Rutgers Information Interaction Lab at TREC 2005: Trying HARD N.J. Belkin, M. Cole, J. Gwizdka, Y.-L. Li, J.-J. Liu, G. Muresan, D. Roussinov*, C.A. Smith, A. Taylor, X.-J. Yuan Rutgers University; *Arizona State
Transcript
Rutgers Information Interaction Lab at TREC 2005:
Trying HARD
N.J. Belkin, M. Cole, J. Gwizdka, Y.-L. Li, J.-J. Liu, G. Muresan, D. Roussinov*,
C.A. Smith, A. Taylor, X.-J. Yuan
Rutgers University; *Arizona State University
Our Major Goal
• Clarification forms (CFs) are simulations of user-system interaction
• Users are unwilling to engage in explicit interaction unless payoff is high, and interaction is understood as relevant
• Is explicit interaction worthwhile, and if so, under what circumstances?
General Approach to the Question
• Use relatively “standard” interactive elicitation techniques to enhance/ disambiguate original query
• Compare results to baseline• Compare results to baseline plus relatively
“standard” non-interactive query enhancement techniques, in particular, pseudo-rf
Methods for Automatic Query Enhancement
• Pseudo-relevance feedback (standard Lemur)
• Language modeling-based query expansion (clarity), derived from collection
• Web-based query expansion
Methods for User-Based Query Enhancement
• User selection of terms suggested by “clarity” and web methods (user selection based on Koenemann & Belkin, 1996; Belkin, et al., 2000)
• Elicitation of extended information problem descriptions (elicitation based on Kelly, Dollu & Fu, 2004; 2005)
Hypotheses for Automatic Enhancement
• H1: Query expansion using “clarity”-derived terms will improve performance over baseline & baseline + pseudo-rf
