Recommendations Based on Speech Classification (and examples of what recommender systems can learn from signal processing) Christian Müller German Research Center for Artificial Intelligence International Computer Science Institute, Berkeley, CA
Transcript
Recommendations Based on Speech Classification
Recommendations Based on Speech Classification
(and examples of what recommender systems can learn from signal processing)
Christian MüllerGerman Research Center for Artificial Intelligence
International Computer Science Institute, Berkeley, CA
(and examples of what recommender systems can learn from signal processing)
Christian MüllerGerman Research Center for Artificial Intelligence
International Computer Science Institute, Berkeley, CA
Christian Müller
OverviewOverview Speech as a source of information for non-intrusive
user modeling Speech as a source of information for non-intrusive
user modeling
Knowledge-driven feature selection
Classification methods for independent “bag of observations” features
Valid application-independent evaluation
Feature space warping normalization
Knowledge-driven feature selection
Classification methods for independent “bag of observations” features
Valid application-independent evaluation
Feature space warping normalization
Vocal aging -> features for speaker age recognition
GMM/SVM supervector approach for acoustic speech features
Detection task and pseudo-NIST evaluation procedure
Rank and polynomial rank normalization
Vocal aging -> features for speaker age recognition
GMM/SVM supervector approach for acoustic speech features
Detection task and pseudo-NIST evaluation procedure
Rank and polynomial rank normalization
Conclusions Conclusions
Speech/signal processing Take-away messages
Recommendations Based on Speech Classification
Recommendations Based on Speech Classification
(and examples of what recommender systems can learn from signal processing)
(and examples of what recommender systems can learn from signal processing)
Christian Müller
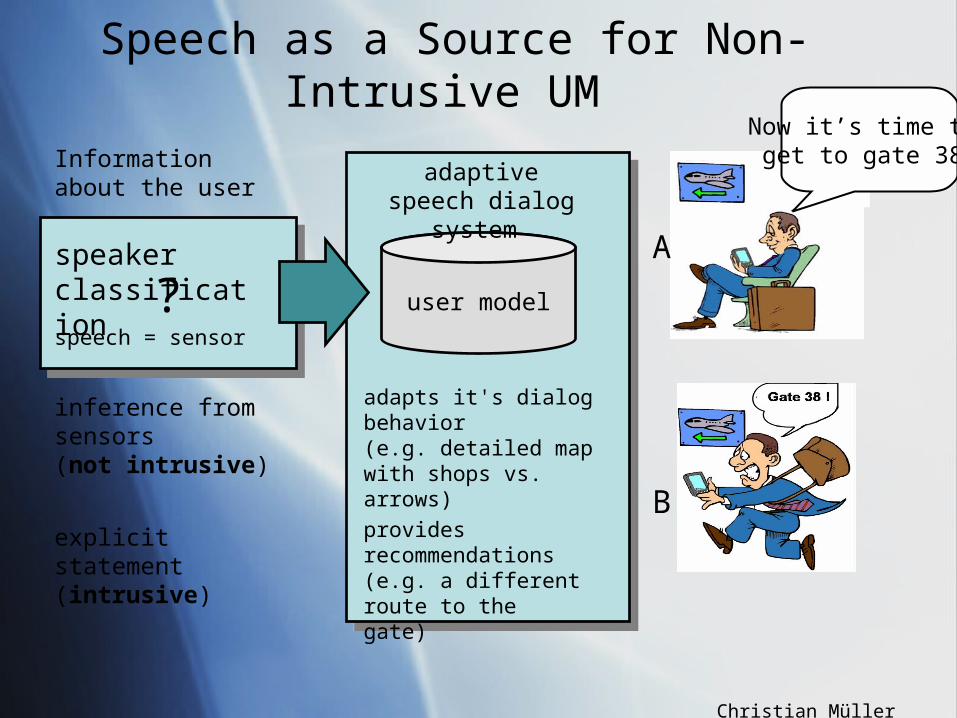
Speech as a Source for Non-Intrusive UM
Information about the user
explicit statement (intrusive)
inference from sensors(not intrusive)
speakerclassification user model
adaptivespeech dialog system
provides recommendations (e.g. a different route to the gate)
adapts it's dialog behavior (e.g. detailed map with shops vs. arrows)
