session 1
Basics of Web Search Engines

Who am I?
• Prof. Panagiotis Ipeirotis (a.k.a. Panos)– Email: [email protected]– AIM: ipeirotis– Office: KMC 8-84– (see “Staff Information” on Blackboard)
• Joined Stern in 2004, “A Computer Scientist in a Business School”
• Research in web mining and in data integration – EconoMining Project:
• Is there positive buzz about iPod Touch? What is the characteristic for which customers would pay the most?
• Which seller on eBay has a reputation of delivering fast? How much higher the merchant can charge and still make a sale?
– Web Searching:• What mergers and acquisitions took place in 2007?

Who are you?
http://pages.stern.nyu.edu/~panos/teaching/W08.html
Mixture of marketing / media + technology backgrounds
70% have LinkedIn accounts Penetration of Facebook accounts less obvious

Class days, time, place
• KMC 3-120• Tuesday Jan 29 (6pm-9pm)• Thursday Jan 31 (6pm-9pm)• Sunday Feb 3 (9am-12n)• Sunday Feb 3 (1pm-4pm)• Tuesday Feb 5 (6pm-9pm)• Thursday Feb 7 (6pm-9pm)
Course Overview
Teaching assistant
• Nikolay Archak ([email protected])
Course Overview
Class requirements
• 6 Assignments
• One take-home final exam or a project• Both due on February 14th
• Submit your proposal for a project by February 1st

Blackboard
• http://sternclasses.nyu.edu/• Use your Stern username and password• Confirm that you can access the course as soon as possible
• Information about your classroom colleagues• All readings• All assignment descriptions• All assignment submissions (well, almost)• All online discussions• Grades, announcements, exam guidelines, stock tips….
Course Overview

Key Objectives of Course
A. Understand the technology behind “search” (Jan 29)
How search engines discover and rank web pages? How can we identify issues and opportunities in a web site? (Mainly lecture-based)
B. Understand search engine advertising (Jan 31)
Advertising on the web: banner ads, contextual ads, keyword ads, Optimizing a website for organic and paid search (Lecture + example discussion)
C. Harnessing the wisdom of the crowds (Feb 3)
Who owns your data? Privacy threats, the changing face of intellectual property (Case presentation + discussion)
Leveraging social networks for marketing, blog analysis, opinion mining and buzz tracking, long tail and recommender/reputation systems, prediction markets and wikis (Lecture + Case Discussion, focus on cases)
D. Data ownership issues (Feb 5)
At its core: A hands-on, “how-to mentality” class

Questions?

Objectives of today’s class
1. Understand the disruptive power of information
2. Learn how information is stored on the Web
3. Learn how search engines discover and rank information
4. Learn how users search for information (Analytics)

Information is ubiquitous
How IT changed these industries?
Telephony
Newspapers
Music
Radio
Advertising
Banking
Travel
Video/TV
Retail / POS Stock MarketManufacturing

Information technology is ubiquitous
Telephony
Newspapers
Music
Radio
Advertising
Banking
Travel
Video/TV
Retail / POS Stock MarketManufacturing
What is common in all disruptive changes?

Key concepts
1. Digitization
2. Information Asymmetries– At the root of every disruption caused by search
technologies– “Web search” is only part of the equation
Google's mission is to organize the world's information and make it
universally accessible and useful

