Real-Time Background Subtraction using Adaptive Thresholding and Dynamic Updating for Biometric Face Detection K. Sundaraj University Malaysia Perlis School of Mechatronic Engineering 02600 Jejawi - Perlis MALAYSIA [email protected]Abstract: Face biometrics is an automated method of recognizing a person’s face based on a physiological or be- havioral characteristic. Face recognition works by first obtaining an image of a person. This process is usually known as face detection. In this paper, we describe an approach for face detection that is able to locate a human face embedded in an outdoor or indoor background. Segmentation of novel or dynamic objects in a scene, often referred to as background subtraction or foreground segmentation, is a critical early step in most computer vision applications in domains such as surveillance and human-computer interaction. All previous implementations aim to handle properly one or more problematic phenomena, such as global illumination changes, shadows, highlights, foreground-background similarity, occlusion and background clutter. Satisfactory results have been obtained but very often at the expense of real-time performance. We propose a method for modeling the background that uses per-pixel time-adaptive Gaussian mixtures in the combined input space of pixel color and pixel neighborhood. We add a safety net to this approach by splitting the luminance and chromaticity components in the background and use their density functions to detect shadows and highlights. Several criteria are then combined to discrimi- nate foreground and background pixels. Our experiments show that the proposed method possesses robustness to problematic phenomena such as global illumination changes, shadows and highlights, without sacrificing real-time performance, making it well-suited for a live video event like face biometric that requires face detection and recog- nition. Key–Words: Background Modeling, Face Detection, Biometric Identification. 1 Introduction Face detection is the first critical processing stage in all kinds of face analysis and modeling applications. These applications have become increasingly attrac- tive in modern life. Video surveillance, facial ani- mation, facial expression analysis, video conferenc- ing, etc. are some of the emerging applications that lure people of both academic and commercial interests over the past decade. Although many laboratory and commercial systems have been developed, most of the proposed methods aim at detecting faces over still im- ages. Since still images convey only visual cues of colors, textures and shapes in the spatial domain, the difficulty and complexity in detecting faces surges as the conveyed spatial-domain cues become vague or noisy. Observing the above-mentioned applications, we find that the major source of faces to be detected is in video data. Video data carries not only the spatial visual information, but also the temporal motion in- formation. The addition of temporal motion informa- tion removes some of the ambiguity suffered in spa- tial visual cues, lowering down the difficulty in face detection. Many of the currently developed systems design their algorithms by trading off detection accu- racy for higher speeds, or vice versa. With the inclu- sion of temporal motion information, many complex situations that require lots of processing time or suffer from detection accuracy become simpler. Therefore, incorporating both spatial and temporal cues for face detection offers an inspirational solution to the prob- lem. Background subtraction is a method that takes ad- vantage of both spatial and temporal cues to identify and track regions of interest. If these regions of inter- est, also known as foreground object, can be detected precisely and effectively, then subsequent image pro- cessing stages will be presented with a much limited processing area within an image. This reduction will lead to better efficiency, accuracy and computational cost for the complete vision system. Within the lit- erature, various techniques that employ background subtraction can be found. Most of these techniques WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj ISSN: 1109-2750 1762 Issue 10, Volume 7, October 2008
Transcript
Real-Time Background Subtraction using Adaptive Thresholdingand Dynamic Updating for Biometric Face Detection
K. SundarajUniversity Malaysia Perlis
School of Mechatronic Engineering02600 Jejawi - Perlis
Abstract: Face biometrics is an automated method of recognizing a person’s face based on a physiological or be-havioral characteristic. Face recognition works by first obtaining an image of a person. This process is usuallyknown as face detection. In this paper, we describe an approach for face detection that is able to locate a humanface embedded in an outdoor or indoor background. Segmentation of novel or dynamic objects in a scene, oftenreferred to as background subtraction or foreground segmentation, is a critical early step in most computer visionapplications in domains such as surveillance and human-computer interaction. All previous implementations aimto handle properly one or more problematic phenomena, such as global illumination changes, shadows, highlights,foreground-background similarity, occlusion and background clutter. Satisfactory results have been obtained butvery often at the expense of real-time performance. We propose a method for modeling the background that usesper-pixel time-adaptive Gaussian mixtures in the combined input space of pixel color and pixel neighborhood.We add a safety net to this approach by splitting the luminance and chromaticity components in the backgroundand use their density functions to detect shadows and highlights. Several criteria are then combined to discrimi-nate foreground and background pixels. Our experiments show that the proposed method possesses robustness toproblematic phenomena such as global illumination changes, shadows and highlights, without sacrificing real-timeperformance, making it well-suited for a live video event like face biometric that requires face detection and recog-nition.
