Research ArticleMapReduce Based Personalized Locality Sensitive Hashing forSimilarity Joins on Large Scale Data
Jingjing Wang12 and Chen Lin12
1School of Information Science and Technology Xiamen University Xiamen 361005 China2Shenzhen Research Institute of Xiamen University Shenzhen 518058 China
Correspondence should be addressed to Chen Lin chenlinxmueducn
Received 28 September 2014 Revised 24 February 2015 Accepted 2 March 2015
Academic Editor J Alfredo Hernandez
Copyright copy 2015 J Wang and C Lin This is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
Locality Sensitive Hashing (LSH) has been proposed as an efficient technique for similarity joins for high dimensional data Theefficiency and approximation rate of LSH depend on the number of generated false positive instances and false negative instancesIn many domains reducing the number of false positives is crucial Furthermore in some application scenarios balancing falsepositives and false negatives is favored To address these problems in this paper we propose Personalized Locality SensitiveHashing(PLSH) where a new banding scheme is embedded to tailor the number of false positives false negatives and the sum of bothPLSH is implemented in parallel usingMapReduce framework to deal with similarity joins on large scale data Experimental studieson real and simulated data verify the efficiency and effectiveness of our proposed PLSH technique compared with state-of-the-artmethods
1 Introduction
A fundamental problem in data mining is to detect similaritems Finding similar pairs of instances is an essentialcomponent in mining numerous types of data includingdocument clustering [1 2] plagiarism detection [3] imagesearch [4] and recommender system [5]
Identifying pairs of similar instances is also called sim-ilarity joins [6] Given a set of data instances a similaritythreshold 119869 and a join attribute 119886 the goal of similarityjoins is to find all pairs of instances ⟨119860 119861⟩ where theirsimilarity on the join attribute is larger than the threshold 119869
(ie sim(119860119886 119861119886) ge 119869) There are various similarity meas-urements including cosine similarity [7] edit distance [68 9] hamming distance [7 10] dimension root similarity[2] and EDU-based similarity for elementary discourse units[11] In this work we focus on Jaccard similarity which isproven to be successful for high dimensional sparse featuresets [6] Jaccard similarity for two feature vectors 119878
1and
1198782is defined as sim(119878
1 1198782) = |119878
1cap 1198782||1198781
cup 1198782| As an
example we illustrate naive computation for similarity joins
based on Jaccard similarity in Table 1 Suppose there are 5
instances namely119860 119861 119862119863 and119864 the join attribute consistsof features 119886 119887 119888 119889 119890 119891 the Jaccard similarity of ⟨119860 119861⟩ is14 ⟨119860 119862⟩ is 23 ⟨119861 119862⟩ is 15 ⟨119861 119864⟩ ⟨119862119863⟩ and ⟨119862 119864⟩
is 14 ⟨119863 119864⟩ is 13 and the similarities for remaining pairs⟨119860119863⟩ ⟨119860 119864⟩ ⟨119861119863⟩ are all 0 Given the similarity threshold119869 = 05 it is directly concluded that instances 119860 and 119862 aresimilar
A naive algorithm which finds similar pairs by comput-ing similarities for all instance pairs is clearly impracticableon a large collection of instances with high dimensionalfeatures To improve efficiency and scalability of similarityjoins previous research efforts generally fall into two cat-egories On one hand parallel algorithms are adopted onclusters of machines Most of them are implemented usingMapReduce framework including a 3-stage MapReduceapproach for end-to-end set-similarity join algorithm [12]fast computation of inner products for large scale newsarticles [13] and a new ant colony optimization algorithmparallelized using MapReduce [14] to select features in a highdimension spaceOthers exploit the parallelism and high data
Hindawi Publishing CorporationComputational Intelligence and NeuroscienceVolume 2015 Article ID 217216 13 pageshttpdxdoiorg1011552015217216
2 Computational Intelligence and Neuroscience
throughput of GPU that is the LSS algorithm [15] On theother hand algorithmic design can be improved to reducetime and storage cost of similarity computation for highdimensional feature space One type of such approachesuses dimension reduction technologies including PrincipleComponents Analysis and neural networks [16] Anothertype is to hash and filter so that high dimensional featurespace can be replaced by smaller representative signaturesMost popular hashing methods include minhashing [17]minwise hashing [18] and Locality Sensitive Hashing (LSH)[10] The core idea of hashing is to map similar pairs tosimilar signatures with several hundred dimensions eachelement of which is the result of hashing and hence shedsinsights to the solution of high dimensionality Hashingcan also be a means for data clustering because it enablessimilar features with vast dimensions to be hashed into thesame buckets and thus partitions features into groups [19]Filteringmethods including length filter [7] prefix filter [20]and suffix filter [21] are frequently utilized consequently toeliminate dissimilar pairs while possible similar pairs remainAs a result fewer similarity computations are neededIn particular banding technique [22] a specified form ofLocality Sensitive Hashing which maps every band of sig-natures to an array of buckets so the probability of collisionis much higher for instances close to each other is the mostefficient filtering method
Although previous works have demonstrated the impor-tance and feasibility of hashing and filtering approaches onecritical issue remains underestimated Hashing and filteringapproaches produce approximate results The similarities ofselected pairs are not guaranteed to be larger than the pre-defined threshold In the meanwhile obsoleted pairs are notindeed dissimilar with similarities less than the predefinedthreshold The former case is called false positive while thelatter one is called false negative An appropriate numberof false positives and false negatives are acceptable in manyapplications However the tolerance to false positive and falsenegative may differ In most application scenarios such asclustering and information retrieval a small amount of falsepositives is emphasized to increase efficiency and precisionIn applications such as recommendation and bioinformaticssystems [23ndash25] a small number of false negatives are moreimportant
In this paper we address the problem of tailoring thenumber of false positives and false negatives for differentapplications To the best of our knowledge this is the firsttime in literature to present such detailed analysis Falsepositives and false negatives are caused by the scheme ofpruning candidate pairs whose signatures map into disjointbucket arrays Intuitively similar signatures are likely tohave highly analogous bands And analogous bands willbe mapped into identical bucket arrays Inspired by thisintuition we propose the new banding technique calledPersonalized Locality Sensitive Hashing (PLSH) in whichbands of signatures mapped to at least 119896 identical bucketsare selected as candidates We also explore the probabilityguarantee of the new banding techniques provided for threecases namely false negatives false positives and the sumof both According to these probabilities we propose the
Table 1 An illustrative example of similarity joins based onJaccard similarity 01 indicates absencepresence of features in eachinstance
upper bounds and lower bounds of false positives andfalse negatives and accordingly present to personalize theparameters involved in banding and hashing algorithms tofulfill different application demands
The contributions of this paper are threefold
(i) We improve the traditional banding technique bya new banding technique with flexible threshold toreduce the number of false positives and improveefficiency
(ii) Wederive the number and lowerupper bound of falsenegatives and false positives and balancing betweenthem for our new banding technique
(iii) We implement the new banding technique usingparallel framework MapReduce
The rest of the paper is structured as follows In Section 2the backgrounds of minhashing and banding technique arepresented In Section 3 we introduce Personalized LocalitySensitive Hashing (PLSH) The implementation of PLSHusing MapReduce is shown in Section 4 In Section 5 wepresent and analyze the experimental results We survey therelated works in Section 6 Finally the conclusion is given inSection 7
2 Background
In this section we briefly introduce the minhashing algo-rithm and the consequent banding algorithm which are thefundamental blocks of Locality Sensitive Hashing (LSH)Theintuition of minhashing is to generate low dimensional sig-natures to represent high dimensional features The intuitionof banding is to filter candidates which are not likely to besimilar pairs
21 MinHashing For large scale data sets feature space isusually high dimensional and very sparse that is only atiny portion of features appear in a single instance In orderto reduce the memory used to store sparse vector we usea signature an integer vector consisting of up to severalhundred elements to represent an instance To generate asignature we first randomly change the order of features Inother words the permutation defines a hash function ℎ
119894that
shuffles the features Each element of signature is a minhashvalue [17] which is the position of the first nonzero featurein the permuted feature vector For example the original
Computational Intelligence and Neuroscience 3
Table 2 An illustrative example of permutation of feature vectors01 indicates absencepresence of features in each instance
feature vector in Table 1 is 119886119887119888119889119890119891 suppose the permutedfeature vector is 119887119886119888119889119891119890 then feature vectors for 119860 119861 119862 119863and 119864 become (100001) (010011) (100101) (001100) and(000110) as illustrated in Table 2Thus the minhash value for119860 119861 119862 119863 and 119864 is 1 2 1 3 and 4 respectively
We can choose 119899 independent permutations ℎ1 ℎ2
ℎ119899 Suppose the minhash value of an instance 119878
119894for a certain
permutation ℎ119895is denoted by min ℎ
119895(119878119894) then the signature
denoted by Sig(119878119894) is
Sig (119878119894) = (min ℎ
1(119878119894) min ℎ
2(119878119894) min ℎ
119899(119878119894)) (1)
The approximate similarity between two instances basedon their signatures is defined as the percentage of identicalvalues at the same position in the corresponding signaturesFor example given 119899 = 6 Sig(119878
22 Banding Given a large set of signatures generated inSection 21 it is still too costly to compare similarities for allsignature pairs Therefore a banding technique is presentedconsequently to filter dissimilar pairs
The banding technique divides each signature into 119887
bands where each band consists of 119903 elements For each bandof every signature the banding technique maps the vector of119903 elements to a bucket array
As shown in Figure 1 the 119894th band of each signature mapsto bucket array 119894 Intuitively if for a pair of signatures thecorresponding bucket arrays have at least one bucket array incommon then the pair is likely to be similar For examplesignature 1 and signature 2 and signature 2 and signature 119898
in Figure 1 are similar Such a pair with common bucket arrayis considered to be a candidate pair and needs to be verifiedin the banding technique
3 Personalized LSH
31 New Banding Technique The candidates generated byLSH are not guaranteed to be similar pairs Chances are thata pair of signatures are projected to identical bucket arrayseven if the Jaccard similarity between the pair of instancesis not larger than the given threshold In the meantime apair of instances can be filtered out from candidates sincetheir corresponding signatures are projected into disjointbucket arrays even if the Jaccard similarity is smaller than thegiven thresholdThe former case is called false positive while
