Page 1
Regresión Cuantílica o “Quantile Regression”
A. Cameron and P. Trivedi, (2005), Macroeconometrics, Methods
and Applications, Cambridge University Press.
R. Koenker, (2005), Quantile Regression, Econometric Society
Monographs
C. M. Kuan, (2004), An Introduction to Quantile Regression,
Institute of Economics, Academia Sinica, Taiwan.
www.sinica.edu.tw/as/ssrc/ckuan
Page 2
2
Introducción
En general , en estudios empíricos se está interesado en analizar el comportamiento
de una variable dependiente dada la información contenida en un conjunto de
regresores o variables explicatorias.
Un enfoque estándar es especificar un modelo de regresión lineal y estimar sus
parámetros no conocidos mediante el método OLS o el método LAD.
•El método OLS estima los parámetros minimizando la suma de
los errores al cuadrado y lleva a una aproximación de la función
media de la distribución condicional de la variable dependiente.
•El método LAD minimiza la suma de los errores absolutos y
conduce a una aproximación de la función de la mediana
Condicional.
Aunque la media y la mediana son dos medidas de localización importantes que
representan el comportamiento promedio o la tendencia central de una distribución,
cuentan muy poco acerca del comportamiento en las colas de la distribución.
Page 3
3
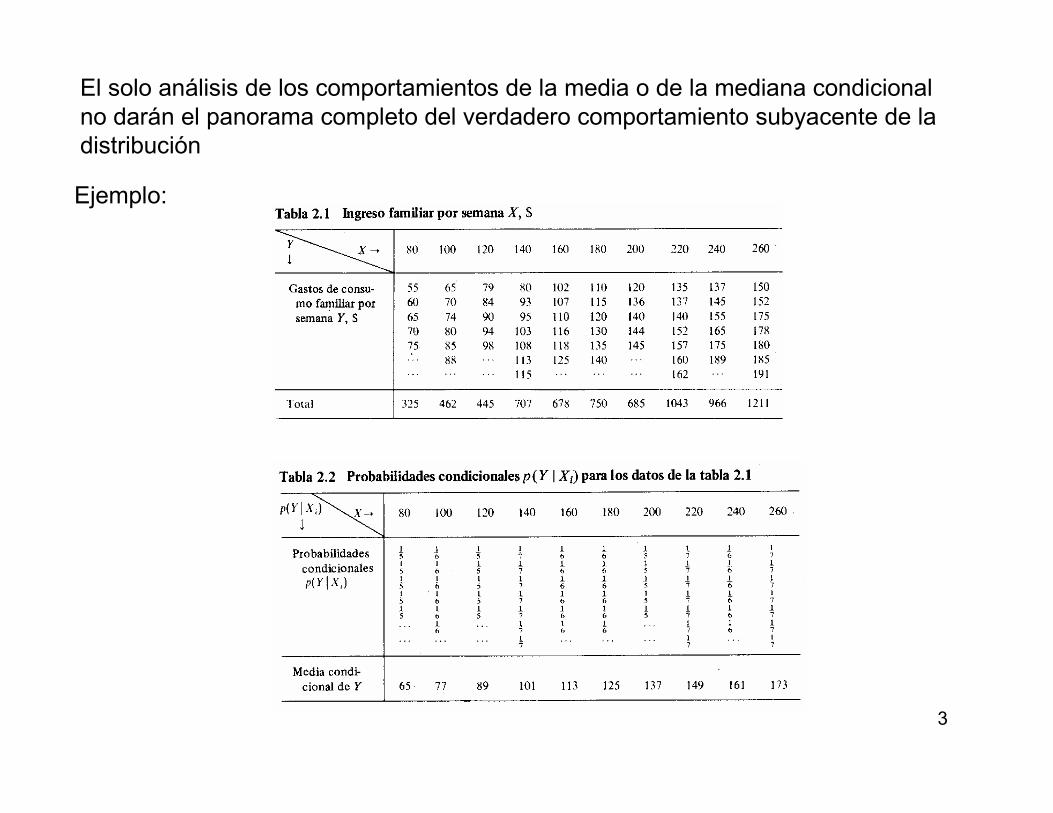
El solo análisis de los comportamientos de la media o de la mediana condicional
no darán el panorama completo del verdadero comportamiento subyacente de la
distribución
Ejemplo:
Page 4
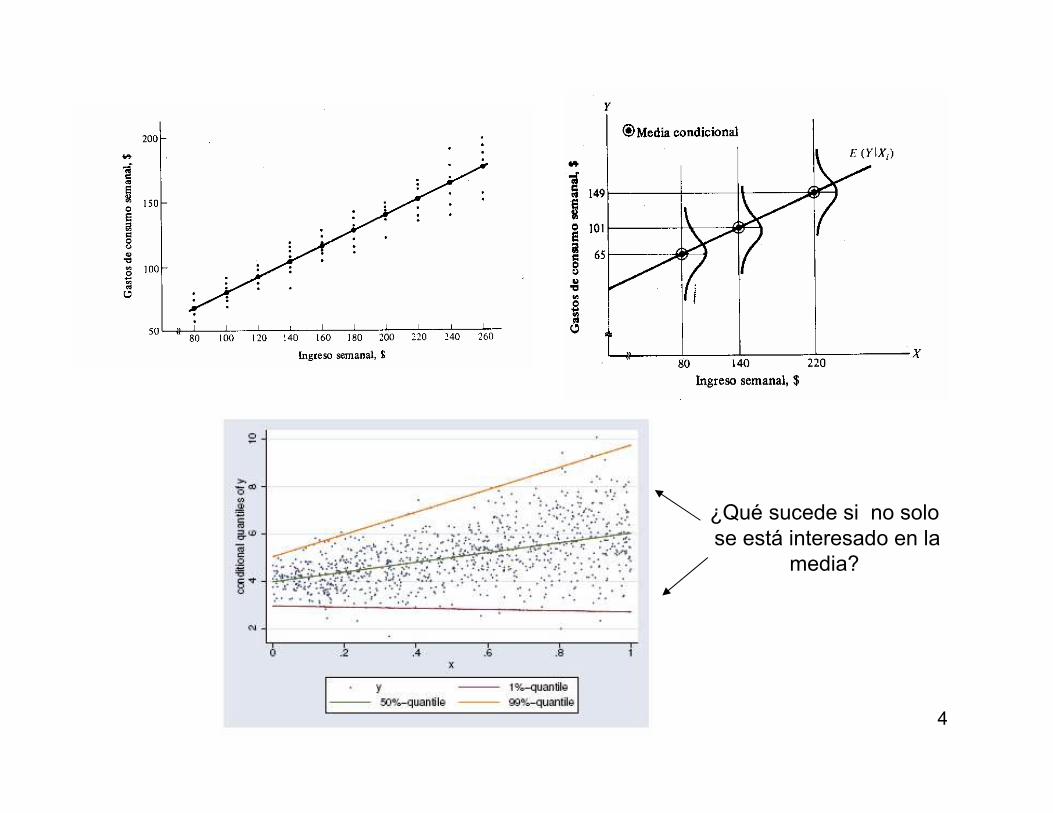
4
¿Qué sucede si no solo
se está interesado en la
media?
