33


Report Documentation Page Form ApprovedOMB No. 0704-0188
Public reporting burden for the collection of information is estimated to average 1 hour per response, including the time for reviewing instructions, searching existing data sources, gathering andmaintaining the data needed, and completing and reviewing the collection of information. Send comments regarding this burden estimate or any other aspect of this collection of information,including suggestions for reducing this burden, to Washington Headquarters Services, Directorate for Information Operations and Reports, 1215 Jefferson Davis Highway, Suite 1204, ArlingtonVA 22202-4302. Respondents should be aware that notwithstanding any other provision of law, no person shall be subject to a penalty for failing to comply with a collection of information if itdoes not display a currently valid OMB control number.
1. REPORT DATE AUG 2010 2. REPORT TYPE
3. DATES COVERED 00-07-2010 to 00-00-2010
4. TITLE AND SUBTITLE CrossTalk. The Journal of Defense Software Engineering. Volume 23,Number 4, July/August 2010
5a. CONTRACT NUMBER
5b. GRANT NUMBER
5c. PROGRAM ELEMENT NUMBER
6. AUTHOR(S) 5d. PROJECT NUMBER
5e. TASK NUMBER
5f. WORK UNIT NUMBER
7. PERFORMING ORGANIZATION NAME(S) AND ADDRESS(ES) 517 SMXS MXDEA,6022 Fir Ave,Hill AFB,UT,84056-5820
8. PERFORMING ORGANIZATIONREPORT NUMBER
9. SPONSORING/MONITORING AGENCY NAME(S) AND ADDRESS(ES) 10. SPONSOR/MONITOR’S ACRONYM(S)
11. SPONSOR/MONITOR’S REPORT NUMBER(S)
12. DISTRIBUTION/AVAILABILITY STATEMENT Approved for public release; distribution unlimited
13. SUPPLEMENTARY NOTES
14. ABSTRACT
15. SUBJECT TERMS
16. SECURITY CLASSIFICATION OF: 17. LIMITATION OF ABSTRACT Same as
Report (SAR)
18. NUMBEROF PAGES
32
19a. NAME OFRESPONSIBLE PERSON
a. REPORT unclassified
b. ABSTRACT unclassified
c. THIS PAGE unclassified
Standard Form 298 (Rev. 8-98) Prescribed by ANSI Std Z39-18

2 CROSSTALK The Journal of Defense Software Engineering July/August 2010
4
8
14
23
28
31316222531
DeparDepar tmentstments
From the Sponsor
Call For Articles
SSTC 2010 Wrap-Up
Web Sites
Coming Events
BackTalk
Why Can’t We Manage Large Projects?Humphrey tries to answer one of software management’s biggestquestions, showing how one naval organization with large systemprojects, over a 15-year period, used the TSP to help them withplanning and tracking, meeting schedules, and understandingknowledge work.by Watts S. Humphrey
An Interview with Watts S. HumphreyWho else can boast more than a half-century in the software industry?Humphrey sits down with CrossTalk to reflect on some of his mostilluminating experiences in the software industry and discusses the past,present, and future of his innovations—including the TSP.
Updating the TSP Quality Plan Using Monte Carlo Simulation Quality planning is an important part of the TSP, and the author showshow the 309th Software Maintenance Group at Hill AFB applied MonteCarlo simulation to planning, adding to the understanding of variability,defects, and the overall process.by David R. Webb
Extending the TSP to Systems Engineering: Early Resultsfrom Team Process IntegrationThe SEI and NAVAIR have joined forces to create TPI, a concept thatleverages the PSP and TSP body of research and practice. This articlereports on the status, progress, lessons learned, and results from a TPIpilot project with the AV-8B Systems Engineering Team.by Anita Carleton, Del Kellogg, and Jeff Schwalb
Building Critical Systems as a Cyborg As outrageous as it may seem, adapting cybernetics to defense softwareis a real possibility in building complex software systems. Ball discussesthe history of cybernetics, what a “cyborg” really is, and how commercialopen-source adaptive technology is being used in the real world.by Greg Ball
Catching Catching UpUp WithWith TSPTSP
Cover Design byKent BinghamPhoto by Silar
ON THE COVER
CrossTalkOSD (AT&L)
NAVAIR
309 SMXG
DHS
MANAGING DIRECTOR
PUBLISHER
MANAGING EDITOR
ASSOCIATE EDITOR
ARTICLE COORDINATOR
PHONE
CrossTalk ONLINE
Stephen P.Welby
Jeff Schwalb
Karl Rogers
Joe Jarzombek
Brent Baxter
Kasey Thompson
Drew Brown
Chelene Fortier-Lozancich
Marek Steed
(801) [email protected]/crosstalk
CrossTalk,The Journal of Defense SoftwareEngineering is co-sponsored by the Office of theSecretary of Defense (OSD) Acquisition, Technologyand Logistics (AT&L); U.S. Navy (USN); U.S.Air Force(USAF); and the U.S. Department of HomelandSecurity (DHS). OSD (AT&L) co-sponsor: SoftwareEngineering and System Assurance. USN co-sponsor:Naval Air Systems Command. USAF co-sponsor:Ogden-ALC 309 SMXG. DHS co-sponsor: NationalCybersecurity Division in the National Protectionand Programs Directorate.
The USAF Software Technology SupportCenter (STSC) is the publisher of CrossTalk,providing both editorial oversight and technical reviewof the journal.CrossTalk’s mission is to encouragethe engineering development of software to improvethe reliability, sustainability, and responsiveness of ourwarfighting capability.
Subscriptions: Send correspondence concerningsubscriptions and changes of address to the followingaddress.You may e-mail us or use the form on p. 21.
517 SMXS/MXDEA6022 Fir AVEBLDG 1238Hill AFB, UT 84056-5820
Article Submissions:We welcome articles of interestto the defense software community. Articles must beapproved by the CROSSTALK editorial board prior topublication. Please follow the Author Guidelines, avail-able at <www.stsc.hill.af.mil/crosstalk/xtlkguid.pdf>.CROSSTALK does not pay for submissions. Publishedarticles remain the property of the authors and may besubmitted to other publications. Security agency releas-es, clearances, and public affairs office approvals are thesole responsibility of the author and their organizations.
Reprints: Permission to reprint or post articles mustbe requested from the author or the copyright hold-er and coordinated with CROSSTALK.
Trademarks and Endorsements:This Department ofDefense (DoD) journal is an authorized publicationfor members of the DoD. Contents of CROSSTALKare not necessarily the official views of, or endorsedby, the U.S. government, the DoD, the co-sponsors, orthe STSC.All product names referenced in this issueare trademarks of their companies.
CrossTalk Online Services: See <www.stsc.hill.af.mil/crosstalk>, call (801) 777-0857 or e-mail<[email protected]>.
Back Issues Available: Please phone or e-mail us tosee if back issues are available free of charge.
OpenOpen FForumorum

July/August 2010 www.stsc.hill.af.mil 3
From the Sponsor
If you’ve been involved with software and system processimprovement for even a short time, you’ve most likely experi-
enced the challenges associated with applying process methodolo-gies and tools to your real-life projects. For many, the realizationthat “one size does not fit all” can lead to frustration about howbest to tailor the processes and tools to fit real-life project needs.TSP is one process framework and toolkit helping teams improve software quality and
productivity. Thoughtfully marrying TSP application with your unique team, products, and goalscan put you on the path to meeting software cost and schedule commitments.
In my experience, the most valuable leg up for adopting TSP are TSP coaches, who focuson supporting the team (as well as individuals) to transition from workshop learning to practi-cal application. They play a huge role in motivating and guiding the team through their TSP jour-ney. Given the coaches’ first-hand TSP experience—and their in-depth knowledge and appreci-ation of the toolkit—they lend a supportive hand as the team tailors, monitors, learns, andgrows.
An example of TSP tailoring that can have powerful results is modifying role definitions.While TSP does define specific and meaningful roles, the assumption is that these roles can (andmay need to be) thoughtfully tailored. In considering how to apply the roles to your project, itis best to evaluate each role in the context of your team’s culture, size, and dynamics. Also, makean effort to align teammates to the roles based on the expectations for a specific role and theirunique capabilities. Just going through this effort to align roles with your team’s context andcharacteristics can lead to unexpected insights and learning.
Standard TSP application assumes that you are tracking a single product from start to finish.Since this is not always the case, think carefully about how best to apply the processes when mul-tiple efforts need to be completed in unison.
TSP offers a useful and free tool to gather and report metrics. This tool is most valuablewhen you take the time to understand how the metrics will be used in your larger project con-text. Based on your experiences, you may even be able to offer insights into how to make thetool more useful. For instance, based on user feedback that indicated a need for milestones tosupport parallel task execution, the tool now offers a single target data feature. With this feature,progress toward incremental milestones can be evaluated and understood.
While TSP is for software, it provides a construct for detailed planning and task allocationto any engineering effort or product. Basically, any task or group of tasks that can be brokendown into increments, activities, goals, and timelines can benefit from applying TSP. Again, it’sa matter of understanding your particular requirements and context, and determining how bestto integrate TSP capabilities.
And finally, to support your endeavors are the annual TSP user conferences, with the nextgathering in Pittsburgh September 20-23 (see <www.sei.cmu.edu/tspsymposium/2010>).These get-togethers provide a forum for open and honest dialogue about the “goods, bads, andothers” related to teams’ efforts to adopt TSP. These symposiums reinforce the culture and con-text you would expect to find in any authentic improvement and learning effort.
So the bottom line is that to be successful, no matter what approach you choose, means thatyou have to take the long-haul perspective and tailor, learn, grow, apply, and repeat as needed.Of course, it goes without saying that you will also need to factor in a healthy dose of relent-less patience.
TSP: Tailor ... Learn ... Grow ... Apply ...and, of Course, Repeat
Susan G. RaglinHead, Software/Systems Product Development & Integration Division
Naval Air Systems Command
CrossTalk wouldlike to thank NAVAIR
for sponsoringthis issue.

4 CROSSTALK The Journal of Defense Software Engineering July/August 2010
Catching Up With TSP
The Naval Oceanographic Office(NAVO) Systems Integration Divi-
sion began working with the SEI 15 yearsago. Their group produces software for arange of systems that supply oceano-graphic and meteorological data to theU.S. Navy’s worldwide fleet. These areenormous terabyte systems that operate24-7, and their subsystems provide criticaloperational information to almost everybranch of the Navy.
Ed Battle—branch head then, andnow Systems Integration Division direc-tor—recalled that when they started work-ing with the SEI, projects were always late,requirements were frequently misunder-stood or wrong, and there was no cooper-ation among the many interdependentgroups. When critical delivery datesapproached, the director tracked the workwith regular Monday, Wednesday, andFriday status meetings. While these meet-ings raised the pressure and took a lot oftime, they didn’t shed much light on pro-ject status.
Battle’s question to us at the SEI was:“Isn’t there a better way?”
The Large System ProblemThe problems Battle’s group faced are typ-ical. Large system projects fail all the timeand the larger they are, the more likelythey are to fail. For example, the new IRSsystem was five years late when it was firstused in 2005, but its costs had exploded to$2 billion. A recent Government Ac-countability Office defense acquisitionassessment of 72 typical weapons pro-grams found that the development costshad climbed 40 percent from the first esti-mates, there was an average delay of 21months, and the total systems overrun was$2 billion [1].
The situation is even worse for trulymassive systems programs, as the NewYork Times also recently reported: Two-thirds of the largest weapons systems ranover their budgets last year, for a com-
bined extra cost of $296 billion [2]. Theseprograms were, on average, almost twoyears behind schedule.
Problem CausesStudies show that these developmentproblems are typically not caused by tech-nology issues but are largely due to pro-gram management [3]. Unfortunately, the
common reaction to program manage-ment problems is to replace the programmanagers. This blame-based culture stiflescommunication and fosters an opaque anddefensive management style. We havebeen changing managers for years, but itshould now be obvious that the problemisn’t bad managers: They are good peopleput in untenable positions.
For example, the replacement FBI sys-tem was recently killed when it fell threeyears behind schedule and after the pro-ject had spent $150 million. The programhad a total of five CIOs and nine programmanagers. Clearly, changing managers didnot fix the FBI’s problems. But neither didchanging acquisition systems, reorganizingthe Pentagon, or modifying procedures.Projects keep failing. In fact, more andmore large projects fail these days than inthe past—and the failures are even moreexpensive and painful.
The common view is that the programmanager is responsible for doing whateveris required to get the job done. If newmanagement or technical methods wereneeded, he or she should put them inplace or take whatever steps were neededto do so. But the fact that these large pro-jects keep failing suggests that programmanagers don’t know what to do.However, we must do something and itshould by now be clear that relying onprogram managers to fix these projectsisn’t working. This article suggests how toaddress these problems in a way that pro-gram managers can implement today.
Knowledge WorkWe explained to the NAVO that the prob-lems with software work were an earlyindicator of the problems that would soonplague all aspects of modern engineeringwork. Software has been hard to managesince the beginning, but the reason hasnothing to do with the technology. Thereason is that software is a different kindof work.
For the more traditional work of thepast, the managers could walk around thelab or plant and see what was going on.This is called management by walkingaround (MBWA), a very effective way tokeep management informed about thework and for keeping the workers on theirtoes. However, the principal problem withMBWA is that it is only effective for workthat one can understand by watching theworkers do it. Today, most sophisticatedtechnical work is more like software: Agreat deal of the creative effort is done ona computer or in a worker’s head, andresults are largely invisible to the casualobserver. Peter Drucker, the first todescribe knowledge work, said that it iswork with the mind rather than with thehands [4]. The products, instead of beingthings you can touch and feel, are ideas.While these ideas may ultimately beembodied in physical products, the bulk ofthe work, and the true product value, is inthe creative effort required to develop
Why Can’t We Manage Large Projects?
Changing managers, procurement regulations, acquisition procedures, or contracting provisions have not resolved the cost andschedule problems of large-scale system development. This article shows the problems that organizations face with large sys-tem projects—and how one government organization has succeeded, over a period of several years, using the Team SoftwareProcess (TSP SM).
Watts S. HumphreySoftware Engineering Institute
“We have beenchanging managers foryears, but it should now
be obvious that theproblem isn’t bad
managers: They aregood people put in
untenable positions.”
SM Team Software Process and TSP are service marks ofCarnegie Mellon University.

Why Can’t We Manage Large Projects?
July/August 2010 www.stsc.hill.af.mil 5
these ideas and transform them into mar-ketable products.
Traditional ManagementEven though the workers and much oftheir work is vastly different from 100years ago, today’s traditional managementmethods are still based largely on the prin-ciples from Fredrick Winslow Taylor’s1911 book, “The Principles of ScientificManagement” [5]. Taylor’s methods weredesigned for uneducated workers and therelatively simple manual tasks of the past.The kind of work and the skills and meth-ods involved in much of today’s work arequite different, but today’s managementmethods still follow Taylor’s commandand control principles. Unfortunately, withsoftware and most other sophisticatedtechnical work, these methods are noteffective in controlling project costs,schedules, or quality. While the managersmay try valiantly to manage the work, theycannot know what the knowledge workersare doing or how they are doing it.
The end result is that today’s managerscannot truly manage their knowledge-working projects. That means that theseprojects are not being managed, andeverybody knows that unmanaged pro-jects usually fail. Unfortunately, the man-agers are generally blamed for the failureswhen the real problem is with the man-agement system—and not the managers.The answer is not to replace potentiallyvery capable managers, but to change themanagement methods. Program man-agers, however, typically do not knowwhat changes to make and are under-standably reluctant to change to a newmanagement method that is not in gener-al use by other similar programs.
Managing Knowledge WorkIn considering how to manage knowledgework, Drucker concluded that since man-agers cannot truly manage such work, theknowledge workers must manage them-selves. While many managers say that theyalready involve their people in their ownmanagement, involvement is quite differ-ent from responsibility. To truly managethemselves, the knowledge workers mustbe trained in personal and team manage-ment methods and they must be heldresponsible for producing their own plans,negotiating their own commitments, andmeeting these commitments with qualityproducts. The manager’s job is no longerto manage the knowledge-working teamsbut to lead, motivate, support, and coachthem.
Software teams like to work this way.Where once they struggled to meet man-
agement’s schedule targets, they nownegotiate their own commitments withmanagement. The teams feel personallyresponsible for and in control of theirwork, they know project status, and theyhave the data to defend their estimates.When they see problems, they resolvethem or get management’s help. Further-more, when the knowledge workers mea-sure, track, and report on their work, themanagers have the data to help themresolve problems. Then the entire man-agement system can participate in makingtheir programs successful.
When knowledge-working teams haveappropriate management, training, andsupport, they can work in this way (see thesidebar for the principles of knowledgemanagement). Then they consistently meettheir cost and schedule commitments withhigh-quality products. What’s more, theseidentical knowledge-working principlescan be applied to all of the engineeringprojects in an organization, producing ameasurable and trackable knowledge-workmanagement process across a large pro-gram or even an entire organization.
Workplace ObjectivesOne of the more fundamental problemswith current management practices is thatthe workers and managers have differentviews of project success. Studies showthat product developers view a project assuccessful if the work was technicallyinteresting and they worked on a cohesiveand supportive team [6]. This was truewhether or not the project met its cost orschedule objectives. Conversely, the man-agers viewed projects as successful if theymet their cost and schedule targets withlittle regard for the nature of the technicalwork or the working team environment.This difference in workplace objectiveshas a profound effect on program man-agement. For example, when the program
manager wants to know when some largeprogram will finish, he or she asks theproject leaders. They then talk to theirteam members. The team members viewthe schedule as management’s problem,however, and give vague answers such as“I’m almost through the design,” or “Justa couple more bugs and I’ll finish testing.”While the knowledge workers are typicallythe first to sense that a project is in sched-ule trouble, they have no way to preciselydescribe job status. Rather than say some-thing and risk getting involved in a lot ofmanagement debates, knowledge workerswould rather concentrate on their techni-cal work and leave the schedule problemsfor their managers.
The Surprise ProblemFred Brooks once said, “Projects slip a dayat a time” [7]. To keep their projects onschedule, all that managers have to do ismake sure that their teams recover fromthese one-day slips every day. With large-scale knowledge work, however, the man-agers can’t see these small daily problemsand the developers don’t have the data todescribe them. As a result, the managerscan’t take action to recover from the one-day slips. By the time the schedule slips arelarge enough to be visible, it is too late todo anything about them. This is why pro-jects that are run by very capable and expe-rienced managers keep having cost, sched-ule, and quality problems. The managersdon’t have the feedback they need to seeproblems in time to prevent them. It is asif they were driving a car at a high speed ina dense fog. Once they see a problem, it isright in front of them, and they must makea panicked effort to avoid a crash. Today,in large systems projects, the managers aredriving fast in a fog—and crashes happenall the time.
By the time more senior managers seethese project crashes, the schedule delays
The management principles for knowledge work are fundamentally different fromthose for traditional engineering. The five management principles for knowledgework—which were adopted from my forthcoming book “Leadership, Teamwork, andTrust: Building a Competitive Software Capability”—are as follows:
1. Trust the knowledge workers. Management must trust the knowledge workersand teams to manage themselves.
2. Build trustworthy teams. The knowledge-working teams must be trustworthy.That is, they must be willing and able to manage themselves.
3. Rely on facts and data. The management system must rely on facts and dates—rather than status and seniority—when making decisions.
4. Manage quality. Quality must be the organization’s highest priority.5. Provide leadership. Management must provide their knowledge workers with
the leadership and support they need to manage themselves.
Management Principles for Knowledge Work