the latter one is called false negative Massive false positiveswill lead to inaccurate results while a large amount of falsenegatives will deteriorate computational efficiency of LSH Toenhance the algorithm precision and efficiency we presenthere a new banding scheme to filter more dissimilar instancepairs Intuitively if two instances are highly alike it is possiblethat many bands of the two corresponding signatures aremapped to identical buckets For example in Figure 1 thereare at least 3 bands (ie the 1st the 5th and the 119887th bands)of signature 1 and signature 2 which map to the same buckets(ie in the corresponding bucket array 1 5 119887)
Therefore we change the banding scheme as follows Forany pair of instances if the two corresponding signatures donot map into at least 119896 (119896 isin [1 119887]) identical buckets it will befiltered out Otherwise it is considered to be a candidate pairand the exact Jaccard similarity is computed and verified Forthe signatures shown in Figure 1 given 119896 = 3 signature 1 andsignature 119898 and signature 2 and signature 119898 are filtered
32 Number of False Positives A candidate pair ⟨1198781 1198782⟩ is
false positive if sim(⟨1198781 1198782⟩) lt 119869 and 119878
1 1198782share at least
119896 common bucket arrays Since the efficiency of LSH ismainly dependent on the number of false positives and mostreal applications demand a high precision we first derivethe possible number of false positives generated by the newbanding technique
Lemma 1 The upper bound of false positives generated by thenew banding technique is equal to the original LSH and thelower bound is approximate to 0
Proof According to the law of large numbers the probabilitythat theminhash values of two feature vectors (eg 119878
1 1198782) are
equal under any random permutation ℎ is very close to thefrequency percentage of observing identical value in the sameposition at two long signatures of the corresponding featurevectors That is
where 119899 is the length of signatures Sig(1198781) and Sig(119878
2) 119903 is the
position in signatures 119903 isin [1 119899]Also the probability that a random permutation of two
feature vectors produces the same minhash value equals theJaccard similarity of those instances [17] That is
119875 (min ℎ (1198781) = min ℎ (119878
2)) =
10038161003816100381610038161198781 cap 1198782
100381610038161003816100381610038161003816100381610038161198781 cup 119878
2
1003816100381610038161003816
= sim (1198781 1198782)
(3)
Based on the above two equations the probability oftwo instances with Jaccard similarity 119904 is considered to be acandidate pair by the new banding technique denoted by119875newas
Figure 1 An illustrative example of banding technique
where 119904 is the Jaccard similarity of the two instances 119903 isthe length of each band and 119887 is the number of bands Wecan prove the derivative of 119875new(119904) is greater than 0 whichrepresents 119875new(119904) a monotonically increasing function of 119904
The number of false positive denoted by FPmax(119896) is
FPmax (119896) = int
119869
0
119873119904119875new (119904) 119889119904 (5)
where 119873119904denotes the total number of similar pairs whose
Jaccard similarity is 119904 in the instances set Given an instanceset 119873
119904is a constant 119869 is the given similarity threshold
The value of FPmax(119896) depends on the similarity distri-bution of a given instance set The upper bound of FPmax(119896)equals the original LSH FPmax(1) Without the knowledge ofthe similarity distribution of the data set the lower boundof false positives cannot be directly derived Hence weintroduce a threshold 120598 to ensure
FPmax (119896)
FPmax (1)le 120598 (6)
where 120598 is close to zero with increasing 119896 If 119896 is lfloor119869119899119903rfloorthe lower bound of false positives approximates to 0 whichindicates that the candidates generated by the proposed newbanding technique are almost all truly similar pairs
To understand the zero lower bound with 119896 = lfloor119869119899119903rfloorsuppose there are two signatures with 119899 elements each lfloor119869119899119903rfloorbands of which are mapped to the same bucket At least119903lfloor119869119899119903rfloor asymp 119869119899 elements in the two signatures are identicalbecause a band includes 119903 elements According to (2) and (3)the approximate similarity between the two correspondinginstances is then greater than 119869119899119899 = 119869 Hence similarity foreach pair of signatures is greater than the threshold 119869 and nofalse positives exist
The introduction of 120598 also enables us to personalizethe number of false positives that is to vary the rangeof 119896 for different 120598 The range of 119896 for a desired 120598 isa function of 119869 119887 119903 that can be numerically solved For
Figure 2 An illustrative example of number of false positives forvarious 119896
example given 119869 = 07 119887 = 20 119903 = 5 Figure 2 showsthe trend of FPmax(119896)FPmax(1) for 119896 The minimum ofFPmax(119896)FPmax(1) is achieved when 119896 = 119887 If the desired120598 = 04 we can find a satisfying range of 119896 isin [3 20] sinceFPmax(2)FPmax(1) ge 120598 and FPmax(3)FPmax(1) le 120598
33 Number of False Negatives False negatives are trulysimilar pairs mapped to disjoint bucket arraysWe also derivethe upper and lower bound of false negatives generated by theproposed new banding technique
Lemma 2 The upper bound of false negatives generated by thenew banding technique is sum
119887minus1
119894=0(( 119894119887) (119904119903)119894(1 minus 119904
119903)119887minus119894
)119873119904ge119869
Thelower bound is close to the original LSH
Proof Similar to Section 32 the number of false negativesdenoted by FNmax(119896) is
FNmax (119896) = int
1
119869
119873119904(1 minus 119875new (119904)) 119889119904 (7)
FNmax(119896) is a monotonic increasing function of 119896 The lowerbound of it is achieved when 119896 = 1 The upper bound of
Computational Intelligence and Neuroscience 5
FNmax(119896) is obtained when 119896 is the total number of bandsHence the upper bound of FNmax(119896) is proportional to thenumber of similar instances 119873
119904ge119869
lim119896rarr119887
FNmax (119896) = (
119887minus1
sum
119894=0
(119894
119887) (119904119903)119894
(1 minus 119904119903)119887minus119894
)119873119904ge119869
(8)
For a desired the number of false negatives we do adivision between FNmax(119896) and FNmax(1) in terms of
FNmax (119896)
FNmax (1)le 120598 (9)
where 120598 is a threshold which is always greater than 1 By deriv-ing the numerical solution for int
1
119869119873119904(1 minus (sum
119887minus1
119894=0( 119894119887) (119904119903)119894(1 minus
119904119903)119887minus119894
))119889119904 the range of 119896 for a desired 120598 is obtained Forexample given the arguments 119869 = 07 119887 = 20 119903 = 5 Figure 3shows us the trend of FNmax(119896)FNmax(1) If the desired 120598 =
100 from Figure 3 we can find that FNmax(5)FNmax(1) asymp 70
and FNmax(6)FNmax(1) asymp 100 so the satisfying range is119896 isin [1 5]
34 Balance False Positives and False Negatives In someapplication scenarios wewant to have a balance between falsepositives and false negatives Here we analyse a special casewhere we want a desired aggregated number of false positivesand false negativesWe use FNPmax to denote the sum of falsepositives and false negatives which is defined as follows
The lower bound of FNPmax(119896) is dependent on thesimilarity distribution of the given data set However sincein most cases 119873
119904lt119869≫ 119873119904ge119869
thus FNPmax(119896) = 119873119904lt119869
119875new(119896) +
119873119904≫119869
(1 minus 119875new(119896)) is less than FNPmax(1) when 119896 is appropri-ately chosen
Inspired by Sections 32 and 33 we can also use athreshold 120598 to obtain the desired degree of precision Asshown in Figure 4 the ratio of FNPmax(119896)FNPmax(1) for119869 = 07 119887 = 20 119903 = 5 on a uniformly distributed data setfirst decreases as the value of 119896 increases The minimum is120598 = 02674when 119896 = 4 Then the ratio increases as 119896 becomeslarger If we are required to have a higher precision of thenew banding technique compared with traditional bandingtechnique in terms of aggregated number of false negativesand false positives (ie small FNPmax(119896)FNPmax(1) le 1)then 119896 isin [1 12] is acceptable
4 MapReduce Implementation of PLSH
In this section we first introduce theMapReduce frameworkThen we present the details of implementing PersonalizedLSH with MapReduce including minhashing banding andverification
Figure 4 An illustrative example of balancing false positives andfalse negatives
41 MapReduce MapReduce [26] is a framework for pro-cessing paralleled algorithms on large scale data sets usinga cluster of computers MapReduce allows for distributedprocessing of data which is partitioned and stored in adistributed file system (HDFS) Data is stored in the form of⟨119896119890119910 V119886119897119906119890⟩ pairs to facilitate computation
As illustrated in Figure 5 the MapReduce data flowconsists of two key phases the map phase and the reducephase In the map phase each computing node works onthe local input data and processes the input ⟨119896119890119910 V119886119897119906119890⟩pairs to a list of intermediate pairs ⟨119896119890119910 V119886119897119906119890⟩ in a differentdomain The ⟨119896119890119910 V119886119897119906119890⟩ pairs generated in map phase arehash-partitioned and sorted by the key and then they are sentacross the computing cluster in a shuffle phase In the reducephase pairs with the same key are passed to the same reducetask User-provided functions are processed in the reducetask on each key to produce the desired output
In similarity joins to generate ⟨119896119890119910 V119886119897119906119890⟩ pairs we firstsegment the join attributes in each instance to tokens Eachtoken is denoted by a unique integer id In the following stepstoken id is used to represent each feature
42 MinHashing We use one map reduce job to implementminhashing Before the map function is called ⟨119905119900119896119890119899 119894119889⟩
6 Computational Intelligence and Neuroscience
Input 0
Input 1
Input 2
Map
Map
Map
ReduceSort
Sort
Sort Reduce
Output 0
Output 1
Shuffle
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
throughput of GPU that is the LSS algorithm [15] On theother hand algorithmic design can be improved to reducetime and storage cost of similarity computation for highdimensional feature space One type of such approachesuses dimension reduction technologies including PrincipleComponents Analysis and neural networks [16] Anothertype is to hash and filter so that high dimensional featurespace can be replaced by smaller representative signaturesMost popular hashing methods include minhashing [17]minwise hashing [18] and Locality Sensitive Hashing (LSH)[10] The core idea of hashing is to map similar pairs tosimilar signatures with several hundred dimensions eachelement of which is the result of hashing and hence shedsinsights to the solution of high dimensionality Hashingcan also be a means for data clustering because it enablessimilar features with vast dimensions to be hashed into thesame buckets and thus partitions features into groups [19]Filteringmethods including length filter [7] prefix filter [20]and suffix filter [21] are frequently utilized consequently toeliminate dissimilar pairs while possible similar pairs remainAs a result fewer similarity computations are neededIn particular banding technique [22] a specified form ofLocality Sensitive Hashing which maps every band of sig-natures to an array of buckets so the probability of collisionis much higher for instances close to each other is the mostefficient filtering method