Key–Words: Background Modeling, Face Detection, Biometric Identification.
1 IntroductionFace detection is the first critical processing stage inall kinds of face analysis and modeling applications.These applications have become increasingly attrac-tive in modern life. Video surveillance, facial ani-mation, facial expression analysis, video conferenc-ing, etc. are some of the emerging applications thatlure people of both academic and commercial interestsover the past decade. Although many laboratory andcommercial systems have been developed, most of theproposed methods aim at detecting faces over still im-ages. Since still images convey only visual cues ofcolors, textures and shapes in the spatial domain, thedifficulty and complexity in detecting faces surges asthe conveyed spatial-domain cues become vague ornoisy. Observing the above-mentioned applications,we find that the major source of faces to be detected isin video data. Video data carries not only the spatialvisual information, but also the temporal motion in-formation. The addition of temporal motion informa-tion removes some of the ambiguity suffered in spa-
tial visual cues, lowering down the difficulty in facedetection. Many of the currently developed systemsdesign their algorithms by trading off detection accu-racy for higher speeds, or vice versa. With the inclu-sion of temporal motion information, many complexsituations that require lots of processing time or sufferfrom detection accuracy become simpler. Therefore,incorporating both spatial and temporal cues for facedetection offers an inspirational solution to the prob-lem.
Background subtraction is a method that takes ad-vantage of both spatial and temporal cues to identifyand track regions of interest. If these regions of inter-est, also known as foreground object, can be detectedprecisely and effectively, then subsequent image pro-cessing stages will be presented with a much limitedprocessing area within an image. This reduction willlead to better efficiency, accuracy and computationalcost for the complete vision system. Within the lit-erature, various techniques that employ backgroundsubtraction can be found. Most of these techniques
WSEAS TRANSACTIONS on COMPUTERS
K. Sundaraj
ISSN: 1109-2750 1762 Issue 10, Volume 7, October 2008
use a background reference image to perform back-ground subtraction. This reference image is obtainedafter the background is mathematically modeled. Inthe final step, the current image is subtracted fromthe reference image to produce a mask that highlightsall foreground objects. The process of image acquisi-tion, background modeling and finally subtracting thecurrent image from the background reference imageis implemented in what is known as the backgroundsubtraction algorithm. Needless to say, a proper com-bination of the three is required to obtain satisfactoryresults for a specific application.
Several background subtraction algorithms havebeen proposed in the recent literature. All of thesemethods try to effectively estimate the backgroundmodel from the temporal sequence of the frames. Oneof the simplest algorithms is frame differencing [1].The current frame is subtracted from the previousframe. This method was extended such that the refer-ence frame is obtained by averaging a period of frames[2] [3] [4] also known as median filtering. A secondextension applied a linear predictive filter to the periodof frames [5] [6]. A disadvantage of this method isthat the coefficients used (based on the sample covari-ance) needs to be estimated for each incoming frame,which makes this method not suitable for real-timeoperation. [7] and [8] proposed a solution to this us-ing a much higher level algorithm for removing back-ground information from a video stream. A furthercomputationally improved technique was developedby [9] and it is reported that this method is success-fully applied in a traffic monitoring system by [10]. Inthese types of time averaging algorithms, the choiceof temporal distance between frames becomes a trickyquestion. It depends on the size and speed of the mov-ing object. According to [11], background subtrac-tion using time averaging algorithms, at best, only tellwhere the motion is. Though this is the simplest al-gorithm, it has many problems; interior pixels of avery slow-moving object are marked as background(known as the aperture problem) and pixels behind themoving object are cast as foreground (known as theghost effect problem). Multi-model algorithms werethen developed to solve this shortcoming. A paramet-ric approach which uses a single Gaussian distribution[12] or multiple Gaussian distribution [13] [14] [15]can be found in the literature. Various improvementstechniques like the Kalman filter to track the changesin illumination [16] [17], updating of Gaussian dis-tributions [18] [19], inclusion of image gradient [20]and the modeling and detection of shadows and high-lights [21] [22] [23] have been done to improve theaccuracy of background subtraction. Non-parametricapproaches have also been attempted in [24] and [25].These approaches use a kernel function to estimate the
density function of the background images.Face biometric applications require the modeling
of environmental lighting changes, shadows and re-flections that appear on a face and the background. Inthe case of online surveillance, the application mustoperate in real-time. Although much as been done onindividual techniques as can be seen in the numerousmethods described above, very few have concentratedon real-time capabilities [26]. Very few of the abovementioned methods can be executed at a frequencyof more that 15Hz. Like most image processing ap-plications, a trade-off has to be made between speedand accuracy in order to obtain an advantage of oneover the other. Hence, the focus of this paper is thedevelopment of a background subtraction algorithmwhich can be run in real-time and is accurate enoughfor the purpose of face detection to be used in a facebiometric application. We propose solutions with lowcomputational cost to solve problems like illumina-tion changes, static thresholds, shadows, model up-dating and background clutter. Our algorithm is ableto perform background subtraction on a image of size640 × 480 at a frequency of about 32Hz. Indoor andoutdoor experiments are presented at the end of thispaper together with the discussion about the results.
