RepliX: Um Mecanismo para a Replicac ¸˜ ao de Dados XML Fl´ avio R. C. Sousa, Heraldo J. A. Carneiro Filho, Rossana M. C. Andrade, Javam C. Machado 1 Grupo de Redes, Engenharia de Software e Sistemas (GREat) Universidade Federal Cear´ a (UFC) Fortaleza – CE – Brasil {flavio,heraldo}@great.ufc.br,{rossana,javam}@ufc.br Abstract. XML has become a widely used standard for data exchange in ap- plications. Native XML DBMS are being developed to manage this data type. Such systems implement several characteristics that are common to traditional database systems. However, few of them provide replication mechanisms. The group communication abstraction is an efficient technology for implementing re- plication protocols since it provides reliability guarantees. This paper presents RepliX, a mechanism for XML data replication based on group communication. In order to evaluate RepliX, experiments measuring performance and availabi- lity were conducted. Resumo. XML tem se tornado um padr˜ ao amplamente utilizado na troca de dados entre aplicac ¸˜ oes. Para gerenciar esses dados, est˜ ao sendo desenvolvi- dos SGBDs XML Nativos. Esses sistemas implementam diversas caracter´ ısticas de sistemas tradicionais. Contudo, poucos deles possuem mecanismos de replicac ¸˜ ao. A abstrac ¸˜ ao de comunicac ¸˜ ao em grupos ´ e uma tecnologia eficiente para implementar protocolos de replicac ¸˜ ao, pois provˆ e garantias de confiabili- dade. Este artigo apresenta o RepliX, um mecanismo para replicac ¸˜ ao de dados XML baseado em comunicac ¸˜ ao em grupos. Visando avaliar o RepliX, alguns experimentos que medem o desempenho e a disponibilidade s˜ ao apresentados. 1. Introduc ¸˜ ao XML [W3C 2007] tem se tornado um padr˜ ao amplamente utilizado na representac ¸˜ ao e troca de dados em aplicac ¸˜ oes. Devido a essa crescente utilizac ¸˜ ao do XML, torna-se ne- cess´ aria a existˆ encia de sistemas eficientes de armazenamento e recuperac ¸˜ ao de dados nesse formato. Para isso, est˜ ao sendo propostos e implementados SGBDs XML Na- tivos (SGBDXNs) [Jagadish et al. 2002]. SGBDXNs s˜ ao sistemas que armazenam do- cumentos XML segundo uma estrutura l´ ogica de grafo, onde os n´ os representam ele- mentos e atributos e as arestas definem os relacionamentos elemento/sub-elemento ou elemento/atributo. Esses bancos implementam muitas das caracter´ ısticas presentes em sistemas tradicionais, tais como armazenamento, indexac ¸˜ ao, processamento de consultas, transac ¸˜ oes e replicac ¸˜ ao. T´ ecnicas de replicac ¸˜ ao de dados tˆ em sido usadas para melhorar a disponibilidade, o desempenho e a escalabilidade em SGBDs tradicionais, tais como os relacionais, e aqueles orientados a objetos [Gray et al. 1996]. Todavia, a flexibilidade dos dados XML imp˜ oe novos desafios, de modo que novas t´ ecnicas de replicac ¸˜ ao devem ser desenvolvidas. Propostas atuais para replicac ¸˜ ao de dados XML tentam adaptar os conceitos existentes ao XXII Simpósio Brasileiro de Banco de Dados SBBD 2007 53
Transcript
RepliX: Um Mecanismo para a Replicacao de Dados XML
Flavio R. C. Sousa, Heraldo J. A. Carneiro Filho,Rossana M. C. Andrade, Javam C. Machado
1Grupo de Redes, Engenharia de Software e Sistemas (GREat)Universidade Federal Ceara (UFC) Fortaleza – CE – Brasil
Abstract. XML has become a widely used standard for data exchange in ap-plications. Native XML DBMS are being developed to manage this data type.Such systems implement several characteristics that are common to traditionaldatabase systems. However, few of them provide replication mechanisms. Thegroup communication abstraction is an efficient technology for implementing re-plication protocols since it provides reliability guarantees. This paper presentsRepliX, a mechanism for XML data replication based on group communication.In order to evaluate RepliX, experiments measuring performance and availabi-lity were conducted.
Resumo. XML tem se tornado um padrao amplamente utilizado na troca dedados entre aplicacoes. Para gerenciar esses dados, estao sendo desenvolvi-dos SGBDs XML Nativos. Esses sistemas implementam diversas caracterısticasde sistemas tradicionais. Contudo, poucos deles possuem mecanismos dereplicacao. A abstracao de comunicacao em grupos e uma tecnologia eficientepara implementar protocolos de replicacao, pois prove garantias de confiabili-dade. Este artigo apresenta o RepliX, um mecanismo para replicacao de dadosXML baseado em comunicacao em grupos. Visando avaliar o RepliX, algunsexperimentos que medem o desempenho e a disponibilidade sao apresentados.
1. IntroducaoXML [W3C 2007] tem se tornado um padrao amplamente utilizado na representacao etroca de dados em aplicacoes. Devido a essa crescente utilizacao do XML, torna-se ne-cessaria a existencia de sistemas eficientes de armazenamento e recuperacao de dadosnesse formato. Para isso, estao sendo propostos e implementados SGBDs XML Na-tivos (SGBDXNs) [Jagadish et al. 2002]. SGBDXNs sao sistemas que armazenam do-cumentos XML segundo uma estrutura logica de grafo, onde os nos representam ele-mentos e atributos e as arestas definem os relacionamentos elemento/sub-elemento ouelemento/atributo. Esses bancos implementam muitas das caracterısticas presentes emsistemas tradicionais, tais como armazenamento, indexacao, processamento de consultas,transacoes e replicacao.
Tecnicas de replicacao de dados tem sido usadas para melhorar a disponibilidade,o desempenho e a escalabilidade em SGBDs tradicionais, tais como os relacionais, eaqueles orientados a objetos [Gray et al. 1996]. Todavia, a flexibilidade dos dados XMLimpoe novos desafios, de modo que novas tecnicas de replicacao devem ser desenvolvidas.Propostas atuais para replicacao de dados XML tentam adaptar os conceitos existentes ao
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
53
modelo XML [Tamino 2007] [X-Hive 2007] [eXist 2007]. Contudo, poucos SGBDXNsfornecem mecanismos de replicacao e nao existem estudos que avaliem explicitamenteaspectos de desempenho, escalabilidade e disponibilidade desses mecanismos.
