41
Alvaro Saurin RabbitMQ in Sprayer
| Date post: | 10-May-2015 |
| Category: |
Technology |
| Upload: | alvaro-saurin |
| View: | 1,283 times |
| Download: | 3 times |
Alvaro Saurin
RabbitMQ in Sprayer
Introduction01
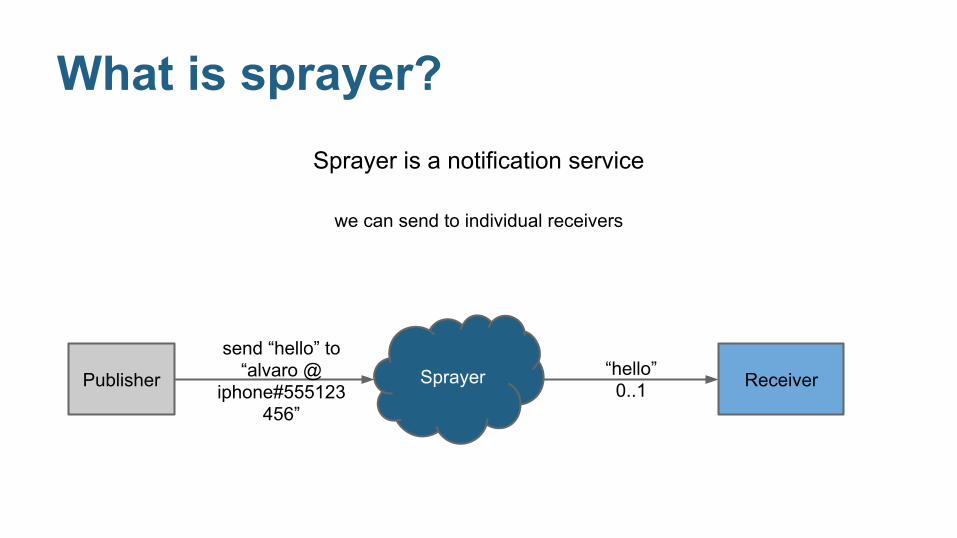
What is sprayer?
Publisher ReceiverSprayersend “hello” to
“alvaro @ iphone#555123
456”
Sprayer is a notification service
we can send to individual receivers
“hello”0..1

What is sprayer?Sprayer has PubSub semantics
we can send to receivers subscribed to a topic
Publisher Sprayersend “hello” to
users subscribed to
“news”
“hello”0..n Receivers
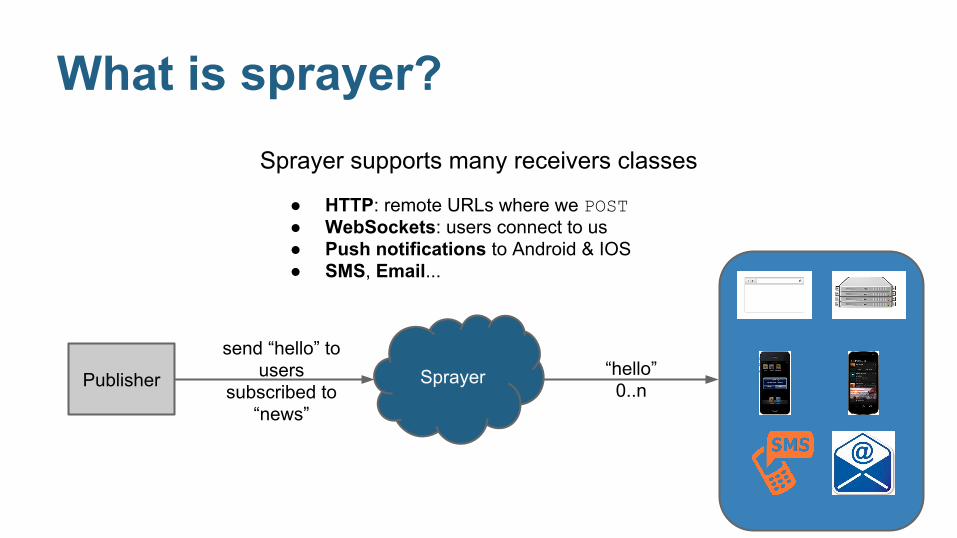
What is sprayer?Sprayer supports many receivers classes
Publisher Sprayersend “hello” to
users subscribed to
“news”
“hello”0..n
● HTTP: remote URLs where we POST● WebSockets: users connect to us● Push notifications to Android & IOS● SMS, Email...
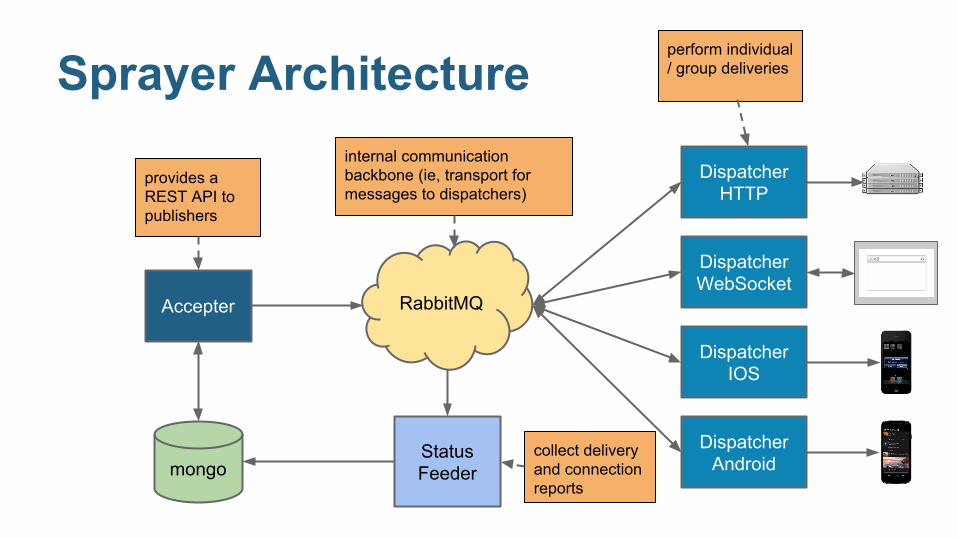
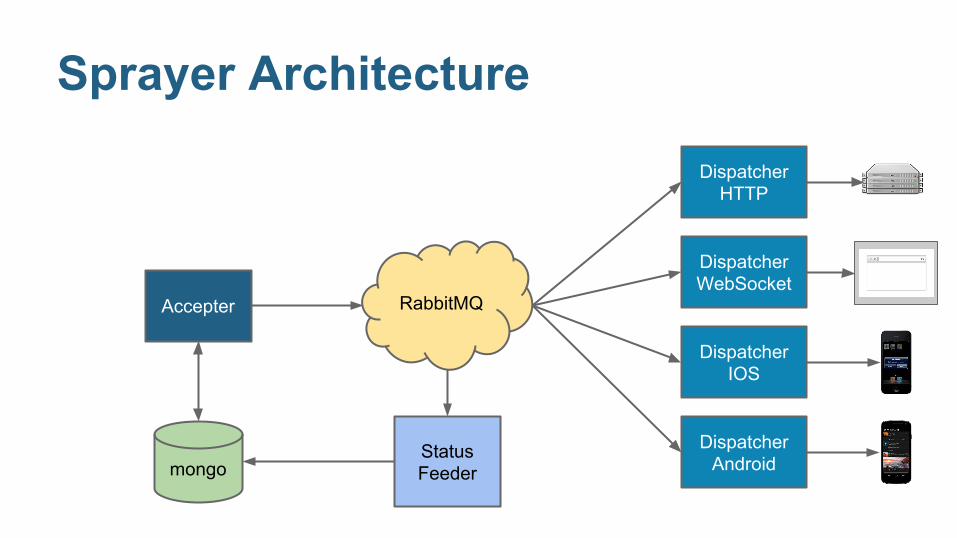
Sprayer Architecture