2 Background ModelingThe background modeling and the subtraction pro-cess is shown in Figure 1. There are four majorsteps in our background subtraction algorithm; pre-processing, consists of transforming the input imagesfrom the raw input video format into a format thatcan be processed by subsequent steps. Backgroundmodeling then learns each video frame to estimatea background model. This background model pro-vides a statistical description of the entire backgroundscene. Foreground detection then identifies pixels inthe video frame that cannot be adequately explainedby the background model, and outputs them as a bi-nary candidate in a foreground mask. Finally, datavalidation examines the candidate mask, eliminatesthose pixels that do not correspond to actual objects,and outputs the final foreground mask. We describethe four major steps in the following subsections.
2.1 PreprocessingIn this stage, we firstly use simple temporal and spa-cial smoothing to reduce camera noise. Smoothingcan also be used to remove transient environmentalnoise. Then to ensure real-time capabilities, we haveto decide on the frame-size and frame-rate which arethe determining factors of the data processing rate.Another key issue in preprocessing is the data format
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1763 Issue 10, Volume 7, October 2008
Figure 1: Block diagram of the background subtrac-tion algorithm.
used by the particular background subtraction algo-rithm. Most of the algorithms handle only luminanceintensity, which is one scalar value per each pixel.However, color image, in either RGB or YUV colorspace, is becoming more popular these days. In thecase of a mismatch, some time will be spent on con-verting the output data from the driver of the camerato the required input data type for the algorithm.
2.1.1 Color ModelThe input to our algorithm is a time series of spa-tially registered and time-synchronized color imagesobtained by a static camera in the YUV color space.This allows us to separate the luminance and chromacomponents which has been decoded in a 4:2:0 ratioby our camera hardware. The observation at pixel i attime t can then be written as:
IC = (Y,U, V ) (1)
2.1.2 Texture ModelIn our implementation, we used the texture informa-tion available in the image in our algorithm by includ-ing and considering the surrounding neighbors of thepixel. This can be obtained several ways. In our im-plementation, we have decided to take the image gra-dient of the Y component in the x and y directions.The gradient is then denoted as follows:
IG = GY = (Gx, Gy)
=√G2
x +G2y (2)
This is obtained using a Sobel operator. The Sobeloperator combines Gaussian smoothing and differen-tiation so the result is more robust to noise. We havedecided to use the following Sobel filter after experi-menting with several other filters. 1 2 1
2 0 21 2 1
(3)
Figure 2 shows the behavior of the camera sensor tothe neighboring pixel and the effect of the surroundingpixels for any given pixel. Notice that the edges of thered, blue and green color zones are not uniform.
Figure 2: The neighbor pixel effect to the camera sen-sor.
2.1.3 Shadow ModelAt this point, we still have a major inconvenience inthe model. Shadows are not translated as being part ofthe background and we definitely do not want them tobe considered as an object of interest. To remedy this,we have chosen to classify shadows as regions in theimage that differ in Y but U,V rest unchanged. Theshadow vector Is is then given as follows:
IS = (YS , U, V ) (4)
where YS = Y ± ∆Y . This is in fact not a disad-vantage. Since the Y component is only sensible toillumination changes, it is in fact redundant for fore-ground or background object discrimination.
2.2 Learning Vector ModelWe can now form the final vectors which we are goingto observe at pixel level. They are given as follows:
B1 = (GY , U, V )
B2 = (YS)
B3 = (U, V ) (5)
whereB1 is the object background model which com-bines the color and texture information but ignoresluminance that is incorporated in B2 which is theshadow background model and B3 is taken as a safety
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1764 Issue 10, Volume 7, October 2008
net vector which measures the chromaticity compo-nent of the background. The choice of the safety netvector is empirically chosen from the conducted ex-periments.
We decided to use the Mixture of Gaussian(MoG) method to maintain a density function at pixellevel. This choice is made for each pixel after study-ing the behavior of the camera sensor. Figure 3 showsvery clearly that the behavior of the camera sensorused in our experiment is Gaussian. However, to en-able real-time computations, we assumed that the den-sity function of each channel have only a single distri-bution which is obtained by considering only the high-est peak from the graph.
Figure 3: Camera sensor used in our experiments havea Gaussian behavior.