Dentre varios tipos de protocolos de replicacao, a abstracao de comunicacaoem grupos (CG) e uma tecnologia eficiente para implementar esses protocolos, poisprove garantias de confiabilidade que simplificam a aplicacao de tecnicas de toleranciaa falhas [Birman 2005]. Primitivas de comunicacao em grupo tem sido aplicadas comeficiencia nesses protocolos, tanto em abordagens sıncronas [Wu and Kemme 2005] comoassıncronas [Pacitti et al. 2005].
Este artigo apresenta o RepliX, um mecanismo para a replicacao de dadosXML, que combina protocolos sıncronos, assıncronos, primitivas de CG e contem-pla caracterısticas dos dados XML. Este trabalho estende nossa abordagem preliminar[Sousa et al. 2007], onde descrevemos suas definicoes iniciais e apresentamos experi-mentos referentes a aspectos de desempenho e escalabilidade. Neste artigo, alem des-ses aspectos, abordamos a disponibilidade, de forma a melhorar o tempo de resposta noprocessamento de consultas e tornar os SGBDXNs tolerantes a falhas.
Este artigo esta organizado da seguinte forma. A secao 2 apresenta, resumida-mente, os conceitos basicos relacionados a este trabalho. Na secao 3, o RepliX e apresen-tado e seus algoritmos sao discutidos. Varios testes de desempenho e disponibilidade doRepliX sao apresentados na secao 4. A secao 5 comenta sobre os trabalhos relacionadose, finalmente, a secao 6 contem as conclusoes.
2. Conceitos Basicos
2.1. Gerenciamento de Dados XML
A flexibilidade de representacao de dados XML dificulta a verificacao de tipos dessesdocumentos e consequentemente o seu tratamento tanto no armazenamento como no pro-cessamento desses dados. O gerenciamento de dados XML e complexo. Isso se deveprincipalmente as seguintes caracterısticas: (i) modelo de dados - documentos XML saorepresentados por um modelo de dados baseado em grafo, o que adiciona maior comple-xidade a sua estrutura (ii) heterogeneidade - um documento XML pode ter um mesmosub-elemento omitido ou repetido varias vezes.
Com relacao ao processamento de consultas, o modelo XML ainda nao dispoe deuma algebra padrao. Assim sendo, o W3C desenvolveu uma semantica formal para aslinguagens XPath e XQuery. Essa semantica possibilita a identificacao de ambiguidadesna linguagem e auxilia na verificacao formal. Contudo ela e complexa e dificulta, porexemplo, a decomposicao de consultas.
Os protocolos para controle de concorrencia a dados XML ainda apresentamlimitacoes, e a maioria das solucoes existentes proporcionam um baixo nıvel de con-correncia. Alguns protocolos sao baseados em bloqueios hierarquicos em arvores[Dekeyser and Hidders 2004], e esses bloqueios ocorrem de forma top-down, ou seja,os nos desde o ponto inicial da consulta ate o final do documento sao bloquea-dos, dificultando a execucao de consultas. Protocolos baseados no modelo DOM[Haustein and Harder 2004] [Helmer et al. 2004] utilizam diferentes tipos de bloqueio
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
54
para agrupar nos de nıveis distintos, apresentando resultados satisfatorios com operacoessobre o modelo DOM, mas sendo poucos eficazes em linguagens como a XQuery.
Os protocolos baseados em bloqueios de caminho aumentam a concorrencia[Jea et al. 2002]. Entretanto, esses protocolos utilizam um subconjunto muito limitadoda linguagem XPath e metodos dispendiosos para determinar conflitos entre consultascomplexas, que inviabilizam sua aplicacao em sistemas praticos. Alguns protocolos[Grabs et al. 2002] [Pleshachkov 2006] utilizam estruturas como o DataGuide para ge-renciar o acesso aos dados e apresentam melhores resultados.
Em relacao a fragmentacao ou particionamento de dados XML, os trabalhos exis-tentes tentam adaptar as tecnicas dos sistemas tradicionais para solucionar esse problema.Alguns destes trabalhos fragmentam o documento XML e utilizam estruturas como DTDpara auxiliar na decomposicao [Ma and Schewe 2003]. Outros fragmentam colecoes dedocumentos baseado em um esquema [Andrade et al. 2006]. Mais detalhes podem serobtidos em [Sousa 2007].
2.2. ReplicacaoReplicacao e um topico cada vez mais importante no contexto de SGBDs e serve sobre-tudo para aumentar a disponibilidade do sistema em caso de falha, permitindo redirecionaros clientes para replicas operacionais [Gray et al. 1996]. Por outro lado, oferece tambemmelhorias na escalabilidade, ao permitir a execucao paralela de requisicoes de clientes nasdiferentes replicas, e, finalmente, pode permitir uma menor latencia no acesso, explorandoa localidade dos dados.
[Gray et al. 1996] classificaram os protocolos para replicacao de SGBDs usandodois parametros. O primeiro parametro estabelece a forma de propagacao dasmodificacoes, que pode ser sıncrona ou assıncrona. O segundo indica quem pode pro-pagar as atualizacoes: uma replica especıfica, chamada de copia primaria, ou qualqueruma das replicas, onde cada uma destas e denominada replica ativa.
Na forma sıncrona, quando uma replica e alterada, essa alteracao e imediatamenteaplicada as demais replicas dentro de uma transacao. SGBDs sıncronos tradicionalmenteutilizam o protocolo de two-phase commit (2PC) [Bernstein and Newcomer 1997]. Em[Gray et al. 1996] foi provado que o protocolo 2PC e impraticavel quando a quantidadede replicas e grande, pois o numero de aborts, deadlocks e mensagens trocadas crescede maneira exponencialmente proporcional ao numero de replicas. Na forma assıncrona,a alteracao de uma replica nao e propagada imediatamente, sendo realizada em um mo-mento posterior, dentro de uma transacao separada. A propagacao das atualizacoes podeser realizada de forma linear ou constante. A primeira consiste em enviar as atualizacoesa cada transacao. A segunda consiste em definir intervalos de tempo configuraveis parao envio das atualizacoes. Em geral, esse tipo de controle de consistencia e usado quandonao ha necessidade de se obter os dados totalmente atualizados.