Catching Up With TSP
6 CROSSTALK The Journal of Defense Software Engineering July/August 2010
are typically quite significant. Further-more, on a large project with many inter-dependencies, delays in any one part willaffect many others. This means that manyparts of a large program will probably getinto schedule problems at about the sametime. The managers of the many parts ofthe program then face a difficult choice:be the first to admit to schedule problemsor wait for someone else to get into trou-ble first.
Blame-Based ManagementUnfortunately, with the current system,senior leadership tends to blame themanagers for management problems. Bybeing the first to admit problems, themanagers could easily be blamed for theentire program’s problems. Not surpris-ingly, most managers decide to concen-trate on the problems they can solve andwait for someone else to blow the whis-tle. By the time the problems are visibleto senior leadership, the program is insuch serious trouble that there is nochance to recover. Then everyoneupstairs is surprised.
The combination of a blame-based man-agement system and the lack of precise pro-ject status measures motivates bothopaque management and a general reluc-tance to admit to problems. With largeand complex systems programs, everypart is important: Problems anywherecan delay everyone. That is why everycomponent element of the work must bemanaged and tracked and why every teammust strive to meet all of its commit-ments. That is also why, without precisestatus information, all estimates andcommitments at the team level (and, forthat matter every higher level) are justguesses. Finally, that is why, with today’stypical management systems, large pro-jects are almost always late and over bud-get.
The NAVO and the TSPAfter we had reviewed these points withBattle and his associates, he agreed that itall sounded very reasonable—but won-dered how it would help him and the othermanagers keep their large programs onschedule. We explained that the SEI haddeveloped a knowledge-working processcalled the TSP, and that one of its princi-pal features was that its management sys-tem was based on precise, operational-level data [8]. With the TSP, the develop-ers gather and use data to manage theirown work, and they use their data to accu-
rately measure project status to withinfractions of a day. TSP teams report theirstatus to management every week, andmanagement can see exactly where everyelement of every project stands. With pre-cise status information, management cansee small cost and schedule problemsbefore they become serious. They canthen take timely action to identify andresolve the problems.
When knowledge workers have beentrained and know how to manage them-selves, they have detailed plans and knowproject status precisely. They also feelresponsible for managing their own prob-lems and, when they need help, can call ontheir teammates or, if needed, on manage-
ment. No process can eliminate problems;they are a natural consequence of doinglarge-scale complex work. But with suffi-cient warning, recovery actions are almostalways possible—and most of the prob-lems can be avoided or resolved without acrash. The key is early warning: That iswhy detailed plans, precise status mea-sures, and working-level issue ownershipare critical. For knowledge work, you willonly get an early warning when the knowl-edge workers manage themselves.
However, just training workers how tomanage themselves is not enough. Many ofthe problems with current engineeringwork are caused not by the workers andmanagers themselves, but because they donot properly use the knowledge theyalready have. To use what is learned, theymust know what to do and how and whento do it. For large-scale projects, an opera-tional process is essential. Program man-agement is a matter of detail, and everystep must be done precisely and correctly.Just like airline pilots when they do theirfinal preflight checks, they follow a detailed
checklist. While they know every step andhave done it thousands of times, studieshave shown that most airplane accidentsinvolve at least one case of a skipped stepor an improperly followed checklist. Thisfocus on precise work is the role of anoperational process: to ensure that everystep is done precisely and correctly.
For many of the simple tasks that wedo all the time, we know unconsciouslywhat to do and how to do it. But for com-plex or new and unfamiliar tasks—such aspersonal planning, precise schedule man-agement, and data-intensive quality man-agement—the steps are not obvious. Thatmeans that merely training the knowledgeworkers in theoretical methods will notget them to use the methods correctly orconsistently. For that, they must have anoperational process with quality measuresand trackable plans. But once knowledgeworkers are properly trained, know whyand how to manage themselves, and havean operational process that they actuallyuse, they can make and follow detailedplans and precisely track and report theirprogress against these plans.
The NAVO ExperienceWhen the NAVO started working with theSEI, they originally used the CapabilityMaturity Model® (CMM®). It was helpful,but gave them the what when they neededhelp with the how—and it was difficult toimplement. On the other hand, theNAVO found that the TSP was a betterfit, with the guidance they needed to prop-erly manage their projects. It also provid-ed for rapid training (initial team-membertraining takes a week), with teams soonafter launching the TSP and managingthemselves.
Once the teams were using the TSP,the benefits of better planning, tracking,and reduced test time were immediatelyapparent. Many organizations even foundthat the savings from just the first projectpay for that team’s entire training andintroduction costs. The team can thencontinue using it without any furthertraining investment.
After using the TSP for several years,Battle reported that their product qualitylevels have improved by about 10 timesand that testing times have been reducedfrom months to weeks. Schedule and costperformance is much more predictablethan before, and the Monday, Wednesday,and Friday weekly status meetings are nolonger needed. Team cooperation andcoordination was also greatly improved.Battle’s final conclusion was that, “This isthe only way to manage large knowledge-working projects.”
“No process caneliminate problems ...
But with sufficientwarning, recovery actions
are almost alwayspossible—and most ofthe problems can beavoided or resolvedwithout a crash.”
® The Capability Maturity Model and CMM are registeredin the U.S. Patent and Trademark Office by CarnegieMellon University.

July/August 2010 www.stsc.hill.af.mil 7
ConclusionsThe consistent failure of large-scale devel-opment programs not only costs a lot oftime and money, it delays the introductionof promising new technology anddeprives our fighting forces of the toolsthey need to protect our nation. By now itshould be obvious that the U.S. defenseindustry lacks the motivation to addressthis problem. For example, a mid-levelexecutive of a major defense contractorrecently told me that he could not affordto use high quality development methodslike the TSP because it would reduce hisrevenue. His organization gets paid whenthey overrun projects and they get newcontracts to fix their defective products. Ifthis executive eliminated this source ofrevenue, he would lose his job. One couldargue that the answer to this situationwould be fixed-price contracts, but thisapproach has been tried several times inthe last 50 years and has not solved theproblem. It merely converts technicalissues into contract disputes and the con-tractors get paid anyway.
Similarly, the program managers can’tsolve this problem. Even if they werefamiliar with the TSP and convinced thatit would work, they would be reluctant totry something before it had been widelyused by other programs or recommendedby acquisition management. The TSP hasa proven record of success and it couldhelp to address this problem right now.The DoD—or some other governmentagency—should evaluate or test the TSP1
and other promising methods to deter-mine their suitability. It should then deter-mine the best methods to use in managingthese large programs and recommend thatprogram managers require their contrac-tors to use these methods. This should notbe an expensive or time-consuming effort.Large-scale systems development is toocritical a national problem to ignore—andthe savings could be enormous.u
References1. GAO. Defense Acquisitions: Assessments of
Selected Weapons Programs. Report toCongressional Committees. GAO-08-467SP. Mar. 2008 <www.gao.gov/new.items/d08467sp.pdf>.
2. “A Lot More to Cut.” Editorial. NewYork Times. 11 May 2009 <www.nytimes.com/2009/05/11/opinion/11mon1.html>.
3. Office of the Under Secretary ofDefense. Report of the Defense ScienceBoard Task Force on Defense Software.Nov. 2000 <www.dtic.mil/cgi-bin/GetTRDoc?AD=ADA385923&Locati
on=U2&doc=GetTRDoc.pdf>.4. Drucker, Peter F. Landmarks of
Tomorrow. New York: Harper & Row,1957.
5. Taylor, Frederick Winslow. ThePrinciples of Scientific Management. NewYork: Harper & Brothers, 1911.
6. Linberg, Kurt R. “Software DeveloperPerceptions about Software ProjectFailure: a Case Study.” The Journal ofSystems and Software 49 (1999): 177-192.
7. Brooks, Frederick P. The Mythical ManMonth: Essays on Software Engineering.20th Anniversary Edition. Reading,MA: Addison-Wesley, 1995.
8. Humphrey, Watts S. Winning withSoftware. Reading, MA: Addison-Wesley, 2002.
Additional Resources1. Callison, Rachel, and Marlene Mac-
Donald. A Bibliography of the PersonalSoftware Process (PSP) and Team SoftwareProcess (TSP). SEI, Carnegie MellonUniversity. Special Report CMU/SEI-2009-SR-025. Oct. 2009 <www.sei.cmu.edu/reports/09sr025.pdf>.
2. Hefley, Bill, Jeff Schwalb, and LisaPracchia. “AV-8B’s Experiences Usingthe TSP to Accelerate SW-CMMAdoption.” CrossTalk Sept. 2002<www.stsc.hill.af.mil/crosstalk/2002/09/hefley.html>.
3. Grojean, Carol A. “Microsoft’s ITOrganization Uses PSP/TSP to Ach-ieve Engineering Excellence.” Cross-Talk Mar. 2005 <www.stsc.hill.af.mil/crosstalk/2005/03/0503 Grojean.html>.
4. Lopez, Gerardo, et al. TOWA’s TSPInitiative: The Ambition to Succeed. Proc.of the 3rd Annual Software Engineer-ing Institute Team Software ProcessSymposium. Phoenix. 22-25 Sept.2008.
5. Nichols, William R., et al. “ADistributed Multi-Company SoftwareProject.” CrossTalk May/June2009 <www.stsc.hill.af.mil/crosstalk/2009/05/0905NicholsCarletonHumphreyOver.html>.
Note1. For the basics of the TSP, see <www.
sei.cmu.edu/tsp> and past Cross-Talk issues (<www.stsc.hill.af.mil/crosstalk/2005/03>, <www.stsc.hill.af.mil/crosstalk/2006/03>, and <www.stsc.hill.af.mil/crosstalk/2002/09>).To examine more detailed informationabout the TSP, see the AdditionalResources section of this article. For asummary of TSP project results, see<www.sei.cmu.edu/reports/03tr014.pdf> and slide 17 of <www.cmminews.com/2009/pdfs-sessions/73.pdf>. For more on organizations usingTSP, see <www.sei.cmu.edu/tsp/casestudies>.
There aren’t many organizations bigger than the defense industry—and none with abigger need for success in their large-scale development programs—where failure canhave billion-dollar financial impacts and, worse yet, present dangerous security vul-nerabilities. TSP creator Watts S. Humphrey, whose groundbreaking 2000 report out-lining the TSP (see <www.sei.cmu.edu/reports/00tr023.pdf>) was sponsored by theDoD, feels that our defense industry can benefit significantly more from the process.Through past experiences, and the success of an organization providing oceano-graphic products and services to all DoD elements, Humphrey shows how and whythe DoD needs the TSP now more than ever.
Software Defense Application
About the Author
Watts S. Humphreyjoined the SEI after hisretirement from IBM. Heestablished the SEI’sProcess Program and leddevelopment of theCMM for Software, the
PSP, and the TSP. At IBM, he managedtheir commercial software developmentand was vice president of technicaldevelopment. He is a fellow for the SEI,the Association of Computing Machin-ery, and the IEEE. He is also a pastmember of the Malcolm Baldrige Na-tional Quality Award Board of Examin-ers. In 2005, President George W. Bushawarded Humphrey the prestigiousNational Medal of Technology for hiscontributions to the software engineer-ing community. He holds master’sdegrees in physics and business adminis-tration and an honorary doctorate insoftware engineering.
SEI4500 Fifth AVEPittsburgh, PA 15213-2612Phone: (412) 268-6379E-mail: [email protected]
Why Can’t We Manage Large Projects?

8 CROSSTALK The Journal of Defense Software Engineering July/August 2010
Q: What were the personalexperiences and values thatinfluenced you while creat-ing CMM, PSP, and TSPtechnologies?
Watts: Three experiences had a majorimpact on me.
Let me start with one of my first man-agement jobs. I got hired by Sylvania inBoston to manage a fairly large circuit-design group that was building a great bigcryptographic system. I had this group ofyoung engineers all designing circuits, butI had been trained as a physicist and didn’tknow the first thing about circuit design.
Rather than fake it, I just spent mytime asking them what they were doingand had them educate me. It was a differ-ent kind of management style than whatpeople are used to. Usually, managers havedone development work themselves,know how it ought to be done, and try totell everybody how to do things. I couldn’tdo that. It was an education for me andhighly motivating for the engineers. Theyloved it, and began to manage themselves.The exciting thing for me to discover wasthe fact that it’s the only way you can man-
age really large groups. You discover whenyou get groups of hundreds or thousandsof people—which I later did—that youcan’t manage what they are doing, so youneed to count on them. That is the styleI’ve used throughout my career. It’s influ-enced everything I’ve done.
Basically you treat management as acontinuous learning process, as a leadingprocess, as a motivating process, and notas a directional process. So you’re nottelling people what to do—you’re havingthem work it out and explain it to you andjustify it. It really makes an extraordinarydifference.
The second experience was at IBMwhere I was a crisis fixer. I found that theproblems were never technical; they werealways management problems. That’swhat I have struggled with trying to fix. Ididn’t know it then, but it’s something Iwould be working on for rest of my life.
Fundamentally, you need to challengepeople to prove to you that they are man-aging themselves: Putting motivation andaccountability together turned out to bevery effective. By and large I’d say that,with essentially no exceptions, all the crisisprojects I led were successfully fixed. Oneexample was an enormous project of4,000 developers building an operatingsystem for IBM. It was terribly late. Webasically stopped everything for about 60
days and had them make plans, and itworked.
The reason I feel that the planning issuewas critical comes from my third influ-ence—my MBA education at the Universityof Chicago. For some strange reason, Idecided to major in manufacturing. Themanufacturing professor emphasized threethings in management: planning, planning,and planning. Basically it’s what he focusedon throughout the whole course.
What fascinated me was that whilehardware engineers have to work withmanufacturing, the software engineersdon’t. The manufacturing people requireplans, so the hardware engineers have tounderstand planning. The software peo-ple could manage their own work if theylearned how to make plans and managethemselves. The CMM, the TSP, and thePSP all start with planning—it’s the firststep for everything you do. But softwarepeople are never taught how to plan.You can’t just tell them to plan—youhave to show them. That’s a big part ofwhat we do.
Q: As you expanded the PSPprocess to the TSP, did theindustry develop at a sloweror faster pace than youenvisioned?
An Interview With Watts S. Humphrey
With more than 50 years in software and countless CrossTalk articles, Watts S. Humphreyneeds no introduction—but we will anyway.
After World War II and academic work at the University of Chicago, Humphreyled an engineering group at Sylvania Electronic Products. Humphrey then joinedIBM in 1959, where he worked on everything from fixing the OS/360 to leadingprojects as Director of Programming and Vice President of Technical Develop-ment. After retiring from IBM in 1986, he joined the SEI, where he establishedthe Software Process Program, led development of the Software CapabilityMaturity Model, and introduced the Software Process Assessment and SoftwareCapability Evaluation methods. Humphrey also led the development of thePersonal Software Process SM (PSP SM) and the TSP. At a White House ceremonyin 2005, President George W. Bush awarded Humphrey the National Medal ofTechnology. Known as the “father of software quality,” he is also the author of 12books—with another one, “Leadership, Teamwork, and Trust: Building aCompetitive Software Capability,” on the way.
CrossTalk talked with Humphrey, who delved into his past and present work, as well asdiscussed the future of CMMI®, PSP, TSP—and the software industry.
SM The Personal Software Process and PSP are servicemarks of Carnegie Mellon University.
® CMMI is registered in the U.S. Patent and TrademarkOffice by Carnegie Mellon University.