Page 5
5
Un nuevo punto en el análisis de regresión es el enfoque de regresión por cuantiles
propuesta por Koenker y Bassett (1978)
•Este enfoque permite estimar distintas funciones cuantílicas de la distribución
condicional, entre ellas la función mediana como caso especial.
•Cada función cuantílica caracteriza un punto particular de la distribución
condicional.
Así, combinando diferentes regresiones cuantílicas se tiene una descripción más
completa de la distribución condicional subyacente
Análisis particularmente útil cuando la distribución condicional no presenta la forma
estándar: -asimetría
-colas más gruesas
-truncamientos
Page 6
6
Algunas ventajas:
•Robustez de los resultados frente a valores atípicos de la variable regresada
•Eficiencia para un conjunto amplio de distribuciones del error
Algunas desventajas:
•Alto grado de trabajo computacional
•En contraste con OLS la función objetivo es no diferenciable en el origen y por
consiguiente no puede darse una solución cerrada
•No se cuenta aún con un buen desarrollo de la teoría asintótica
•Un agran cantidad de autores están trabajando en este punto
Algunas ventajas y desventajas
Page 7
7
Función cuantílica
Para cualquier y para cualquier variable aleatoria (contínua o discreta):
El cuantil de puede definirse como:
( )1,0∈τ Y
ésimo−τ Y
( ) ( )τττ ξτξξ ≤≤≤<ℜ∈ YPYP
τξτξ
Al menos por ciento de la masa de la probabilidad de es menor o igual a y por
lo menos porciento de la masa de probabilidad de es mas alto que τ Y τξ( )τ−1 Y
τξ
τ
http://www.stat.wvu.edu/SRS/Modules/Normal/normal.html
Page 8
8
Tal probabilidad:
•Siempre existe
•Es única siempre la variable aleatoria sea una variable contínua
•La igualdad siempre se alcanza al ser la variable aleatoria contínua
Y
Algunas distribuciones y algunas funciones cuantílicas
Page 9
9
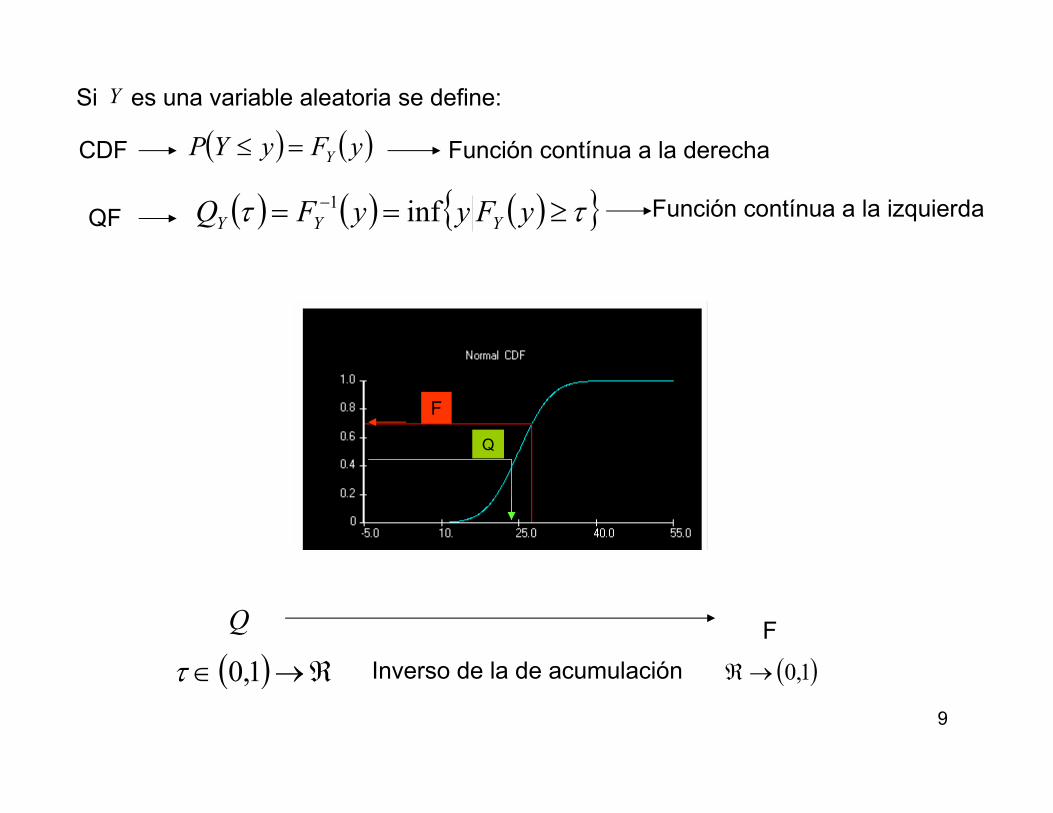
Si es una variable aleatoria se define: Y
CDF ( ) ( )yFyYP Y=≤ Función contínua a la derecha