No protocolo de copia primaria, uma das replicas e escolhida como copia oureplica primaria e as outras copias sao replicas secundarias. Essa copia primaria geren-cia as demais e envia ao cliente a resposta da operacao. Esse protocolo possui algumasdesvantagens como a necessidade de escolha de uma nova primaria, no caso de falha, etempos de respostas inaceitaveis, quando a primaria torna-se um gargalo, pois ela centra-liza todas as operacoes de atualizacao [Birman 2005].
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
55
No protocolo de replicas ativas, qualquer uma das replicas pode executaroperacoes de atualizacao [Bernstein and Newcomer 1997]. Essas operacoes sao execu-tadas na mesma sequencia por todas as replicas, produzindo resultados identicos. Esseprotocolo e tolerante a falhas, ja que nao existe uma copia primaria, e de apresentar melhordesempenho, pois varias replicas podem ser acessadas de forma concorrente. Uma des-vantagem desse protocolo e a necessidade de um mecanismo que assegure a consistenciaentre as replicas quando atualizacoes sao executadas.
3. RepliXO RepliX e um mecanismo para replicacao de dados XML que considera as principaislimitacoes no gerenciamento de dados XML, tais como complexidade de decomposicaodas linguagens de consulta, o controle de concorrencia e a fragmentacao. Alem disso, oRepliX nao possui os problemas dos protocolos tradicionais, tais como copia primaria ereplica ativa. Estendemos o protocolo PDBREP [Akal et al. 2005] de forma a contemplarcaracterısticas do modelo XML e adicionamos tecnicas para torna-lo tolerante a falhas. Ocriterio one-copy serializability [Bernstein and Newcomer 1997] e usado neste trabalhocomo modelo de corretude.
3.1. Arquitetura
O RepliX e dividido em alguns componentes de software que se comunicam entre si, im-plementando o mecanismo para replicacao em SGBDXNs. Uma visao geral da arquiteturado RepliX pode ser observada na Figura 1.
Figura 1. Arquitetura do RepliX
O RepliXDriver e o componente que permite o acesso ao mecanismo. Esse drivere uma interface simples para a execucao de transacoes, encapsulando as funcionalidadesdo RepliX e permitindo que o desenvolvedor se abstraia da sua arquitetura. O RepliXDri-ver possui metodos similares a API JDBC [Sun 2007], adaptado ao modelo XML.
O RepliXCoordinator e composto de tres partes: o escalonador, responsavel poridentificar o tipo das transacoes, o roteador, que decide onde as transacoes serao executa-das, e o balanceador, que realiza balanceamento de carga entre os SGBDXNs.
O RepliXNode e o componente acoplado a cada um dos SGBDXNs. Esse com-ponente acessa o banco e executa as transacoes solicitadas, repassando os resultados aoRepliXDriver que, por sua vez, repassa-os a aplicacao.
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
56
3.2. Especificacao
Seja um sistema composto por N sites (nos de rede com recursos computacionais), di-vididos em dois grupos distintos: grupo de leitura e grupo de atualizacao, que tratamtransacoes de leitura e atualizacao, respectivamente. O RepliX realiza a distincao entreas transacoes, classificando-as de acordo com o conteudo de suas operacoes. Transacoesque contenham apenas operacoes de leitura sao consideradas de leitura. Caso a transacaocontenha pelo menos uma operacao de modificacao (insercao, atualizacao ou remocao),ela e classificada como de atualizacao. Considerando que a quantidade de sites pode seralterada, ja que sites podem ser removidos ou adicionados, o conjunto N de sites nao efixo.
A estrategia de particionar os sites em grupos e um aspecto importante do RepliX.Essa abordagem visa melhorar o desempenho do sistema e diminuir conflitos duranteas operacoes de atualizacao, ja que o controle para concorrencia a dados XML aindaapresenta muitas limitacoes. Com essa estrategia, apenas uma parte dos sites precisa seratualizada a cada modificacao. Adotamos a replicacao total dos dados devido as carac-terısticas do modelo XML: complexidade da decomposicao de linguagens de manipulacaode dados XML, como a linguagem XQuery, e a fragmentacao de dados nesse formato.
Quando um cliente submete uma transacao, ele especifica se necessita executaroperacoes de atualizacao. Assim, o RepliX verifica o seu conteudo e a direciona paraum dos grupos. Caso a transacao seja direcionada para o grupo de atualizacao, um sitedeste grupo a recebe. Esse site e chamado de primario e e o responsavel por verificarconflitos com as demais transacoes que estao sendo executadas localmente e, em seguida,enviar um multicast com a propriedade de ordenacao total para os demais sites do grupo.Estes sites sao chamados de secundarios em relacao ao primario que enviou o multicaste realizam um teste de certificacao, que verifica se uma transacao local no primario estaem conflito com as demais transacoes em execucao nos secundarios. Esse teste garanteo criterio de serializabilidade: a transacao e abortada se a sua confirmacao gera estadoinconsistente no grupo de atualizacao. Se a transacao passa no teste de certificacao, entaoela e confirmada no grupo de atualizacao.
A Figura 2 exibe um exemplo do grupo de atualizacao. O site s2 e o site primariopara o cliente c1 e os sites s1 e s3 sao os secundarios. Ja o site s3 e o site primario paraos clientes c2 e c3 e os demais sites sao secundarios. Nesse exemplo, o site s1 atua comosecundario em relacao aos demais sites.
Figura 2. Grupo de Atualizacao
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
57
As transacoes executadas no grupo de atualizacao recebem um identificador unico,o que permite sua identificacao pelo RepliX. As modificacoes do grupo de atualizacao saoserializadas e enviadas continuamente pelo primario para o grupo de leitura atraves de ummulticast com a propriedade de ordenacao FIFO. Essas modificacoes sao adicionadas emfilas locais de cada site do grupo de leitura e executadas na mesma sequencia do grupo deatualizacao.
