21
Representation Learning of Vector of Words and Phrases Felipe Moraes [email protected] 1 LATIN - LAboratory for Treating INformation
| Date post: | 25-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | felipe-moraes |
| View: | 203 times |
| Download: | 1 times |

Representation Learning of Vector of Words and
PhrasesFelipe Moraes
1
LATIN - LAboratory for Treating INformation

Agenda• Motivation
• One-hot-encoding
• Language Models
• Neural Language Models
• Neural Net Language Models (NN-LMs) (Bengio et al., ’03)
• Word2Vec (Mikolov et al., ’13).
• Supervised Prediction Tasks
• Recursive NNs (Socher et al., ’11).
• Paragraph Vector (Le & Mikolov, ’14).

Motivation
Input Learning Algorithm Output

Let's start with words for now
How to learn good representations for texts?

One-hot encoding• Form vocabulary of words that maps lemmatized words to a
unique ID (position of word in vocabulary)
• Typical vocabulary sizes will vary between 10 000 and 250 000

One-hot encoding• From its word ID, we get a basic representation of a word through
the one-hot encoding of the ID
• the one-hot vector of an ID is a vector filled with 0s, except for a 1 at the position associated with the ID
• ex.: for vocabulary size D=10, the one-hot vector of word ID w=4 ise(w) = [ 0 0 0 1 0 0 0 0 0 0 ]
• a one-hot encoding makes no assumption about word similarity
• all words are equally different from each other
• this is a natural representation to start with, though a poor one

One-hot encoding• The major problem with the one-hot representation is that it is very high-
dimensional
• the dimensionality of e(w) is the size of the vocabulary
• a typical vocabulary size is ≈100 000
• a window of 10 words would correspond to an input vector of at least 1 000 000 units
• This has 2 consequences:
• vulnerability to overfitting
• millions of inputs means millions of parameters to train in a regular neural network
• computationally expensive

Language Modeling• A language model is a probabilistic model that assigns
probabilities to any sequence of words p(w1, ... ,wT)
• language modeling is the task of learning a language model that assigns high probabilities to well formed sentences
• plays a crucial role in speech recognition and machine translation systems
uma pessoa inteligentea smart person
a person smart

N-gram Model• An n-gram is a sequence of n words
• unigrams(n=1):’‘is’’,‘‘a’’,‘‘sequence’’,etc.
• bigrams(n=2): [‘‘is’’,‘‘a’’], [‘’a’’,‘‘sequence’’],etc.
• trigrams(n=3): [‘’is’’,‘‘a’’,‘‘sequence’’],[‘‘a’’,‘‘sequence’’,‘‘of’’],etc.
• n-gram models estimate the conditional from n-grams counts
• the counts are obtained from a training corpus (a data set of word text)

N-gram Model• Issue: data sparsity
• we want n to be large, for the model to be realistic
• however, for large values of n, it is likely that a given n-gram will not have been observed in the training corpora
• smoothing the counts can help
• combine count(w1 , w2 , w3 , w4), count(w2 , w3 , w4), count(w3 , w4), and count(w4) to estimate p(w4 |w1, w2, w3)
• this only partly solves the problem