Although previous works have demonstrated the impor-tance and feasibility of hashing and filtering approaches onecritical issue remains underestimated Hashing and filteringapproaches produce approximate results The similarities ofselected pairs are not guaranteed to be larger than the pre-defined threshold In the meanwhile obsoleted pairs are notindeed dissimilar with similarities less than the predefinedthreshold The former case is called false positive while thelatter one is called false negative An appropriate numberof false positives and false negatives are acceptable in manyapplications However the tolerance to false positive and falsenegative may differ In most application scenarios such asclustering and information retrieval a small amount of falsepositives is emphasized to increase efficiency and precisionIn applications such as recommendation and bioinformaticssystems [23ndash25] a small number of false negatives are moreimportant
In this paper we address the problem of tailoring thenumber of false positives and false negatives for differentapplications To the best of our knowledge this is the firsttime in literature to present such detailed analysis Falsepositives and false negatives are caused by the scheme ofpruning candidate pairs whose signatures map into disjointbucket arrays Intuitively similar signatures are likely tohave highly analogous bands And analogous bands willbe mapped into identical bucket arrays Inspired by thisintuition we propose the new banding technique calledPersonalized Locality Sensitive Hashing (PLSH) in whichbands of signatures mapped to at least 119896 identical bucketsare selected as candidates We also explore the probabilityguarantee of the new banding techniques provided for threecases namely false negatives false positives and the sumof both According to these probabilities we propose the
Table 1 An illustrative example of similarity joins based onJaccard similarity 01 indicates absencepresence of features in eachinstance
upper bounds and lower bounds of false positives andfalse negatives and accordingly present to personalize theparameters involved in banding and hashing algorithms tofulfill different application demands
The contributions of this paper are threefold
(i) We improve the traditional banding technique bya new banding technique with flexible threshold toreduce the number of false positives and improveefficiency
(ii) Wederive the number and lowerupper bound of falsenegatives and false positives and balancing betweenthem for our new banding technique
(iii) We implement the new banding technique usingparallel framework MapReduce
The rest of the paper is structured as follows In Section 2the backgrounds of minhashing and banding technique arepresented In Section 3 we introduce Personalized LocalitySensitive Hashing (PLSH) The implementation of PLSHusing MapReduce is shown in Section 4 In Section 5 wepresent and analyze the experimental results We survey therelated works in Section 6 Finally the conclusion is given inSection 7
2 Background
In this section we briefly introduce the minhashing algo-rithm and the consequent banding algorithm which are thefundamental blocks of Locality Sensitive Hashing (LSH)Theintuition of minhashing is to generate low dimensional sig-natures to represent high dimensional features The intuitionof banding is to filter candidates which are not likely to besimilar pairs
21 MinHashing For large scale data sets feature space isusually high dimensional and very sparse that is only atiny portion of features appear in a single instance In orderto reduce the memory used to store sparse vector we usea signature an integer vector consisting of up to severalhundred elements to represent an instance To generate asignature we first randomly change the order of features Inother words the permutation defines a hash function ℎ
119894that
shuffles the features Each element of signature is a minhashvalue [17] which is the position of the first nonzero featurein the permuted feature vector For example the original
Computational Intelligence and Neuroscience 3
Table 2 An illustrative example of permutation of feature vectors01 indicates absencepresence of features in each instance
feature vector in Table 1 is 119886119887119888119889119890119891 suppose the permutedfeature vector is 119887119886119888119889119891119890 then feature vectors for 119860 119861 119862 119863and 119864 become (100001) (010011) (100101) (001100) and(000110) as illustrated in Table 2Thus the minhash value for119860 119861 119862 119863 and 119864 is 1 2 1 3 and 4 respectively
We can choose 119899 independent permutations ℎ1 ℎ2
ℎ119899 Suppose the minhash value of an instance 119878
119894for a certain
permutation ℎ119895is denoted by min ℎ
119895(119878119894) then the signature
denoted by Sig(119878119894) is
Sig (119878119894) = (min ℎ
1(119878119894) min ℎ
2(119878119894) min ℎ
119899(119878119894)) (1)
The approximate similarity between two instances basedon their signatures is defined as the percentage of identicalvalues at the same position in the corresponding signaturesFor example given 119899 = 6 Sig(119878
22 Banding Given a large set of signatures generated inSection 21 it is still too costly to compare similarities for allsignature pairs Therefore a banding technique is presentedconsequently to filter dissimilar pairs
The banding technique divides each signature into 119887
bands where each band consists of 119903 elements For each bandof every signature the banding technique maps the vector of119903 elements to a bucket array
As shown in Figure 1 the 119894th band of each signature mapsto bucket array 119894 Intuitively if for a pair of signatures thecorresponding bucket arrays have at least one bucket array incommon then the pair is likely to be similar For examplesignature 1 and signature 2 and signature 2 and signature 119898
in Figure 1 are similar Such a pair with common bucket arrayis considered to be a candidate pair and needs to be verifiedin the banding technique
3 Personalized LSH
31 New Banding Technique The candidates generated byLSH are not guaranteed to be similar pairs Chances are thata pair of signatures are projected to identical bucket arrayseven if the Jaccard similarity between the pair of instancesis not larger than the given threshold In the meantime apair of instances can be filtered out from candidates sincetheir corresponding signatures are projected into disjointbucket arrays even if the Jaccard similarity is smaller than thegiven thresholdThe former case is called false positive while
the latter one is called false negative Massive false positiveswill lead to inaccurate results while a large amount of falsenegatives will deteriorate computational efficiency of LSH Toenhance the algorithm precision and efficiency we presenthere a new banding scheme to filter more dissimilar instancepairs Intuitively if two instances are highly alike it is possiblethat many bands of the two corresponding signatures aremapped to identical buckets For example in Figure 1 thereare at least 3 bands (ie the 1st the 5th and the 119887th bands)of signature 1 and signature 2 which map to the same buckets(ie in the corresponding bucket array 1 5 119887)
Therefore we change the banding scheme as follows Forany pair of instances if the two corresponding signatures donot map into at least 119896 (119896 isin [1 119887]) identical buckets it will befiltered out Otherwise it is considered to be a candidate pairand the exact Jaccard similarity is computed and verified Forthe signatures shown in Figure 1 given 119896 = 3 signature 1 andsignature 119898 and signature 2 and signature 119898 are filtered
32 Number of False Positives A candidate pair ⟨1198781 1198782⟩ is
false positive if sim(⟨1198781 1198782⟩) lt 119869 and 119878
1 1198782share at least
119896 common bucket arrays Since the efficiency of LSH ismainly dependent on the number of false positives and mostreal applications demand a high precision we first derivethe possible number of false positives generated by the newbanding technique
Lemma 1 The upper bound of false positives generated by thenew banding technique is equal to the original LSH and thelower bound is approximate to 0
Proof According to the law of large numbers the probabilitythat theminhash values of two feature vectors (eg 119878
1 1198782) are
equal under any random permutation ℎ is very close to thefrequency percentage of observing identical value in the sameposition at two long signatures of the corresponding featurevectors That is
where 119899 is the length of signatures Sig(1198781) and Sig(119878
2) 119903 is the
position in signatures 119903 isin [1 119899]Also the probability that a random permutation of two
feature vectors produces the same minhash value equals theJaccard similarity of those instances [17] That is
119875 (min ℎ (1198781) = min ℎ (119878
2)) =
10038161003816100381610038161198781 cap 1198782
100381610038161003816100381610038161003816100381610038161198781 cup 119878
2
1003816100381610038161003816
= sim (1198781 1198782)
(3)
Based on the above two equations the probability oftwo instances with Jaccard similarity 119904 is considered to be acandidate pair by the new banding technique denoted by119875newas
Figure 1 An illustrative example of banding technique
where 119904 is the Jaccard similarity of the two instances 119903 isthe length of each band and 119887 is the number of bands Wecan prove the derivative of 119875new(119904) is greater than 0 whichrepresents 119875new(119904) a monotonically increasing function of 119904
The number of false positive denoted by FPmax(119896) is
FPmax (119896) = int
119869
0
119873119904119875new (119904) 119889119904 (5)
where 119873119904denotes the total number of similar pairs whose
Jaccard similarity is 119904 in the instances set Given an instanceset 119873
119904is a constant 119869 is the given similarity threshold
The value of FPmax(119896) depends on the similarity distri-bution of a given instance set The upper bound of FPmax(119896)equals the original LSH FPmax(1) Without the knowledge ofthe similarity distribution of the data set the lower boundof false positives cannot be directly derived Hence weintroduce a threshold 120598 to ensure
FPmax (119896)
FPmax (1)le 120598 (6)
where 120598 is close to zero with increasing 119896 If 119896 is lfloor119869119899119903rfloorthe lower bound of false positives approximates to 0 whichindicates that the candidates generated by the proposed newbanding technique are almost all truly similar pairs
To understand the zero lower bound with 119896 = lfloor119869119899119903rfloorsuppose there are two signatures with 119899 elements each lfloor119869119899119903rfloorbands of which are mapped to the same bucket At least119903lfloor119869119899119903rfloor asymp 119869119899 elements in the two signatures are identicalbecause a band includes 119903 elements According to (2) and (3)the approximate similarity between the two correspondinginstances is then greater than 119869119899119899 = 119869 Hence similarity foreach pair of signatures is greater than the threshold 119869 and nofalse positives exist
The introduction of 120598 also enables us to personalizethe number of false positives that is to vary the rangeof 119896 for different 120598 The range of 119896 for a desired 120598 isa function of 119869 119887 119903 that can be numerically solved For
Figure 2 An illustrative example of number of false positives forvarious 119896
example given 119869 = 07 119887 = 20 119903 = 5 Figure 2 showsthe trend of FPmax(119896)FPmax(1) for 119896 The minimum ofFPmax(119896)FPmax(1) is achieved when 119896 = 119887 If the desired120598 = 04 we can find a satisfying range of 119896 isin [3 20] sinceFPmax(2)FPmax(1) ge 120598 and FPmax(3)FPmax(1) le 120598
33 Number of False Negatives False negatives are trulysimilar pairs mapped to disjoint bucket arraysWe also derivethe upper and lower bound of false negatives generated by theproposed new banding technique
Lemma 2 The upper bound of false negatives generated by thenew banding technique is sum
119887minus1
119894=0(( 119894119887) (119904119903)119894(1 minus 119904
119903)119887minus119894
)119873119904ge119869
Thelower bound is close to the original LSH
Proof Similar to Section 32 the number of false negativesdenoted by FNmax(119896) is
FNmax (119896) = int