QF ( ) ( ) ( ) ττ ≥== − yFyyFQ YYY inf1 Función contínua a la izquierda
F
Q
( ) ℜ→∈ 1,0τ Inverso de la de acumulación ( )1,0→ℜ
Q F
Page 10
10
Para cualquier nos proporciona el cuantil de
no condicional
( ) ( )ττ YQ,1,0∈ ésimo−τ Y
Algunas propiedades interesantes:
• Creciente monotónica
• función continua a la izquierda ( ) ( )( ) ( ) ( )( )( ) ττττ =≤=≤∈∀ YY QgYgPQYP1,0g
•Para una variable aleatoria continua , se define la función de densidad de
de probabilidad (PDF):
Y
( ) ( )dy
ydFyf Y
Y =
•De forma similar, para la función cuantílica se tiene:
( ) ( )ττ
τd
dQS YY = Función de densidad cuantílica
Page 11
11
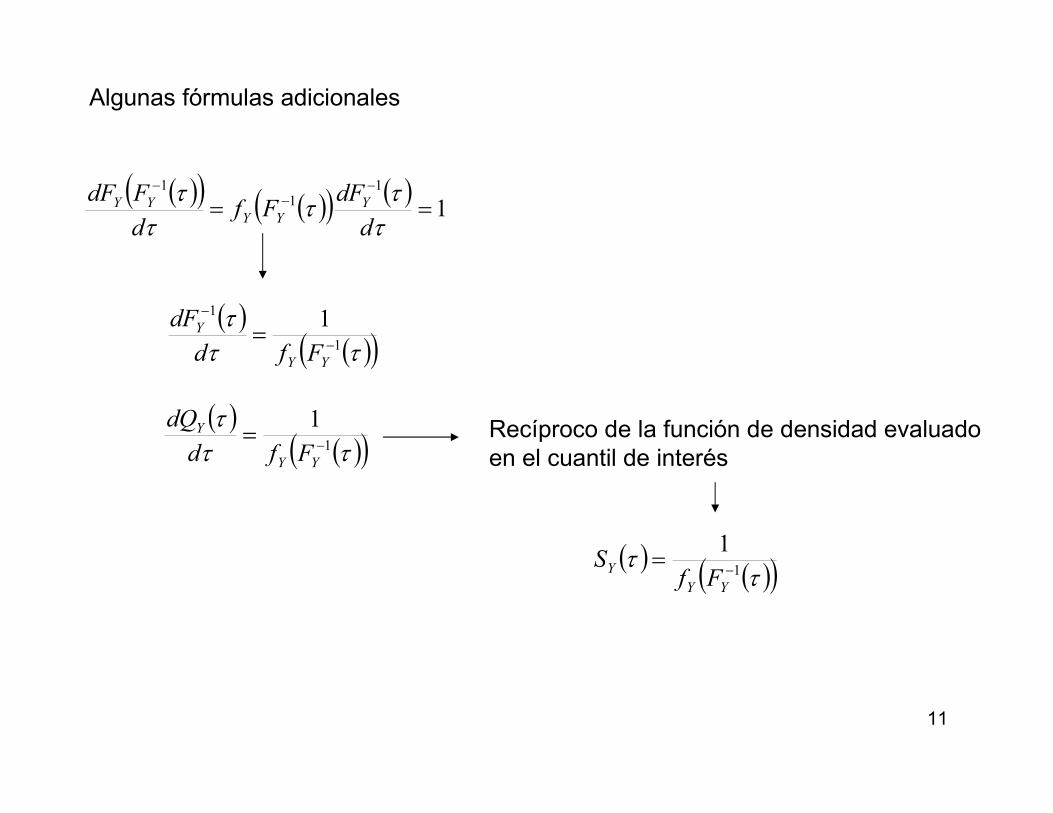
Algunas fórmulas adicionales
( )( ) ( )( ) ( )1
11
1
==−
−−
ττ
ττ
τd
dFFf
d
FdF YYY
YY
( )( )( )ττ
τ1
11−
−
=YY
Y
Ffd
dF
( )( )( )ττ
τ1
1−=YY
Y
Ffd
dQ Recíproco de la función de densidad evaluado
en el cuantil de interés
( )( )( )τ
τ1
1−=YY
YFf
S
Page 12
12
Cuantiles empíricos
Sea una muestra aleatoria su función de distribución empírica está
definida por la razón entre el numero de observaciones menores o iguales al valor
de interés y el número total de observaciones:
nyyy ,,, 21 L
( ) ( )n
yyyF i
Y
≤=#
ˆ
De igual manera, se puede definir la función cuantílica empírica como:
( ) ( ) ( )10,
#infˆˆ 1 <<
≥≤
== − τττn
yyyyFQ i
Y Y
Con el propósito de obtener el cuantil deseado:
•Ordenar la muestra
•Revisar en que observación se alcanza el umbral
•Método para el cálculo de los cuantiles
( )
( )
−−+−= ∑∑<∈≥∈ℜ∈
τττ ξ
τξ
τξξτξττ
ii yiii
yiiiY yyQ 1minargˆ Función objetivo
Función de pérdida ponderada
Page 13
13
Ejemplo: Evaluación de la función objetivo para una muestra aleatoria tomada de
una distribución normal estándar para 25.0=τ
Ordenamiento
Minimización de la función
Objetivo en el intervalo:
-0.9411827, -0.6687527
4
1de las observaciones
Page 15
15
La función objetivo es convexa y se puede obtener el intervalo donde se produce
el mínimo.