O grupo de leitura executa dois tipos de transacoes: propagacao e refresh.Transacoes de propagacao sao executadas durante o tempo ocioso de um site, ou seja,quando nao estao sendo executadas transacoes de leitura ou transacoes de refresh, com oobjetivo de efetivar as atualizacoes. Transacoes de refresh sao aplicadas para adicionar astransacoes contidas na fila local a um site do grupo de leitura.
Durante a execucao das transacoes de leitura em um determinado site, o RepliXgerencia as replicas atraves da aplicacao das transacoes de propagacao e de refresh. Casonovas modificacoes sejam adicionadas na fila local, o RepliX continua a execucao daconsulta nesse site e posteriormente executa uma transacao de propagacao, adicionandoo conteudo da fila ao banco de dados local. Quando uma nova transacao e direcionadapara esse site, o RepliX realiza as seguintes verificacoes: (i) se a nova transacao requisitadados que foram atualizados, uma transacao de refresh e executada, (ii) caso contrario, atransacao e executada sem a necessidade de transacoes de refresh ou propagacao.
A Figura 3 mostra um exemplo do grupo de leitura. O site s6 esta atendendo asrequisicoes dos clientes c4 e c6, que iniciou-se antes da transacao T1 enviada pelo grupode atualizacao. O site s5 esta tratando a requisicao do cliente c5, que se iniciou antesda transacao T2 e que recebeu a transacao de propagacao T1. Como o site s4 estavaocioso, ele ja aplicou as transacoes T1 e T2 e encontra-se atualizado. Para evitar conflitosdurante a execucao das transacoes de leitura e refresh, as de refresh bloqueiam os dados aserem modificados, utilizando um bloqueio compatıvel, chamado de bloqueio de refresh.Apesar de combinar protocolos sıncronos e assıncronos, da perspectiva do usuario, oRepliX funciona de forma sıncrona, pois os usuarios sempre acessam dados atualizados.
Figura 3. Grupo de Leitura
4. Algoritmos para Replicacao de Dados XMLEsta secao descreve os principais algoritmos do RepliX. O Algoritmo 1 e executado pelocomponente RepliXCoordinator. Ao receber uma transacao (l. 3), esse componente ana-lisa suas operacoes (l. 4) para, em seguida, encaminha-la a um dos sites do grupo apropri-ado. O coordenador gerencia os sites de cada um dos dois grupos e utiliza um algoritmoround-robin para escolher o site que recebera a transacao, com o objetivo de distribuir a
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
58
carga entre os sites. Esse algoritmo esta implementado para o grupo de atualizacao (l. 5a 8) e para o de leitura (l. 10 a 13). Se a transacao contem operacoes de atualizacao, oproximo site do grupo de atualizacao e escolhido (l. 5) e a variavel que indica o numero doproximo site de escrita e incrementada (l. 6). Em seguida, o coordenador envia a transacaoao site escolhido que a executa localmente e retorna um objeto remoto correspondente atransacao iniciada (l. 7). O coordenador, entao, retorna esse objeto ao cliente (l. 8) quepode utiliza-lo para examinar os resultados da transacao e fazer um commit ou abort. Nocaso de uma transacao de leitura (l. 9), o processo ocorre de maneira semelhante (l. 10 a13).
Algorithm 1 - Procedimento executado pelo coordenador1: procedure processar transacoes2: loop3: transacao← coordenador.receber transacao();4: if transacao contem operacao de atualizacao then5: site← coordenador.get site(coordenador.numero site escrita);6: coordenador.numero site escrita← coordenador.numero site escrita + 1;7: transacao remota← site.begin(transacao);8: return transacao remota;9: else
10: site← coordenador.get site(numero site leitura);11: coordenador.numero site leitura← coordenador.numero site leitura + 1;12: transacao remota← site.begin(transacao);13: return transacao remota;14: end if15: end loop
16: end procedure
As operacoes realizadas pelo site primario sao mostradas no Algoritmo 2. Osite primario recebe continuamente mensagens enviadas por seus clientes (l. 3). Nasmensagens de begin (l. 4), a transacao e iniciada no banco de dados local (l. 5), sendoexecutadas suas operacoes e os resultados retornados ao cliente (l. 6). Quando o clienterequisita o commit da transacao (l. 7), as operacoes de atualizacao (write set) da transacaosao enviados aos outros sites do grupo de atualizacao (sites secundarios) utilizando umaprimitiva de ordenacao total do sistema de CG (l. 8). Em seguida, o site primario aguardaas confirmacoes dos testes de certificacao executados nos sites secundarios da visao atual(l. 9). Se ocorrerem conflitos no teste de certificacao (l. 10), o site primario envia ummulticast com a mensagem de abort para os sites secundarios (l. 11). Caso nao ocorramconflitos, e feito um multicast aos sites secundarios para que estes realizem o commit datransacao nos bancos de dados locais (l. 13). Na sequencia, o site primario faz o commitlocalmente (l. 15) e envia o write set da transacao aos sites do grupo de leitura (l. 16).Posteriormente, os sites de leitura efetivarao essas modificacoes em seus bancos de dadoslocais.
O Algoritmo 3 descreve o comportamento dos sites secundarios. Ao receber umamensagem enviada pelo primario (l. 3), caso a mensagem contenha um write set (l. 4),e executado um teste de certificacao (l. 5) para verificar se as atualizacoes conflitamcom alguma transacao em execucao e, em caso negativo, e enviada uma mensagem deconfirmacao ao site primario (l. 6). Os sites que nao responderam, por motivos de falha nosite ou de comunicacao, sao excluıdos do grupo e podem ser reintegrados posteriormente.Se a mensagem recebida for de commit (l. 7), uma transacao e iniciada no banco de dadoslocal (l. 8) e as operacoes do write set recebido anteriormente sao executadas (l. 9). Em
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
59
Algorithm 2 - Procedimento executado pelo site primario1: procedure processar transacoes2: loop3: msg ← site primario.receber mensagem();4: if msg.tipo = BEGIN then5: site primario.begin();6: resultados← site primario.execute(msg.transacao, msg.operacoes);7: else if msg.tipo = COMMIT then8: site primario.multicast(grupo atualizacao, msg.transacao, WRITE SET );9: site primario.esperar confirmacao certificacao();
10: if encontrou conflito nas certificacoes then11: site primario.multicast(grupo atualizacao, msg.transacao, ABORT );12: else13: site primario.multicast(grupo atualizacao, msg.transacao, COMMIT );14: end if15: primario.commit();16: primario.multicast(grupo leitura, msg.transacao, WRITE SET );17: end if18: end loop
19: end procedure
seguida, o commit da transacao e feito (l. 10). Se a mensagem recebida for de abort (l.12), o site secundario aborta a transacao (l. 12).