speech = sensor
?A
B
Now it’s time to get to gate 38.
Christian Müller
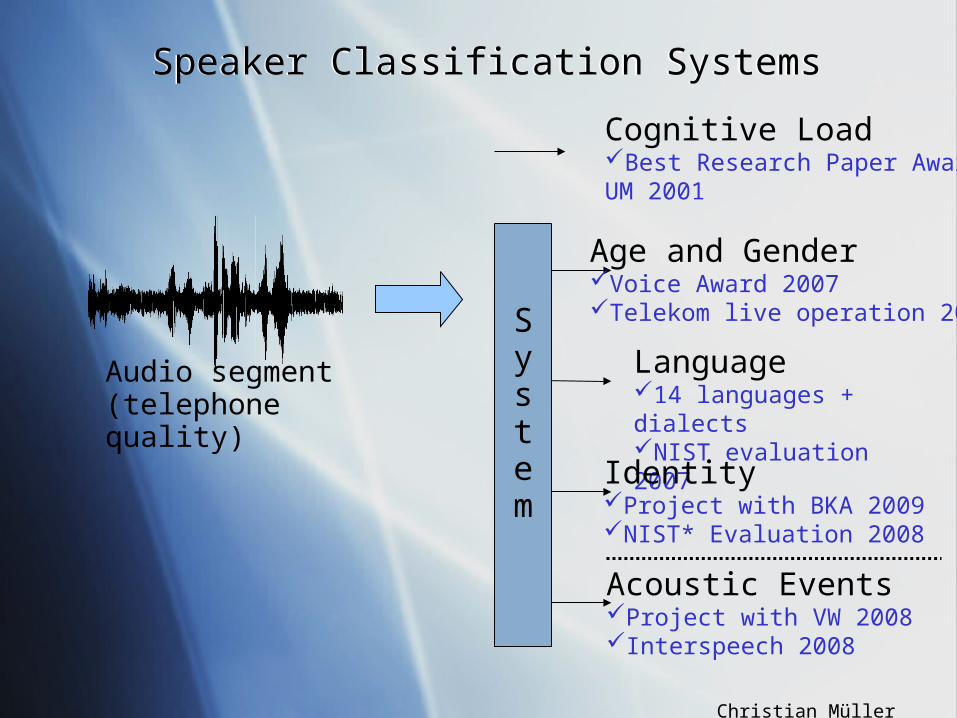
Speaker Classification SystemsSpeaker Classification Systems
Audio segment(telephone quality)
Age and GenderVoice Award 2007Telekom live operation 2009
Language14 languages + dialectsNIST evaluation 2007
IdentityProject with BKA 2009NIST* Evaluation 2008
Acoustic EventsProject with VW 2008Interspeech 2008
System
Cognitive LoadBest Research Paper AwardUM 2001
Christian Müller
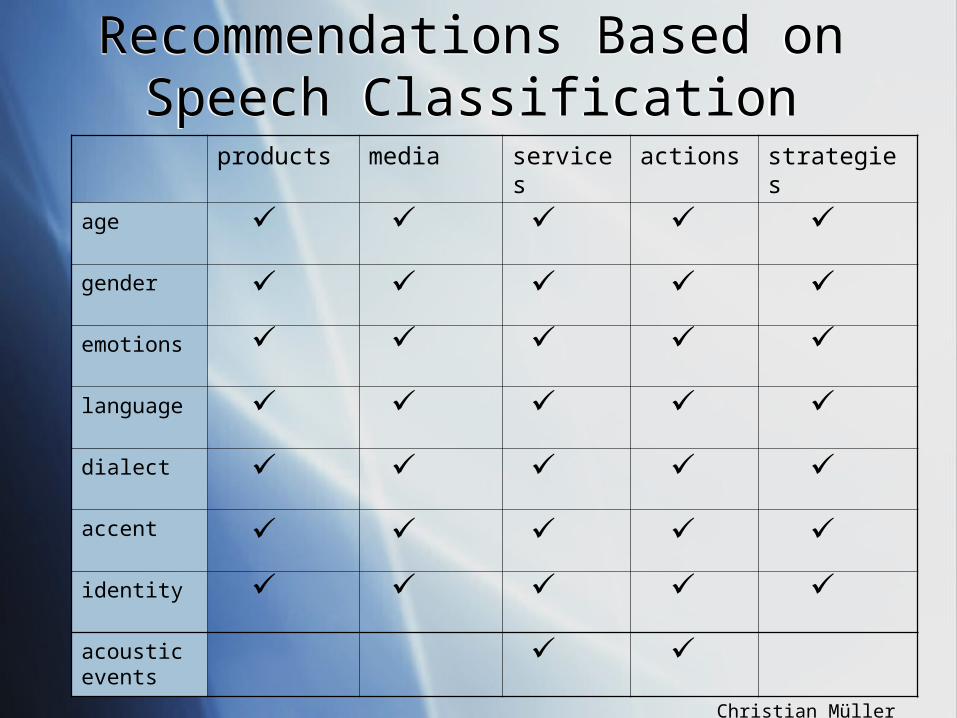
Recommendations Based on Speech Classification
Recommendations Based on Speech Classification
products media services actions strategies
age
gender
emotions
language
dialect
accent
identity
acousticevents
Christian Müller
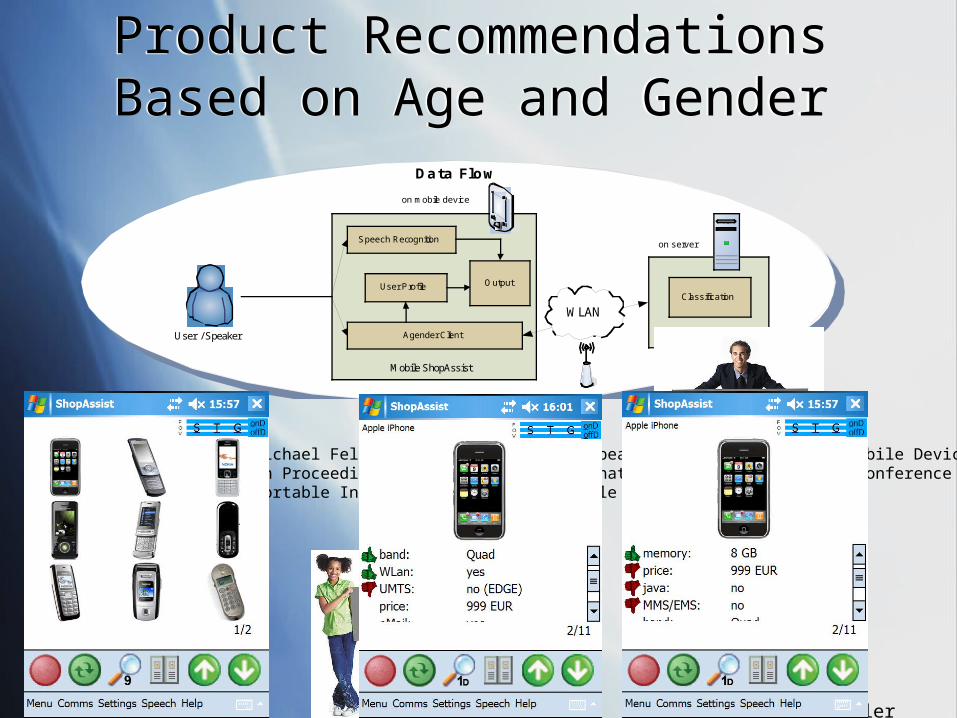
Product Recommendations Based on Age and GenderProduct Recommendations Based on Age and Gender
Zur Anzeige wird der QuickTime™ Dekompressor „svq1“
benötigt.
Christian Müller
Michael Feld and Christian Müller. Speaker Classification for Mobile Devices. In Proceedings of the 2nd IEEE International Interdisciplinary Conference on Portable Information Devices (Portable 2008). 2008
Data Flow
on mobile device
on server
Agender Server
Classification
User / Speaker
Mobile ShopAssist
Speech Recognition
Agender Client
User Profile Output
WLAN
AM
YF
Product Recommendations Based on Age and GenderProduct Recommendations Based on Age and Gender
Christian Müller
How can you find features for building your models by explicitly studying the underlying phenomena?
Proposing Knowledge-driven feature select the example of features for speaker age recognition
How can you find features for building your models by explicitly studying the underlying phenomena?
Proposing Knowledge-driven feature select the example of features for speaker age recognition
Christian Müller
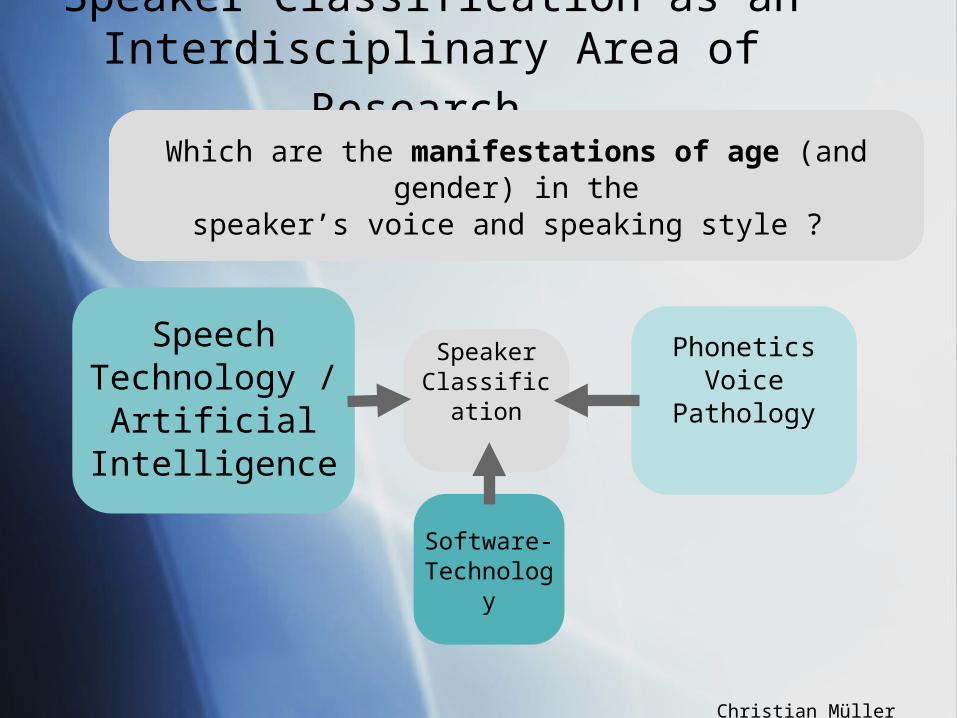
PhoneticsVoice
Pathology
SpeakerClassificati
on
Speaker Classification as an Interdisciplinary Area of Research
Speech Technology /
Artificial Intelligence
Software-Technolog
y
Which are the requirements of a speaker classification system and how can they be solved on the implementation layer ?
How can the age (and the gender) of a speaker be recognized automatically ?
Which are the manifestations of age (and gender) in thespeaker’s voice and speaking style ?