Neural Network Language Model
• Solution:
• model the conditional p(wt | wt−(n−1) , ... ,wt−1) with a neural network
• learn word representations to allow transfer to n-grams not observed in training corpus
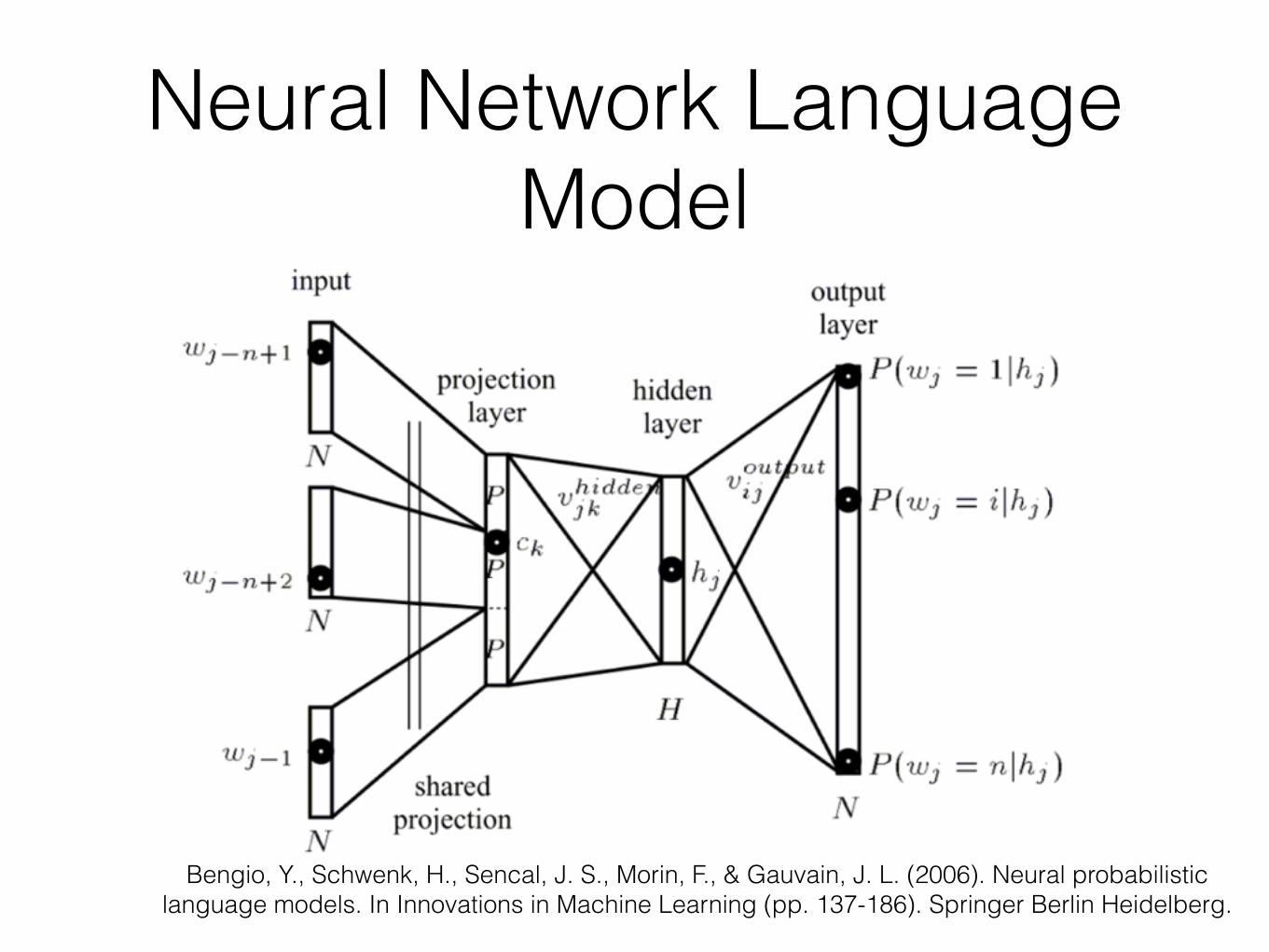
Neural Network Language Model
Bengio, Y., Schwenk, H., Sencal, J. S., Morin, F., & Gauvain, J. L. (2006). Neural probabilistic language models. In Innovations in Machine Learning (pp. 137-186). Springer Berlin Heidelberg.

NNLMs
• Predicting the probability of each next word is slow in NNLMs because the output layer of the network is the size of the dictionary.

Word2Vec
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jerey Dean. Distributed Representations of Words and Phrases and their Compositionality. NIPS, 2013.

Word2VecSan Francisco France
• It was recently shown that the word vectors capture many linguistic regularities, for example:
• vector operations vector('Paris') - vector('France') + vector('Italy') results in a vector that is very close to vector('Rome')
• vector('king') - vector('man') + vector('woman') is close to vector(‘queen’)