Algorithm 3 - Procedimento executado pelos sites secundarios1: procedure receber transacoes2: loop3: msg ← site secundario.receber mensagem();4: if msg.tipo = WRITE SET then5: resultado← site secundario.teste de certificacao(msg.operacoes);6: return resultado;7: else if msg.tipo = COMMIT then8: site secundario.begin();9: site secundario.execute(msg.transacao, msg.write set);
10: site secundario.commit();11: else if msg.tipo = ABORT then12: site secundario.abort(msg.transacao);13: end if14: end loop
15: end procedure
O Algoritmo 4 mostra o teste de certificacao utilizado no site secundario. Esseteste verifica conflitos entre as transacoes, comparando seus read sets e write sets (l. 3 a5). Depois do teste de certificacao, a transacao e confirmada, abortando transacoes locais(nos sites secundarios) em execucao que estao em conflito com a transacao enviada peloprimario.
O Algoritmo 5 descreve o comportamento dos sites de leitura. O site de leiturarecebe mensagens (l. 3) de clientes ou do grupo de atualizacao. Ao receber mensagensde begin (l. 4), provenientes de clientes, a fila e inspecionada, verificando se existemmodificacoes pendentes recebidas do grupo de atualizacao a serem efetivadas (l. 5). Emcaso positivo, os itens de dados do site a serem atualizados sao bloqueados (l. 6), ouseja, esses itens de dados nao podem ser acessados por outras transacoes ate que sejamdesbloqueados, para a execucao de uma transacao de refresh (l. 7) com as atualizacoespresentes na fila. Esse e o bloqueio de refresh. Ao final da execucao, os dados do sitesao desbloqueados (l. 8). Em seguida, a transacao e iniciada no banco de dados local (l.10), suas operacoes sao executadas dentro da transacao iniciada (l. 11) e os resultados
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
60
Algorithm 4 - Procedimento do teste de certificacao1: procedure teste de certificacao2: for transacoes em site secundario do3: if (operacoes.read set = transacoes.operacoes.write set) or4: (operacoes.write set = transacoes.operacoes.read set) or5: (operacoes.write set = transacoes.operacoes.write set) then6: return falso;7: end if8: end for9: return true;
10: end procedure
retornados ao cliente (l. 12). Caso a mensagem seja de atualizacao (l. 13), originada deum dos sites do grupo de atualizacao, o write set recebido e colocado no fim da fila do sitede leitura (l. 14) para, posteriormente, ser efetivado atraves de uma transacao de refreshou de propagacao.
Algorithm 5 - Procedimento executado pelos sites de leitura1: procedure processar transacoes2: loop3: msg ← site leitura.receber mensagem();4: if msg.tipo = BEGIN then5: if fila esta vazia then6: site leitura.bloquear(msg.itens de dados);7: site leitura.executar transacao refresh(fila);8: site leitura.desbloquear(msg.itens de dados);9: end if
10: site leitura.begin();11: resultado← site leitura.execute(msg.operacoes);12: return resultados;13: else if msg.tipo = ATUALIZACAO then14: fila.adicionar(msg.write set);15: end if16: while site leitura esta ocioso do17: if fila esta vazia then18: site leitura.bloquear(msg.itens de dados);19: site leitura.executar transacao propagacao(fila);20: site leitura.desbloquear(msg.itens de dados);21: end if22: end while23: end loop
24: end procedure
Nos momentos em que o site se encontra ocioso (l. 16), isto e, nao esta executandonenhuma transacao, e verificado se existem atualizacoes pendentes na fila (l. 17). Casoexistam, os itens de dados a serem atualizados sao bloqueados (l. 18), e uma transacaode propagacao com as alteracoes contidas na fila e executada (l. 19). Os itens de dadossao bloqueados para impedir que novas transacoes sejam executadas antes da transacaode propagacao terminar, impedindo que aquelas vejam dados desatualizados. Ao final daexecucao, os itens de dados do site sao desbloqueados (l. 20) e este esta disponıvel paraexecutar as transacoes pendentes.
5. AvaliacaoA avaliacao deste trabalho busca analisar o desempenho e a disponibilidade proporcio-nada pelo RepliX. Devido as interfaces e as linguagens de acesso aos SGBDXNs, torna-se complexo desenvolver experimentos apropriados para verificar o desempenho desses
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
61
sistemas. Nesse sentido, varios benchmarks para dados XML foram propostos, tais comoos apresentados em [Schmidt et al. 2002][Yao et al. 2004]. Recentemente tem sido pro-postas operacoes de atualizacao para a linguagem XQuery, entretanto, os benchmarks, emgeral, possuem suporte apenas a operacoes de leitura [Lu et al. 2005].
Para permitir a execucao do teste de certificacao, modificamos o SGBDXN Sedna[Fomichev et al. 2006], versao 1.0, adicionando suporte para a deteccao de conflito en-tre transacoes. Visando melhorar o controle de concorrencia, implementamos o bloqueiodos itens de dados de acordo com o protocolo proposto por [Pleshachkov 2006]. O sis-tema de comunicacao de grupos Spread, versao 4.0, [Spread 2007] foi utilizado para pro-ver a comunicacao. Para a geracao da base de dados, estendemos o benchmark XMark[Schmidt et al. 2002] adicionando operacoes de atualizacao [Sousa 2007], de acordo comobservacoes feitas por [Pleshachkov 2006], de forma a viabilizar a execucao de experi-mentos. Esses sistemas tem codigo aberto, podendo ser alterados e distribuıdos com asalteracoes.