Accepter
Dispatcher HTTP
Dispatcher IOS
Dispatcher Android
Dispatcher WebSocket
Status Feeder
RabbitMQ
mongo
provides a REST API to publishers
internal communication backbone (ie, transport for messages to dispatchers)
perform individual / group deliveries
collect delivery and connection reports
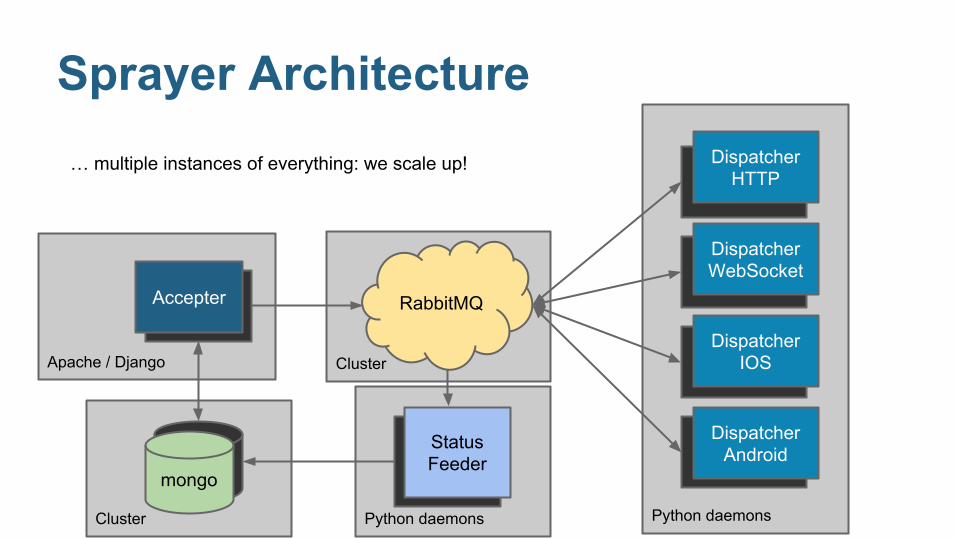
Cluster
Cluster
Python daemons Python daemons
Apache / Django
Sprayer Architecture
Accepter
Dispatcher HTTP
RabbitMQ
Dispatcher IOS
Dispatcher Android
Dispatcher WebSocket
Status Feedermongo
Accepter
Dispatcher HTTP
Dispatcher WebSocket
Dispatcher IOS
Dispatcher Android
Status Feeder
mongo
… multiple instances of everything: we scale up!

RabbitMQ02

RabbitMQ in Sprayer
so we use RabbitMQ as the main transport for messages
we ended up having a few queues:
● queues for sending messages to dispatchers
● queues for sending delivery reports to the status feeder
● ...
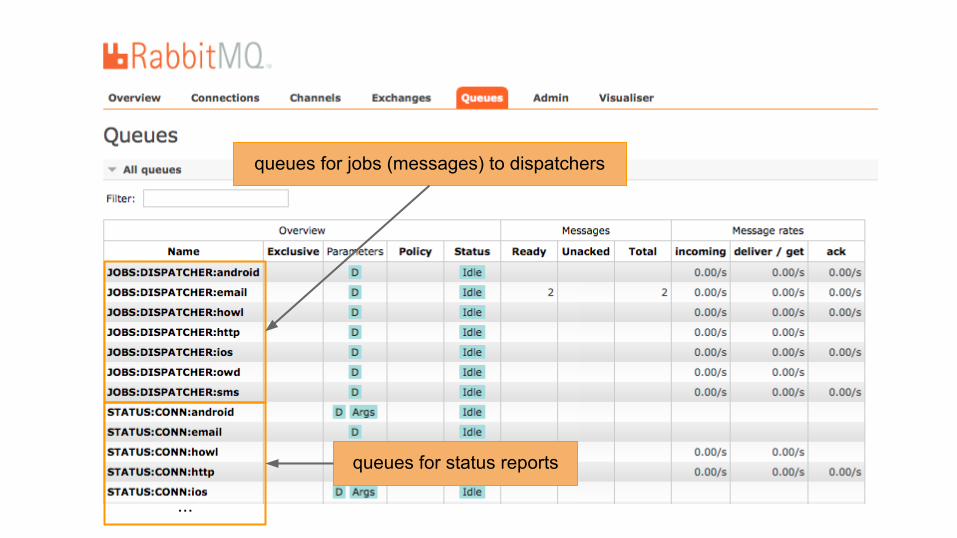
queues for jobs (messages) to dispatchers
...
