Project Beehive: A Hardware/Soware Co-Designed Platform for Runtime and Architectural Research Christos Kotselidis, Andrey Rodchenko, Colin Barre, Andy Nisbet, John Mawer, Will Toms, James Clarkson, Cosmin Gorgovan, Amanieu d’Antras, Yaman Cakmakci, anos Stratikopoulos, Sebastian Werner, Jim Garside, Javier Navaridas, Antoniu Pop, John Goodacre, Mikel Luj´ an Advanced Processor Technologies Group e University of Manchester [email protected]1 INTRODUCTION Traditionally, soware and hardware providers have been delivering signicant performance improvements on a yearly basis. Unfortunately, this is no longer feasible. Predictions about ”dark silicon” [25] and resiliency [53], especially in the forthcoming exascale era [17], suggest that traditional approaches to computing problems are impeded by power constraints and process manufacturing. Furthermore, since single-threaded performance has been saturated both at the hardware and the soware layers, new ways for pushing the boundaries have emerged. Aer the introduction of multi and many core systems, heterogeneous computing and ad-hoc acceleration, via ASICs and FPGAs [34, 65], are advancing into mainstream computing. e extreme scaling of current architectures, from low- power wearables to high-performance computing, along with the diversity of programming languages and soware stacks, create a wide spectrum of space exploration for achiev- ing optimal energy-ecient results. Co-designing an archi- tectural solution at the system-level 1 requires tight integra- tion and collaboration between teams, that have typically been working in isolation. e design-space to be explored is vast, and there is the potential that a poor, even if well intentioned, decision will propagate through the entire co- designed stack. us, amending the consequences at a later date may prove extremely complex and expensive, if not impossible. In this paper we present Beehive: a complete full-system hardware/soware co-designed platform for rapid prototyp- ing and experimentation (All the available hardware and soware components of Beehive will be publicly available). Beehive enables co-designed optimizations from the applica- tion level down to the system and hardware level, enabling accurate decision making for architectural and runtime op- timizations. As a use-case, we accelerate and optimize the 1 In this context we refer to architectural solution as a co-designed solu- tion that spans from a running application to the underlying hardware architecture. complex KinectFusion [47] Computer Vision application in numerous ways through Beehive’s highly integrated stack achieving up to 43x performance improvements. In detail, Beehive makes the following contributions: • Enables co-designed research and development for traditional and emerging applications and workloads: To achieve this, we tightly integrate the soware and hardware layers of the stack in a unied manner while expanding Beehive’s reach to complex applications and workloads (Section 2.2). We show- case that capability by implementing a Java-based version of KinectFusion and co-designing it through Beehive’s stack. • Enables co-designed compiler and runtime re- search for multiple dynamic and non-dynamic programming languages in a unied manner: is is achieved by unifying under the same com- pilers and runtimes, high-quality production and research Virtual Machines able to execute transpar- ently multiple programming languages (Section 2.3.1). • Enables heterogeneous processing on a variety of platforms such as ARM (ARMv7 and Aarch64), and x86: e unied runtime layer has been ex- tended to support multiple ISAs scaling from high- performing x86 to low-power ARM architectures (Section 2.3). We showcase that capability by eval- uating standard benchmarks along with the Kinect- Fusion use case. • Provides fast prototyping and experimentation on heterogeneous programming on GPGPUs, SIMD units, and FPGAs: e novel Tornado, Indigo, and MAST modules achieve transparent heterogeneous execution on GPGPUs, SIMD units, and FPGAs re- spectively, without sacricing productivity (Sections 2.3.3, 2.3.2, 2.5). We showcase that capability by ac- celerating KinectFusion on GPGPUs, SIMD units, and FPGAs under the same infrastructure. arXiv:1509.04085v3 [cs.DC] 5 Jun 2017
Transcript
Project Beehive: A Hardware/So�ware Co-DesignedPlatform for Runtime and Architectural Research
Christos Kotselidis, Andrey Rodchenko, Colin Barre�, Andy Nisbet, John Mawer,Will Toms, James Clarkson, Cosmin Gorgovan, Amanieu d’Antras, YamanCakmakci, �anos Stratikopoulos, Sebastian Werner, Jim Garside, Javier
Navaridas, Antoniu Pop, John Goodacre, Mikel LujanAdvanced Processor Technologies Group
1 INTRODUCTIONTraditionally, so�ware and hardware providers have beendelivering signi�cant performance improvements on a yearlybasis. Unfortunately, this is no longer feasible. Predictionsabout ”dark silicon” [25] and resiliency [53], especially inthe forthcoming exascale era [17], suggest that traditionalapproaches to computing problems are impeded by powerconstraints and process manufacturing. Furthermore, sincesingle-threaded performance has been saturated both at thehardware and the so�ware layers, new ways for pushingthe boundaries have emerged. A�er the introduction ofmulti and many core systems, heterogeneous computingand ad-hoc acceleration, via ASICs and FPGAs [34, 65], areadvancing into mainstream computing.
�e extreme scaling of current architectures, from low-power wearables to high-performance computing, alongwith the diversity of programming languages and so�warestacks, create a wide spectrum of space exploration for achiev-ing optimal energy-e�cient results. Co-designing an archi-tectural solution at the system-level1 requires tight integra-tion and collaboration between teams, that have typicallybeen working in isolation. �e design-space to be exploredis vast, and there is the potential that a poor, even if wellintentioned, decision will propagate through the entire co-designed stack. �us, amending the consequences at a laterdate may prove extremely complex and expensive, if notimpossible.
In this paper we present Beehive: a complete full-systemhardware/so�ware co-designed platform for rapid prototyp-ing and experimentation (All the available hardware andso�ware components of Beehive will be publicly available).Beehive enables co-designed optimizations from the applica-tion level down to the system and hardware level, enablingaccurate decision making for architectural and runtime op-timizations. As a use-case, we accelerate and optimize the
1In this context we refer to architectural solution as a co-designed solu-tion that spans from a running application to the underlying hardwarearchitecture.
complex KinectFusion [47] Computer Vision application innumerous ways through Beehive’s highly integrated stackachieving up to 43x performance improvements.
In detail, Beehive makes the following contributions:
• Enables co-designed research anddevelopmentfor traditional and emerging applications andworkloads: To achieve this, we tightly integrate theso�ware and hardware layers of the stack in a uni�edmanner while expanding Beehive’s reach to complexapplications and workloads (Section 2.2). We show-case that capability by implementing a Java-basedversion of KinectFusion and co-designing it throughBeehive’s stack.
• Enables co-designed compiler and runtime re-search for multiple dynamic and non-dynamicprogramming languages in a uni�ed manner:�is is achieved by unifying under the same com-pilers and runtimes, high-quality production andresearch Virtual Machines able to execute transpar-ently multiple programming languages (Section 2.3.1).
• Enables heterogeneous processing on a varietyof platforms such asARM (ARMv7 andAarch64),and x86: �e uni�ed runtime layer has been ex-tended to support multiple ISAs scaling from high-performing x86 to low-power ARM architectures(Section 2.3). We showcase that capability by eval-uating standard benchmarks along with the Kinect-Fusion use case.
• Provides fast prototyping and experimentationonheterogeneous programming onGPGPUs, SIMDunits, and FPGAs: �e novel Tornado, Indigo, andMAST modules achieve transparent heterogeneousexecution on GPGPUs, SIMD units, and FPGAs re-spectively, without sacri�cing productivity (Sections2.3.3, 2.3.2, 2.5). We showcase that capability by ac-celerating KinectFusion on GPGPUs, SIMD units,and FPGAs under the same infrastructure.
arX
iv:1
509.
0408
5v3
[cs
.DC
] 5
Jun
201
7
• Enables co-designed architectural research onpower, performance, and resiliency techniquesvia high-performing simulators and real hard-ware: Along with a plethora of real hardware, Bee-hive integrates a number of high-performing sim-ulators in a uni�ed framework (Section 2.6). Weshowcase this capability by providing a novel hard-ware/so�ware co-designed optimization for Kinect-Fusion.
• Supports dynamic binary optimization techniquesvia instrumentation andoptimization at the sys-tem and chip level: Beehive extends its research ca-pabilities to novel micro-architectures by providingdynamic binary instrumentation and optimizationtechniques for all supported hardware architectures(Section 2.4).
�e paper is organized as follows: Section 2 explains thearchitecture of Beehive along with its individual compo-nents. Section 3 presents the Computer Vision applicationthat forms the use case in this paper. Section 4 presents thevarious co-designed optimizations applied to the selectedapplication along with their correspondent performance eval-uations. Finally, Sections 5 and 6 present the related work,the concluding remarks and the future vision of Beehive,respectively.
2 BEEHIVE ARCHITECTURE2.1 OverviewBeehive, as depicted in Figure 1, follows a multi-layeredapproach of highly co-designed components spanning fromthe application down to the hardware level. �e designphilosophy of Beehive revolves around �ve pillars:
(1) Rapid prototyping for developing full-stack opti-mizations e�ciently by using high-level program-ming languages.
(2) Diversity for tackling multiple application domains,programming languages, and runtime systems in auni�ed manner.
(3) Accuracy of obtained results by integrating and aug-menting state-of-the-art industrial-strength compo-nents.
(4) Maintainability of the platform keeping it on parwith the state-of-the-art in the long term.
(5) Scalability of the platform to complex systems andarchitectures in a seamless manner.