Suma izquierdaSuma derecha
Función compuesta
de pérdida
25.0=τ
Pérd
ida
Page 16
16
El concepto de ordenar se remplaza por el de optimizar
una función de pérdida ponderada
Ejemplo:
2
1=τEn el caso de la media
Definición: función de verificación
( ) ( )( )( ) ( )( ) τρ
τρ
τρ
τ
τ
τ
uuuSi
uuuSi
uIuu
=⇒≥⋅
−=⇒<⋅
<−=
0
10
0
Variable indicadora
Donde 10 << τ
Permite reformular la función objetivo
Page 17
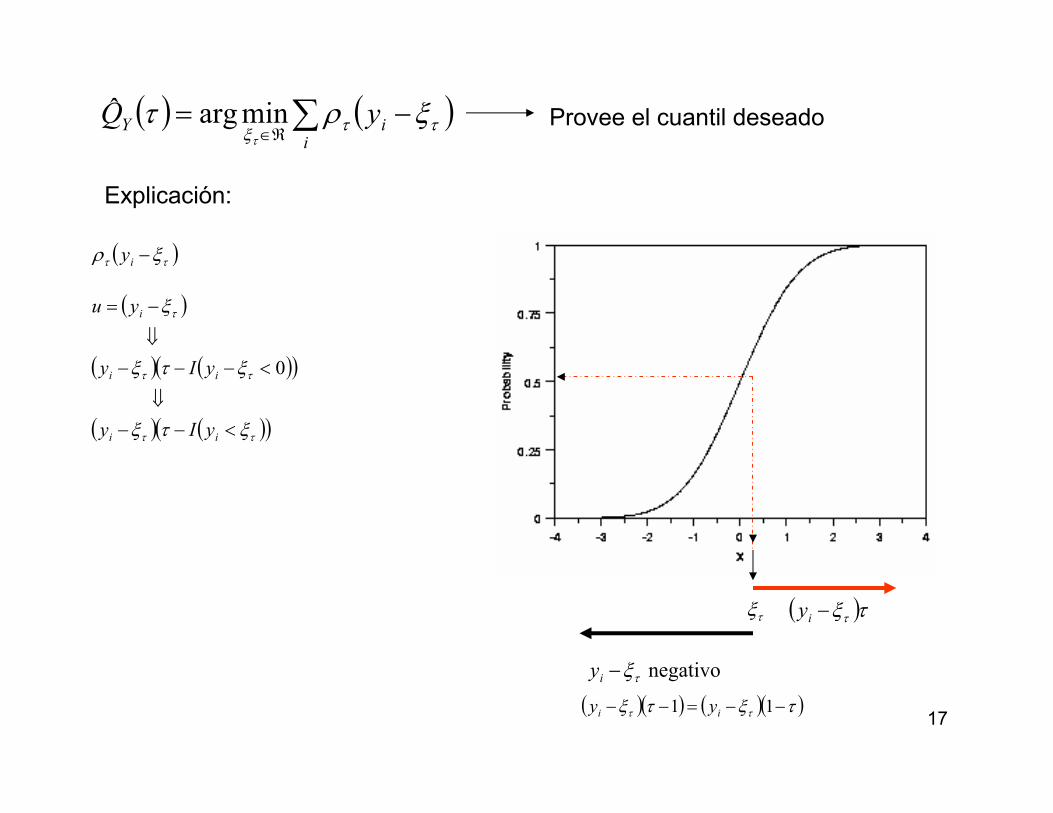
17
( ) ( )∑ −=ℜ∈
iiY yQ ττξ
ξρττ
minargˆ Provee el cuantil deseado
Explicación:
( )ττ ξρ −iy
( )
( ) ( )( )
( ) ( )( )ττ
ττ
τ
ξτξ
ξτξ
ξ
<−−
⇓
<−−−
⇓
−=
ii
ii
i
yIy
yIy
yu
0
τξ ( )τξτ−iy
negativoτξ−iy
( )( ) ( )( )τξτξ ττ −−=−− 11 ii yy
Page 18
18
Valor esperado de la función de pérdida:
( )[ ] ( ) ( ) ( ) ( ) ( )∫∫∞−
∞
−−−−=−τ
τ
ξ
τξ
τττ ξτξτξρ ydFyydFyyE 1 Notación ( ) ( )dy
ydFyf Y
Y =
Tomando la derivada respecto a se tiene:τξ
( )[ ]( ) ( )
( )( ) ( )
τ
ξ
τ
τ
ξτ
τ
ττ
ξ
ξτ
ξ
ξτ
ξξρ
τ
τ
∂
∂−∂−−
∂
∂−∂
=∂
−∂ ∫∫∞−
∞
yFyyFyyE
1
( ) ( ) ( )∫∫∞−
∞
∂−+∂−=τ
τ
ξ
ξ
ττ yFyF 1
( )( ) ( ) ( )( )ττ ξτξτ FF +−−+−−= 011
( ) ( ) ( )τττ ξτξξττ FFF −++−=
Haciendo la derivada igual a cero se tiene: ( ) τξτ =F
La función de pérdida esperada es convexa y se minimiza solo si se tiene
•El óptimo de la función de pérdida provee el cuantil deseado
Page 19
19
Regresión cuantílica
Una vez estudiado el punto de cómo determinar cuantiles empíricos, la pregunta que
surge es: ¿Como podría ser utilizada esta nueva formulación en el análisis de
regresión?
Al utilizar un modelo de regresión lineal:
TiuXy iii ,,2,1'L=+= β
Donde se supone que [ ] [ ] β'0 iiiii XXyEXuE =⇒=
El vector de parámetros puede estimarse por OLS:β ( )2'minargˆ ∑ −=ℜ∈ i
ii Xyk
βββ
Supóngase
El cuantil del término de error condicional a los regresores ceroésimo−τ
( ) 0, =ii XuQ ττ( )( )
( )( )iu
iu
ii
XQ
XQ
XuQ
i
i
τ
τ
τ
ττ
τ,
,
(No el valor esperado)
niuXy iii ,,2,1,
'L=+= ττβ T
Page 20
20
El cuantil condicional de con respecto a puede ser escrito:ésimo−τ iy iX
( ) ττ β'iii XXyQ =
Reuniendo las siguientes ecuaciones:
( )
( )
−−+−= ∑∑<∈≥∈ℜ∈
τττ ξ
τξ
τξξτξττ
ii yiii
yiiiY yyQ 1minargˆ
( ) ( )∑ −=ℜ∈
iiY yQ ττξ
ξρττ
minargˆ
( ) ττ β'iii XXyQ =
Para cualquier el vector de parámetros puede ser estimado de la siguiente
forma:
( )1,0∈τ τβ
( )
−−+−= ∑∑<∈≥∈ℜ∈
τττ β
τβ
τβ
τ βτβτβ''
'' 1minargˆ
iiii
k
Xyii
ii
Xyii
ii XyXy
( )∑ −=ℜ∈ i
ii Xyk ττ
ββρ
τ
'minarg
⋅
⋅⋅
Page 21
21
Todas las observaciones por encima del hiperplano estimado por , es decir, la
diferencia absoluta entre y son ponderadas por y todas las observaciones
por debajo son ponderadas por . La mediana condicional se tiene cuando
τβXiy τβ
'
iX τ( )τ−1 5.0=τ
∑ −=ℜ∈ i
ii Xyk 5.0
'
5.05.0
minargˆ βββ
El estimador de del cuantil puede ser obtenido minimizando su
contraparte muestral. Es decir, puede entenderse como el promedio ponderado
asimétrico de los errores absolutos, con ponderaciones sobre errores
positivos y sobre los errores negativos:
β ésimoτ −
τ( )1 τ−
( ) ( )' '
' '
: :
1; 1
i i i i
T i i i i
i y X i y X
V y X y XT β β
β τ τ β τ β≥ <
= − + − −
∑ ∑
Page 22
22
Mediante la función se tiene:
( ) ( )
( )'
'
1
'
01
1;
11
i i
T
T i i
i
T
i iy Xi
V y XT
y XT
τ
β
β τ ρ β
τ β
=
− <=
= −
= − −
∑
∑
τρ
La condición de primer orden de la minimización de es: ( );TV β τ
' 01
1: 1 0
i i
T
i y Xi
XT β
τ− <
=
= − =
∑ Excepto en , la derivada no
está definida
'
i iy X β=
Una vez se obtiene , el hiperplano de regresión cuantílica y los residuales
son estimados:τβ)
'
iX τβ)
( ) '
i i ie y X ττ β= −))
Resolviendo para se obtiene el estimador de regresión cuantílica
para
β τβ)
ésimoτ −β
Page 23
23
Mientras más regresiones cuantílicas se estimen, mejor puede entenderse la
forma de la distribución condicional.