Christian Müller
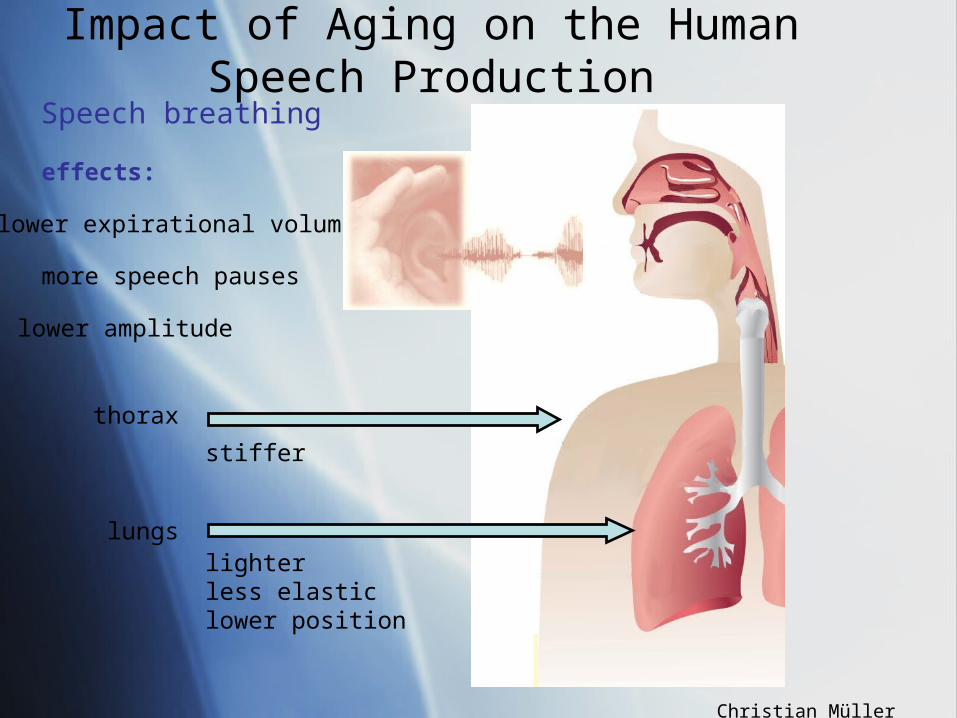
Impact of Aging on the Human Speech Production
Speech breathing
lighterless elasticlower position
lungs
thorax
stiffer
effects:
more speech pauses
lower amplitude
lower expirational volume
Christian Müller
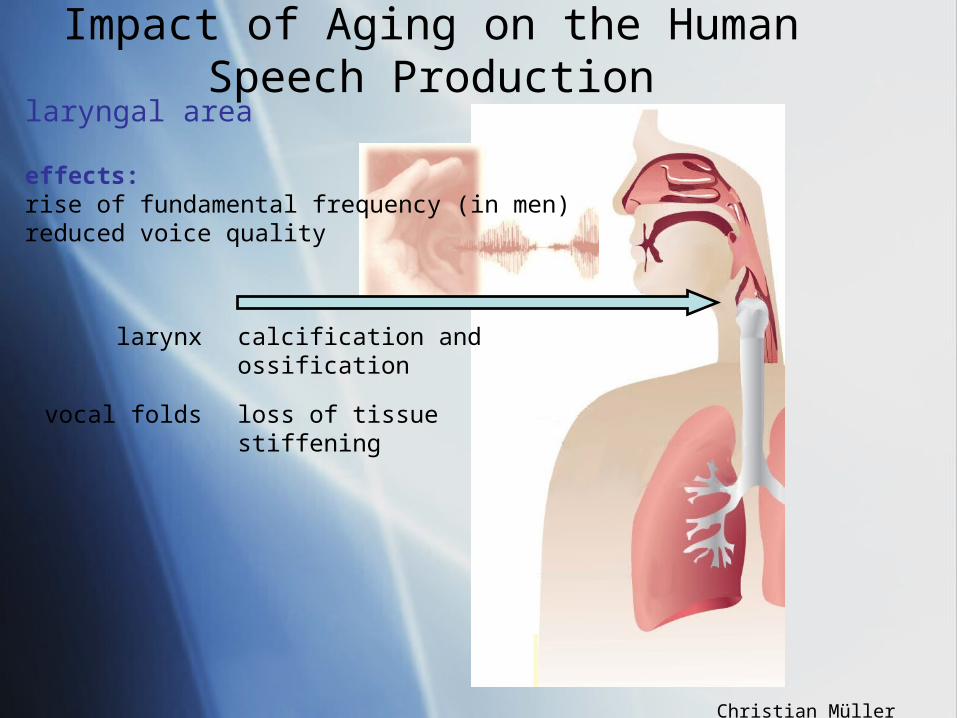
Impact of Aging on the Human Speech Production
calcification and ossification
laryngal area
larynx
vocal folds loss of tissuestiffening
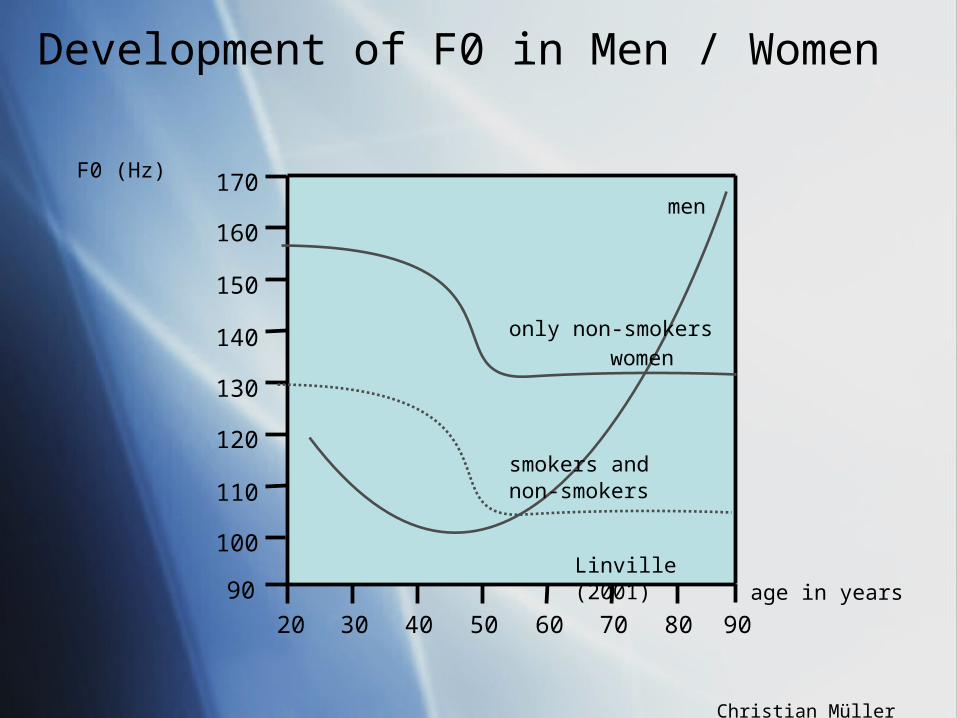
effects: rise of fundamental frequency (in men)reduced voice quality
Christian Müller
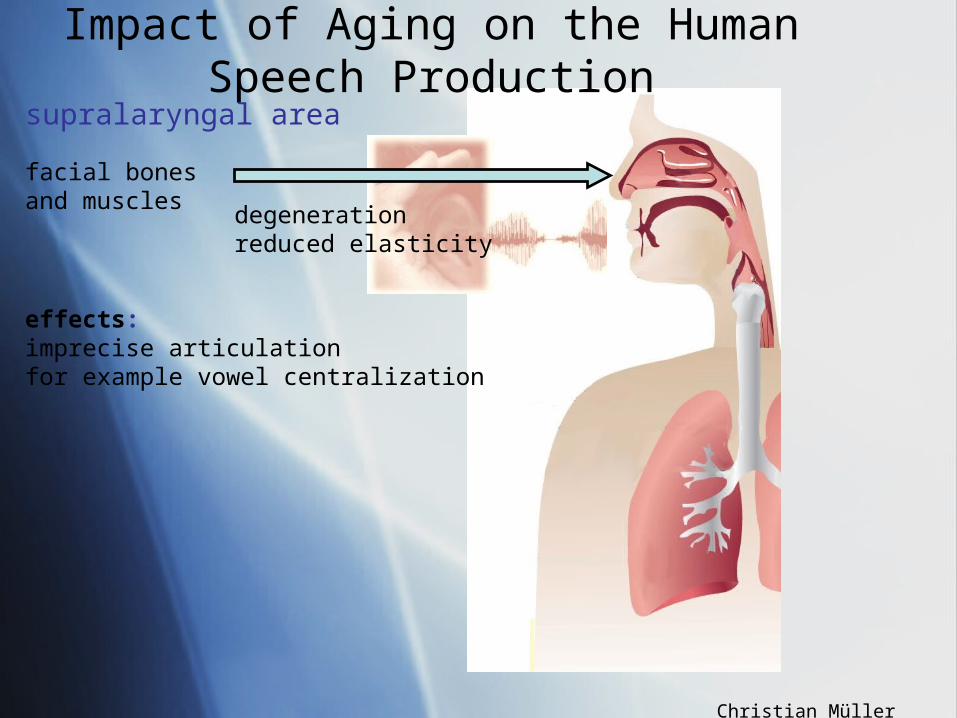
Impact of Aging on the Human Speech Production