Beehive targets a variety of workloads ranging from tradi-tional benchmarks to emerging applications from a varietyof domains such as Computer Vision and Big Data. Further-more, as explained later in Section 2.2, Beehive allows mul-tiple implementations of complex applications in a varietyof programming languages in order to enable comparative
Heterogeneous Architectures
Aarch64
ARMv7
x86
GPUSFPGAs
VPUs ASICs
Resiliency
Simulators Emulated Architectures
MAMBODynamic Binary
Translator
Zsim
Com
pute
Pla
tfor
m
Maxine VM
T1X
TornadoHeterogeneous
Accelerator(OpenCL)
Operating System
Traditional Benchmarking (SpecJVM, Dacapo, etc.)
Computer Vision SLAM Applications
Big Data Applications
(Spark, Flink, Hadoop, etc.)DSLs (LLVM IR, etc.)
Full System Co-design
Pow
er
Per
form
ance Native
(C/C++)
ZZZ Services and Drivers (PIN, MAMBO, MAMBO-X64)
ISA extensions
App
licat
ions
Run
time
Laye
r
Scripting and Dynamic Languanges
(Ruby, Scala, R, etc.)
IndigoSIMD
Accelerator(SSE)
OpenJDKTruffle
Graal
Virtualization (KVM)
Client
Memory Manager (GC) Memory Manager (GC)
VoltspotMachine Learning(FEAST, KNN, SVM)
GEM5 Full System Simulator
HotspotNVSimMcPATCacti
MASTFPGA Accelerator
Framework
Fault Injection
Figure 1: Beehive architecture overview.
research amongst them. Beehive supports both managedand un-managed languages as explained in Subsection 2.3.Finally, applications can execute either directly on hardware,in-directly on hardware using a dynamic binary optimizationlayer, or inside Beehive’s simulator stack.
�e following subsections explain in detail each layer ofBeehive along with the supported applications, programminglanguages, and hardware platforms.
2.2 ApplicationsBeehive targets a variety of applications in order to enableco-designed optimizations in numerous domains. Whilstcompiler and micro-architectural research traditionally usesbenchmarks such as SpecCPU [56], SpecJVM [57], Dacapo[14], PARSEC [10], Beehive also considers complex emergingapplication areas. �e two primary domains targeted byBeehive are Computer Vision applications and algorithmssuch as KinectFusion [47] and other SLAMs (SimultaneousLocalization and Mapping algorithms) along with Big Dataso�ware stacks such as Spark [7], Flink [5], and Hadoop[6]. To showcase Beehive, we selected an implementation ofKinectFusion to be the main vehicle of experimentation.
Recent advances in real-time 3D scene understanding ca-pabilities can radically change the way robots interact withand manipulate the world. A proliferation of applications andalgorithms, in recent years, have targeted real time 3D space
2
reconstruction both in desktop and mobile environments[1, 2, 47]. To assess both the accuracy and performance of theproposed optimizations, we use SLAMBench [46] a bench-marking suite that provides a KinectFusion implementation.SLAMBench harnesses the ICL-NUIM dataset [30] of syn-thetic RGB-D sequences with trajectory and scene groundtruth for reliable accuracy comparison of di�erent imple-mentations and algorithms. SLAMBench currently includesimplementations in C++, CUDA, OpenCL, and OpenMP al-lowing a broad range of languages, platforms, and techniquesto be investigated. In Section 3, SLAMBench is explainedand decomposed to its key kernels.
2.3 Runtime LayerSome of the key features of Beehive are found in its runtimelayer, which provides capability beyond simply running na-tive applications. One of the challenges when designing suchtightly co-designed systems is the application and program-ming languages support. Supporting numerous runtimeswith various back-ends and compilers, while seamlessly in-tegrating them with the lower layers of the computing stack,is a time consuming task which impedes the maintainabilityof the whole platform. �ese issues in turn will manifestin slow adoption of state-of-the-art so�ware and hardwarecomponents and applications.
In order to overcome these challenges, we have takenthe design decision to build the runtime layer around twocomponents: the Java Virtual Machine (JVM) and nativeC/C++ applications. Despite being able to execute nativeC/C++ applications (regardless of the compiler used), Bee-hive has been designed to target languages that can run, andbe optimized, on top of the JVM. �e advent of the Graalcompiler [24] along with the Tru�e AST interpreter [64]enables the execution of multiple existing 2, and novel, dy-namic and non-dynamic programming languages and DSLson top of the JVM. Building the Beehive platform aroundTru�e, Graal, and the JVM, we achieve high performing ex-ecution of a variety of programming languages in a uni�edmanner. Furthermore, the amount of maintenance necessi-tated is contained to two compilers and one runtime system.In addition, any changes from the open sourced Graal andTru�e projects can be down-streamed to Beehive; keepingit synchronized with the latest so�ware components.
Regarding the runtime systems of Graal and Tru�e, twodesign alternatives have been deployed. �e �rst route is thevanilla implementations running on top of OpenJDK. �ebene�ts of this approach is that Beehive can be utilized byindustrial-strength, high-performing systems that run ontop of OpenJDK. �is, however, has a number of drawbacks.Components of the runtime layer such as Object Layouts,2For example, languages such as Ruby, JavaScript, R, LLVM-based, etc., arecurrently supported by Tru�e.
Garbage Collection (GC) algorithms, Monitor Schemes, etc.,are di�cult to research due to the lack of modularity in Open-JDK. To that end, we decided to add an additional runtimelayer for Graal and Tru�e: the Maxine Research VirtualMachine [63].
�e MaxineVM, a meta-circular Java-in-Java VM devel-oped by Oracle Labs, has been adopted and augmented forusage in Beehive [38]. Since its last release from Oracle,it has been enhanced by the Beehive team both in perfor-mance and functionality terms (Section 2.3.1). �e Graalcompiler ported on top of MaxineVM has been stabilized andits performance has been improved making MaxineVM thehighest performing research VM (Section 2.3.1). In addition,as depicted in Figure 1, both MaxineVM and OpenJDK usethe same optimizing compiler accompanied by the Tru�eAST interpreter enabling Beehive to extend its research ca-pabilities from industrial strength to high-quality researchprojects.
�e multi-language capabilities of Beehive have been fur-ther augmented by novel so�ware components that enableheterogeneous execution of applications on numerous hard-ware devices; Indigo, Tornado, and MAST [38, 45]. WhileIndigo enables the exploitation of SIMD units, Tornado tar-gets GPGPUs and FPGAs by OpenCL code emission. Further-more, MAST provides a clean API to access FPGA modulesin a concurrent and thread-safe manner. �e following sub-sections explain in detail MaxineVM, Indigo, Tornado, whileMAST is explained in Section 2.5.
2.3.1 MaxineVM.�e latest release of MaxineVM from Oracle had the follow-ing three compilers:
(1) T1X: A fast template-based interpreter (stable).(2) C1X: An optimizing SSA-based JIT compiler (stable).(3) Graal: An aggressively optimizing SSA-based JIT
compiler scheduled to be integrated in OpenJDKJava9 (semi-stable).
Furthermore, MaxineVM was tied to the x86 64 architecture.In the context of Beehive the following enhancements hasbeen made to MaxineVM:
Figure 3: SpecJVM2008 benchmarks (higher is better) normalized to OpenJDK-Zero-IcedTea6 1.13.11.
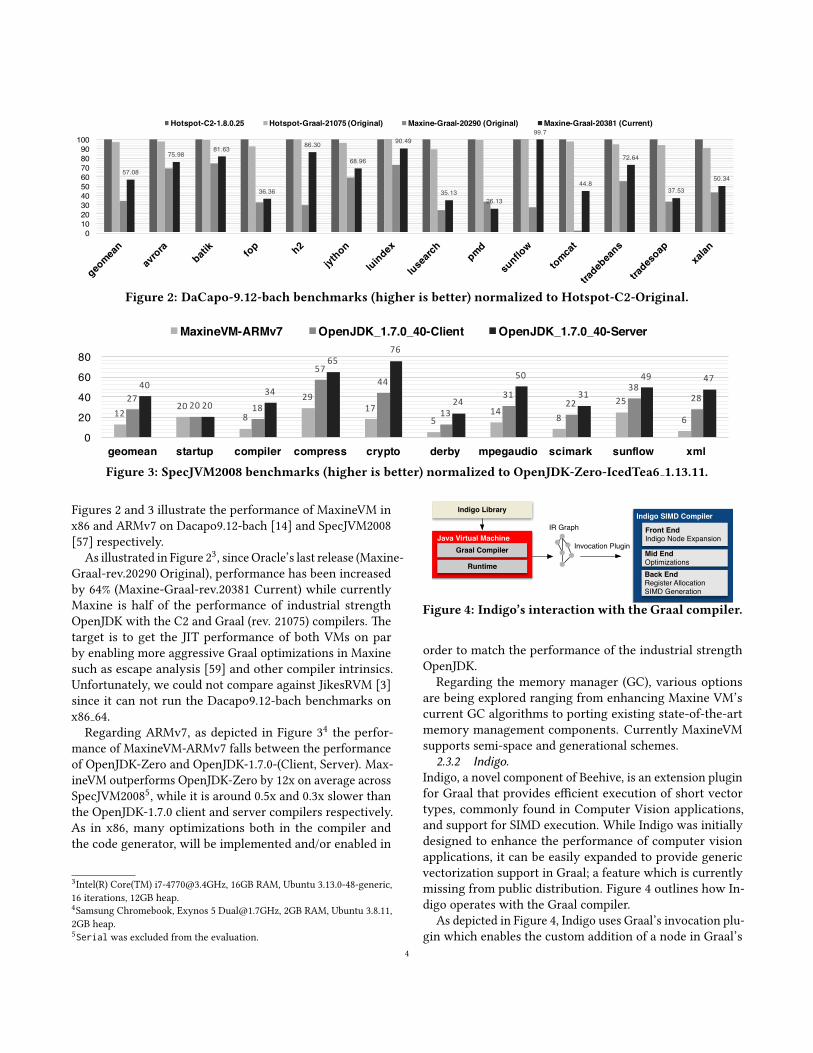
Figures 2 and 3 illustrate the performance of MaxineVM inx86 and ARMv7 on Dacapo9.12-bach [14] and SpecJVM2008[57] respectively.