An Interview With Watts S. Humphrey
July/August 2010 www.stsc.hill.af.mil 9
Watts: Slower. I am reminded of a storyabout Fredrick Winslow Taylor1. Morethan a century ago he was working with amachine tool shop in England and invent-ed the idea of lubricating the cutting tool:It was effective, it was very easy to intro-duce, and it cost practically nothing. Hewent back 20 years later and checked onmachine shops in England and discoveredthat only one other shop was using it.
Now my point is that extraordinarymethods that save an enormous amountof money are often relatively easy to putin place and are unbelievably effective—but they don’t get adopted. You have towonder why that is. I’ve concluded thatthere are three reasons.
First, every five years or so for the past60 years that I’ve been working, some“magical new software method” comesalong, and most of them don’t work—except for the person who invented them.This has caused a lot of skepticism.Workable new ideas won’t be believeduntil software engineers see them work forthemselves. And they won’t try it forthemselves until they believe it willwork—so you’re stuck with a chicken andegg problem.
The second is that introducing newideas is always difficult. When things aregoing well, organizations don’t think theyneed to change—and when things aregoing badly they can’t afford to change. Soyou’re stuck and it takes people with greatvision to see the strategic need to changeeven when they don’t have to. Most onlychange when there’s some pressure thatmakes them change.
And the third is that very few man-agers below senior levels are willing orable to take the initiative to introduce newmethods—even when the benefits areobvious and proven.
Q: So what you’re saying isthey feel powerless.
Watts: Well ... they feel that way, but peo-ple really aren’t powerless. I’ve talked tomanagers who have hundreds of peopleworking for them and say they can’t doanything. But I’ve been a manager withhundreds of people working for me andI’ve done it. I basically would just do whatI felt I had to do and I’d tell my manager,“Here’s what we’re doing.” I’ve alwaysbelieved that if it makes sense and you canjustify it, just do it and it almost always will
work. Tell people in advance and don’tever surprise your boss, but I’ve alwaysfollowed that old saying: “It is better toask for forgiveness than permission.”
Q: What are the other engi-neering areas to which yousee the PSP/TSP expand-ing?
Watts: The PSP and the TSP are funda-mental; they’re not just about software. Ifyou’ve read Peter Drucker, he started talk-ing about knowledge work in 1959.Knowledge work is dramatically differentfrom the typical work we do with ourhands. It’s work where you can watchknowledge workers but you can’t tell whatthey’re doing.
Now with typical engineering work—hardware engineering, manufacturing,construction, you name it—you can watchpeople doing their work and you can tellwhat they are doing and how well they aredoing it. I mention in the article [in thisissue], the method called “management bywalking around” (MBWA): Managers goout and walk around the shop and seewhat is going on. As I say in the article, anincreasing amount of the true work isdone on computers and in people’s heads.That’s where the value is. And that isknowledge work.
So with a few exceptions, knowledgework is becoming pervasive—and why it’sso extremely hard to manage some ofthese jobs. Managers don’t know how tooperate if they can’t use MBWA—youcan’t use it with knowledge work. That’swhy software has been so extraordinarilyhard to manage from the very beginning.Drucker’s point was that the knowledgeworkers have to manage themselves, andthat’s what we are showing them how todo with the TSP.
Today’s knowledge workers don’tknow how to manage themselves becausethey don’t believe that they need to. Theythink that anything called management isthe manager’s job. So the knowledgeworkers don’t manage themselves: theydon’t want to, they don’t know how to,and they literally can’t do it. As a result,knowledge work is not being managed—which means that projects often fail.
The TSP is designed for knowledgework. It’s not just designed for software,it’s designed for any kind of knowledgework—and we’ve used it with systems
design, video game development withartists and game designers, as well as withsoftware people and hardware groups.The TSP is universally helpful as a man-agement system for just about any kindof complex work. One of the mostimpressive things to me was that wetrained some Mexican software engineersto be TSP coaches—and they returned toMexico and started a business. They’venow grown that business to nearly 400people, and they expect to be at 1,000 ina few years. They’re even running theircorporate office with the TSP.
The places where it can be used arealmost limitless—and the benefits insoftware are so extraordinary that that’swhere knowledge workers are most likelyto see the benefits of self-management.In software, you can cut test time incre-mentally. We’ve seen organizations thathave been spending a year in test; withthe TSP, they now spend a month and ahalf in test. You don’t quite see that inthe other areas, but it is equally applica-ble. The TSP is universally helpful as amanagement system for just about anykind of complex work.
Q: On a side note, our organi-zation just finished a six-year training programwhere we trained more thana thousand leaders hereand—I’ll just be honest—we stole heavily from thoseconcepts to get folks out-side of software to use thosetypes of disciplines. Thething that I noticed is peo-ple seem to inherently beattracted to the PSP/TSP—I mean, it just makes senseto them.
Watts: Well, people love it: Their moralegoes up, they are excited about it, and theirjobs are much better. PSP-trained peoplehave to know how to manage, estimate,and track their own work—personally. Ifthey don’t know how to plan, they don’thave the foundation required for self-management. That’s why the training is soextraordinarily important. But managersjust want to read a book on “how to be ateam.” That doesn’t work because theydon’t really understand planning, manage-

10 CROSSTALK The Journal of Defense Software Engineering July/August 2010
ment, and tracking, or how to control aproject.
Q: What is your vision forusing the TSP concepts inwhole organizations andhow would they managesuch an effort?
Watts: There are two ways to look at this.Let me first talk about a big company. Irecommend that organizations start with amodest-sized area and run a few teams.Typically, they’ll start with multiple pro-jects of six to 12 people—which are greatfor TSP teams—and we have them runthose projects and start building skills.Then, broadening TSP use across thebusiness is purely a question of howrapidly the organization wants to go andhow rapidly they can build the manage-ment skills. The engineering skills can bebuilt very quickly: In one week, we cantrain an engineering team to use the TSPand be a TSP team. The problem is that ittakes quite a while for management tounderstand what the TSP is all about. It’sa change in management style, and chang-ing management style in an organization ismuch more difficult. The engineers take toit like ducks to water—they just dive in.We typically have engineers refusing towork any other way after they’ve used it.
Second, there is the case where you’vegot an entire organization-wide programand the organization may have multiplecompanies, multiple locations, and it’s allone great big job. When the people run-ning these great big projects want to real-ly know project status, the managers mustgo to the individual software and systemdesign teams—and talk to the developersand ask them exactly where they stand ontheir schedules and how they’re doing.Unfortunately, the teams can’t tell them.They’re guessing, they don’t know. Theproject or team leaders may poke aroundand talk to everybody and they get vaguestories. Then, when these managers talk tomore senior management, they’re guessingand defensive. They really can’t level withmanagement because they really don’tknow.
With the TSP, you don’t sit down andargue and debate. You say: “Here is exact-ly where we stand, we’ve got these prob-lems, and here we are.” You discover thatwhen you have the facts, your customersand your managers will work with you to
solve problems. We have seen that withthe Navy and with several DoD projectswe’ve worked on. All of a sudden, insteadof faking it, you know exactly what you’retalking about. Nobody is guessing. You’vegot the data and you sit down and say,“Okay, we’ve got a problem to solve. Howdo we do that?” It is a totally different atti-tude.
In big programs you need to start atthe base, get everybody using it, and havethat whole attitude—of honesty, of level-ing, of data, of facts—where you can real-ly negotiate and deal openly with the man-agement team. Building an environmentof trust is absolutely crucial. We do nothave that today in large programs becausethe facts aren’t there to engender trust.
Q: PSP theory talks of experi-encing a 100 defect perthousand lines of code(KLOC) defect density astypical for PSP softwareengineers (as well as theTSP teams they belong to)when developing software.With software teams usingmore powerful, context-sensitive editors for devel-oping software, TSP teamswith which we are familiarare seeing defect densitiesof anywhere from 50-70defects per KLOC. Assum-ing this new “reality” existsbeyond the teams we study,does this evolution in soft-ware development impactthe way that PSP should betaught?
Watts: Well, the 100 defects per KLOCdefect level is what we see when develop-ers first start learning PSP. At the end oftraining, they’re typically at 50-70 defectsper KLOC or less. I’ve seen some down inthe 20s. The numbers come down: Peopleare using more disciplined methods andare aware of the defects they injectbecause they are measuring and trackingthem. Just measuring and understandingthe mistakes you make generates feedbackreal quickly. The numbers really do comedown sharply when people understandtheir mistakes.
The second issue concerns the devel-opment environment. I’ve written someprograms with .NET, with stuff like that.But those tools do not eliminate yourerrors and do not address the key prob-lems with logic errors. All of these toolsare designed to generate a working pro-gram from whatever the developer puts in,so it could very cleverly produce a workingprogram from a highly erroneous design.Software people tend to think that whensome tool fixes their trivial defects that allthe defects are fixed. People have to beconscious of what they’re doing and evenmore so when working with very sophisti-cated tools like .NET, where you can putin all these very complex functions thatmost people don’t even understand. Theselanguages are so complicated that very fewpeople ever really understand them com-pletely.
Q: Is it safe to say they are get-ting a false sense of security,as far as these defects go, byusing some of these tools?
Watts: Yes, that is true. Powerful toolscan lead to powerful mistakes. The wholeprocess of designing tools and languagesis aimed at richer and richer capabilities.Not a whole lot of attention is paid tounderstanding why developers makeerrors and/or how to design languagesand tools that minimize human error. I’vehoped that the academic communitywould look at this, but unfortunately noone has done it yet. It is time they started.We really do need that kind of help.
Q: You have stated that yourpersonal goal since themid-80s has been to trans-form the world of softwareengineering. In what wayshave you succeeded in this,and what unreached goalsdo you hope to meet in thefuture?
Watts: When I retired from IBM, I madethe outrageous statement that I was goingto “change the world of software.” Youcan never really do that sort of thing byyourself, but it was really motivating. WhatI found fascinating was that people gotexcited about it. They joined in. I got a
Catching Up With TSP

An Interview With Watts S. Humphrey
July/August 2010 www.stsc.hill.af.mil 11
whole movement going and it was mar-velous. When you get people working withyou, you can get a lot done. That has beenexciting—and we’ve had some remarkablesuccesses as well as some real disappoint-ments.
Let me talk about the successes first.With the OS/3602, after I took over thatproject [at IBM], we put together a newplan and we put in place the managementsystems I’ve been talking about. This wasat a much earlier level—we didn’t under-stand it all then. But we [then] didn’t missa single delivery date for two and halfyears. There are not many people whohave done that with big software systems.We put out the first 19 releases of OS/360on schedule. Take a look at Microsoft oranybody else today: They never deliver onschedule, but we did, and it made an enor-mous difference.
Okay, so that is the success. We nowhave a basic understanding of this stuff.We know how and why software costs,schedules, and quality have been out ofcontrol—and we know what to do to fixthem. I’m not saying that we have solvedevery problem, but when we work withorganizations, we can help them build thecapabilities they need to consistently deliv-er quality products on schedule. And itworks: We have seen it with hundreds ofteams across many businesses; we’ve seenit work with small two, three, four personprojects, up to great big multi-companyprograms.
What is so disappointing is the accep-tance of these ideas. The defense industryhasn’t really looked at this at all. One ofthe main reasons and one of the bigobjectives I had when I started this wholething was to address this national need:We have these enormous programs andour whole defense industry and militarypreparedness is dependent on these pro-jects getting completed—and on time.
During my very first SEI project, I wasworking with the electronic systems com-mand. That’s where we started the CMM,the predecessor of CMMI. Every projectwas failing. They were all behind sched-ule—on average 60 to 70 percent late, andcosts were at least twice what was planned.There was a recent report in the NewYork Times3 saying that two-thirds of thelargest DoD weapons systems ran overtheir budgets and the combined extra costwas $296 billion dollars—and they wereon average two years behind schedule.This is a tragedy. We know how to do bet-
ter—we are just throwing money downthe drain.
I had a major executive on a defensecontract ask me, “You mean to tell me youwant me to spend profit dollars to cut rev-enue?” These companies today are beingpaid to do crappy work and then fix itlater. And with the current system, youand I as taxpayers just keep paying for it.The more junior-level managers can’t fixit, and it isn’t that they don’t want to; myguess is that they would love to, but can’t.They are measured on revenue and profitand they literally cannot reduce it. Theycan’t spend profit dollars to train their
people to do quality work and have theirrevenue go down. The whole structuredoes not allow them to do it.
The DoD is constantly struggling.They are trying to change procurementregulations and trying to change managersand get smarter people, but there will beexactly the same problems until they startto deal with the fundamental managementsystem that’s currently being used. Andthat is what the TSP does: It managesknowledge work. It’s not dealing with thework as something you can walk aroundand watch, because you can’t. Knowledgework is invisible to the managers and if wecontinue to operate in the same way, noneof the band-aids the DoD is trying willever fix it. I’ve seen it for 50 years. So it isnot going to change in the next five, 10, or20 years until leadership begins to realizethat we have to try something different.
And the TSP is different. It lets teamsknow precisely where they stand. Theycan give data to their managers, they cantell them exactly what is going on, andthey can identify any problems. Mostcrises in big programs are obvious: They
are identified years ahead by somebodyway down in the trenches. And usuallythose people don’t feel that they own theproject. They assume somebody else willhandle the problems, so they just go onwith their jobs—and the crisis blows up.
What is exciting about TSP teams isthey actually do risk analysis and trackproblems. They take ownership and assignindividual team members to track andmanage them. We have standard roles forTSP teams—a customer interface manag-er, a test manager, a design manager, andothers—and each of these roles isassigned to a team member. So you nowhave ownership at a team level; you haveteam members who will bring issuesupstairs when they need to. Instead of hid-ing their problems and going on with theirwork, they’re actually addressing issuesproactively and getting management’s helpwhen they need to—and it works.
We need that attitude throughout theseenormous programs in the DoD. It muststart down at the root level. If you have itthere, it will build all the way up to theexecutive level. When the managers knowwhat they are talking about, you begin toget cooperation between the defense con-tractors and the DoD. And the DoD cannow deal honestly with Congress. Rightnow, Congress doesn’t trust the DoDbecause they can’t get the facts and every-thing is a surprise.
The other disappointment is the acad-emic community. With few exceptions,computer science and software engineer-ing programs have shown no interest inthe TSP and PSP. Until they start teachingthis stuff, their graduates won’t under-stand it and industry will have to re-edu-cate their people—and that’s expensive.The way people are working today, they’rebasically beating their heads against thewall, testing until midnight, in at all hours.Nobody likes it, it’s a painful job, there arefailures all the time—and it has become avery unattractive career.
The U.S. Census Bureau did a studysome time ago—and unfortunately I don’thave the reference—forecasting that with-in 10 years, 50 percent of the people doingsoftware work would leave the field. Theseare enormously talented and skilled peoplewho have had 10 years of experience thatare just going off and doing other things.They make some money and then theyleave. They can’t take it. It’s because theydon’t know how to manage themselves;they don’t know how to work in this envi-
“[The TSP] lets teamsknow precisely wherethey stand. They can
give data to theirmanagers, they can tellthem exactly what is
going on, and they canidentify any problems.”