queues for status reports
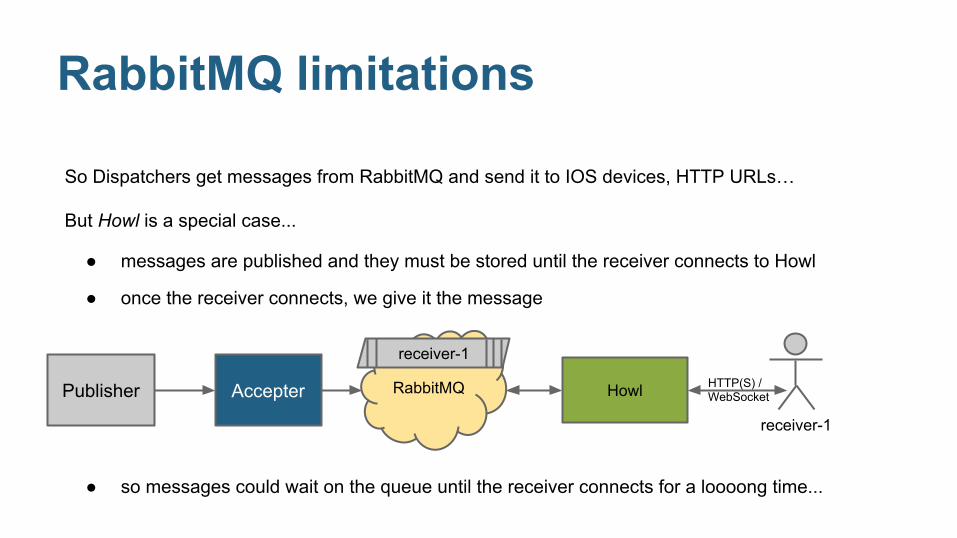
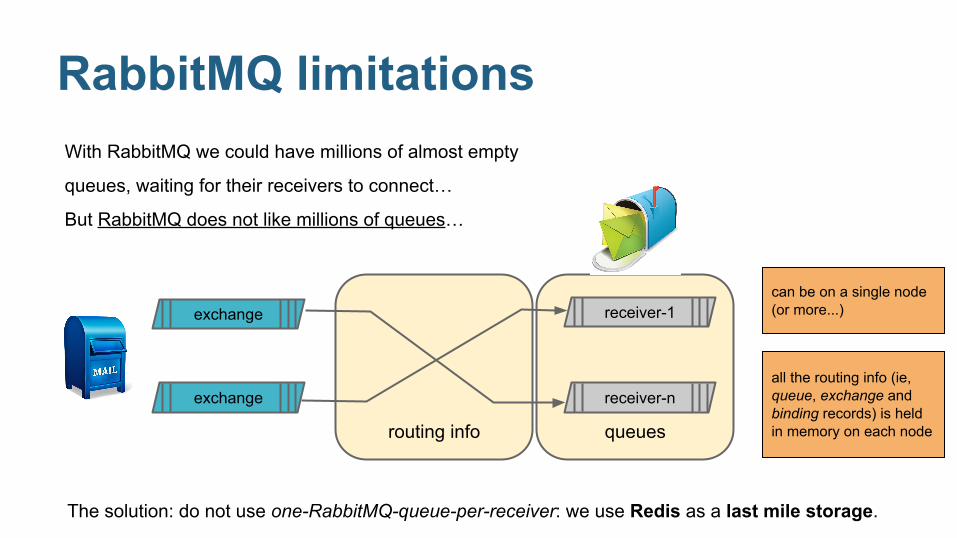
RabbitMQ limitations
So Dispatchers get messages from RabbitMQ and send it to IOS devices, HTTP URLs… But Howl is a special case...
HowlRabbitMQ
receiver-1
Publisher Accepter
receiver-1
● messages are published and they must be stored until the receiver connects to Howl
● once the receiver connects, we give it the message
● so messages could wait on the queue until the receiver connects for a loooong time...
HTTP(S) / WebSocket
routing info queues
RabbitMQ limitationsWith RabbitMQ we could have millions of almost empty
queues, waiting for their receivers to connect…
But RabbitMQ does not like millions of queues…
receiver-1
receiver-n
exchange
exchange
The solution: do not use one-RabbitMQ-queue-per-receiver: we use Redis as a last mile storage.
can be on a single node (or more...)
all the routing info (ie, queue, exchange and binding records) is held in memory on each node
Sprayer Architecture
Accepter
Dispatcher HTTP
RabbitMQ
Dispatcher IOS
Dispatcher Android
Dispatcher WebSocket
Status Feedermongo
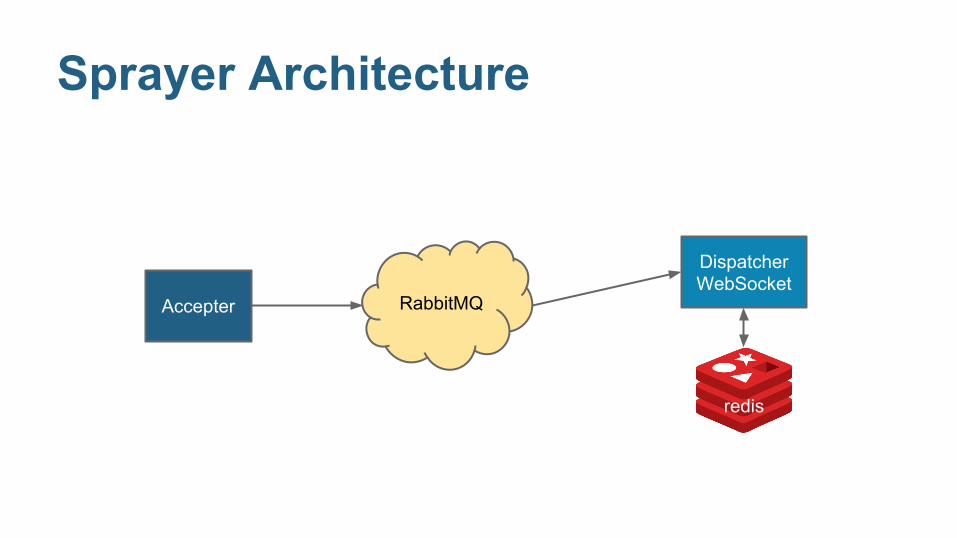
Sprayer Architecture
RabbitMQ
Dispatcher WebSocket
Accepter
redis
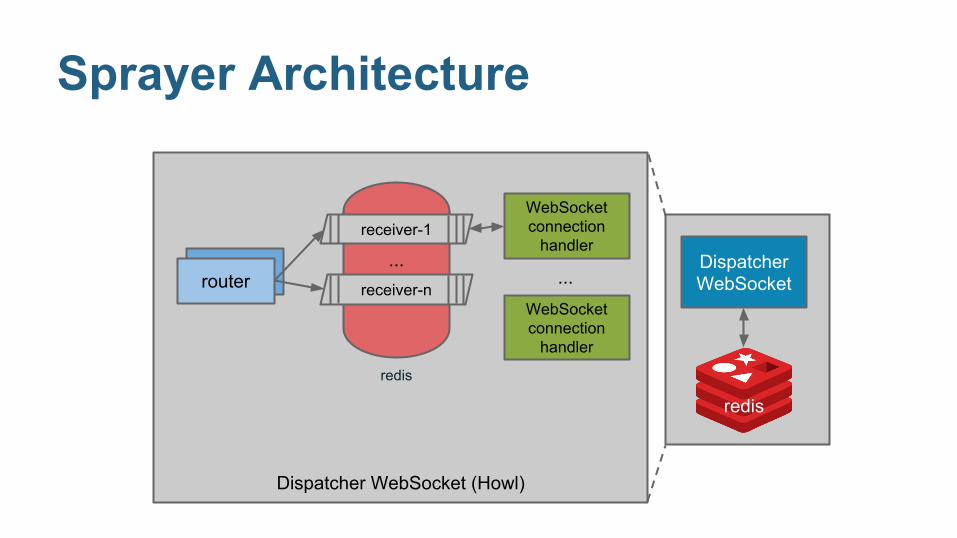
Dispatcher WebSocket (Howl)
Sprayer Architecture
Dispatcher WebSocket
receiver-1
receiver-n
...router
WebSocket connection
handler
WebSocket connection
handler
redis
...