As illustrated in Figure 23, since Oracle’s last release (Maxine-Graal-rev.20290 Original), performance has been increasedby 64% (Maxine-Graal-rev.20381 Current) while currentlyMaxine is half of the performance of industrial strengthOpenJDK with the C2 and Graal (rev. 21075) compilers. �etarget is to get the JIT performance of both VMs on parby enabling more aggressive Graal optimizations in Maxinesuch as escape analysis [59] and other compiler intrinsics.Unfortunately, we could not compare against JikesRVM [3]since it can not run the Dacapo9.12-bach benchmarks onx86 64.
Regarding ARMv7, as depicted in Figure 34 the perfor-mance of MaxineVM-ARMv7 falls between the performanceof OpenJDK-Zero and OpenJDK-1.7.0-(Client, Server). Max-ineVM outperforms OpenJDK-Zero by 12x on average acrossSpecJVM20085, while it is around 0.5x and 0.3x slower thanthe OpenJDK-1.7.0 client and server compilers respectively.As in x86, many optimizations both in the compiler andthe code generator, will be implemented and/or enabled in
3Intel(R) Core(TM) [email protected], 16GB RAM, Ubuntu 3.13.0-48-generic,16 iterations, 12GB heap.4Samsung Chromebook, Exynos 5 [email protected], 2GB RAM, Ubuntu 3.8.11,2GB heap.5Serial was excluded from the evaluation.
IR Graph
Methods
Java Virtual MachineGraal Compiler
Runtime
Indigo LibraryIndigo SIMD Compiler
Front EndIndigo Node Expansion
Back EndRegister AllocationSIMD Generation
Mid EndOptimizations
Invocation Plugin
Figure 4: Indigo’s interaction with the Graal compiler.
order to match the performance of the industrial strengthOpenJDK.
Regarding the memory manager (GC), various optionsare being explored ranging from enhancing Maxine VM’scurrent GC algorithms to porting existing state-of-the-artmemory management components. Currently MaxineVMsupports semi-space and generational schemes.
2.3.2 Indigo.Indigo, a novel component of Beehive, is an extension pluginfor Graal that provides e�cient execution of short vectortypes, commonly found in Computer Vision applications,and support for SIMD execution. While Indigo was initiallydesigned to enhance the performance of computer visionapplications, it can be easily expanded to provide genericvectorization support in Graal; a feature which is currentlymissing from public distribution. Figure 4 outlines how In-digo operates with the Graal compiler.
As depicted in Figure 4, Indigo uses Graal’s invocation plu-gin which enables the custom addition of a node in Graal’s
4
Intermediate Representation (IR). �is, in turn, can be ex-ploited by Indigo to re-direct the compilation route fromGraal to Indigo and use its compilation stack to compileand optimize for SIMD execution. Within Graal, the IR ismaintained as a structured graph with nodes representingactions or values while edges represent their dependencies.�e graph is initially generated by parsing the bytecode froma class �le.
�e objective of vectorization is to reduce the distancebetween vector operations in the IR enabling further opti-mizations through virtualization (i.e. escape analysis andscalar replacement [59]). With the use of virtualization, wecan maintain temporary vectors entirely at the registers ofthe targeted architectures. �e addresses of the vectors arebeing used for reading and writing, enabling us to break freefrom the primitive Java types and, more importantly, fromthe use of Java arrays. However, since this is not an inher-ent safe usage of the Java semantics we made the followingassumptions:
• Hardware supports 128-bit vector operations, truefor ARM NEON and Intel SSE implementations.
• �e class contains four single-precision �oating pointnumbers suitable for vector operations of SLAM ap-plications.
• Unused elements of a vector are zero.• �e elements of a vector are contiguous in memory.• Once constructed, a vector is immutable.
�e aforementioned assumptions apply to the library pro-vided by Indigo and in turn allow some of the restrictions inJava to be eliminated. �is enables the IR to be extended andoptimized more aggressively since the semantics are nowwithin the vector abstraction and not within the generalpurpose language.
Invocation plugins allow the replacement of a method in-vocation with a sub-graph created during the graph buildingphase in Graal. We used a single node plugin that contains itsown domain speci�c compiler stack. �e major bene�t of thisapproach is the runtime independence from Graal. �erefore,it can be downloaded and used a standalone library that, ifthe JVM uses Graal on top of the JVM Compiler Interface(JMVCI) [36], SIMD instruction emission can be generated.Indigo’s compiler stack contains a basic graph builder, op-timizer, register allocator, and code generator with a scopelimited for its target domain: Computer Vision applications.
Indigo nodes are generated either during the graph build-ing phase of the compilation or indirectly during inlining.Once a graph has been constructed, it is transformed duringthe optimization phases by exploiting canonicalization andsimpli�cation to merge nodes. �is allows us to maximizethe number of operations in the node and eliminate newinstance nodes (allocation of new objects) from the graph,leaving the data in registers. A simpli�cation phase traverses
Figure 5: Indigo’s performance against Apache CMLon common vector and matrix operations.
the operand edges of the Indigo node to detect other Indigonodes and merges the internal operation graphs together.
When Indigo nodes are lowered to the low-level IR (LIR)nodes used by Graal, they must claim virtual registers fromGraal. At this point we lower the operation to a genericSIMD instruction to be scheduled while pro�ling the registerrequirements. In order to maintain the vanilla implemen-tation of Graal, we indirectly use its register allocator toprovide general purpose and vector registers by claimingvalues to satisfy the requirements of the compiled method.Later, these will be converted into physical registers duringthe back end phases. �e use of pro�ling enables us to of-�oad the allocation algorithms to Graal, while ensuring thatno vector registers are spilled to the stack. �is techniqueprohibits the JVM from entering un-recoverable states whilebeing spatially more e�cient.
�anks to the modularity of Graal, and access to the com-piler through the JVMCI, it is possible to insert novel nodesinto the compiler at runtime. With Indigo we show thatit is possible to add a domain speci�c compilation pluginto augment the Graal compiler. �is allows us to bypassall Graal internals and emit machine code exploiting SIMDinstructions that are unsupported in the publicly availableGraal. While this approach targets idiomatic SIMD for Com-puter Vision, there is no technical reason why it cannot beextended to insert other domain speci�c knowledge intoJava.
Figure 5, contains Indigo’s relative performance againstthe Apache Common Mathematics Library (CML) [62] for atotal number of 13 vector and matrix operations commonlyfound in Computer Vision applications. As depicted in Fig-ure 5, Indigo outperforms Apache CML both in vector andmatrix operations. As expected, the largest gains are ob-served in matrix operations with matrix-vector multiplica-tion exhibiting a 66.75x speedup. �e observed performanceimprovements derive from the use of SIMD execution alongwith the compiler optimizations provided by Indigo (nullcheck elimination, scalar replacement, etc.).
5
2.3.3 Tornado.Tornado, a novel component of Beehive, originated by JACC[20], is a framework designed to improve the productivityof developers targeting heterogeneous hardware. By exploit-ing the available heterogeneous resources, they have thepotential to improve the performance and energy-e�ciencyof their applications. �e key di�erence between Tornadoand existing programming languages and frameworks is itsdynamism; developers do not need to make a priori decisionsabout their hardware targets. �e Tornado runtime systemachieves transparent computation o�oading with supportfor automatic device management, data movement, and codegeneration. �is is possible by exploiting the design of VM-based languages: Tornado simply augments the underlyingVM with support for OpenCL by using the JVMCI (Java Vir-tual Machine Compiler Interface); similarly, to Indigo. �eJVMCI allows e�cient access to low-level information insidethe JVM, such as a methods bytecodes and pro�ling informa-tion. Using this information Tornado is able to JIT compileJava bytecode to execute on OpenCL compatible devices.
As depicted in Figure 6, the Tornado API provides devel-opers with a task-based programming model. In Tornado, atask can be thought of as being analogous to a single OpenCLkernel execution. �is means that a task must encapsulatethe code it needs to execute, the data it should operate on,and some meta-data. �e meta-data can contain informationsuch as the device it should execute on or pro�ling informa-tion. �e mapping between tasks and devices is done at atask-level granularity; meaning each task is capable of beingexecuted on a di�erent piece of hardware. �ese mappingscan be provided either by the developer or by the Tornadoruntime; the mappings are dynamic and have the ability tochange anytime.
Instead of focusing on scheduling individual tasks, Tor-nado allows developers to combine multiple tasks together toform a larger schedulable unit of work (called a task-graph).�is approach has a number of bene�ts: �rstly, it provides aclean separation between the code which co-ordinates tasksexecution and the code which performs the actual compu-tation; and secondly, it allows the Tornado runtime systemto exploit a wider range of runtime optimizations. For in-stance, the task-graph provides the runtime system withenough information to determine the data dependencies be-tween tasks. By using this knowledge, the runtime system isable to exploit any available task parallelism by overlappingthe execution of task execution and data movement. It alsoprovides the runtime system with the ability to eliminateany unnecessary data transfers that would occur because ofread-a�er-write data dependencies between tasks.
To increase developer productivity, Tornado is designed tomake o�oading computation as transparent as possible. �is
- Tornado expands graphs to include data movement.- Graph is optimized to remove redundant data transfers.