Catching Up With TSP
12 CROSSTALK The Journal of Defense Software Engineering July/August 2010
ronment. The academic community reallyhas to get on board: understand it andteach it. They ought to lead this charge.
Q: Do you see issues betweenthe model community(CMMI) and the processcommunity (TSP) and, ifso, what are your thoughtson how to overcome suchdifferences?
Watts: Frankly, in the past, we have haddifferences, but they were principally dueto misunderstandings. The groups had notbeen working that closely together. Wewere basically on our own paths. Our chal-lenge was to figure out how to make thisstuff work. Now we’ve worked throughthese differences and see that the twoapproaches work together extremely well.The CMMI people now see that it works.
Fundamentally, one of the big prob-lems CMMI has now is performance—performance for high-maturity organiza-tions. The CMMI community is beginningto see that what we’ve got does work. Andso we are beginning to work together;CMMI and the TSP are very complemen-tary. We are now working as a coordinatedgroup to figure out how we can betterhelp people improve their organization’sperformance and accelerate processimprovement.
Q: What is your opinion of thedirection that CMMI ap-pears to be headed for highmaturity? Specifically, doyou believe that we will seebenefits from the kinds ofProcess Performance Base-lines and Models for whichlead assessors are now look-ing?
Watts: Let me talk about the two kindsof processes: procedural and operational.
CMMI is an excellent example of aprocedural process. Fundamentally, it setsorganizational standards and sets baselineprocedures across a business.
The CMMI framework is exactly whatwe did at IBM: We defined standard mile-stones where the teams had to go throughsix project review steps before they couldgo out the door. They had to do this
before they could get funded, before theycould announce a product—that sort ofstuff. We had steps that all the projectshad to go through: guidelines for qualityassurance, testing techniques, and inspec-tion procedures. We established a reviewprocedure and all the involved groups par-ticipated—the maintenance people, themarketing people, the support groups, andso forth. They all had to sign off. Whilethis was a lot of bureaucracy, it forced theorganization to do things that TSP teamsdo naturally. But it worked real fast. Sincewe were in a crisis, we needed that.
Before CMMI, we didn’t have thatsort of thing—everybody was off doingtheir own stuff, nobody had a standardframework, none of that. CMMI isextremely helpful in stabilizing an organi-zation and getting a level of statisticalcontrol: It is repeatable; you can more orless get stuff to work in a predictable way.And so that is how CMMI—in Levels 2,3, 4, and ultimately 5—stabilizes an orga-nization and begins to build the kind offoundation you need for real improve-ment. So CMMI is what I call a procedur-al process.
Now you get to an operational processwhere you are talking about what thedevelopment teams do when they developsoftware. How do they do it? How dothey manage quality and cost and sched-ule? What data do they gather? Whatmeasures do they use? We found thatuntil you provide specific guidance to thedevelopers, they won’t do it.
Think of it this way: When you tell adeveloper, “I want you to make a plan,”they don’t have the vaguest idea of howto do it and they don’t even know whatone looks like. That’s what I saw at IBM.Everybody was coding and testing.Everybody knew that they ought to haveplans and requirements, and they knewthat they ought to have all this otherstuff in place—but they didn’t knowhow to do it. I put a thousand managersthrough a course on how to plan. If wehadn’t done that, the managers wouldn’thave been able to make plans. We putthat in place and it worked. It was extra-ordinary.
So the whole idea here of the proce-dural process is to build the base capabil-ity and then begin to move toward anoperational process where people reallydo what they have to do to generate thedata, manage the quality, and build theperformance of the organization. So
that’s the distinction between the proce-dural process and operational process.With a procedural process, you usuallyneed a bureaucracy to enforce it, but withan operational process—as long as theteams are properly coached—they can betrusted to do their work properly and thebureaucracy is unnecessary. So the trade-off is coaching versus bureaucracy.
When we originally put together thewhole maturity model framework, we weredoing it for the acquisition community. Weknew that we had to give guidance on thequestion, “What do you look for?” So wefocused on artifacts. What is the evidenceof an organization’s performance? Say wewant an organization that is producingplans and that uses configuration manage-ment and requirements management.What are the things that you’d have to haveif you did that? You could say, “Well okay,if you do planning then you ought to haveplans.” You can now look around and say,“Do you have plans?”, “Do you havereview meetings?”, and “Do you havereview meeting minutes?” If you haveconfiguration management then you oughtto have configuration management audits,reviews, and updates so that there are actu-al artifacts produced as a natural conse-quence using the process. It shouldn’t beexpensive to produce. If you’re actuallyusing that process those are things youought to naturally have; you look and makesure they’re there.
When we put together the originalmaturity models, this is what we did.While the acquisition people didn’t reallyunderstand the details, they could tell thatsomebody had a development plan, it wasfor this project, it was signed off, and ithad what appeared to be the right stuff init. It was fairly easy to do. The originalintent was that these artifacts were thenatural consequence of the process beingused, so there shouldn’t be a lot of costinvolved in preparing for such a review.
Now notice what happened withCMMI: Appraisals became important soorganizations were in a great hurry toreach a high maturity level. Increasingly,organizations discovered that it isextremely hard to change what the devel-opment teams actually do. It’s a heck of alot quicker to have task groups generatedocuments that meet the needs of theappraisal. So you’ve got groups that puttogether configuration plans, develop-ment plans, and all of this stuff. And it’snot developed by the developers—but

July/August 2010 www.stsc.hill.af.mil 13
there is nothing in CMMI says that it’swrong to do this—so you’ve got all ofthese artifacts. Now you have these inde-pendent groups bureaucratically produc-ing stuff that has no relationship to thework that is being done. And so you don’timprove organization performance at all.Unfortunately CMMI, as currently built,doesn’t protect against that. And so that’swhat we need to focus on: How do wework together so the CMMI and TSPfolks really focus on what it takes to havea high-performance organization?
This is why the performance idea is socritically important. If you really are talk-ing about data and measurement, youhave to think about performance in a dif-ferent way. You need to show that you notonly have the artifacts but you are gettingthe performance the artifacts should pro-duce. So that’s the thing that we are talk-ing about. Up to this point, when we’veput people together, it has cut the costand time for process improvement. Itaccelerates the movement from one levelto another and produces dramatic perfor-mance improvements.
Q: Where do you see thingsgoing in the future? Do yousee the DoD taking moresteps to utilize the TSP?
Watts: In terms of where we are going,
the future is exciting. I’ve found that evenenormous programs can be managed. Canyou imagine how our economy wouldwork and how the DoD would function ifpeople could actually put together plansfor these massive programs and thendelivered them on schedule and for theirplanned costs?
People don’t understand when I say,“Delivering on cost and within schedule,”that this will be a fundamental problemfor the DoD. It doesn’t mean that theteams can deliver on whatever schedulethe politicians or generals demand, itmeans that the development teams them-selves—when they know how to managetheir own operations and put togethertheir own plans—can go to the generals.Then the generals can go to the politiciansand say, “Here is what it is really going totake.” Instead of saying, “We’re going todo it in 18 months,” you may do it in 30months, but people will actually deliver onschedule and they will meet their costgoals with quality products.
We are seeing that time and time again.We are seeing it with big teams and we’veeven seen it with multi-company teamswhere you have people working togetheracross several companies. There was onecase with two competing companies4—under a DoD contract—where they actu-ally did deliver on schedule and the prod-uct really did work. We heard the cus-
tomers say, “This is extraordinary. We’renot going to work any other way.” So weknow it can be done.
So the customers will like it, the politi-cians will like it, the generals will like it, theusers will like it, and we’ll get a hell of a lotfaster stuff out there to the fightingforces. It’s a very exciting future. I hopeI’m there to see it.u
Notes1. See <http://en.wikipedia.org/wiki/
Fredrick_Winslow_Taylor>.2. IBM’s OS/360, officially known as the
IBM System/360 Operating System,was developed for IBM’s then-newSystem/360 mainframe computers.The multiple virtual storage version ofOS/360 was the first large-scale gener-al purpose operating system and it wasone of the first to make direct accessstorage devices a prerequisite for theiroperation.
3. See <www.nytimes.com/2009/03/31/business/31defense.html>.
4. This project is detailed in theMay/June 2009 CrossTalk article,“A Distributed Multi-Company Soft-ware Project,” co-written by Humph-rey with Dr. William R. Nichols, AnitaD. Carleton, and James W. Over. See<www.stsc.hill.af.mil/crosstalk/2009/05/0905NicholsCarletonHumphreyOver.pdf>.
An Interview With Watts S. Humphrey
DATA: Mining, Flow, and ReliabilityJan/Feb 2011
Submission Deadline: August 13, 2010
Rugged SoftwareMarch/April 2011
Submission Deadline: October 8, 2010
People Solutions to Software ProblemsMay/June 2011
Submission Deadline: December 10, 2010
Please follow the Author Guidelines for CrossTalk, available on the Internetat <www.stsc.hill.af.mil/crosstalk>. We accept article submissions on software-relatedtopics at any time, along with Letters to the Editor and BackTalk. We also provide a
link to each monthly theme, giving greater detail on the types of articles we'relooking for at <www.stsc.hill.af.mil/crosstalk/theme.html>.
CALL FOR ARTICLES
Pleat <wwtopics
lin
If your experience or research has produced information that could beuseful to others, CrossTalk can get the word out. We are specificallylooking for articles on software-related topics to supplement upcomingtheme issues. Below is the submittal schedule for three areas of emphasiswe are looking for:

14 CROSSTALK The Journal of Defense Software Engineering July/August 2010
The TSP quality plan is composed dur-ing meeting 5 of the launch1 by deter-
mining the defect injection rates and yieldsfor each phase of the product develop-ment process. Using the team’s historicalaverages for these rates and estimatedhours per phase, the team can predict howmany defects will likely be injected andremoved as products move through thisprocess. Unfortunately, these averages donot take into account normal variability inthe process. However, by applying aMonte Carlo simulation to the standardTSP quality planning process, a team candetermine the historical distribution ofprocess variability and produce a plan withranges for expected defects injected andremoved, as well as a measure of goodness forthe product and process.
The TSP Quality PlanOne of the hallmarks of projects usingthe TSP is the attention to quality or, moreaccurately, the ability to manage productdefects. In fact, TSP creator Watts S.Humphrey says:
... defect management must be a toppriority, because the defect contentof the product will largely deter-mine your ability to develop thatproduct on a predictable scheduleand for its planned costs. [1]
A chief component of this focus is thequality plan developed during meeting 5of the TSP launch (for a project). Thisplan is composed by estimating defectsinjected and removed during the variousphases of the software process. The teamuses historical averages of defects injectedper hour to determine defects injected andsimilar averages for yield (the percent ofexisting defects found and fixed during aphase) to determine those removed (seeTable 1 for a sample quality plan).According to Humphrey, the true purposeof the quality plan “is to establish teamyield goals for each process step” [2]. Ifthe team does not have sufficient histori-
cal data, average injection and removaldata collected by SEI can be employed.Using this approach, the team estimatesfinal product quality and then determineswhether or not that quality will meet theircustomer, management, and team goals. Ifthose goals are not met, the team decideswhat process changes should be made tomeet them.
Once the plan has been developed andthe launch completed, it is the role of theteam’s quality manager (assigned duringthe launch) to monitor progress againstthe quality plan. Results of the monitoringactivities are discussed during the team’sweekly meeting. In addition to monitoringactual values for defects injected andremoved, the quality manager can helpfocus the team on quality issues by exam-ining other metrics, such as the defectremoval profile (the defects per thousandlines of code removed from softwarecomponents as they move through thedevelopment life cycle) and the productquality index. Exercises such as the cap-ture-recapture method2 can even predicthow many defects may have escaped apersonal review or inspection. When doneproperly, these measures, metrics, andactivities can improve the team’s qualityfocus, reducing rework and improving on-time and within-budget performance.
Many TSP teams that have no issueswith most TSP concepts struggle with thisprogress monitoring. While teams areexcited about producing the quality planduring launch, the quality manager nolonger reports quality progress after a fewweeks—other than announcing when thenext quality event (inspection, test, etc.)will take place. Let’s say, at the projectpost-mortem, that a team dutifully collectsthe quality data needed for the nextlaunch, but notes in the lessons learnedthat they “need to do a better job on thequality plan in the future.” In my experi-ence, there are few key reasons for thisfall-off of the quality focus:• The team has not collected sufficient
historical data for defect injection andremoval; they utilize the by-the-book
numbers provided by the SEI, but donot really believe them because theyare not their numbers.
• Historical averages blend the results ofhigh performers with average or lowperformers. Depending upon who isworking on a module or series ofmodules, the predictions may or maynot truly represent the work beingdone, so the team doesn’t trust them—and certainly does not use the predic-tions to guide their work.
• Defect injection rates (DIRs) are basedupon the effort estimate for each mod-ule; while TSP teams are great at usingEarned Value techniques to balanceworkloads to meet their estimates, notevery module is accurately estimated,making the defect injection numberssuspect.
• Team members are not consistentlycollecting defect data; either individu-als are counting defects differently orthey are not measuring them at all,making any defect prediction modelinaccurate, and thus, unusable.
• When actual data begins to come in,the quality manager, team leader, andsometimes even the coach don’t reallyknow what to make of it (e.g., does alower number of defects than expect-ed mean the team is just very good, orthat the quality activity was badly exe-cuted?).These issues can be addressed by two
basic practices: 1) consistently collectingdata; and 2) properly using the concepts ofvariability in developing and tracking thequality plan. What follows is an examina-tion of some simple ways to ensure qualitydata are consistently and properly collect-ed, and a discussion of how to use MonteCarlo simulation to account for inherentprocess variability—in turn making thequality plan more accurate and usable.
Consistent Data CollectionFrom an examination of the data of 10randomly selected PSP students fromvarious classes over a five-year period, itbecomes obvious that the rate of defects
Updating the TSP Quality Plan Using Monte Carlo Simulation
David R. Webb309th Software Maintenance Group
The 309th Software Maintenance Group at Hill AFB has started implementing an updated version of the TSP qualityplan utilizing Monte Carlo simulation. This article presents an overview of why an updated quality plan with variability isneeded, what data the model requires to be useful, and how the new model works. Actual data from Hill AFB projects thathave implemented this method are presented for review.

Updating the TSP Quality Plan Using Monte Carlo Simulation
July/August 2010 www.stsc.hill.af.mil 15
injected per hour varies widely by person(averaging 0-60 per hour); even the plotsof the averages of defect injection rates indesign (averaging from 0-30 per hour) andcode (averaging from 2-10 per hour) showthat every person is different—sometimesvastly different.
While some of this variability has to dowith individual capabilities, the program-ming environment used, the difficulty ofthe assignment, and personal coding styles,much of it also has to do with commonoperational definitions and recording prac-tices. Anyone who has taught a PSP classhas noticed that not everyone fills out theirdefect logs the same way: Some studentsrecord several missing semi-colons as asingle defect then fix them all at once,while others count each semi-colon as anindividual defect with distinct fix times.Most instructors allow this individual styleof defect logging, as long as the student isconsistent in the method used; however,when determining team defect injectionrates, this kind of instability in definitionsand recording methods can cause a predic-tion model to behave erratically. This leadsthe observer to doubt the validity of usingpersonal defect logs, unless all engineersare somehow coerced into using identicallogging techniques.
Another reason to suspect that per-sonal defect data may not be the best fitfor a quality prediction model can be seenin the actual project data. The distribu-tions in personal defect logs were collect-ed over an 18-month period from a TSPteam at Hill AFB. During this project’sexecution, the variability in personaldefect logging noted in the classroom datadid not stabilize or become more consis-tent. The most disturbing trend in thesedata is the severe lack of personallyrecorded data, as evidenced by the num-ber of engineers with data from only onemodule or no defects logged at all. It isimportant to note that these data comefrom a team with strong coaching and aheavy quality focus (they have neverreleased a major defect).
For these reasons, it appears to beundesirable to use personal defect log datafor defect injection analyses. That beingthe case, the question becomes: Whatkinds of data would make sense?Interviews with the engineers on thenoted project (as well as other TSP pro-jects at Hill) suggest that more consisten-cy may be found in defect data frominspection and test databases. These pub-lic databases require more strict control toensure that defects are properly identified,analyzed, addressed, and tracked. Thistypically requires users to enter data
according to a defined procedure and touse common definitions for defects anddefect types. This kind of control seemsto drive more stable operational defini-tions and data recording practices thanevidenced in the personal defect logs.
When looking at the design and codeinspection data from our TSP project, itshows that the distributions are muchtighter than those in the personal logswithout the problem of a lack of record-ed data. That being said, there is still somevariability in the data—in this case, higherin the code inspections than the designinspections. For example, the average DIRon both the design and code review data istoward the lower end of the distribution,suggesting a skewed normal or lognormaldistribution in defect injection rates.
Therefore, a possible conclusion ofthis analysis is that personal defect logdata is not as useful in creating a qualitymodel for the quality plan as is data frompublic databases, such as the inspectionand test databases. However, even in thesedata, the defect injection rates display acertain amount of variability that shouldbe accounted for in our quality model.
One very important note here is thatthis analysis should not be used to suggestor validate the idea that personal defectlogs are not useful. Several engineers inter-viewed found them very useful for per-sonal improvement—they simply are notconsistent from person to person, makingthe data unusable for team modeling pur-poses. Strict coaching and quality manageroversight, focusing on common opera-tional definitions and recording proce-
dures, may make these data more usable.
Monte Carlo SimulationOne method of taking into account thevariability of the defect injection ratesand yields in a quality model would beusing a technique called Monte Carlosimulation. The Monte Carlo method isany technique using random numbers andprobability distributions to solve problems[3, 4], using the brute force of computa-tional power to overcome situations wheresolving a problem analytically would bedifficult. Monte Carlo simulation iterative-ly uses the Monte Carlo method manyhundreds or even thousands of times todetermine an expected solution.
The basic steps of Monte Carlo are asfollows:1. Create a parametric model.2. Generate random inputs.3. Evaluate the model and store the
results.4. Repeat steps 2 and 3 many, many
times.5. Analyze the results of the runs.
This is useful in creating a form of pre-diction interval around an estimate. Forexample, assume the number of defects ina software product (in the design phase ofdevelopment) can be predicted by multi-plying the historical defects injected perhour by the number of hours estimatedfor the phase. We can improve that esti-mate by using the ratio of historically esti-mated hours to actual hours, known as theCost Productivity Index (CPI). The CPI
TSP (v1) Rollup Plan Summary Quality Summary
Plan Actual
Code Review 28.5Code Inspection 5.51
Inspection/Review Rates
Defects/KLOC Plan Actual
Detailed Design Review 164Detailed Design Inspection 49.1Code Review 395Compile 87.9Code Inspection 61.6Unit Test 31.1Build and Integration Test 2.76System Test 0.55
Total Development 1038Total 1.04
Defect Density
Plan Actual
Percent Appraisal COQ 32.70%
Percent Failure COQ 4.69%
Cost of Quality (COQ)
Appraisal/Failure Ratio 6.98
Plan Actual
Requirements Review 70%
Requirements Inspection 70%
High-Level Design (HLD) Review 70%
HLD Inspection 70%
Detailed Design Review 70%
Code Review 70%
Compile 50%
Code Inspection 70%
Unit Test 90%
Build and Integration Test 80%
Phase Yields
System Test 80%
Defects Injected per Hour Plan Actual
Requirements 0.25
HLD 0.25
Detailed Design 0.75
Code 2
Compile 0.3
Unit Test 0.07
Defect Injection Rates
Table 1: Sample TSP Quality Plan Created During Meeting 5
Continued on Page 18