Objectives of today’s class
1. Understand the disruptive power of information
2. Learn how information is stored on the Web
3. Learn how search engines discover and rank information
4. Learn how users search for information
In Assignment 1 you created a website
• Can you find it on Google?– If yes, how– If no, why?
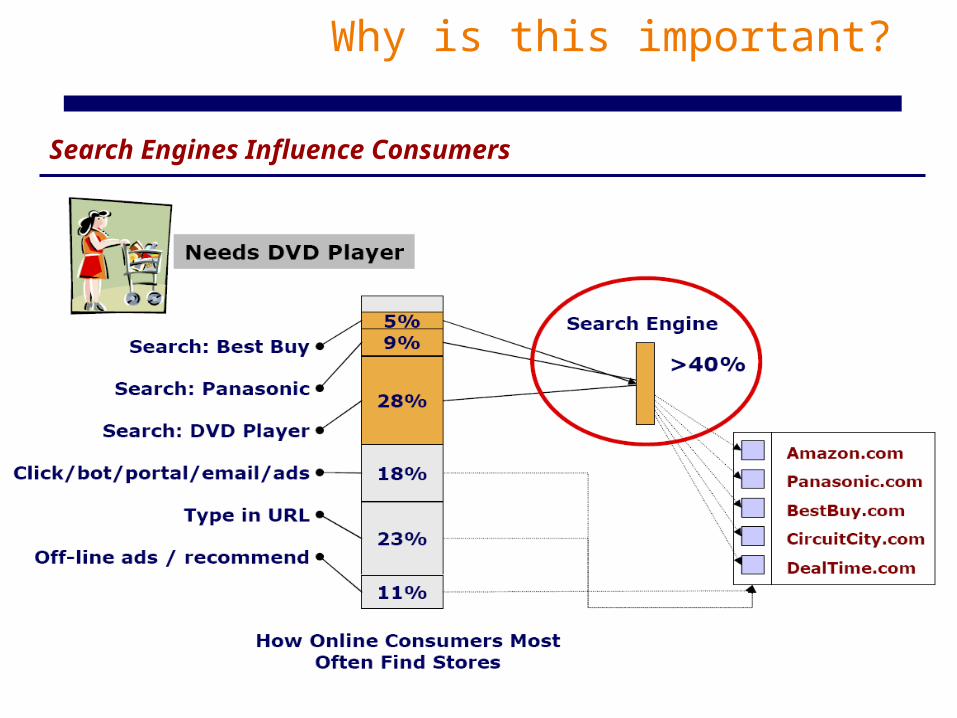
Why is this important?
Search Engines Influence Consumers

Slide adapted from Marti Hearst, Lew & Davis
Let’s cover the basics
• Internet and Web are not synonymous
• Internet is a global communication network connecting millions of computers
• World Wide Web (WWW) is one component of the Internet, along with e-mail, chat, etc
Internet vs. WWW

How Does the WWW Work?
• You created a web page index.html for the class on your PC
• Then you copy the page to a directory /sne/w08/ on a the NYU computer that runs a “web server”
• The computer’s name is “homepages.nyu.edu”
Web server

Reading a URL
http://homepages.nyu.edu/sne/w08/index.html
http:// = HyperText Transfer Protocol (i.e., Web) homepages = service name (often is www).nyu = domain name .edu/ = top level domaini141/ = directory namef07/ = directory nameindex.html = file name of web page
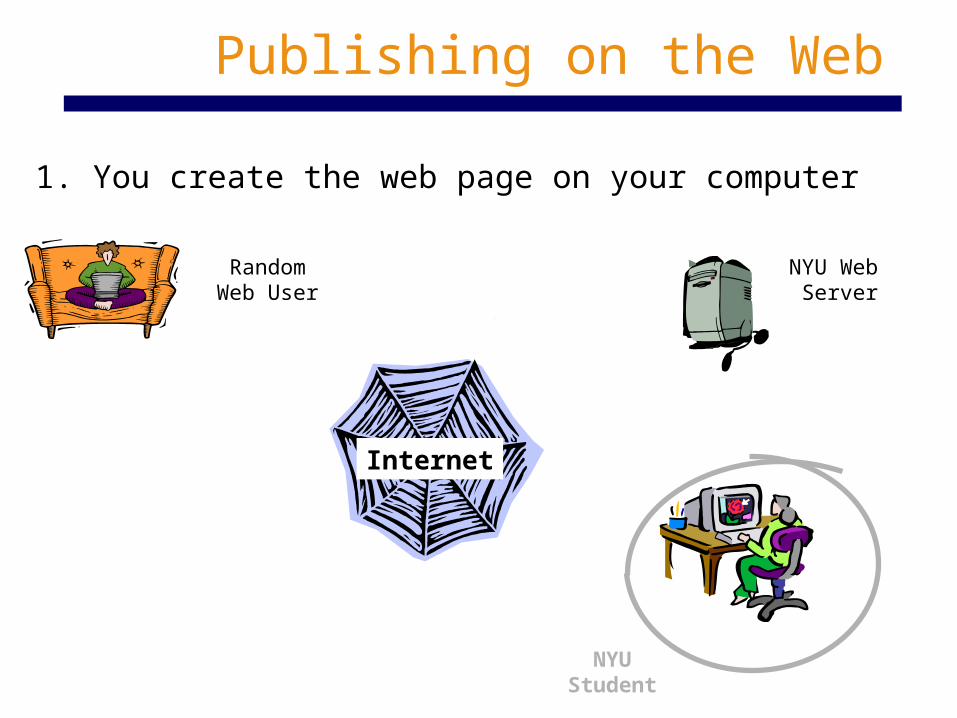
Publishing on the Web
1. You create the web page on your computer
Internet
NYU Web Server
RandomWeb User
NYU Student