Tornado Runtime
Code Cache Memory
Task Queue
Device
Device Device Device…
- Runtime schedules tasks on devices.
Figure 6: Tornado outline.
is achieved via its runtime system which is able to automat-ically schedule data transfers between devices and handlethe asynchronous execution of tasks. Moreover, the JIT com-piler provides support for user-guided parallelization. �eresult is that developers are able to rapidly develop portableheterogeneous applications which can exploit any OpenCLcompatible device in the system.
2.4 Binary Instrumentation LayerBeehive integrates a number of binary instrumentation toolsto enable research and rapid prototyping of novel micro-architectures and ISA extensions. Along with the well-establishedIntel’s PIN tool [43], Beehive integrates the newly introducedMAMBO [27], and MAMBO-x64 [22] tools for ARMv7 andAArch64 architectures.
2.4.1 MAMBO.MAMBO is a low-overhead dynamic binary instrumentationand modi�cation tool for the ARM architecture which cur-rently supports ARMv7 and the AArch32 execution state ofARMv8. In the context of Beehive, the initial performanceof MAMBO has been further improved since its �rst release.�e introduced optimizations include:
• A novel scheme to enable hardware return addressprediction for dynamic binary translation.
• A number of micro-architectural speci�c optimiza-tions such as usage of huge pages for internal data.
While the initial version of MAMBO achieves a geometricmean overhead of 28% on a Cortex-A9 (a dual-issue out-of-order superscalar processor with 8 to 11 pipeline stages) andof 34% on a Cortex-A15 (a triple-issue out-of-order super-scalar processor with 15 to 24 pipeline stages), the introducedoptimizations reduce the overhead on the two systems to15% and 21% respectively.
2.4.2 MAMBO-X64.�e introduced ARM AArch64 architecture is a 64-bit execu-tion mode with a new instruction set which retains binarycompatibility with ARMv7 32-bit execution mode. Due to theneed to support the large number of existing 32-bit ARM ap-plications, current implementations of AArch64 processorsinclude hardware support for ARMv7. However, this support
6
comes at a cost in hardware complexity, power usage, andveri�cation time.
MAMBO-X64 is a dynamic binary translator which exe-cutes 32-bit ARM binaries (both single-threaded and multi-threaded) using the AArch64 instruction set. �e integrationof MAMBO-X64 into Beehive creates a path for experimen-tation for future processors to drop hardware support forthe legacy 32-bit instruction set while retaining the abilityto run ARMv7 applications.
In the context of Beehive, the performance of MAMBO-X64 has been further improved by employing a number ofnovel optimizations such as: mapping ARMv7 �oating-pointregisters to AArch64 registers dynamically, generating tracesthat harness hardware return address prediction, and e�-ciently handling operating system signals. A�er applying theaforementioned optimizations, on SPEC CPU2006 [56], wemeasured a very low geometric mean average performanceoverhead of 0.2%, 3.3% and 8.3% on X-Gene, Cortex-A57,and Cortex-A53 processors respectively. �e performanceof MAMBO-X64 also scales to multi-threaded applications,with an overhead on the PARSEC [10] multithreaded bench-mark suite of only 2.1% with 1, 2 and 4 threads, and 4.9%with 8 threads.
2.5 Hardware/FPGA LayerAs depicted in Figure 1, Project Beehive targets a variety ofhardware platforms and therefore signi�cant e�ort is beingplaced in providing the appropriate support for the compil-ers and runtimes of choice. Besides targeting conventionalCPU/GPU systems, it is also possible to target FPGA systemssuch as the Xilinx Zynq ARM/FPGA System on Chip (SoC).
In order to e�ciently program FPGAs from high levelprogramming languages, we developed MAST: a ModularAcceleration and Simulation Technology. MAST consistsof a hardware/so�ware library and tools allowing the rapiddevelopment of systems using ARM based FPGAs. Fromthe hardware perspective it consists of a standardized in-terface which allows IP blocks to be identi�ed and lockedfor use by processes running on the ARM processor. All IPblocks feature an AXI slave port, used for con�guration andlow speed communication, and optionally an AXI masterport to provide high speed access to the system memory ofthe ARM processor, typically via the ACP port to providecache coherency. Currently hardware design is carried outusing Bluespec System Verilog [8], with interface modulesconforming to the hardware. �e so�ware library, which isentirely in user space, provides a hardware manager whichcan be used to discover IP on the programmable logic andallocate it a speci�c process thread. �e so�ware library alsoprovides a simple interface with IP blocks between the virtualmemory world of the processor and the physical memory
Gem5
stats.txt McPAT Features Predictor
Hotspot Voltspot NVSim KNN SVN
FEAST
Outputs
Figure 7: Beehive’s Gem5 stack.
required by the hardware, where either the library or thehost application can perform memory allocation.
2.6 Simulation LayerBesides running directly on real hardware, Beehive o�ersthe opportunity to conduct micro-architectural research viaits advanced simulation infrastructure. �e two simulatorsof choice, with diverse characteristics, ported to the Beehiveplatform are: Gem5 [11] and ZSim [52]. While Zsim o�ers afast and high accurate simulation time on x86 (≈ 10 MIPS inour experiments), Gem5 provides a slower yet more detailedfull-system simulation framework for numerous architec-tures.
2.6.1 Gem5.�e Gem5 full-system simulator has been adopted and aug-mented in the following ways:
• Integrationwith other architectural simulators:A new interface layer has been developed within theGem5 full-system simulator [12] to facilitate easyintegration with a range of architectural simulatorsas depicted in Figure 7.
�e statistics package has been augmented to al-low statistics to be assigned to groups, speci�ed atrun-time and manipulated (output and reset) inde-pendently, without a�ecting the total values of thestatistics or requiring updates to the code base. �isallows new architectural simulators to be invokedfrom within the Gem5 simulator by using standardC++ template code. Current simulators integratedinto the Gem5 framework include:
1) McPAT [40] and Hotspot [33]: �e power andtemperature modelers provided by those tools areconjoined to provide accurate temperature-basedleakage models. Power samples may be triggeredfrom within the Gem5 simulator, at intervals be-tween 10ns to 10us (allowing transient traces to begenerated for benchmarks), and from within the sim-ulated OS (allowing accurate power and temperature�gures to be used within user space programs). �ereis around a 10% simulation time overhead for tem-perature and power modelling with 10us samples.
7
2) Voltspot [66]: In order to measure Voltage noiseevents caused by power-gating or switching pat-terns in Multicore SOCs over realistic workloads,the Voltspot simulator has been incorporated intothe framework. �e additional statistics generatedallow nanosecond timing of events to be recordedwhile using samples of courser granularity.
3) NVSim [23]: �e non-volatile memory sim-ulator NVSim has been incorporated into the sim-ulation infrastructure. NVSim can be invoked byMcPat (alongside the conventional SRAM modelingtool Cacti [42]) allowing accurate delay, power, andtemperature modeling of non-volatile memory any-where in the memory hierarchy.
• Machine Learning andDataAnalytics techniques:�e interface layer has also been used to allow machine-learning/data-analytics techniques to be incorpo-rated within the simulation framework. Machine-learning techniques are used to analyze statisticalpa�erns in the data aiding in the creation of hardware-predictors for power-management, prefetching, branch-prediction etc. �e statistics package allows for thespeci�cation of features at runtime. Features are de-�ned as a statistic over a given period (e.g. the branchmispredict rate over 1us, or the L2 cache miss-rateover 10ms). Features are speci�ed at run-time andcan be accessed periodically or triggered from eventswithin the simulator and the statistics package guar-antees to return the features over their speci�ed time(within an error range which is also set at run-time).�e FEAST toolkit [15] has been incorporated intothe framework (Figure 7) to allow for (o�ine) featureselection. Packages for online K-nearest neighbour(KNN) and Support Vector Machine regression havebeen incorporated into the framework to allow foronline prediction once the features have been chosen.Interaction between the simulator and the predictorsis controlled by the statistics package again allowingfor the prediction to be triggered within the Gem5simulator code or from within the simulated OS.
• Resiliency and Fault-Injection: A critical aspectof any computer system is its dependability eval-uation [37, 39, 58]. �e accurate identi�cation ofvulnerabilities assists computer architects to care-fully plan for low cost and high energy e�cientresiliency mechanisms. On the contrary, inaccu-rate dependability assessment o�en results on over-designed microprocessors impacting negatively time-to-market and product costs. To aid dependabilitystudies, we developed a fault injection frameworkthat adheres to the following principles: 1) Flexibil-ity: easy to setup, de�ne and perform fault injection
APPLICATION
SIM
ULAT
OR
OS
ARCHITECTURE / ISA
MICRO-ARCHITECTURE
DATA ADDRESS CACHE
TEST SCENARIO
monitor()
apply()
…
fault_model()
injLIBRARY
gem5.opt –faultType X –faultData Y –module cache SIMULATOR-SPECIFIC API
injCONTROLLER
verify output
prop
agat
ion
PIPELINE
Figure 8: Beehive’s fault injection tool.
experiments, 2) Reproducibility: enable reproducibleexperiments, 3) Generality: support a wide set ofISAs in a uniform way performing comparative stud-ies, and 4) Scalability: easily deployed to multi-coredesigns.