16 CROSSTALK The Journal of Defense Software Engineering July/August 2010
The 2010 Systems and Software Technol-ogy Conference (SSTC), held April 26-
29 in Salt Lake City, explored various tech-nologies which are expected to make abruptchanges to common thought. Participantsexplored the tools, processes, and ideaswhich will change the game and make theway we have done things in the past obsolete.
The SSTC kicked off with Mondaytutorials ranging from people technology toAgile software and systems engineering.After opening general session remarks byBrig Gen John B. Cooper, Commander ofthe 309th Maintenance Wing, afternoonsessions focused on assurance/securityissues, modernizing systems and software,new processes, and lessons learned.
Along with a full slate of presentations,Tuesday marked the start of the alwayspopular two-day trade show, includingbooths from IBM, INCOSE, the SEI, andthe Software Technology Support Center—the organization behind CrossTalk.
Wednesday proved to be the mostaction-packed day for conference-goers,from the plenary breakfast sessions ... topresentations ... to the trade show luncheon... to dinner and the a cappella singing groupVoice Male.
As with previous years, there were sev-eral CrossTalk authors representedamong the presenters. There was also somegood follow-up work during the plenarysessions: Dr. Azad Madni’s “IntegratingHumans with Software and Systems” was agreat companion piece to CrossTalk’sSoftware Human Capital-themed May/June2010 issue; and Dr. Robert Cloutier’s“Evolutionary Capabilities Developed andFielded in Zero to Nine Months” presentedan extended and updated version of hisMay/June 2009 CrossTalk article (withPortia Crowe) of the same name.
Information for the 2011 conferencewill begin appearing in your e-mail and mail-boxes beginning in late August with the“Call for Speakers” brochure. We can’t waitto start reading those abstracts!
Technology: Changing the GameThe 22nd Annual Systems and Software Technology Conference
Photography by Drew Brown, Marek Steed,and Bill Orndorff
Brig Gen John B. Cooper gives the opening general session remarks.
Marek Steed, CrossTalk article coordinator(far right), talks with visitors at the Software Tech-nology Support Center trade show booth.SSTC attendees in-between track sessions.

July/August 2010 www.stsc.hill.af.mil 17
Above: David R. Webb (right) of the 309th Software Maintenance Group and CrossTalk publisherKasey Thompson (left) present “Combining TSP, CMMI, Project Management, and People Skills to CreateBetter Software” with Larry W. Smith (unpictured).Right: Lt. Col. Scott Brown of the Directorate of Science, Technology & Engineering leads a panel dis-cussion of software technology readiness levels and assessments.Bottom Right: Hillel Glazer of Entinex expands on his January/February 2010 CrossTalk arti-cle “Love and Marriage: Why CMMI and Agile Need Each Other.”
Wednesday’s dinner social.Conference-goers enjoy the trade show.

Catching Up With TSP
18 CROSSTALK The Journal of Defense Software Engineering July/August 2010
represents how well tasks have been esti-mated in the past; a number near 1 meansthat estimates have been fairly accurate inthe past; a number greater than 1 tells usthat we tend to overestimate; a number lessthan 1 says we typically underestimate ourtasks. Dividing the estimated hours by theCPI will compensate for any tendencies toover- or underestimate. Thus, our finalprediction equation for design defectsinjected is the DIR for design multipliedby the number of estimated hours in thedesign phase, divided by the CPI fordesign. This is the parametric model need-ed for step 1 of the simulation:
d = DIRdesign x Hoursdesign ÷ CPIdesign
In step 2, we need to generate randominputs to the DIR and CPI variables of theequation, since these are parameters thatare subject to variability in our historicaldata3. The question is: Where do we getthese random values from? The answer canbe found by examining each of the vari-
ables. For example, the typical TSPapproach to estimating design defectswould be to use the average historical val-ues for the DIR and CPI, as defined inTable 2. The only problem with thatapproach is that, while the average DIR indesign is 2.1, it can vary from 1 to 5, in alognormal fashion. Additionally, the histor-ical data in Table 2 shows that the averageCPI for design is 1, but it varies from 0.5 to1.5 according to a normal curve. With thisin mind, we would use these distributionsto generate our random input data for step2 of the Monte Carlo process. Having esti-mated that 8.3 hours will be spent indesign, we randomly select values fromeach of these distributions, choosing 0.88defects per hour for the DIR and a value of1.12 for the CPI. Therefore:
d = 0.88defects/hour x 8.3hours ÷1.12 = 6.52defects
This gives us the value of 6.52 defects,which is how we evaluate the model andstore the results for step 3 of the process.
Step 4 of the Monte Carlo processsimply requires repeating steps 2 and 3many, many times—each time storingaway the newly generated answers. Let’ssay we do 10,000 of these calculationsand store them all away; when complete,we will have built up a new distributionfor “d”, the results of the equation.
Step 5 of this process is examining thedistribution of the results to determinewhat we can learn. In Figure 1, we can seethat the answers from our equation usingthe Monte Carlo process fall into a lognor-mal distribution, with a mean of 18.39defects and a standard deviation of 11.56.Further analysis of the data suggest that 70percent of the time, we should expect nomore than about 21 defects will be injectedin the design phase of our process. Thisprovides us a bit more insight than wewould see in a typical TSP quality plan. Forinstance, we now know that if there are
fewer than 21 design defects found duringour project, it’s not necessarily a bad thing;however, if we find more than this, say 40defects, something may be out of the ordi-nary (since that happens rarely). If we findmany more than 21 defects—200, forexample—then we can be pretty certain wehave an issue that needs to be addressed.The wonderful thing about this is that wecan determine these parameters at plan-ning—a concept that fits well with TSPprinciples and philosophies.
Using Monte Carlo Simulationfor the TSP Quality PlanThere are essentially five steps in modify-ing a TSP quality plan to take advantageof the previously described Monte Carlosimulation techniques:1. Gather historical data and determine
distributions for the DIR, yield, andCPI.
2. Modify the equations that determinedefect injection, defect removal,defects remaining, and any other met-rics important to the team.
3. Run the Monte Carlo simulation usingestimates for hours per process phaseand the distributions for the DIR,yield, and CPI.
4. Examine the results, determine howwell project goals are addressed, andcome up with next steps for the project.
5. Use this plan to guide and track theproject’s quality progress.
Gathering Historical Data andDetermining DistributionsThe first step is fairly straightforward forTSP projects that have been using theprocess for a while and have post-mortemdata available. The team simply needs togather data on the DIR, yield, and CPI fora number of past projects to determinethe actual distributions of data. This canbe done on a project-by-project basis, orby module, capability, or build (as desired).In Figure 2, the actual data from a HillAFB project are listed as Baseline ChangeRequests (BCRs) and represent codechanges made to an existing softwarebaseline over 18 months. In this example,the team used Oracle Crystal Ball (aspreadsheet-based application suite forpredictive modeling) to determine the dis-tributions of each set of data.
Once the data gathering and analysishave been done, the team must determinethe quality planning parameters4, as shownin Table 3.
Modifying the EquationsCurrently, the TSP quality plan predicts
Project
Average
P1
P2
P3
P4
P5
P6
P7
P8
P9
P10
P11
P12
P13
P14
P15
DIR-Design
2.10
1.02
1.33
2.06
1.13
5.00
2.50
1.30
4.10
3.20
1.08
1.00
1.62
1.88
3.10
1.23
CPI-Design
0.50
1.15
0.67
0.88
0.96
1.35
1.50
0.62
1.50
1.38
0.98
0.89
0.78
0.88
0.92
1.00
Table 2: DIR and CPI Notional HistoricalData
Figure 1: Sample Distribution of Results from Monte Carlo Simulation of Defects Injected in Design
Continued from Page 15
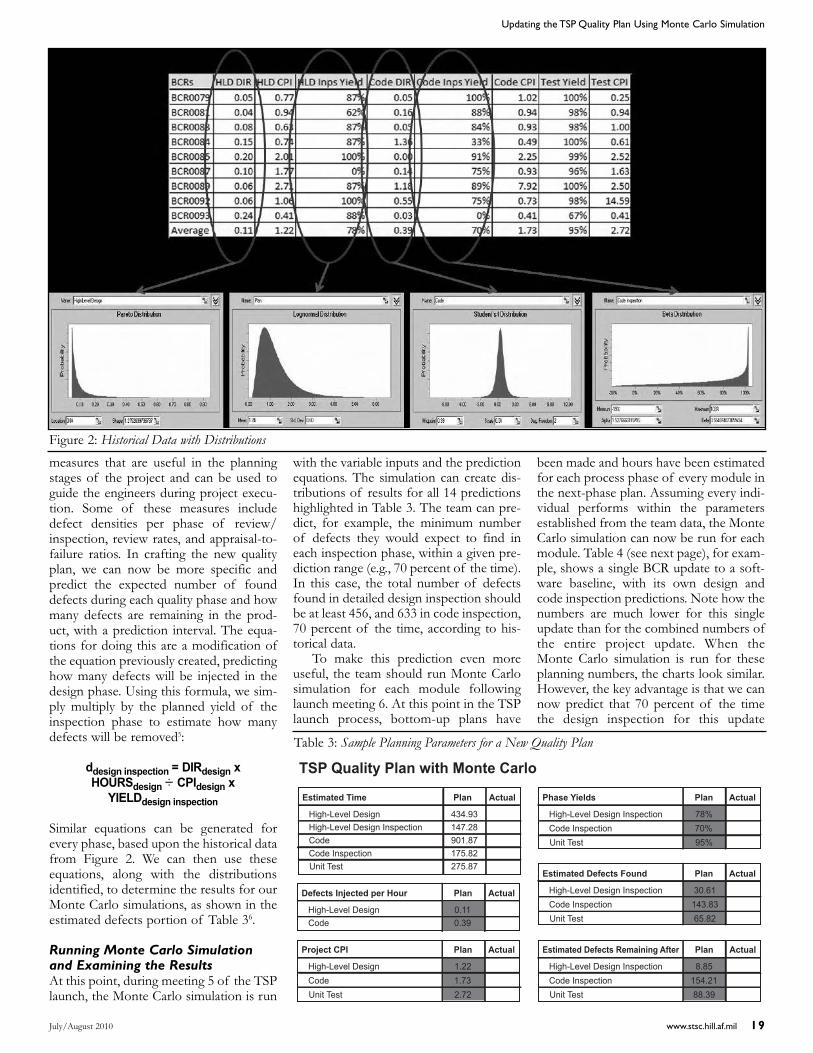
Updating the TSP Quality Plan Using Monte Carlo Simulation
July/August 2010 www.stsc.hill.af.mil 19
measures that are useful in the planningstages of the project and can be used toguide the engineers during project execu-tion. Some of these measures includedefect densities per phase of review/inspection, review rates, and appraisal-to-failure ratios. In crafting the new qualityplan, we can now be more specific andpredict the expected number of founddefects during each quality phase and howmany defects are remaining in the prod-uct, with a prediction interval. The equa-tions for doing this are a modification ofthe equation previously created, predictinghow many defects will be injected in thedesign phase. Using this formula, we sim-ply multiply by the planned yield of theinspection phase to estimate how manydefects will be removed5:
ddesign inspection = DIRdesign xHOURSdesign ÷ CPIdesign x
YIELDdesign inspection
Similar equations can be generated forevery phase, based upon the historical datafrom Figure 2. We can then use theseequations, along with the distributionsidentified, to determine the results for ourMonte Carlo simulations, as shown in theestimated defects portion of Table 36.
Running Monte Carlo Simulationand Examining the ResultsAt this point, during meeting 5 of the TSPlaunch, the Monte Carlo simulation is run
with the variable inputs and the predictionequations. The simulation can create dis-tributions of results for all 14 predictionshighlighted in Table 3. The team can pre-dict, for example, the minimum numberof defects they would expect to find ineach inspection phase, within a given pre-diction range (e.g., 70 percent of the time).In this case, the total number of defectsfound in detailed design inspection shouldbe at least 456, and 633 in code inspection,70 percent of the time, according to his-torical data.
To make this prediction even moreuseful, the team should run Monte Carlosimulation for each module followinglaunch meeting 6. At this point in the TSPlaunch process, bottom-up plans have
been made and hours have been estimatedfor each process phase of every module inthe next-phase plan. Assuming every indi-vidual performs within the parametersestablished from the team data, the MonteCarlo simulation can now be run for eachmodule. Table 4 (see next page), for exam-ple, shows a single BCR update to a soft-ware baseline, with its own design andcode inspection predictions. Note how thenumbers are much lower for this singleupdate than for the combined numbers ofthe entire project update. When theMonte Carlo simulation is run for theseplanning numbers, the charts look similar.However, the key advantage is that we cannow predict that 70 percent of the timethe design inspection for this update
Figure 2: Historical Data with Distributions
Estimated Time Plan Actual
High-Level Design 434.93
High-Level Design Inspection 147.28
Code 901.87
Code Inspection 175.82
Unit Test 275.87
TSP Quality Plan with Monte Carlo
Project CPI Plan Actual
High-Level Design 1.22
Code 1.73
Unit Test 2.72
Defects Injected per Hour Plan Actual
High-Level Design 0.11
Code 0.39
Phase Yields Plan Actual
High-Level Design Inspection 78%
Code Inspection 70%
Unit Test 95%
Estimated Defects Found Plan Actual
High-Level Design Inspection 30.61
Code Inspection 143.83
Unit Test 65.82
Estimated Defects Remaining After Plan Actual
High-Level Design Inspection 8.85
Code Inspection 154.21
Unit Test 88.39
Table 3: Sample Planning Parameters for a New Quality Plan