From Words to Phrases• How could we learn representations for phrases of arbitrary
length?
• can we model relationships between words and multiword expressions
• ex.: ‘‘ consider ’’ ≈ ‘‘ take into account ’’
• can we extract a representation of full sentences that preserves some of its semantic meaning
• ex.: ‘‘ word representations were learned from a corpus ’’ ≈ ‘‘ we trained word representations on a text data set’‘
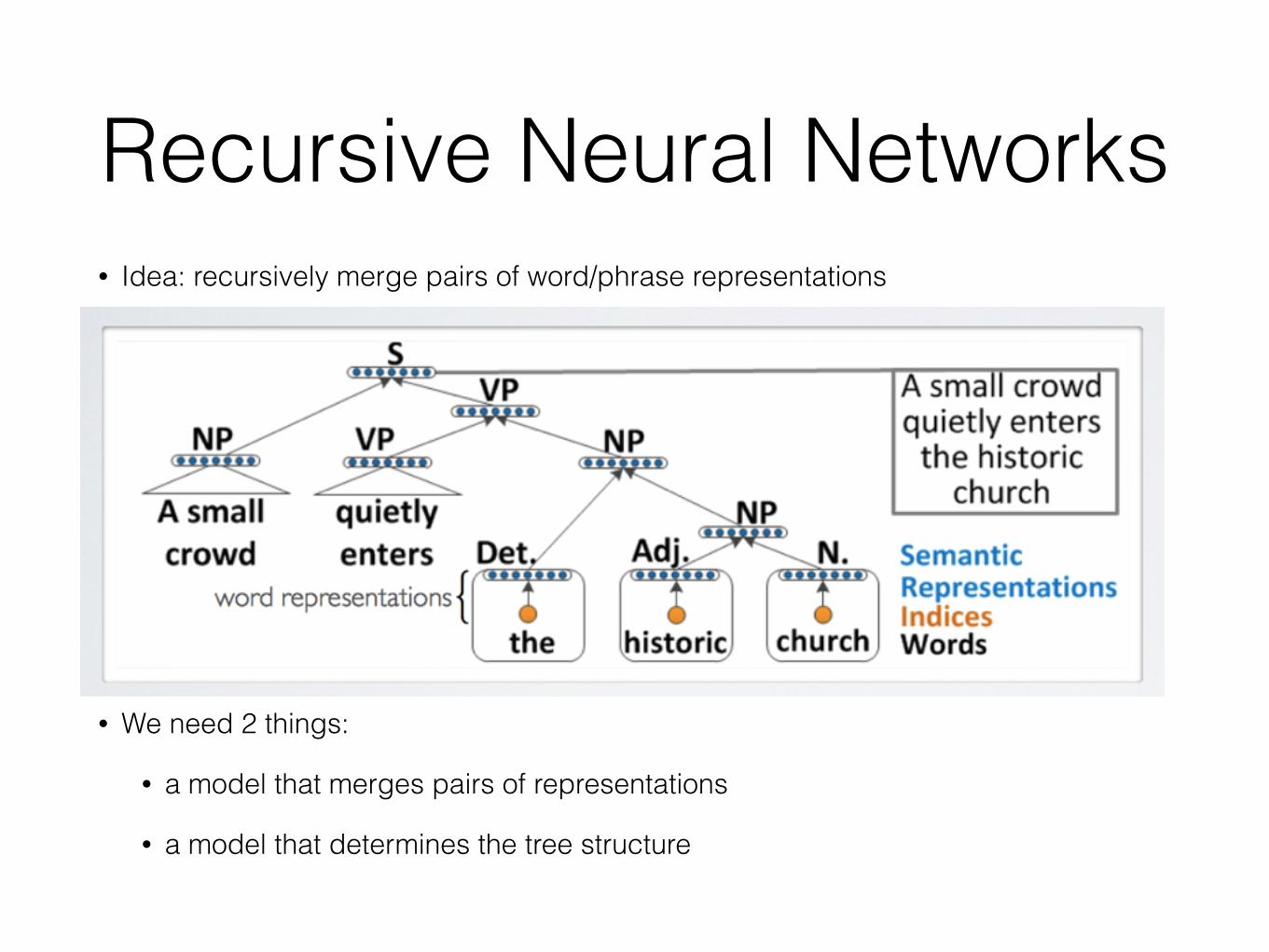
Recursive Neural Networks• Idea: recursively merge pairs of word/phrase representations
• We need 2 things:
• a model that merges pairs of representations
• a model that determines the tree structure

Paragraph Vector

Paragraph Vector

Paragraph Vector Applications

Paragraph Vector Applications
