Figure 8 depicts the �oor-plan of the fault injec-tion tool. �e developed fault injection frameworkis built on top of Gem5 and operates as follows: Auser-de�ned test scenario is translated into a set offault injection arguments using a simulator-speci�cAPI. �e injection library implements all the nec-essary simulation calls: (i) fault model(): setup ofa transient, intermi�ent or permanent fault model[13, 21, 44]. Transient faults are modeled by �ippingthe value of a randomly selected bit in a randomly se-lected time window within simulation. Intermi�entfaults are modelled by se�ing the state of storageelements to one (stuck-at-1) or zero (stuck-at-0), in arandomly selected time window, for a random period.Moreover, permanent faults set the state of storageelement persistently to one or to zero. Finally, multi-bit fault injections, having a combination of the afore-mentioned models, are also supported. (ii) apply():injects the faults into a user-de�ned location (e.g. L1,L2 cache, etc.); and (iii) monitor(): logs and clustersthe fault injection output. Finally, the injection con-troller, the kernel of the framework, communicateswith the injection library and orchestrates the actualfault injection based on the user-de�ned arguments.
2.6.2 ZSim.�e ZSim simulator, a user-level x86-64 simulator with anOOO-core model of the Westmere (Nehalem) micro-architecture,has been augmented in order to run managed workloads onMaxineVM resulting in the MaxSim simulation platform [50].Alternative options such as the Sniper [18] simulator thatruns with JikesRVM [54], or the full-system Gem5 simulatorwere considered but abandoned due to a number of limita-tions: Sniper can only run in a 32-bit mode, while Gem5 has arelatively low simulation speed. Finally, in order to perform
8
energy and power estimations, we integrated the McPAT[41] tool into the ZSim simulator following the methodologyproposed by the Sniper simulator [32]. �e methodologynecessitated the implementation of a number of extra micro-architectural events in ZSim such as the number of predictedbranches and �oating point micro-operations.
3 SLAM APPLICATIONS3.1 KinectFusionTo showcase the capabilities of the ZZZ platform, we fo-cused on emerging applications which are becoming sig-ni�cant both in desktop and mobile domains: real-time 3Dscene understanding in Computer Vision. In particular, weinvestigate SLAMBench a complex Simultaneous Localiza-tion and Mapping (SLAM) application which implementsthe KinectFusion (KFusion) algorithm. SLAM applicationsare challenging due to the amount of computation neededper frame and the programming complexity of achievinghigh performing implementations. SLAMBench allows thereconstruction of a three-dimensional representation from astream of depth images produced by a RGB-D camera (Figure9), such as the Microso� Kinect. Typically, the slower theframes are processed, the harder it is to build an accuratemodel of the scene. Each of the depth images is used as input
Figure 9: RGB-D camera combines RGB with Depthinformation (top le� and middle). �e tracking (le�)results in the 3D reconstruction of the scene (right).
to the six-stage processing pipeline shown in Figure 10:• Acquisition obtains the next RGB-D frame; either
from a camera or from a �le.• Pre-processing is responsible for cleaning up the
incoming data using a bilateral �lter and standard-izes the units used for measurement.
• Tracking estimates the new pose of the camera; itbuilds a point cloud from the current data frame andmatches it against a reference point cloud, producedfrom the raycasting step, using an iterative closestpoint (ICP) algorithm.
• Integrate fuses the current frame into the internalmodel, if a new pose has been estimated.
• Raycast using raycasting the pipeline can constructa new reference point cloud from the internal repre-sentation of the scene.
• Rendering this stage uses the same raycasting tech-nique to visualize the 3D scene.
It should be noted that the pipeline has a feedback loop.Each of the pipeline stages is composed from a number ofdi�erent kernels. In the original KinectFusion implementa-tion, a kernel represents a separate region of code which isexecuted on the GPU. In a typical pipeline execution Kinect-Fusion will execute between 18 and 54 kernels (best andworst case scenarios). �e variation is dependent on theperformance of the ICP algorithm, if it is able to estimate thenew camera pose quickly then less kernels will be executed.�is means that to achieve a real-time performance of 30frames per second, the application will need to sustain theexecution of between 540 and 1620 kernels every second.
3.2 Programmability Vs. PerformanceSLAMBench o�ers baseline and high-performing implemen-tations of KinectFusion in C++, OpenMP, CUDA, and OpenCL.In order to achieve the QoS targets of Computer Vision (typi-cally over 30 FPS), KinectFusion has to be heavily parallelizedon GPGPUs and therefore the CUDA and OpenCL implemen-tations are those matching the required targets. Developingon CUDA or OpenCL, however, comes with a number ofdrawbacks. �e �rst one is code complexity and productivitywhile the second one is portability since applications haveto recompiled and tuned for each target hardware platform.
To tackle the aforementioned problems and to showcasethe capabilities of ZZZ, we decided to experiment with Com-puter Vision applications in Java; a language that up-to-nowwas not considered for such high performing and demand-ing applications. Implementing SLAMBench, and in generalComputer Vision applications, in Java provides a trade-o�between programmability e�orts and performance.
While Java can provide rapid prototyping, in contrast towriting OpenCL or CUDA, vanilla and un-optimized imple-mentations can not meet the QoS requirements. We usethe Java programming language as a challenge in order tobuild and optimize Computer Vision applications aimingto achieve real-time 3D space reconstruction. A�er havingdeveloped and validated a serial implementation of SLAM-Bench, we performed a performance analysis and identi�edperformance bo�lenecks. �en, we utilized ZZZ to apply a
9
Java - 0.71 FPS
C++ - 2.40 FPS
Tornado - 31.07 FPS
0
10
20
30
40
50
0 500 1000Frame Number
Fra
me
s P
er
Se
co
nd
Figure 11: FPS achieved of Tornado versus baselineJava and C++ implementations.
number of co-designed acceleration and optimization tech-niques to the various stages of SLAMBench. �e accelerationtechniques span from custom FPGA acceleration of certainkernels to full-application acceleration through co-designedobject compaction and GPGPU o�-loading.
4 EVALUATION�e following subsections describe the acceleration and opti-mizations techniques applied to SLAMBench via the Beehiveplatform along with the experimental results. �e hardwareand so�ware con�gurations for each optimization are pre-sented in Table 1.
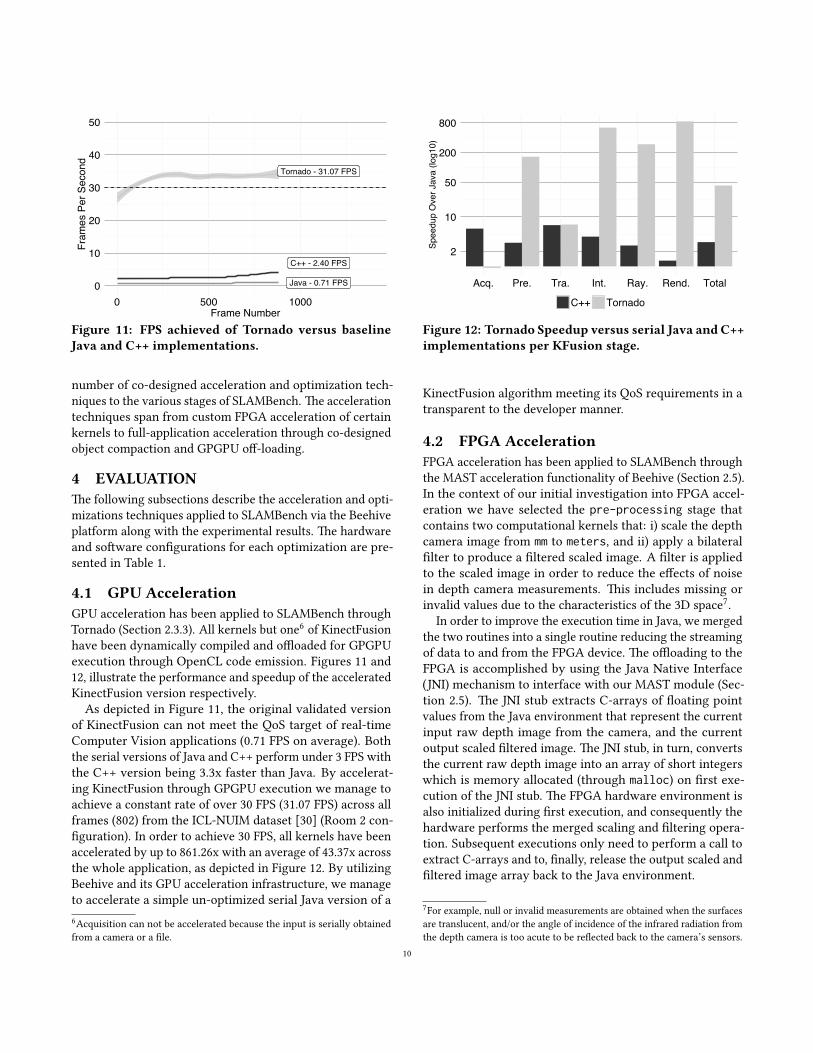
4.1 GPU AccelerationGPU acceleration has been applied to SLAMBench throughTornado (Section 2.3.3). All kernels but one6 of KinectFusionhave been dynamically compiled and o�oaded for GPGPUexecution through OpenCL code emission. Figures 11 and12, illustrate the performance and speedup of the acceleratedKinectFusion version respectively.
As depicted in Figure 11, the original validated versionof KinectFusion can not meet the QoS target of real-timeComputer Vision applications (0.71 FPS on average). Boththe serial versions of Java and C++ perform under 3 FPS withthe C++ version being 3.3x faster than Java. By accelerat-ing KinectFusion through GPGPU execution we manage toachieve a constant rate of over 30 FPS (31.07 FPS) across allframes (802) from the ICL-NUIM dataset [30] (Room 2 con-�guration). In order to achieve 30 FPS, all kernels have beenaccelerated by up to 861.26x with an average of 43.37x acrossthe whole application, as depicted in Figure 12. By utilizingBeehive and its GPU acceleration infrastructure, we manageto accelerate a simple un-optimized serial Java version of a6Acquisition can not be accelerated because the input is serially obtainedfrom a camera or a �le.