20 CROSSTALK The Journal of Defense Software Engineering July/August 2010
Catching Up With TSP
should find at least three defects (althoughit would not be unusual for the codereview to find zero). This gives us someindication of the goodness of the inspec-tions and a lower limit that we can look forduring the execution of the project.Likewise, in the unit test for this change,we should find no more than 12 defects,70 percent of the time (see Figure 3). Inthis case, we look for the upper limit, sinceour goals are to find more defects ininspections than in testing.
Guiding and Tracking Project ProgressOnce the TSP launch is complete and theplans are approved by management, theteam uses these plans to guide their work.The team also checks progress against theplans during their weekly meetings. Thequality manager, for example, reports onthe current defect injection rates andyields for modules complete to date. He orshe also provides feedback on the currentproduct quality index, defect removal pro-file, and so forth (as shown in Table 1).
With the new Monte Carlo-generatedquality plan, the quality manager has addi-tional information to present at the weeklymeetings. For example, he or she could pre-sent how many defects have actually beenfound in inspection or test activities—ver-sus those predicted by the model. Anothernew metric is an updated estimate of thepredicted defects remaining, easily calculat-ed taking the estimates for defects injectedand subtracting the estimates for defectsremoved. Once actual project quality databegins to come in, these models can beused again—this time replacing the esti-mated values with actual values and rerun-ning the simulation. This provides a newprediction for defects remaining that canbe tracked throughout the project duration.
It is important to point out that thisnew way of examining and predicting thequality of the product in no way supplantsthose currently being used by TSP pro-jects. This is simply one more weapon toadd to the quality arsenal.
SummaryA TSP quality plan is a very effective wayof focusing a team on the tracking andresolution of defects early in the projectlife cycle. However, the current version ofthe plan does not take into account vari-ability. Applying Monte Carlo simulationto data already being collected by TSPteams provides a more robust insight intothe quality processes TSP teams employ.It also gives further insight into what canbe expected in terms of product andprocess quality. The TSP teams at HillAFB recently started using this techniqueand are still gathering data on its useful-ness.u
References1. Humphrey, Watts S. TSP – Leading a
Development Team. Upper Saddle River,NJ: Addison-Wesley, 2006. Page 138.
2. Humphrey, Watts S. TSP – Leading aDevelopment Team. Upper Saddle River,NJ: Addison-Wesley, 2006. Page 87.
3. Weisstein, Eric W. “Monte CarloMethod.” Wolfram MathWorld. <http://mathworld.wolfram.com/MonteCarloMethod.html>.
4. Wittwer, J.W. “Monte Carlo Simula-tion Basics.” Vertex42. 1 June 2004<http://vertex42.com/ExcelArticles/mc/MonteCarloSimulation.html>.
Notes1. The best resource to learn about TSP’s
numbered meetings and quality plansis Watts S. Humphrey’s Nov. 2000report “The Team Software Process.”Section 7.1 discusses quality plans. See
Est. Time Plan Actual
High-Level Design 84
High-Level Design Inspection 21
Code 62
Code Inspection 25
Unit Test 14
TSP Quality Plan with Monte Carlo (Single BCR)
Project CPI Plan Actual
High-Level Design 1.22
Code 1.73
Unit Test 2.72
Defects Injected per Hour Plan Actual
High-Level Design 0.11
Code 0.39
Phase Yields Plan Actual
High-Level Design Inspection 78%
Code Inspection 70%
Unit Test 95%
Est. Defects Found Plan Actual
High-Level Design Inspection 5.91
Code Inspection 9.89
Unit Test 5.57
Est. Defects Remaining After Plan Actual
High-Level Design Inspection 1.71
Code Inspection 11.70
Unit Test 6.13
Table 4: Sample TSP Quality Plan for a Single Update
The software defense community will benefit from utilizing the proposed TSP qual-ity plan update, as this article shows how to determine and apply variability into theplan through Monte Carlo simulation. Users will be able to predict product andprocess quality at stages throughout the life cycle and at delivery. It will also help inmeeting requirements for Quantitative Project Management and OrganizationalProcess Performance at CMMI Level 4. These methods closely track product andprocess quality, providing tools for project managers in avoiding cost and schedulepitfalls—and in delivering near zero-defect products.
Software Defense Application
Figure 3: Estimated Maximum Defects Found in a Unit Test for a Single BCR

Updating the TSP Quality Plan Using Monte Carlo Simulation
July/August 2010 www.stsc.hill.af.mil 21
<www.sei.cmu.edu/reports/00tr023.pdf>.
2. For more on this method, see <www.stsc.hill.af.mil/CrossTalk/2007/08/0708Schofield.html>.
3. Let us assume here that we determinedhours earlier via Proxy-Based Estima-tion (PROBE) or other estimatingmodel.
4. Don’t be confused by the values yousee in the shaded cells. Each of thehighlighted cells for defects injectedper hour, CPI, and yield in Table 2 ini-tially contain an average value, similarto the current TSP quality plan; how-ever, this value is replaced by the toolwith random values from the distribu-tions in Figure 2 when the MonteCarlo simulation is run.
5. In this situation, yield must be a deci-mal number between 0 and 1 insteadof 0 and 100 percent.
6. The highlighted cells for “estimateddefects found” and “estimated defectsremaining after” in this table show theresults of the parametric equationsusing the average values; these arereplaced with the results of the calcu-lations using random values from thedistributions, during the Monte Carlosimulation.
About the Author
David R. Webb is aTechnical Director forthe 520th Software Main-tenance Squadron of the309th Software Mainte-nance Group at HillAFB, Utah. Webb is a
project management and process im-provement specialist with 22 years oftechnical, program management, andprocess improvement experience in AirForce software. Webb is an SEI-autho-rized PSP instructor, a TSP launchcoach, and has worked as an Air Forcesection chief, software engineeringprocess group member, systems softwareengineer, and test engineer. He is a fre-quent contributor to technical journalsand symposiums, and holds a bachelor’sdegree in electrical and computer engi-neering from Brigham Young University.
7278 4th STBLDG 100Hill AFB, UT 84056Phone: (801) 586-9330E-mail: [email protected]
Get Your Free Subscription
Fill out and send us this form.
517 SMXS/MXDEA
6022 Fir Ave
Bldg 1238
Hill AFB, UT 84056-5820
Fax: (801) 777-8069 DSN: 777-8069
Phone: (801) 775-5555 DSN: 775-5555
Or request online at www.stsc.hill.af.mil
NAME:________________________________________________________________________
RANK/GRADE:_____________________________________________________
POSITION/TITLE:__________________________________________________
ORGANIZATION:_____________________________________________________
ADDRESS:________________________________________________________________
________________________________________________________________
BASE/CITY:____________________________________________________________
STATE:___________________________ZIP:___________________________________
PHONE:(_____)_______________________________________________________
ELECTRONIC COPY ONLY? YES NO
E-MAIL:__________________________________________________________________
CHECK BOX(ES) TO REQUEST BACK ISSUES:
OCT2008 o FAULT-TOLERANT SYSTEMS
NOV2008 o INTEROPERABILITY
DEC2008 o DATA AND DATA MGMT.
JAN2009 o ENG. FOR PRODUCTION
FEB2009 o SW AND SYS INTEGRATION
MAR/APR09 o REIN. GOOD PRACTICES
MAY/JUNE09 o RAPID & RELIABLE DEV.
JULY/AUG09o PROCESS REPLICATION
NOV/DEC09 o 21ST CENTURY DEFENSE
JAN/FEB10 o CMMI: PROCESS
MAR/APR10 o SYSTEMS ASSURANCE
MAY/JUNE10 o SW HUMAN CAPITAL
To request back issues on topics notlisted above, please contact <[email protected]> .

22 CROSSTALK The Journal of Defense Software Engineering July/August 2010
The ITMPI’s Fall Webinars andConferences www.itmpi.org/webinarsNow is a good time to sign up for the IT Metrics &Productivity Institute’s (ITMPI’s) free fall Webinars.Forthcoming Webinars include: ways to revolutionize thetesting process with decision model; a “re-education” inbasic and advanced software engineering principles; a “how-to” for organizations that want to become Agile; guidanceon preparing an organizational training plan; increasingproductivity through social networking; case studies fromtest assessments; guidelines on maintenance, support, andenhancement; and techniques, processes, and strategies toimprove bad project planning. The ITMPI will also haveall-day Webinars live from their Software Best Practicesconferences in Baltimore (Sept. 14), Detroit (Sept. 28),Tallahassee (Oct. 7), Orlando (Oct. 13), Philadelphia (Oct.21), and Rochester (Oct. 27).
Ahead in the Clouds www.mitre.org/work/info _tech/cloud _computingWhat are the essential components or capabilities necessaryto create a private cloud computing environment? Whatcan organizations do to facilitate the adoption of cloudcomputing to more effectively provide IT services? What isthe most significant concern for federal organizations who
want to use cloud computing? “Ahead in the Clouds” is theMITRE Corporation’s public forum to provide federal gov-ernment agencies with meaningful answers to commoncloud computing questions like these, drawing from leadingthinkers in the field. New questions are posed—and thenindustry experts chime-in with detailed responses.
Grady Booch Interviews Watts S.Humphrey http://archive.computerhistory.org/resources/access/text/Oral _History/102702107.05.01.acc.pdfWith this issue’s article and interview with Watts S.Humphrey—and CrossTalk’s interview with GradyBooch appearing in our November/December 2010 edi-tion—why not learn about what happened when the twolegends met? The Computer History Museum sponsoredthis three-day (and eventually 184-page) oral history inter-view, by a developer of UML, of the man who developedthe CMM, PSP, and TSP. Topics include his upbringing,formative years, time at Sylvania and NortheasternUniversity, and his challenges in building a computergroup. Also included is a thorough examination of the IBMyears and, of course, his move to the SEI, discussing theCMM and CMMI and how his famed software processestook shape. Humphrey also talks about his family, andlooks into the future of software.
WEB SITES
Departments

July/August 2010 www.stsc.hill.af.mil 23
Since the emergence of software engi-neering in the 1960s, the size, pervasive-
ness, and complexity of software-intensivesystems have increased by several orders ofmagnitude. The size of aircraft softwaresystems in the 1960s approximated 1,000lines of code while aircraft systems built in2000 contained more than six million linesof code. The pervasiveness of softwarewithin aircraft systems has increased fromcontrolling less than 10 percent of thefunctions the pilot performed in the 1960sto 80 percent in 2000 (as shown in Figure 1on the following page).
We know that increases in software andsystem size contribute to increased com-plexity which, in turn, has contributed topushing delivery and costs well beyond tar-geted schedules and budgets [1].
In a recent workshop conducted by theNational Defense Industrial Association,the top issues relative to the acquisition anddeployment of software-intensive systemswere identified. Among them are:• The impact of system requirements
upon software is not consistently quan-tified and managed in development orsustainment.
• Fundamental systems engineering deci-sions are made without full participa-tion of software engineering.
• Software life-cycle planning and man-agement by acquirers and suppliers isineffective.So the biggest challenge is creating the
right foundation: estimation, planning,development, and management practices aswell as team processes, training, coaching,and operational support that will assist in amigration from buggy products and unnec-essary rework (resulting in inflating devel-opment costs) to a proactive approach thatbuilds integrated, quality software-intensivesystems from requirements to field deploy-ment.
BackgroundThe SEI’s TSP provides engineers witha structured framework for doing soft-ware engineering work. It includesscripts, forms, measures, standards, andtools that show software engineers howto use disciplined processes to plan,measure, and manage their work [2].The principal motivator for the TSP isthe conviction that engineering teams
can do extraordinary work if they areproperly formed, suitably trained,staffed with skilled members, and effec-tively coached and led.
The TSP is already being used withgreat results on software teams [3]. AMicrosoft study reported that by usingthe TSP, software teams cut scheduleerror from 10 to one percent. With itsTSP teams, Intuit has increased by 50percent the time that teams can spendin developing products during a typicalyear-long release cycle: Increased quali-ty has dramatically cut the testing timerequired. An analysis of 20 projects in
13 organizations showed TSP teamsaveraged 0.06 defects per thousandlines of new or modified code.Approximately one-third of these pro-jects were defect-free. Other studiesshow that TSP teams delivered theirproducts an average of just six percentlater than planned. This comparesfavorably with industry data showingthat more than half of all software pro-jects were more than 100 percent late—or were cancelled. These TSP teamsalso improved their productivity (sizeof developed code per hour of devel-opment time) by an average of 78 per-cent.
NAVAIR develops, acquires, andsupports the aircraft and relatedweapons systems used by the U.S. Navyand Marine Corps. In recent years, inter-est in applying TSP to non-softwaredomains has increased. The SEI TSPteam has collaborated with NAVAIR toexpand the TSP to teams that do otherengineering along with software. Theseinclude areas such as systems engineer-ing and integration, product integrity,CM/DM/QA (Configuration Manage-ment/Data Management/Quality Assur-ance), and process improvement itself.
NAVAIR already has a proven trackrecord with the TSP and has demon-strated return on investment on theirsoftware projects [4, 5]. Table 1 (on thefollowing page) shows TSP results fromtwo NAVAIR programs: the AV-8B’sJoint Mission Planning System (JMPS)program and the P-3C program. Thisresult, due to the reduction in defectdensity, is a gross savings of $3,225,606($3,782,153 less the investment of$556,547). In turn, the ROI is derivedfrom the cost savings compared to thecost of initially putting the TSP inplace; in this case, it was a ratio of bet-ter than 7 to 1. Further, these organiza-tions each reached CMM Level 4 in less
Extending the TSP to Systems Engineering:Early Results from Team Process Integration
A collaboration between the SEI and NAVAIR—Team Process Integration (TPI SM)—is currently underway. The TPIeffort leverages the PSP and TSP research and body of practice. This article discusses the progress and performance througha pilot project with the AV-8B Systems Engineering team as well as others within NAVAIR that have utilized TPI innon-software domains. This article will share lessons and experiences with other industry/government organizations interest-ed in applying the TSP in a non-software setting. The early results suggest some encouraging trends.
Del Kellogg and Jeff SchwalbNAVAIR
Anita CarletonSEI
“The principal motivatorfor the TSP is theconviction that
engineering teams cando extraordinary work
if they are properlyformed, suitably trained,
staffed with skilledmembers, and effectively
coached and led.”
SM TPI is a service mark of Carnegie Mellon University.

Catching Up With TSP
24 CROSSTALK The Journal of Defense Software Engineering July/August 2010
than 30 months—instead of the typicalsix years.
Very similar results occurred withother programs at that time, like with theE-2C aircraft program, also achievingCMM Level 4 in less than 30 monthswith their development teams using theTSP at the same time. Most recently (Jan.2010), the H1 aircraft program workedless than 20 months to obtain a CMMILevel 3 rating while their developmentteam used TSP to maintain aircraft soft-ware for the fleet.
The organizations referenced havestandardized the TSP for all of theirsoftware development and maintenancework. These early adopters of the TSPare meeting their mission of producinghigher quality products while maintain-ing significant cost savings. Their devel-opment teams now like using the TSP,saying of their staffs, “Once they haveadopted it, they can’t imagine workingany other way.” In all presented cases, theinitial investment was returned in theirfirst project and has then gone forwardtime and again to benefit the organiza-tions for many years.
Results from these examples continueto inspire other NAVAIR System SupportActivities (SSAs) to use the TSP. There aremore than 20 additional NAVAIR SSAsnow pursuing software process improve-ment activities. NAVAIR is seeing recurringsavings and can now direct cost savings to
the procurement of additional aircraft andweapons. In addition, NAVAIR used theTSP to accelerate CMMI improvement.
Starting TPI EffortsBased on the demonstrated, measuredsuccess of software projects using theTSP in NAVAIR, other teams asked ifthey could apply the same processes tosystems engineering and software/systemsacquisition projects. As a result, NAVAIRhas teamed with the SEI to expand theTSP framework to a technology calledTPI. The SEI is also receiving additionalrequests to apply the TSP to non-softwaresettings since it is becoming increasinglydifficult to solve software problems with-out addressing systems engineering issues.
The NAVAIR/SEI collaborationentails testing the hypothesis that we canachieve the same kind of performanceimprovements applying TPI to systemsengineering as we did applying the TSP tosoftware projects, thereby improving man-agement and communications in software-intensive systems and acquisitions. Ourapproach will entail conducting a series ofpilot projects to determine if extendingTSP practices to systems engineeringresults in measurable improvement. Wewill then use the results of this work toestablish common processes for both sys-tems and software engineering across theNAVAIR teams. Initially, the AV-8B JointSSAs (developing the Harrier Aircraft)
was selected as the systems engineeringpilot program.
In kicking off these efforts, we real-ized that there were a number of researchchallenges that specifically had to beaddressed. We extended the TSP practicesto systems engineering by:• Determining the baseline performance
for systems engineering work atNAVAIR.
• Developing prototype processes/process definitions/scripts for systemsengineering.
• Formulating relevant measures, espe-cially size and quality measures perti-nent to systems engineering.
• Building conviction and discipline inour leadership and team member train-ing materials for teams that don’t nec-essarily write software programs.
• Developing an extensible tool thatallows for outlining any process, forcollecting data unobtrusively, and fordefining a measurement frameworkpertinent to any engineering domain.Early results of applying TPI show
some encouraging trends. The AV-8BSystems Engineering pilot project team ischanging the way they do their work and isbeginning to see some results similar tothose realized by TSP teams. The AV-8Bteam is practicing more disciplined meth-ods for planning and executing their work.They are meeting their missions andbeginning to see some cost savings. Inaddition, the pilot team is inspiring otherNAVAIR 4.0 SSAs to pursue processimprovement [6].
BenefitsThrough the pilot effort, we are seeingsome of the following benefits:
Establishment of a SystemsEngineering BaselineWe are beginning to establish a baselinefor systems engineering performance atNAVAIR that can be used for estimating,planning, and tracking projects and pro-grams:• The requirements productivity rate
varies between three and nine require-
0
10
20
30
40
50
60
70
80
90
F-4
1960
A-7
1964
F-111
1970
F-15
1975
F-16
1982
F/A-22
2000
Multi-yeardelays
associatedwith
softwareand systemstability
B-2
1990
Software andtesting delayspush costabove
Congressionalceiling
PercentofSpecificationRequirements
InvolvingSoftwareControl
Defect DensityBefore TSP
1.13
4.60
Defect DensityAfter TSP
0.59
0.60
Total DefectsBefore TSP
176
501
Total DefectsAfter TSP
261
23
AverageCost to Fix
$8,330
$8,432
Product Size(KSLOC)
443.0
38.3
Cost SavingsFrom Reduced
Defects
$1,992,663
$1,789,490
$3,782,153Total Savings:
Figure 1: Increasing Capabilities and Challenges of Software in DoD Systems 1
0
10
20
30
40
50
60
70
80
90
F-4
1960
A-7
1964
F-111
1970
F-15
1975
F-16
1982
F/A-22
2000
Multi-yeardelays
associatedwith
softwareand systemstability
B-2
1990
Software andtesting delayspush costabove
Congressionalceiling
PercentofSpecificationRequirements
InvolvingSoftwareControl
Defect DensityBefore TSP
1.13
4.60
Defect DensityAfter TSP
0.59
0.60
Total DefectsBefore TSP
176
501
Total DefectsAfter TSP
261
23
AverageCost to Fix
$8,330
$8,432
Product Size(KSLOC)
443.0
38.3
Cost SavingsFrom Reduced
Defects
$1,992,663
$1,789,490
$3,782,153Total Savings:
AV-JMPS
P-3C
Project
Table 1: TSP Results at NAVAIR