1
119869
119873119904(1 minus 119875new (119904)) 119889119904 (7)
FNmax(119896) is a monotonic increasing function of 119896 The lowerbound of it is achieved when 119896 = 1 The upper bound of
Computational Intelligence and Neuroscience 5
FNmax(119896) is obtained when 119896 is the total number of bandsHence the upper bound of FNmax(119896) is proportional to thenumber of similar instances 119873
119904ge119869
lim119896rarr119887
FNmax (119896) = (
119887minus1
sum
119894=0
(119894
119887) (119904119903)119894
(1 minus 119904119903)119887minus119894
)119873119904ge119869
(8)
For a desired the number of false negatives we do adivision between FNmax(119896) and FNmax(1) in terms of
FNmax (119896)
FNmax (1)le 120598 (9)
where 120598 is a threshold which is always greater than 1 By deriv-ing the numerical solution for int
1
119869119873119904(1 minus (sum
119887minus1
119894=0( 119894119887) (119904119903)119894(1 minus
119904119903)119887minus119894
))119889119904 the range of 119896 for a desired 120598 is obtained Forexample given the arguments 119869 = 07 119887 = 20 119903 = 5 Figure 3shows us the trend of FNmax(119896)FNmax(1) If the desired 120598 =
100 from Figure 3 we can find that FNmax(5)FNmax(1) asymp 70
and FNmax(6)FNmax(1) asymp 100 so the satisfying range is119896 isin [1 5]
34 Balance False Positives and False Negatives In someapplication scenarios wewant to have a balance between falsepositives and false negatives Here we analyse a special casewhere we want a desired aggregated number of false positivesand false negativesWe use FNPmax to denote the sum of falsepositives and false negatives which is defined as follows
The lower bound of FNPmax(119896) is dependent on thesimilarity distribution of the given data set However sincein most cases 119873
119904lt119869≫ 119873119904ge119869
thus FNPmax(119896) = 119873119904lt119869
119875new(119896) +
119873119904≫119869
(1 minus 119875new(119896)) is less than FNPmax(1) when 119896 is appropri-ately chosen
Inspired by Sections 32 and 33 we can also use athreshold 120598 to obtain the desired degree of precision Asshown in Figure 4 the ratio of FNPmax(119896)FNPmax(1) for119869 = 07 119887 = 20 119903 = 5 on a uniformly distributed data setfirst decreases as the value of 119896 increases The minimum is120598 = 02674when 119896 = 4 Then the ratio increases as 119896 becomeslarger If we are required to have a higher precision of thenew banding technique compared with traditional bandingtechnique in terms of aggregated number of false negativesand false positives (ie small FNPmax(119896)FNPmax(1) le 1)then 119896 isin [1 12] is acceptable
4 MapReduce Implementation of PLSH
In this section we first introduce theMapReduce frameworkThen we present the details of implementing PersonalizedLSH with MapReduce including minhashing banding andverification
Figure 4 An illustrative example of balancing false positives andfalse negatives
41 MapReduce MapReduce [26] is a framework for pro-cessing paralleled algorithms on large scale data sets usinga cluster of computers MapReduce allows for distributedprocessing of data which is partitioned and stored in adistributed file system (HDFS) Data is stored in the form of⟨119896119890119910 V119886119897119906119890⟩ pairs to facilitate computation
As illustrated in Figure 5 the MapReduce data flowconsists of two key phases the map phase and the reducephase In the map phase each computing node works onthe local input data and processes the input ⟨119896119890119910 V119886119897119906119890⟩pairs to a list of intermediate pairs ⟨119896119890119910 V119886119897119906119890⟩ in a differentdomain The ⟨119896119890119910 V119886119897119906119890⟩ pairs generated in map phase arehash-partitioned and sorted by the key and then they are sentacross the computing cluster in a shuffle phase In the reducephase pairs with the same key are passed to the same reducetask User-provided functions are processed in the reducetask on each key to produce the desired output
In similarity joins to generate ⟨119896119890119910 V119886119897119906119890⟩ pairs we firstsegment the join attributes in each instance to tokens Eachtoken is denoted by a unique integer id In the following stepstoken id is used to represent each feature
42 MinHashing We use one map reduce job to implementminhashing Before the map function is called ⟨119905119900119896119890119899 119894119889⟩
6 Computational Intelligence and Neuroscience
Input 0
Input 1
Input 2
Map
Map
Map
ReduceSort
Sort
Sort Reduce
Output 0
Output 1
Shuffle
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
feature vector in Table 1 is 119886119887119888119889119890119891 suppose the permutedfeature vector is 119887119886119888119889119891119890 then feature vectors for 119860 119861 119862 119863and 119864 become (100001) (010011) (100101) (001100) and(000110) as illustrated in Table 2Thus the minhash value for119860 119861 119862 119863 and 119864 is 1 2 1 3 and 4 respectively
We can choose 119899 independent permutations ℎ1 ℎ2
ℎ119899 Suppose the minhash value of an instance 119878
119894for a certain
permutation ℎ119895is denoted by min ℎ
119895(119878119894) then the signature
denoted by Sig(119878119894) is
Sig (119878119894) = (min ℎ
1(119878119894) min ℎ
2(119878119894) min ℎ
119899(119878119894)) (1)
The approximate similarity between two instances basedon their signatures is defined as the percentage of identicalvalues at the same position in the corresponding signaturesFor example given 119899 = 6 Sig(119878
22 Banding Given a large set of signatures generated inSection 21 it is still too costly to compare similarities for allsignature pairs Therefore a banding technique is presentedconsequently to filter dissimilar pairs
The banding technique divides each signature into 119887
bands where each band consists of 119903 elements For each bandof every signature the banding technique maps the vector of119903 elements to a bucket array
As shown in Figure 1 the 119894th band of each signature mapsto bucket array 119894 Intuitively if for a pair of signatures thecorresponding bucket arrays have at least one bucket array incommon then the pair is likely to be similar For examplesignature 1 and signature 2 and signature 2 and signature 119898
in Figure 1 are similar Such a pair with common bucket arrayis considered to be a candidate pair and needs to be verifiedin the banding technique
3 Personalized LSH
31 New Banding Technique The candidates generated byLSH are not guaranteed to be similar pairs Chances are thata pair of signatures are projected to identical bucket arrayseven if the Jaccard similarity between the pair of instancesis not larger than the given threshold In the meantime apair of instances can be filtered out from candidates sincetheir corresponding signatures are projected into disjointbucket arrays even if the Jaccard similarity is smaller than thegiven thresholdThe former case is called false positive while
the latter one is called false negative Massive false positiveswill lead to inaccurate results while a large amount of falsenegatives will deteriorate computational efficiency of LSH Toenhance the algorithm precision and efficiency we presenthere a new banding scheme to filter more dissimilar instancepairs Intuitively if two instances are highly alike it is possiblethat many bands of the two corresponding signatures aremapped to identical buckets For example in Figure 1 thereare at least 3 bands (ie the 1st the 5th and the 119887th bands)of signature 1 and signature 2 which map to the same buckets(ie in the corresponding bucket array 1 5 119887)
Therefore we change the banding scheme as follows Forany pair of instances if the two corresponding signatures donot map into at least 119896 (119896 isin [1 119887]) identical buckets it will befiltered out Otherwise it is considered to be a candidate pairand the exact Jaccard similarity is computed and verified Forthe signatures shown in Figure 1 given 119896 = 3 signature 1 andsignature 119898 and signature 2 and signature 119898 are filtered
32 Number of False Positives A candidate pair ⟨1198781 1198782⟩ is
false positive if sim(⟨1198781 1198782⟩) lt 119869 and 119878
1 1198782share at least
119896 common bucket arrays Since the efficiency of LSH ismainly dependent on the number of false positives and mostreal applications demand a high precision we first derivethe possible number of false positives generated by the newbanding technique
Lemma 1 The upper bound of false positives generated by thenew banding technique is equal to the original LSH and thelower bound is approximate to 0
Proof According to the law of large numbers the probabilitythat theminhash values of two feature vectors (eg 119878
1 1198782) are
equal under any random permutation ℎ is very close to thefrequency percentage of observing identical value in the sameposition at two long signatures of the corresponding featurevectors That is
where 119899 is the length of signatures Sig(1198781) and Sig(119878
2) 119903 is the
position in signatures 119903 isin [1 119899]Also the probability that a random permutation of two
feature vectors produces the same minhash value equals theJaccard similarity of those instances [17] That is
119875 (min ℎ (1198781) = min ℎ (119878
2)) =
10038161003816100381610038161198781 cap 1198782
100381610038161003816100381610038161003816100381610038161198781 cup 119878
2
1003816100381610038161003816
= sim (1198781 1198782)
(3)
Based on the above two equations the probability oftwo instances with Jaccard similarity 119904 is considered to be acandidate pair by the new banding technique denoted by119875newas
Figure 1 An illustrative example of banding technique
where 119904 is the Jaccard similarity of the two instances 119903 isthe length of each band and 119887 is the number of bands Wecan prove the derivative of 119875new(119904) is greater than 0 whichrepresents 119875new(119904) a monotonically increasing function of 119904
The number of false positive denoted by FPmax(119896) is
FPmax (119896) = int
119869
0
119873119904119875new (119904) 119889119904 (5)
where 119873119904denotes the total number of similar pairs whose
Jaccard similarity is 119904 in the instances set Given an instanceset 119873
119904is a constant 119869 is the given similarity threshold
The value of FPmax(119896) depends on the similarity distri-bution of a given instance set The upper bound of FPmax(119896)equals the original LSH FPmax(1) Without the knowledge ofthe similarity distribution of the data set the lower boundof false positives cannot be directly derived Hence weintroduce a threshold 120598 to ensure
FPmax (119896)
FPmax (1)le 120598 (6)
where 120598 is close to zero with increasing 119896 If 119896 is lfloor119869119899119903rfloorthe lower bound of false positives approximates to 0 whichindicates that the candidates generated by the proposed newbanding technique are almost all truly similar pairs
To understand the zero lower bound with 119896 = lfloor119869119899119903rfloorsuppose there are two signatures with 119899 elements each lfloor119869119899119903rfloorbands of which are mapped to the same bucket At least119903lfloor119869119899119903rfloor asymp 119869119899 elements in the two signatures are identicalbecause a band includes 119903 elements According to (2) and (3)the approximate similarity between the two correspondinginstances is then greater than 119869119899119899 = 119869 Hence similarity foreach pair of signatures is greater than the threshold 119869 and nofalse positives exist
The introduction of 120598 also enables us to personalizethe number of false positives that is to vary the rangeof 119896 for different 120598 The range of 119896 for a desired 120598 isa function of 119869 119887 119903 that can be numerically solved For
Figure 2 An illustrative example of number of false positives forvarious 119896
example given 119869 = 07 119887 = 20 119903 = 5 Figure 2 showsthe trend of FPmax(119896)FPmax(1) for 119896 The minimum ofFPmax(119896)FPmax(1) is achieved when 119896 = 119887 If the desired120598 = 04 we can find a satisfying range of 119896 isin [3 20] sinceFPmax(2)FPmax(1) ge 120598 and FPmax(3)FPmax(1) le 120598