2. You send the files to the NYU Web server
Publishing on the Web
NYU Web Server
Internet
RandomWeb User
FTP
NYU Student

3. A web user requests your home page URL
Publishing on the Web
Internet
NYU Web Server
RandomWeb User
NYU Student
http request

4. The NYU Web server serves up your page
Publishing on the Web
Internet
NYU Web Server
RandomWeb User
Stern StudentClient
http response

When anyone can publish, how do we find what we need?
• The information is spread across multiple autonomous computers
• With millions of choices, how do we find what we need?
Information on the Web
?Internet

Objectives of today’s class
1. Understand the disruptive power of information
2. Learn how information is stored on the Web
3. Learn how search engines discover and rank information
4. Learn how users search for information

How Search Engines Work
i. Gather the contents of all web pages (using a program called a crawler or spider)
ii. Organize the contents of the pages in a way that allows efficient retrieval (indexing)
iii. Take in a query, determine which pages match, and show the results (ranking and display of results)
Three main parts:

How do Search Engines Discover Information?
• How do crawlers find web pages? Start with a list of domain names,
visit the home pages there. Look at the hyperlink on the home
page, and follow those links to more pages.
Keep a list of URLs visited, and those still to be visited.
Each time the program loads in a new HTML page, add the links in that page to the list to be crawled.
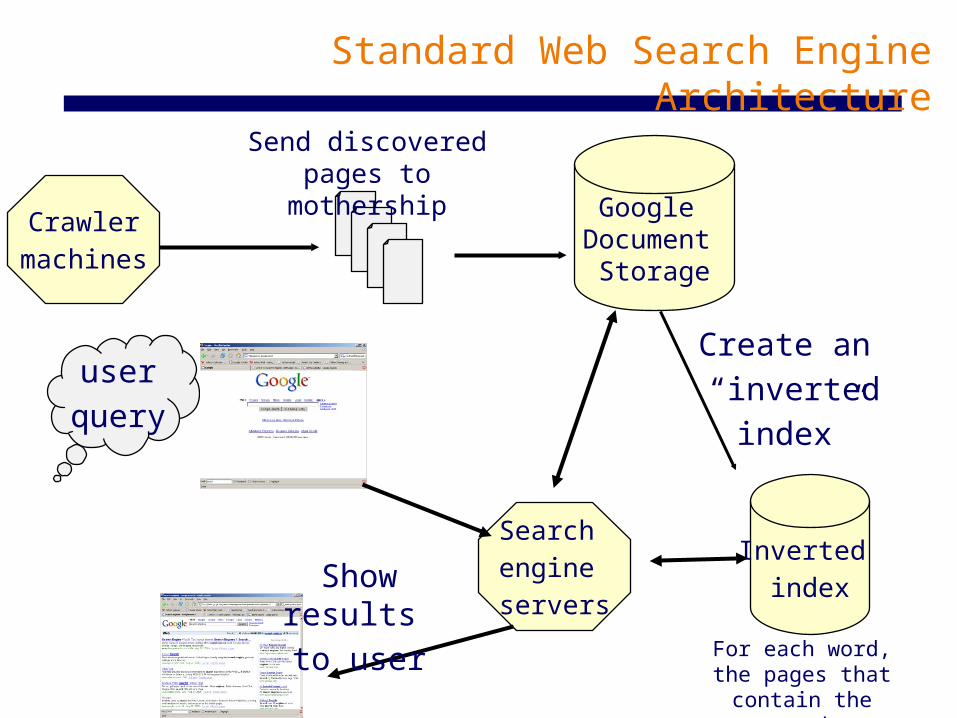
Standard Web Search Engine Architecture
Inverted index
Search engine servers
Google Document
Storage
Crawlermachines
Send discovered pages to mothership
Create an “inverted
index”
userquery
Show results to user For each word,
the pages that contain the word

Crawler behavior varies
• Parts of a web page that are indexed– Until recently, only the first few parts of the page
were retrieved/stored
• How deeply a site is indexed – Google/Yahoo/MSN get only the first top levels
• How frequently the site is crawled– Can be few minutes (news), hours (blogs), days, or
weeks (my site )
What are the implications?