5.1. Ambiente
Assumimos um conjunto de sites S={S1...SN}. Cada site Si possui um SGBD e estecontem uma copia completa da base de dados, realizando o gerenciamento das transacoeslocalmente. O banco assegura as propriedades ACID na execucao das transacoes locaise utiliza o protocolo 2PL para garantir o controle de concorrencia. Consideramos umconjunto de clientes C={C1...CM}, que sao a origem das transacoes. Para processar umatransacao t, um cliente C conecta-se ao RepliX e submete a transacao t ao RepliX querepassa t ao site Si. Para cada transacao t, somente um site Si a recebe. No grupo deatualizacao, esse site e o primario. A concorrencia de transacoes e simulada usandomultiplos clientes.
Para gerar a carga a ser executada pelo sistema replicado, desenvolvemos um si-mulador de clientes. Esse simulador gera as transacoes de acordo com certos parametros,envia para o RepliX e coleta os resultados ao final da cada execucao. O ambiente utilizadopara a avaliacao foi um cluster de 11 PCs conectados atraves de um Hub Ethernet. CadaPC possui um processador de 3.0 GHz, 1 GB de RAM, sistema operacional WindowsXP e interface de rede full-duplex de 100 Mbit/s. O grupo de atualizacao foi compostopor 3 PCs (sites). Cada transacao foi composta por 10 operacoes. A base de dados e umdocumento XML de 10 MB, gerado pelo XMark.
5.2. Experimentos
Cada experimento explora um aspecto diferente de um SGBD replicado, tais como tempode resposta, throughput ou vazao, escalabilidade, proporcao de atualizacoes e disponibi-lidade. A comparacao foi feita entre o banco Sedna convencional e o RepliX acoplado aoSedna. Nos experimentos, cada cliente submete 100 transacoes, sendo 80% das transacoesde leitura. Para evitar que atrasos na inicializacao do RepliX viessem a interferir nos re-sultados, as medidas iniciais obtidas das transacoes executadas (10%) foram descartadas,considerando os valores posteriores, o que torna os experimentos mais proximos de umambiente real.
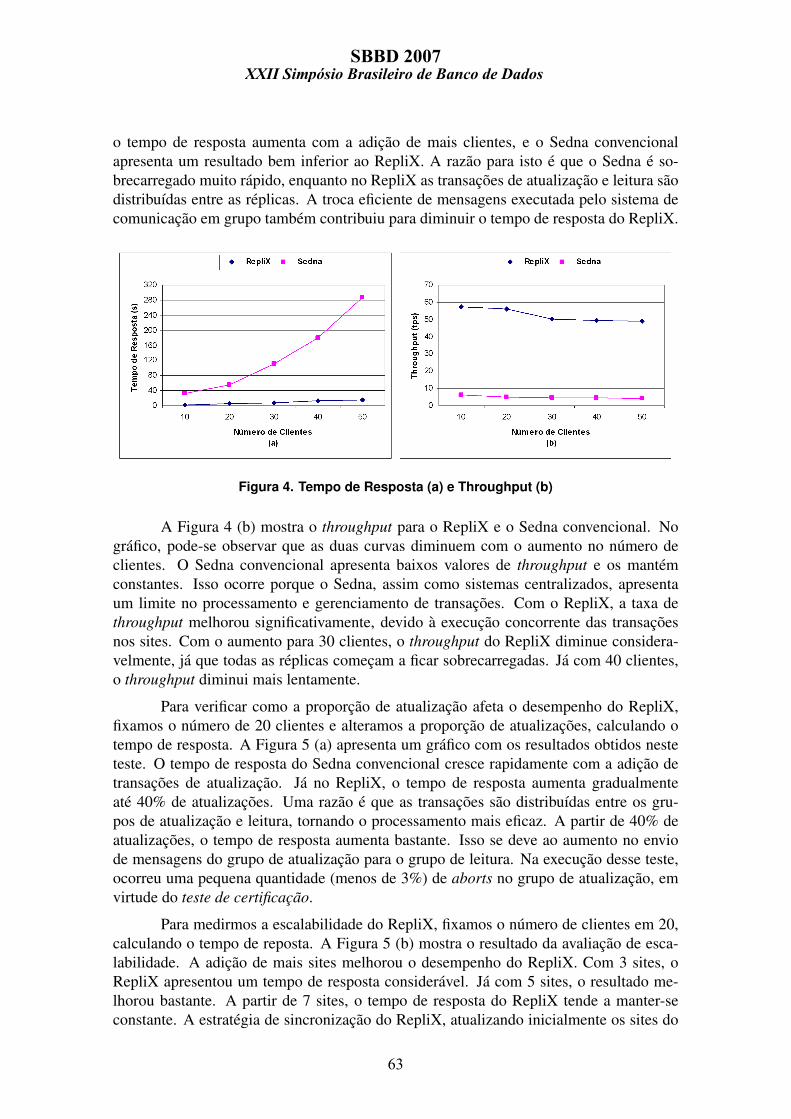
Para medir o desempenho do RepliX, foram considerados dois ındices: o tempode resposta e o throughput. A Figura 4 (a) mostra o tempo medio de resposta. No grafico,
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
62
o tempo de resposta aumenta com a adicao de mais clientes, e o Sedna convencionalapresenta um resultado bem inferior ao RepliX. A razao para isto e que o Sedna e so-brecarregado muito rapido, enquanto no RepliX as transacoes de atualizacao e leitura saodistribuıdas entre as replicas. A troca eficiente de mensagens executada pelo sistema decomunicacao em grupo tambem contribuiu para diminuir o tempo de resposta do RepliX.
Figura 4. Tempo de Resposta (a) e Throughput (b)
A Figura 4 (b) mostra o throughput para o RepliX e o Sedna convencional. Nografico, pode-se observar que as duas curvas diminuem com o aumento no numero declientes. O Sedna convencional apresenta baixos valores de throughput e os mantemconstantes. Isso ocorre porque o Sedna, assim como sistemas centralizados, apresentaum limite no processamento e gerenciamento de transacoes. Com o RepliX, a taxa dethroughput melhorou significativamente, devido a execucao concorrente das transacoesnos sites. Com o aumento para 30 clientes, o throughput do RepliX diminue considera-velmente, ja que todas as replicas comecam a ficar sobrecarregadas. Ja com 40 clientes,o throughput diminui mais lentamente.