33 Number of False Negatives False negatives are trulysimilar pairs mapped to disjoint bucket arraysWe also derivethe upper and lower bound of false negatives generated by theproposed new banding technique
Lemma 2 The upper bound of false negatives generated by thenew banding technique is sum
119887minus1
119894=0(( 119894119887) (119904119903)119894(1 minus 119904
119903)119887minus119894
)119873119904ge119869
Thelower bound is close to the original LSH
Proof Similar to Section 32 the number of false negativesdenoted by FNmax(119896) is
FNmax (119896) = int
1
119869
119873119904(1 minus 119875new (119904)) 119889119904 (7)
FNmax(119896) is a monotonic increasing function of 119896 The lowerbound of it is achieved when 119896 = 1 The upper bound of
Computational Intelligence and Neuroscience 5
FNmax(119896) is obtained when 119896 is the total number of bandsHence the upper bound of FNmax(119896) is proportional to thenumber of similar instances 119873
119904ge119869
lim119896rarr119887
FNmax (119896) = (
119887minus1
sum
119894=0
(119894
119887) (119904119903)119894
(1 minus 119904119903)119887minus119894
)119873119904ge119869
(8)
For a desired the number of false negatives we do adivision between FNmax(119896) and FNmax(1) in terms of
FNmax (119896)
FNmax (1)le 120598 (9)
where 120598 is a threshold which is always greater than 1 By deriv-ing the numerical solution for int
1
119869119873119904(1 minus (sum
119887minus1
119894=0( 119894119887) (119904119903)119894(1 minus
119904119903)119887minus119894
))119889119904 the range of 119896 for a desired 120598 is obtained Forexample given the arguments 119869 = 07 119887 = 20 119903 = 5 Figure 3shows us the trend of FNmax(119896)FNmax(1) If the desired 120598 =
100 from Figure 3 we can find that FNmax(5)FNmax(1) asymp 70
and FNmax(6)FNmax(1) asymp 100 so the satisfying range is119896 isin [1 5]
34 Balance False Positives and False Negatives In someapplication scenarios wewant to have a balance between falsepositives and false negatives Here we analyse a special casewhere we want a desired aggregated number of false positivesand false negativesWe use FNPmax to denote the sum of falsepositives and false negatives which is defined as follows
The lower bound of FNPmax(119896) is dependent on thesimilarity distribution of the given data set However sincein most cases 119873
119904lt119869≫ 119873119904ge119869
thus FNPmax(119896) = 119873119904lt119869
119875new(119896) +
119873119904≫119869
(1 minus 119875new(119896)) is less than FNPmax(1) when 119896 is appropri-ately chosen
Inspired by Sections 32 and 33 we can also use athreshold 120598 to obtain the desired degree of precision Asshown in Figure 4 the ratio of FNPmax(119896)FNPmax(1) for119869 = 07 119887 = 20 119903 = 5 on a uniformly distributed data setfirst decreases as the value of 119896 increases The minimum is120598 = 02674when 119896 = 4 Then the ratio increases as 119896 becomeslarger If we are required to have a higher precision of thenew banding technique compared with traditional bandingtechnique in terms of aggregated number of false negativesand false positives (ie small FNPmax(119896)FNPmax(1) le 1)then 119896 isin [1 12] is acceptable
4 MapReduce Implementation of PLSH
In this section we first introduce theMapReduce frameworkThen we present the details of implementing PersonalizedLSH with MapReduce including minhashing banding andverification
Figure 4 An illustrative example of balancing false positives andfalse negatives
41 MapReduce MapReduce [26] is a framework for pro-cessing paralleled algorithms on large scale data sets usinga cluster of computers MapReduce allows for distributedprocessing of data which is partitioned and stored in adistributed file system (HDFS) Data is stored in the form of⟨119896119890119910 V119886119897119906119890⟩ pairs to facilitate computation
As illustrated in Figure 5 the MapReduce data flowconsists of two key phases the map phase and the reducephase In the map phase each computing node works onthe local input data and processes the input ⟨119896119890119910 V119886119897119906119890⟩pairs to a list of intermediate pairs ⟨119896119890119910 V119886119897119906119890⟩ in a differentdomain The ⟨119896119890119910 V119886119897119906119890⟩ pairs generated in map phase arehash-partitioned and sorted by the key and then they are sentacross the computing cluster in a shuffle phase In the reducephase pairs with the same key are passed to the same reducetask User-provided functions are processed in the reducetask on each key to produce the desired output
In similarity joins to generate ⟨119896119890119910 V119886119897119906119890⟩ pairs we firstsegment the join attributes in each instance to tokens Eachtoken is denoted by a unique integer id In the following stepstoken id is used to represent each feature
42 MinHashing We use one map reduce job to implementminhashing Before the map function is called ⟨119905119900119896119890119899 119894119889⟩
6 Computational Intelligence and Neuroscience
Input 0
Input 1
Input 2
Map
Map
Map
ReduceSort
Sort
Sort Reduce
Output 0
Output 1
Shuffle
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 1 An illustrative example of banding technique
where 119904 is the Jaccard similarity of the two instances 119903 isthe length of each band and 119887 is the number of bands Wecan prove the derivative of 119875new(119904) is greater than 0 whichrepresents 119875new(119904) a monotonically increasing function of 119904
The number of false positive denoted by FPmax(119896) is
FPmax (119896) = int
119869
0
119873119904119875new (119904) 119889119904 (5)
where 119873119904denotes the total number of similar pairs whose
Jaccard similarity is 119904 in the instances set Given an instanceset 119873
119904is a constant 119869 is the given similarity threshold
The value of FPmax(119896) depends on the similarity distri-bution of a given instance set The upper bound of FPmax(119896)equals the original LSH FPmax(1) Without the knowledge ofthe similarity distribution of the data set the lower boundof false positives cannot be directly derived Hence weintroduce a threshold 120598 to ensure
FPmax (119896)
FPmax (1)le 120598 (6)
where 120598 is close to zero with increasing 119896 If 119896 is lfloor119869119899119903rfloorthe lower bound of false positives approximates to 0 whichindicates that the candidates generated by the proposed newbanding technique are almost all truly similar pairs
To understand the zero lower bound with 119896 = lfloor119869119899119903rfloorsuppose there are two signatures with 119899 elements each lfloor119869119899119903rfloorbands of which are mapped to the same bucket At least119903lfloor119869119899119903rfloor asymp 119869119899 elements in the two signatures are identicalbecause a band includes 119903 elements According to (2) and (3)the approximate similarity between the two correspondinginstances is then greater than 119869119899119899 = 119869 Hence similarity foreach pair of signatures is greater than the threshold 119869 and nofalse positives exist
The introduction of 120598 also enables us to personalizethe number of false positives that is to vary the rangeof 119896 for different 120598 The range of 119896 for a desired 120598 isa function of 119869 119887 119903 that can be numerically solved For
Figure 2 An illustrative example of number of false positives forvarious 119896
example given 119869 = 07 119887 = 20 119903 = 5 Figure 2 showsthe trend of FPmax(119896)FPmax(1) for 119896 The minimum ofFPmax(119896)FPmax(1) is achieved when 119896 = 119887 If the desired120598 = 04 we can find a satisfying range of 119896 isin [3 20] sinceFPmax(2)FPmax(1) ge 120598 and FPmax(3)FPmax(1) le 120598
33 Number of False Negatives False negatives are trulysimilar pairs mapped to disjoint bucket arraysWe also derivethe upper and lower bound of false negatives generated by theproposed new banding technique
Lemma 2 The upper bound of false negatives generated by thenew banding technique is sum
119887minus1
119894=0(( 119894119887) (119904119903)119894(1 minus 119904
119903)119887minus119894
)119873119904ge119869
Thelower bound is close to the original LSH
Proof Similar to Section 32 the number of false negativesdenoted by FNmax(119896) is
FNmax (119896) = int
1
119869
119873119904(1 minus 119875new (119904)) 119889119904 (7)
FNmax(119896) is a monotonic increasing function of 119896 The lowerbound of it is achieved when 119896 = 1 The upper bound of
Computational Intelligence and Neuroscience 5
FNmax(119896) is obtained when 119896 is the total number of bandsHence the upper bound of FNmax(119896) is proportional to thenumber of similar instances 119873
119904ge119869
lim119896rarr119887
FNmax (119896) = (
119887minus1
sum
119894=0
(119894
119887) (119904119903)119894
(1 minus 119904119903)119887minus119894
)119873119904ge119869
(8)
For a desired the number of false negatives we do adivision between FNmax(119896) and FNmax(1) in terms of
FNmax (119896)
FNmax (1)le 120598 (9)
where 120598 is a threshold which is always greater than 1 By deriv-ing the numerical solution for int
1
119869119873119904(1 minus (sum
119887minus1
119894=0( 119894119887) (119904119903)119894(1 minus
119904119903)119887minus119894
))119889119904 the range of 119896 for a desired 120598 is obtained Forexample given the arguments 119869 = 07 119887 = 20 119903 = 5 Figure 3shows us the trend of FNmax(119896)FNmax(1) If the desired 120598 =
100 from Figure 3 we can find that FNmax(5)FNmax(1) asymp 70
and FNmax(6)FNmax(1) asymp 100 so the satisfying range is119896 isin [1 5]
34 Balance False Positives and False Negatives In someapplication scenarios wewant to have a balance between falsepositives and false negatives Here we analyse a special casewhere we want a desired aggregated number of false positivesand false negativesWe use FNPmax to denote the sum of falsepositives and false negatives which is defined as follows
The lower bound of FNPmax(119896) is dependent on thesimilarity distribution of the given data set However sincein most cases 119873
119904lt119869≫ 119873119904ge119869
thus FNPmax(119896) = 119873119904lt119869
119875new(119896) +
119873119904≫119869
(1 minus 119875new(119896)) is less than FNPmax(1) when 119896 is appropri-ately chosen
Inspired by Sections 32 and 33 we can also use athreshold 120598 to obtain the desired degree of precision Asshown in Figure 4 the ratio of FNPmax(119896)FNPmax(1) for119869 = 07 119887 = 20 119903 = 5 on a uniformly distributed data setfirst decreases as the value of 119896 increases The minimum is120598 = 02674when 119896 = 4 Then the ratio increases as 119896 becomeslarger If we are required to have a higher precision of thenew banding technique compared with traditional bandingtechnique in terms of aggregated number of false negativesand false positives (ie small FNPmax(119896)FNPmax(1) le 1)then 119896 isin [1 12] is acceptable
4 MapReduce Implementation of PLSH
In this section we first introduce theMapReduce frameworkThen we present the details of implementing PersonalizedLSH with MapReduce including minhashing banding andverification
Figure 4 An illustrative example of balancing false positives andfalse negatives
41 MapReduce MapReduce [26] is a framework for pro-cessing paralleled algorithms on large scale data sets usinga cluster of computers MapReduce allows for distributedprocessing of data which is partitioned and stored in adistributed file system (HDFS) Data is stored in the form of⟨119896119890119910 V119886119897119906119890⟩ pairs to facilitate computation
As illustrated in Figure 5 the MapReduce data flowconsists of two key phases the map phase and the reducephase In the map phase each computing node works onthe local input data and processes the input ⟨119896119890119910 V119886119897119906119890⟩pairs to a list of intermediate pairs ⟨119896119890119910 V119886119897119906119890⟩ in a differentdomain The ⟨119896119890119910 V119886119897119906119890⟩ pairs generated in map phase arehash-partitioned and sorted by the key and then they are sentacross the computing cluster in a shuffle phase In the reducephase pairs with the same key are passed to the same reducetask User-provided functions are processed in the reducetask on each key to produce the desired output