In the MoG method, at each pixel, the variationin the observed vectors B1, B2 and B3 can be eachmodeled separately by a mixture of K Gaussian. Theprobability P (B) then of belonging to the backgroundis given by:
P (Bj) =K∑
i=1
ωi f( Bj , µi , Ci ) (6)
where j = 1, 2, 3, K denotes the number of Gaus-sian distributions used to model the density function,µ the mean value vector of the Gaussian, C the co-variance matrix associated with this Gaussian and ωis the weight assigned to the Gaussian distribution.In our approach, B2, B3 and B1 are each modeledseparately as a one, two and three component densityfunction. These density functions can be viewed as acurve, surface and ellipsoid respectively. But, sinceeach density function of each component is assumedto only have a single peak, K = ω = 1 ∀ j = 1, 2, 3.
3 Background Subtraction Algo-rithm
In this section, we describe how the backgroundmodel is constructed and used to discriminate fore-ground and background pixels. The background
model that is constructed is stored in an image calleda background reference image. During run-time, thereference image is subtracted from the current imageto obtain a mask which will highlight all foregroundobjects. Once the mask is obtained, the backgroundmodel can be updated. There a four major steps in thebackground subtraction algorithm. These are detailedin the following subsections.
3.1 Background LearningIn this stage, for each incoming frame, at pixel level,we store the number of samples n, the sum of the ob-served vector a, b, c grouped as U and the sum ofthe cross-product of the observed vector d, e and fgrouped as V .
n =N∑
i=1
1
a =N∑
i=1
B1 , b =N∑
i=1
B2 , c =N∑
i=1
B3
d =N∑
i=1
(B1 ×B1) , e =N∑
i=1
(B2 ×B2)
f =N∑
i=1
(B3 ×B3) (7)
This stage will be defined as the learning phaseand is required for initialization. From our experi-ments, about 100 frames is necessary to sufficientlylearn the variations in the background. This corre-sponds to about 2 to 4 seconds of initialization usingour camera.
3.2 Parameter EstimationAt the end of the learning phase, the required variablesfor the Gaussian models need to be calculated. Theyare given as follows:
µ1 =a
n, µ2 =
b
n, µ3 =
c
n
CB1 =1n
(d)− 1n2
(a× aT )
CB2 =1n
(e)− 1n2
(b× bT )
CB3 =1n
(f)− 1n2
(c× cT ) (8)
These variables are calculated in a very efficientmanner such that real-time compatibility is alwaysmaintained. In our implementation this stage is re-ferred to the Gaussian distribution parameter estima-tion stage.
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1765 Issue 10, Volume 7, October 2008
3.3 Foreground DetectionForeground detection compares the input video framewith the background reference image and identifiescandidate foreground pixels from the input frame. Themost commonly used approach for foreground detec-tion is to check whether the input pixel is signifi-cantly different from the corresponding backgroundestimate. In the MoG method, we can do this by ex-panding the characterizing equation for each Gaussiandistribution.
P (Bj) = f( Bj , µj , CBj )
= ( 2πn2 ×
√|CBj | )−1
× exp { (Bj − µj)T
× C−1Bj× (Bj − µj) } (9)
where j = 1, 2, 3. To compute this probability, it isnot entirely necessary to evaluate the whole expres-sion. The first term is a constant and the remain-ing term is popularly known as the Mahalanobis Dis-tance (MD). Hence, the decision making process isstreamed down to the following three categories,
MDj = (Bj − µj)T × C−1Bj× (Bj − µj) (10)
for j = 1, 2, 3. This expression evaluates the dif-ference between the reference image and the currentimage using the three density functions. The differ-ence is decomposed into there MD’s. Applying suit-able thresholds yields an object category which indi-cates the type of the pixel. As mentioned before, staticthresholds are unsuitable for dynamic environments.In order to make the threshold adaptive, their valuesare derived form the magnitude of the covariance ma-trices of each Gaussian distribution which indicatesthe extent of variation in the observed values. Wenote here that we do not ignore inter-channel depen-dency in the computation of our covariance matricesand their inverses as some authors do. Our methodclassifies a given pixel into the following three cate-gories,
OB if
MD1 > ε1|CB1 |MD2 > ε2|CB2 |MD3 > ε3|CB3 |
SH if
MD1 > ε1|CB1 |MD2 > ε2|CB2 |MD3 < ε3|CB3 |
BG if
MD1 < ε1|CB1 |MD2 < ε2|CB2 |MD3 < ε3|CB3 |
(11)
where ε1, ε2 and ε3 are constants which depend on thecamera sensor and the output from the camera driver.
They are determined empirically during the experi-ments.