•Si la recta de regresión mediana difiere de la obtenida a través de OLS (media)
de manera significativa, la distribución es asimétrica.
•La distribución condicional es asimétrica a la izquierda si las líneas cuantilicas
superiores están muy cerca unas de otras en comparación con las líneas
cuantílicas Inferiores.
•En general se puede encontrar que las regresiones cuantílicas estimadas
difieren entre si a través de los cuantiles. Lo cual sugiere que las variables
explicativas pueden tener diferentes impactos sobre la variable dependiente.
Es decir, el impacto depende de la localización de la distribución condicional.
Page 24
24
Cálculo del estimador
El estimador de la regresión cuantílica no es sencillo de calcular debido a que la
función objetivo no es diferenciable, por consiguiente los métodos estándar de
optimización numérica no son fácilmente aplicables.
En la práctica, la estimación de la regresión cuantílica es usualmente llevada a
cabo resolviendo un problema de programación lineal.
( ) ( )'
,
1
k
i i i i j j j i i
j
y X e x e eβ β β+ − + −
=
= + = − + −∑
jβDonde es el coeficiente de tal que:
parte positiva
parte negativa
j ésimo− β
( )min ,0j jβ β− = −
( )max ,0j j
β β+ =j j jβ β β+ −= −
Page 25
25
De igual forma, se tiene t t te e e+ −= −
Sea e+ El vector ie+
Sea e− El vector ie−
´ ´ ´ ´ ´
, , ,Z e eβ β+ − + − = De dimensiones de elementos
no negativos( )2 k T+
De lo anterior se tiene la siguiente especificación no lineal:
dimensión x1tY y T= →
dimensión xk -X T t ésima→ fila
[ ] ( ), , , x2T T
A X X I I T k T= − − → +
'
tX
( ) ( )
AZY
eeXY
=
−+−= −+−+ ''
ββ
Donde:
Page 26
26
0 dimensionalk→ −
Se define:
La función objetivo ( );T
V β τ '1c Z
T
Para resolver el problema de programación lineal Barrodale y Roberts (1974)
diseñaron un algoritmo basado en el método simplex para la estimación LAD.
Este fue extendido posteriormente por Koenker y d’Orey (1987) para la estimación
cuantílica.
( )[ ]''''' 1,,0,0 ιττι −=c
ldimensiona−→Tι
•(La implementación de este procedimiento está en Koenker’s (2004) quantile regression package for
The R Proyect)
Minimizar es equivalente a minimizar con respecto a , sujeto a las
restricción de que y que no contiene elementos negativos.
( );TV β τ Z
Y AZ= Z
Zc '
Page 27
27
Comentarios generales
•En el modelo de regresión cuantílica, para cualquier el cuantil
condicional de respecto a la matriz de regresores puede ser calculada
como:
( )0,1τ ∈Y X
•Variando , el método de regresión cuantílica nos permite evaluar la distribución
condicional completa de la variable dependiente. En contraste con el enfoque de
OLS el cual nos provee de un único valor: la media condicional
τ
•La estructura flexible del QR es capaz de detectar algunas formas de comportamiento
heteroscedástico en los datos, analizando diferentes cuantiles.
•Koenker y Portnoy (1999) establecen que en un modelo con regresores, existen
residuales con valores de cero. La proporción de residuales negativos es
aproximadamente igual a y la proporción de positivos es
kk
τ ( )1 τ−
−T+T
( ) 'Q Y X Xτ τβ=) ( )ττ
βτ βρβ
τ
iii
Xyk
−= ∑ℜ∈
minargˆ
Page 28
28
Donde se tiene
PositivosNegativos
•En OLS se calcula el como una medida de bondad de ajuste:2R
Koenker y Machado (1999) proponen una medida similar para la regresión
cuantílica:
Mide el éxito relativo del modelo de regresión cuantílica. Puede ser interpretado
como una medida de bondad de ajuste local, para un cuantil particular.
( )T
kT
T
T
T
kT
T
T +≤−≤
+≤≤
++−−
ττ 1,
( )( )
( )( )∑
∑
∑
∑
−
−−=
−
−=
ii
iii
ii
ii
yy
Xy
yy
yX
R2
2'
2
2'
2
min
ˆmin
1min
ˆmin ββ
( )( )( )
( )( )
( )( )( )∑
∑
∑
∑
−
−−=
−
−=
ii
iii
ii
ii
yQy
Xy
yQy
yQX
Rττ
ττ
ττ
τττ
ρ
βρ
ρ
βρτ
min
ˆmin
1min
ˆmin ''
1
Page 29
29
Lo que no es concepto erróneo
Algunas veces de forma equivocada puede pensarse que la regresión por cuantiles
puede ser estimada simplemente segmentando en subconjuntos de acuerdo con
su distribución no condicional y luego estimar OLS para cada subconjunto.