2
10
50
200
800
Acq. Pre. Tra. Int. Ray. Rend. Total
Sp
ee
du
p O
ve
r Ja
va
(lo
g1
0)
C++ Tornado
Figure 12: Tornado Speedup versus serial Java and C++implementations per KFusion stage.
KinectFusion algorithm meeting its QoS requirements in atransparent to the developer manner.
4.2 FPGA AccelerationFPGA acceleration has been applied to SLAMBench throughthe MAST acceleration functionality of Beehive (Section 2.5).In the context of our initial investigation into FPGA accel-eration we have selected the pre-processing stage thatcontains two computational kernels that: i) scale the depthcamera image from mm to meters, and ii) apply a bilateral�lter to produce a �ltered scaled image. A �lter is appliedto the scaled image in order to reduce the e�ects of noisein depth camera measurements. �is includes missing orinvalid values due to the characteristics of the 3D space7.
In order to improve the execution time in Java, we mergedthe two routines into a single routine reducing the streamingof data to and from the FPGA device. �e o�oading to theFPGA is accomplished by using the Java Native Interface(JNI) mechanism to interface with our MAST module (Sec-tion 2.5). �e JNI stub extracts C-arrays of �oating pointvalues from the Java environment that represent the currentinput raw depth image from the camera, and the currentoutput scaled �ltered image. �e JNI stub, in turn, convertsthe current raw depth image into an array of short integerswhich is memory allocated (through malloc) on �rst exe-cution of the JNI stub. �e FPGA hardware environment isalso initialized during �rst execution, and consequently thehardware performs the merged scaling and �ltering opera-tion. Subsequent executions only need to perform a call toextract C-arrays and to, �nally, release the output scaled and�ltered image array back to the Java environment.
7For example, null or invalid measurements are obtained when the surfacesare translucent, and/or the angle of incidence of the infrared radiation fromthe depth camera is too acute to be re�ected back to the camera’s sensors.
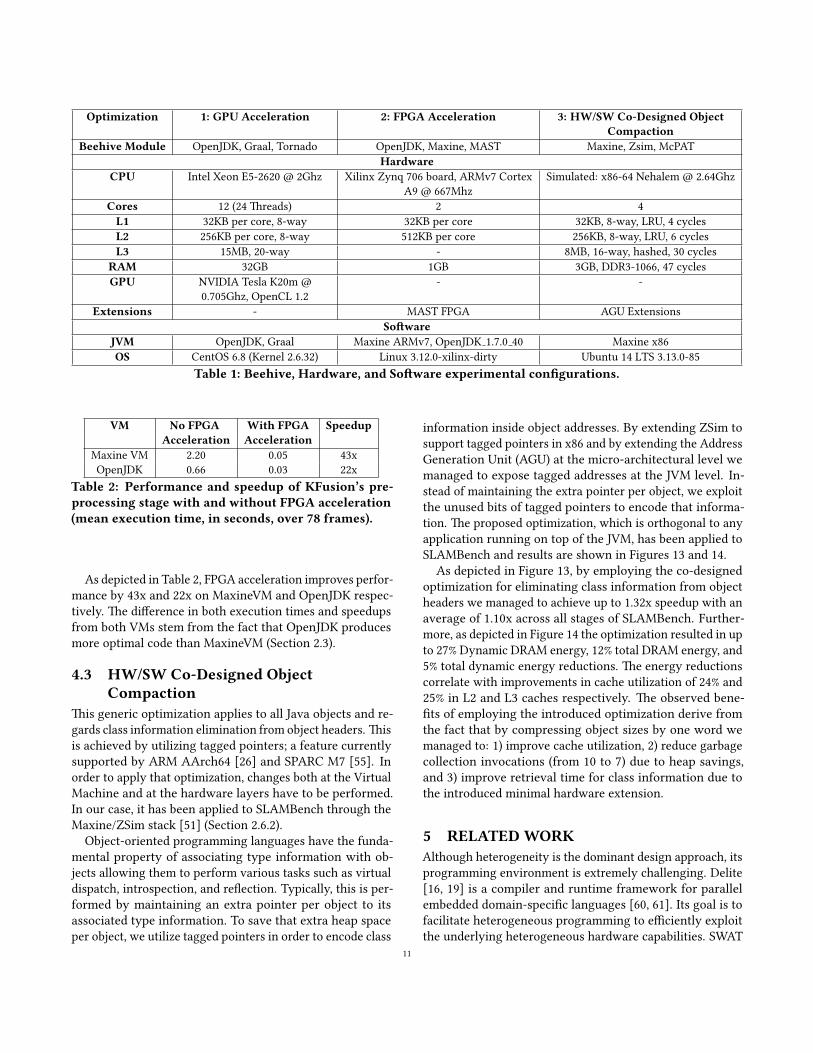
Table 1: Beehive, Hardware, and So�ware experimental con�gurations.
VM No FPGA With FPGA SpeedupAcceleration Acceleration
Maxine VM 2.20 0.05 43xOpenJDK 0.66 0.03 22x
Table 2: Performance and speedup of KFusion’s pre-processing stage with and without FPGA acceleration(mean execution time, in seconds, over 78 frames).
As depicted in Table 2, FPGA acceleration improves perfor-mance by 43x and 22x on MaxineVM and OpenJDK respec-tively. �e di�erence in both execution times and speedupsfrom both VMs stem from the fact that OpenJDK producesmore optimal code than MaxineVM (Section 2.3).
4.3 HW/SW Co-Designed ObjectCompaction
�is generic optimization applies to all Java objects and re-gards class information elimination from object headers. �isis achieved by utilizing tagged pointers; a feature currentlysupported by ARM AArch64 [26] and SPARC M7 [55]. Inorder to apply that optimization, changes both at the VirtualMachine and at the hardware layers have to be performed.In our case, it has been applied to SLAMBench through theMaxine/ZSim stack [51] (Section 2.6.2).
Object-oriented programming languages have the funda-mental property of associating type information with ob-jects allowing them to perform various tasks such as virtualdispatch, introspection, and re�ection. Typically, this is per-formed by maintaining an extra pointer per object to itsassociated type information. To save that extra heap spaceper object, we utilize tagged pointers in order to encode class
information inside object addresses. By extending ZSim tosupport tagged pointers in x86 and by extending the AddressGeneration Unit (AGU) at the micro-architectural level wemanaged to expose tagged addresses at the JVM level. In-stead of maintaining the extra pointer per object, we exploitthe unused bits of tagged pointers to encode that informa-tion. �e proposed optimization, which is orthogonal to anyapplication running on top of the JVM, has been applied toSLAMBench and results are shown in Figures 13 and 14.
As depicted in Figure 13, by employing the co-designedoptimization for eliminating class information from objectheaders we managed to achieve up to 1.32x speedup with anaverage of 1.10x across all stages of SLAMBench. Further-more, as depicted in Figure 14 the optimization resulted in upto 27% Dynamic DRAM energy, 12% total DRAM energy, and5% total dynamic energy reductions. �e energy reductionscorrelate with improvements in cache utilization of 24% and25% in L2 and L3 caches respectively. �e observed bene-�ts of employing the introduced optimization derive fromthe fact that by compressing object sizes by one word wemanaged to: 1) improve cache utilization, 2) reduce garbagecollection invocations (from 10 to 7) due to heap savings,and 3) improve retrieval time for class information due tothe introduced minimal hardware extension.
5 RELATEDWORKAlthough heterogeneity is the dominant design approach, itsprogramming environment is extremely challenging. Delite[16, 19] is a compiler and runtime framework for parallelembedded domain-speci�c languages [60, 61]. Its goal is tofacilitate heterogeneous programming to e�ciently exploitthe underlying heterogeneous hardware capabilities. SWAT
Figure 13: Performance improvements of class infor-mation elimination in SLAMBench.
27%
12%
5%
24%25%
0%
5%
10%
15%
20%
25%
30%
DRAM Dynamic Energy Reduction
DRAM Total Energy Reduction
Total Dynamic Energy Reduction
L2 Cache Misses/KiloInst.
Reduction
L3 Cache Misses/KiloInstr.
Reduction
Figure 14: Energy and Cache Miss improvements ofclass information elimination in SLAMBench.
[29] is a so�ware platform that enables native executionof Spark applications on heterogeneous hardware. Further-more, OpenPiton [9] is an open source many-core researchframework covering only the hardware layer, X-Mem [28]is an open-source so�ware tool that characterizes the mem-ory hierarchy for cloud computing, and Minerva [49] is aHW/SW co-designed framework for deep neural networks.In contrast to the aforementioned approaches, the Beehiveframework is a hardware/so�ware experimentation platformthat enables co-designed optimizations for runtime and ar-chitectural research. covering all applications and computestack. Regarding GPGPU Java acceleration, a number of ap-proaches such as APARAPI [4], Ishizaki et. al. [35], Rootbeer[48], and Habanero-Java [31], exist. Beehive’s Tornado mod-ule di�ers due to its dynamic nature and its co-operationwith other parts of the framework such as MAST.
6 CONCLUSIONS AND FUTUREWORKIn this paper, we introduced Beehive: a hardware/so�wareco-designed platform for full-system runtime and architec-tural research. Beehive builds on top of existing state-of-the-art as well as novel components at all layers of the platform.
By utilizing Beehive, we managed to accelerate a complexComputer Vision application in three distinct ways: GPGPUacceleration, FPGA acceleration, and by compacting objectsin a hardware/so�ware co-designed manner. �e experimen-tal results proved that we managed to achieve real-time 3Dspace reconstruction (>30 fps) of the KFusion application,a�er accelerating it by up to 43×.