redis
RabbitMQ
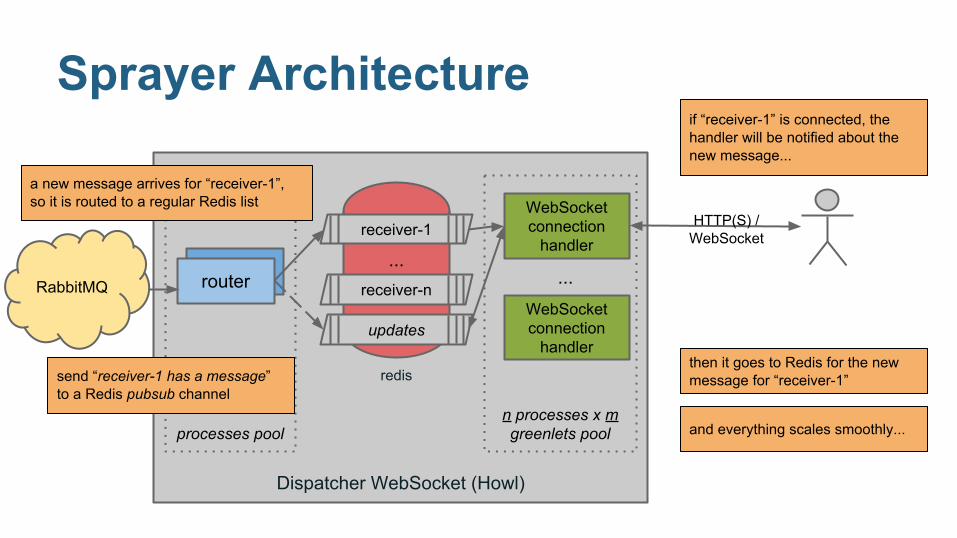
Dispatcher WebSocket (Howl)
Sprayer Architecture
receiver-1
receiver-n
...
updates
router
processes pooln processes x m greenlets pool
WebSocket connection
handler
WebSocket connection
handler
redis
...
send “receiver-1 has a message” to a Redis pubsub channel
if “receiver-1” is connected, the handler will be notified about the new message...
then it goes to Redis for the new message for “receiver-1”
a new message arrives for “receiver-1”, so it is routed to a regular Redis list
and everything scales smoothly...
HTTP(S) / WebSocket
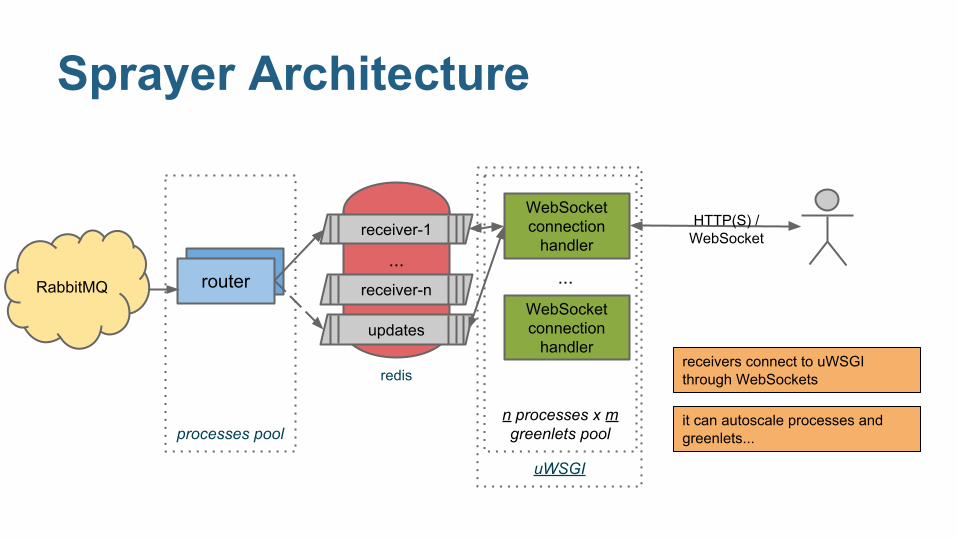
uWSGI
Sprayer Architecture
receiver-1
receiver-n
...
updates
router
processes pooln processes x m greenlets pool
WebSocket connection
handler
WebSocket connection
handler
RabbitMQ
redis
...
HTTP(S) / WebSocket
receivers connect to uWSGI through WebSockets
it can autoscale processes and greenlets...