Extending the TSP to Systems Engineering: Early Results from Team Process Integration
July/August 2010 www.stsc.hill.af.mil 25
ment statements per hour, dependingon the complexity of the project2.
• By just tracking requirements sizegrowth, the team was able to decreasethe rate of project size growth from23.6 percent in the initial developmentcycle to 11.5 percent in the subsequentdevelopment cycle.
• By collecting the planned and actualrequirements size and growth for thevarious components and the team pro-ductivity rate, the team builds up his-torical data that can be used on futureprojects.
• To quote one team leader: “Prior toTPI, we made estimates in a bubble.Now we are establishing and maintain-ing baselines for all of our releases,which allow us to make better esti-mates and more realistic plans andschedules.”
Establishment of Planning PracticesPlanning at the program and team level isnow accomplished by holding multi-teamlaunches that involve all of the teamsimplementing either the TSP or TPI. Atfirst, they plan for no more than fourmonths of work at a time so that theirtasks can be detailed enough with fairlystable component sets. The componentsets start to vary for a longer developmentduration so their plan would be less stable.This process is used by the AV-8B pro-gram to understand requirements frommanagement, assemble plans, allocatework, and achieve commitment to plansfrom management and team members.The overall plan for the year and the next-phase plan are developed by the teams,work is allocated by the team, and theschedule is determined and committed toby team members.
Establishing Tracking PracticesFor tracking purposes, work is brokendown into small chunks that can easily betracked (tasks are tracked at a granularityof less than 10 hours). Tracking only thetask hours per week (planning for around20) allows two or three tasks to be com-pleted each week. Work is tracked daily byteam members and discussed weekly inteam meetings: Every team memberknows how they are performing to theirindividual plan and the team plan.Monthly status reports are derived fromthe consolidated weekly reports by theteam leader and presented to the integrat-ed product team leads.
Twelve team members were able toachieve (on average) between 18 and 22on-project task hours per week. The teamperformed well above the planned task
hours: 15 per week in the first cycle.The engineers embraced project plan-
ning and tracking. Each individual is ableto track personal commitments to theteam, enabling the team to better monitorcommitments to the program. Trackingthe work helped the team members withstaying on-task, commenting that: “I needto stop doing X to get back on track. It isvery easy to see the impact daily and week-ly of not working to the plan.”
Developing Standard Processes,Measures, and ToolsStandard processes, measures, terminol-ogy, and tools were developed and usedby the AV-8B Program:• The PSP-derived Excel spreadsheet
and a process support technologyAccess-based tool were used for esti-mating, planning, and tracking workfor team members and team leads.
• Team members identified, defined,and documented all systems engi-neering standard life-cycle processesin the tool. The team defined anddeveloped an 18-step overall systemsengineering process and a 482-stepdetailed systems engineering process.
• Through the defined processes,NAVAIR was able to maintain theconsistency of processes across pro-jects/programs. The defined processesalso offered the ability to cross-trainindividuals. One integrated productteam lead said: “We have a team con-cept across our program with all of thesub-teams (systems engineering, prod-uct integrity, software, test, lab, etc.).We also have a common set ofprocesses and metrics to help all of theteams better communicate and addressdependencies across the teams.”
Performance Trends With no historical data to go by, the team’sinitial plan identified a guess at a goal ofless than 5 percent schedule slip and mea-sured performance against the goal. Theactual performance had an overrun of lessthan 10 percent. Now with some historicaldata, the team can set more realistic goalsand try to continually improve on them.As far as cost and quality performance,size and effort estimates were within ±10percent of what was planned, and therewere no high-priority problem reportscoming out of test.
Employee Work/Life BalanceTPI helped improve employee work/lifebalance. In order to get their job donebefore implementing TPI, employees rou-tinely worked overtime. With TPI (and in
COMING EVENTS
August 23-25
The 13th IASTED International
Conference on Computers and
Advanced Technology in Education
Maui, HI
www.iasted.org/conferences/
home-709.html
September 13-16
Military Logistics Summit 2010
Washington, D.C.
www.militarylogisticssummit.com
September 13-17
PSQT 2010
Practical Software Quality and Testing
Minneapolis, MN
www.psqtconference.com/2010north
September 19-23
Oracle OpenWorld 2010
San Francisco, CA
www.oracle.com/us/openworld
September 26-October 1
STARWEST 2010
San Diego, CA
www.sqe.com/starwest
October 25-28
TechNet Asia-Pacific International
Conference and Exposition 2010
Honolulu, HI
www.afcea.org/events/asiapacific
October 31-November 3
MILCOM 2010
San Jose, CA
www.milcom.org
COMING EVENTS: Please submit coming events thatare of interest to our readers at least 90 daysbefore registration. E-mail announcements to:<[email protected]>.

Catching Up With TSP
26 CROSSTALK The Journal of Defense Software Engineering July/August 2010
order to get their 18-22 task hours perweek), they did not have to work as muchovertime. Overtime was decreased frombeing standard practice—sometimes 25percent or more—to occasional overtimehours (less than 10 percent).
Customer ResponsivenessCustomer responsiveness has improved tothe fleet, the naval aviators, and to theinternal program managers. The systemsengineering team is able to more easilyadapt to program and personnel changes.The pilots are beginning to provide inputearly on in the project—during the launchprocess—before the work has com-menced (instead of providing feedbackduring the test phases). Program manage-ment feels that the TSP/TPI efforts are asuccess because the teams understandtheir work and the dependencies amongall of the teams. The systems engineeringteam can also plan for a percentage ofunplanned tasks to use their data to nego-tiate impact and trade-offs of unplannedwork to planned work.
More Teams Doing TPIWe have since launched more non-soft-ware teams using the TPI approach. One
of these is a mixed engineering team atJoint Munitions Effectiveness MatrixWeaponeering Systems that is applyingthe TPI to their non-software work aswell as to their software team. This teamhas been using TPI for more than a year,has gone through four launch/relaunch-es, and has seen the types of benefitsthat the AV-8B team has seen. They alsoare seeing steady progress in makingmore accurate and precise estimates oftheir work, and have refined the triggersthat would initiate an adjustment of theirbehavior so they stay on schedule.
Another example is the PrecisionAttack Weapon System Tactical ProgramOffice, demonstrating the effectivenessof the TPI approach for one of theirsystems engineering teams. Their teamhas been using the TPI approach formore than a year and saw immediatebenefits. During the initial launch, theydeveloped a never-before-seen detailedplan that gave senior management theneeded data to get additional projectfunding without having to arm wrestle theProgram Manager, Air (PMA).
Then there is the P-3 lab team at thePatuxent River, Maryland Naval AirStation, who has been applying this
approach to the many configurations ofthe lab setup they must provide. The P-3team started applying TPI as anapproach to the implementation phase oftheir Black Belt DMAIC (or Define,Measure, Analyze, Improve, andControl) project. Since starting aboutthree years ago, the team has since pro-vided two annual cycles of lab servicesand is halfway through their third. TheP-3 lab team supports their customers byproviding more than a dozen lab config-urations across the PMA. This breaksinto two basic types of support: usage interms of running tests, and support interms of configuring labs for those tests.Aggregate lab usage data shows a devia-tion of 12 percent less than plannedwhile aggregate lab support data shows adeviation of .5 percent more thanplanned. While performance is impres-sive, deviation was at times greater whenexamined at the individual lab-customerlevel. As expected, this aggregate devia-tion demonstrates the advantage of esti-mating in smaller increments.
At the time of writing this article,several other process improvementefforts at NAVAIR are getting startedwith plans of applying TSP to their soft-ware teams and TPI to their non-soft-ware teams.
SummaryAll engineering efforts must start withintegrated teams. These teams must plantheir work—and work to those plans—while collecting basic measures. Theymust then apply analyses to this data andderive metrics to determine their status oncurrent work and, eventually, as a sourcefor improving their planning capability onfuture work. From this approach, we haveseen quality products and services deliv-ered over and over with the potential forfurther improvement.
To make this happen, we have seen theneed to put in place the TPI foundation ofestimation and planning processes, teamprocesses, development and managementpractices, effective and timely training, aswell as launch, coaching, and operationalsupport.
Projects that have adopted these meth-ods have shown a dramatic increase inproduct quality and fidelity of scheduleand effort estimates. The methods aresupported by a doctrine that trains andsustains performance and quality im-provement in an organization.
This article has shown what is possi-ble when teams use TPI to establish thisfoundation to meet critical businessneeds. The end result is the delivery of

Extending the TSP to Systems Engineering: Early Results from Team Process Integration
July/August 2010 www.stsc.hill.af.mil 27
About the Authors
Del Kellogg is a PSPCertified Developer, PSPCertified Instructor, andTSP Authorized Coachfor NAVAIR-China Lake.He has spent most of his
30 years at NAVAIR working on devel-opment of embedded software for theA-7E, AV-8B, and the AH-1W aircraft.He has applied the PSP and TSP for thelast nine years within multiple NAVAIRteams. He is currently working in theProcess Resource Team at NAVAIR.Kellogg’s background is in computer sci-ence, physics, and math, and received hisbachelor’s degree in computer sciencefrom the University of Idaho.
NAVAIR Systems/Software Support Center1900 N Knox RDBLDG 1494 (MS 6308)China Lake, CA 93555Phone: (760) 939-5494Fax: (760) 939-0150E-mail: [email protected]
Anita Carleton is asenior member of thetechnical staff at the SEI,Carnegie Mellon Univer-sity, where she has work-ed for more than 20 years
on software process improvement,process measurement, and the TSP. Sheis the author of “Measuring theSoftware Process: Statistical ProcessControl for Software Process Improve-ment.” Carleton has a degree in appliedmathematics from Carnegie MellonUniversity and is a member of the IEEEComputer Society and the NationalDefense Industrial Association.
SEI4500 Fifth AVEPittsburgh, PA 15213-2612Phone (412) 268-7718Fax: (412) 268-5758E-mail: [email protected]
Jeff Schwalb is em-ployed by NAVAIR atChina Lake, California,where he has been since1984. He currently leadsa NAVAIR enterprise
team that helps provide continuousprocess improvement support acrossNAVAIR. Schwalb first became involvedwith process improvement in the 1990susing the SW-CMM, then becoming acertified PSP instructor and TSP coach.He has taught each of the TSP/PSPcourses and has been involved in theTSP launch of several projects acrossNAVAIR. He is now working with theSEI to extend TSP practices into otherdomains. He received his bachelor’sdegree in computer science fromCalifornia State University, Chico.
NAVAIR Systems/Software Support Center1900 N Knox RDBuilding 1494 (MS 6308)China Lake, CA 93555-6106Phone: (760) 939-6226Fax: (760) 939-0150E-mail: [email protected]
high quality systems, on cost, and withimproved productivity.u
References1. Walker, Ellen. “Tech Views – Challen-
ges Dominate Our Future.” DACSSoftware Tech News. Oct. 2007 <www.softwaretechnews.com/stn_view.php?stn_id=43&article_id=86>.
2. Humphrey, Watts S. TSP: Leading aDevelopment Team. Upper Saddle River,NJ: Addison-Wesley Publishers, 2006.
3. Davis, Noopur, and Julia Mullaney. TheTeam Software Process (TSP) in Practice: ASummary of Recent Results. SEI,Carnegie Mellon University. TechnicalReport CMU/SEI-2003-TR-014. Sept.2003 <www.sei.cmu.edu/reports/03tr014. pdf>.
4. Wall, Daniel S., James McHale, andMarsha Pomeroy-Huff. Case Study:Accelerating Process Improvement byIntegrating the TSP and CMMI. SEI,Carnegie Mellon University. SpecialReport CMU/SEI-2005-SR-012. June2007 <www.sei.cmu.edu/reports/07tr013.pdf>.
5. Saint-Amand, David. Process Improve-ment at NAVAIR Using TSP and CMM.Proc. of the 1st Annual TSP Sympo-sium. San Diego: Sept. 2006.
6. Carleton, Anita, et al. Extending TeamSoftware Process (TSP) to SystemsEngineering: A NAVAIR ExperienceReport. SEI, Carnegie Mellon Univer-sity. Technical Report CMU/SEI-2010-TR-008. Mar. 2010 <www.sei.cmu.edu/reports/10tr008.pdf>.
Notes 1. This graphic was created based on a
table called “System Functionality
Requiring Software,” but the originalcreator of the table is debated: eitherPM Magazine or a U.S. Air Force “BoldStrike” Executive Software Coursefrom 1992. To view the table, see:Ferguson, Jack. “Crouching Dragon,Hidden Software: Software in DoDWeapon Systems.” IEEE SoftwareJuly/Aug. (2001): 105-107.
2. For example, AV-8B uses TelelogicDOORS Objects to identify the num-ber of requirement statements and,hence, the size of the requirement set.Any organization/program productcan be viewed as a comparable proxy.
Software defense organizations will benefit by learning about Team ProcessIntegration, the continuing collaboration between the SEI and NAVAIR. As detailedin the article, results from current projects utilizing TPI show a gross savings of morethan $3.7 million and a net savings of more than $3.2 million, with a return seventimes the original investment. Quality improvement on two examined projects was areduction in defect density from 1.1 to 0.59 defects per thousand LOC on one and4.6 to 0.6 defects per thousand LOC on the other. TPI lowers costs, helps projectsmeet schedules, and improves productivity.
Software Defense Application

28 CROSSTALK The Journal of Defense Software Engineering July/August 2010
Cybernetics is the study of communica-tion and control processes, especially
the comparison of these processes in bio-logical and artificial systems. It attempts tolearn principles that can be applied to anytype of system regardless of its materialrealization. This kind of study began longbefore the existence of the modern digitalcomputer. The term itself goes back toPlato.
Don’t assume those early cyberneticistswould be impressed by our modern high-availability computer systems. They mighteven view our conventional approach tosoftware as fatally arrogant, requiring aprogrammer to anticipate everything.
Conventional software is based on thealgorithmic approach pioneered by Johnvon Neumann in the 1940s. An algorithmis just “a series of steps to achieve a desiredaim” [1] that we then give to our machinesto execute. It is a well-behaved approachwith predictable results—so long as all ofyour assumptions are valid, your code isperfect, the world doesn’t change, and yourenemies are powerless to interfere.
I assume you’ve experienced what hap-pens otherwise. The more critical a con-ventional system is, the more rigidly andexhaustively we must define those steps.We must also carefully control its runtimeenvironment. According to the higheststandards of compliance (e.g., DO-178B/ED-12B or MIL-STD-498) we must testevery possible decision, every pathway, andevery conceivable combination of data.
If certification is required, then thecost to produce the associated verificationevidence grows exponentially with the sizeof the application. At some point, this isimpossible—even in a modestly complexclosed system. And in an open system, wecan’t even control the scope of the prob-lem.
I sometimes wonder if, like an overpro-tective parent, our emphasis on rigor hasn’tactually made our systems more vulnerable.Whenever our conventional systemsencounter something other than the sterileenvironment that we intended, what sort of
coping skills have we given them? Von Neumann himself wrote about an
alternative neural approach, one in whichnew behaviors can emerge in response tochanges in the environment. This would fitthe theoretical principles of our cyberneti-cists exactly, as they emphasize the use offeedback to accomplish goals rather thanfollowing a predetermined set of steps.While a neural or cybernetic approach isless well-behaved and less predictable thanthe software we are used to, it is alsoextremely adaptable and powerful.
Rather than spending too much timeon a soapbox, I would rather present youwith a question: Given the right tools,could you design a system that is safer andmore economical to build because it hasthe ability to overcome its own imperfec-tions and environmental obstacles and stillcomplete the mission? Assuming that youare at least thinking about it, let’s talk abouthow you might go about designing such asystem.
What Is a Cyborg?We want both kinds of the behavior thatI’ve talked about, with predictable systemsthat follow established rules and proce-dures. But we also want them to adapt inthe face of the unexpected. So it wouldseem that what we need is a hybridapproach: a combination of cyberneticstechnology with some other type of sys-tem. And that’s a fairly good working defi-nition of a cyborg. Fair, but not great; it isa bit like describing a car as “somethingwith tires.”
The original authoritative definitionwas published by Dr. Nathan S. Kline andManfred Clynes in the September 1960issue of the scientific journal Astronautics.And yes, they did suggest that the bodies ofpilots could be modified for space travelusing drugs and assorted parts (yikes, can’timagine why that wasn’t popular). Butthose sensational examples were not partof the definition. Instead, they proposed acybernetic principle that can be applied toany type of system. In their own words:
What are some of the devices nec-essary for creating self-regulatingman-machine systems? This self-regulation must function withoutthe benefit of consciousness inorder to cooperate with the body’sown autonomous homeostaticcontrols. For the exogenouslyextended organizational complexfunctioning as an integrated home-ostatic system unconsciously, wepropose the term “Cyborg.” [2]
Homeostatic is the idea of an open sys-tem that can regulate itself to functioneffectively in a broad range of conditions.
Open, as used here, refers to a system inwhich energy or material (resources) can beadded or lost. It also means that the typeand number of parts that make up the sys-tem are not static.
Exogenous in this context means anymaterial that is present and active in anindividual organism but that originatedoutside of that organism. It is meant todescribe a cyborg’s blended nature, wherecontrol is extended over other non-cyber-netic parts.
A cyborg has the authority to uncon-sciously alter its operation. This languagecoincides with their example of the humanautonomic nervous system. For example,you don’t generally think about breathing.You can control it, but normally you con-centrate on the mission while the bodyadjusts to your activities, environmentalconditions, threats, etc.
A cyborg may alter its operation, butonly to maintain a stable state or accom-plish goals that we’ve set for it. Therefore,this definition both empowers and sets spe-cific limits on the authority that is given toa cyborg.
One thing that the original definitiondoes not explicitly mention is the conceptof self—though you might infer that fromthe root words cybernetic organism: An organ-ism is a separate distinct individual.
In my opinion, a cyborg must be ableto distinguish self from any other organism,
Building Critical Systems as a CyborgGreg Ballcyborgg.com
In science fiction, a cyborg is a marriage of machine and human flesh. I’m not suggesting that you turn your favorite officer into anespresso machine, but this article explains the seemingly outrageous possibility that cybernetics may be the next step in the evolutionof critical systems, demonstrates actual code and technology that is available, and describes real-world experiences in using it. Thestrength of this technology is in its resilience and adaptability in building complex critical systems that must face the real world.However, its use requires a shift in thinking about software—much like the introduction of “object-oriented” concepts once did.
Open Forum