Our vision regarding Beehive is to improve both its inte-gration and performance throughout all the layers. In thelong term, we aim to unify the platform’s components undera semantically aware runtime increasing developer produc-tivity. Furthermore, we plan to de�ne a hybrid ISA betweenemulated and hardware capabilities. �is ISA will provide aroadmap of movement of interactions between abstractionso�ered in so�ware and in hardware. Finally, we plan to workon new hardware services for scale out and representation ofvolatile and non-volatile communication services. �is willprovide a consistent view of platform capabilities across het-erogeneous processors for Big Data and HPC applications.
7 ACKNOWLEDGEMENTS�e research leading to these results has received fundingfrom UK EPSRC grants DOME EP/J016330/1, AnyScale AppsEP/L000725/1, INPUT EP/K015699/1 and PAMELA EP/K008730/1and the EU FP7 Programme under grant agreement No 318633AXLE project, and EU H2020 No 732366 ACTiCLOUD. MikelLujan is funded by a Royal Society University Research Fel-lowship and Antoniu Pop a Royal Academy of EngineeringResearch Fellowship.
REFERENCES[1] Dyson 360 Eye web site. h�ps://www.dyson360eye.com.[2] Project Tango web site. h�ps://www.google.com/atap/projec�ango.[3] B. Alpern, C. R. A�anasio, J. J. Barton, M. G. Burke, P. Cheng, J.-D.
Choi, A. Cocchi, S. J. Fink, D. Grove, M. Hind, S. F. Hummel, D. Lieber,V. Litvinov, M. F. Mergen, T. Ngo, J. R. Russell, V. Sarkar, M. J. Serrano,J. C. Shepherd, S. E. Smith, V. C. Sreedhar, H. Srinivasan, and J. Whaley.�e jalapeno virtual machine. IBM Systems Journal, 2000.
[4] AMD-Aparapi. h�p://developer.amd.com/tools-and-sdks/heterogeneous-computing/aparapi/. October 12, 2021.
[5] Apache Flink. h�ps://�ink.apache.org. October 12, 2021.[6] Apache Hadoop. h�p://hadoop.apache.org/. October 12, 2021.[7] Apache Spark. h�ps://spark.apache.org/. October 12, 2021.[8] Arvind. Bluespec: A language for hardware design, simulation, syn-
thesis and veri�cation invited talk. In Proceedings of the First ACMand IEEE International Conference on Formal Methods and Models forCo-Design, MEMOCODE ’03, pages 249–, Washington, DC, USA, 2003.IEEE Computer Society.
[9] Jonathan Balkind, Michael McKeown, Yaosheng Fu, Tri Nguyen, YanqiZhou, Alexey Lavrov, Mohammad Shahrad, Adi Fuchs, Samuel Payne,Xiaohua Liang, Ma�hew Matl, and David Wentzla�. Openpiton: Anopen source manycore research framework. In Proceedings of theTwenty-First International Conference on Architectural Support for Pro-gramming Languages and Operating Systems, ASPLOS ’16, pages 217–232, New York, NY, USA, 2016. ACM.
[10] Christian Bienia. Benchmarking Modern Multiprocessors. PhD thesis,Princeton University, January 2011.
[11] Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Rein-hardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower,Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell,Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood. �egem5 simulator. SIGARCH Comput. Archit. News, 39(2):1–7, August2011.
[12] Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Rein-hardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower,Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell,Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood.�e gem5 simulator. SIGARCH Comput. Archit. News.
[13] Arijit Biswas, Paul Racunas, Razvan Cheveresan, Joel Emer, Shub-hendu S. Mukherjee, and Ram Rangan. Computing architecturalvulnerability factors for address-based structures. SIGARCH Comput.Archit. News, 33(2):532–543, May 2005.
[14] S. M. Blackburn, R. Garner, C. Ho�man, A. M. Khan, K. S. McKinley,R. Bentzur, A. Diwan, D. Feinberg, D. Frampton, S. Z. Guyer, M. Hirzel,A. Hosking, M. Jump, H. Lee, J. E. B. Moss, A. Phansalkar, D. Ste-fanovic, T. VanDrunen, D. von Dincklage, and B. Wiedermann. �eDaCapo benchmarks: Java benchmarking development and analy-sis. In OOPSLA ’06: Proceedings of the 21st annual ACM SIGPLANconference on Object-Oriented Programing, Systems, Languages, andApplications. ACM Press, 2006.
[15] Gavin Brown, Adam Pocock, Ming-Jie Zhao, and Mikel Lujan. Condi-tional likelihood maximisation: a unifying framework for informationtheoretic feature selection. Journal of Machine Learning Research,13(Jan):27–66, 2012.
[16] K. J. Brown, A. K. Sujeeth, H. J. Lee, T. Rompf, H. Cha�, M. Odersky,and K. Olukotun. A heterogeneous parallel framework for domain-speci�c languages. In Parallel Architectures and Compilation Techniques(PACT), 2011 International Conference on, pages 89–100, 2011.
[17] Franck Cappello, Al Geist, Bill Gropp, Laxmikant Kale, Bill Kramer,and Marc Snir. Toward exascale resilience. November 2009.
[18] Trevor E. Carlson, Wim Heirman, and Lieven Eeckhout. Sniper: Ex-ploring the level of abstraction for scalable and accurate parallel multi-core simulation. In Proceedings of 2011 International Conference forHigh Performance Computing, Networking, Storage and Analysis, SC’11, pages 52:1–52:12, New York, NY, USA, 2011. ACM.
[19] Hassan Cha�, Arvind K. Sujeeth, Kevin J. Brown, HyoukJoong Lee,Anand R. Atreya, and Kunle Olukotun. A domain-speci�c approach toheterogeneous parallelism. In Proceedings of the 16th ACM Symposiumon Principles and Practice of Parallel Programming, PPoPP ’11, pages35–46, New York, NY, USA, 2011. ACM.
[20] James Clarkson, Christos Kotselidis, Gavin Brown, and Mikel Lujan.Boosting java performance using gpgpus. In ARCS 2017: InternationalConference on Architecture of Computing Systems, volume 10172, pages59–70. LNCS dx.doi.org/10.1007/978-3-319-54999-6 5, 2017.
[21] C. Constantinescu. Trends and challenges in vlsi circuit reliability.IEEE Micro, 23(4):14–19, July 2003.
[22] Amanieu d’Antras, Cosmin Gorgovan, Jim Garside, and Mikel Lujan.Optimizing indirect branches in dynamic binary translators. ACMTrans. Archit. Code Optim., 13(1):7:1–7:25, April 2016.
[23] Xiangyu Dong, Cong Xu, Norm Jouppi, and Yuan Xie. Nvsim: Acircuit-level performance, energy, and area model for emerging non-volatile memory. In Emerging Memory Technologies, pages 15–50.Springer, 2014.
[24] G. Duboscq, L. Stadler, T. Wurthinger, D. Simon, C. Wimmer, andH. Mossenbock. Graal ir: An extensible declarative intermediaterepresentation. In Asia-Paci�c Programming Languages and Compilers,2013.
[25] Hadi Esmaeilzadeh, Emily Blem, Renee St. Amant, Karthikeyan Sankar-alingam, and Doug Burger. Dark silicon and the end of multicorescaling. In Proceedings of the 38th Annual International Symposium onComputer Architecture, ISCA ’11, pages 365–376, New York, NY, USA,2011. ACM.
[26] Cortex-A Series Programmer’s Guide for ARMv8-A.h�p://infocenter.arm.com/help/topic/com.arm.doc.den0024a/DEN0024A v8 architecture PG.pdf. October 12, 2021.
[27] Cosmin Gorgovan, Amanieu d’Antras, and Mikel Lujan. Mambo: Alow-overhead dynamic binary modi�cation tool for arm. ACM Trans.Archit. Code Optim., 13(1):14:1–14:26, April 2016.
[28] Mark Go�scho, Sriram Govindan, Bikash Sharma, Mohammed Shoaib,and Puneet Gupta. X-mem: A cross-platform and extensible memorycharacterization tool for the cloud. In 2016 IEEE International Sympo-sium on Performance Analysis of Systems and So�ware, ISPASS 2016,Uppsala, Sweden, April 17-19, 2016, pages 263–273, 2016.
[29] Max Grossman and Vivek Sarkar. Swat: A programmable, in-memory,distributed, high-performance computing platform. In Proceedings ofthe 25th ACM International Symposium on High-Performance Paralleland Distributed Computing, HPDC ’16, pages 81–92, New York, NY,USA, 2016. ACM.
[30] A. Handa, T. Whelan, J.B. McDonald, and A.J. Davison. A Benchmarkfor RGB-D Visual Odometry, 3D Reconstruction and SLAM. In ICRA,2014.
[31] Akihiro Hayashi, Max Grossman, Jisheng Zhao, Jun Shirako, andVivek Sarkar. Accelerating habanero-java programs with opencl gen-eration. In Proceedings of the 2013 International Conference on Principlesand Practices of Programming on the Java Platform: Virtual Machines,Languages, and Tools, 2013.
[32] Wim Heirman, Souradip Sarkar, Trevor E. Carlson, Ibrahim Hur, andLieven Eeckhout. Power-aware multi-core simulation for early de-sign stage hardware/so�ware co-optimization. In Proceedings of the21st International Conference on Parallel Architectures and CompilationTechniques, PACT ’12, pages 3–12, New York, NY, USA, 2012. ACM.