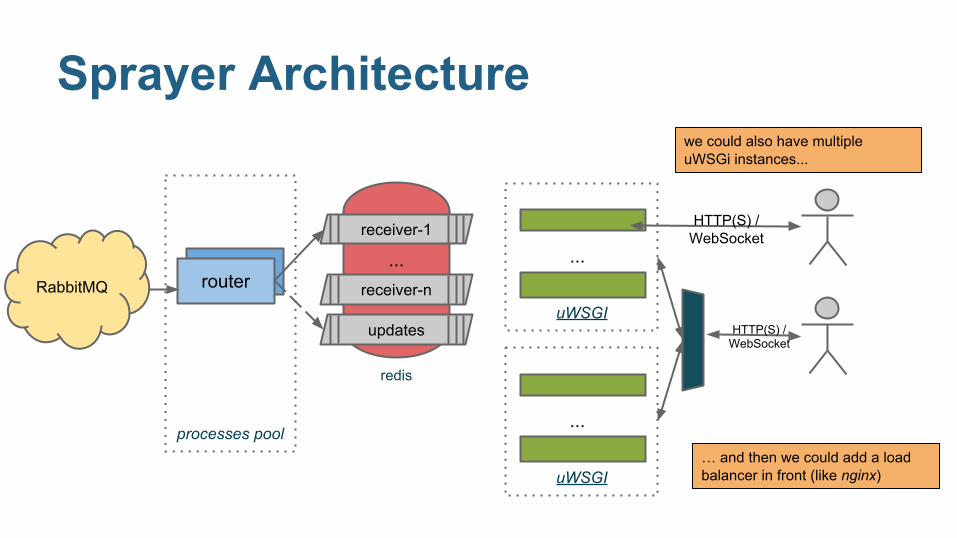
Sprayer Architecture
receiver-1
receiver-n
...
updates
router
processes pool
RabbitMQ
redis
uWSGI
...
… and then we could add a load balancer in front (like nginx)
uWSGI
...
HTTP(S) / WebSocket
HTTP(S) / WebSocket
we could also have multiple uWSGi instances...
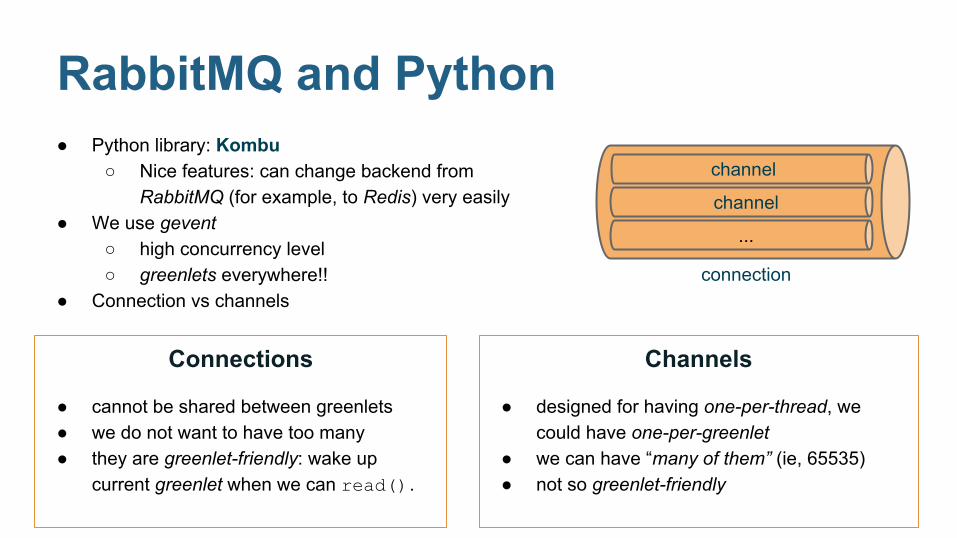
RabbitMQ and Python● Python library: Kombu
○ Nice features: can change backend from RabbitMQ (for example, to Redis) very easily
● We use gevent○ high concurrency level○ greenlets everywhere!!
● Connection vs channels
channel
channel
...
connection
Connections
● cannot be shared between greenlets● we do not want to have too many● they are greenlet-friendly: wake up
current greenlet when we can read().
Channels
● designed for having one-per-thread, we could have one-per-greenlet
● we can have “many of them” (ie, 65535)● not so greenlet-friendly

RabbitMQ and Python
>>> connection = Connection('amqp://')
>>> pool = connection.Pool(2)
>>> c1 = pool.acquire()
>>> c2 = pool.acquire()
>>> c3 = pool.acquire()
>>> c1.release()
>>> c3 = pool.acquire()
● So we decided to go for a simple pool of connections…
● We restrict who can read from queues
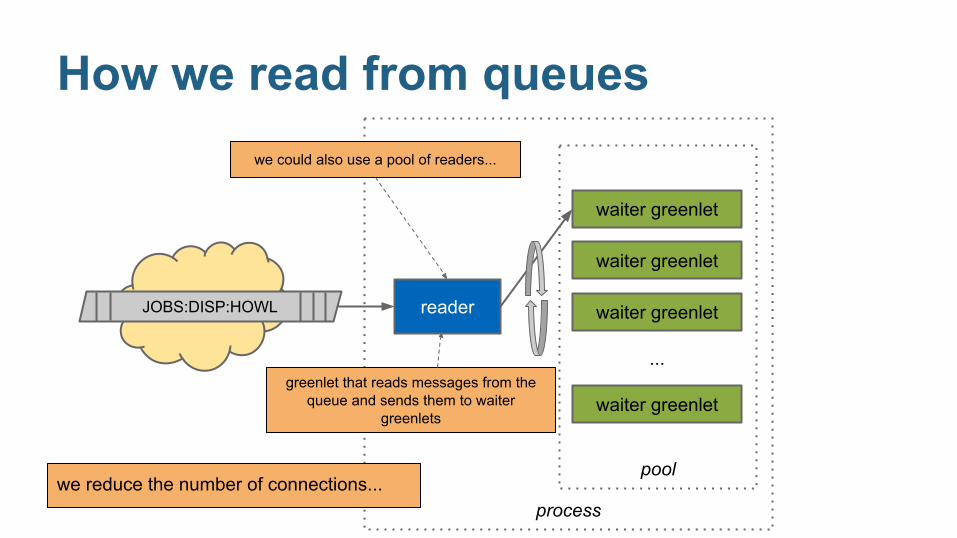
process
pool
How we read from queues
readerRabbitMQJOBS:DISP:HOWL
waiter greenlet
waiter greenlet
waiter greenlet
waiter greenlet
...
we reduce the number of connections...
we could also use a pool of readers...
greenlet that reads messages from the queue and sends them to waiter
greenlets

Clustering and HA03

High Availability: overview
Target: always (someone) available, zero downtime!!
First, you need a cluster !!! [
...
{rabbit, [
...
{cluster_nodes,
{['rabbit@rabbit1',
'rabbit@rabbit2',
'rabbit@rabbit3'],
disc}},
...