Indexing
Record the following information about each page
• List of words– Is the word in the title?– How far down in the page?– Was the word in boldface?
• URLs of pages pointing to this one
• Anchor text on pages pointing to this one
• …many other “secret ingredients”

The importance of anchor text
<a href=http://behind-the-enemy-lines …>An MBA course the way it should be</a>
The anchor text summarizes what the website is about.
(Gives also birth to the “GoogleBombing” phenomenon)http://en.wikipedia.org/wiki/Google_bomb
<a href=http://behind-the-enemy-lines…>Finally, another course on prediction markets</a>

Text-based retrieval is not enough
• So far, we examined how text is used for retrieving pages
• However, text alone is not enough. Why?

Measuring Importance of Linking
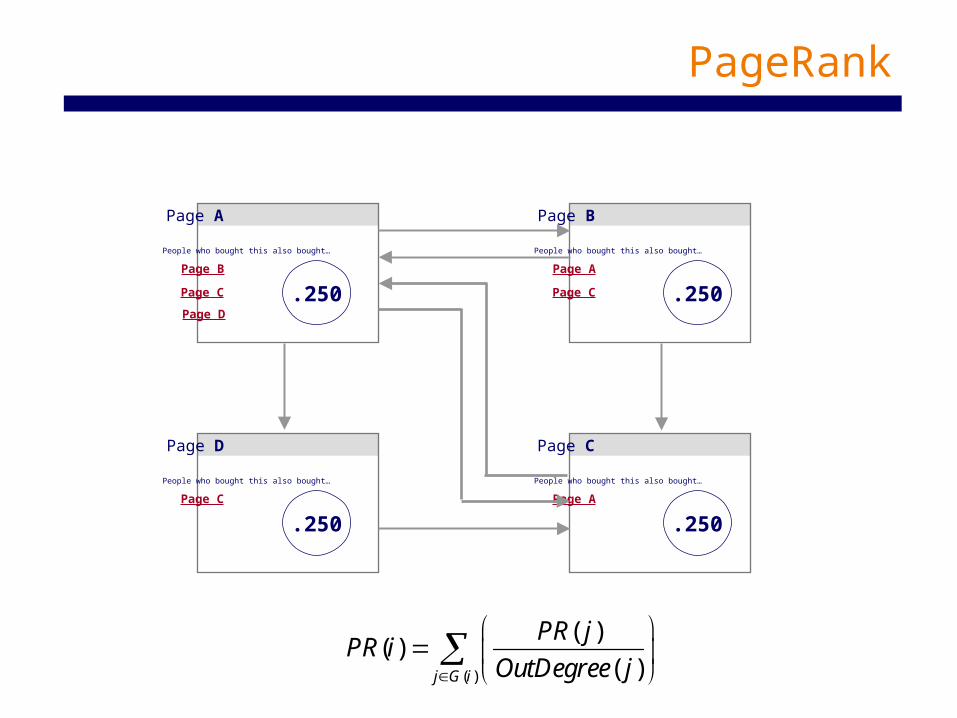
PageRank Algorithm
• Idea: important pages are pointed to by other important pages
• Method:– Each link from one page to another is counted
as a “vote” for the destination page • The number of incoming links is important!• But it is not enough!
– But each “vote” is different! Pagerank places more importance to votes that come from pages with large number of votes (and so on, and so on)
• Compare, for example, the cases for the circled page in cases A and B
B
A

People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C
Computing PageRank – don’t need to ‘know’
( )
( )( )
( )j G i
PR jPR i
OutDegree j
(ignoring damping factor for illustration)