3.4 Model UpdateIn order to fully capture the changing dynamic envi-ronment, the background model has to be updated. Inthe proposed algorithm, we need to update the meanvector, the covariance matrix and its inverse. In orderto avoid recalculating all the coefficients altogether, arecursive update is preferred. The will allow us to ob-tain the new values of the model parameters from theold ones. From the general expression for the meanvector and the correlated Gaussian distributions,
µt =Ut
nt
Ct =1
nt−1 + 1
×{[Vt−1 + (Bt ×BT
t )]
−[(Ut−1 +Bt)× (UT
t−1 +BTt )
nt−1 + 1
]}(12)
we can then obtain a simplified expression for the up-dated mean vector and the updated inverse covariancematrix,
µt =µt−1nt−1 +Bt
nt−1 + 1C−1
t = (Ct−1 +BtBTt )−1
= C−1t−1 −
C−1t−1BtB
Tt C
−1t−1
1 +BTt C
−1t−1Bt
(13)
The updating of covariances matrices and the meanvalues are only done to pixels which were assigned asbackground (BG). Once the covariances matrices areupdated, the respective thresholds are also updated.The updated inverse covariance matrices are used insubsequent decision making process.
4 Data ValidationWe define data validation as the process of improvingthe candidate foreground mask based on informationobtained from outside the background model. Inac-curacies in threshold levels, signal noise and uncer-tainty in the background model can sometimes leadto pixels easily mistaken as true foreground objectsand typically results in small false-positive or false-negative regions distributed randomly across the can-didate mask. The most common approach is to com-bine morphological filtering and connected compo-nent grouping to eliminate these regions. Applying
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1766 Issue 10, Volume 7, October 2008
morphological filtering on foreground masks elimi-nates isolated foreground pixels and merges nearbydisconnected foreground regions. Opening and clos-
Figure 4: Image before applying morphological filter.
ing are two important operators that are both derivedfrom the fundamental operations of erosion and dila-tion. These operators are normally applied to binaryimages. The basic effect of an opening is somewhatlike erosion in that it tends to remove some of theforeground (bright) pixels from the edges of regionsof foreground pixels. However, it is less destructivethan erosion in general. Figure 5 shows the result af-
Figure 5: Image after applying the erosion filter.
ter applying the opening (erosion) filter to Figure 4which eliminates the foreground pixels in the scenethat is misjudged by the background subtraction al-gorithm or due to improper thresholding. We use a5 × 5 mask to eliminate this foreground noise that isnot part of the scene or the object of interest. Anotheradded advantage of using this filter is to remove anyunconnected pixel that does not belong to the object.The size of the mask is determined empirically fromour experiments. Closing is similar in some ways to
dilation in that it tends to enlarge the boundaries offoreground (bright) regions in an image (and shrinkbackground color holes in such regions), but it is lessdestructive to the original boundary shape. Figure 6
Figure 6: Image after applying erosion and dilationfilter.
shows the result of applying an opening and closingfilter to Figure 4. We apply a 5 × 5 closing mask af-ter applying the opening filter. The effect of apply-ing both operators is to preserve background regionsthat have a similar shape to the structuring element, orthat can completely contain the structuring element,while eliminating all other regions of background pix-els. The advantage of this is that the foreground pix-els which are misjudged as background pixels makethe object to look as if it is not connected. Openingand closing are themselves often used in combinationto achieve more subtle results. It is very clear that ap-plying morphological opening and closing filters has apositive effect on the process of extracting object fromthe scene by removing the noise from the subtractedforeground.
5 Face LocalizationThe target of this research is to use background sub-traction technique to detect an object in the scene. Theobject of interest to us is the human face which is re-quired for biometric identification. Every object ortarget has its own methods for uniquely recognizingthemselves based upon one or more inherent physicalor behavioral character. Our implementation is to de-tect the face of a human when the subject is standingin front of a camera and then by initiating a capture se-quence. The hardware for this has been developed andattached to the system through an RS-232 communi-cation port interface. The space between the cameraand the subject should ideally be around 1m to 1.5m.
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1767 Issue 10, Volume 7, October 2008
This would normally give us an image that shows thehead of the subject and part of its shoulder. Figure7 shows the analysis of an image (one frame) of sizeM × N after the background is subtracted and datavalidation completed. The only object that appearsin the scene is the face and part of the shoulder. Wethen proceed to calculate the vertical (V) and horizon-tal (H) density of the image (binary image) and obtainthe density graphs as shown in Figure 7. The height of
Figure 7: Face localization using vertical and horizon-tal densities.
the graph bars will be considered from the top of theimage. With a suitable algorithm, we can compute thevertical and horizontal density of the mask as follows:
V (x) =M∑
x=1
I(x, y) ∀ x = {1, N}
H(y) =N∑
y=1
I(x, y) ∀ y = {1,M} (14)
From these values, we can then localize the center ofthe face and the face size. Next, we proceed to obtaina rectangular mask and apply it to our image. Thiswill give us the first results for face detection. Theseresults can be easily saved in a database or comparedwith an existing image in a database for biometric pur-poses or for personnel identification. After the rectan-gle mask is obtained, we can then refine the result toobtain an ellipse mask around the face based on theside lengths of the rectangle. A simple approach canbe used to determine the center of the ellipse, the ma-jor axis and the minor axis.
