18
Regression III: Robust regressions • Outliers • Tests for outlier detections • Robust regressions • Breakdown point • Least trimmed squares • M-estimators
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 223 times |
| Download: | 1 times |

Regression III: Robust regressions
• Outliers
• Tests for outlier detections
• Robust regressions
• Breakdown point
• Least trimmed squares
• M-estimators

Outliers
Outliers are observations that deviates from all others significantly. They may occur by accident or they may be results of measurement errors. Presence of outliers may lead to misleading results. In the example shown on the figure without outlier mean value is -0.41 and with outlier it is -0.01. If we want to test the hypothesis: H0:mean=0 then without outlier we conclude that H0 can be rejected (p-value is 0.009), however with outlier we cannot reject null-hypothesis (p-value is 0.98).
Analysis and dealing with outliers is an important ingredient of modern statistical analysis. Sometimes careful analysis of outliers, their removal or weighting down may change the conclusions considerably.
With outliers
Without outlier
Outlier

Dealing with outliersFor simple cases such as mean, variance calculations one way of dealing with
outliers is using trimmed data for statistic calculation. For example in the case above mean without outlier is -.41, with outlier -0.09 and trimmed mean with 10% removed is -0.33. Trimmed mean gives “better” than mean based on all data.
Often mean and other statistics are used for testing some hypothesis. In these cases using non-parameteric (wilcox.test) tests may be better alternatives to t.test (wilcox.test gives p-value 0.09 and t.test gives p-value 0.98).
For simple cases like mean, covariance calculations and test based on them usual approach is to use rank of observations instead of their values. Obviously when rank is used the power of tests will be reduced, however better conclusions could be more reliable.
Before carrying out analysis and tests it is always good idea to visualise data and explore to see if there are outliers.

Outlier detection: Grubbs’ testIt may be a good idea to test for outliers and remove them if possible before starting to
analyse the data and doing hypothesis testing. One of the techniques for doing this is Grubbs’ test. It tests
H0: there is an outlier versus H1: there is no outlier
To do this Grubbs suggested using the statistic:
G = (max(y)-mean(y))/sd(y)
to test if the maximum value is outlier
G = (mean(y)-mean(y))/sd(y)
to test if the minimum value is outlier and
G = max(|yi-mean(y)|)/sd(y)
to test if maximum or minimum is outlier. There are versions for two outliers also.
Obviously test statistics will depend on the number of observations.
Grubbs’ test (grubbs.test) is available from the package outliers. It is not part of the standard R distributions.

Outlier detection: Grubbs’ testApplying grubbs.test for the example we get:
Grubbs test for one outlier
data: del1
G = 2.9063, U = 0.0709, p-value = 9.858e-06
alternative hypothesis: highest value 4 is an outlier
Since p-value is very small we can reject null hypothesis that there is no outlier.
Once we are sure that there is an outlier then we remove it and carry out tests and/or analysis further.

Outlier detection: Simulated distributionIf outliers package is not available then we can generate distribution for the statistics
given above. Let us write for one of them (H0: maximum value is not outlier):outdist = function(nsample,n){
ff = vector(length=n)
for (i in 1:n){rr=rnorm(nsample);ff[i]=max(rr-mean(rr))/sd(rr)}
ff
}
Now we can generate distribution of the statistics for samples of different sizes. For example the distribution for sample of sizes 10,15 and 20 are shown on the figure. To generate the figure the following set of commands are used
oo10 = outdist(10,10000) curve(ecdf(oo10)(x),from=0,to=15,lwd=3)
oo15 = outdist(15,10000)
curve(ecdf(oo15)(x),from=0,to=15,lwd=3)
oo20 = outdist(20,10000)
curve(ecdf(oo20)(x),from=0,to=15,lwd=3)
Obviously as the sample size increases probability that
large values will be genuinely observed will increase. That is why as sample size increases the distribution shifts to the right.