Building Critical Systems as a Cyborg
July/August 2010 www.stsc.hill.af.mil 29
or the environment, because it mustattempt to regulate only itself.
It must not get confused and try toimpose its goals on others. It must notattempt to change or take over the uni-verse. It has to have a clear idea of whichparts belong to it and which do not. Itmust have healthy boundaries to protectitself and play well with others.
Since we’re now somewhat stretchingthe original definition of a cyborg, theterm we propose to use is cyborg gratia or“for the sake of the cyborg.” It meansthat the cybernetic organism is operatingfor itself as an independent organisminside a larger social structure.
Social governance is the final piecenecessary to complete the concept. In anopen system, you have to expect commu-nication and cooperation, but also some-times conflict between organisms. It ishighly desirable to design a resilient sys-tem as an ecology of independent, coop-erative, and adaptive organisms—onethat can embody complex relationshipswith security and selective trust.
Such systems can align themselveswith the changing and varied relation-ships between partners, alliances, andcustomers. They also enable a differentparadigm for development and mainte-nance that embraces change and diversi-ty.
Technology in ActionThe question now is how to make that areality. Cyborgg (pronounced “cyborggee”) is commercial open-source cyber-netic technology in its second generation.It is impossible to describe everything ina short article—and difficult to knowwhere to start. But I can show that work-ing with a cyborg is not onerous.
Cyborgg employs a heterogeneousnetwork of several neuron types to facil-itate the integration of these cyberneticextensions into the rest of your system1.The data that they work with is not limit-ed to numerical values2. They fall into twogeneral classifications:• Afferent (or sensory) neurons are
used to receive input.• Efferent neurons are used to manipu-
late or interact with the outside world.One reason cyborgg was made open wasto drive consensus on some basic termsand standards. For example: Just as theformat of an e-mail address is importantto everyone, so is standardizing the for-mat of a Cyborg URI3 (or CURI).
CURIs are a key mechanism for surgi-cally implanting complex cyberneticcomponents in conventional code, asshown in the following three examples:
EXAMPLE No. 1Hooking into the neural net: We provide itwith some feedback on system perfor-mance using a cyborg helper class.
// Define the neuron in questionCURI curi = newCURI(“curi://afferent/responsetime$my service”);
// You could obtain and use the neurondirectly// but this helper class is convenientTimeMarker marker =TimeMarker.start(curi);
// Do something that you want to mea-sure, thenmarker.stopAndRecordTime();
EXAMPLE No. 2Another indirect way of hooking into theneural net includes defining an attribute fora class that cyborgg will dynamically con-trol. The following organelle shown is aconvenient wrapper around a neuron thatimplies that this class is an organ. Butwhere is the CURI? Cyborgg creates itbehind the scenes by inspecting the rest ofthe class:
protected Organelle queueSize =Organelle.newInteger(“queue size”,10);
EXAMPLE No. 3One can also select a cybernetic compo-nent or service. Note that many factors arein play here including failover, system load,authentication, biases, automated servicediscovery, etc. But these are handled invisi-bly by the cybernetic core:
// Asking for a certain type of servicewith no filters or restrictionsCURI curi = new CURI(“curi://$my ser-vice”);
// Cyborgg class used for dynamic depen-dency injectionInjector injector = new Injector();// obtain the serviceMyService service = injector.use(curi);
What happens when you do somethinglike this? Under the hood, cyborgg com-plies with Aleksander’s definition of aneural net as having a “network of adapt-able nodes which, through a process oflearning, store experiential knowledge andmake it available for use” [3]4. New systembehaviors can and do arise from changes tothe structure of this net.
Each cyborgg neuron has a complex
internal structure that is more cell-like thanthe classical neural approaches5. This wasdone to overcome two barriers to generaluse.
The first barrier was the difficulty ofunderstanding and having confidence in thedecisions made by the net (analysis of aclassical neural net is something only aresearcher could love).
To address this, each cyborgg neuroncontains a nucleus—a statistical modelthat captures information about the neu-ron’s behavior (most of the informationthat a Six Sigma practitioner would askfor). Therefore, when a neuron fires, it cantell you plainly things like “with 80 percentcertainty, these adjustments to the systemare predicted to change the behavior of acertain aspect by 68 percent (plus orminus 10 percent).”
You can track the difference betweenthe neuron’s prediction and the actualresult—and track the performance of thesystem in general. It keeps the cyborgfrom acting on weak or invalid assump-tions. It is also used to discover new orunexpected correlations. This not onlygives the cyborg power, but allows it toserve as a research tool.
The second barrier was the difficulty oftraining the net, of knowing what synapsesto forge, and how the health of one neuronis related to the health of another. So eachneuron contains a genetic algorithm orgenotype that is used to grow and test newrelationships. A pluggable axon allows thesystem to grapple with how it shouldrespond6. Both of these are guided duringthe cyborg configuration.
This configuration includes the abilityto define rules to shape, as well as extend ormodify, the cyborg’s behavior even after thesystem is deployed and running. It will obeybroadcasted commands (using an extensi-ble lexical command processor), includingbuilt-in diagnostic and test commands.
I have barely scratched the surface ofjust this one aspect, and there is no room toexplain how service selection and failovertakes place. There so much to describeabout the social structure that is a centralpart of that decision—or the communica-tion and other technology that supports it.Still, I’ve made clear what the purposes of acyborg are and presented enough about thetechnology to encourage you to exploreand test it for yourselves.
Lessons of UseCyborgg is currently in use supporting anumber of medical facilities from cancerresearch to small practices. It is the techni-cal foundation or glue inside a leading

Open Forum
30 CROSSTALK The Journal of Defense Software Engineering July/August 2010
health care software vendor’s product,which brings together a distributed groupof components from multiple vendorsinto a single enterprise services bus forhealth care. Its application has includedelectronic medical record services, diseasemanagement, clinical trials management,transcription, and document scanning.
Among the lessons learned in its use(so far):• Configuration of a large distributed
adaptable system can be problematic,which led to a redesign of the config-uration subsystem in the latest versionof cyborgg7.
• The amount of benefit that youreceive is closely related to the waythat you modularize and package yoursystem. Greater benefits come whenapplications are not monolithic.
• We found that good modular designswere sometimes negated by thedeployment model. This led to theintroduction of organs as an addition-al cyborgg concept, and Java NetworkLaunch Protocol Replaceable Units asa supporting service or technology.
• The concepts are currently differentand new enough to require goodtraining of your development team. Itparticularly rewards a savvy architect
that takes the time to learn its capabil-ities.
• Visibility is a key organizational suc-cess factor, underlining the impor-tance of features to allow technicalusers to interact with a cyborg.The strength of this technology is in
building complex critical systems thatdefense organizations face in the realworld. That the old combat phrase “noplan survives contact with the enemy”still holds true, as is the belief that anysystem that cannot adapt is likely to fail.Cyborg technology represents a con-trolled step defense organizations cantake to be more adaptable—away fromtheir stiff, pre-programmed conventionalsoftware and towards systems that havegreater problem-solving skills.u
References 1. von Neumann, John, Arthur Burks, and
Herman H. Goldstine. Preliminary Dis-cussion of the Logical Design of an ElectronicComputing Instrument. U.S. Army Ordi-nance Department Report. June 1946.
2. Clynes, Manfred E., and Nathan S.Kline. “Cyborgs and Space.” Astronaut-ics (Sept. 1960): 26-27 and 74-75.
3. Aleksander, Igor, and Helen Morton.An Introduction to Neural Computing. Lon-
don: International Thomson Com-puter, 1995.
Notes1. For example, motor neurons work with
threaded processes, failure analysis neu-rons are for failure analysis, and germ lay-ers work with exogenous services in aservice-oriented architecture.
2. Strings and other non-numeric data areconverted to ordinals.
3. A Uniform Resource Identifier (URI) islike the familiar Uniform ResourceLocator (URL) except that the resourceit identifies does not necessarily specifylocation. A URL is a type of URI.
4. Igor Aleksander’s work led to the devel-opment of the first computer based onneural principles to reach the market-place.
5. For example, Boltzmann machines,Kohonen maps, and perceptrons.
6. Slipping into the math for a minute, therelationship between real-world neu-rons is likely not a simple linear rela-tionship. Ask questions such as“Should it be quadratic?” and “Shouldwe use a radial basis function?” Thedefault axon uses a type of ragged cubethat allows each neuron to fire accord-ing to a data-driven complex curve.However, the cyborgg application pro-gramming interface allows and encour-ages the researcher to substitute theirown firing function and measure itseffectiveness versus other approaches.
7. Changes included: automatic discoveryof cyborgg-enabled services; the optionto use configuration references where acommonly used set of goals or otherparameters is defined only once, using aunique identification, and then refer-enced by other components; and withthe addition of new installation and con-figuration services that allow the push-ing of upgrades to remote customers.
About the Author
Greg Ball is a softwareand system architect withmore than 15 years ofgovernment and privateindustry experience. Heprefers a complex techni-cal problem to most
other forms of entertainment. Ball is theoriginal creator of cyborgg.
7911 Woodstone LNDallas,TX 75248E-mail: [email protected]

BACKTALK
July/August 2010 www.stsc.hill.af.mil 31
It happens to the best of us: the dreaded day our trustycomputer leaves the surly bonds of electromagnetism to
touch the face of neutrality—leaving the unprepared in sev-eral days of pure hell. Sure, it teases with a spark or sputteronly to return to the blue screen of death, the black screenof doom, or the nauseous bios merry-go-round.
Such was my fate at the onset of 2010. It began with anunsolicited Windows upgrade that automatically downloadedand deemed itself so urgent the operating system incessantlybegged for a restart and eventually took matters into its ownhands. Luckily, I had the common sense to back-up my datato my new Christmas present—a 500GB Hitachi mobile harddrive that resembles an armadillo tank. Thanks, Santa!
My first step in Hades started with a “Gold Support” call.It sounded good when purchased, but what I didn’t realizewas that Gold Support starts with a call center operator on amission to get you to fix your computer via telephone. Sure,I don’t mind a few qualifying questions to eliminate bone-heads (“yes, it’s plugged in...”), but after that I want help; notcomputer repair on-the-job training. Note to computer man-ufacturers: How about “Platinum Support” that gets me backup and running without delay, no questions asked?
After Harold and Kumar failed to find my laptop’s heart-beat, I took it to a local repair shop only to find out the reme-dy would outpace the cost of a replacement. The computer waslimping through its fourth year of service and I was eager to jet-tison Vista (and its barnacles picked up over those years). It wastime for a new computer. I had threatened to purchase a newcomputer over the past nine months; those threats rang hollowas I realized that necessity is not only the mother of inventionbut also the ugly stepsister of action.
I needed a computer quick—and a custom computer wasgoing to take time. I don’t know about you, but if I’m taking acomputer into the trenches, I prefer it be tailored to my needs.So I was in need of quick makeshift computing while I found along term solution. Enter my son’s college computer (he’s onhiatus in Oregon). With minimum processing power and diskspace, I coupled it with my new tank drive to survive. It wasenlightening to see what you can do with mobile storage andprovisional computing.
Now I could take some time to find a suitable replacement.Along with Windows 7, I was interested in the new Intel Corei3, i5, and i7 processors—as well as their 32-nanometer submi-cron processing technology. While perusing the specs, some-thing caught my eye. The i7 has floating-point processing capa-bility.
Did you hear me? A readily available, commercially sup-ported floating-point processor. To the ears of an embeddedsystem designer that is like Charlie finding the golden ticket.Finally!
After years of neglect, has Intel decided to focus on militaryembedded systems? Hardly. It turns out Intel customers areattracted to floating-point to power a new generation of per-sonal computers that handle high resolution graphics and highvolume video.
Nowadays, it’s not good enough to share pictures. Thosepictures have to move in multiple windows, at the same time,and in high definition. We want “Avatar” in 3D THX surroundsound streaming on our laptop with pop-up director notes
devoid of jitter, loading stutter, or delay. That’s where floating-point comes in.
While The Buggles decried, “Video Killed the Radio Star,”it turns out in this millennium, video has an unlikely partner: themilitary. Not a partner in murder, rather a partner in readilyavailable commercial off-the-shelf floating-point processors.
Video is an unintentional accessory to the art of war. Yes,your desire to stream your baby’s first steps to grandma andgrandpa has military embedded computer designers dreamingof a commercial processor crunching complex fast movingradar, sonar, and electronic warfare data by day and handlingroutine data parsing, links, stores management, and fault toler-ant checks by night.
Sure, standalone digital signal processing (DSP) chips havebeen in operation for years; however, as standalone chips, theycommand their own real-estate on densely populated circuitboards. That gives rise to high rent, heavy footprints, and con-gestion. Now designers can use a processor that performs DSPas well as general-purpose processing on a single chip, shrink-ing substantial processing capability into a smaller space.
Couple size benefits with the cost savings from commercialprocessor mass manufacturing, and you have embedded systemdesigners squirming with joy like Iggy Pop sucking an extra sourWarhead.
So I had a choice: i3, i5, or i7. Did I really need the i7? No.Did I want the i7? Yes. Did I get the i7? Of course—as well asa couple of 500GB hard drives in RAID configuration with aboatload of RAM.
Now I need a good lead on a miniature radar antenna—about five to six inches in diameter with a SCSI output. I’ll plugthat into my new laptop and start painting targets in the officeby day and research why Cher is morphing into Joey Ramone bynight. All because Dave Cook wants to watch movies on his lap-top1.
Thanks Dave.
—Gary A. PetersenArrowpoint Solutions, [email protected]
Note1. Although Dave’s always talking about his laptop in his
BackTalk, see <www.stsc.hill.af.mil/crosstalk/2008/12/0812BackTalk.html>.
Video Thrills the Radar Tsars
Can You BackTalk?
Here is your chance to make your point without your bosscensoring your writing. In addition to accepting articles thatrelate to software engineering for publication in CrossTalk,we also accept articles for the BackTalk column. These arti-cles should provide a concise, clever, humorous, and insight-ful perspective on the software engineering profession orindustry or a portion of it. Your BackTalk article should beentertaining and clever or original in concept, design, or deliv-ery, and should not exceed 750 words.
For more information on how to submit your BackTalkarticle, go to <www.stsc.hill.af.mil>.

CrossTalk / 517 SMXS/MXDEA6022 Fir AVEBLDG 1238Hill AFB, UT 84056-5820
PRSRT STDU.S. POSTAGE PAID
Albuquerque, NMPermit 737
CrossTalk thanksthe above
organizations forproviding their support.

