• H2: Query expansion using web-derived terms will improve performance, ditto
• H2b: Query expansion using both clarity- and web-derived terms will improve performance, ditto
Hypotheses for User-Based Query Enhancement
• H3: Query expansion with terms selected by the user from those suggested by clarity- and web-derived terms will improve performance, over everything else
• H4: Query expansion using “problem statements” elicited from users will increase performance over baseline & baseline + pseudo-rf
Hypothesis for When Elicitation is Useful
• H5: The effectiveness of query expansion using problem statements will be negatively correlated with query clarity.
• RUTGALL: Baseline + all suggested terms and all user-generated terms
Identification of Suggested Terms
• Clarity: Compute query clarity for topic baseline (Lemur QueryClarity); sort terms accordingly; choose top ten
• Web: Next slide, please
Title: human smugglingDescription: Identify incidents of human smuggling
Navigation by Expansion Paradigm (NBE)
aliens
arrested
borderhaitianstrafficked
undocumented
Navigation by Expansion Paradigm (NBE)
• Step1: Overview of the surroundings– Produces words and phrases “clearly related” to the topic– Internet mining: topic sent to Google– Logistic regression on the “signal to noise” ratio:
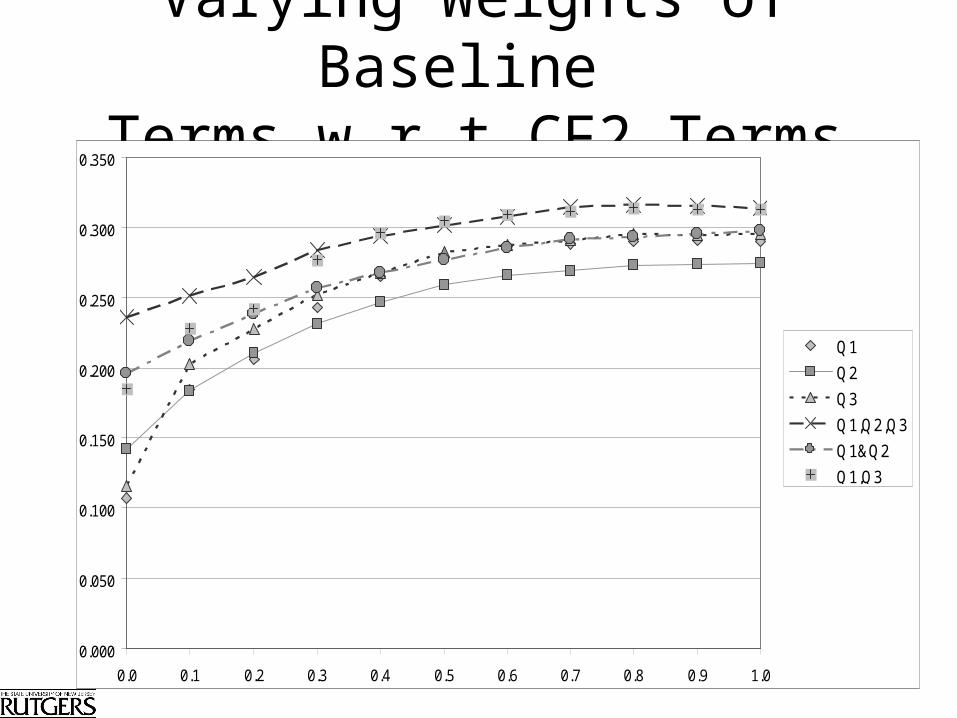
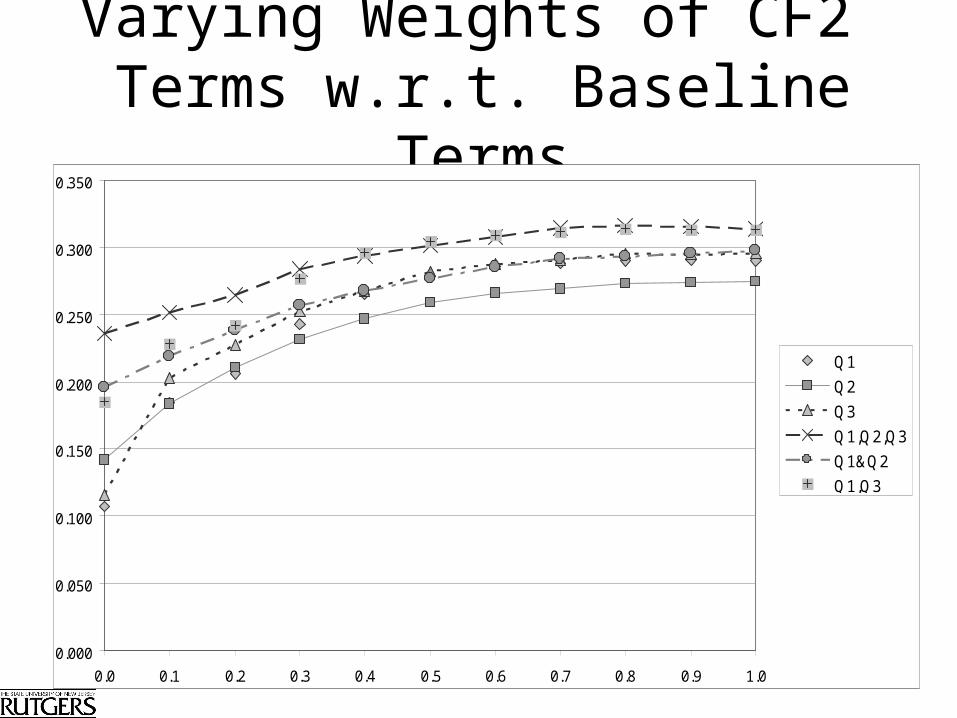
Varying Weights of CF2 Terms w.r.t. Baseline Terms
0.000
0.050
0.100
0.150
0.200
0.250
0.300
0.350
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Q1
Q2
Q3
Q1,Q2,Q3
Q1&Q2
Q1,Q3
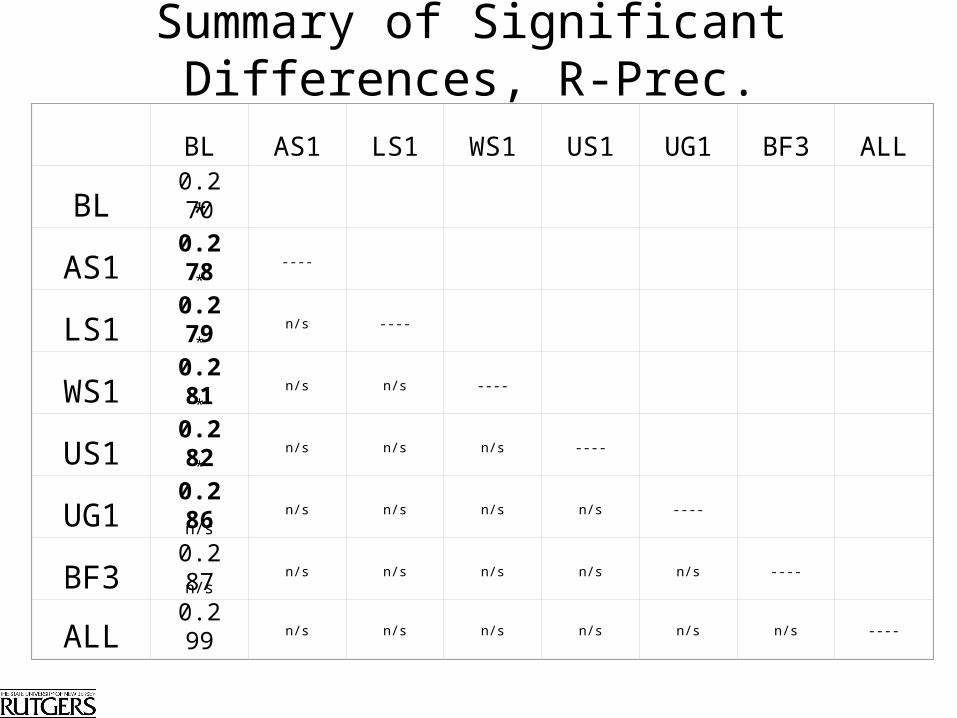