[33] Wei Huang, S. Ghosh, S. Velusamy, K. Sankaranarayanan, K. Skadron,and M.R. Stan. HotSpot: A Compact �ermal Modeling Methodol-ogy for Early-Stage VLSI Design. Very Large Scale Integration (VLSI)Systems, IEEE Transactions on, 14(5):501–513, 2006.
[34] Intel. Intel Atom Processor E6x5C Series-Based Platform for EmbeddedComputing. h�ps://newsroom.intel.com/wp-content/uploads/sites/11/2016/01/ProductBrief-IntelAtomProcessor E600C series.pdf.Online; last accessed 23-March-2016.
[35] K. Ishizaki, A. Hayashi, G. Koblents, and V. Sarkar. Compiling andOptimizing Java 8 Programs for GPU Execution. In 2015 InternationalConference on Parallel Architecture and Compilation (PACT), pages419–431, Oct 2015.
[36] Jep 243: Java-level jvm compiler interface.h�p://openjdk.java.net/jeps/243, 2016. [Online; last accessed1-Feb-2016].
[37] M. Kaliorakis, S. Tselonis, A. Chatzidimitriou, N. Foutris, and D. Gi-zopoulos. Di�erential fault injection on microarchitectural simulators.In Workload Characterization (IISWC), 2015 IEEE International Sympo-sium on, pages 172–182, Oct 2015.
[38] Christos Kotselidis, James Clarkson, Andrey Rodchenko, Andy Nisbet,John Mawer, and Mikel Lujan. Heterogeneous managed runtimesystems: A computer vision case study. In Proceedings of the 13thACM SIGPLAN/SIGOPS International Conference on Virtual ExecutionEnvironments, VEE ’17, pages 74–82, New York, NY, USA, 2017. ACM.
[39] Man-Lap Li, Pradeep Ramachandran, Swarup Kumar Sahoo, Sarita V.Adve, Vikram S. Adve, and Yuanyuan Zhou. Understanding the propa-gation of hard errors to so�ware and implications for resilient systemdesign. SIGOPS Oper. Syst. Rev., 42(2):265–276, March 2008.
[40] Sheng Li, Jung-Ho Ahn, R.D. Strong, J.B. Brockman, D.M. Tullsen,and N.P. Jouppi. McPAT: An Integrated Power, Area, and TimingModeling Framework for Multicore and Manycore Architectures. In42nd Annual IEEE/ACM International Symposium on Microarchitecture,pages 469–480, 2009.
[41] Sheng Li, Jung Ho Ahn, Richard D. Strong, Jay B. Brockman, Dean M.Tullsen, and Norman P. Jouppi. �e mcpat framework for multicoreand manycore architectures: Simultaneously modeling power, area,and timing. ACM Trans. Archit. Code Optim., 10(1):5:1–5:29, April 2013.
[42] Sheng Li, Ke Chen, Jung Ho Ahn, Jay B Brockman, and Norman PJouppi. Cacti-p: Architecture-level modeling for sram-based structureswith advanced leakage reduction techniques. In Computer-AidedDesign (ICCAD), 2011 IEEE/ACM International Conference on, pages694–701. IEEE, 2011.
[43] Chi-Keung Luk, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser,Geo� Lowney, Steven Wallace, Vijay Janapa Reddi, and Kim Hazel-wood. Pin: Building customized program analysis tools with dynamicinstrumentation. In Proceedings of the 2005 ACM SIGPLAN Conferenceon Programming Language Design and Implementation, PLDI ’05, pages190–200, New York, NY, USA, 2005. ACM.
[44] M. Maniatakos, N. Karimi, C. Tirumurti, A. Jas, and Y. Makris.Instruction-level impact analysis of low-level faults in a modern micro-processor controller. IEEE Transactions on Computers, 60(9):1260–1273,Sept 2011.
[45] John Mawer, Oscar Palomar, Cosmin Gorgovan, Will Toms, AndyNisbet, and Mikel Lujan. �e potential of dynamic binary modi�cationand cpu/fpga socs for simulation. In 25th IEEE International Symposiumon Field-Programmable Custom Computing Machines (FCCM), 2017.
[46] Luigi Nardi, Bruno Bodin, M. Zeeshan Zia, John Mawer, Andy Nisbet,Paul H. J. Kelly, Andrew J. Davison, Mikel Lujan, Michael F. P. O’Boyle,Graham Riley, Nigel Topham, and Steve Furber. Introducing SLAM-Bench, a performance and accuracy benchmarking methodology forSLAM. In ICRA, 2015.
[47] Richard A. Newcombe, Shahram Izadi, Otmar Hilliges, DavidMolyneaux, David Kim, Andrew J. Davison, Pushmeet Kohli, JamieSho�on, Steve Hodges, and Andrew Fitzgibbon. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 201110th IEEE International Symposium on Mixed and Augmented Real-ity, ISMAR ’11, pages 127–136, Washington, DC, USA, 2011. IEEEComputer Society.
[48] P.C. Pra�-Szeliga, J.W. Fawce�, and R.D. Welch. Rootbeer: Seamlesslyusing gpus from java. In Proceedings of 14th International IEEE HighPerformance Computing and Communication Conference on EmbeddedSo�ware and Systems, 2012.
[49] Brandon Reagen, Paul Whatmough, Robert Adolf, Saketh Rama,Hyunkwang Lee, Sae Kyu Lee, Jos Miguel Hernndez-Lobato, Gu-YeonWei, and David Brooks. Minerva: Enabling low-power, highly-accuratedeep neural network accelerators. In Proceedings of the 43rd AnnualInternational Symposium on Computer Architecture, ISCA ’16. ACM,2016.
[50] Andrey Rodchenko, Christos Kotselidis, Andy Nisbet, Antoniu Pop,and Mikel Lujan. Maxsim: A simulator platform for managed appli-cations. In ISPASS - IEEE International Symposium on PerformanceAnalysis of Systems and So�ware, 2017.
[51] Andrey Rodchenko, Christos Kotselidis, Andy Nisbet, Antoniu Pop,and Mikel Lujan. Type information elimination from objects on ar-chitectures with tagged pointers support. In IEEE Transactions onComputers, 2017.
[52] Daniel Sanchez and Christos Kozyrakis. Zsim: Fast and accurate mi-croarchitectural simulation of thousand-core systems. In Proceedingsof the 40th Annual International Symposium on Computer Architecture,ISCA ’13, pages 475–486, New York, NY, USA, 2013. ACM.
[53] Muhammad Sha�que, Siddharth Garg, Jorg Henkel, and Diana Mar-culescu. �e eda challenges in the dark silicon era: Temperature,reliability, and variability perspectives. In Proceedings of the 51st An-nual Design Automation Conference, DAC ’14, pages 185:1–185:6, NewYork, NY, USA, 2014. ACM.
[54] Sniper. Jikes - sniper page in sniper online documentation. h�p://snipersim.org/w/Jikes, 2014. [Online; last accessed 1-Feb-2016].
[55] M7: Next Generation SPARC. h�p://www.oracle.com/us/products/servers-storage/servers/sparc-enterprise/migration/m7-next-gen-sparc-presentation-2326292.html. October 12, 2021.
[56] SpecCPU2006. h�ps://www.spec.org/cpu2006/. October 12, 2021.[57] SpecJVM2008. h�ps://www.spec.org/jvm2008/. October 12, 2021.[58] J. Srinivasan, S. V. Adve, P. Bose, and J. A. Rivers. �e impact of
technology scaling on lifetime reliability. In Dependable Systems andNetworks, 2004 International Conference on, pages 177–186, June 2004.
[59] Lukas Stadler, �omas Wurthinger, and Hanspeter Mossenbock. Par-tial escape analysis and scalar replacement for java. In Proceedings ofAnnual IEEE/ACM International Symposium on Code Generation andOptimization, CGO ’14, pages 165:165–165:174, New York, NY, USA,2014. ACM.
[60] Arvind K. Sujeeth, Austin Gibbons, Kevin J. Brown, HyoukJoong Lee,Tiark Rompf, Martin Odersky, and Kunle Olukotun. Forge: Generatinga high performance dsl implementation from a declarative speci�ca-tion. In Proceedings of the 12th International Conference on GenerativeProgramming: Concepts & Experiences, GPCE ’13, pages 145–154,New York, NY, USA, 2013. ACM.
[61] Arvind K. Sujeeth, Hyoukjoong Lee, Kevin J. Brown, Hassan Cha�,Michael Wu, Anand R. Atreya, Kunle Olukotun, Tiark Rompf, andMartin Odersky. Optiml: an implicitly parallel domainspeci�c lan-guage for machine learning. In in Proceedings of the 28th InternationalConference on Machine Learning, ser. ICML, 2011.
[63] Christian Wimmer, Michael Haupt, Michael L. Van De Vanter, MickJordan, Laurent Daynes, and Douglas Simon. Maxine: An approach-able virtual machine for, and in, java. January 2013.
[64] �omas Wurthinger, Christian Wimmer, Andreas Woß, Lukas Stadler,Gilles Duboscq, Christian Humer, Gregor Richards, Doug Simon, andMario Wolczko. One vm to rule them all. In Proceedings of the 2013ACM International Symposium on New Ideas, New Paradigms, andRe�ections on Programming & So�ware, Onward! ’13, 2013.
[65] Xilinx. Zynq-7000 all programmable SoC overview.h�p://www.xilinx.com/support/documentation/data sheets/ds190-Zynq-7000-Overview.pdf.Online; last accessed 23-March-2016.
[66] Runjie Zhang, Ke Wang, B.H. Meyer, M.R. Stan, and K. Skadron. Ar-chitecture implications of pads as a scarce resource. In ACM/IEEE 41stInternational Symposium on Computer Architecture, pages 373–384,2014.