In similarity joins to generate ⟨119896119890119910 V119886119897119906119890⟩ pairs we firstsegment the join attributes in each instance to tokens Eachtoken is denoted by a unique integer id In the following stepstoken id is used to represent each feature
42 MinHashing We use one map reduce job to implementminhashing Before the map function is called ⟨119905119900119896119890119899 119894119889⟩
6 Computational Intelligence and Neuroscience
Input 0
Input 1
Input 2
Map
Map
Map
ReduceSort
Sort
Sort Reduce
Output 0
Output 1
Shuffle
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
FNmax(119896) is obtained when 119896 is the total number of bandsHence the upper bound of FNmax(119896) is proportional to thenumber of similar instances 119873
119904ge119869
lim119896rarr119887
FNmax (119896) = (
119887minus1
sum
119894=0
(119894
119887) (119904119903)119894
(1 minus 119904119903)119887minus119894
)119873119904ge119869
(8)
For a desired the number of false negatives we do adivision between FNmax(119896) and FNmax(1) in terms of
FNmax (119896)
FNmax (1)le 120598 (9)
where 120598 is a threshold which is always greater than 1 By deriv-ing the numerical solution for int
1
119869119873119904(1 minus (sum
119887minus1
119894=0( 119894119887) (119904119903)119894(1 minus
119904119903)119887minus119894
))119889119904 the range of 119896 for a desired 120598 is obtained Forexample given the arguments 119869 = 07 119887 = 20 119903 = 5 Figure 3shows us the trend of FNmax(119896)FNmax(1) If the desired 120598 =
100 from Figure 3 we can find that FNmax(5)FNmax(1) asymp 70
and FNmax(6)FNmax(1) asymp 100 so the satisfying range is119896 isin [1 5]
34 Balance False Positives and False Negatives In someapplication scenarios wewant to have a balance between falsepositives and false negatives Here we analyse a special casewhere we want a desired aggregated number of false positivesand false negativesWe use FNPmax to denote the sum of falsepositives and false negatives which is defined as follows
The lower bound of FNPmax(119896) is dependent on thesimilarity distribution of the given data set However sincein most cases 119873
119904lt119869≫ 119873119904ge119869
thus FNPmax(119896) = 119873119904lt119869
119875new(119896) +
119873119904≫119869
(1 minus 119875new(119896)) is less than FNPmax(1) when 119896 is appropri-ately chosen
Inspired by Sections 32 and 33 we can also use athreshold 120598 to obtain the desired degree of precision Asshown in Figure 4 the ratio of FNPmax(119896)FNPmax(1) for119869 = 07 119887 = 20 119903 = 5 on a uniformly distributed data setfirst decreases as the value of 119896 increases The minimum is120598 = 02674when 119896 = 4 Then the ratio increases as 119896 becomeslarger If we are required to have a higher precision of thenew banding technique compared with traditional bandingtechnique in terms of aggregated number of false negativesand false positives (ie small FNPmax(119896)FNPmax(1) le 1)then 119896 isin [1 12] is acceptable
4 MapReduce Implementation of PLSH
In this section we first introduce theMapReduce frameworkThen we present the details of implementing PersonalizedLSH with MapReduce including minhashing banding andverification
Figure 4 An illustrative example of balancing false positives andfalse negatives
41 MapReduce MapReduce [26] is a framework for pro-cessing paralleled algorithms on large scale data sets usinga cluster of computers MapReduce allows for distributedprocessing of data which is partitioned and stored in adistributed file system (HDFS) Data is stored in the form of⟨119896119890119910 V119886119897119906119890⟩ pairs to facilitate computation
As illustrated in Figure 5 the MapReduce data flowconsists of two key phases the map phase and the reducephase In the map phase each computing node works onthe local input data and processes the input ⟨119896119890119910 V119886119897119906119890⟩pairs to a list of intermediate pairs ⟨119896119890119910 V119886119897119906119890⟩ in a differentdomain The ⟨119896119890119910 V119886119897119906119890⟩ pairs generated in map phase arehash-partitioned and sorted by the key and then they are sentacross the computing cluster in a shuffle phase In the reducephase pairs with the same key are passed to the same reducetask User-provided functions are processed in the reducetask on each key to produce the desired output
In similarity joins to generate ⟨119896119890119910 V119886119897119906119890⟩ pairs we firstsegment the join attributes in each instance to tokens Eachtoken is denoted by a unique integer id In the following stepstoken id is used to represent each feature
42 MinHashing We use one map reduce job to implementminhashing Before the map function is called ⟨119905119900119896119890119899 119894119889⟩
6 Computational Intelligence and Neuroscience
Input 0
Input 1
Input 2
Map
Map
Map
ReduceSort
Sort
Sort Reduce
Output 0
Output 1
Shuffle
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 5 An illustrative example of MapReduce data flow with 2reduce tasks
pairs are loaded In themap task each instance is representedby a set of tokens 119894119889 present in this instance
In the reduce task for each instance the reducer producesa signature with length 119899 As described in Section 2 the min-hashing function requires random permutations of featuresBut it is not feasible to permute massive features explicitlyInstead a random hash function is adopted to simulate thistask Suppose the total number of features is 119905119888 integer set119883 = [0 1 119905119888 minus 1] we choose the hash function as
where 119886 119887 119894 isin [0 119905119888 minus 1] and 119886 119905119888 must be relatively primeand 119886 mod 119887 is a function that obtains the remainder of 119886
divided by 119887 It maps a number 119894 isin [0 119905119888 minus 1] to anothernumber ℎ(119894) isin [0 119905119888 minus 1] with no collision Hence the resultlist ℎ(0) ℎ(1) ℎ(119905119888 minus 1) is a permutation of the originalfeatures
Furthermore since it requires 119899 independent permuta-tions to produce a signature for each instance we prove thatthere are more than 119899 different permutations
Lemma 3 Given 119905119888 features the desired signature length 119899 thehash function ℎ(119894) = (119886 lowast 119894 + 119887) mod 119905119888 where 119886 119887 and 119894 isin
[0 119905119888 minus 1] produces more than 119899 different permutations
Proof Assume a permutation 1199090 1199091 119909
119905119888minus1is generated
by hash function ℎ with parameters 119886 and 119887 then 119887 = 1199090
1199091= (119886+119887) mod 119905119888 119886 = (119909
1minus119887+119905119888) mod 119905119888 and119909
119896+1= (119909119896+
119886) mod 119905119888 119896 isin [0 119905119888 minus 2] Hence for a specified 119886 differentintegers 119887 isin [0 119905119888minus1] produce different permutations Eulerrsquostotient function 120601(119899
1015840) is an arithmetic function that counts
the number of totatives of integer 1198991015840 which indicates the
number of desired 119886 is 120601(119905119888)Therefore there are 120601(119905119888)119905119888 pairsof ⟨119886 119887⟩ which produce 120601(119905119888)119905119888 different permutations Since120601(119905119888)119905119888 ge 119905119888 ge 119899 we prove that hash function ℎ producesmore than 119899 different permutations
43 Banding Banding technique filters dissimilar pairs Asshown in Figure 6 we implement the banding procedure intwo MapReduce phases
In the first phase the signatures are input to the mapfunction The map function divides each signature into 119887
bands each band consists of 119903 elements and then eachband is mapped to a bucket The outputs are in form of⟨[119887119886119899119889119868119889 119887119906119888119896119890119905119868119889] 119894119899119904119905119886119899119888119890119868119889⟩ In other words 119887119886119899119889119868119889
and 119887119906119888119896119890119905119868119889 are combined as a key and 119894119899119904119905119886119899119888119890119868119889 isassigned to the corresponding value For example as shown
in Figure 6 the signature of instance 1 is (1 2 11 3 4 23 sdot sdot sdot )and (2 2 13 3 4 23 sdot sdot sdot ) for instance 2 Suppose 119903 = 3 theninstance 1 is divided into at least 2 bands (1 2 11) and (3 423) The two bands are mapped to bucket 11 in bucket array1 and bucket 12 in bucket array 2 So the outputs of mapfunction for instance 1 include ⟨[1 11] 1⟩ and ⟨[2 12] 1⟩Analogously ⟨[1 5] 2⟩ and ⟨[2 12] 2⟩ are a part of mapoutputs for instance 2
In reduce task all instances with the same 119887119886119899119889119868119889 and119887119906119888119896119890119905119868119889 are assigned to the same reduce task An output inthe form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 1⟩ is produced forevery pair of instances where the fixed value 1 representsthe occurrence frequency for pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]For instance ⟨[1 5] 2⟩ and ⟨[1 5] 23⟩ are the aforemen-tioned map outputs for instances 1 and 2 since they have thesame 119887119886119899119889119868119889 1 and 119887119906119888119896119890119905119868119889 5 the reduce task produces apair ⟨[2 23] 1⟩ That is to say instance 2 and instance 23 arelikely to be a candidate pair because their first bands are bothmapped to the 5th bucket
In the second phase the map task outputs what isproduced in the first phrase To minimize the networktraffic between the map and reduce functions we use acombine function to aggregate the outputs generated by themap function into partial local counts in the computingnode Subsequently the reduce function computes the totalcounts for each instance pair Outputs of the reduce functionare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119888119900119906119899119905⟩ pairswhere 119888119900119906119899119905 is the global frequency for the instance pairPersonalized LSH eliminates those pairs of instances whose119888119900119906119899119905 is less than the given threshold 119896 As shown in Figure 6suppose 119896 = 12 the count of instance pair ⟨[2 23] 15⟩ isgreater than 119896 so [2 23] is a candidate pair
44 Verification Candidate pairs generated in Section 43need to be checked in the verification stage For eachcandidate instance pair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] signaturesimilarity is computed Because of the massive number ofinstances it is not a trivial task
In order to reduce the storage cost for each reducetask the set of signatures for all instances is partitionedinto small files according to instance ids In this wayeach reduce task holds only two different small partitionswhere the first partition is for the first instance in the pair[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] and the second partition is forthe second instance For example for each reduce inputpair [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] the first partition containsthe signature for instance1198681198891 while the second partitioncontains the signature for 1198941198991199041199051198861198991198881198901198681198892 All pairs of instancesids contained in the same partitions have to be assigned to thesame reduce task Hence map task calculates the reduce taskid for each pair according to its instances ids and producesan output ⟨119903119890119889119906119888119890119879119886119904119896119868119889 [1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892]⟩ Inreduce task signatures similarity for each pair of instancesis computed Finally reduce task outputs pairs whose sim-ilarities are greater than the given threshold 119869 The outputsare in the form of ⟨[1198941198991199041199051198861198991198881198901198681198891 1198941198991199041199051198861198991198881198901198681198892] 119904119894119898⟩ where119904119894119898 is the Jaccard similarity for 1198941198991199041199051198861198991198881198901198681198891 and 1198941198991199041199051198861198991198881198901198681198892As shown in Figure 7 suppose the given threshold 119869 = 07