6 Experimental ResultsThe background subtraction algorithm that is pro-posed in this paper was tested in various outdoor and
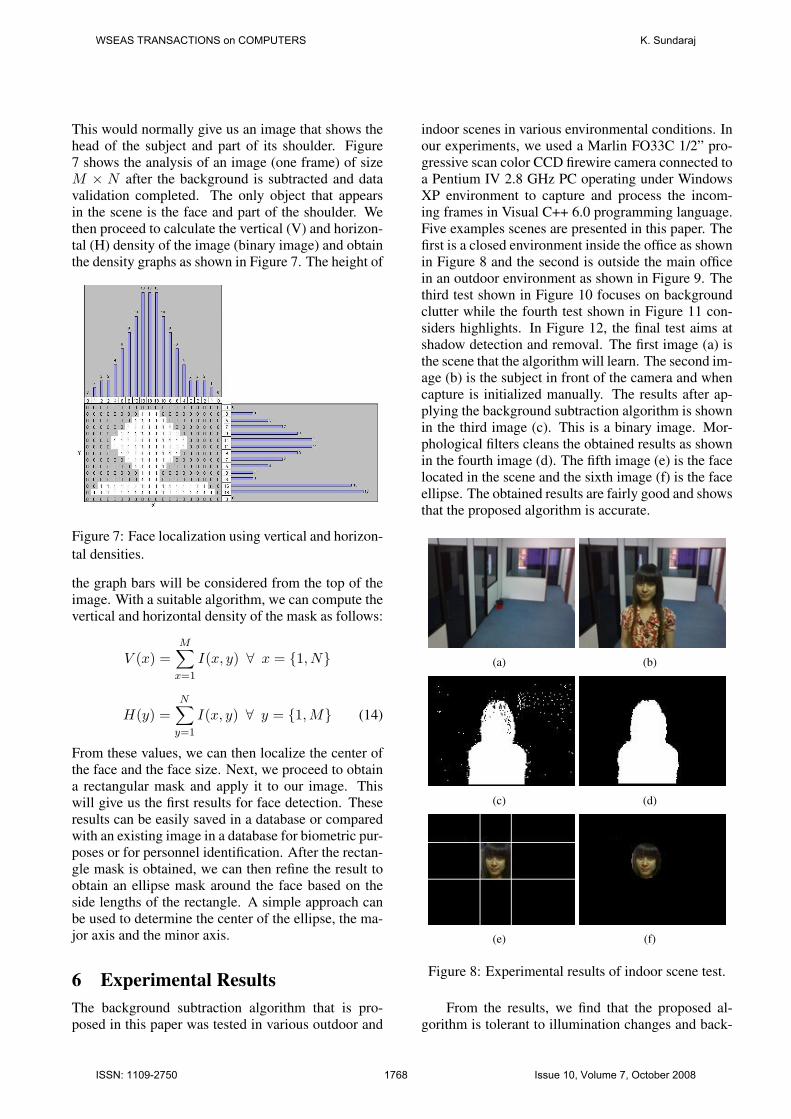
indoor scenes in various environmental conditions. Inour experiments, we used a Marlin FO33C 1/2” pro-gressive scan color CCD firewire camera connected toa Pentium IV 2.8 GHz PC operating under WindowsXP environment to capture and process the incom-ing frames in Visual C++ 6.0 programming language.Five examples scenes are presented in this paper. Thefirst is a closed environment inside the office as shownin Figure 8 and the second is outside the main officein an outdoor environment as shown in Figure 9. Thethird test shown in Figure 10 focuses on backgroundclutter while the fourth test shown in Figure 11 con-siders highlights. In Figure 12, the final test aims atshadow detection and removal. The first image (a) isthe scene that the algorithm will learn. The second im-age (b) is the subject in front of the camera and whencapture is initialized manually. The results after ap-plying the background subtraction algorithm is shownin the third image (c). This is a binary image. Mor-phological filters cleans the obtained results as shownin the fourth image (d). The fifth image (e) is the facelocated in the scene and the sixth image (f) is the faceellipse. The obtained results are fairly good and showsthat the proposed algorithm is accurate.
(a) (b)
(c) (d)
(e) (f)
Figure 8: Experimental results of indoor scene test.