supralaryngal area
degenerationreduced elasticity
facial bones and muscles
effects:imprecise articulationfor example vowel centralization
Christian Müller
Impact of Aging on the Human Speech Production
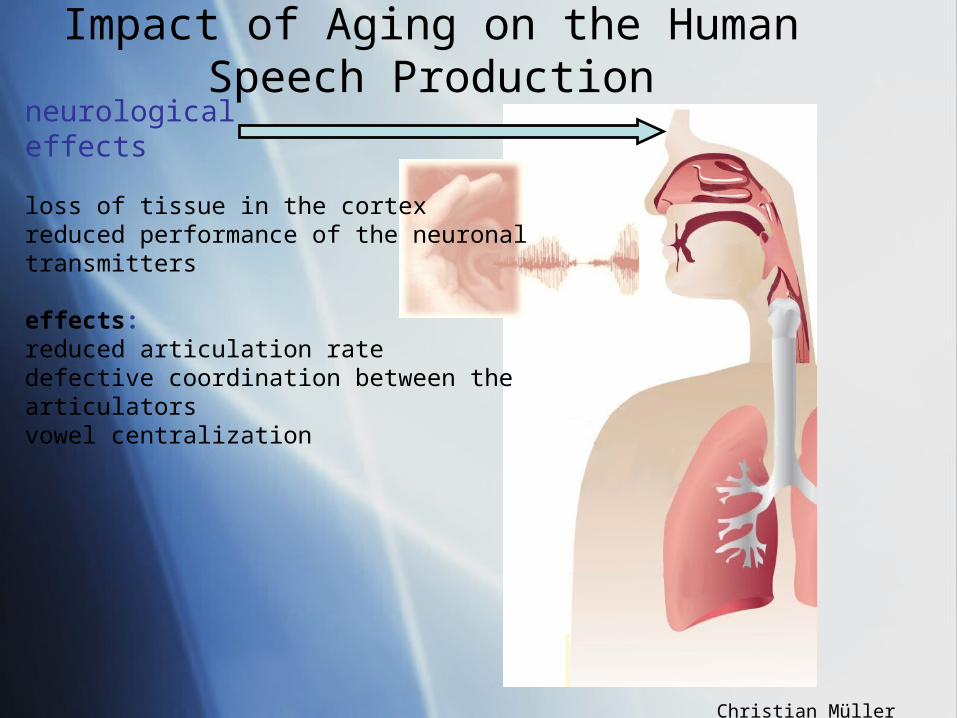
neurological effects
loss of tissue in the cortexreduced performance of the neuronal transmitters
effects:reduced articulation ratedefective coordination between the articulatorsvowel centralization
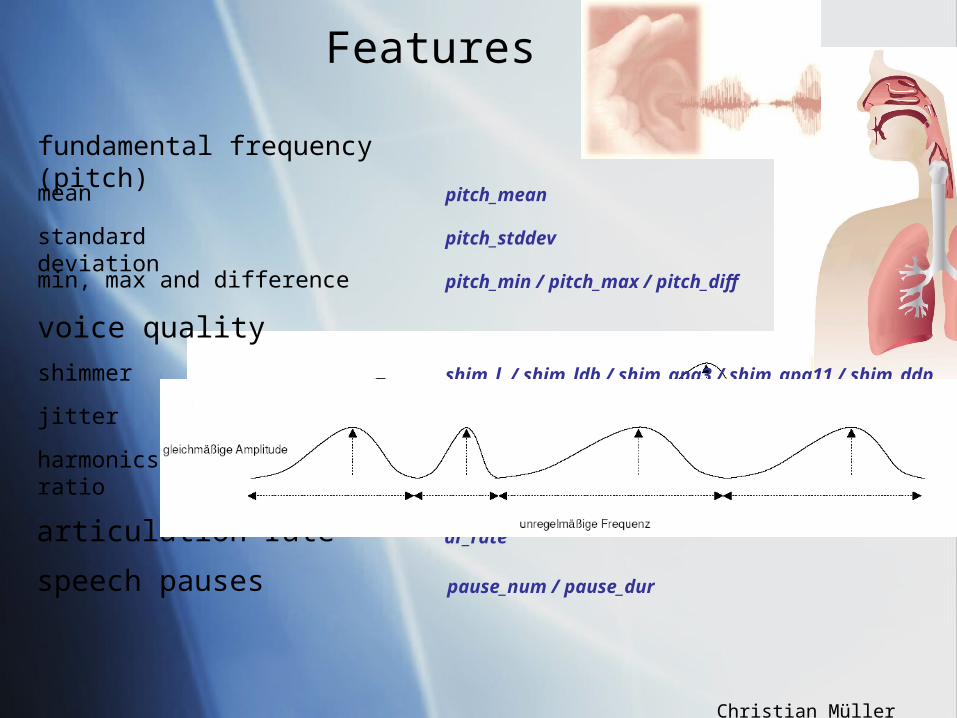
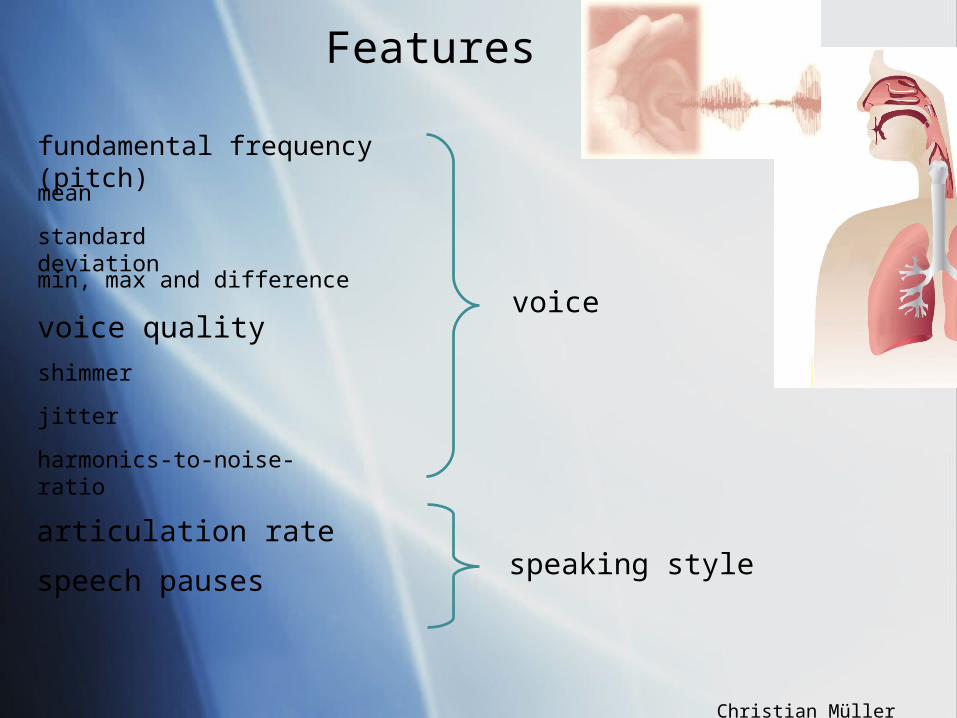
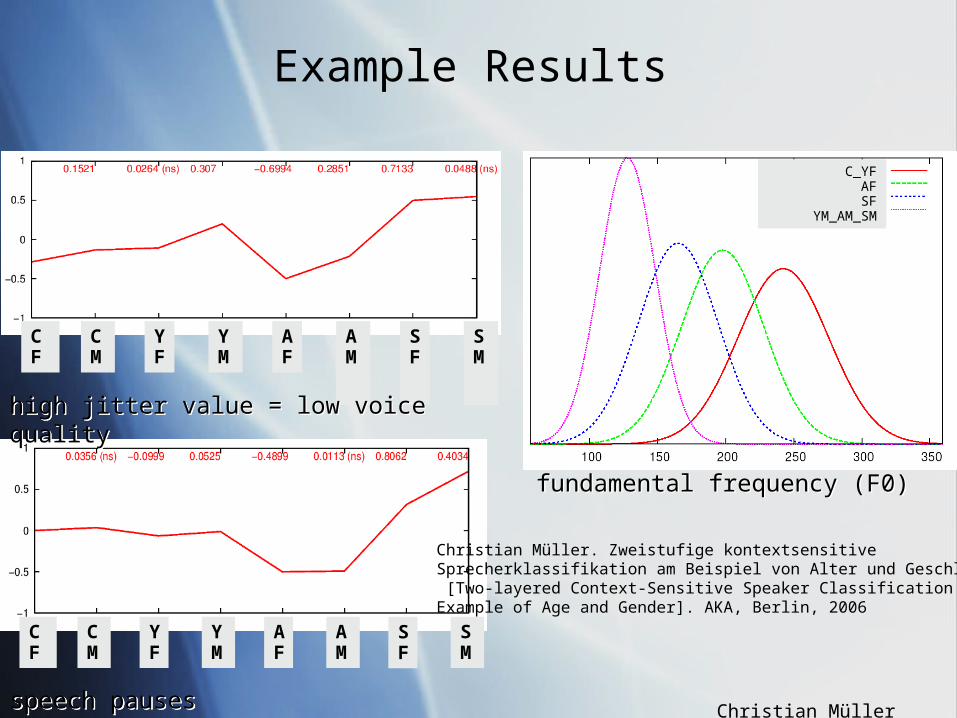
high jitter value = low voice qualityhigh jitter value = low voice quality