]},
...
].
/etc/rabbitmq/rabbitmq.config
Then you need to share a cookie between all the members of the cluster...
… and that’s all !!!

cluster nodes types:
● disk-node: they persist data to disk● memory-node: they only work with on-memory data
For maximum security, at least 2 disk nodes are recommended.
For maximum performance, do not use all disk-nodes.
High Availability: the cluster
(RabbitMQ 2.8.1 - PowerEdge R610 with dual Xeon E5530s and 40GB RAM)
[
...
{rabbit, [
...
{cluster_nodes,
{['rabbit@rabbit1',
'rabbit@rabbit2',
'rabbit@rabbit3'],
disc}},
...
]},
...
].
/etc/rabbitmq/rabbitmq.config

Some operations considerations:
● nodes must be started up in reverse order to the one they were stopped down
● remember: all the nodes in the cluster must share the same Erlang cookie in order to
communicate
High Availability: the cluster

High Availability: overview… then we can use Mirrored Queues for achieving HA…
Mirrored Queues:
Active/active high availability for queues. This works by allowing queues to be mirrored on
other nodes within a RabbitMQ cluster. The result is that should one node of a cluster fail, the
queue can automatically switch to one of the mirrors and continue to operate, with no
unavailability of service.

High Availability: setting things up
Very easy setup:
● From command line:
rabbitmqctl set_policy ha-all "^JOBS\." '{"ha-mode":"all"}'
● … or from the web console
● … or when creating the queue from Kombu
we can also specify # of replicas, or the nodes names...
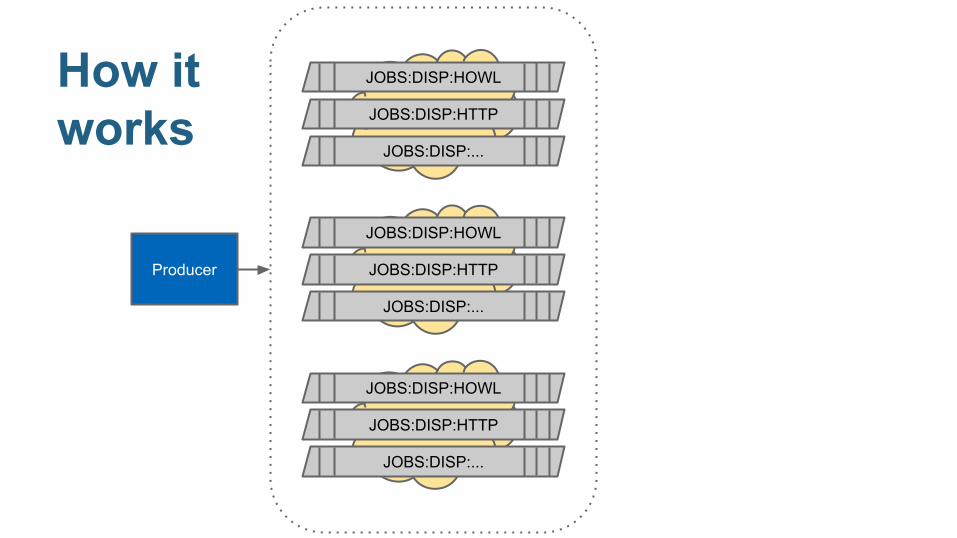
Producer RabbitMQ
JOBS:DISP:HOWL
JOBS:DISP:HTTP
JOBS:DISP:...
JOBS:DISP:HOWL
JOBS:DISP:HTTP
JOBS:DISP:...
JOBS:DISP:HOWL
JOBS:DISP:HTTP
JOBS:DISP:...
How it works
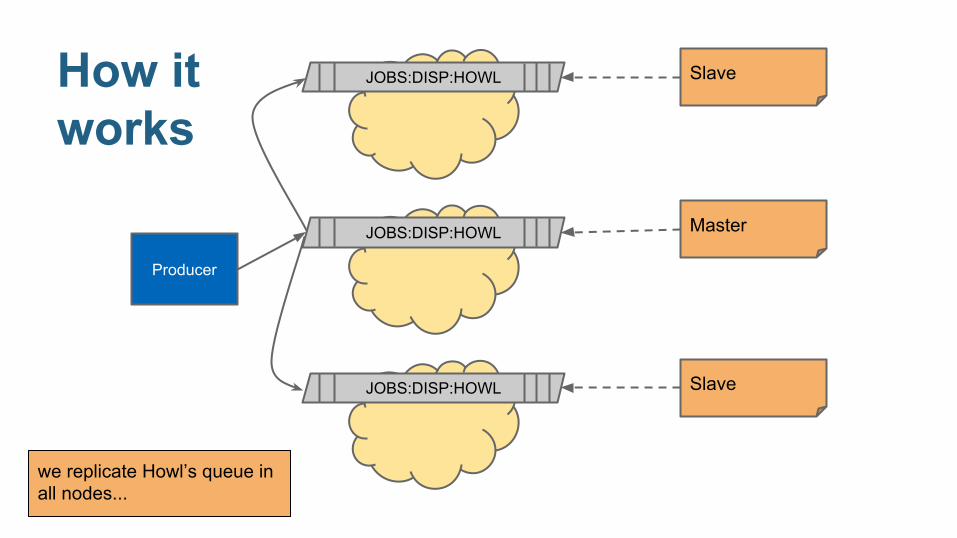
Producer
JOBS:DISP:HOWL
JOBS:DISP:HOWL
JOBS:DISP:HOWL
Master
Slave
Slave
we replicate Howl’s queue in all nodes...