Para verificar como a proporcao de atualizacao afeta o desempenho do RepliX,fixamos o numero de 20 clientes e alteramos a proporcao de atualizacoes, calculando otempo de resposta. A Figura 5 (a) apresenta um grafico com os resultados obtidos nesteteste. O tempo de resposta do Sedna convencional cresce rapidamente com a adicao detransacoes de atualizacao. Ja no RepliX, o tempo de resposta aumenta gradualmenteate 40% de atualizacoes. Uma razao e que as transacoes sao distribuıdas entre os gru-pos de atualizacao e leitura, tornando o processamento mais eficaz. A partir de 40% deatualizacoes, o tempo de resposta aumenta bastante. Isso se deve ao aumento no enviode mensagens do grupo de atualizacao para o grupo de leitura. Na execucao desse teste,ocorreu uma pequena quantidade (menos de 3%) de aborts no grupo de atualizacao, emvirtude do teste de certificacao.
Para medirmos a escalabilidade do RepliX, fixamos o numero de clientes em 20,calculando o tempo de reposta. A Figura 5 (b) mostra o resultado da avaliacao de esca-labilidade. A adicao de mais sites melhorou o desempenho do RepliX. Com 3 sites, oRepliX apresentou um tempo de resposta consideravel. Ja com 5 sites, o resultado me-lhorou bastante. A partir de 7 sites, o tempo de resposta do RepliX tende a manter-seconstante. A estrategia de sincronizacao do RepliX, atualizando inicialmente os sites do
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
63
Figura 5. Proporcao de Atualizacoes (a) e Escalabilidade (b)
grupo de atualizacao e difundindo as modificacoes, diminui o problema de sincronizartodas as replicas a cada atualizacao, o que favorece a escalabilidade.
Para analisar a disponibilidade do RepliX, foram realizados dois experimentosnos quais foram provocadas sucessivas falhas em uma instancia no grupo de replicacao,enquanto eram realizadas requisicoes ao RepliX de forma contınua. Fixamos o numerode clientes em 20. No primeiro experimento, configuramos para que um site funcionassecorretamente por 5 minutos e, decorrido esse tempo, interrompesse a execucao por umminuto. Esse experimento foi realizado por um perıodo de 3 horas para cada quantidadede sites, calculando-se o tempo de resposta. A Figura 6 (a) mostra o comportamento doRepliX. Por exemplo, com 3 sites, houve somente 2,4% de aumento no tempo de respostadas requisicoes. A adicao de mais sites melhorou a disponibilidade, ja que um numeromenor de requisicoes sofre falha e precisa ser direcionada para outro site.
Figura 6. Disponibilidade com Falhas Programadas (a) e Falhas Constantes (b)
No segundo experimento, mostrado na Figura 6 (b), adicionamos uma falha cons-tante em um dos sites, ou seja, esse site nao responde a requisicoes e nao se recupera,permanecendo com falha durante todo o experimento. O tempo de resposta diminuiem comparacao com a execucao do RepliX sem a presenca de falhas, mas manteve-seaceitavel. No pior caso, na configuracao com falha e 3 sites, o RepliX e apenas 6,2% maislento que na configuracao sem falha. Nos dois experimentos, nenhuma das requisicoes
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
64
dos clientes deixou de ser respondida pelo RepliX, mesmo com falhas sendo provocadasem um dos sites.
6. Trabalhos Relacionados
O eXist [eXist 2007] possui um mecanismo de replicacao baseado no sistema de CGJavaGroups para sincronizar as replicas. O eXist utiliza replicacao total dos dados etrabalha de acordo com o protocolo de copia primaria, propagando as alteracoes de formasıncrona. Quando uma operacao de atualizacao e enviada ao grupo de replicacao do eXist,este envia a atualizacao para a copia primaria e bloqueia as copias secundarias. Quando acopia primaria executa uma atualizacao, esta e propagada para as copias secundarias, queposteriormente sao desbloqueadas para executar as novas requisicoes.
O X-Hive [X-Hive 2007] apresenta um mecanismo baseado em copia primaria,executando as atualizacoes de forma assıncrona. As atualizacoes sao armazenadas emum log e enviadas posteriormente para as copias secundarias. Como as modificacoes saoexecutadas de forma assıncrona, as aplicacoes que acessam as copias secundarias podemler dados desatualizados.
O Tamino [Tamino 2007] permite a replicacao de duas formas: protocolo de copiaprimaria e protocolo 2PC. Quando o Tamino e configurado com o protocolo de copiaprimaria, a replicacao ocorre de forma similar ao banco X-Hive. No caso do protocolo2PC, a execucao e semelhante aos bancos tradicionais.
Apesar do eXist utilizar primitivas de CG, essas primitivas sao utilizadas apenaspara a troca confiavel de mensagens. O X-Hive e o Tamino aplicam tecnicas tradicio-nais para prover replicacao. Contudo, essas tecnicas nao atendem totalmente as neces-sidades para replicacao de dados XML. O protocolo de copia primaria utilizado pelosbancos eXist, X-Hive e Tamino nao e tolerante a falhas nem favorece a escalabilidade[Ozsu and Valduriez 1999]. Nenhum dos trabalhos relacionados estudados apresenta re-sultados que comprovem a eficiencia de seus mecanismos. Alem disso, as solucoes poreles apresentadas sao implementadas no nucleo dos SGBDs, dificultando a portabilidadedestas solucoes.
7. Conclusoes
Este trabalho apresentou o RepliX, um mecanismo de replicacao de dados XML quecombina protocolos sıncronos e assıncronos com primitivas de comunicacao em grupo deforma a permitir a replicacao eficiente de dados XML. Avaliou-se o RepliX considerandodiversas caracterısticas de replicacao. Pela analise dos resultados obtidos, foi possıvelverificar que o RepliX melhorou o desempenho e a disponibilidade do SGBDXN Sedna,mesmo em cenarios de replicacao com grande proporcao de atualizacoes.