Christian Müller. Zweistufige kontextsensitive Sprecherklassifikation am Beispiel von Alter und Geschlecht [Two-layered Context-Sensitive Speaker Classification on the Example of Age and Gender]. AKA, Berlin, 2006
speech pauses speech pauses
fundamental frequency (F0)fundamental frequency (F0)
Christian Müller
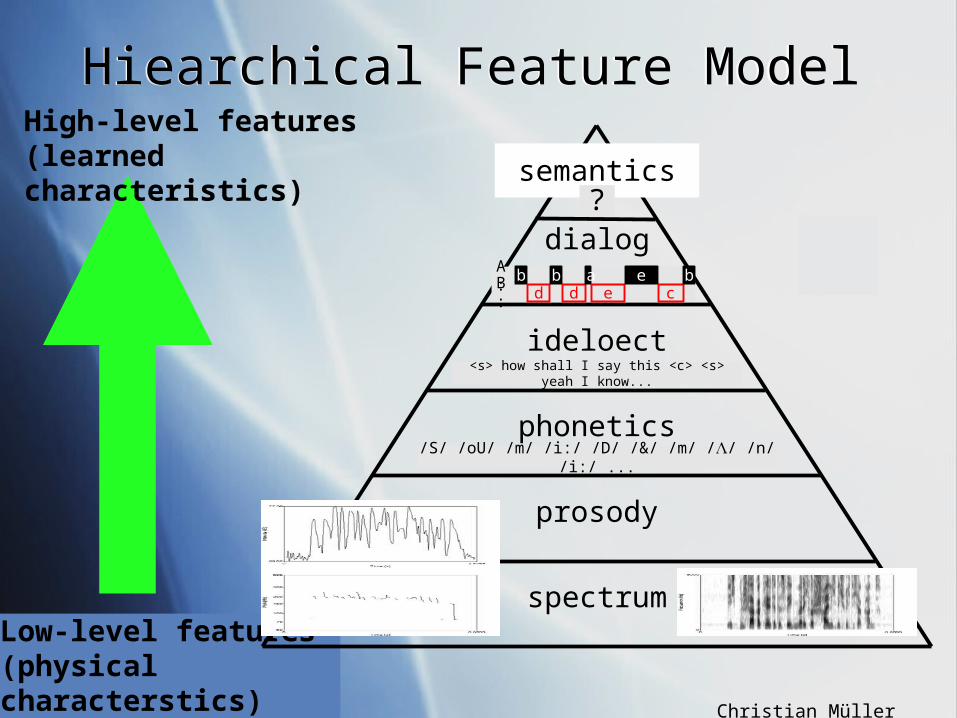
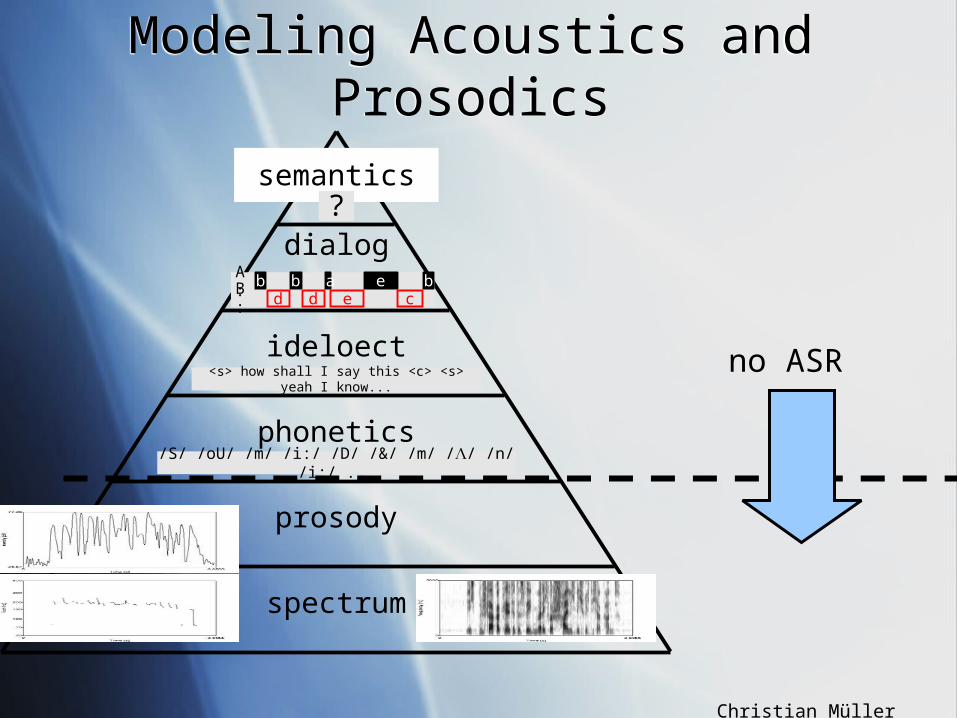
Low-level features(physical characterstics)
spectrum
prosody
phonetics
ideloect
dialog
semantics
<s> how shall I say this <c> <s> yeah I know...
/S/ /oU/ /m/ /i:/ /D/ /&/ /m/ // /n/ /i:/ ...
d d e cbb a e bA
:B:
?