People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C
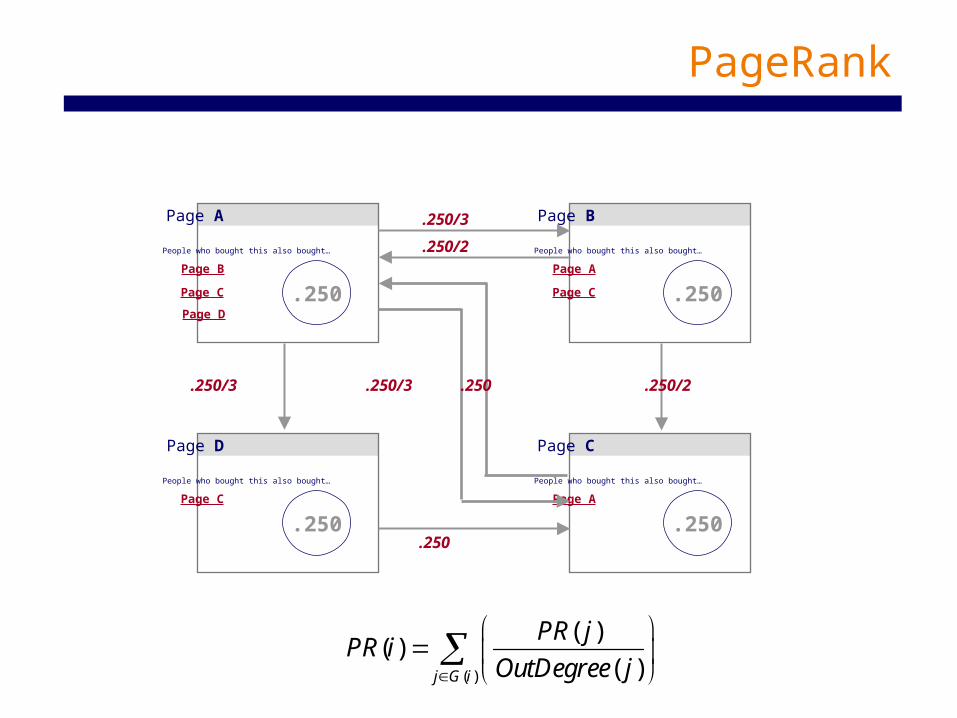
Computing PageRank
( )
( )( )
( )j G i
PR jPR i
OutDegree j
PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C.250 .250
.250 .250
( )
( )( )
( )j G i
PR jPR i
OutDegree j
PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C.250 .250
.250 .250
.250/3
.250
.250/3
.250/2
.250.250/3 .250/2
( )
( )( )
( )j G i
PR jPR i
OutDegree j

PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C
.250/3
.250
.250/3
.250/2
.250.250/3 .250/2
.375 .083
.083 .458
( )
( )( )
( )j G i
PR jPR i
OutDegree j

PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C
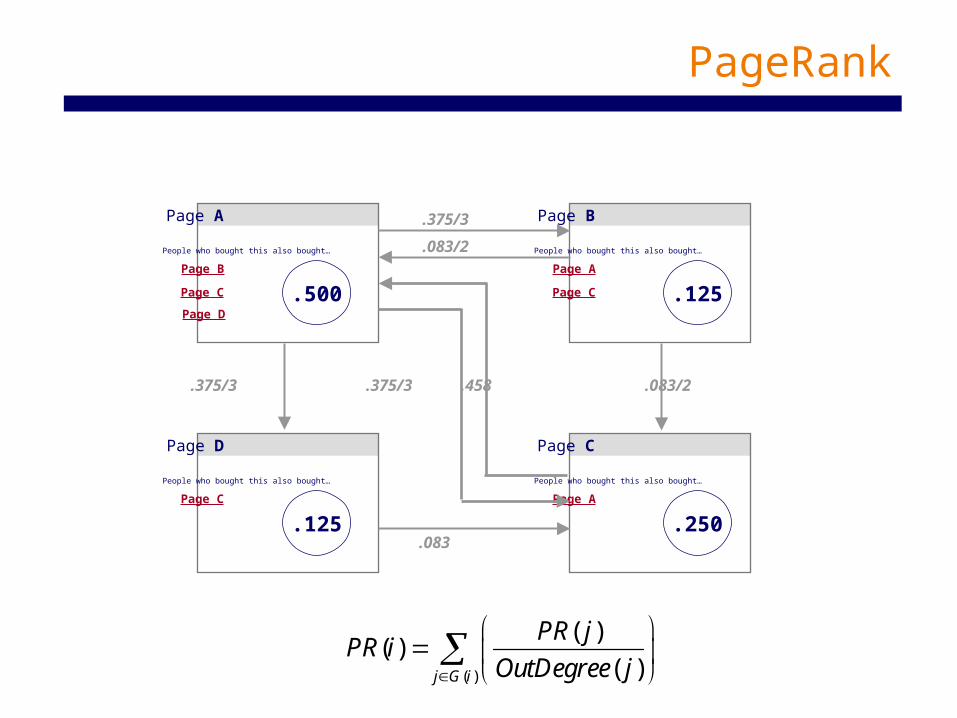
.375/3
.083
.375/3
.083/2
.458.375/3 .083/2
.375 .083
.083 .458
( )
( )( )
( )j G i
PR jPR i
OutDegree j
PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C
.375/3
.083
.375/3
.083/2
.458.375/3 .083/2
.500 .125
.125 .250
( )
( )( )
( )j G i
PR jPR i
OutDegree j