Como trabalhos futuros, pretendemos realizar um estudo comparativo entre oRepliX e outros protocolos de replicacao, como o 2PC. Com a replicacao total de da-dos XML, identificamos que poucas caracterısticas desses dados sao utilizadas pelo Re-pliX. Assim sendo, outro aspecto importante e o desenvolvimento de estrategias para adecomposicao de consultas XQuery, fragmentacao e alocacao, o que permitara ao RepliXtrabalhar com replicacao parcial e, consequentemente, contemplar mais caracterısticasdos dados XML.
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
65
O RepliX foi validado com o SGBDXN Sedna. Entretanto, pode ser utilizado porqualquer SGBDXN, pois a unica modificacao necessaria no SGBDXN para a utilizacaodo RepliX e a deteccao de conflito entre transacoes. Pretendemos tambem avaliar oRepliX em ambientes de WAN com o intuito de identificar a variacao no tempo deresposta, adicionado em decorrencia da latencia da rede.
AgradecimentosOs autores agradecem ao ISPRAS (Institute for System Programming - Russian Academyof Sciences) pela colaboracao no desenvolvimento deste trabalho.
ReferenciasAkal, F., Turker, C., Schek, H.-J., Breitbart, Y., Grabs, T., and Veen, L. (2005). Fine-
grained replication and scheduling with freshness and correctness guarantees. In VLDB’05: Proceedings of the 31st international conference on Very large data bases, pages565–576.
Andrade, A., Ruberg, G., Baiao, F., Braganholo, V., and Mattoso, M. (2006). Effici-ently Processing XML Queries over Fragmented Repositories with PartiX. In EDBTWorkshops, volume 4254 of Lecture Notes on Computer Science, pages 150–163.
Bernstein, P. and Newcomer, E. (1997). Principles of transaction processing: for thesystems professional. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.
Birman, K. (2005). Reliable Distributed Systems: Technologies, Web Services, and Ap-plications. Hardcover.
Dekeyser, S. and Hidders, J. (2004). Conflict scheduling of transactions on XML docu-ments. In ADC ’04: Proceedings of the fifteenth conference on Australasian database,pages 93–101.
eXist (2007). eXist: Open Source Native XML Database. http://exist-db.org.
Fomichev, A., Grinev, M., and Kuznetsov, S. (2006). Sedna: A native xml dbms. InSOFSEM 2006, volume 3831 of Lecture Notes in Computer Science, pages 272–281.
Grabs, T., Bohm, K., and Schek, H.-J. (2002). Xmltm: efficient transaction managementfor xml documents. In CIKM ’02: Proceedings of the eleventh international conferenceon Information and knowledge management, pages 142–152.
Gray, J., Helland, P., O’Neil, P., and Shasha, D. (1996). The dangers of replication anda solution. In SIGMOD ’96: Proceedings of the 1996 ACM SIGMOD internationalconference on Management of data, pages 173–182, New York, NY, USA.
Haustein, M. P. and Harder, T. (2004). A Lock Manager for Collaborative Processing ofNatively Stored XML Documents. In XIX Simposio Brasileiro de Bancos de Dados,pages 230–244.
Helmer, S., Kanne, C.-C., and Moerkotte, G. (2004). Evaluating lock-based protocols forcooperation on XML documents. SIGMOD Rec., 33(1):58–63.
Jagadish, H. V., Al-Khalifa, S., Chapman, A., Lakshmanan, L. V. S., Nierman, A., Papa-rizos, S., Patel, J. M., Srivastava, D., Wiwatwattana, N., Wu, Y., and Yu, C. (2002).TIMBER: A native XML database. The VLDB Journal, 11(4):274–291.
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007
66
Jea, K.-F. J., Chen, S.-Y., and Wang, S.-H. (2002). Concurrency Control in XML Do-cument Databases: XPath Locking Protocol. In ICPADS ’02: Proceedings of the 9thInternational Conference on Parallel and Distributed Systems, pages 551–556.
Lu, H., Yu, J. X., Wang, G., Zheng, S., Jiang, H., Yu, G., and Zhou, A. (2005). Whatmakes the differences: benchmarking XML database implementations. ACM Trans.Inter. Tech., 5(1):154–194.
Ma, H. and Schewe, K.-D. (2003). Fragmentation of XML Documents. In XVIII SimposioBrasileiro de Bancos de Dados, pages 200–214.
Ozsu, M. T. and Valduriez, P. (1999). Principles of distributed database systems. Prentice-Hall, Inc.
Pacitti, E., Coulon, C., Valduriez, P., and Ozsu, M. T. (2005). Preventive Replication in aDatabase Cluster. Distrib. Parallel Databases, 18(3):223–251.
Pleshachkov, P. (2006). Transaction Management in XML Database Management Sys-tems. PhD thesis, Institute for System Programming of Russian Academy of Sciences,Russia.
Schmidt, A., Waas, F., Kersten, M. L., Carey, M. J., Manolescu, I., and Busse, R. (2002).Xmark: A benchmark for xml data management. In 28th International Conference onVery Large Data Bases, pages 974–985.
Sousa, F. R. C. (2007). RepliX: Um Mecanismo para a Replicacao de Dados XML.Master’s thesis, Universidade Federal do Ceara, Fortaleza, Brasil.
Sousa, F. R. C., Filho, H. J. A. C., and Machado, J. C. (2007). A New Approach toReplication of XML Data. In DEXA 2007: Proceedings of the 18th InternationalConference Database and Expert Systems Applications, volume 4653 of Lecture Notesin Computer Science, pages 141–150.
Spread (2007). The Spread Toolkit. http://www.spread.org.
Sun (2007). JDBC 4.0 API Specification. http://java.sun.com/jdbc.
Tamino (2007). Tamino XML Server. http://www.softwareag.com/tamino.
Wu, S. and Kemme, B. (2005). Postgres-R(SI): Combining Replica Control with Con-currency Control Based on Snapshot Isolation. In ICDE ’05: Proceedings of the 21stInternational Conference on Data Engineering, pages 422–433.
Yao, B. B., Ozsu, M. T., and Khandelwal, N. (2004). XBench Benchmark and Perfor-mance Testing of XML DBMSs. In ICDE ’04: Proceedings of the 20th InternationalConference on Data Engineering, page 621.
XXII Simpósio Brasileiro de Banco de DadosSBBD 2007