From the results, we find that the proposed al-gorithm is tolerant to illumination changes and back-
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1768 Issue 10, Volume 7, October 2008
(a) (b)
(c) (d)
(e) (f)
Figure 9: Experimental results of outdoor scene test.
Table 1: Average error rate (%) of 25 frames for vari-ous experimented scenes.
ground clutter. The indoor and outdoor scenes wererepeated numerous times under different lighting con-ditions and background texture. We also experi-mented with various outdoor scenes with movingleaves, waving branches and moving clouds. In allthese experiments, the proposed algorithm success-fully executed in real-time (≈ 32Hz), which makes itwell suited for systems that require online monitor-ing. During these experiments, we also found thatwith a higher number of learning frames, accuracycan be improved. Figure 12 shows the shadow de-tection results of our proposed method. Shadows aredetected and removed from the image, thus prevent-ing undesired corruption to the final result which maylead to problems such as the detected object’s shapebeing distorted or the object’s shape being merged.This will introduce inaccuracies in the estimation of
(a) (b)
(c) (d)
(e) (f)
Figure 10: Experimental results of background clutterscene test.
Table 2: Average frame rate (Hz) of experimentedmethods.
Method [20] [21] OursFrame rate 9.6 12.3 32.5
face location. In order to test the robustness of theproposed algorithm, we benchmarked our algorithmwith that of [20] and [21]. In the benchmark test, 25frames from the results of the background subtractionalgorithm of various experiments of indoor and out-door scenes were compared to obtain the recognitionrate of correctly assigned background pixels. Subjectswere told to move around in all experiments. The er-ror rate is based on manually obtained predeterminedratio of the correct number of background pixels tothe correct number of foreground pixels. The resultsof this benchmark is tabulated in Table 1 and 2.
7 ConclusionThis paper presents the implementation details for afast background subtraction algorithm to detect an lo-calize a human face from a dynamic background scenethat contains shading and shadows using color im-
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1769 Issue 10, Volume 7, October 2008
(a) (b)
(c) (d)
(e) (f)
Figure 11: Experimental results of highlight scenetest.
ages. The experimental results in real-time applica-tions shows that the propose method is accurate, ro-bust, reliable and computed efficiently. This methodwas designed under an assumption that the back-ground scene although dynamic, can be effectivelymodeled by allowing the system to update adaptivelyduring runtime. The background reference modelwhich is obtained from the fast update contributes tothe efficiency of this algorithm. We have implementedthese routines as efficient as possible. Like all learn-ing algorithms, caution must be observed because al-gorithms can be fed with information that might leadto wrong learning or too little information leading toinsufficient learning. Several benchmarks concerningaccuracy and speed have been presented. In this paper,we have implemented a system that uses an image sizeof about 640× 480 pixels. Using this option, we havefound that the system runs at about 30 to 35 framesper second which is generally sufficient for real-timeapplications.
References:
[1] N. Friedman and S. Russel, “Image segmen-tation in video sequences: A probabilistic ap-
(a)
(b)
Figure 12: Experimental results of shadow detection.
proach,” in Proceedings of IEEE InternationalConference on Uncertainty in Artificial Intelli-gence, San Francisco, USA, 1997, pp. 175–181.
[2] D. Hong and W. Woo, “A background subtrac-tion for a vision-based user interface,” in Pro-ceedings of IEEE International Conference onInformation, Communications and Signal Pro-cessing, vol. 1, 2003, pp. 263– 267.
[3] M. Harville, G. Gordon, and J. Woodfill, “Fore-ground segmentation using adaptive mixturemodels in color and depth,” in Proceedings ofIEEE Workshop on Detection and Recognitionof Events in Video, Los Angeles, USA, 2001, pp.3–11.
[4] R. Cucchiara, C. Grana, M. Piccardi, andA. Prati, “Detecting moving objects, ghosts andshadows in video streams,” IEEE Transactionson Pattern Analysis and Machine Intelligence,vol. 25, no. 10, pp. 1337–1342, 2003.
[5] I. Haritaoglu, R. Cutler, D. Harwood, andL. Davis, “Backpack - Detection of people car-rying objects using silhouettes,” in Proceedingsof Computer Vision and Image Understanding,vol. 81, no. 3, New York, USA, 2001, pp. 385–397.
[6] K. M. Cheung, T. Kanade, J. Bouguet, andM. Holler, “A real-time system for robust 3Dvoxel reconstruction of human motions,” in Pro-ceedings of Computer Vision and Pattern Recog-nition, vol. 2, 2000, pp. 714 – 720.
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1770 Issue 10, Volume 7, October 2008
[7] K. Toyama, J. Krumm, B. Brumitt, and B. Mey-ers, “WallFlower - Principles and practice ofbackground maintenance,” in Proceedings ofInternational Conference on Computer Vision,California, USA, 1999, pp. 255–261.