High-level features(learned characteristics)
Hiearchical Feature ModelHiearchical Feature Model
Christian Müller
How can your features be modeled assuming that they are multi-dimentional represent repeating observations of
the same kind can be assumed to be independent
(“bag” of observations) Proposing the GMM/SVM
Supervector Approach on the example of frame-by-frame acoustic features
How can your features be modeled assuming that they are multi-dimentional represent repeating observations of
the same kind can be assumed to be independent
(“bag” of observations) Proposing the GMM/SVM
Supervector Approach on the example of frame-by-frame acoustic features
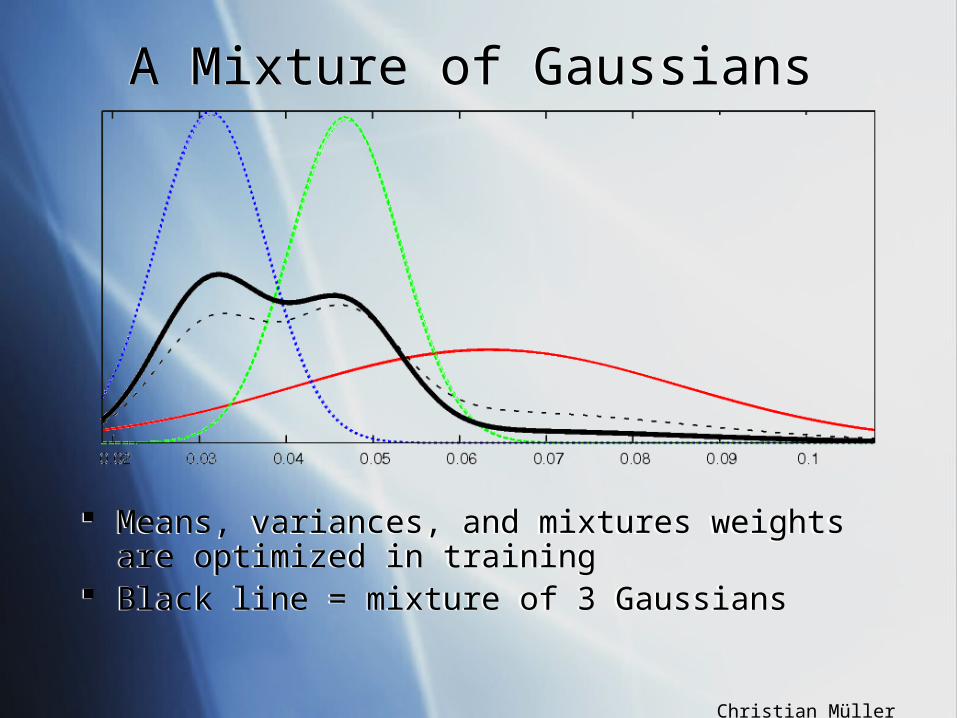
Means, variances, and mixtures weights are optimized in training
Black line = mixture of 3 Gaussians
Means, variances, and mixtures weights are optimized in training
Black line = mixture of 3 Gaussians
Christian Müller
featureextraction
“em. vehic.” (1)
training
“not em. vehic.” (-1)“em. vehic.”
model
Discriminative Method: Support Vector Machine (SVM)
Discriminative Method: Support Vector Machine (SVM)
Features are transformed into higher-dimensional space where problem is linear
Discriminating hyper plane is learned using linear regression Trade-off between training error and width of margin Model is stored in form of “support vectors” (data points on the
margin)
Features are transformed into higher-dimensional space where problem is linear
Discriminating hyper plane is learned using linear regression Trade-off between training error and width of margin Model is stored in form of “support vectors” (data points on the
margin)
Christian Müller
Discriminative Method: Support Vector Machine (SVM)
Discriminative Method: Support Vector Machine (SVM)
featureextraction
?
test
score (distance to hyper plane)
Discriminative methods have shown to be superior to generative methods for similar tasks
Features vectors have to be of the same lengths (sensitive to variable segment lengths)
Solutions: feature statistics calculated over the entire utterance fixes portion of the segment sequential kernels
Discriminative methods have shown to be superior to generative methods for similar tasks
Features vectors have to be of the same lengths (sensitive to variable segment lengths)
Solutions: feature statistics calculated over the entire utterance fixes portion of the segment sequential kernels
Combines discriminative power of SVMs with length independency of GMMs
Very successful with similar tasks such as speaker recognition
GMM is trained using MAP adaptation
Combines discriminative power of SVMs with length independency of GMMs
Very successful with similar tasks such as speaker recognition
GMM is trained using MAP adaptation
Christian Müller
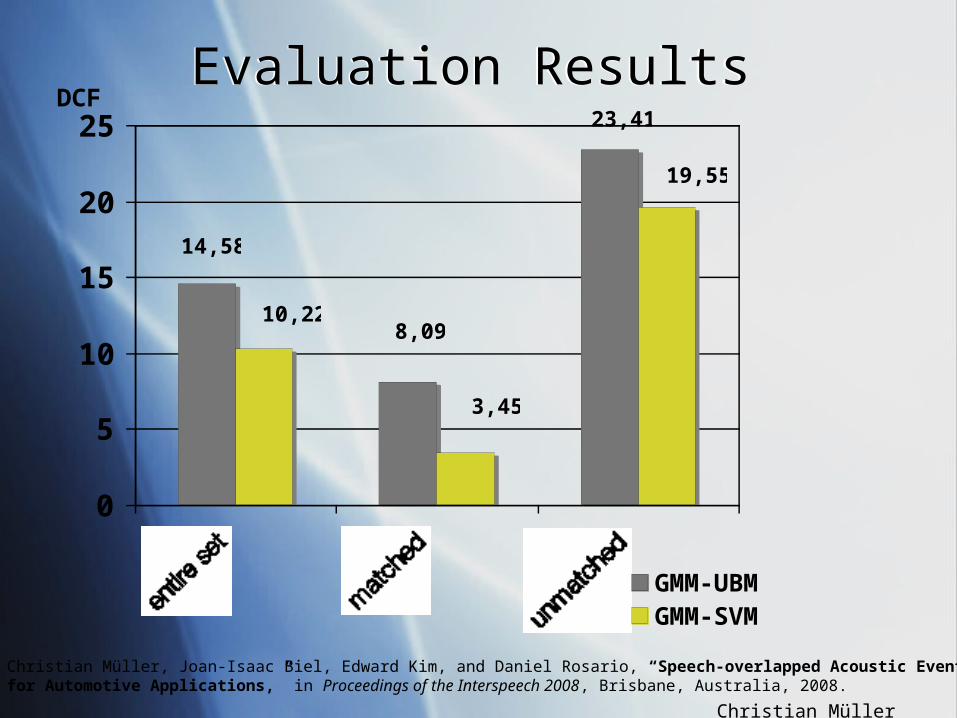
Evaluation ResultsEvaluation Results23,41
8,09
14,58
19,55
10,22
3,45
0
5
10
15
20
25
entire set matchedunmatched
DCF
GMM-UBMGMM-SVM
Christian Müller, Joan-Isaac Biel, Edward Kim, and Daniel Rosario, “Speech-overlapped Acoustic Event Detectionfor Automotive Applications,” in Proceedings of the Interspeech 2008, Brisbane, Australia, 2008.
Christian Müller
How can you evaluate your multi-class models independently from the given application?
How can you establish a appropriate evaluation in order procedure to obtain valid results?
Proposing the detection task and the “pseudo NIST” evaluation procedure on the example of acoustic event detection and speaker age recognition.
How can you evaluate your multi-class models independently from the given application?
How can you establish a appropriate evaluation in order procedure to obtain valid results?
Proposing the detection task and the “pseudo NIST” evaluation procedure on the example of acoustic event detection and speaker age recognition.
Christian Müller
BackgroundBackground
With multi-class recognition problems, many test/analyzing methods are very application specific. e.g. confusion matrices. we want a method that allows results to be
generalized across a large set of applications. With home-grown databases, parameter
tuning on the evaluation set often compromises the validity of the results/inferences. we want a fair “one shot” evaluation.
With multi-class recognition problems, many test/analyzing methods are very application specific. e.g. confusion matrices. we want a method that allows results to be
generalized across a large set of applications. With home-grown databases, parameter
tuning on the evaluation set often compromises the validity of the results/inferences. we want a fair “one shot” evaluation.
Christian Müller
The Detection TaskThe Detection Task
Given a speech segment (s) and an acoustic event to be detected (target
event, ET ) the task is to decide whether ET is
present in s (yes or no) the system's output shall also contains a
score indicating its confidence with more positive scores indicating greater confidence.
Given a speech segment (s) and an acoustic event to be detected (target
event, ET ) the task is to decide whether ET is
present in s (yes or no) the system's output shall also contains a
score indicating its confidence with more positive scores indicating greater confidence.
system
emergeny vehicle ?
yes , 1.324326
Christian Müller
TerminologyTerminology
Segment class e.g. segment event, segment age-class. ground truth (not known).
Target the hypothesized class.
Trial a combination of segment and target.
Segment class e.g. segment event, segment age-class. ground truth (not known).
Target the hypothesized class.
Trial a combination of segment and target.
Christian Müller
EvaluationEvaluation
The system performance is evaluated by presenting it with a set of trials.
Each test segment is used for multiple trials. The absence of all of all targets is explicitly included.
The system performance is evaluated by presenting it with a set of trials.