How it works
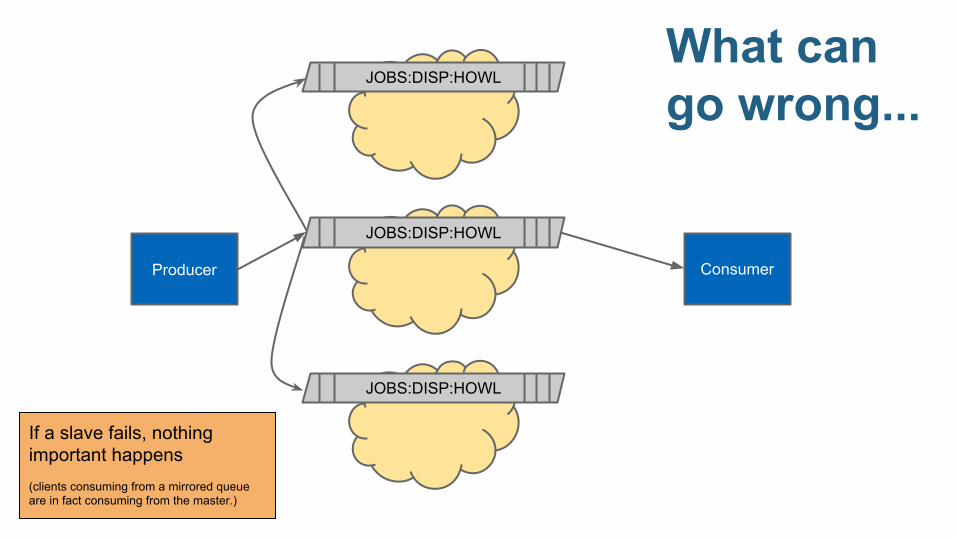
Producer
JOBS:DISP:HOWL
JOBS:DISP:HOWL
If a slave fails, nothing important happens(clients consuming from a mirrored queue are in fact consuming from the master.)
Consumer
JOBS:DISP:HOWLWhat can go wrong...
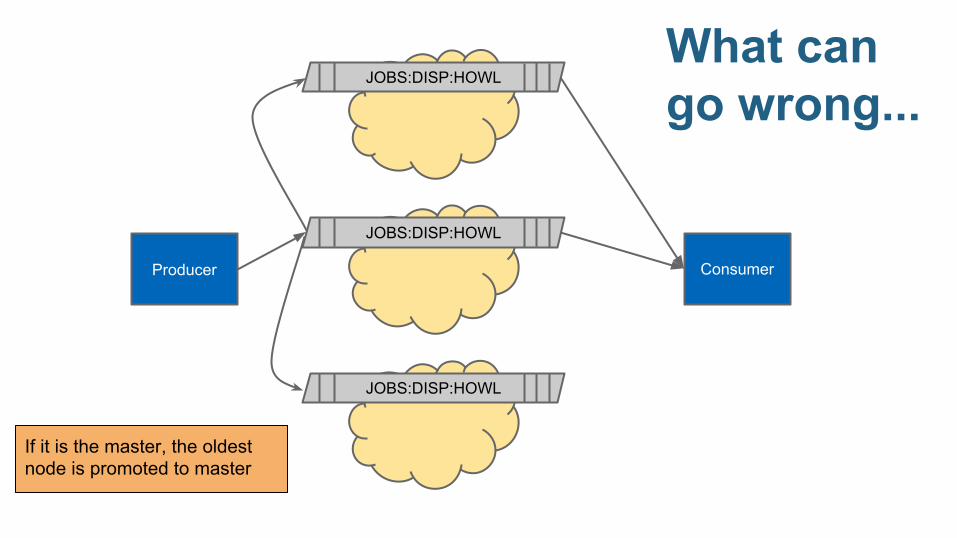
Producer
JOBS:DISP:HOWL
JOBS:DISP:HOWL
JOBS:DISP:HOWL
If it is the master, the oldest node is promoted to master
Consumer
What can go wrong...
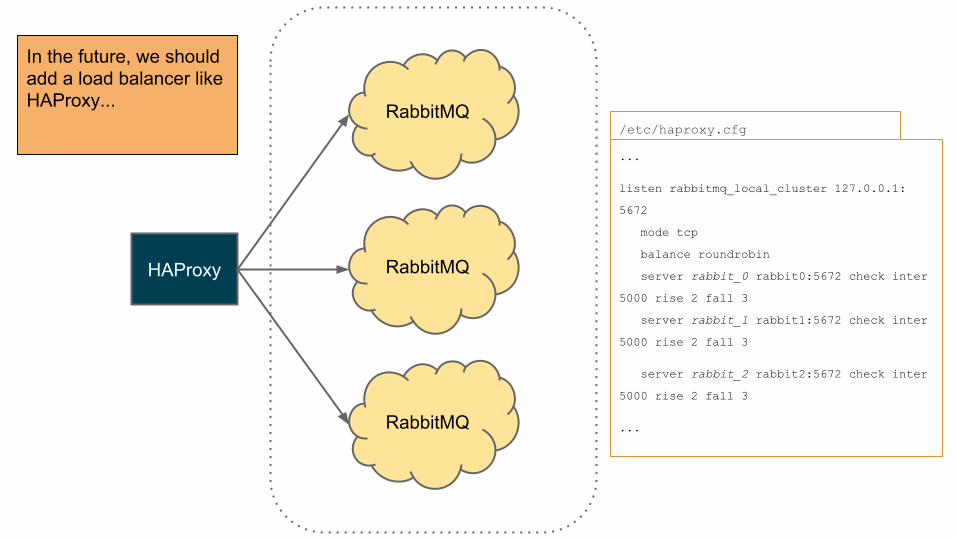
HAProxy RabbitMQ
RabbitMQ
RabbitMQ
In the future, we should add a load balancer like HAProxy...
...
listen rabbitmq_local_cluster 127.0.0.1:
5672
mode tcp
balance roundrobin
server rabbit_0 rabbit0:5672 check inter
5000 rise 2 fall 3
server rabbit_1 rabbit1:5672 check inter
5000 rise 2 fall 3
server rabbit_2 rabbit2:5672 check inter
5000 rise 2 fall 3
...
/etc/haproxy.cfg

… and what about Kombu?what should we do in our Python publisher/consumer when someone dies?
nothing!!!
can ensure() operations: will reconnect if
needed, and recreate exchanges, queues, etc.
after reconnection to a different node…
● takes some time to realize a node is
down…
● so ensure() can take some time to
complete...
>>> from kombu import Connection, Producer
>>> conn = Connection('amqp://')
>>> producer = Producer(conn)
>>> def errback(exc, interval):
... logger.error('Error: %r', exc, exc_info=1)
... logger.info('Retry in %s seconds.', interval)
>>> publish = conn.ensure(producer, producer.publish,
... errback=errback, max_retries=3)
>>> publish({'hello': 'world'}, routing_key='dest')

PartitioningRabbitMQ clusters do not tolerate network partitions well.
● Forget WAN-clusters (use federation or shovel).
● HA-queues end up with a master in each partition.
● When connectivity is restored, you must choose one
partition which you trust the most
What else can go wrong...