Y
Sesgo de selección Hallock, Madalozzo y Rech (2003)
•Resultados equivocados como producto del
truncamiento de la variable Y
•Aun cuando el ajuste concreto en un cuantil
condicional está determinado por puntos,
la decisión sobre los puntos depende de la
muestra completa para cualquier cuantil
kk
Page 30
30
Equivarianza, robustez, eficiencia e interpretación
Koenker y Bassett (1978) muestran las siguientes propiedades de equivalencia
de los coeficientes estimados de la regresión cuantílica:
( ) ( ) [ )( ) ( ) [ )( ) ( )( ) ( ) singularNo,ˆ,ˆ.4
,ˆ,ˆ.3
,0,ˆ,ˆ.2
,0,ˆ,ˆ.1
1
1
→=
ℜ∈+=+
∞∈=−
∞∈=
−
−
AXyAXAy
XyXXy
XyXy
XyXy
k
ττ
ττ
ττ
ττ
ββ
γγβγβ
λβλλβ
λβλλβ
1. y 2. establecen que es equivariante en escala. Si la variable dependiente es
reescalada por el factor es reescalada en la misma proporción.τβ Y
τβλ ˆ⇒
3. Se conoce como propiedad de localización o regresión equivariante: si es la
solución de es la solución de dondeτβ
( ) γβτ +⇒ ˆ, Xy ( )Xy ,* γXyy +=*
4. Equivarianza de reparametrización de la matriz de diseño. La transformación de
está dada por la inversa de la matriz de transformación de τβ X
Page 31
31
El estimado QR disfruta de otra propiedad de equivarianza, la cual es más fuerte
que las anteriores:
( )( ) ( )( )XyQhXyhQ ττˆˆ.5 = con ( ) ℜ⋅ enh
Es decir, los cuantiles condicionales son equivariantes frente a transformaciones
no decrecientes sobre la variable dependiente.
La media condicional no comparte tal propiedad: ( )[ ] [ ]( )XyEhXyhE ≠
6. Otra propiedad de la regresión cuantílica es la robustez frente a valores atípicos
o extremos de la variable dependiente. Una vez fijado el hiperplano cuantílico
condicional, cualquier observación por encima del plano puede ser arbitrariamente
grande o cualquiera por debajo muy pequeña sin alterar la solución establecida.
Las propiedades 1. - 4. son compartidas por el estimador OLS
Page 32
32
Derivadas
•En OLS los coeficientes de regresión se interpretan como derivadas parciales del
valor esperado de y
[ ]k
kX
XyE
∂
∂=β
•En regresión cuantílica la interpretación es similar
( )k
kX
XyQ
∂
∂= τ
τβ ,Responde a la pregunta sobre ¿Cómo reacciona el
cuantil condicional de ante cambios en
ésimo−τy kX
Ejemplo:
( )( )
( )( )k
X
k
eX
XyQ
XXyQ
,
'
'log
log
τβτ
ττ
β
β
τ=∂
∂
=
Page 33
33
Resultados asintóticos e Inferencia
Normalidad asintótica
•Cuantiles muestrales
( ) ( )∑ −=ℜ∈
iiY yQ ττξ
ξρττ
minargˆ Cuantil muestral unidimensional
La ley de los grandes números establece que la función de distribución empírica de
una v.a unidimensional converge uniformemente en probabilidad a la verdadera
función de distribución.
( )( ) ( )2,0ˆ ωξτ τ NQT Y →−
( )( )
( ) ( )τττ
ξττ
ωτ
2
2
2
1
1
y
y
S
f
−=
−=
El espaciamiento de los datos en un cuantil específico determina
la precisión del valor estimado
Page 34
34
•Regresión lineal cuantílica
( ) ( )( ) ( )τττττ ττββ Λ−→− −− ,0~1,0ˆ 11 NJHHNT
∑−
∞→=
iii
TXXTJ '1lim
( )( )iii
iiiT
XyQfXXTH ττ ∑−
∞→= '1lim
Si los errores se suponen , la primera ecuación se simplifica de la siguiente manera: iid
( ) ( )( )( )
−→− −
−1
12
1,0ˆ J
FfNT
τττ
ββ ττ
siendo '1lim i
i
iT
XXTJ ∑−
∞→=
Page 35
35
•Distribución asintótica conjunta
Sea ( )''' ,,1 mττ ββζ L= km − estimadores de regresión cuantílica
( )''' ˆ,,ˆˆ1 mττ ββζ L= Su valor estimado
La distribución asintótica conjunta de éstos vectores de coeficientes estimados está
dada por:
m
( ) ( )Ω→− ,0ˆ NT ζζ
( ) ( )( ) 11,min −−−==Ω jijijiij JHHw ττττττ
'1lim i
i
iT
XXTJ ∑−
∞→=
( )( )iii
iiiT
XyQfXXTH ττ ∑−
∞→= '1lim
Page 36
36
Estimación del espaciamiento (Sparcity)
Residuales iid
Bajo el supuesto de errores iid
( ) ( )( )( )
−→− −
−1
12
1,0ˆ J
FfNT
τττ
ββ ττ
Para llevar a cabo cualquier proceso de inferencia se debe estimar el cuadrado
del recíproco de la densidad ( )( )τ1−Ff
Sabemos que ( )( )( )τ
τ1
1−=YY
YFf
S
( ) ( )
( )ττ
ττ
τ
∂∂
=
∂∂
=
−1Y
YY
F
QS
( ) ( ) ( )T
TTY
h
hFhFS
2
ˆˆˆ
11 −−+=
−− τττ Cociente en diferencia de la función
cuantílica empírica
Estimación de la función cuantílica
Ancho de banda
Page 37
37
La pregunta que surge es ¿Cómo seleccionar de forma adecuada el parámetro de
ancho de banda?
•Bofinger (1975)( )
( )
51
2''
2
5/1 5.4
= −
ττ
S
SThT
Minimiza el error medio cuadrático en
condiciones regulares deF
Dado que no es muy sensible a , se puede calcular para
algunas distribuciones.