CF2 & Baseline Terms, Equal WeightsRun name R-Precision Precision at 10 Mean Average Precision
Mean SD Mean SD Mean SD
RUTGBL 0.270 0.167 0.408 0.3 0.206 0.16
Q1 0.290 0.178 0.498* 0.325 0.236 0.183
Q2 0.274 0.181 0.474* 0.321 0.223 0.181
Q3 0.295 0.164 0.498** 0.303 0.237** 0.175
Q1Q2 0.298* 0.182 0.514** 0.326 0.248** 0.190
Q1Q3 0.313* 0.176 0.538*** 0.314 0.263** 0.186
Q1Q2Q3 0.314** 0.179 0.564*** 0.304 0.268** 0.190
Results w.r.t. Hypotheses
• H1, H2, H3, H4 weakly supported w.r.t. baseline, not to pseudo-rf
• H5 not supported– No correlation between baseline query clarity,
and effectiveness of expanding with CF2 terms
Discussion (1)
• Both automatic and user-based query enhancement improved performance over baseline, but not over pseudo-rf
• No significant differences in performance between any enhancement methods, except Q1 v. Q1+Q3 (r-precision, 0.290 vs. 0.313)
Discussion (2)
• Some benefit both from automatic methods, and to explicit interaction with user, which require some effort from the user that goes beyond initial query formulation
• This interpretation of the results depends on the assumption that title+description queries are accurate simulations of user behavior
(Tentative) Conclusions
• Results indicate that invoking user interaction for query clarification is unlikely to be cost effective
• Alternative might be to develop ways to encourage more elaborate query formulation in the first instance, enhanced with automatic methods.
• Subsequent enhancement could be via implicit sources of evidence, rather than explicit questioning, requiring no additional effort from the user.