Outlier detection: Simulated distributionOnce we have the desired distributions we can calculate For example for the case we
considered we sample size is 11. Let us generate empirical cumulative probability distribution and use it for outlier detection:
oo11=outdist(11,10000)
ec11 = ecdf(oo11)
st = max(del1-mean(del1))/sd(del1)
1-ec11(st)
This sequence of commands will produce p-values. If the maximum value is 4 then p-value is 0, if the maximum value is 2 then p-value is 0.001 and when maximum value is 1 then p-value is 0.04. We can reject null-hypothesis for first and the second case, however for the third case we should be careful.

Breakdown pointBreakdown point of an estimator is a fraction of of sample if changed arbitrarily
that does not affect the estimation significantly. For example for mean value if we changing by value arbitrarily we can change mean value as much as we want. Let us take an example:
-0.8 -0.6 -0.3 0.1 -1.1 0.2 -0.3 -0.5 -0.5 -0.3 4.0
Sample size is 11, mean value is -0.09. If we change the last value to 100 then the mean value becomes 8.72. Breakdown point of mean value is 0.
Another limiting case is median. Median of the above sample is -0.3. If we change one value and make it extremely large then median will not change much. For example if we change the last value to -100 then median will become -0.5. Breakdown point for median is 0.5, i.e. more than 50% of the sample should be changed arbitrarily to change the median arbitrarily. Breakdown point 0.5 is the theoretical limit.
Efficiency of estimators with high breakdown point is usually worse than those with lower breakdown point. In other words variances of estimators with high breakdown point are larger.

Outliers and regression
Let us remind us the form of the least-squares equations for regressions. Again x is a vector of input (predictor) parameters, β is a vector of parameters, y is output, the number of sample points is n.
As we know in special case when g(β,x) =β, and β is a single value then least-squares estimation gives mean value of y. We can consider above estimation as an extension of mean value estimation. Breakdown point of this estimation is 0, so least-squares is very sensitive to outliers.
There are several approaches to deal with outliers in regression analysis. We will consider only two of them: 1) least-trimmed squares; 2) M-estimators
€
(y i − g(x i,β ))2
i=1
n
∑ ==> min
Regression: no outliers
Regression: with an outlier
Outlier

Least trimmed squaresLeast trimmed squares works iteratively.
1) Set up initial values for the model parameters (for example using simple least squares method implemented in lm)
2) Calculate squared residuals ri2=(yi-g(xi,β))2
3) Sort squared residuals
4) Remove fraction of observations for which squared residuals are large
5) Minimise least squares using these observations only
6) Repeat 2)-6) until convergence achieved.
The function lts in R does LTS and several others as a special case of LTS (least median and least quantile squares). The number of used residuals for different methods are different. For least-median it is [(n+1)/2], for least quantile [(n+p+1)/2] and for LTS it is [n/2]+[(p+1)/2], where [] is the integer part of the argument
The result of default lqs

Robust M-estimators
General extension of least-squares have the form:
Form the function ρ defines various forms of robust M-estimators. When ρ(z)=z2 it becomes simple least-squares.
Let us first analyse this function. To minimise this function let us use Gauss-Newton method. To use this method we need the first and second derivatives (more precisely an approximation for the second derivative)
Where ρ’, ρ’’ are the first and the second derivative of ρ. In Gauss-Newton methods the second term of the second derivative equation is usually ignored. Usually ρ’=ψ and ρ’’=w notations are used. If we look at the equations we can see that it looks like an extension of least-squares equations. The minimisation of the function is done iteratively using iteratively reweighted least squares (IRLS or IWLS).
ψ function is an influence function. Analysis of values of this function at the observations may help to understand outliers in the data and how are dealt with.
€
f (β ) = ρ (y i − g(x i,β )i=1
n
∑ ) ==> min
€
∂f
∂β= − ρ '(y i − g(x i,β ))
∂g
∂βi=1
n
∑
∂ 2 f
∂β T∂β= ρ ' '(y i − g(x i,β ))
∂g
∂β T
∂g
∂β+
i=1
n
∑ ρ '(y i − g(x i,β ))∂ 2g
∂β T∂βi=1
n
∑