PageRank
People who bought this also bought…
Page A
Page B
Page C
Page D
People who bought this also bought…
Page D
Page C
People who bought this also bought…
Page C
Page A
People who bought this also bought…
Page B
Page A
Page C.400 .133
.133 .333
.400/3
.133
.400/3
.133/2
.333.400/3 .133/2
( )
( )( )
( )j G i
PR jPR i
OutDegree j

How PageRank is used
1. Locate the pages that contain the query text2. Weight the “text score” with the “link score”3. Rank results
Lesson: PageRank of competitors matters!Do not obsess (only) about your PageRank

Cool! Let’s Get some PageRank
• Obvious incentives to game the system
• Or at least to speed up the process of going up in the results

A few spam technologies
• Cloaking– Serve fake content to search engine robot– DNS cloaking: Switch IP address.
Impersonate
• Doorway pages– Pages optimized for a single keyword that re-
direct to the real target page (typically get real content from legitimate pages and synthesize)
• Keyword Spam– Misleading meta-keywords, excessive
repetition of a term, fake “anchor text”– Hidden text with colors, CSS tricks, etc.
Is this a SearchEngine spider?
N
Y
SPAM
FakeDoc
Cloaking
Meta-Keywords = “… London hotels, hotel, holiday inn, hilton, discount, Pageing, reservation, sex, mp3, britney spears, viagra, …”

Gaming PageRank: Link spam
• Link spam: Inflating the rank of a page by creating nepotistic links to it– From own sites: Link farms– From partner sites: Link exchanges– From unaffiliated sites (e.g. blogs, guest books, web
forums, etc.)
• The more links, the better– Generate links automatically– Use scripts to post to blogs– Synthesize entire web sites– Synthesize many web sites (DNS spam)
• The more important the linking page, the better– Buy expired highly-ranked domains– Post links to high-quality blogs

Gaming PageRank and Trust
TrustRank Algorithm
• Initial votes come only from trusted pages
• Compare, for example, the cases for the circled page in cases A and B
• The main reason behind the initial success of Google
• Get links from trusted, quality sites!
B
A
NYU student
MIT student
Links from untrusted sources

Other ranking factors
• Location, Location, Location...and Frequency– Query words in title, or in first few sentences– The more frequent the query words, the better
• Clickthrough measurement– How often users click on your URL, when they see it– How long do they stay (using toolbars!)

How to rank high in the results
• Position your keywords (title, headings, early on page)
• Make text visible (no tiny fonts, no white-on-white)
• “Alt text” for images: Accessibility + search engines• Frames can kill, (Flash, AJAX also problematic)
• Have relevant content• Do not change topics• Build links (nice to build a real community)• Just say no to search engine spamming
• Submit your key pages• Verify often your listing

Objectives of today’s class
1. Understand the disruptive power of information
2. Learn how information is stored on the Web
3. Learn how search engines discover and rank information
4. Learn how users search for information (after the break)

