[8] C. Ianasi, V. Gui, F. Alexa, and C. I. Toma,“Noncausal adaptive mode tracking estimationfor background subtraction in video surveil-lance,” WSEAS Transactions on Signal Process-ing, vol. 2, no. 1, pp. 52–59, 2006.
[9] N. J. B. McFarlane and C. P. Schofield, “Seg-mentation and tracking of piglets in images,”Machine Vision and Applications, vol. 8, no. 3,pp. 187–193, 1995.
[10] S. C. S. Cheung and C. Kamath, “Robust back-ground subtraction with foreground validationfor urban traffic video,” EURASIP Journal ofApplied Signal Processing, vol. 2005, no. 1, pp.2330–2340, 2005.
[11] Y. Chen and T. S. Huang, “Hierarchical MRFmodel for model-based multi-object tracking,”in Proceedings of IEEE International Confer-ence on Image Processing, vol. 1, Thessaloniki,Greece, 2001, pp. 385–388.
[12] C. R. Wren, A. Azarbayejani, T. Darrell, andA. Pentland, “Pfinder: Real-time tracking ofthe human body,” IEEE Transactions on Pat-tern Analysis and Machine Intelligence, vol. 19,no. 7, pp. 780–785, 1997.
[13] J. Heikkila and O. Silven, “A real-time sys-tem for monitoring of cyclists and pedestrians,”in Proceedings of IEEE Workshop on VisualSurveillance, vol. 22, no. 7, Washington, USA,2004, pp. 563–570.
[14] K. Kim, T. H. Chalidabhongse, D. Harwood, andL. Davis, “Background modeling and subtrac-tion by codebook construction,” in Proceedingsof International Conference on Image Process-ing, vol. 5, 2004, pp. 3061– 3064.
[15] D. S. Lee, J. J. Hull, and B. Erol, “A bayesianframework for gaussian mixture backgroundmodeling,” in Proceedings of International Con-ference on Image Processing, 2003, pp. 973–976.
[16] D. Koller, J. Weber, and T. Huang, “Towardsrobust automatic traffic scene analysis in real-time,” in IEEE International Conference on De-cision and Control, 1994, pp. 3776–3782.
[17] P. Roth, H. Bischof, D. Skovcaj, andA. Leonardis, “Object detection with boot-strapped learning,” in Proceedings 10thComputer Vision Winter Workshop, 2005, pp.33–42.
[18] C. Stauffer and W. E. L. Grimson, “Adap-tive background mixture models for real-timetracking,” in Proceedings of IEEE Conferenceon Computer Vision and Pattern Recognition,vol. 2, 1999, pp. 246–252.
[19] N. Li, D. Xu, and B. Li, “A novel backgroundupdating algorithm based on the logical relation-ship,” in WSEAS International Conference onSignal, Speech and Image Processing, 2007, pp.154–158.
[20] O. Javed, K. Shafique, and M. Shah, “A hier-archical approach to robust background subtrac-tion using color and gradient information,” inProceedings of IEEE Workshop on Motion andVideo Computing, Washington, USA, 2002, pp.22–27.
[21] T. Horprasert, D. Harwood, and L. Davis, “A sta-tistical approach for real-time robust backgroundsubtraction and shadow detection,” in Interna-tional Conference on Computer Vision, Kerkyra,Greece, 1999, pp. 1–19.
[22] P. L. Rosin and T. Elis, “Image difference thresh-old strategies and shadow detection,” in Pro-ceedings of the British Machine Vision Confer-ence, 1995.
[23] T. M. Su and J. S. Hu, “Robust background sub-traction with shadow and highlight removal forindoor surveillance,” EURASIP Journal on Ad-vances in Signal Processing, vol. 2007, p. 14,2007.
[24] A. Elgammal, D. Harwood, and L. Davis, “Non-parametric model for background subtraction,”in Proceedings of the European Conference onComputer Vision, 2000.
[25] A. Elgammal, R. Duraiswami, D. Harwood, andL. Davis, “Background and foreground model-ing using non-parametric kernel density estima-tion for video surveillance,” Proceedings of theIEEE, vol. 90, no. 7, pp. 1151–1163, 2002.
[26] K. Appiah, A. Hunter, and T. Kluge, “GW4:a real-time background subtraction and main-tenance algorithm for FPGA implementation,”WSEAS Transactions on Systems, vol. 4, no. 10,pp. 1741–1751, 2005.
WSEAS TRANSACTIONS on COMPUTERS K. Sundaraj
ISSN: 1109-2750 1771 Issue 10, Volume 7, October 2008