( )( )ττ''S
S F Th
En general( )( )
−
+
≈
ff
ff
ff
f
S
S''''
2
''
2ττ
( )( )( )( )( )( )
5
1
221
415/1
12
5.4
+Φ
Φ=
−
−−
τ
τφThT Considerando φ=f
( )( ) ( )ττ 11'
−− Φ=
Ff
f
Distribución normal:
Dado que la distribución gaussiana es simétrica, es similar en y en Th τ ( )τ−1
Page 38
38
El ancho de banda es más pequeño en la medida en que o aumentan. Este
último alejándose por encima o por debajo de T τ
5.0
•Hall – Sheather (1988) ( )( )
31
''3
23/1 5.1
= −
ττ
αS
SZThT
donde
−Φ= −
211 α
αZ
( )( )( )( )( )
3
1
21
21
32
3/1
12
5.1
+Φ
Φ=
−
−−
τ
τφαZThTDistribución normal
•Una tercera y más simple alternativa es propuesta por Buchinsky (1991)
( )τττ
α−
=1
ZhT Chamberlain
Page 39
39
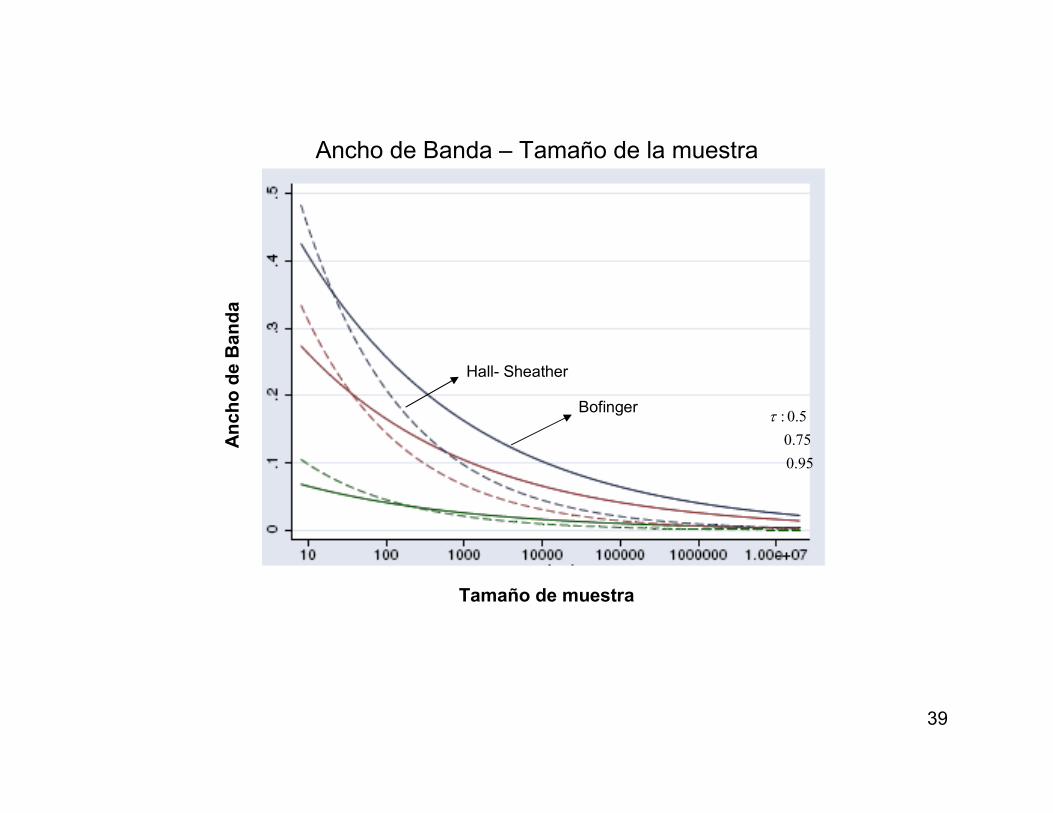
95.0
75.0
5.0:τBofinger
Hall- Sheather
Ancho de Banda – Tamaño de la muestra
An
ch
o d
e B
an
da
Tamaño de muestra
Page 40
40
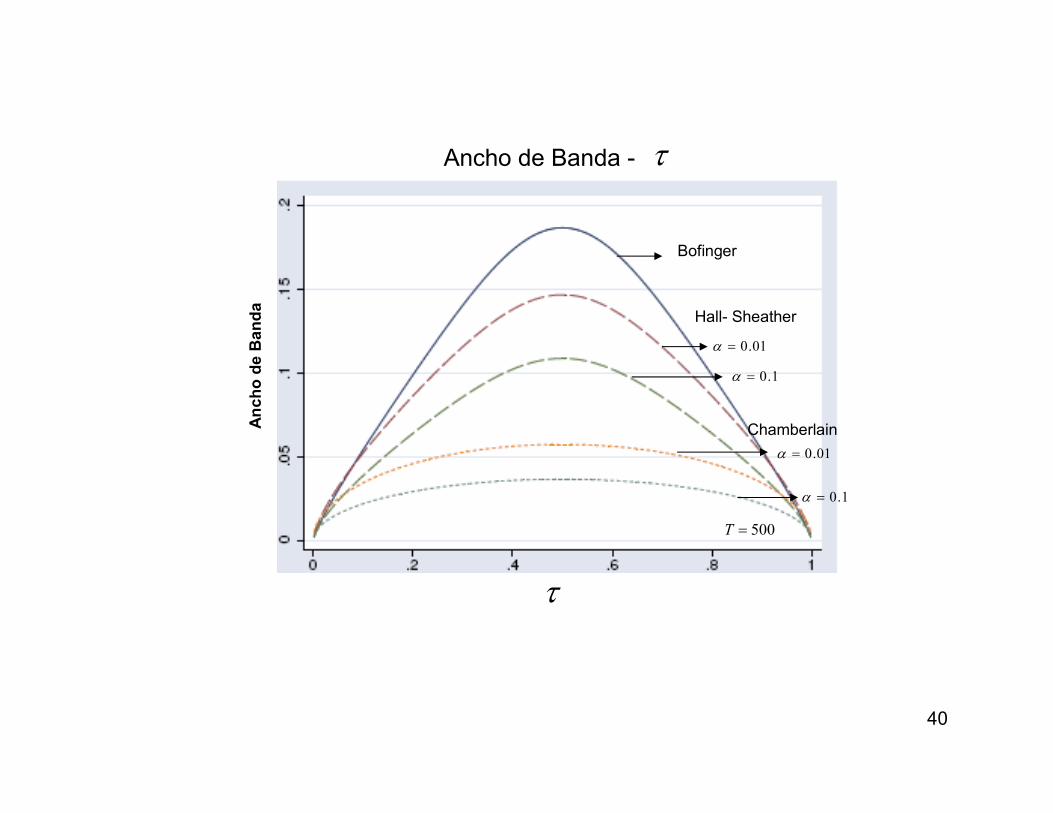
BofingerA
nc
ho
de
Ba
nd
a
τ
500=T
1.0=α
01.0=α
Hall- Sheather
01.0=α
1.0=α
Chamberlain
Ancho de Banda - τ
Page 41
41
Una vez determinado el ancho de banda nos centramos en la pregunta de cómo
calcular la función cuantílica empírica:
( )ττ1ˆˆ −= FQ ( ) ( ) ( )
T
TTY
h
hFhFS
2
ˆˆˆ
11 −−+=
−− τττ
•Enfoque sencillo:
1. Tomar los residuales de la regresión cuantílica fijada para un cuantil seleccionado*τ
TiXyu iii ,,2,1ˆˆ *
'L=−=
τβ
2. Ordenamiento de residuales
( ) Tiu i ,,1:ˆ L=
3. Estimación de la función cuantílica empírica
Estadística de orden
( ) ( )
−∈=−
T
i
T
iuF i ,
1ˆˆ 1 ττ
4. Estimación lineal a trozos
( )
( )
( ) ( ) ( )
( )
−
∈
+−
∈−+
∈
= +−
1,2
12ˆ
2
12,
2
12ˆ1ˆ
2
1,0ˆ
~1
1
1
T
Tu
T
j
T
juu
Tu
F
T
jj
τ
τλλ
τ
τ1,,1,
2
1−=+−= TjjT Lτλ
Page 42
42
•Otro enfoque fue el presentado por Bassett y Koenker (1982):
( ) τβτ ˆˆ '1
iXF =−
En resumen:
( ) ( ) ( )T
TTY
h
hFhFS
2
ˆˆˆ
11 −−+=
−− τττ
( ) ( )
−∈=−
T
i
T
iuF i ,
1ˆˆ 1 ττ
( )
( )
( ) ( ) ( )
( )
−
∈
+−
∈−+
∈
= +−
1,2
12ˆ
2
12,
2
12ˆ1ˆ
2
1,0ˆ
~1
1
1
T
Tu
T
j
T
juu
Tu
F
T
jj
τ
τλλ
τ
τ
( )( )
51
2''
2
5/1 5.4
= −
ττ
S
SThT
( )( )
31
''3
23/1 5.1
= −
ττ
αS
SZThT
( )τττ
α−
=1
ZhT
Page 43
43
Sp
arc
ity
τ
Bofinger
Hall- Sheather
Chamberlain
Espaciamiento estimado para una muestra aleatoria para 500 valores de la
Distribución normal estándar
Page 44
44
•Bootstrapping
Existen diversas propuestas para estimar la función de espaciamiento y muchas
de ellas se basan en técnicas de resampling o bootstrapping (Efron (1979)).
Existen diferentes implementaciones del procedimiento de bootstrap.
Residuales bootstrap sugerida por Efron (1982) Regresión no lineal en la mediana
Una adaptación para el caso de regresión cuantílica fue desarrolado por Hahn (1995)
1. Establecer el modelo de regresión cuantílica y obtenga sus residuales:
2. Extraer una muestra con reemplazamiento de tamaño de la distribución empírica
estimada de los residuales ( residual bootstrapping):
TiXyu iii ,,1ˆˆ'
, L=−= ττ β
*
,
*
,1 ,, ττ Tuu L
3. Calcular:*
,
'* ˆττβ iii uXy +=
Page 45
45
4. Determinar el coeficiente bootstrap de regresión cuantílica:
( )ττβ
τ βρβτ
'** minargˆii
i
Xyk
−= ∑ℜ∈
5. Repetir el proceso veces hasta alcanzar:B
*
,
*
1,ˆ,,ˆ
Bττ ββ L
6. Construir la matriz de var-cov asintótica de la siguiente manera:
( )( )'*
,1
*
,ˆˆˆˆˆτττττ ββββ −−=Λ ∑
=b
B
bb
B
T
Page 46
46
Residuales no iid
( ) ( )( ) ( )τττττ ττββ Λ−→− −− ,0~1,0ˆ 11 NJHHNTEn la ecuación
La varianza asintótica de los coeficientes estimados de la regresión cuantílica
presenta diferentes densidad en cada observación. τH
Debe ser estimada completa.
Es decir, para cada observación
•La primera propuesta es la de Hendricks y Koenker (1992):
1. estimar la función de densidad para cada observación :
( )( ) ( )TT hhi
Tiii
X
hXyQf
−+ −=
τττ ββ'
2ˆ
2. Los valores obtenidos son incluidos en , en caso de que el denominador no sea
Positivo se debe hacer la siguiente corrección: τH
( )( ) ( ) 0conˆˆ
2,0maxˆ
'>
−−=
−+
+ εεββ ττ
τ
TT hhi
Tiii
X
hXyQf
Page 47
47
•La segunda propuesta es la de Powell (1986-1991):
( )
:
ˆˆ
ˆ
'
,
',1
K
Xyu
XXh
uKThH
iii
iii T
i
T
ττ
ττ
β−=
= ∑−
Función Kernel
•Bootstrapping
En el caso en que el término de error sea independiente aunque no identicamente
distribuido se puede llevara cabo un bootstrap de la matriz de diseño que provee
una alternativa de los residuales
1. Muestrear de la distribución empírica conjunta:
( )ii Xy ,
2. Determinar para el conjunto de duplas seleccionadas:
*
τβ
3. Llevar a cabo el procedimiento veces y construir luego la matriz de var-cov:B
( )( )'*
,1
*
,ˆˆˆˆˆτττττ ββββ −−=Λ ∑
=b
B
bb
B
T
Page 48
48
Procedimientos de prueba
Se han revisado diferentes formas de estimar la matriz de varianza asintótica de los
coeficientes estimados de regresión, se presentan a continuación algunas pruebas
basadas en dicha matriz.
•Prueba de Wald
Considere el siguiente modelo de regresión cuantílica:
ττβ ,
'
iii uXy +=
Con la siguiente hipótesis lineal:
rRH =τβ:0
Koenker y Bassett (1982) proponen el siguiente test estadístico para verificar la validez
de la hipótesis nula:
( ) ( ) ( ) ( )rrRRRrRTw 21''~ˆˆˆ χββ ττττ −Λ−=
−
Page 49
49
•Test de Razón de Verosimilitud
Sea el valor de la función objetivo en el minimizador no restringido:τV τβ
( )∑ −=ℜ∈ i
ii XyVk ττ
βτ βρ
τ
'minargˆ
Sea el valor de la función objetivo en el minimizador restringido:τV~
τβ~
( )∑ −==ℜ∈ i
iirR
XyVk ττ
ββτ βρ
ττ
'minarg~
Koenker y Machado (1991) muestran que bajo errores iid :
( )( ) ( )
( )RS
VVL 2~
ˆ1
ˆ~2
χτττττ
τ −−
=