Forms of robust regression
Robust M-estimators are usually chosen so that to make contribution of gradients for large residuals small, in other words to weight down large deviations. They can be chosen either using ρ or ψ.
Basic idea behind robust estimators is: For small deviations behaviour of the function should be similar to least squares and for large deviations contributions should be weighted down. Different functions differ by degree of weighting.
Example of ρ and ψ (Geman and Mcclure function)

Forms of robust regressionMost popular forms of robust estimators are:
1) Huber
1) Tukey’s bisquare
1) Geman and Mcclure
1) Welsch
2) t-distribution (actually it is a little bit modified form of –log t distribution)
€
ρ(x) =x 2 /2, | x |< k
k(| x | −k
2 otherwise
⎧
⎨ ⎪
⎩ ⎪
€
ρ(x) =x 2
c 2 + x 2
€
ρ(x) =c 2
2(1− e−x 2 / c 2
)
€
ρ(x) =c 2
2log(1+ x 2 /c 2)
€
ρ(x) =c 2
6(1− (1− (
x
c)2)2) | x |≤ c
c 2 /6 otherwise
⎧
⎨ ⎪
⎩ ⎪

Robust estimators
The result of robust regression with Huber function is very good. In practice choice of the function will depend on the number and severity of outliers.

Robust estimators: Dagnostic plots
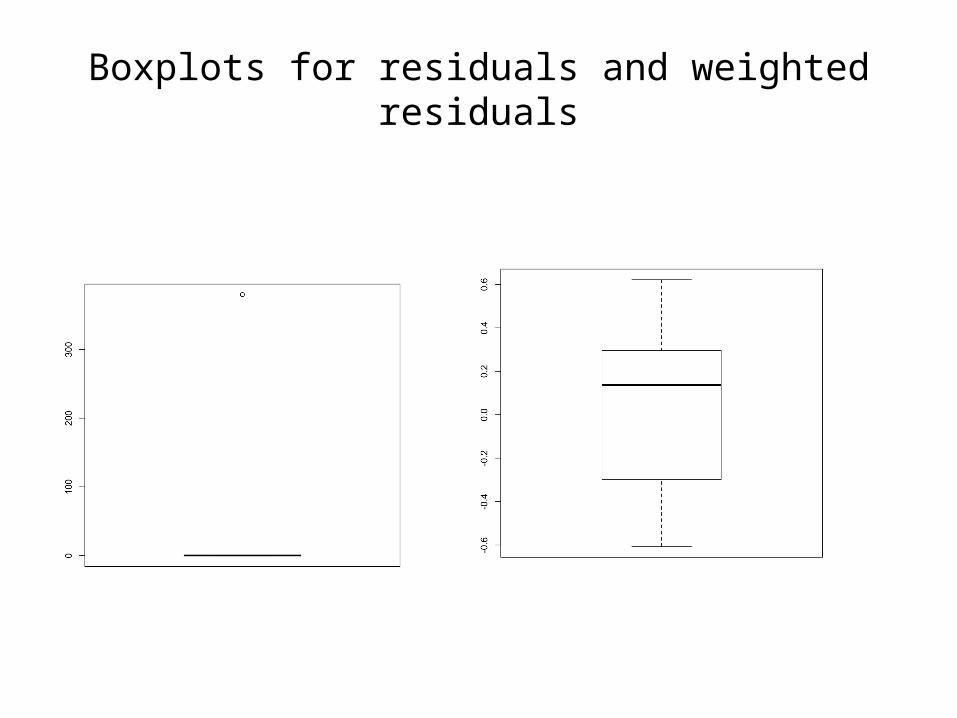
Boxplots for residuals and weighted residuals

R commands for robust estimation
lqs – least trimmed, least median estimation
rlm – robust linear model estimation using M-estimator
outliers package may be helpful.

References
1) P. J. Huber (1981) “Robust Statistics”.
2) F. R. Hampel, E. M. Ronchetti, P. J. Rousseeuw and W. A. Stahel (1986) “Robust Statistics: The Approach based on Influence Functions”
3) A. Marazzi (1993) “Algorithms, Routines and S Functions for Robust Statistics”,
4) W. N. and Ripley, B. D. (2002) “Modern Applied Statistics with S”
