Each test segment is used for multiple trials. The absence of all of all targets is explicitly included.
systemmusic ?talking ?laughing ?phone ?
music ?talking ?laughing ?phone ?
no -0.3212no 1.8463no -2.5773yes 0.00132no 2.20122
no event ?no event ?
yes 1.32432
emergency vehicle ?
Christian Müller
Type of ErrorsType of Errors
system
target “em. vehic” ?target “em. vehic” ?
no
segment “em. vehic.”segment “em. vehic.”
“MISS”
system
target “phone” ?target “phone” ?
yes
segment “em. vehic”segment “em. vehic”
“FALSE ALARM”
Christian Müller
Decision-Error TradeoffDecision-Error Tradeoff
Selecting an operating point (decision threshold) along the dotted line trades misses off false alarms.
Optimal operating point is application dependent. Low false alarm rates are desirable for most
applications.
Selecting an operating point (decision threshold) along the dotted line trades misses off false alarms.
Optimal operating point is application dependent. Low false alarm rates are desirable for most
applications.
false alarms
misses
“equal error rate”
Christian Müller
Decision Cost FunctionDecision Cost Function
Weighted sum of misses and false alarms using variable costs and priors.
Application model parameters are selected according to the application.
The application parameters for EER are:
CMiss
= CFA
= 1 and PTarget
= 0.5
C(ET, E
N) = C
Miss · P
Target · P
Miss(E
T)
+ CFA
· (1-PTarget
) · PFA
(ET,E
N)
where ET and E
N are the target and non-target events,
and CMiss
, CFA
and PTarget
are application model parameters.
Christian Müller
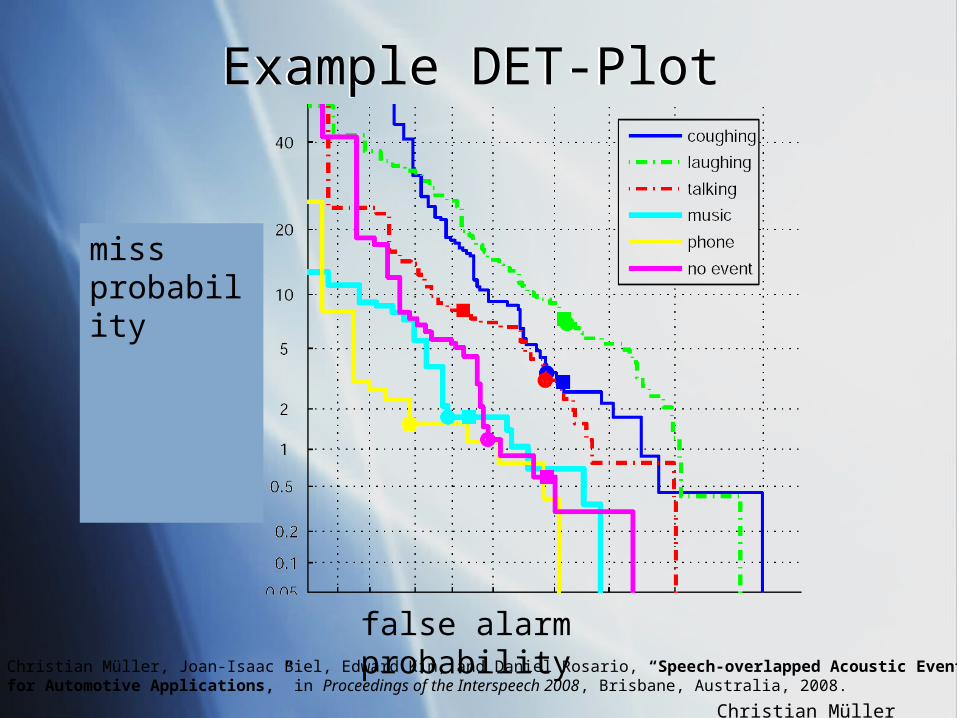
Example DET-PlotExample DET-Plot
false alarm probability
miss probability
Christian Müller, Joan-Isaac Biel, Edward Kim, and Daniel Rosario, “Speech-overlapped Acoustic Event Detectionfor Automotive Applications,” in Proceedings of the Interspeech 2008, Brisbane, Australia, 2008.
Christian Müller
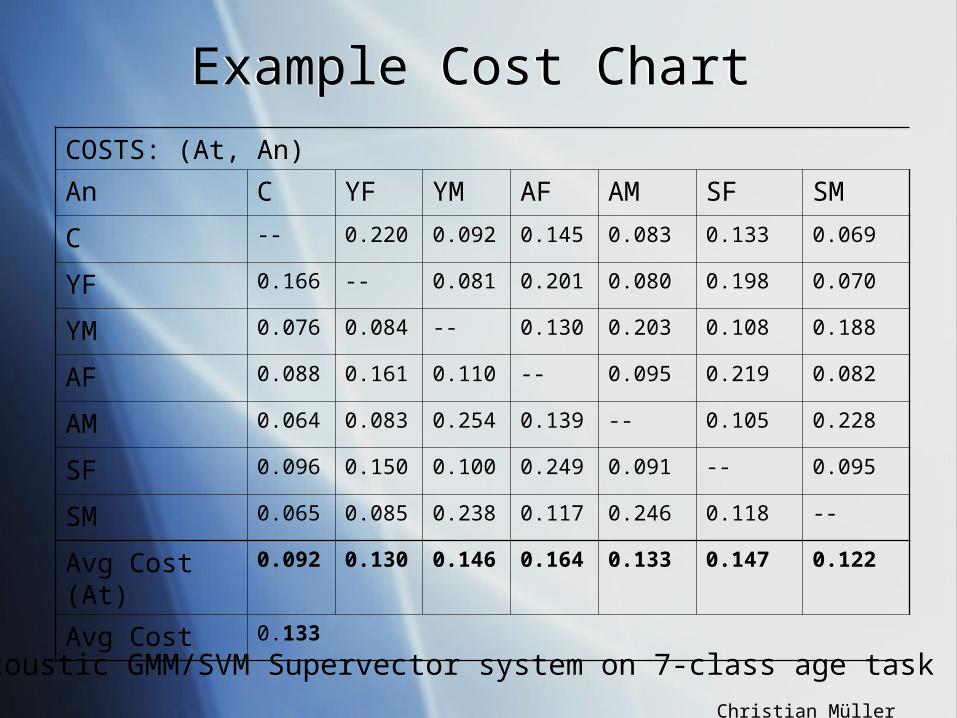
Example Cost ChartExample Cost ChartCOSTS: (At, An)
An C YF YM AF AM SF SM
C -- 0.220 0.092 0.145 0.083 0.133 0.069
YF 0.166 -- 0.081 0.201 0.080 0.198 0.070
YM 0.076 0.084 -- 0.130 0.203 0.108 0.188
AF 0.088 0.161 0.110 -- 0.095 0.219 0.082
AM 0.064 0.083 0.254 0.139 -- 0.105 0.228
SF 0.096 0.150 0.100 0.249 0.091 -- 0.095
SM 0.065 0.085 0.238 0.117 0.246 0.118 --
Avg Cost (At)
0.092 0.130 0.146 0.164 0.133 0.147 0.122
Avg Cost 0.133
Acoustic GMM/SVM Supervector system on 7-class age task
Christian Müller
Pseudo NIST Evaluation Procedure
Pseudo NIST Evaluation Procedure
ERL provided development and evaluation data as representative as possible for the application.
Three months before the evaluation, ICSI was provided with the development data.
At a pre-determined date, the blind evaluation data was provided to ICSI for processing.
The system's output was submitted to ERL in NIST format. ERL downloaded the scoring software from NIST’s website,
made the necessary modifications due to the changes in the labels.
ERL ran the software on the submitted system output. The results were then disclosed to ICSI along with the keys
(truth) for further analysis. --> Fair “one-shot” evaluation, no parameter tuning on the
evaluation set.