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
ValueKey Value Key Value Key Value Key Value Key Value
Figure 6 An illustrative example of data flow in banding stage
similarity between signature 2 and signature 5 is 073 whichis greater than 119869 the output is ⟨[2 5] 073⟩
5 Experiment Evaluation
In this section we design a series of experiments to analyzethe performance of the proposed PLSH algorithms We wantto study the following research questions
(i) The efficiency of PLSH for example is the PLSH fastcompared with other similarity join algorithms Canit scale to large scale data setsWill the different valuesof parameters affect the efficiency of PLSH
(ii) The effectiveness of PLSH for example is the PLSHaccurate Can it generate less false positives and falsenegatives
(iii) The personalization of PLSH for example howshould we set the parameters of PLSH to generate thedesired number of false positives and false negativesIs the tailored PLSH more appropriate for differentapplications
The experiments are conducted on a 6-node cluster Eachnode has one processor i7-3820 36GHz with four cores32GB of RAM and 100Ghard disks On each node we installthe Ubuntu 1204 64-bit server edition operating systemJava 16 with a 64-bit server JVM and Hadoop 10 ApacheHadoop is an open source implementation of MapReduceWe run 2 reduce tasks in parallel on each node
We use DBLP and CITESEERX dataset and increasethe number of instances when needed The original DBLPdataset has approximately 12M instances while the originalCITESEERX has about 13M instances As shown in Figure 8when increasing the number of instances of these two datasets CITESEERX occupies larger storage than DBLP
In our experiments we tokenize the data by word Theconcatenation of the paper title and the list of authors are thejoin attributes (ie paper title and the list of authors are twoattributes in each instance) The default threshold of Jaccard
similarity 119869 = 07 The default length of hash signature 119899 is100 and each band has 119903 = 5 elements
51 Efficiency of PLSH The ground truth is the truly similarpairs generated by fuzzyjoin [12] A 3-stage MapReduceapproach is implemented for end-to-end set-similarity joinalgorithm and selects instance pairs with Jaccard similaritiesgreater than the given threshold
We first compare the efficiency of our method PLSHwith fuzzyjoin on the DBLP and CITESEERX data sets TheCPU times of different algorithms are shown in Figure 9We can conclude from Figure 9 that (1) generally PLSH isfaster than fuzzyjoin When the number of instances is 75Min DBLP and CITESEERX the time cost of fuzzyjoin isnearly two times of that of PLSH (2) When the data sizeincreases the efficiency improvement is more significantThis suggests that PLSH is more scalable to large scale datasets (3) Fuzzyjoin takes roughly equivalent CPU time onDBLP and CITESEERX with similar size while PLSH worksfaster onDBLP than onCITESEERXThis suggests that PLSHis more affected by the similarity distribution in a data set
Next we analyze the effect of the number of reduce tasksfor algorithm efficiency Because the reduce task numberof verification step is different from the previous steps werecord the CPU time in the previous three stages (minhash-ing banding1 and banding2 note that banding procedureis completed in two MapReduce phases) and in verificationstep separately In the three steps we vary the reduce tasksnumber from 2 to 12 with a step size of 2 The data sets areDBLP datasets containing 06M 12M 25M 5M and 75Minstances respectively
From Figure 10 we have the following observations (1)In general the time cost of PLSH reduces with more reducetasks This verifies our assumption that the parallel mecha-nism improves the algorithm efficiency (2) When there areless than 25M instances CPU time decreases slowly withthe increasing reduce tasks number This is because the starttime of MapReduce cannot be shortened even though tasksnumber is increasingWhen the CPU time is more than 2000
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 7 An illustrative example of the data flow in verification stage
0
5
10
15
20
25
30
Dat
a siz
e (G
)
Number of instances
CITESEERXDBLP
06M 12M 25M 5M 75M 10M 15M 20M
Figure 8 Dataset sizes of DBLP and CITESEERX
seconds the percentage of start time is just a small part ofthe total time Therefore when the number of instances isrelatively large the improvement is more significant Thissuggests that the parallelmechanismof PLSH ismore suitablefor large scale data sets
We further study the speedup of reduce task numbersWe set the time cost with 2 reduce tasks as the baseline andplot the ratio between the running time versus the baselinefor various reduce task numbers From Figure 11 we observethat when the size of dataset increases the speedup is moresignificant But none of the curves is a straight line whichsuggest that the speedup is not linear with respect to thenumber of reduce tasks The limited speedup is due to twomain reasons (1)There are 5 jobs to find the similar instancesThe start time of each job will not be shortened (2) As thenumber of dataset increases more data is sent through thenetwork and more data is merged and reduced thus thetraffic cost cannot be reduced
The number of reduce tasks is fixed in the verificationstage However in this stage parameter 119896 in the proposed
PLSH has a significant effect on the running time Weanalyze the performance of PLSH with various values of119896 From Figure 12 we have the following observations (1)In general as the value of 119896 increases the time cost inverification stage decreases This suggests that with a larger119896 the proposed PLSH can better prune dissimilar pairs andenhance efficiency (2) When the data set is small that is thenumber of instances is smaller than 25M the enhancementis not obvious The underlying reason is that there are fewercandidates in a small data set (3) Speedup is significant inlarge scale data set (with more than 5M instances) whichsuggests the scalability of PLSH
52 Effectiveness Evaluation In this subsection we study theeffectiveness of PLSH and how the length of signature thedefined threshold and the parameter 119896 affect effectiveness
Computational Intelligence and Neuroscience 9
0
500
1000
1500
2000
2500
3000
2 4 6 8 10 12
CPU
tim
e (s)
Number of reduce tasks
06M12M
25M5M
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 10 CPU time of stages previous to verification for differentdata sizes with various reduce task number
115
225
335
445
555
6
2 4 6 8 10 12
Ratio
Number of reduce tasks
06M12M
25M5M
Figure 11 Relative CPU time for different data sizes with variousreduce task number
We first define four types of instances False positives(FP) are dissimilar pairs (similarity lower than the threshold)that are selected as candidates by PLSH True positives (TP)are similar pairs (similarity higher than the threshold) thatare selected as candidates by PLSH False negatives (FN)are similar pairs (similarity higher than the threshold) thatare pruned by PLSH True Negatives (TN) are dissimilarpairs (similarity lower than the threshold) that are pruned byPLSH
The numbers of FP with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 13We have the following observations (1) For a fixed signaturelength the number of false positives significantly decreaseswith larger 119896 (2) For larger 119896 (eg 119896 = 5) prolongingthe signature results in fewer false positives (3) For small 119896
0
50
100
150
200
250
1 2 3 4 5
CPU
tim
e (s)
k
06M12M25M
5M75M
Figure 12 Verification time with various 119896
0
500
1000
1500
2000
2500
3000
200 300 400 500 600 700Length of signature
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 13 The number of false positives with various signaturelength and 119896
and shorter signatures (lt400 elements) the number of falsepositives is uncertain The above three observations indicatethat the proposed PLSH can achieve a high precision withlarger 119896 longer signatures
The numbers of FP with various similarity threshold and119896 with signature length 119899 = 500 are shown in Figure 14We have the following observations (1) For a fixed simi-larity threshold the number of false positives significantlydecreases with larger 119896 (2) For a fixed 119896 the number offalse positives significantly decreases with larger similaritythreshold This is because with larger similarity thresholdthere are fewer qualified candidates
The numbers of FN with various signature length and 119896with similarity threshold 119869 = 07 are shown in Figure 15We have the following observations (1) For a fixed signaturelength the number of false negatives generated by original
10 Computational Intelligence and Neuroscience
0200400600800
10001200140016001800
07 08 09Similarity threshold
Num
ber o
f FP
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 14 Number of false positives with various similarity thresh-olds and 119896
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
200 300 400 500 600 700Length of signature
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 15 The number of false negatives with various signaturelengths and 119896
LSH (119896 = 1) is fewer than PLSH (2) For original LSH shortersignatures generate more FN (3) In terms of FN PLSH is notvery sensitive to the length of signature
The numbers of FN with various similarity thresholdand 119896 with signature length 119899 = 500 are shown inFigure 16 Although the number of false negatives for PLSHis larger than the original PLSH we observe that for largesimilarity threshold 119869 = 09 the difference is minute In mostapplications we want to search for very similar pairs thusthe PLSH will still perform good in most scenarios
Since the false negatives generated by PLSH are in generalmore than LSH we further use precision and specificity toevaluate the performance of PLSH Precision is defined asPR = TP(TP+FP) and specificity is defined asTN(FP+TN)In this subsection we want to analyze the effect of 119896 119899 and
0100020003000400050006000700080009000
07 08 09Similarity threshold
Num
ber o
f FN
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 16 The number of false negatives with various similaritythresholds and 119896
09997809998
099982099984099986099988
09999099992099994099996099998
1
200 300 400 500 600 700Length of signature
Spec
ifici
ty
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 17 Specificity with various 119899 and 119896
119869 in terms of precision and specificity We vary 119896 from 1 to 5with a step size of 1 119899 from 200 to 500 with a step size 100and 119869 from 07 to 09 with a step size 01
FromFigures 17 to 20 we have the following observations(1) The PLSH method performs better than LSH in terms ofspecificity and precision which demonstrates the potential ofPLSH in many data mining and bioinformatics applications(2) Generally longer signatures outperform shorter signa-tures
53 Personalized LSH As proved in Section 3 an importantcharacteristic of our proposed PLSH is that it is capable oftailoring the number of false positives and false negatives fordifferent applications In this subsection we present a pilotstudy on the tailoring capability of PLSHWefirst numericallyderive the appropriate 119896 for different degree of desired preci-sion As shown in Table 3 the required precision is measuredin terms of the ratio of false positives versus conventionalLSH FPmax(119896)FPmax(1) the ratio of false negatives versusconventional LSH FNmax(119896)FNmax(1) and the ratio of totalerrors (the sum of false positives and false negatives) versus
Computational Intelligence and Neuroscience 11
Table 3 Recommendation performance with different 119896
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Figure 18 Specificity with various 119869 and 119896
086
088
09
092
094
096
098
1
200 300 400 500 600 700
Prec
ision
Length of signature
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 19 Precision with various 119899 and 119896