2 partitions
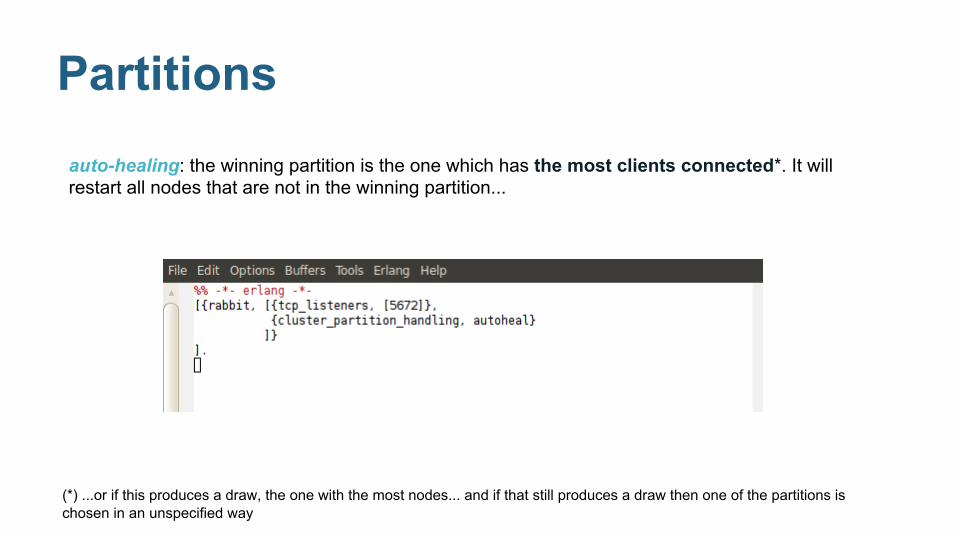
Partitionsauto-healing: the winning partition is the one which has the most clients connected*. It will restart all nodes that are not in the winning partition...
(*) ...or if this produces a draw, the one with the most nodes... and if that still produces a draw then one of the partitions is chosen in an unspecified way

Future directions04
Maybe we will grow...
We must investigate flow-control:
● prevent messages being published faster than they can be routed to queues
● prevent messages from being published when running out of memory/disk
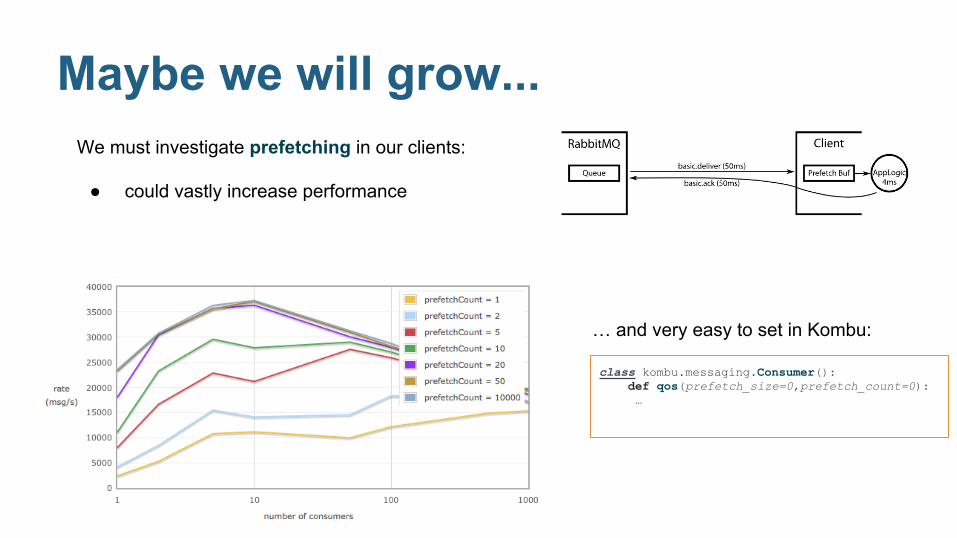
Maybe we will grow...We must investigate prefetching in our clients:
● could vastly increase performance
class kombu.messaging.Consumer(): def qos(prefetch_size=0,prefetch_count=0): …
… and very easy to set in Kombu:
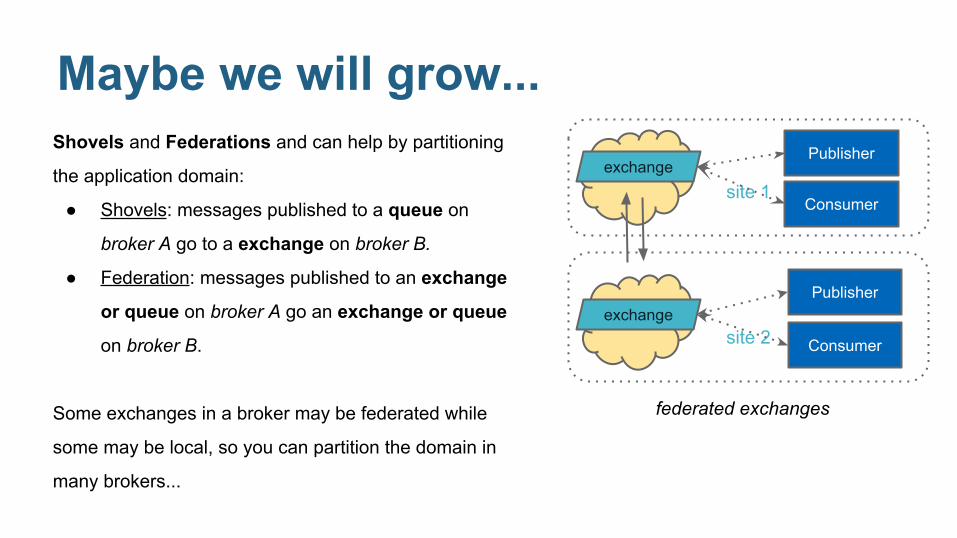
Maybe we will grow...Shovels and Federations and can help by partitioning
the application domain:
● Shovels: messages published to a queue on
broker A go to a exchange on broker B.
● Federation: messages published to an exchange
or queue on broker A go an exchange or queue
on broker B.
Some exchanges in a broker may be federated while
some may be local, so you can partition the domain in
many brokers...
site 1
site 2
exchange
exchange
Publisher
Consumer
Publisher
Consumer
federated exchanges

Maybe we will grow...
and last but not least...
SSD disks seem to make a huge difference in RabbitMQ performance. All disk writes in Rabbit are append-only, but when if you have many queues…
Alvaro Saurin
RabbitMQ in Sprayer
questions…?

