Christian Müller
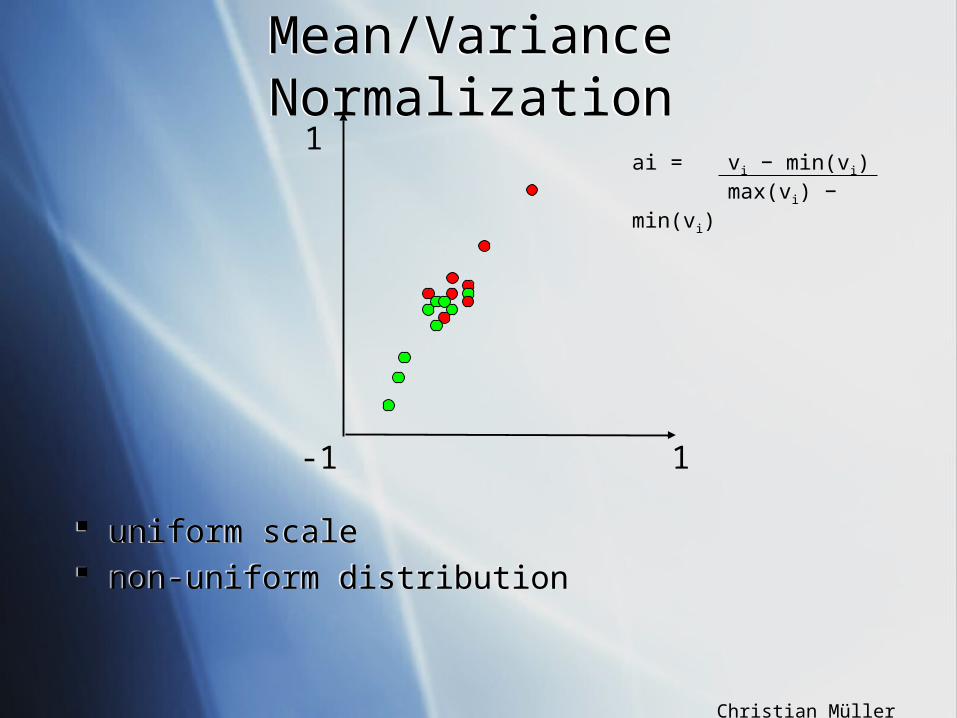
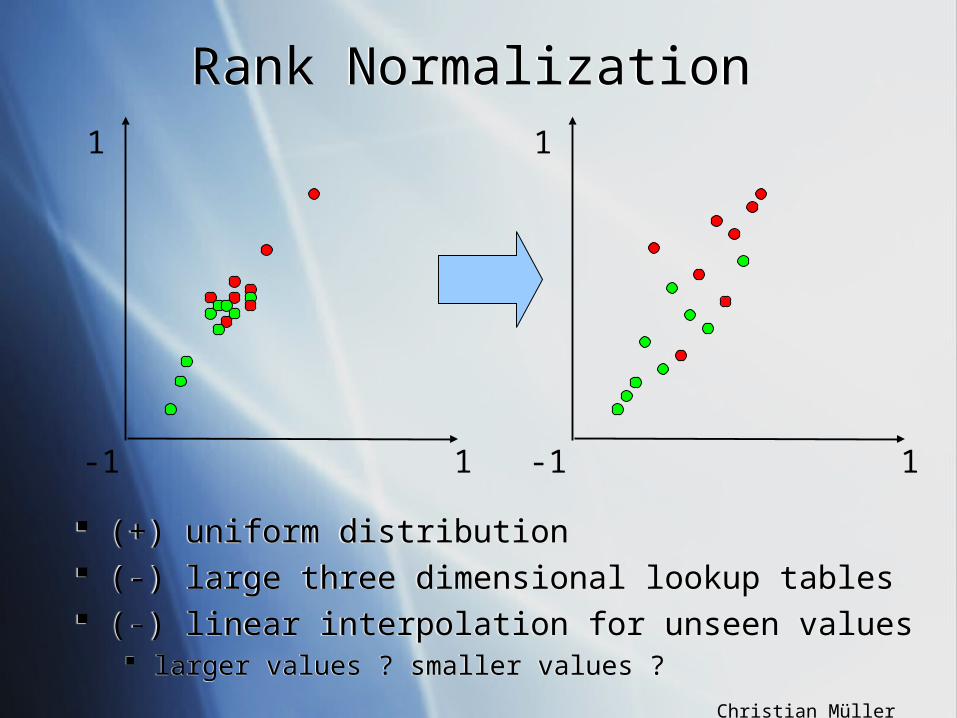
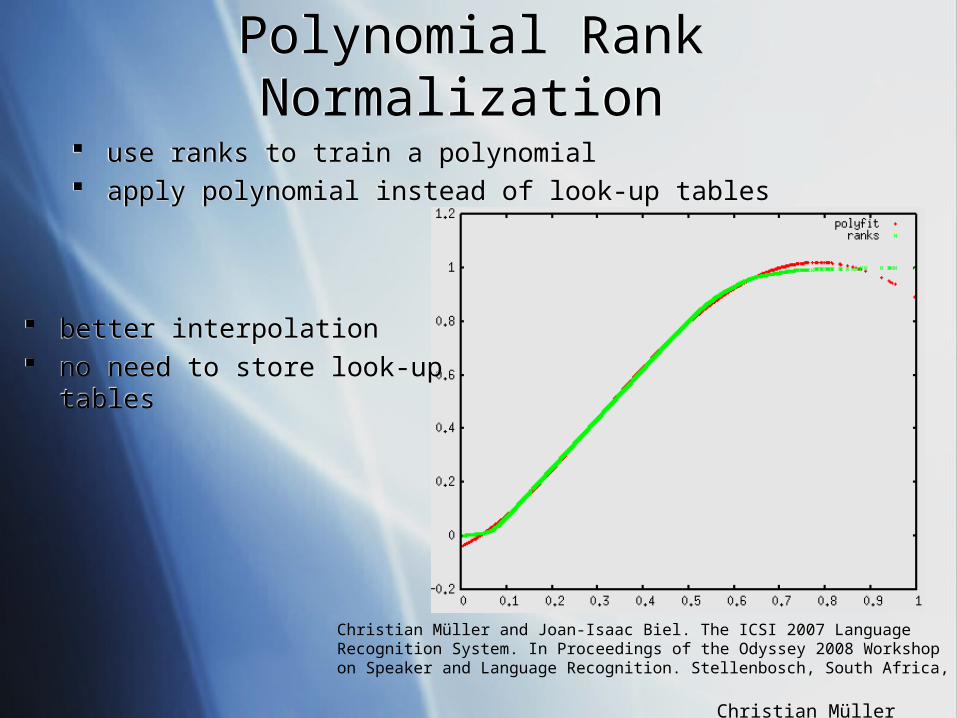
How can you normalize your features in order to obtain a uniform scale and a unifom distribution?
use ranks to train a polynomial apply polynomial instead of look-up tables
use ranks to train a polynomial apply polynomial instead of look-up tables
better interpolation no need to store look-up
tables
better interpolation no need to store look-up
tables
Christian Müller and Joan-Isaac Biel. The ICSI 2007 Language Recognition System. In Proceedings of the Odyssey 2008 Workshop on Speaker and Language Recognition. Stellenbosch, South Africa, 2008
Christian Müller
ConclusionsConclusions Speech as a source of information for non-intrusive user
modeling Speech as a source of information for non-intrusive user
modeling
Knowledge-driven feature selection
Classification methods for independent “bag of observations” features
Valid application-independent evaluation
Feature space warping normalization
Knowledge-driven feature selection
Classification methods for independent “bag of observations” features
Valid application-independent evaluation
Feature space warping normalization
Vocal aging -> features for speaker age recognition
GMM/SVM supervector approach for acoustic speech features
Detection task and pseudo-NIST evaluation procedure
Rank and polynomial rank normalization
Vocal aging -> features for speaker age recognition
GMM/SVM supervector approach for acoustic speech features
Detection task and pseudo-NIST evaluation procedure







































![A Fuzzy Recommender System for eElections - unifr.ch Fuzzy Recommender System for eElections 63 2 Recommender Systems for eCommerce According to Yager [4], recommender systems used](https://static.documents.pub/doc/80x56/5b08be647f8b9a93738cdc60/a-fuzzy-recommender-system-for-eelections-unifrch-fuzzy-recommender-system-for.jpg)