the conventional LSH FNPmax(119896)FNPmax(1) For examplewe can see that if we want to generate less than half of falsenegatives in LSH FNmax(119896)FNmax(1) le 05 we should set119896 = 3
We then use the different settings of 119896 to generatecollaborator recommendations on DBLP and CITESEERXdata setsWe keep the authors who have publishedmore than25 papers We use a modified collaborative filtering [25] togenerate recommendations For each paper 119901
119886published by
author 119886 PLSH is utilized to find a set of similar publications119903 with similarity sim(119903 119901
119886) ge 119869119869 = 07 We then gather
09091092093094095096097098099
1
07 08 09Pr
ecisi
onSimilarity threshold
k = 1
k = 2
k = 3
k = 4
k = 5
Figure 20 Precision with various 119869 and 119896
the set of authors 119886(119903) who write the similar publicationsIn recommendation systems the similar authors are treatedas nearest neighbors Each nearest neighbor is assigned ascore which is the accumulated similarities between thepublication of nearest neighbor and the publication of theauthor 119886 For each author the top 5 nearest neighborswith largest accumulated similarities are returned as recom-mended collaboratorsWemanually annotate the resultsTheevaluation metric is the precision at top 5 results (1198755)The average 1198755 results are shown in Table 3 We have thefollowing conclusions (1)When the number of false positivesis reduced we can generate more precise nearest neighboursthus the recommendation performance is boosted (2)Whenthe number of false positives is too small then due to thesparsity problem the collaborative filtering framework isnot able to generate enough nearest neighbors thus therecommendation performance is deteriorated (3) A recom-mendation system achieves best performance with a finetuned parameter 119896 which optimizes the trade-off betweenfalse positives and false negatives
6 Related Work
There are fruitful research works on the similarity joins prob-lem Commonly adopted similarity measurements includecosine similarity [7] edit distance [8] Jaccard similarity [12]hamming distance [10] and synonym based similarity [27]
12 Computational Intelligence and Neuroscience
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
Themethodologies used in similarity joins can be catego-rized into two classesThe first class adopts dimension reduc-tion technologies [16] so that the similarity computation isconducted in a lower dimensional space The second classutilizes filtering approaches to avoid unnecessary similaritycomputation including prefix filter [7] length filter [7]prefix filter [20] and suffix filter [21] and positional filter[8] To take advantage of the two categories a series ofhashing methods (such as minhashing [17] minwise hashing[18] and Locality Sensitive Hashing (LSH) [10 19]) combinedimension reduction and filtering approaches by first using asignature scheme [28] to project the original feature vectorsto low dimensional signatures and then filter unqualifiedsignatures
Recently parallel algorithms are adopted on clusters ofmachines to improve efficiency of similarity joins for largescale and high dimensional data sets We have seen anemerging trend of research efforts in this line including a3-stage MapReduce approach for end-to-end set-similarityjoin algorithm [12 13] fast computation of inner productsfor large scale news articles [13] a new ant colony optimiza-tion algorithm parallelized using MapReduce [14] to selectfeatures in a high dimension space and the LSS algorithmexploiting the high data throughput of GPU [15]
In the era of big data approximate computation is alsoa possible solution if the approximate result with much lesscomputation cost is pretty close to the accurate solutionApproximate computation can be implemented not onlythrough hardware modules [29 30] but also through approx-imate algorithms [31 32] Unlike exact similarity joins [25]approximate similarity joins and top-119896 similarity joins [33]are better adapted to different application domains [34]
7 Conclusion
The problem of similarity joins based on Jaccard similarity isstudied We propose a new banding technique which reducesthe number of false positives false negatives and the sumof them From our experiments it is shown that our newmethod is both efficient and effective
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
Chen Lin is partially supported by China Natural Sci-ence Foundation under Grant nos NSFC61102136 andNSFC61472335 Base Research Project of Shenzhen Bureau ofScience Technology and Information (JCYJ2012061815565-5087) CCF-Tencent Open Research Fund under Grantno CCF-Tencent20130101 and Baidu Open Research underGrant no Z153283
References
[1] C Carpineto S Osinski G Romano and D Weiss ldquoA surveyof web clustering enginesrdquoACMComputing Surveys vol 41 no3 article 17 2009
[2] R Saracoglu K Tutuncu andN Allahverdi ldquoA fuzzy clusteringapproach for finding similar documents using a novel similaritymeasurerdquo Expert Systems with Applications vol 33 no 3 pp600ndash605 2007
[3] T C Hoad and J Zobel ldquoMethods for identifying versionedand plagiarized documentsrdquo Journal of the American Society forInformation Science and Technology vol 54 no 3 pp 203ndash2152003
[4] B Kulis andK Grauman ldquoKernelized locality-sensitive hashingfor scalable image searchrdquo in Proceedings of the IEEE 12thInternational Conference on Computer Vision (ICCV rsquo09) pp2130ndash2137 IEEE Kyoto Japan October 2009
[5] L Li L Zheng F Yang and T Li ldquoModeling and broadeningtemporal user interest in personalized news recommendationrdquoExpert Systems with Applications vol 41 no 7 pp 3168ndash31772014
[6] JWang J Feng and G Li ldquoEfficient trie-based string similarityjoins with edit-distance constraintsrdquo Proceedings of the VLDBEndowment vol 3 no 1-2 pp 1219ndash1230 2010
[7] R J Bayardo Y Ma and R Srikant ldquoScaling up all pairssimilarity searchrdquo in Proceedings of the 16th International WorldWideWebConference (WWWrsquo07) pp 131ndash140ACMMay 2007
[8] C Xiao W Wang and X Lin ldquoEd-join An efficient algorithmfor similarity joinswith edit distance constraintsrdquo inProceedingsof the VLDB Endowment vol 1 pp 933ndash944 2008
[9] G Li D Deng J Wang and J Feng ldquoPass-join a partition-based method for similarity joinsrdquo Proceedings of the VLDBEndowment vol 5 no 3 pp 253ndash264 2011
[10] A Gionis P Indyk and R Motwani ldquoSimilarity search in highdimensions via hashingrdquo inProceedings of the 25th InternationalConference on Very Large Data Bases (VLDB rsquo99) pp 518ndash529Edinburgh Scotland September 1999
[11] N X Bach N L Minh and A Shimazu ldquoExploiting discourseinformation to identify paraphrasesrdquo Expert Systemswith Appli-cations vol 41 no 6 pp 2832ndash2841 2014
[12] R Vernica M J Carey and C Li ldquoEfficient parallel set-similarity joins using MapReducerdquo in Proceedings of the ACMSIGMOD International Conference on Management of Data(SIGMOD rsquo10) pp 495ndash506 ACM June 2010
[13] T Elsayed J Lin and D W Oard ldquoPairwise document sim-ilarity in large collections with mapreducerdquo in Proceedings ofthe 46th Annual Meeting of the Association for ComputationalLinguistics on Human Language Technologies Short Papers pp265ndash268 Association for Computational Linguistics Strouds-burg Pa USA June 2008
[14] M J Meena K R Chandran A Karthik and A V Samuel ldquoAnenhanced ACO algorithm to select features for text categoriza-tion and its parallelizationrdquo Expert Systems with Applicationsvol 39 no 5 pp 5861ndash5871 2012
[15] M D Lieberman J Sankaranarayanan and H Samet ldquoA fastsimilarity join algorithm using graphics processing unitsrdquo inProceedings of the IEEE 24th International Conference on DataEngineering (ICDE 08) pp 1111ndash1120 Cancun Mexico April2008
[16] M Ture I Kurt and Z Akturk ldquoComparison of dimensionreduction methods using patient satisfaction datardquo ExpertSystems with Applications vol 32 no 2 pp 422ndash426 2007
Computational Intelligence and Neuroscience 13
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008
[17] A Z Broder M Charikar A M Frieze and M MitzenmacherldquoMin-wise independent permutationsrdquo Journal of Computerand System Sciences vol 60 no 3 pp 630ndash659 2000
[18] P Li and C Konig ldquob-Bit minwise hashingrdquo in Proceedings ofthe 19th International World Wide Web Conference (WWW rsquo10)pp 671ndash680 ACM April 2010
[19] C Chen S-J Horng and C-P Huang ldquoLocality sensitive hash-ing for sampling-based algorithms in association rule miningrdquoExpert Systems with Applications vol 38 no 10 pp 12388ndash12397 2011
[20] S Chaudhuri V Ganti and R Kaushik ldquoA primitive operatorfor similarity joins in data cleaningrdquo in Proceedings of the 22ndInternational Conference on Data Engineering (ICDE rsquo06) p 5IEEE April 2006
[21] C Xiao W Wang X Lin J X Yu and G Wang ldquoEfficientsimilarity joins for near-duplicate detectionrdquoACMTransactionson Database Systems vol 36 no 3 article 15 2011
[22] A Rajaraman and J D Ullman Mining of Massive DatasetsCambridge University Press 2011
[23] J P Lucas S Segrera and M N Moreno ldquoMaking use ofassociative classifiers in order to alleviate typical drawbacks inrecommender systemsrdquo Expert Systems with Applications vol39 no 1 pp 1273ndash1283 2012
[24] J P Lucas N LuzM NMoreno R Anacleto A A Figueiredoand C Martins ldquoA hybrid recommendation approach for atourism systemrdquo Expert Systems with Applications vol 40 no9 pp 3532ndash3550 2013
[25] J Bobadilla F Ortega A Hernando andA Gutierrez ldquoRecom-mender systems surveyrdquo Knowledge-Based Systems vol 46 pp109ndash132 2013
[26] T White Hadoop The Definitive Guide OrsquoReilly MediaSebastopol Calif USA 2012
[27] A Arasu S Chaudhuri and R Kaushik ldquoTransformation-based framework for record matchingrdquo in Proceedings of theIEEE 24th International Conference on Data Engineering (ICDErsquo08) pp 40ndash49 Cancun Mexico April 2008
[28] A Arasu V Ganti and R Kaushik ldquoEfficient exact setsimilarityjoinsrdquo in Proceedings of the 32nd International Conferenceon Very Large Data Bases pp 918ndash929 VLDB EndowmentSeptember 2006
[29] W-T J Chan A B Kahng S Kang R Kumar and J SartorildquoStatistical analysis and modeling for error composition inapproximate computation circuitsrdquo in Proceedings of the IEEE31st International Conference on Computer Design (ICCD rsquo13)pp 47ndash53 IEEE Asheville NC USA October 2013
[30] J Huang J Lach and G Robins ldquoA methodology for energy-quality tradeoff using imprecise hardwarerdquo in Proceedings of the49th Annual Design Automation Conference (DAC rsquo12) pp 504ndash509 ACM New York NY USA June 2012
[31] M W Mahoney ldquoApproximate computation and implicit reg-ularization for very large-scale data analysisrdquo in Proceedings ofthe 31st Symposium onPrinciples of Database Systems(PODS rsquo12)pp 143ndash154 ACM New York NY USA 2012
[32] J Strassburg and V Alexandrov ldquoOn scalability behaviour ofMonte Carlo sparse approximate inverse for matrix computa-tionsrdquo in Proceedings of the Workshop on Latest Advances inScalable Algorithms for Large-Scale Systems (ScalA rsquo13) pp 61ndash68 ACM New York NY USA November 2013
[33] C Xiao W Wang X Lin and H Shang ldquoTop-k set similarityjoinsrdquo in Proceedings of the 25th IEEE International Conferenceon Data Engineering (ICDE rsquo09) pp 916ndash927 IEEE April 2009
[34] K Chakrabarti S Chaudhuri V Ganti andD Xin ldquoAn efficientfilter for approximate membership checkingrdquo in Proceedings ofthe ACM SIGMOD International Conference on Management ofData (SIGMOD rsquo08) pp 805ndash817 ACM June 2008







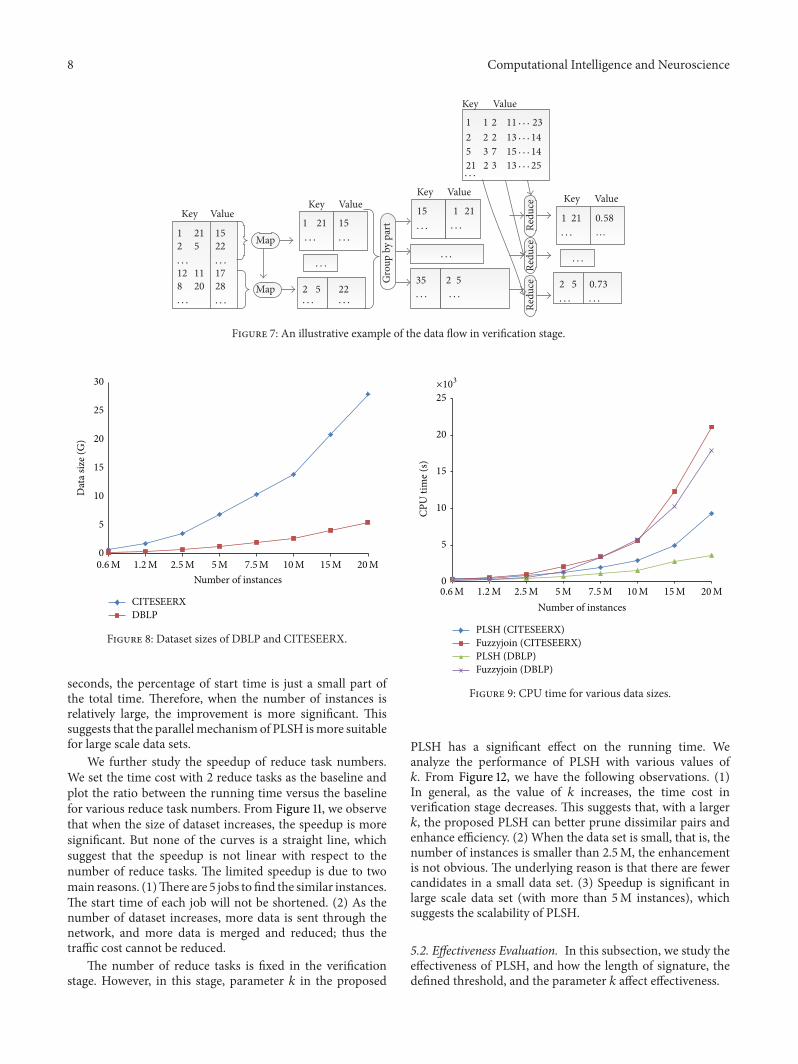
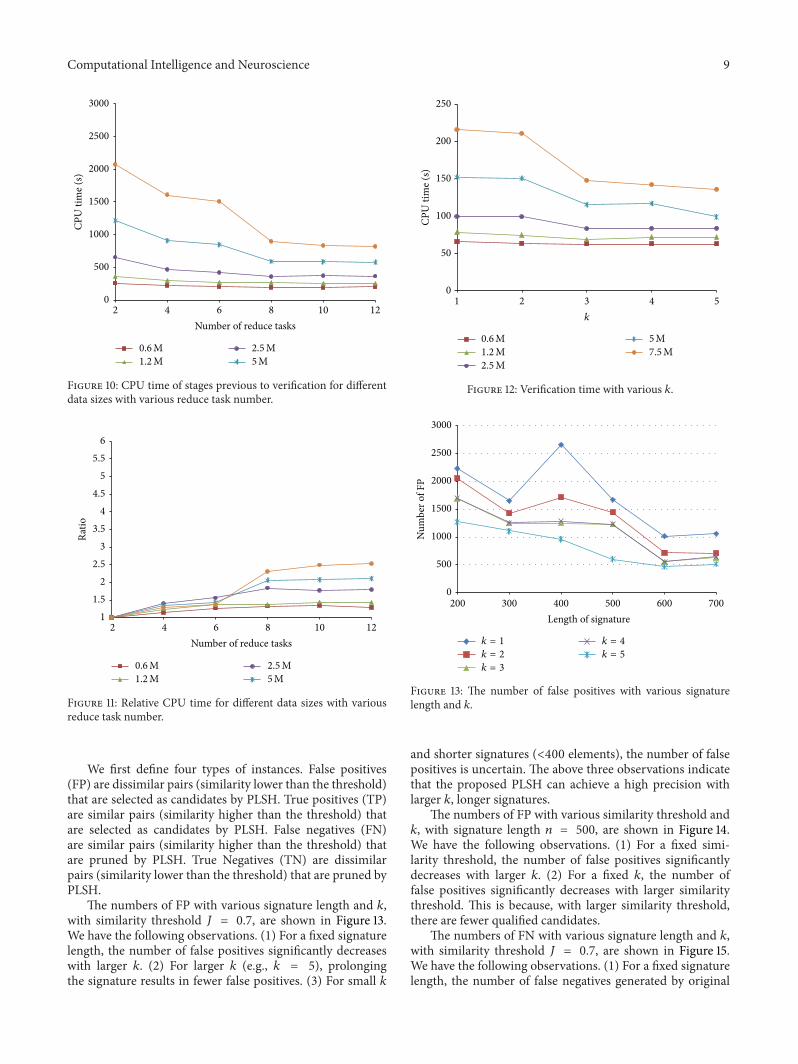



















![Fast Personalized PageRank on MapReduce...including large scale graph computations [15, 16]. One of the most well known graph computation problems is computing personalized PageRanks](https://static.documents.pub/doc/80x56/5f1d9d47d3cd8141252f1060/fast-personalized-pagerank-on-mapreduce-including-large-scale-graph-computations.jpg)


